用于文本相关说话人识别的数据增强方法及系统与流程
本发明涉及智能语音领域,尤其涉及一种用于文本相关说话人识别的数据增强方法及系统。
背景技术:
文本相关说话人验证是验证给定的语音是否属于所声称的说话人身份的任务,其中文本被限制在固定的词汇内容中。传统的i-vector系统和基于深度学习的模型,如d-vector、j-vector和x-vector,都得到了广泛的研究。然而,所有这些方法都需要足够的训练数据,而文本相关数据的收集往往是非常困难和昂贵的。
为了增加现有数据的数量和多样性,在构建深度学习模型时,通常将数据扩充作为预处理步骤。例如,通过在干净的音频中添加噪声和混响,可以显著提高x向量系统的性能。specaugment的简单语音识别数据增强方法,它也证明了它对说话人验证任务的有效性。与随机擦除策略有着相似的思想,同样适用于说话人验证任务。除了前端嵌入提取器的增强外,还有生成对抗网络(gan)和变分自动编码器(vae)在后端plda(probabilisticlineardiscriminantanalysis,概率线性判别分析)增强中的应用。
在实现本发明过程中,发明人发现相关技术中至少存在如下问题:
然而,上述所有的数据增强方法只提供了声音环境的变化,这只是系统鲁棒性的一个方面。这些新生成的数据没有使用新的说话人数据。只是在已有的说话人数据上增加了变化,因此模型性能提升有限。
技术实现要素:
为了至少解决现有技术中数据增强只提供声音环境的变化,而没有使用新的说话人数据,模型性能提升有限的问题。
第一方面,本发明实施例提供一种用于文本相关说话人识别的数据增强方法,包括:
基于多个说话人的文本无关的数据训练得到语音合成模型;
将第一真实语音数据对应的文本输入至所述语音合成模型,生成所述多个说话人的第二合成语音数据;
将所述第一真实语音数据以及所述第二合成语音数据作为用于文本相关的说话人识别的训练数据。
第二方面,本发明实施例提供一种用于文本相关说话人识别的数据增强系统,包括:
模型训练程序模块,用于基于多个说话人的文本无关的数据训练得到语音合成模型;
数据生成程序模块,用于将第一真实语音数据对应的文本输入至所述语音合成模型,生成所述多个说话人的第二合成语音数据;
数据增强程序模块,用于将所述第一真实语音数据以及所述第二合成语音数据作为用于文本相关的说话人识别的训练数据。
第三方面,提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的用于文本相关说话人识别的数据增强方法的步骤。
第四方面,本发明实施例提供一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现本发明任一实施例的用于文本相关说话人识别的数据增强方法的步骤。
本发明实施例的有益效果在于:利用tts系统生成新说话人的语音,使用该维度训练的数据可以进一步提升模型的性能,在极低资源条件下,该方法显著地提高了说话人识别模型的准确率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的流程图;
图2是本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的结构图;
图3是本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的基于条件fastspeech2的tts体系结构图;
图4是本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的tts系统为同一个说话人生成的4个实例的mel光谱图;
图5是本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的不同rs015的eer(%)试验数据图;
图6是本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的在rsr2015测试集上当合成语音中使用不同数量的扬声器时i-vector的eer(%)曲线图;
图7是本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的在rsr2015测试集上,当200个说话人中的每个人合成不同数量的话语时,i-vector系统的eer(%)数据图;
图8是本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的当使用不同的数据扩充方法时,rsr2015测试集上的eer(%);
图9是本发明一实施例提供的一种用于文本相关说话人识别的数据增强系统的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
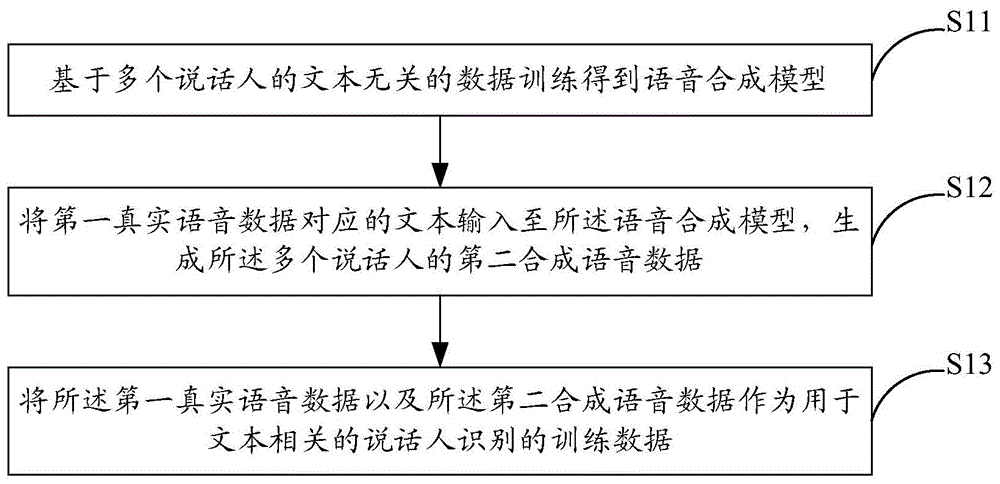
如图1所示为本发明一实施例提供的一种用于文本相关说话人识别的数据增强方法的流程图,包括如下步骤:
s11:基于多个说话人的文本无关的数据训练得到语音合成模型;
s12:将第一真实语音数据对应的文本输入至所述语音合成模型,生成所述多个说话人的第二合成语音数据;
s13:将所述第一真实语音数据以及所述第二合成语音数据作为用于文本相关的说话人识别的训练数据。
在本实施方式中,受合成语音在自动语音识别(asr)中的成功应用的启发,我们提出了一种新的数据增强方法synaug(也就是本方法),该方法通过语音合成系统生成新说话人的受控语音,用于文本相关的说话人验证训练。该方法与其他基于tts(texttospeech,从文本到语音)的语音增强方法的主要区别在于,我们可以使用额外的文本无关语音作为参考来指导合成。
对于步骤s11,我们假设有一个有限的与文本相关的数据集dtd和一个与文本无关的大型数据集dti。图2展示了数据增强方法的流程。例如,文本相关的数据集中的数据是a、b、c三名用户,文本相关的数据集为与“打开空调”文本相关的语音。而文本无关的大型数据集是可以任意采集的,不需要指定哪些人,也不需要指定特定的文本,因此这类数据在采集时相对简单。我们首先在dti上训练tts(texttospeech,从文本到语音)系统,也就是语音合成模型。训练后的语音合成模型包含了文本无关的数据集中各人物的声音特征。
对于步骤s12,将文本相关的数据集中真实语音对应的文本输入至步骤s11中的训练的语音合成模型中。生成多个说话人的“打开空调”的语音数据。
对于步骤s13,通过在dti中采样每个说话人的不同语音作为参考,使用真实语音数据以及合成语音数据生成了一个依赖于文本的合成数据集dstd,其中每个说话人对于每个目标文本都有几种不同的音频。
使用该合成数据集dstd对说话人识别模型进行训练,训练模型的对于i-vector系统,仅在dtd上训练ubm和plda,而在dtd和dstd的合并数据上对i-vector提取器进行训练。
通过该实施方式可以看出,利用tts系统生成新说话人的语音,使用该维度训练的数据可以进一步提升模型的性能,在极低资源条件下,该方法显著地提高了说话人识别模型的准确率。
作为一种实施方式,在本实施例中,所述基于多个说话人的文本无关的数据训练得到语音合成模型包括:
通过提取器确定所述文本无关的数据中的各说话人的特征信息,其中,所述特征信息包括:音素、音色、音量、语速;
利用所述特征信息确定预测mel-声谱图;
基于预设参考mel-声谱图与所述预测mel-声谱图对所述语音合成模型的提取器进行训练,直至所述预测mel-声谱图趋近于所述预设参考mel-声谱图为止。
所述提取器的内核大小为3*3,包括6层2d卷积层。
所述提取器还包括:批处理归一化层用于防止梯度爆炸和梯度消失以及relu激活函数用于降低计算量。
在本实施方式中,本文的tts模型基于fastspeech2,以一个音素序列作为输入,输出320维的mel-声谱图。在本方法中,我们需要合成多个变异性说话人的语音,因此我们使用了条件提取器,从参考语音中提取除输入音素以外的其他信息,包括说话人、说话风格、音量、速度等。这些信息被表示为嵌入条件c,然后广播并添加到快语音的编码器输出进行语音合成。我们的tts模型的总体架构如图3所示。在训练阶段,参考语音就是训练tts的目标语音。因此,我们对条件提取器进行了优化,以提取c语言中的有效信息,以便更好地重构mel声谱图,也就是说可以通过预设参考mel-声谱图与所述预测mel-声谱图的差值进行反向训练,这样基于差值进行重构me。
在推理阶段,我们可以随机选择一个mel声谱图作为参考,然后得到一个与给定文本对应的合成语音。
本方法中条件提取器的结构包含6层2d卷积,内核大小为33,每层之后是批处理归一化层和relu激活函数。在上述模块之后,设计了隐藏大小为128的双向gru。来自gru层的前后状态的串联状态是条件提取器的输出,称为条件嵌入c。
通过该实施方式可以看出,通过该方法训练的语音合成模型可以有效的确定说话人的特征信息。
对本方法进行具体试验,rsr2015-part1语料库的背景集用于训练包含97个说话人的说话人验证系统。利用同一语料库中的评价集对所提出的系统进行评价。评价共1568008个试验,其中靶向试验19052个,冒名冒充试验1548956个。
libritts是一个大型多音箱tts数据集,其训练集分为“train-clean-460”和“train-other-500”两部分。我们使用train-clean-460作为tts训练集,包含约245小时的数据。为简便起见,语音被重新采样为16khz。
对于i-vector系统,我们使用30维mfcc,窗口大小为25ms,帧移为10ms。ubm有512个高斯混合分量,i-vector维数设为700。为了模拟不同数量td数据可用的情况,我们在实验中分别使用10、20、50和rsr2015中的所有97个扬声器。
数据增强的一个简单想法是直接使用额外的文本无关的数据dti来训练i-vector提取器。因此,有必要证明在不限制讲话内容的情况下直接引入新的讲话人对于基于文本的讲话人验证来说不是一个好主意。我们将首先说明以所需内容合成语音的重要性,然后分析合成质量对sv系统的影响。
首先,我们从train-clean-460数据集中随机选择200个说话人,直接使用对应的文本无关数据作为扩展的dti。
然后,我们应用synaug(也就是本方法),我们在rsr2015中合成30个固定转录本20次,每个相同的200个dti演讲者。我们使用对应说话人的不同话语作为参考,以生成不同条件下的话语。图4展示了tts系统使用相同的说话人和文本生成的4个实例的mel声谱图的示例。尽管它们相似,但我们可以发现四种mel声谱图之间存在明显的差异,这说明生成样本的多样性。我们分别使用griffin-lim算法和wavernn对预测的mel谱图进行重构。合成语音dstd与原始文本相关的训练数据一起用于i-向量训练。在plda阶段,我们只使用原始数据而不进行扩展。
上述系统的结果见图5所示。一般来说,synaug优于与文本无关的数据增强,这显示了生成文本匹配语音的重要性。我们还发现,神经声码器wavernn比griffin-lim算法提供了更多的改进,合成语音的音质更好。例如,当rsr2015中97个扬声器全部可用时,synaug和wavernn的eer相对降低了14.1%,当rsr2015中只有10个扬声器可用时,eer相对降低了76.5%。
我们分析合成语音中的说话人数量如何影响synaug的性能。当可用不同数量的td数据时,我们仍将模拟上述4种情况。以下实验中的声码器是wavernn。然后,我们从train-clean-460数据集中分别随机选择100、200、500和1000个说话人,并使用它们为synaug合成20次30个固定转录本。
结果如图6所示。我们可以发现,当synaug使用更多的扬声器时,eer会降低。然而,在合成语音中增加说话人的数量不能与在真实语音中增加说话人的数量匹配。例如,当我们在真实语音中有10个说话人,在合成语音中有200个说话人(总共210个说话人)时,eer为2.18;但是当我们在真实语音中有20个发言者在合成语音中有100个发言者时,总共120个发言者(比以前的组合少),则eer较低,为1.23。rsr2015和train-clean-460中扬声器之间的域差异可以部分解释这一点。此外,可以观察到,将合成语音中的说话人数量从200增加到500或1000所获得的改善要比将语音数量从100增加到200所获得的改善小。因此,在以下实验中,我们仍将200个说话人用于synaug,以在性能和计算成本。
除了说话人数量之外,我们还研究合成语音中每个说话人的发音数量。在这里,我们分别为每个说话人合成30个转录本5、10和20次,并观察增益。如图7所示,当每个扬声器的发声数增加时,eer减小。这符合常识,即更多的训练数据可以提供更好的性能。
我们首先给出了添加噪声和混响的结果以进行数据扩充。我们遵循kaldivoxcelebrecipev2并生成原始数据集的增强噪声副本。原始数据和产生的噪声数据都用来训练i-向量提取器。如图8的结果表明,在rsr2015中,当10、20和50个扬声器可用时,添加噪声和混响可以降低eer。
然后,我们结合synaug方法,加入噪声和混响。利用tts合成的语音和上述生成的含噪语音进行i-向量训练。我们在图8中展示了结果。与仅使用tts的系统相比,这种组合在资源较低的情况下产生了进一步的收益。然而,当rsr2015中可以使用更多的扬声器时,这种组合不会带来任何好处。例如,当rsr2015中有10个扬声器时,与不应用数据增强的基准相比,这种组合降低了相对eer的82.2%,与仅使用噪声和混响进行数据增强的系统相比,降低了58.8%。
在本文中,我们提出了一种新的基于综合的数据增强方法synaug,该方法利用tts系统生成新说话人的语音,用于文本相关的说话人验证训练。通过使用新说话人的受控语音生成语音,我们证明了synaug可以极大地改善基于文本的说话人验证系统,特别是在原始训练数据非常有限的情况下。在rsr2015数据集上的实验表明,当rsr2015中97个扬声器全部可用时,使用200个增强扬声器,eer相对降低了14.1%;当rsr2015中只有10个扬声器可用时,eer相对降低了76.5%。此外,与传统的加噪声、混响等增强方法相结合,可以进一步提高系统的性能。在未来,我们将在x-vector等基于深度学习的框架中探索synaug方法,实现更大的数据集。
如图9所示为本发明一实施例提供的一种用于文本相关说话人识别的数据增强系统的结构示意图,该系统可执行上述任意实施例所述的用于文本相关说话人识别的数据增强方法,并配置在终端中。
本实施例提供的一种用于文本相关说话人识别的数据增强系统10包括:模型训练程序模块11,数据生成程序模块12和数据增强程序模块13。
其中,模型训练程序模块11用于基于多个说话人的文本无关的数据训练得到语音合成模型;数据生成程序模块12用于将第一真实语音数据对应的文本输入至所述语音合成模型,生成所述多个说话人的第二合成语音数据;数据增强程序模块13用于将所述第一真实语音数据以及所述第二合成语音数据作为用于文本相关的说话人识别的训练数据。
进一步地,所述模型训练程序模块用于:
通过提取器确定所述文本无关的数据中的各说话人的特征信息,其中,所述特征信息包括:音素、音色、音量、语速;
利用所述特征信息确定预测mel-声谱图;
基于预设参考mel-声谱图与所述预测mel-声谱图对所述语音合成模型的提取器进行训练,直至所述预测mel-声谱图趋近于所述预设参考mel-声谱图为止。
进一步地,所述提取器的内核大小为3*3,包括6层2d卷积层。
进一步地,所述提取器还包括:批处理归一化层用于防止梯度爆炸和梯度消失以及relu激活函数用于降低计算量。
本发明实施例还提供了一种非易失性计算机存储介质,计算机存储介质存储有计算机可执行指令,该计算机可执行指令可执行上述任意方法实施例中的用于文本相关说话人识别的数据增强方法;
作为一种实施方式,本发明的非易失性计算机存储介质存储有计算机可执行指令,计算机可执行指令设置为:
基于多个说话人的文本无关的数据训练得到语音合成模型;
将第一真实语音数据对应的文本输入至所述语音合成模型,生成所述多个说话人的第二合成语音数据;
将所述第一真实语音数据以及所述第二合成语音数据作为用于文本相关的说话人识别的训练数据。
作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块,如本发明实施例中的方法对应的程序指令/模块。一个或者多个程序指令存储在非易失性计算机可读存储介质中,当被处理器执行时,执行上述任意方法实施例中的用于文本相关说话人识别的数据增强方法。
非易失性计算机可读存储介质可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据装置的使用所创建的数据等。此外,非易失性计算机可读存储介质可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,非易失性计算机可读存储介质可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
本发明实施例还提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的用于文本相关说话人识别的数据增强方法的步骤。
本申请实施例的电子设备以多种形式存在,包括但不限于:
(1)移动通信设备:这类设备的特点是具备移动通信功能,并且以提供话音、数据通信为主要目标。这类终端包括:智能手机、多媒体手机、功能性手机,以及低端手机等。
(2)超移动个人计算机设备:这类设备属于个人计算机的范畴,有计算和处理功能,一般也具备移动上网特性。这类终端包括:pda、mid和umpc设备等,例如平板电脑。
(3)便携式娱乐设备:这类设备可以显示和播放多媒体内容。该类设备包括:音频、视频播放器,掌上游戏机,电子书,以及智能玩具和便携式车载导航设备。
(4)其他具有数据处理功能的电子装置。
在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”,不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!