一种音视频的高码率获取方法与流程
1.本发明涉及信号处理领域,尤其涉及一种音视频的高码率获取方法。
背景技术:
2.网络的普及,使得网络上的音乐资源越来越丰富,数字格式音乐非常流行。然而现在大部分流通的数字音乐都是普通数字音乐,其优势在于通过有损压缩到达缩小文件体积的目的,但随之而来的却是音乐质量受到损害。高质量数字音乐给听众带来更好的音乐体验,但体积庞大。
技术实现要素:
3.鉴于上述技术问题,本发明旨在提供一种对于低码率信号恢复到高码率信号都可行的方法,例如高质量语音的重构,高分辨率图像的获取,均可通过本发明的方法训练得到不同的字典,从而应用到不同的场合。
4.本发明解决上述技术问题的主要技术方案为:
5.一种音视频的高码率获取方法,其特征在于,应用于将低码率信号恢复到高码率信号,且所述低码率信号和所述高码率信号为一个信号的两个码率版本,所述获取方法包括:
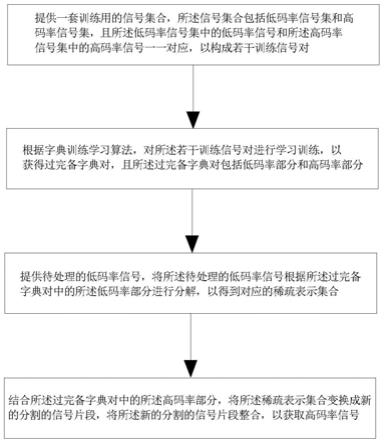
6.步骤s1,提供一套训练用的信号集合,所述信号集合包括低码率信号集和高码率信号集,且所述低码率信号集中的低码率信号和所述高码率信号集中的高码率信号一一对应,以构成若干训练信号对;
7.步骤s2,根据字典训练学习算法,对所述若干训练信号对进行学习训练,以获得过完备字典对,且所述过完备字典对包括低码率部分和高码率部分;
8.步骤s3,提供待处理的低码率信号,将所述待处理的低码率信号根据所述过完备字典对中的所述低码率部分进行分解,以得到对应的稀疏表示集合;
9.步骤s4,结合所述过完备字典对中的所述高码率部分,将所述稀疏表示集合变换成新的分割的信号片段,将所述新的分割的信号片段整合,以获取高码率信号;
10.其中,获得所述过完备字典对的步骤包括:
11.步骤a1,将所述低码率信号按重叠比例和低码率向量帧长度进行分帧,得到若干低码率向量帧;
12.步骤a2,将所述高码率信号按重叠比例和高码率向量帧长度进行分帧,得到若干高码率向量帧;
13.步骤a3,将所述若干低码率向量帧构成所述低码率部分,所述若干高码率向量帧构成所述高码率部分,且所述低码率部分和所述高码率部分用以训练生成所述过完备字典对。
14.优选的,上述音视频的高码率获取方法中,所述字典训练学习算法以对应的所述低码率向量帧和所述高码率向量帧对作为输入,以输出所述过完备字典对。
15.优选的,上述音视频的高码率获取方法中,所述低码率向量帧和所述高码率向量帧满足公式:
[0016][0017]
其中,d
p
为所述过完备字典对中的所述低码率部分,d
g
为所述过完备字典对中的所述高码率部分;
[0018]
为所述低码率向量帧,i表示编号;
[0019]
为所述高码率向量帧,i表示编号;
[0020]
n
p
为所述低码率向量帧长度,n
g
为所述高码率向量帧长度;
[0021]
s
i
为所述稀疏表示集合中的稀疏表示向量,所述低码率向量帧和所述高码率向量帧共用同一稀疏表示向量。
[0022]
优选的,上述音视频的高码率获取方法中,计算获得所述过完备字典对的公式为:
[0023][0024][0025][0026][0027]
其中,d
c
为所述过完备字典对;
[0028]
为平衡参数,用于平衡误差和稀疏度之间的重要程度。
[0029]
优选的,上述音视频的高码率获取方法中,所述取值在0-1之间,且所述取值越大表示稀疏性越重要,越小表示误差越重要。
[0030]
优选的,上述音视频的高码率获取方法中,所述取值为0.15。
[0031]
优选的,上述音视频的高码率获取方法中,获取所述高码率信号的步骤包括:
[0032]
步骤1,将所述低码率信号分解成低码率向量帧;
[0033]
步骤2,提取所述过完备字典对的低码率部分,将所述低码率向量帧分解成稀疏表示向量;
[0034]
步骤3,提取所述过完备字典对的高码率部分,结合所述稀疏表示向量,重构得到高码率向量帧;
[0035]
步骤4,将得到的所述高码率向量帧整合,以获取所述高码率信号。
[0036]
优选的,上述音视频的高码率获取方法中,步骤4中的所述整合步骤和步骤1中的所述分解步骤为互逆操作。
[0037]
优选的,上述音视频的高码率获取方法中,所述步骤2的公式为:
[0038][0039]
其中,为所述低码率向量帧,i表示编号;
[0040]
d
p
为所述过完备字典对中的所述低码率部分;
[0041]
s
i
为所述稀疏表示集合中的稀疏表示向量,所述低码率向量帧和所述高码率向量帧共用同一稀疏表示向量。
[0042]
优选的,上述音视频的高码率获取方法中,所述步骤3的公式为:
[0043][0044]
其中,为所述高码率向量帧,i表示编号;
[0045]
d
g
为所述过完备字典对中的所述高码率部分;
[0046]
s
i
为所述稀疏表示集合中的稀疏表示向量,所述低码率向量帧和所述高码率向量帧共用同一稀疏表示向量。
[0047]
上述技术方案具有如下优点或有益效果:
[0048]
本发明通过训练信号集来学习用于高码率信号获取的过完备字典对,该字典对由低码率部分和高码率部分组成,根据训练得到的过完备字典对中的低码率部分对待处理的信号进行分解,从而得到一组稀疏表示向量,再根据得到的稀疏表示向量,结合过完备字典对中的高码率部分,计算得到与待处理的低码率信号相对应的高码率信号。本发明的技术方案新颖,结构明确,容易实施。
附图说明
[0049]
参考所附附图,以更加充分的描述本发明的实施例。然而,所附附图仅用于说明和阐述,并不构成对本发明范围的限制。
[0050]
图1为本发明的音视频的高码率获取方法的流程图;
[0051]
图2为实施例中基于本发明的方法获取高质量数字音乐的示意图。
具体实施方式
[0052]
在下文的描述中,给出了大量具体的细节以便提供对本发明更为彻底的理解。当然除了这些详细描述外,本发明还可以具有其他实施方式。
[0053]
本发明的音视频的高码率获取方法,参考图1,对于低码率信号恢复到高码率信号都是可行的,例如对于高质量语音的重构,高分辨率图像的获取都具有可行性。主要根据训练得到的字典不同,而应用的场合不同。
[0054]
例如用于高质量的数字音乐获取,通过训练音乐集来学习用于高质量数字音乐获取的过完备字典对,该字典对有普通部分和高质量部分组成,根据训练得到的过完备字典对中普通部分对待处理的音乐进行分解,从而得到一组稀疏表示向量,再根据得到的稀疏表示向量,结合过完备字典对的高质量部分,从而计算得到与待处理普通数字音乐相对应的高质量数字音乐。一般普通数字音乐通过应用本发明的方法而从体积较小的有损音乐中重新生成具有更好音乐体验的高质量数字音乐。采用本发明的方法将普通的音乐资源转换成高质量数字音乐,在不增加流通媒体体积和其他成本的情况下,获得了更好的音乐体验。
[0055]
下面就以高质量的数字音乐获取为例具体阐述本发明的音视频的高码率获取方法。
[0056]
实施例一
[0057]
参照图2示意图所示,本实施例中对高质量数字音乐获取方法主要包含以下几点:
[0058]
一、训练阶段。需要有训练用的音乐集合,包含普通数字音乐和高质量数字音乐,而且是成对的,即相同的音乐有普通版本和高质量版本,通过对这些音乐集合进行学习训练,获得可用的过完备字典对。需要注意的是,训练好的字典可以用于以后的高质量音乐重构,而不是每次从普通数字音乐获取高质量数字音乐都需要重新训练字典。
[0059]
二、处理阶段。将待处理的普通数字音乐,按照字典规格,进行分割,结合训练得到的过完备字典对中的普通部分,将分割的音乐进行分解,得到分解后的稀疏表示集合。
[0060]
三、完成阶段。再结合过完备字典对中的高质量部分,将之前得到的稀疏表示集合变换成新的分割的音乐片段,将这些重新生成的音乐片段组合,得到高质量数字音乐。
[0061]
具体的,本实施例的基于过完备字典对的高质量数字音乐获取方法包括以下详细步骤:
[0062]
第一步,提供一套训练用的音乐集合,该音乐集合由两部分组成,分别是普通数字音乐集和高质量数字音乐集,该普通数字音乐集和高质量数字音乐集具有一一对应关系,从而构成训练音乐对。
[0063]
第二步,根据字典训练学习算法,将所述音乐集合用于训练,获得过完备字典对。过完备字典对由过完备字典对普通部分和过完备字典对高质量部分组成。该过完备字典对普通部分用于分解普通数字音乐,得到对应的稀疏表示。
[0064]
具体的,训练过完备字典对的步骤(也即字典训练部分)还包括:
[0065]
提供一套训练用的音乐集合,该音乐集合由两部分组成,分别是普通数字音乐集和高质量数字音乐集,该普通数字音乐集和该高质量数字音乐集具有一一对应关系,从而构成训练音乐对。
[0066]
将普通数字音乐按重叠比例,普通向量帧长度,进行分帧,得到若干普通向量帧。
[0067]
将高质量数字音乐按重叠比例,高质量向量帧长度,进行分帧,得到若干高质量向量帧。
[0068]
其中,普通向量帧记为i表示编号;
[0069]
高质量向量帧记为i表示编号;
[0070]
重叠比例记为φ;
[0071]
普通帧块长度记为n
p
;
[0072]
高质量帧块长度记为n
g
。
[0073]
则训练用核心公式为:(字典学习算法接收普通向量帧和高质量向量帧对作为输入,过完备字典对作为输出)
[0074]
在满足约束:
[0075][0076]
时,改写
[0077][0078][0079][0080][0081]
其中,字典学习算法输出过完备字典对d
c
。
[0082]
过完备字典对普通部分记为d
p
[0083]
过完备字典对高质量部分记为d
g
[0084]
为平衡参数,用于平衡误差和稀疏度之间的重要程度,取值在0-1之间,越大表示稀疏性越重要,越小表示误差更重要,一般取值0.15。
[0085]
稀疏表示向量记为s
i
,普通向量帧和高质量向量帧共用同一稀疏表示向量。
[0086]
第三步,根据得到的普通数字音乐的稀疏表示,再结合过完备字典对高质量部分,获取高质量数字音乐。
[0087]
具体的,获取高质量数字音乐的步骤(也即高质量音乐获取部分)还包括:
[0088]
提供待处理普通数字音乐和过完备字典对。
[0089]
步骤1,将普通数字音乐分解成普通向量帧(分解方法同第二步中字典训练部分)。
[0090]
步骤2,提取过完备字典对普通部分,将普通向量帧分解成稀疏表示向量。
[0091]
步骤3,提取过完备字典对高质量部分,结合稀疏表示向量,重构得到高质量向量帧。
[0092]
步骤4,将得到的高质量向量帧整合,得到高质量音乐。
[0093]
用公式表示记为
[0094]
(步骤2)
[0095]
(步骤3)
[0096]
需要注意的是,整合部分和分帧部分是逆操作,将得到的若干向量帧重新整合即得到完整的音乐。
[0097]
实施例二
[0098]
在获取高质量数字音乐的过程中,首先需要对音乐训练集进行学习训练,从而构成过完备字典对。在本次实施例中,我们采用马克西姆2008年发行的专辑《greastest maksim》作为高质量音乐训练集(16比特,采样率44.1khz),对该专辑里面的音乐进行4倍降采样,得到普通音乐集合(16比特,采样率11.05khz)。
[0099]
首先,训练部分:
[0100]
分帧:将高质量数字音乐读取,然后获得一段较长的一维信号,对该信号进行随机分段提取,每段长度为160,总共提取2,000,000段。同理记录下这2,000,000段高质量音乐帧的位置,找到相应位置的普通音乐片段,由于普通音乐是高质量音乐的4倍降采样,因此可得到2,000,000段普通音乐帧,每段长度为40。
[0101]
训练:字典包含的原子个数1024,那么最后得到的字典的大小就是200x1024。通过对这200万对音乐片段,得到训练后的字典,其中普通部分大小是40x1024,高质量部分是160x1024,整体的大小是200x1024。
[0102]
其次,处理部分:
[0103]
以《克罗地亚狂想曲》为例,准备一首普通音质的数字音乐,通过训练好的字典,得到高质量数字音乐。
[0104]
分帧:首先将普通数字音乐进行分帧,根据字典长度,字典普通音乐的大小是40x1024,那么我们将该音乐分解成为若干个长度为40的音乐帧,为了保证音乐质量,各相邻音乐帧之间有50%的重叠。
[0105]
分解:将得到的若干个音乐帧进行分解,提取过完备字典对的普通部分,将长度为40的音乐帧分级为长度为1024的稀疏表示向量,若干个音乐帧分别分解,得到一个稀疏表示集合。
[0106]
重构:用得到的稀疏表示集合去查找过完备字典的高质量部分,从而得到若干个长度为160的高质量音乐帧。
[0107]
整合:将若干个高质量音乐帧按50%的重叠稀疏进行整合,得到完整的高质量音乐。
[0108]
需要注意的是,其中音乐帧长度,字典长度,重叠比例这些都是可以根据需要来进行灵活设置的。即可以构造多个字典,然后根据需要来重构出想要的音乐。举例的是4倍重构,倍数越大,重构越难。
[0109]
以上通过基于超完备字典对的高质量音乐获取(也即用于音乐的重构)示例,对本发明的音视频的高码率获取方法进行了详细阐述。需要注意的是,本发明的方法从本质上来讲对于任何低码率信号恢复到高码率信号的情况都是可行的,例如对于其他的高质量语音的重构,高分辨率图像的获取都具有可行性。只要根据本发明的方法,训练得到的字典不同,就可以实现应用的场合不同。
[0110]
综上所述,本发明通过训练信号集来学习用于高码率信号获取的过完备字典对,
该字典对由低码率部分和高码率部分组成,根据训练得到的过完备字典对中的低码率部分对待处理的信号进行分解,从而得到一组稀疏表示向量,再根据得到的稀疏表示向量,结合过完备字典对中的高码率部分,计算得到与待处理的低码率信号相对应的高码率信号。本发明的技术方案新颖,结构明确,容易实施。
[0111]
对于本领域的技术人员而言,阅读上述说明后,各种变化和修正无疑将显而易见。因此,所附的权利要求书应看作是涵盖本发明的真实意图和范围的全部变化和修正。在权利要求书范围内任何和所有等价的范围与内容,都应认为仍属本发明的意图和范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1