一种基于transformer模型编码器的语音情感特征提取方法与流程
1.本发明涉及一种语音情感特征提取方法,尤其适用于人工智能和语音情感识别领域使用的一种基于transformer模型编码器的语音情感特征提取方法。
背景技术:
2.随着科技的进步,人机交互已经成为一个重要的研究领域。语音情感识别技术可以使机器更加人性化。目前,语音情感识别已研究了数十余年,其本质为计算机对人类情感感知和理解过程的模拟,任务就是从预处理后的语音信号中提取有效的情感声学特征,并找出这些声学特征与人类情感的映射关系。
3.在语音情感识别的研究中,如何从语音信号中提取出最具情感信息的特征仍是一大难题与热点。已有技术中使用较多的特征主要是语音的韵律学信息、音质信息和频谱信息。韵律信息主要包括音高,语速和能量以及停顿;频谱信息目前用的最广泛的是mel频率倒谱系数(mfcc)、线性预测系数(lpc)。由于很多情感的韵律特征具有相同的特性,因此单独使用感知特征(低级描述符和它们的统计值)不能保证系统获得良好的性能。在语音情感识别中,应该强调其情感信息,消减语音、说话人、性别等无关信息,因而迫切需要一种能够更加适合于语音情感识别的特征提取方式,如何从语音信号中提取出更加适合于语音情感识别的特征成为了提高识别率的最关键问题。
4.近十年来在模式识别领域兴起的一种模仿人类大脑学习的技术——深度学习,从早期的人工神经网络发展而来,已经成功应用于语音情感识别,并表现了良好的性能。直接利用深度网络提取语音信号中的情感特征也成为了一种热点。但是目前仍以rnn、dnn等神经网络提取学习特征的系统较多,但是由于易存在长距离梯度消失以及长序列到定长向量的信息损失问题,因此传统的神经网络对于语音情感的全局信息尚未能很好的提取,存在很大的局限性,而这个性质在语音情感特征方面是相当重要的。
技术实现要素:
5.针对上述技术的不足之处,提供一种针对语音情感识别中全局特征的提取方法,直接在原始语音波形中捕捉低级语音情感特征,对transformer模型编码器进行改进,在该模型前添加了一层sincnet滤波器,以选取出更具有情感信息的特征,能够对语音情感的全局信息进行提取的基于transformer模型编码器的语音情感特征提取方法。
6.为实现上述技术目的,本发明的基于transformer模型编码器的语音情感特征提取方法,首先利用sincnet滤波器从原始语音波形中提取低级语音情感特征,然后利用多层transformer模型编码器对低级语音情感特征进一步学习;其中改进后的transformer模型编码器为常规transformer模型编码器前添加一层sincnet滤波器,即一组具有带通滤波器的参数化sinc函数,利用sincnet滤波器完成语音原始波形信号的低级特征提取工作,并使网络更好的捕捉重要的窄带情感特征,如音调和共振峰。
7.具体步骤如下:
8.s1:将输入的语音数据预处理后转换为原始语音波形;
9.s2:在常规transformer模型编码器的前添加一层sincnet滤波器,构建出一个可融合全局上下文信息特征的改进transformer模型编码器;
10.s3:将原始语音波形与sincnet进行卷积计算,捕捉出语音信号中包含的低级情感信息特征h[n];如重要的窄带情感特征,音调和共振峰;
[0011]
s4:使用transformer模型编码器对低级情感信息特征h[n]再次进行处理,得到更深层次包含全局上下文信息的帧级情感特征y[n]
[0012]
s5:将具有全局信息的帧级情感特征y[n]输入池化层,通过池化并与经验权重向量相乘,使每一次迭代中的帧级特征合并,最终合并为一个话语级情感特征向量;
[0013]
s6:利用softmax分类器对话语级情感特征进行分类,从而获得当前的输入语音数据的情感。
[0014]
优选的,所述改进transformer模型编码器,由sincnet滤波器与transformer模型编码器构建的一种融合上下文特征的神经网络结构,包括输入层、中间层以及输出层,所述中间层包括顺序连接的sincnet滤波器、transformer模型编码器结构以及池化层,其中常规transformer模型编码器部分包括多头注意力子层、全连接层以及前馈神经网络。
[0015]
优选的,将语音数据转换成原始语音波形的步骤如下:首先对原始波形信号进行预加重、加窗分帧和端点检测的预处理获得x[n],每个语音波形的采样率设置为16khz,16bit量化,同时使用窗长和偏移为250ms和10ms的hamming窗口,再将语音信号转变为原始语音波形图。
[0016]
优选的,步骤s2具体为:
[0017]
将语音波形信号x[n]和sincnet层滤波器组函数g[n,θ]之间执行卷积计算,构建出包含低级情感信息特征h[n],其映射关系式为:h[n]=x[n]*g[n,θ],其中θ为可学习参数,g为滤波器组函数;
[0018]
进一步地,所述sincnet层是一种基于参数化sinc函数,由矩形带通滤波器组成,矩形带通滤波器能够用两个具有可学习截止频率的低通滤波器来表示,具体公式如下:
[0019]
g[n,f1,f2]=2f2sinc(2πf2n)-2f1sinc(2πf1n),
[0020]
其中,f1,f2表示低截止频率和高截止频率。低截止频率和高截止频率是从数据中学习到的滤波器的唯一参数。
[0021]
优选的,步骤s4的具体为:
[0022]
s41:将s3得到的包含浅层情感信息的特征向量输入到transformer模型编码器的多头注意力子层,得到输入语音的帧级注意力特征向量;
[0023]
多头注意力子层先将输入向量映射到不同的子空间中,再分别在所有子空间上做点乘运算,计算出注意力向量,最后把所有子空间计算得到的注意力向量拼接起来,并映射到原输入空间中,得到最终的注意力向量作为输出;从而获取到全局的上下文信息,避免传统循环神经网络因梯度消失或梯度爆炸而导致的信息消失问题;具体公式如下:
[0024]
mutihead(q,k,v)=concat(head1,
…
,head
h
)w
o
[0025]
其中,head
i
=attention(qw
iq
,kw
ik
,vw
iv
)
[0026]
其中mutihead(q,k,v)是multi-headattention层的输出结果;concat是矩阵拼接函数;head
i
是第i个head的输出结果,h是head的个数;w
o
是输出的映射参数矩阵;w
iq
、w
ik
、w
iv
分别为q、k、v在第i个head上的映射参数矩阵;
[0027]
每一个head均采用scaleddot-productattention,具体计算公式如下
[0028][0029]
其中attention(q,k,v)是scaled dot-product attention的输出,softmax(x)是归一化指数函数;w
rl
是序列相对位置关系权重参数;k
t
为矩阵k的转置;为比例因子;
[0030]
s42:将s41得到的输入语音的帧级注意力特征向量输入到编码器的前向反馈子层,得到输入语音的上下文特征向量;前向反馈子层由两层前馈神经网络组成,是对多头注意力子层的输出进行两次线性变换和一次relu激活,具体公式如下:
[0031]
ffn(x)=max(0,xw1+b1)w2+b2[0032]
多头注意力子层和前向反馈子层都包含一个残差连接结构,将子层输出与子层输入相加再做规范化作为子层最终输出,每个子层最后的输出公式为:output=layernorm(input+sublayer(input)),
[0033]
其中,layernorm为层规范化操作,input为子层输入,sublayer为子层相应的计算公式,即上述mutihead或ffn公式。
[0034]
s43:重复s41与s42的步骤6次,得到输入语音的最终上下文特征向量。
[0035]
优选的,所述s6将话语级情感特征向量输入到softmax分类中,使用softmax分类器来预测标签情感类别,将输出映射到(0,1)区间内,可以对应情感类别的概率;最终取概率最大的维度所对应的情感类别作为最终输出结果,从而输出与整段语音相对应的情感类别,即模型对预测的情感进行分类。
[0036]
有益效果:
[0037]
本发明没有采用手工制作的低级描述符及其统计数值作为语音情感特征,提出一种基于transformer模型编码器的语音情感识别方法,使用transformer模型编码器作为主体模型,以获取深度双向全局表征。
[0038]
本发明采用transformer模型编码器代替rnn、cnn网络结构,将语音转换成原始波形图作为原始输入,能够在把输入序列上不同位置的信息联系起来,即考虑输入的每条语音全局上下文情感逻辑,可以获得更深层次包含全局上下文信息的帧级情感特征。
[0039]
在transformer模型编码器网络前添加一层sincnet滤波器用以克服语音情感中信息分布不平均等问题,从而在原始语音波形中捕捉一些重要的窄带情感特征,如音调和共振峰等,使其整个网络结构在特征提取过程中具有指导性。
附图说明
[0040]
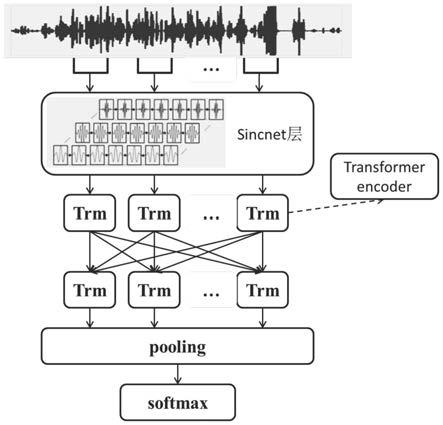
图1是本发明基于transformer模型编码器的语音情感特征提取方法中的系统框架图;
[0041]
图2是本发明基于transformer模型编码器的语音情感特征提取方法中的transformer模型编码器内部结构框架图
具体实施方式
[0042]
为了更充分的解释本发明,下面结合附图和具体实施方式对本发明进行详细说明。以下实施例仅用于更加清楚说明本发明的技术方案,而不能以此来限制本发明的保护范围。
[0043]
如图1所示,本发明的基于transformer模型编码器的语音情感特征提取方法,首先利用sincnet滤波器从原始语音波形中提取低级语音情感特征,然后利用多层transformer模型编码器对低级语音情感特征进一步学习;其中改进后的transformer模型编码器为常规transformer模型编码器前添加一层sincnet滤波器,即一组具有带通滤波器的参数化sinc函数,利用sincnet滤波器完成语音原始波形信号的低级特征提取工作,并使网络更好的捕捉重要的窄带情感特征,如音调和共振峰。
[0044]
具体步骤如下:
[0045]
s1:将输入的语音数据预处理后转换为原始语音波形;
[0046]
s2:在常规transformer模型编码器的前添加一层sincnet滤波器,构建出一个可融合全局上下文信息特征的改进transformer模型编码器;
[0047]
具体的,将语音波形信号x[n]和sincnet层滤波器组函数g[n,θ]之间执行卷积计算,构建出包含低级情感信息特征h[n],其映射关系式为:h[n]=x[n]*g[n,θ],其中θ为可学习参数,g为滤波器组函数;
[0048]
进一步地,所述sincnet层是一种基于参数化sinc函数,由矩形带通滤波器组成,矩形带通滤波器能够用两个具有可学习截止频率的低通滤波器来表示,具体公式如下:
[0049]
g[n,f1,f2]=2f2sinc(2πf2n)-2f1sinc(2πf1n),
[0050]
其中,f1,f2表示低截止频率和高截止频率。低截止频率和高截止频率是从数据中学习到的滤波器的唯一参数。
[0051]
如图2所示,所述改进transformer模型编码器,由sincnet滤波器与transformer模型编码器构建的一种融合上下文特征的神经网络结构,包括输入层、中间层以及输出层,所述中间层包括顺序连接的sincnet滤波器、transformer模型编码器结构以及池化层,其中常规transformer模型编码器部分包括多头注意力子层、全连接层以及前馈神经网络;
[0052]
s3:将原始语音波形与sincnet进行卷积计算,捕捉出语音信号中包含的低级情感信息特征h[n];如重要的窄带情感特征,音调和共振峰;
[0053]
将语音数据转换成原始语音波形的步骤如下:首先对原始波形信号进行预加重、加窗分帧和端点检测的预处理获得x[n],每个语音波形的采样率设置为16khz,16bit量化,同时使用窗长和偏移为250ms和10ms的hamming窗口,再将语音信号转变为原始语音波形图。
[0054]
s4:使用transformer模型编码器对低级情感信息特征h[n]再次进行处理,得到更深层次包含全局上下文信息的帧级情感特征y[n];
[0055]
s41:将s3得到的包含浅层情感信息的特征向量输入到transformer模型编码器的多头注意力子层,得到输入语音的帧级注意力特征向量;
[0056]
多头注意力子层先将输入向量映射到不同的子空间中,再分别在所有子空间上做点乘运算,计算出注意力向量,最后把所有子空间计算得到的注意力向量拼接起来,并映射到原输入空间中,得到最终的注意力向量作为输出;从而获取到全局的上下文信息,避免传
统循环神经网络因梯度消失或梯度爆炸而导致的信息消失问题;具体公式如下:
[0057]
mutihead,k,v)=concat(head1,
…
,head
h
)w
o
[0058]
其中,head
i
=attention(qw
iq
,kw
ik
,vw
iv
)
[0059]
其中mutihead(q,k,v)是multi-headattention层的输出结果;concat是矩阵拼接函数;head
i
是第i个head的输出结果,h是head的个数;w
o
是输出的映射参数矩阵;w
iq
、w
ik
、w
iv
分别为q、k、v在第i个head上的映射参数矩阵;
[0060]
每一个head均采用scaleddot-productattention,具体计算公式如下
[0061][0062]
其中attention(q,k,v)是scaled dot-productattention的输出,softmax(x)是归一化指数函数;w
rl
是序列相对位置关系权重参数;k
t
为矩阵k的转置;为比例因子;
[0063]
s42:将s41得到的输入语音的帧级注意力特征向量输入到编码器的前向反馈子层,得到输入语音的上下文特征向量;前向反馈子层由两层前馈神经网络组成,是对多头注意力子层的输出进行两次线性变换和一次relu激活,具体公式如下:
[0064]
ffn(x)=max(0,xw1+b1)w2+b2[0065]
多头注意力子层和前向反馈子层都包含一个残差连接结构,将子层输出与子层输入相加再做规范化作为子层最终输出,每个子层最后的输出公式为:output=layernorm(input+sublayer(input)),
[0066]
其中,layernorm为层规范化操作,input为子层输入,sublayer为子层相应的计算公式,即上述mutihead或ffn公式。
[0067]
s43:重复s41与s42的步骤6次,得到输入语音的最终上下文特征向量。
[0068]
s5:将具有全局信息的帧级情感特征y[n]输入池化层,通过池化并与经验权重向量相乘,使每一次迭代中的帧级特征合并,最终合并为一个话语级情感特征向量;具体来说,输入每一句话都会有一个情感类别,通过分帧处理将话语分成若干个帧级片段并分别处理,最终在加权合并成一句话形式的特征向量,送入分类器处理;
[0069]
s6:利用softmax分类器对话语级情感特征进行分类,从而获得当前的输入语音数据的情感。
[0070]
具体的,将话语级情感特征向量输入到softmax分类中,使用softmax分类器来预测标签情感类别,将输出映射到(0,1)区间内,可以对应情感类别的概率;最终取概率最大的维度所对应的情感类别作为最终输出结果,从而输出与整段语音相对应的情感类别,即模型对预测的情感进行分类。
[0071]
实施例一、
[0072]
使用iemocap语音情感库进行提取,该数据库共包含10种情感,本实施例中采用生气、高兴、伤心、中立4种情感,其中高兴与兴奋划分为高兴类别,以实现类别平衡,共5531句英语音频。
[0073]
具体按照以下步骤实施:
[0074]
第一步:对原始波形信号进行预加重、加窗分帧和端点检测的预处理获得x[n],每个语音波形的采样率设置为16khz,16bit量化,同时使用窗长和偏移为250ms和10ms的
hamming窗口,再将语音信号转变为原始语音波形图;
[0075]
第二步:利用sincnet滤波器层来学习针对语音情感识别而调整的定制滤波器组,将x[n]与sincnet层g[n,θ]之间执行卷积计算,用于初步选取语音信号中低级情感信息特征h[n];
[0076]
第三步:将第二步得到的低级情感信息特征h[n]输入至多层transformer模型编码器中,得到具有全局信息的帧级情感特征y[n];
[0077]
第四步:将第三步得到的具有全局信息的帧级情感特征y[n]输入至池化层,通话池化并与经验权重向量相乘,使每一次迭代中的帧级特征合并,生成一个话语级特征向量;
[0078]
第五步:将话语级特征向量输入至softmax层,进行情感分类。
[0079]
通常transformer网络的层数越多,提取的特征也就越具有区分性,但是会导致训练时长过长或者难以收敛等问题,且不适用于数据集较少的语料库,所以我们构建一个两层transformer编码器网络,这样既能提取具有区分性的特征,也能降低训练时间,具体网络如图1,图2所示。该transformer编码器网络主要由三层多头注意力子层和三层前向反馈子层以及六个残差连接结构组成,最终提取倒数第二层共768维输出序列作为语音情感特征。
[0080]
随机将实验中原始波形图的80%作为训练数据库,20%作为测试数据库,训练数据库用于通过调整改进的transformer编码器网络上的权重来创建一个有效的特征提取器,测试数据集用于测试最终的训练完成的模型,以确认该模型的实际分类能力。为了进一步说明本发明,将本发明与传统语音情感特征进行对比,其中传统特征采用opensmile工具包分别提取384维,988维以及1582维声学特征,其中opensmile工具包为语音情感识别领域常用的特征提取工具,其不同配置文件可提取出不同维度的情感声学特征,这些声学特征主要由低级描述符(如强度、响度、mfcc和音调等)及其统计特性组成。其次,不同特征直接送入softmax分类器,进行语音情感分类,结果如表1所示,如表所示,采用本发明总体效果良好,平均识别率为63.43%,明显优于传统方式提取出的情感声学特征。
[0081]
综上所述,本发明从分许语音原始波形的角度,针对如何挖掘更加适合于语音情感识别的特征,采用改进的transformer编码器直接提取语音中深层次包含全局上下文信息的特征,并结合sincnet滤波器层,更好地捕捉对语音情感有益的信息,最终能提高语音情感识别的识别率。
[0082]
表1在iemocap数据库上不同特征进行语音情感分类的准确度的结果展示
[0083]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1