基于改进噪声估计的MMSE-LSA语音增强方法与流程
本发明涉及改进噪音的语音增强领域,具体是基于改进噪声估计的mmse-lsa语音增强方法。
背景技术:
噪声污染会使语音中的有用信息被湮没,严重影响语音质量和可懂度。语音增强技术就是在尽量减小失真的前提下抑制噪声、改善语音质量的技术。目前的语音增强方法主要基于短时谱幅度估计法、语音参数模型法、听觉场景分析法等。
而mmse-lsa方法是基于语音活动检测的,利用语音和噪声统计特性的先验知识对带噪语音帧进行噪声帧和语音帧的判决,只在噪声帧来更新噪声估计,对语音帧则延续过去的噪声谱估计,再在最小均方误差准则下估计出谱增益函数,进而重构纯净语音。但是,mmse-lsa方法由于使用经验阈值来判决噪声帧和语音帧,存在较大误差,容易出现噪声过估计和欠估计,使增强语音失真和噪声残留问题严重。
在现有技术中,虽然mmse-lsa谱估计器能够采用基于最小值控制递归平均方法,利用连续最小值跟踪得到初步噪声估计,再利用过去的噪声谱估计和当前帧的带噪语音功率谱的加权和作为当前帧的噪声估计,但是由于其语音存在概率由先验的语音存在和不存在的概率决定,仍然存在一定的噪声估计误差,使mmse-lsa语音增强性能受限;而引入短时能量和谱熵能够组成能熵比,利用能熵比进行语音存在概率的估计,再结合谱减法进行语音增强,该方法虽然能有效减小噪声估计误差,提高语音信噪比,但在非平稳环境下其仍然存在一定程度的噪声残留和语音失真问题。
所以,如何减小噪声估计误差,调高语音信噪比,并且避免在非平稳环境下的噪声残留和语音失真问题,便成为改进噪音的语音增强领域亟待解决的问题。
技术实现要素:
本发明的目的在于克服现有技术无法在减小噪声估计误差,调高语音信噪比的同时避免在非平稳环境下造成噪声残留和语音失真的不足,提供了一种基于改进噪声估计的mmse-lsa语音增强方法,通过对语音特征参数能熵比的构建,利用平滑后的语音存在概率,来达到准确地跟踪噪声变化,减小噪声残留和语音失真,改善语音质量的目的。
本发明的目的主要通过以下技术方案实现:
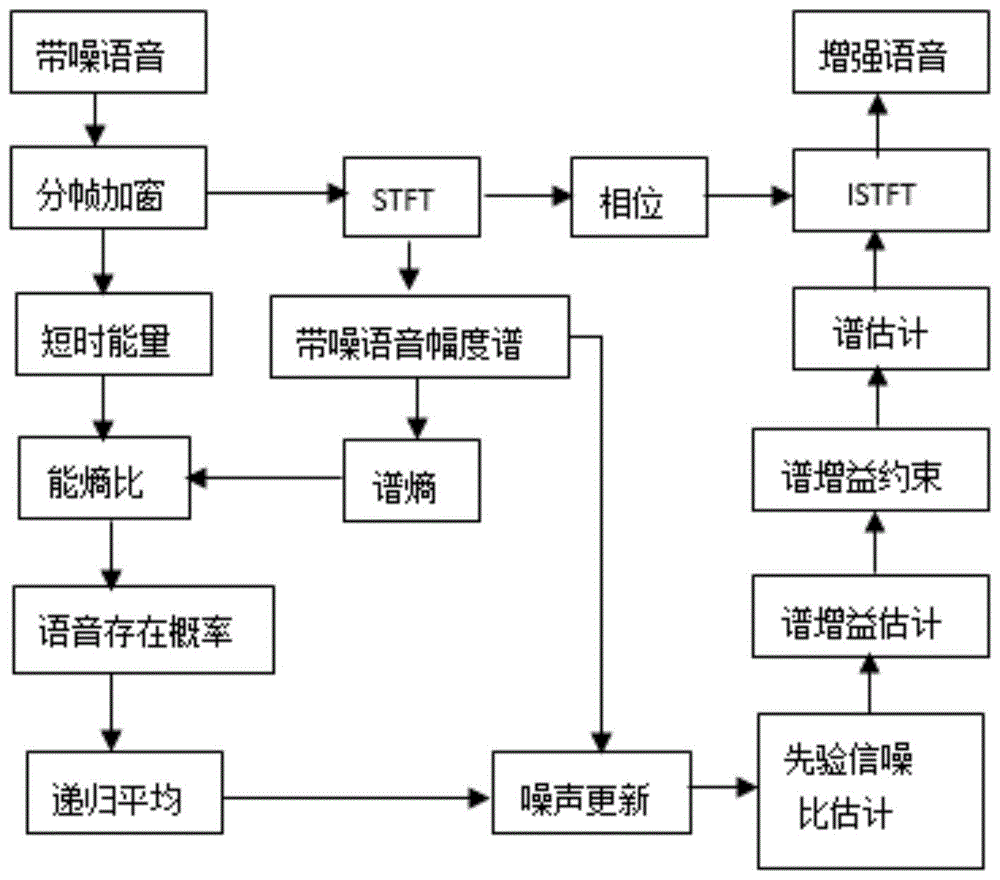
基于改进噪声估计的mmse-lsa语音增强方法,包括以下步骤:
s1:对带噪语音进行分帧、加窗处理,再对其做短时傅里叶变换,求出带噪语音的幅度谱和相角;
s2:根据步骤s1的结果,计算出带噪语音的对数能量和谱熵,构建出新的语音特征参数能熵比;
s3:根据步骤s2中的能熵比和语音存在概率的性质,得到能熵比和语音存在概率成正比关系,建立能熵比和语音存在概率的数学关系模型,得到语音存在概率估计值;
s4:对步骤s3中得出的语音存在概率估计值进行平滑,利用平滑后的语音存在概率来更新噪声功率谱估计;
s5:根据步骤s4的结果计算出先验信噪比从而得到谱增益估计,给增益函数添加一个约束阈值;
s6:根据谱估计,并利用mmse-lsa谱估计器对带噪语音进行语音增强。
在本发明中假定是y(n)输入的带噪语音,s(n)是干净语音,d(n)是噪声信号,则带噪语音模型为:
y(n)=s(n)+d(n)
由于语音是非平稳信号,其在整个时域内是变化的,而我们认为其在短时内可看作性质平稳,因此在语音增强前通常需要先对带噪语音信号y(n)进行分帧、加窗等预处理,得到信号yi(m),i表示第i帧。再对预处理后的yi(m)做短时傅里叶变换,得到第i帧带噪语音幅度谱yi(ωk)和相位θy。由于干净语音的相位不好计算,利用人耳对相位不敏感的特点,可以直接用原始带噪语音的相位θy作为增强语音的相位估计,再通过反傅里叶变换可以得到增强后的语音信号,故以下我们只对纯净语音幅度谱进行估计。假设噪声和语音相互独立,则可以对上式两边同时做短时傅里叶变换,得到:
式中,y(ωk)、s(ωk)、d(ωk)分别是第k个频率分量的带噪语音幅度谱、干净语音幅度谱、噪声幅度谱,θy、θs、θd分别是第k个频率分量的带噪语音相位、干净语音相位、噪声相位。mmse-lsa谱估计器的目的就是使增强语音对数谱幅度
假设h0(ωk)和h1(ωk)分别表示语音不存在和语音存在两种状态,则概率密度函数分别为:
式中,
假设各个频率分量独立,基于上述最小化目标函数和概率密度函数,可最终得到优化的mmse幅度谱估计器:
其中εk是先验信噪比,即第k个频谱分量的实际信噪比;γk为后验信噪比,即加入噪声后第k个频谱分量测量的信噪比,数学表达式分别为:
vk定义为:
由此可以对mmse-lsa谱估计器的增益函数做如下定义:
本发明通过对语音特征参数能熵比的构建,利用平滑后的语音存在概率,来达到准确地跟踪噪声变化,减小噪声残留和语音失真,改善语音质量的目的。
进一步的,在所述步骤s2中,所述对数能量根据语音段的短时能量大于无语音段可得,具体如下,
若假设经分帧加窗后第i帧的带噪语音信号为yi(m),则该帧的短时能量为:
其中,n为帧长,进一步改进能量计算得到对数能量:
le(i)=log10(1+e(i)/a)
式中,a取2.1。
进一步的,在所述步骤s2中,所述谱熵由下式可得,
设含噪语音信号加窗分帧后的第i帧语音信号为yi(m),经傅里叶变换后,设第k个频率分量的功率谱为yi2(ωk),则每个频率分量的归一化概率密度函数为:
则每个分析帧的谱熵为:
进一步的,在所述步骤s3中,所述能熵比和语音存在概率的数学关系模型的建立过程如下,
令wi(ωk)为能熵比,则其表达式为:
可将能熵比与语音存在概率的关系估计为:
其中,a、b均为控制参数。语音存在概率的取值范围为0到1之间,在a取值相同时,b增大,
进一步的,在所述步骤s4中,对估计出的语音存在概率进行递归平滑,其平滑形式如下:
其中,ap为平滑参数,
进一步的,在所述步骤s5中,采用如下判决引导法估计出先验信噪比εk,
其中η是平滑系数,取0.98。本发明是先采用改进的噪声估计方法估计出噪声功率谱,再由带噪语音功率谱和噪声功率谱估计求出后验信噪比γk,才使用判决引导法估计出先验信噪比εk。
进一步的,在所述步骤s5中,通过给mmse-lsa谱增益添加一个门限阈值来约束增益取值范围,约束谱增益如下:
式中,ε0为先验信噪比阈值,gfloor为常数,取0.01。
综上所述,本发明与现有技术相比具有以下有益效果:
本发明针对mmse-lsa方法对非平稳语音的噪声估计不够准确、导致语音增强性能受限的问题,引入能熵比参数来估计语音存在概率,再利用平滑后的语音存在概率来更新噪声估计;同时添加一个地板阈值来约束谱增益,缓解谱增益欠估计引起的语音失真。本发明能较好地跟踪噪声变化,减小噪声估计的误差,有效抑制噪声和减小语音失真,提高语音可懂度。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
图1为本发明方法流程示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
实施例1:
如图1所示,本实施例涉及一种基于改进噪声估计的mmse-lsa语音增强方法,包括以下步骤:
s1:对带噪语音进行分帧、加窗处理,再对其做短时傅里叶变换,求出带噪语音的幅度谱和相角;
s2:根据步骤s1的结果,计算出带噪语音的对数能量和谱熵,构建出新的语音特征参数能熵比;
s3:根据步骤s2中的能熵比和语音存在概率的性质,得到能熵比和语音存在概率成正比关系,建立能熵比和语音存在概率的数学关系模型,得到语音存在概率估计值;
s4:对步骤s3中得出的语音存在概率估计值进行平滑,利用平滑后的语音存在概率来更新噪声功率谱估计;
s5:根据步骤s4的结果计算出先验信噪比从而得到谱增益估计,给增益函数添加一个约束阈值;
s6:根据谱估计,并利用mmse-lsa谱估计器对带噪语音进行语音增强。
以本实施例设计仿真实验,从timit语料库中选择5男5女共200条录音作为初始纯净语料,噪声源使用noisex-92数据库中的white噪声、babble噪声、f16和factory噪声。语音信号的采样率为16khz,帧长为512,帧间重叠50%。按-5db、0db、5db、10db这四种信噪比将噪声分别和每条纯净语音相加,得到200条含噪语音。
以平均输出信噪比snr作为客观评价指标,语音感知质量评估作为主观评价指标,snr表达式如下:
仿真实验中使用white噪声模拟平稳环境,其他噪声模拟非平稳环境,实验结果如表1所示。可以看出,不管是在平稳环境还是非平稳环境下,本实施例中方法的输出信噪比snr、pesq分数表现都是最优,说明本实施例的方法能较好地跟踪噪声变化,有效抑制噪声,改善语音质量,且能适应于多种噪声环境。
表1输出信噪比snr和pesq分数
实施例2:
如图1所示,本实施例在实施例1的基础上,在所述步骤s2中,所述对数能量根据语音段的短时能量通常明显大于无语音段可得,具体如下,
若假设经分帧加窗后第i帧的带噪语音信号为yi(m),则该帧的短时能量为:
其中,n为帧长,进一步改进能量计算得到对数能量:
le(i)=log10(1+e(i)/a)
式中,a取2.1。
实施例3:
如图1所示,本实施例在实施例1或2的基础上,在所述步骤s2中,所述谱熵由下式可得,
设含噪语音信号加窗分帧后的第i帧语音信号为yi(m),经傅里叶变换后,设第k个频率分量的功率谱为yi2(ωk),则每个频率分量的归一化概率密度函数为:
则每个分析帧的谱熵为:
实施例4:
如图1所示,本实施例在实施例1~3任一实施例的基础上,在所述步骤s3中,所述能熵比和语音存在概率的数学关系模型的建立过程如下,
令wi(ωk)为能熵比,则其表达式为:
可将能熵比与语音存在概率的关系估计为:
其中,a、b均为控制参数。语音存在概率的取值范围为0到1之间,在a取值相同时,b增大,
本实施例中能熵比与语音存在概率实际为:当能熵比为0时,语音存在的概率为0;当能熵比为1时,语音存在的概率为0.85;当能熵比为2时,语音存在的概率为0.9;当能熵比为3时,语音存在的概率为0.92。
实施例5:
如图1所示,本实施例在实施例1~4任一实施例的基础上,在所述步骤s4中,对估计出的语音存在概率进行递归平滑,其平滑形式如下:
其中,ap为平滑参数,
实施例6:
如图1所示,本实施例在实施例1~5任一实施例的基础上,在所述步骤s5中,采用如下判决引导法估计出先验信噪比εk,
其中η是平滑系数,取0.98。
在所述步骤s5中,通过给mmse-lsa谱增益添加一个门限阈值来约束增益取值范围,约束谱增益如下:
式中,ε0为先验信噪比阈值,gfloor为常数,取0.01。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!