基于AI降噪模型的扩声系统及方法与流程
基于ai降噪模型的扩声系统及方法
技术领域
[0001]
本发明涉及语音数据处理技术领域,具体来说涉及一种基于ai降噪模型的扩声系统及方法。
背景技术:
[0002]
在教室或会议室场景,通常需要对语音信号进行扩声。室内扩声一般有两种方式,一种是采用手持麦克风采集声音,然后放大声音,手持麦克风的优点是灵敏度低,指向性强,采集到的噪声较少,因此需要人非常靠近麦克风才会采集到人的声音,但手持麦克风的缺点是携带不方便。
[0003]
另一种是采用吊装麦克风,吊装麦克风的灵敏度较高,采集的覆盖范围较广,能将一个区域内的所有声音都采集到麦克风,因此采集到的声音就包括人声和声场内的其它声音,而这些其它声音就是噪声,如果不经过处理,声音直接通过功放和音箱输出,就会导致噪声也放大。
技术实现要素:
[0004]
本发明旨在解决现有的室内扩声方式噪声较大的问题,提出一种基于ai降噪模型的扩声系统及方法。
[0005]
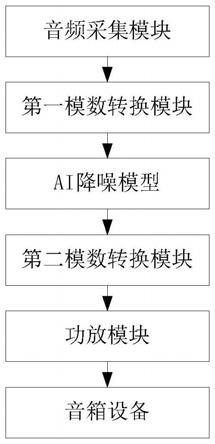
本发明解决上述技术问题所采用的技术方案是:基于ai降噪模型的扩声系统,包括:音频采集模块、第一模数转换模块、第二模数转换模块、ai降噪模型、功放模块和音箱设备;
[0006]
所述音频采集模块,用于采集音频模拟信号,并将所述音频模拟信号发送至第一模数转换模块;
[0007]
所述第一模数转换模块,用于接收音频模拟信号,将所述音频模拟信号转换为音频数字信号,并将所述音频数字信号输入至ai降噪模型;
[0008]
所述ai降噪模型,用于接收音频数字信号,对所述音频数字信号降噪后输出语音数字信号,并将所述语音数字信号输入至第二模数转换模型;
[0009]
所述第二模数转换模块,用于接收语音数字信号,将所述语音数字信号转换为语音模拟信号,并将所述语音模拟信号输入至功放模块;
[0010]
所述功放模块,用于接收语音模拟信号,对所述语音模拟信号进行模拟放大,并将模拟放大后的语音模拟信号输入至音箱设备;
[0011]
所述音箱设备,用于接收并播放放大后的语音模拟信号。
[0012]
进一步的,所述ai降噪模型通过以下方法得到:
[0013]
获取噪声样本数据和纯净语音样本数据;
[0014]
创建神经网络模型,将所述噪声样本数据和纯净语音样本数据输入至神经网络模型中训练,得到ai降噪模型。
[0015]
进一步的,所述神经网络模型为rnn模型、dnn模型或cnn模型。
[0016]
进一步的,所述音频采集模块为吊装麦克风。
[0017]
本发明还提出一种基于ai降噪模型的扩声方法,包括以下步骤:
[0018]
步骤1、采集音频模拟信号;
[0019]
步骤2、将所述音频模拟信号转换为音频数字信号;
[0020]
步骤3、通过ai降噪模型对所述音频数字信号降噪后得到语音数字信号;
[0021]
步骤4、将所述语音数字信号转换为语音模拟信号;
[0022]
步骤5、对所述语音模拟信号进行模拟放大;
[0023]
步骤6、播放放大后的语音模拟信号。
[0024]
进一步的,所述ai降噪模型通过以下方法得到:
[0025]
获取噪声样本数据和纯净语音样本数据;
[0026]
创建神经网络模型,将所述噪声样本数据和纯净语音样本数据输入至神经网络模型中训练,得到ai降噪模型。
[0027]
进一步的,步骤3中,所述神经网络模型为rnn模型、dnn模型或cnn模型。
[0028]
进一步的,步骤1中,所述音频模拟信号为通过吊装麦克风采集的音频模拟信号。
[0029]
本发明的有益效果是:本发明所述的基于ai降噪模型的扩声系统及方法,通过ai智能识别的方法进行噪声处理,通过训练噪声样本,得到训练模型,将训练模型应用到吊麦扩声系统中,能达到较好的噪声抑制效果,对非平稳噪声起到较好的抑制作用。
附图说明
[0030]
图1为本发明实施例所述的基于ai降噪模型的扩声系统的结构示意图;
[0031]
图2为本发明实施例所述的基于ai降噪模型的扩声方法的流程示意图。
具体实施方式
[0032]
下面将结合附图对本发明的实施方式进行详细描述。
[0033]
本发明所述的基于ai降噪模型的扩声系统,包括:音频采集模块、第一模数转换模块、第二模数转换模块、ai降噪模型、功放模块和音箱设备;所述音频采集模块,用于采集音频模拟信号,并将所述音频模拟信号发送至第一模数转换模块;所述第一模数转换模块,用于接收音频模拟信号,将所述音频模拟信号转换为音频数字信号,并将所述音频数字信号输入至ai降噪模型;所述ai降噪模型,用于接收音频数字信号,对所述音频数字信号降噪后输出语音数字信号,并将所述语音数字信号输入至第二模数转换模型;所述第二模数转换模块,用于接收语音数字信号,将所述语音数字信号转换为语音模拟信号,并将所述语音模拟信号输入至功放模块;所述功放模块,用于接收语音模拟信号,对所述语音模拟信号进行模拟放大,并将模拟放大后的语音模拟信号输入至音箱设备;所述音箱设备,用于接收并播放放大后的语音模拟信号。
[0034]
在应用之前,需要训练一个ai降噪模型并将其应用到扩声系统中,在具体使用时,首先采集用户输入的音频模拟信号,对采集的音频模拟信号的处理流程为:将音频模拟信号转换为音频数字信号;通过ai降噪模型对音频数字信号降噪后得到语音数字信号;将语音数字信号转换为语音模拟信号;对语音模拟信号进行模拟放大;播放放大后的语音模拟信号。在ai降噪模型中,将数字音频帧进行ai识别,如果识别为噪声,则对音频数据帧进行
降噪处理,进而得到纯净的语音数字信号,进而实现对噪声的抑制。
[0035]
实施例
[0036]
本发明实施例所述的基于ai降噪模型的扩声系统,如图1所示,包括:音频采集模块、第一模数转换模块、第二模数转换模块、ai降噪模型、功放模块和音箱设备;
[0037]
所述音频采集模块,用于采集音频模拟信号,并将所述音频模拟信号发送至第一模数转换模块;
[0038]
其中,音频采集模块可以是麦克风,对于距离用户较远的吊装麦克风来说,本实施例能够取得更好的噪声抑制效果。
[0039]
所述第一模数转换模块,用于接收音频模拟信号,将所述音频模拟信号转换为音频数字信号,并将所述音频数字信号输入至ai降噪模型;
[0040]
所述ai降噪模型,用于接收音频数字信号,对所述音频数字信号降噪后输出语音数字信号,并将所述语音数字信号输入至第二模数转换模型;
[0041]
具体而言,ai降噪模型可以采用rnn、dnn或cnn等神经网络模型得到,神经网络模型的识别精确度主要依赖于通过样本训练得到一个模型数据,本实施例中可以通过如下方式获取到用于噪声识别的ai降噪模型:
[0042]
获取噪声样本数据和纯净语音样本数据;
[0043]
创建神经网络模型,将所述噪声样本数据和纯净语音样本数据输入至神经网络模型中训练,得到ai降噪模型。
[0044]
音频数字信号输入至ai降噪模型后,ai降噪模型对该音频数字信号每一帧进行噪声识别,如果判定该帧语音信号为噪声信号,则进行降噪处理,降噪处理如减小音量。最后输出较为纯净的语音数字信号。
[0045]
所述第二模数转换模块,用于接收语音数字信号,将所述语音数字信号转换为语音模拟信号,并将所述语音模拟信号输入至功放模块;
[0046]
所述功放模块,用于接收语音模拟信号,对所述语音模拟信号进行模拟放大,并将模拟放大后的语音模拟信号输入至音箱设备;
[0047]
所述音箱设备,用于接收并播放放大后的语音模拟信号。
[0048]
基于上述技术方案,本实施例还提出一种基于ai降噪模型的扩声方法,如图2所示,包括以下步骤:
[0049]
步骤s1、采集音频模拟信号;
[0050]
步骤s2、将所述音频模拟信号转换为音频数字信号;
[0051]
步骤s3、通过ai降噪模型对所述音频数字信号降噪后得到语音数字信号;
[0052]
步骤s4、将所述语音数字信号转换为语音模拟信号;
[0053]
步骤s5、对所述语音模拟信号进行模拟放大;
[0054]
步骤s6、播放放大后的语音模拟信号。
[0055]
可以理解,由于本发明实施例所述的基于ai降噪模型的扩声方法是基于实施例所述基于ai降噪模型的扩声系统实现的方法,对于实施例公开的方法而言,由于其与实施例公开的系统相对应,所以描述的较为简单,相关之处参见系统的部分说明即可。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1