一种基于语音和雷达双传感器的测谎方法及系统
本发明属于测谎领域,特别涉及一种基于语音和雷达双传感器的测谎方法及系统。
背景技术:
说谎是人类在一定的场景下,通过自身的虚假的描述来隐瞒事情的真相、使对方信服的一种特殊行为。测谎技术是心理学、生理学、语言学、认知学科、统计学、传感器技术、模式识别、刑侦学等多种学科交叉融合的一项重要技术,对于认识了解人类的行为特点,特别是是辅助刑侦司法案件有着重要的意义。而人类本身对于谎言的判断基本上是凭借主观的随机猜测,准确率很低,因此需要科学的、可靠的系统以及方法来指导人类检测谎言。
以往对于谎言的检测主要借助于多道生理仪来检测说谎过程中的生理参数与正常情况下的异常,这种方法具有一定的可靠性,因为人类在说谎过程中的确会不自主地发生一些生理反应,比如心跳加快、呼吸受到抑制等。但这种方法要求被试者身上穿戴多种传感器,会对受试者造成不适,甚至会带来很大的压迫感,会给测量结果造成影响。当前国内对于谎言检测主要借助于语音分析,从语音或者语义的角度分析谎言的语音或语义特点。这种方法虽然说可以做到非接触式的测量,但也存在着很大的局限性,因为每个人的说话习惯、表达内容有着极大的差异性。
技术实现要素:
本发明的目的在于提供一种可靠性强、适用性广的基于语音和雷达双传感器的测谎方法及系统,可以实现非接触式地获取语音信号、呼吸信号和心跳信号,融合三种信号来对谎言进行检测。
实现本发明目的的技术解决方案为:一种基于语音和雷达双传感器的测谎方法,所述方法包括以下步骤:
步骤1,利用麦克风和连续波雷达同步采集语音信号和雷达信号;
步骤2,对步骤1采集的语音信号进行降噪、声音事件检测、预加重预处理;
步骤3,针对步骤2得到的预处理后的语音信号,提取基频、发声概率、短时过零率、帧均方根能量、梅尔倒谱系数特征,并对这5种特征运用最大值、最小值、均值、标准差、偏度、峰度6种统计参数,得到语音特征集x;
步骤4,对步骤1采集的雷达信号进行解调、滤波,得到呼吸信号和心跳信号;
步骤5,分别对步骤4得到的呼吸信号和心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r和心跳特征集h;
步骤6,将步骤5得到的呼吸特征集r和心跳特征集h进行融合,得到生理特征集y,之后对生理特征集y和步骤3得到的语音特征集x进行特征融合,得到融合特征集z;
步骤7,利用步骤6得到的融合特征集z训练分类器,对语音样本进行测谎分类。
进一步地,步骤2中所述对步骤1采集的语音信号进行降噪,具体过程包括:
步骤2-1,针对分贝超过预设阈值的噪声即主要噪声,录制其噪声样本;
步骤2-2,对于步骤2-1得到的噪声样本,运用sox音频处理程序生成噪声样本配置文件,并根据噪声样本配置文件对语音信号进行一次降噪,去除主要噪声;
步骤2-3,对步骤2-2得到的一次降噪后的语音信号,利用改进谱减法进行二次降噪,去除噪声样本外的其他类型噪声,得到纯净的语音信号。
进一步地,步骤5所述分别对步骤4得到的呼吸信号和心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r和心跳特征集h,具体包括:
步骤5-1,对呼吸信号进行时域、频域和非线性特征提取,得到呼吸特征集r;
a、时域特征:提取呼吸幅度均值、呼吸幅度标准差、呼吸平均幅度差、呼吸归一化平均幅度差作为呼吸信号的时域特征;其中,
(1)呼吸幅度均值μx,用于反映测谎过程中呼吸的平均幅度情况,表达式为:
式中,x(n)为第n个呼吸序列,n为呼吸序列总数,1≤n≤n;
(2)呼吸幅度标准差σx,用于反映测谎过程中呼吸的总体变化情况,表达式为:
(3)呼吸平均幅度差δx,用于反映测谎过程中呼吸幅度的短时变化的情况,表达式为:
(4)呼吸归一化平均幅度差δrx,用于反映测谎过程中呼吸幅度的短时变化对总体变化的影响,表达式为:
b、频域特征:提取呼吸低频段fl、呼吸中频段fm和呼吸高频段fh这三个频段功率谱幅度均值作为呼吸信号的频域特征;其中,fl<p1hz,p1hz≤fm<p2hz,fh>p2hz;
c、非线性特征:提取呼吸去趋势波动标度指数、呼吸样本熵作为呼吸信号的非线性特征;
(1)呼吸去趋势波动标度指数
呼吸去趋势波动标度指数用于反映测谎过程中呼吸信号的非平稳特性,其计算步骤具体如下:
1)假设呼吸序列为x(n),计算其均值μx:
2)计算呼吸序列的累计差值y(n):
3)将y(n)不重叠地划分为a个窗,窗长为b;
4)对每段窗长区间利用最小二乘法拟合出局部趋势yb(n),然后去除掉每个区间的局部趋势,得到新的呼吸序列并计算出新呼吸序列的均方根f(n):
5)改变窗长b的大小然后重复以上步骤,直至获得所需的数据量;
6)根据上面步骤所计算的参数,以log(n)为横坐标、log[f(n)]为纵坐标绘制一条曲线,该曲线的斜率即为呼吸序列的呼吸去趋势波动标度指数;
(2)呼吸样本熵
呼吸样本熵用于评估测谎过程中呼吸信号的复杂性,其计算步骤为:
1)将呼吸时间序列表示为x(n),以m为窗长,将呼吸时间序列分为s=n-m+1个呼吸子序列:
xm(t)=(x(t),x(t+1),…,x(t+m-1)),1≤t≤n-m+1
式中,xm(t)为第t个呼吸子序列;
2)定义序列xm(i)和序列xm(j)的距离为对应元素最大差值的绝对值并计算出每个呼吸子序列与其他所有呼吸子序列之间的距离dij:
dij=maxk=0,…,m-1(|xm(i+k)-xm(j+k)|)
式中,1≤i≤n-m,1≤j≤n-m,i≠j;
3)计算呼吸幅度标准差σx并定义阈值f=r*σx,r为常数,取0.1-0.25;将上述2)计算出的距离dij中小于或等于f的个数与s的比值记
4)改变窗长为m+1,重复上述1)到3)步,得到φm+1(t);
5)计算呼吸样本熵sampen(t):
sampen(t)=ln[φm(t)]-ln[φm+1(t)]
步骤5-2,对心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r;
a、时域特征:提取心跳幅度均值、心跳幅度标准差、心跳平均幅度差、心跳归一化平均幅度差作为心跳信号的时域特征,具体计算方式与呼吸特征提取部分相同;
b、频域特征:提取心跳低频段fl'、心跳中频段fm'和心跳高频段fh'这三个频段功率谱幅度均值作为心跳信号的频域特征;其中,fl'<p3hz,p3hz≤fm'<p4hz,fh'>p4hz,p3>p1,p4>p2;
c、非线性特征:提取心跳去趋势波动标度指数、心跳样本熵作为心跳信号的非线性特征,具体计算方式与呼吸特征提取部分相同。
进一步地,步骤6具体过程包括:
步骤6-1,对呼吸特征集r和心跳特征集h采取串行融合的特征融合方式,得到生理特征集y:
y=[rh]
步骤6-2,计算语音特征集x和生理特征集y每个类和所有特征数据的向量均值,下面以语音特征集x的过程进行说明,y同理可得,具体如下:
式中,
式中,
步骤6-3,分别计算语音信号特征集x和生理特征集y的投影矩阵,以使x和y特征集的类间相关性最小,下面以x的投影矩阵计算过程进行说明,y同理可得,具体如下:
首先计算语音信号特征集x的类间散布矩阵sbx:
其中,
类间相关性最小时,φbxtφbx为对角矩阵,又因φbxtφbx对称半正定,存在如下变换:
式中,p为正交特征向量矩阵,
设q是由矩阵p中r个最大非零特征值对应的r个特征向量组成,相应的有:
qt(φbxtφbx)q=a
则可得到x的投影矩阵wbx:
同理可得y的投影矩阵wby;
步骤6-4,根据步骤6-3计算出的投影矩阵对x和y进行投影,得到投影后的语音特征集xp和生理特征集yp:
xp=wbxtx
yp=wbyty
步骤6-5,利用奇异值分解svd对角化投影后的特征集的集间协方差矩阵,得到语音特征集转换矩阵wx和生理特征集转换矩阵wy,具体如下:
其中,sxy=xpypt,b为对角元素非零的对角矩阵,其中u、v通过svd可求得;由
式中,i为单位阵;
于是得到语音特征集转换矩阵wx和生理特征集转换矩阵wy:
wx=wcxtwbxt
wy=wcytwbyt
步骤6-6,根据6-5计算出的转换矩阵,计算转换后的语音特征集xdca和生理特征集ydca:
xdca=wxx
ydca=wyy
步骤6-7,对6-6计算的语音特征集xdca和生理特征集ydca进行串行融合,得到融合特征集z:
z=[xdcaydca]。
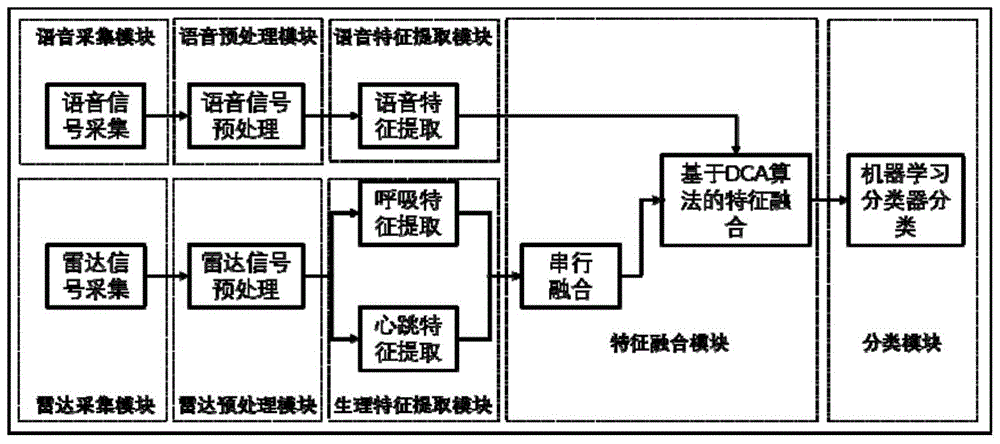
一种基于语音和雷达双传感器的测谎系统,所述系统包括语音采集模块、雷达采集模块、语音预处理模块、雷达预处理模块、语音特征提取模块、生理特征提取模块、特征融合模块和分类模块;
所述语音采集模块,用于利用麦克风采集语音信号;
所述雷达采集模块,用于利用连续波雷达采集雷达信号;
所述语音预处理模块,用于对采集的语音信号进行降噪、声音事件检测、预加重预处理;
所述雷达预处理模块,用于对采集的雷达信号进行解调、滤波,得到呼吸信号和心跳信号;
所述语音特征提取模块,用于针对预处理后的语音信号,提取基频、发声概率、短时过零率、帧均方根能量、梅尔倒谱系数特征,并对这5种特征运用最大值、最小值、均值、标准差、偏度、峰度6种统计参数,得到语音特征集x;
所述生理特征提取模块,用于分别对呼吸信号和心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r和心跳特征集h;
所述特征融合模块,用于将呼吸特征集r和心跳特征集h进行融合,得到生理特征集y,之后对生理特征集y和语音特征集x进行特征融合,得到融合特征集z;
所述分类模块,用于利用融合特征集z训练分类器,对语音样本进行测谎分类。
本发明与现有技术相比,其显著优点为:1)本利用连续波雷达可以实现对呼吸和心跳的非接触式测量,能有效减少受试者的不适感,对于受试者的生理和心理压迫感小,减小对测量结果的影响;2)结合了语音、呼吸和心跳信号三种信号,能够克服语音信号个体差异性强、易伪装、局限性强等问题;3)结合sox降噪程序和改进谱减法的特点,能够达到更好的降噪效果;4)利用dca算法对语音特征和生理特征进行融合,最小化类间相关性的同时最大化特征集间相关性,提高谎言检测的准确性。
下面结合附图对本发明作进一步详细描述。
附图说明
图1为本发明基于语音和雷达双传感器的测谎系统框图。
图2为一个实施例中原始带噪语音波形示意图。
图3为一个实施例中原始带噪语音经过sox处理后语音波形示意图。
图4为一个实施例中原始带噪语音经过改进谱减法处理后的语音波形示意图。
图5为一个实施例中原始带噪语音经过sox+改进谱减法处理后的语音波形示意图。
图6为一个实施例中不同特征集测谎结果对比图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
另外,若本发明中有涉及“第一”、“第二”等的描述,则该“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
本发明提供了一种基于语音和雷达双传感器的测谎方法,所述方法包括以下步骤:
步骤1,利用麦克风和连续波雷达同步采集语音信号和雷达信号;
步骤2,对步骤1采集的语音信号进行降噪、声音事件检测、预加重预处理;具体过程包括:
步骤2-1,针对分贝超过预设阈值的噪声即主要噪声,录制其噪声样本,时长为2s;
步骤2-2,对于步骤2-1得到的噪声样本,运用sox音频处理程序生成噪声样本配置文件,并根据噪声样本配置文件对语音信号进行一次降噪,去除主要噪声;
步骤2-3,对步骤2-2得到的一次降噪后的语音信号,利用改进谱减法进行二次降噪,去除噪声样本外的其他类型噪声,得到纯净的语音信号。
步骤3,针对步骤2得到的预处理后的语音信号,根据人在说谎状态下可能出现的声调异变、停顿、语速变化等特点,提取基频、发声概率、短时过零率、帧均方根能量、梅尔倒谱系数特征(0-12),并对这5种特征运用最大值、最小值、均值、标准差、偏度、峰度6种统计参数,得到语音特征集x;
步骤4,对步骤1采集的雷达信号进行解调、滤波,得到呼吸信号和心跳信号;
步骤5,根据人在说谎状态可能出现的呼吸“抑制”、心跳加快等特点,分别对步骤4得到的呼吸信号和心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r和心跳特征集h;具体包括:
步骤5-1,对呼吸信号进行时域、频域和非线性特征提取,得到呼吸特征集r;
a、时域特征:提取呼吸幅度均值、呼吸幅度标准差、呼吸平均幅度差、呼吸归一化平均幅度差作为呼吸信号的时域特征;其中,
(1)呼吸幅度均值μx,用于反映测谎过程中呼吸的平均幅度情况,表达式为:
式中,x(n)为第n个呼吸序列,n为呼吸序列总数,1≤n≤n;
(2)呼吸幅度标准差σx,用于反映测谎过程中呼吸的总体变化情况,表达式为:
(3)呼吸平均幅度差δx,用于反映测谎过程中呼吸幅度的短时变化的情况,表达式为:
(4)呼吸归一化平均幅度差δrx,用于反映测谎过程中呼吸幅度的短时变化对总体变化的影响,表达式为:
b、频域特征:提取呼吸低频段fl(fl<0.2hz)、呼吸中频段fm(0.2≤fm≤0.3hz)和呼吸高频段fh(fh>0.3hz)这三个频段功率谱幅度均值作为呼吸信号的频域特征;
c、非线性特征:提取呼吸去趋势波动标度指数、呼吸样本熵作为呼吸信号的非线性特征;
(1)呼吸去趋势波动标度指数
呼吸去趋势波动标度指数用于反映测谎过程中呼吸信号的非平稳特性,其计算步骤具体如下:
1)假设呼吸序列为x(n),计算其均值μx:
2)计算呼吸序列的累计差值y(n):
3)将y(n)不重叠地划分为a个窗,窗长为b;
4)对每段窗长区间利用最小二乘法拟合出局部趋势yb(n),然后去除掉每个区间的局部趋势,得到新的呼吸序列并计算出新呼吸序列的均方根f(n):
5)改变窗长b的大小然后重复以上步骤,直至获得所需的数据量;
6)根据上面步骤所计算的参数,以log(n)为横坐标、log[f(n)]为纵坐标绘制一条曲线,该曲线的斜率即为呼吸序列的呼吸去趋势波动标度指数;
(2)呼吸样本熵
呼吸样本熵用于评估测谎过程中呼吸信号的复杂性,其计算步骤为:
1)将呼吸时间序列表示为x(n),以m为窗长,将呼吸时间序列分为s=n-m+1个呼吸子序列:
xm(t)=(x(t),x(t+1),…,x(t+m-1)),1≤t≤n-m+1
式中,xm(t)为第t个呼吸子序列;
2)定义序列xm(i)和序列xm(j)的距离为对应元素最大差值的绝对值并计算出每个呼吸子序列与其他所有呼吸子序列之间的距离dij:
dij=maxk=0,…,m-1(xm(i+k)-xm(j+k))
式中,1≤i≤n-m,1≤j≤n-m,i≠j;
3)计算呼吸幅度标准差σx并定义阈值f=r*σx,r为常数,取0.1-0.25;将上述2)计算出的距离dij中小于或等于f的个数与s的比值记
4)改变窗长为m+1,重复上述1)到3)步,得到φm+1(t);
5)计算呼吸样本熵sampen(t):
sampen(t)=ln[φm(t)]-ln[φm+1(t)]
步骤5-2,对心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r;
a、时域特征:提取心跳幅度均值、心跳幅度标准差、心跳平均幅度差、心跳归一化平均幅度差作为心跳信号的时域特征,具体计算方式与呼吸特征提取部分相同;
b、频域特征:提取心跳低频段fl'(fl'<0.8hz)、心跳中频段fm'(0.8≤fm'≤1.2hz)和心跳高频段fh'(fh'>1.2hz)这三个频段功率谱幅度均值作为心跳信号的频域特征;
c、非线性特征:提取心跳去趋势波动标度指数、心跳样本熵作为心跳信号的非线性特征,具体计算方式与呼吸特征提取部分相同。
步骤6,将步骤5得到的呼吸特征集r和心跳特征集h进行串行融合,得到生理特征集y,之后利用dca算法对生理特征集y和步骤3得到的语音特征集x进行特征融合,得到融合特征集z;具体过程包括:
步骤6-1,对呼吸特征集r和心跳特征集h采取串行融合的特征融合方式,得到生理特征集y:
y=[rh]
步骤6-2,计算语音特征集x和生理特征集y每个类和所有特征数据的向量均值,下面以语音特征集x的过程进行说明,y同理可得,具体如下:
式中,
式中,
步骤6-3,分别计算语音信号特征集x和生理特征集y的投影矩阵,以使x和y特征集的类间相关性最小,下面以x的投影矩阵计算过程进行说明,y同理可得,具体如下:
首先计算语音信号特征集x的类间散布矩阵sbx:
其中,
类间相关性最小时,φbxtφbx为对角矩阵,又因φbxtφbx对称半正定,存在如下变换:
式中,p为正交特征向量矩阵,
设q是由矩阵p中r个最大非零特征值对应的r个特征向量组成,相应的有:
qt(φbxtφbx)q=a
则可得到x的投影矩阵wbx:
同理可得y的投影矩阵wby;
步骤6-4,根据步骤6-3计算出的投影矩阵对x和y进行投影,得到投影后的语音特征集xp和生理特征集yp:
xp=wbxtx
yp=wbyty
步骤6-5,利用奇异值分解svd对角化投影后的特征集的集间协方差矩阵,得到语音特征集转换矩阵wx和生理特征集转换矩阵wy,具体如下:
其中,sxy=xpypt,b为对角元素非零的对角矩阵,其中u、v通过svd可求得;
由
式中,i为单位阵;
于是得到语音特征集转换矩阵wx和生理特征集转换矩阵wy:
wx=wcxtwbxt
wy=wcytwbyt
步骤6-6,根据6-5计算出的转换矩阵,计算转换后的语音特征集xdca和生理特征集ydca:
xdca=wxx
ydca=wyy
步骤6-7,对6-6计算的语音特征集xdca和生理特征集ydca进行串行融合,得到融合特征集z:
z=[xdcaydca]。
步骤7,利用步骤6得到的融合特征集z训练分类器,对语音样本进行测谎分类。
结合图1,本发明提供了一种基于语音和雷达双传感器的测谎系统,所述系统包括语音采集模块、雷达采集模块、语音预处理模块、雷达预处理模块、语音特征提取模块、生理特征提取模块、特征融合模块和分类模块;
所述语音采集模块,用于利用麦克风采集语音信号;
所述雷达采集模块,用于利用连续波雷达采集雷达信号;
所述语音预处理模块,用于对采集的语音信号进行降噪、声音事件检测、预加重预处理;该模块包括依次执行的:
采集主要噪声单元,用于针对分贝超过预设阈值的噪声即主要噪声,录制其噪声样本;
一次噪声单元,用于对上述噪声样本,运用sox音频处理程序生成噪声样本配置文件,并根据噪声样本配置文件对语音信号进行一次降噪,去除主要噪声;
二次噪声单元,用于对一次降噪后的语音信号,利用改进谱减法进行二次降噪,去除噪声样本外的其他类型噪声,得到纯净的语音信号。
所述雷达预处理模块,用于对采集的雷达信号进行解调、滤波,得到呼吸信号和心跳信号;
所述语音特征提取模块,用于针对预处理后的语音信号,提取基频、发声概率、短时过零率、帧均方根能量、梅尔倒谱系数特征,并对这5种特征运用最大值、最小值、均值、标准差、偏度、峰度6种统计参数,得到语音特征集x;
所述生理特征提取模块,用于分别对呼吸信号和心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r和心跳特征集h;该模块包括依次执行的:
呼吸特征集获取单元,用于对呼吸信号进行时域、频域和非线性特征提取,得到呼吸特征集r;
a、时域特征:提取呼吸幅度均值、呼吸幅度标准差、呼吸平均幅度差、呼吸归一化平均幅度差作为呼吸信号的时域特征;其中,
(1)呼吸幅度均值μx,用于反映测谎过程中呼吸的平均幅度情况,表达式为:
式中,x(n)为第n个呼吸序列,n为呼吸序列总数,1≤n≤n;
(2)呼吸幅度标准差σx,用于反映测谎过程中呼吸的总体变化情况,表达式为:
(3)呼吸平均幅度差δx,用于反映测谎过程中呼吸幅度的短时变化的情况,表达式为:
(4)呼吸归一化平均幅度差δrx,用于反映测谎过程中呼吸幅度的短时变化对总体变化的影响,表达式为:
b、频域特征:提取呼吸低频段fl、呼吸中频段fm和呼吸高频段fh这三个频段功率谱幅度均值作为呼吸信号的频域特征;其中,fl<p1hz,p1hz≤fm<p2hz,fh>p2hz;
c、非线性特征:提取呼吸去趋势波动标度指数、呼吸样本熵作为呼吸信号的非线性特征;
(1)呼吸去趋势波动标度指数
呼吸去趋势波动标度指数用于反映测谎过程中呼吸信号的非平稳特性,其计算步骤具体如下:
1)假设呼吸序列为x(n),计算其均值μx:
2)计算呼吸序列的累计差值y(n):
3)将y(n)不重叠地划分为a个窗,窗长为b;
4)对每段窗长区间利用最小二乘法拟合出局部趋势yb(n),然后去除掉每个区间的局部趋势,得到新的呼吸序列并计算出新呼吸序列的均方根f(n):
5)改变窗长b的大小然后重复以上步骤,直至获得所需的数据量;
6)根据上面步骤所计算的参数,以log(n)为横坐标、log[f(n)]为纵坐标绘制一条曲线,该曲线的斜率即为呼吸序列的呼吸去趋势波动标度指数;
(2)呼吸样本熵
呼吸样本熵用于评估测谎过程中呼吸信号的复杂性,其计算步骤为:
1)将呼吸时间序列表示为x(n),以m为窗长,将呼吸时间序列分为s=n-m+1个呼吸子序列:
xm(t)=(x(t),x(t+1),…,x(t+m-1)),1≤t≤n-m+1
式中,xm(t)为第t个呼吸子序列;
2)定义序列xm(i)和序列xm(j)的距离为对应元素最大差值的绝对值并计算出每个呼吸子序列与其他所有呼吸子序列之间的距离dij:
dij=maxk=0,…,m-1(|xm(i+k)-xm(j+k)|)
式中,1≤i≤n-m,1≤j≤n-m,i≠j;
3)计算呼吸幅度标准差σx并定义阈值f=r*σx,r为常数,取0.1-0.25;将上述2)计算出的距离dij中小于或等于f的个数与s的比值记
4)改变窗长为m+1,重复上述1)到3)步,得到φm+1(t);
5)计算呼吸样本熵sampen(t):
sampen(t)=ln[φm(t)]-ln[φm+1(t)]
呼吸特征集获取单元,用于对心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r;
a、时域特征:提取心跳幅度均值、心跳幅度标准差、心跳平均幅度差、心跳归一化平均幅度差作为心跳信号的时域特征,具体计算方式与呼吸特征提取部分相同;
b、频域特征:提取心跳低频段fl'、心跳中频段fm'和心跳高频段fh'这三个频段功率谱幅度均值作为心跳信号的频域特征;其中,fl'<p3hz,p3hz≤fm'<p4hz,fh'>p4hz,p3>p1,p4>p2;
c、非线性特征:提取心跳去趋势波动标度指数、心跳样本熵作为心跳信号的非线性特征,具体计算方式与呼吸特征提取部分相同。
所述特征融合模块,用于将呼吸特征集r和心跳特征集h进行融合,得到生理特征集y,之后对生理特征集y和语音特征集x进行特征融合,得到融合特征集z;该模块包括依次执行的:
第一特征融合单元,用于对呼吸特征集r和心跳特征集h采取串行融合的特征融合方式,得到生理特征集y:
y=[rh]
第一计算单元,用于计算语音特征集x和生理特征集y每个类和所有特征数据的向量均值,下面以语音特征集x的过程进行说明,y同理可得,具体如下:
式中,
式中,
第二计算单元,用于分别计算语音信号特征集x和生理特征集y的投影矩阵,以使x和y特征集的类间相关性最小,下面以x的投影矩阵计算过程进行说明,y同理可得,具体如下:
首先计算语音信号特征集x的类间散布矩阵sbx:
其中,
类间相关性最小时,φbxtφbx为对角矩阵,又因φbxtφbx对称半正定,存在如下变换:
式中,p为正交特征向量矩阵,
设q是由矩阵p中r个最大非零特征值对应的r个特征向量组成,相应的有:
qt(φbxtφbx)q=a
则可得到x的投影矩阵wbx:
同理可得y的投影矩阵wby;
投影单元,用于根据投影矩阵对x和y进行投影,得到投影后的语音特征集xp和生理特征集yp:
xp=wbxtx
yp=wbyty
奇异值分解svd单元,用于利用奇异值分解svd对角化投影后的特征集的集间协方差矩阵,得到语音特征集转换矩阵wx和生理特征集转换矩阵wy,具体如下:
其中,sxy=xpypt,b为对角元素非零的对角矩阵,其中u、v通过svd可求得;
由
式中,i为单位阵;
于是得到语音特征集转换矩阵wx和生理特征集转换矩阵wy:
wx=wcxtwbxt
wy=wcytwbyt
第三计算单元,用于根据转换矩阵,计算转换后的语音特征集xdca和生理特征集ydca:
xdca=wxx
ydca=wyy
第二特征融合单元,用于对语音特征集xdca和生理特征集ydca进行串行融合,得到融合特征集z:
z=[xdcaydca]。
所述分类模块,用于利用融合特征集z训练分类器,对语音样本进行测谎分类。
关于基于语音和雷达双传感器的测谎系统的具体限定可以参见上文中对于基于语音和雷达双传感器的测谎方法的限定,在此不再赘述。上述基于语音和雷达双传感器的测谎系统中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
下面结合实施例对本发明做进一步详细的描述。
实施例
本发明基于语音和雷达双传感器的测谎方法,实现测谎的步骤具体为:
步骤1,利用麦克风和连续波雷达同步采集语音信号和雷达信号;
步骤2,对步骤1采集的语音信号进行降噪、声音事件检测、预加重预处理;
步骤3,针对步骤2得到的预处理后的语音信号,根据人在说谎状态下可能出现的声调异变、停顿、语速变化等特点,提取基频、发声概率、短时过零率、帧均方根能量、梅尔倒谱系数特征,并对这5种特征运用最大值、最小值、均值、标准差、偏度、峰度6种统计参数,得到语音特征集x;
步骤4,对步骤1采集的雷达信号进行解调、滤波,得到呼吸信号和心跳信号;
步骤5,根据人在说谎状态可能出现的呼吸“抑制”、心跳加快等特点,分别对步骤4得到的呼吸信号和心跳信号进行时域、频域和非线性特征提取,得到呼吸特征集r和心跳特征集h;
步骤6,将步骤5得到的呼吸特征集r和心跳特征集h进行串行融合,得到生理特征集y,之后利用dca算法对生理特征集y和步骤3得到的语音特征集x进行特征融合,得到融合特征集z;
步骤7,利用步骤6得到的融合特征集z训练分类器,对语音样本进行测谎分类。
结合图2、图3、图4、图5,sox音频处理程序对于主要噪声成分的降噪效果很好,但是不能完全去除噪声;改进谱减法拥有很强的降噪能力,但是会对有效语音段进行误判。采用sox音频处理程序进行一次降噪,然后用改进谱减法进行二次降噪,既能够达到很好的降噪效果,同时不会损失有效语音片段。
结合图6,由于语音的局限性,语音特征集上的测谎分类准确率最高为59.1%;生理特征集测谎分类准确率最高为67.6%,说明了生理信号以及所提取的生理特征集用于测谎的有效性;利用串行融合和dca算法对语音特征集和生理特征集进行融合得到的融合特征集,取得了比单独两种特征集更高的测谎分类准确率,最高为70.2%。
综上所述,本发明的基于语音和雷达双传感器测谎方法及系统,不但不会给被测者带来不适感,并且能够消除语音的局限性,有效提高了测谎准确率,可靠性高,适用性广。
以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!