基于伪彩色时频图像及卷积网络的环境声音识别方法
1.本发明属于声音信号识别领域,本发明涉及一种环境声音信号检测方法,特别是一种基于伪彩色时频图像及卷积网络的环境声音识别方法。
背景技术:
2.环境声是除语音声和音乐声之外的所有可听声的总称。过去几十年来,人们主要针对语音声和音乐声进行了大量的基础和应用研究,如语音合成和识别、乐声分析与自动索检等等。将环境声作为一种单独的声音类别进行听觉感知与应用研究是近十多年的事。环境声自动识别在科学研究、工业生产、社会生活、军事斗争等诸多领域有着广泛的应用,如基于动物发声的物种调查与保护、基于声与振动的故障诊断与修复、水下目标的识别与分类等。目前,环境声识别的热门应用领域是城市中环境声识别,其对帮助人们实现智能化的城市管理具有重要意义。
3.文献“噪声背景下环境声音识别研究,electronic engineering&product world,2019,vol26(09),p34
‑
38”公开了一种基于声音增强与声谱图扇形投影特征的噪声背景下环境声音识别方法。该方法采用改进的最小递归平均算法来估计噪声方差,结合对数谱最小均方误差实现对环境声音信号去躁的目的。在对环境声音信号进行噪声去除的基础上,采用基于子带能量分布的声谱图对信号进行表征,利用gammatone滤波器组对声谱图进行滤波处理,使滤波后得到的声谱图的频率分布特性更符合人耳蜗的听觉特性。同时,用扇形投影变换对声谱图进行重构,通过重构得到声谱图在各方向的投影系数并将其作为环境声音信号的特征向量,其在降低声谱图维度的同时有效提取了声音信号特征。文献所述方法采用频率相关函数估计阈值来对信号进行噪声去除,而环境声音信号频率分布较广,从而使得该算法适应性不强;声谱图适用于对稳态信号进行表征,用其无法对非稳态的环境声音信号进行有效表征;多分类支持向量机作为分类器,分类速度慢且在高噪声条件下鲁棒性差。
技术实现要素:
4.本发明解决的技术问题是:为了解决现有的环境声音信号识别方法适应性弱、鲁棒性差且环境声音信号缺少有效的时频表征方法的问题,本发明提供了一种基于伪彩色时频图像及深度卷积神经网络的鲁棒环境声音信号识别方法。该方法首先提出了一种基于模态中心频率差分的自适应变分模态分解方法,通过其对环境声音信号进行噪声去除与信号重建,并结合伪wigner
‑
vile算法生成时频图像,该时频表征算法能在降低噪声对时频图像污染的同时有效对非稳态信号进行表征;在时频图像基础上,应用伪彩色变换将灰度时频图像转换为伪彩色时频图像,进一步提升了时频表征的鲁棒特性;针对传统分类器鲁棒性较差的问题,构建了一个基于深度卷积神经网络的环境声音信号识别模型,将伪彩色时频图像输入该模型进行识别,有效提高了算法的识别精度和鲁棒性。
5.本发明的技术方案是:一种基于伪彩色时频图像及深度卷积神经网络的鲁棒环境
声音信号识别方法,其特征在于,包括以下步骤:
6.步骤1:计算模态数为k时各模态信号u
k
及相应的中心频率ω
k
:
[0007][0008][0009][0010]
其中,f表示输入的声音信号,n表示迭代次数,τ为噪声容限,λ为拉格朗日乘子,ζ为无约束变分问题,{}表示集合;
[0011]
步骤2:计算相邻模态信号中心频率的差分值
[0012]
d
k
=ω
k+1
(t)
‑
ω
k
(t)k=1,...,k
‑1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0013]
λ
k
=d
k+1
/d
k
k=1,...,k
‑2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0014]
其中,d
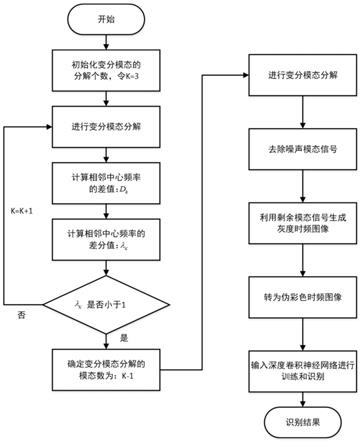
k
为中心频率差值,λ
k
中心频率差分值。
[0015]
步骤3;确定最优分解个数k
[0016][0017]
满足终止条件时,最优分解个数k
best
=k
‑
1。
[0018]
步骤4去除噪声分量后计算各模态信号的时频分布:
[0019][0020]
其中,h(τ)为高斯核函数,表示对频率的二维卷积,imf
n
为第n个模态分量信号,pwvd
n
(t,f)为第n个imf的pwvd时频图。
[0021]
步骤5重构得到灰度时频图
[0022][0023]
步骤6引入阈值并进行归一化
[0024]
pwvd(t,f)=max[pwvd(t,f)
‑
max(pwvd),
‑
80db]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0025][0026]
步骤7非线性变换得到伪彩色时频图
[0027]
m
c
(f,t)=h
c
(g(t,f))c=red,green,blue
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0028]
其中,m
c
(f,t)为第c个单色图像,h
c
为第c个单色图像的非线性映射函数;灰度图映射到hsv伪彩色时频图的三个通道所对应的非线性变换为:
[0029][0030][0031]
参数{l2,l1,u1,u2}在三个通道下的值分别为:
[0032][0033]
得到伪彩色时频图后,利用lancazos(a=3)插值算法将时频图像大小调整为512
×
512。
[0034]
步骤8:构建深度卷积神经网络。
[0035]
本发明进一步的技术方案是:所述步骤1中,
[0036]
ζ公式及迭代终止条件为:
[0037][0038][0039]
其中,α为二次惩罚因子,δ(t)为单位脉冲函数,j为虚数,*表示卷积运算,e为收敛条件,表示对t求偏导。
[0040]
本发明进一步的技术方案是:所述步骤8中,神经网络共包含26层,其中包含7层卷积层,9层激活层,7层池化层,3层全连接层,深度卷积神经网络的输入为尺寸为512
×
512的rgb三通道彩色图像,每一层卷积层都加入了relu激活函数和批标准化。
[0041]
发明效果
[0042]
本发明的技术效果在于:
[0043]
(1)步骤1~4使用基于模态中心频率差分的自适应变分模态分解方法对环境声音
信号进行了分解与噪声模态的去除,有效降低了噪声对时频图像的污染,且去噪时不依赖任何关于噪声的先验知识,算法适应性强;
[0044]
(2)传统使用的短时傅里叶变换需要采用分帧的方法对非平稳信号进行近似表示,无法获得信号的瞬时时频分布。步骤5结合伪wigner
‑
vile算法对环境声音信号进行时频表征,可以得到的时频图像的瞬时时频分布,从而使得到的时频图像分辨率更高且具有更加明确的物理意义;
[0045]
(3)步骤7采用伪彩色时频图像,通过映射灰度图像到高维彩色空间,环境噪声对声学特性的影响可以进一步减少,进一步提升了时频图像的抗噪能力;并利用卷积神经网络对伪彩色时频图像进行特征提取和分类,利用神经网络的泛化能力及抗噪能力进一步提升了识别算法的泛化能力和鲁棒性。
附图说明
[0046]
图1是算法流程图。
[0047]
图2是自适应变分模态分解的分解结果。(第一行为原信号的波形图和频谱图,第二到第五行为分解的各模态信号的波形图和频谱图。)
[0048]
图3是灰度时频图像。
[0049]
图4是伪彩色时频图像。
[0050]
图5是卷积神经网络示意图
具体实施方式
[0051]
一种基于伪彩色时频图像及深度卷积神经网络的鲁棒环境声音信号识别方法,其特点是包括下述步骤:
[0052]
步骤1计算模态数为k时各模态信号u
k
及相应的中心频率ω
k
:
[0053][0054][0055][0056]
其中,f表示输入的声音信号,n表示迭代次数,τ为噪声容限,λ为拉格朗日乘子,ζ为无约束变分问题,{}表示集合;ζ公式及迭代终止条件为:
[0057][0058][0059]
其中,α为二次惩罚因子,δ(t)为单位脉冲函数,j为虚数,*表示卷积运算,e为收敛
条件,表示对t求偏导。
[0060]
步骤2计算相邻模态信号中心频率的差分值
[0061]
d
k
=ω
k+1
(t)
‑
ω
k
(t)k=1,...,k
‑1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0062]
λ
k
=d
k+1
/d
k
k=1,...,k
‑2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(23)
[0063]
其中,d
k
为中心频率差值,λ
k
中心频率差分值。
[0064]
步骤3确定最优分解个数k
[0065][0066]
满足终止条件时,最优分解个数k
best
=k
‑
1。
[0067]
步骤4去除噪声分量后计算各模态信号的时频分布:
[0068][0069]
其中,h(τ)为高斯核函数,表示对频率的二维卷积,imf
n
为第n个模态分量信号,pwvd
n
(t,f)为第n个imf的pwvd时频图。
[0070]
步骤5重构得到灰度时频图
[0071][0072]
步骤6引入阈值并进行归一化
[0073]
pwvd(t,f)=max[pwvd(t,f)
‑
max(pwvd),
‑
80db]
ꢀꢀꢀꢀꢀꢀꢀꢀ
(27)
[0074][0075]
步骤7非线性变换得到伪彩色时频图
[0076]
m
c
(f,t)=h
c
(g(t,f))c=red,green,blue
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(29)
[0077]
其中,m
c
(f,t)为第c个单色图像,h
c
为第c个单色图像的非线性映射函数;灰度图映射到hsv伪彩色时频图的三个通道所对应的非线性变换为:
[0078][0079]
[0080]
参数{l2,l1,u1,u2}在三个通道下的值分别为:
[0081][0082]
得到伪彩色时频图后,利用lancazos(a=3)插值算法将时频图像大小调整为512
×
512。
[0083]
步骤8构建深度卷积神经网络
[0084]
本发明构建的神经网络共包含26层,其中包含7层卷积层,9层激活层,7层池化层,3层全连接层,深度卷积神经网络的输入为尺寸为512
×
512的rgb三通道彩色图像,每一层卷积层都加入了relu激活函数和批标准化。其整体结构和具体参数见下表1
‑
1。将伪彩色时频图像直接输入到卷积神经网络中进行特征提取和分类,从而实现对环境声音信号的鲁棒识别。
[0085]
表1
‑
1深度卷积神经网络结构和参数
[0086][0087][0088]
为下面结合附图对本发明的技术方案进行详细说明。
[0089]
本发明基于伪彩色时频图像和深度卷积神经网络的鲁棒环境声识别方法,具体实
施方式包括以下步骤:
[0090]
下面结合对环境声数据的识别实例说明本发明的具体实施方式,但本发明的技术内容不限于所述的范围。
[0091]
本发明提出一种基于伪彩色时频图像及深度卷积神经网络的鲁棒环境声识别方法,包括以下步骤:步骤1:利用基于频率中心差分的自适应变分模态分解对信号进行分解;步骤2:通过对低频模态信号的去除实现对背景噪声的去除,然后利用剩余模态信号结合伪wigner
‑
vile时频分布实现灰度时频图像的生成;步骤3:利用非线性变换将灰度时频图像转换为伪彩色时频图像;步骤4:将伪彩色时频图像输入到cnn中进行训练与识别。
[0092]
步骤一、信号分解。
[0093]
当环境声音信号加入背景噪声时,时频图像的相应区域也会受到噪声污染,本发明通过自适应变分模态分解实现对环境声音信号的分解与去躁。传统的变分模态分解需要预设模态信号的个数k,k值选取不当会导致模态混叠或出现虚假分量,而环境声音信号的非稳态特性导致难以准确确定k值。因此,本发明提出了基于中心频率差分的自适应变分模态分解(svmd)来实现对信号的有效分解,具体步骤如下:
[0094]
(1)初始化k值,令k=3。
[0095]
(2)对信号进行vmd分解,得到k个模态信号分量和相应的中心频率ω
k
(t)。
[0096][0097][0098][0099]
其中,n表示迭代次数,τ为噪声容限,λ为拉格朗日乘子,ζ为无约束变分问题,{}表示集合;约束ζ的公式及迭代终止条件为:
[0100][0101][0102]
其中,α为二次惩罚因子,δ(t)为单位脉冲函数,j为虚数,*表示卷积运算,e为收敛条件,表示对t求偏导。
[0103]
(3)相邻中心频率的差值:
[0104]
d
k
=ω
k+1
(t)
‑
ω
k
(t)k=1,...,k
‑1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(38)
[0105]
其中,ω
k
(t)为第k个imf
k
分量的中心频率,d
k
为第k+1个模态分量的中心频率ω
k+1
(t)与前一个模态分量的中心频率ω
k
(t)的差值,即中心频率差值。
[0106]
(4)相邻中心频率的差分值:
[0107]
λ
k
=d
k+1
/d
k
k=1,...,k
‑2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(39)
[0108]
其中,λ
k
为差分中心频率。
[0109]
(5)根据λ
k
‑2的值,判断是否达到最优分解个数k:
[0110][0111]
当中心频率差值曲线出现负增长时,即λ
k
‑2<1时,认为达到了最优分解个数,否则k=k+1继续进行循环,直到找到最优分解个数k。满足终止条件时,最优分解个数k
best
=k
‑
1。
[0112]
步骤二、噪声去除及时频图像的生成
[0113]
通过svmd分解可以将环境声信号分解成一系列中心频率由低到高增加的模态信号,而背景噪声主要分布于低频模态中,因此可以通过对低频模态信号的去除来实现去躁。利用信号分解去躁的同时,结合二次型时频分布伪wigner
‑
vile算法进行时频图像的生成,有效抑制了二次型时频分布中固有的交叉干扰项的影响,得到时频分辨率更高且具有明确物理意义的时频图像。具体步骤如下:
[0114]
(1)首先利用本发明提出的svmd对信号进行分解,确定最优分解模态个数k及相对应的k个imf:imf1,...,imf
k
。
[0115]
(2)将k个imf中的低频模态分量去除,以达到噪声去除和消除交叉干扰项的目的,由于去除低频模态也会一定程度上造成环境声音信号的丢失,因此仅将imf1模态分量去除,最后保留的模态分量为:imf2,...,imf
k
。
[0116]
(3)利用pwvd时频分布求各模态分量的时频图:
[0117][0118]
其中,h(τ)为高斯核函数,表示对频率的二维卷积,imf
n
为第n个模态分量信号,pwvd
n
(t,f)为第n个imf的pwvd时频图。
[0119]
(4)对各模态分量的时频图进行线性叠加,得到灰度时频图:
[0120][0121]
(5)引入阈值并进行归一化
[0122]
pwvd(t,f)=max[pwvd(t,f)
‑
max(pwvd),
‑
80db]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(43)
[0123][0124]
步骤三、转换为伪彩色时频图
[0125]
通过非线性函数将灰度时频图映射到r、g、b三个通道,从而得到三通道的伪彩色时频图。时频图像的鲁棒性是由环境声音信号时频图像的稀疏分布特性产生的,噪声的能量强度主要分布于谱图的低频区域,而时频图的高频区域仍由声音信号的高频成分主导,并未受到噪声较大干扰。而通过将灰度图经过非线性映射到高维颜色空间,可以进一步降低环境噪声对声特征的影响。
[0126]
非线性变换的公式为:
[0127]
m
c
(f,t)=h
c
(g(t,f))c=red,green,blue
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(45)
[0128]
其中,m
c
(f,t)为第c个单色图像,h
c
为第c个单色图像的非线性映射函数;将灰度图映射到hsv伪彩色时频图的三个通道所对应的非线性变换为:
[0129][0130][0131]
对非线性变换公式中的超参数{l2,l1,u1,u2}在red、green和blue三个颜色通道下进行赋值即可得到hot伪彩色时频图变换对应的非线性公式,相应的参数值为:
[0132][0133]
得到伪彩色时频图后,利用lancazos(a=3)插值算法将时频图像大小调整为512
×
512。
[0134]
步骤四、环境声音信号的识别
[0135]
本发明通过构建一个基于深度卷积神经网络的识别模型来实现对环境声音信号的识别。该神经网络共26层,包含了7层卷积层,9层激活层,7层池化层,3层全连接层,其整体结构和具体参数在表1
‑
1中已详细列出,这里不再赘述。首先需要构建环境声音数据库,数据库中的声音信号通过上述步骤变换后得到伪彩色时频图像,最后将其输入到神经网络中进行训练,在训练过程中需要设置批大小、学习率、动量、训练批次等超参数。训练好的神经网络模型即可实现对相应类型环境声音信号的识别。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1