一种人类鼾声识别方法及其装置与流程
1.本发明涉及声音识别技术领域,尤其涉及一种人类鼾声识别方法和人类鼾声识别装置。
背景技术:
2.打鼾是由于人们在睡眠过程中因为各种原因导致咽部通道变窄,从而在呼吸时气流通过发出的声音。人们对于打鼾程度的判断多是依靠同室的主观描述,或是分贝仪进行测量,对于独自居住的人们,更是难以知晓自身打鼾情况,可能导致始终不知晓自身患有鼾症,甚至影响身体健康。
3.目前,电动床多采用分贝仪进行打鼾检测并进行干预,通过声音的强度识别鼾声,检测准确度低,容易误触发。
技术实现要素:
4.本发明提供一种人类鼾声识别方法,以解决现有技术中鼾声识别不准确的技术问题。
5.本发明提供的一种人类鼾声识别方法包括:
6.采集声音信号;
7.对所述声音信号进行自相关端点检测,以确定所述声音信号的音源;
8.若所述声音信号的音源包含人类声音,则提取所述声音信号的声学特征;
9.将所述声学特征与预设声学模型进行匹配;若匹配成功,则初步判定所述声音信号为人类鼾声,并记录初步判定所述声音信号为人类鼾声的时间点;
10.若在预设时长内,所述时间点的数量超过预设数量阈值,则最终判定所述声音信号为人类鼾声。
11.进一步地,若在预设时长内,所述时间点的数量超过预设数量阈值,则最终判定所述声音信号为人类鼾声的步骤包括:
12.根据如下公式(1)计算累加时间:
[0013][0014]
其中,ct表示累加时间,t
n
表示检测到鼾声相近两个时间点的差值,k为自然数,n为正整数。
[0015]
进一步地,所述对所述声音信息进行自相关端点检测,以确定所述声音信息的音源的步骤包括:
[0016]
对所述声音信号进行分帧,计算每一帧自相关函数的主峰比值以及对数能量;
[0017]
将主峰比值和对数能量分别进行归一化;
[0018]
将所述自相关函数主峰比值除以所述对数能量,得到均值;
[0019]
根据如下公式(2)、(3)分别计算第一门限阈值和第二门限阈值:
[0020]
t1=α*mean
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2);
[0021]
t2=β*mean
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3);
[0022]
其中,t1表示第一门限阈值,t2表示第二门限阈值,mean表示所述自相关函数主峰比值除以所述对数能量得到的均值,α表示第一阈值系数,β表示第二阈值系数,且0<α<β<1;
[0023]
计算所述声音信号的波形数值;
[0024]
若所述声音信号的波形数值大于第二门限阈值,则判定所述音源包含人类声音。
[0025]
进一步地,在采集得到声音信号之前,还包括:
[0026]
建立声学模型;
[0027]
对所述声学模型进行训练。
[0028]
进一步地,所述建立声学模型步骤包括:
[0029]
采集打鼾语料样本;
[0030]
对所述打鼾语料样本进行预加重、分帧和加窗处理,得到鼾声语料数据;
[0031]
执行梅尔倒普系数法提取所述鼾声语料数据的声学特征。
[0032]
进一步地,在将所述声学特征与预设声学模型进行匹配之前,还包括:若所述声音信号的音源不包含人类声音,则继续采集声音信号。
[0033]
进一步地,所述将所述声学特征与预设声学模型进行匹配的步骤包括:若匹配失败,则舍弃所述声学特征。
[0034]
进一步地,在所述最终判定所述声音信号为人类鼾声之后,还包括:控制电动床执行预设的动作。
[0035]
本发明还提供了相应的人类鼾声识别的装置包括:
[0036]
采集模块,用于采集声音信号;
[0037]
分析模块,用于对所述声音信号进行自相关端点检测,以确定所述声音信息的音源;
[0038]
特征提取模块,用于若所述声音信号的音源包含人类声音,则提取所述声音信号的声学特征;
[0039]
匹配模块,用于将所述声学特征与预设声学模型进行匹配,以初步判断所述声音信号是否为人类鼾声,并记录初步判定所述声音信号为人类鼾声的时间点;
[0040]
比较模块,用于比较预设时长内所述时间点的数量超过预设数量阈值。
[0041]
具体地,所述比较模块根据如下公式(1)计算累加时间:
[0042][0043]
其中,ct表示累加时间,t
n
表示检测到鼾声相近两个时间点的差值,k为自然数,n为正整数。
[0044]
具体地,所述分析模块包括:
[0045]
第一计算模块,用于对所述声音信号进行分帧,计算每一帧自相关函数的主峰比值以及对数能量;
[0046]
第二计算模块,用于将主峰比值和对数能量分别进行归一化;
[0047]
第三计算模块,用于将所述自相关函数主峰比值除以所述对数能量,得到均值;
[0048]
第四计算模块,用于根据如下公式(2)、(3)分别计算第一门限阈值和第二门限阈值:
[0049]
t1=α*mean
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2);
[0050]
t2=β*mean
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3);
[0051]
其中,t1表示第一门限阈值,t2表示第二门限阈值,mean表示所述自相关函数主峰比值除以所述对数能量得到的均值,α表示第一阈值系数,β表示第二阈值系数,且0<α<β<1;
[0052]
第五计算模块,用于计算所述声音信号的波形数值;
[0053]
第六计算模块,用于判断所述声音信号的波形数值是否大于第二门限阈值,以判定所述音源是否包含人类声音。
[0054]
进一步地,还包括:
[0055]
模型计算模块,用于建立声学模型;
[0056]
训练模块,用于对所述声学模型进行训练。
[0057]
进一步,还包括:
[0058]
样本采集模块,用于采集打鼾语料样本;
[0059]
语料处理模块,用于对所述打鼾语料样本进行预加重、分帧和加窗处理,得到鼾声语料数据;
[0060]
语料特征提取模块,用于执行梅尔倒普系数法提取所述鼾声语料数据的声学特征。
[0061]
进一步地,还包括:指令模块,用于控制电动床执行预设的动作。
[0062]
本发明的人类鼾声识别方法通过提高鼾声识别的准确度,提高触发的准确性,提升用户体验。
附图说明
[0063]
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0064]
图1为本发明实施例一的人类鼾声识别方法的流程示意图;
[0065]
图2为本发明实施例一的人类鼾声统计方法示意图;
[0066]
图3为本发明实施例二的人类鼾声识别方法的流程示意图;
[0067]
图4为本发明实施例的人类鼾声识别装置的结构示意图。
具体实施方式
[0068]
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
[0069]
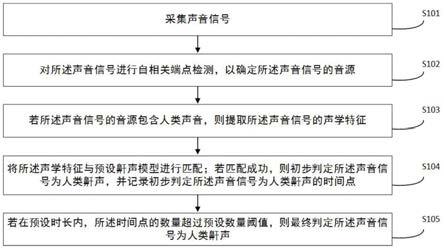
图1是本发明实施例一的人类鼾声识别方法流程示意图,如图1所示,本发明实施例一提供了一种人类鼾声识别方法,其包括:
[0070]
步骤s101,采集声音信号。
[0071]
采集周围环境中的声音信号,并分帧打包按时间缓存,为后面的计算提供数据,以便后续进行识别。
[0072]
步骤s102,对所述声音信号(分帧打包按时间缓存的数据)进行自相关端点检测,以确定所述声音信号的音源。
[0073]
自相关端点检测就是判断音节的开始和结束,是后续数据计算的预处理部分。基音周期是语音信号最重要的参数之一,它描述了语音激励源的一个重要特征,反映了声门相邻两次开闭之间的时间间隔或开闭的频率。
[0074]
自相关端点检测采用短时自相关函数进行基音周期检查。短时自相关函数具有以下特性,当原信号具有周期性,那么它的自相关函数也具有周期性,并且周期性与原信号的周期相同,且在时间延迟量是周期整数倍时会出现峰值。通常取第一最大峰值点作为基音周期点。自相关函数法基音检测利用这一性质来进行基音周期检查,基音检测点定为端点,即数据要处理计算的开始点。
[0075]
鼾声与其他声音在音色、响度、频率、音调有明显区别,通过这些区别可以准确的捕捉鼾声,过滤掉人类声音以外的声音信号,减少其他声源的干扰,自相关端点检测还能提高识别率,并降低中央处理器(cpu)运算的数据量。
[0076]
步骤s103,若所述声音信号的音源包含人类声音,则提取所述声音信号的声学特征。
[0077]
梅尔倒普系数(mfcc),即声学特征。进行声学特征提取,首先对预处理数据的每一帧进行快速傅立叶变换(fft)得到频谱,进而计算出幅度谱,再对幅度谱加mel滤波器组,最后对所有的滤波器输出值做对数运算,再进一步做离散余弦变换(dct)得到梅尔倒普系数(mfcc)。人通过声道产生声音,声道的形状决定了发出怎样的声音,声道的形状包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素phoneme进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而梅尔倒普系数(mfcc)就是一种准确描述这个包络的一种特征,所以说梅尔倒普系数(mfcc)作为声学特征非常重要,相较于传统的分贝仪、频域分析对声音的识别更有效更可靠。
[0078]
步骤s104,将所述声学特征与预设声学模型进行匹配;若匹配成功,则初步判定所述声音信号为人类鼾声,并记录初步判定所述声音信号为人类鼾声的时间点。
[0079]
将提取到的声学特征与经过大量数据训练好的预设声学模型进行匹配,匹配系数0~1之间可设,该系数越大识别率就越高,但误识别率也会变大,0.5~0.8较合适。若匹配成功则初步判断该声音信号是否为人类鼾声,并记录该时间点以确定打鼾的的情况。
[0080]
步骤s105,若在预设时长内,所述时间点的数量超过预设数量阈值,则最终判定所述声音信号为人类鼾声。
[0081]
对识别到的鼾声时间点做统计,在最近t时间内,鼾声识别次数大于n,n和t均为可设置数值,则最终判定为人类鼾声。通过对一段时间的中出现的可能的鼾声次数的统计,减少单次判断错误对整个判断的影响,提高鼾声判断的准确度。
[0082]
具体地,可以通过统计学方法实现,图2为本发明实施例一的人类鼾声统计方法示意图,如图2所示,p为检测到鼾声的时间点,并根据如下公式(1)计算累加时间:
[0083][0084]
其中,ct表示累加时间,t
n
表示检测到鼾声相近两个时间点的差值,k为自然数,n为正整数。
[0085]
如ct小于t,则最终判定所述声音信号为人类鼾声。该方法有助于提高人类鼾声识别的准确度,降低误识别率。
[0086]
图3是本发明实施例二的人类鼾声识别方法的流程示意图,如图3所示,本发明实
施例二提供了人类鼾声识别方法,其包括:
[0087]
步骤s201,采集打鼾语料样本。
[0088]
搜集语音及打鼾语料样本是由于每个人发出的声音是不一样的,同样的话每个人有不同的音色,男人女人小孩声音的频率都不同,所以搜集大量的语料能提取更多的语音特征参数,提高识别率。
[0089]
步骤s202,对所述打鼾语料样本进行预加重、分帧和加窗处理,得到鼾声语料数据。
[0090]
信号预处理(预加重,分帧,加窗):声音信号中有很多杂波,需要对数据做一下相关处理,方便后面的计算。
[0091]
(1)预加重处理其实是将语音信号通过一个高通滤波器:
[0092]
h(z)=1
‑
μz
‑1[0093]
其中μ的值介于0.9
‑
1.0之间,μ的值推荐取值为0.96,z表示频率值。预加重的目的是提升高频部分,使信号的频谱变得平坦,移除频谱倾斜,来补偿语音信号受到发音系统所抑制的高频部分。同时,也是为了消除发生过程中声带和嘴唇的效应,口唇辐射可以等效为一个一阶零点模型。
[0094]
(2)分帧:因为语音信号为短时平稳信号,所以需要进行分帧处理,以便把每一帧当成平稳信号处理。同时为了减少帧与帧之间的变化,相邻帧之间取重叠。一般帧长取25ms,帧移取帧长的一半。
[0095]
(3)加窗:fft算法当中,实际上作了周期性延拓。这是因为计算机进行处理的数据是有限时间段内的,而傅立叶变换要求的是时间从负无穷到正无穷的积分,因此必需要做延拓。这里就涉及到了谱泄漏问题。时域中的突变点在傅立叶变换下会对频谱有明显的影响,即谱泄漏(spectral leakage)。为了消除这种spectral leakage,我们需要引入windowing算法。谱泄漏对频谱图的影响的大小取决于时域图中边界上的不连续程度。加窗方法可以将这种不连续最小化。
[0096]
步骤s203,执行梅尔倒普系数法提取所述鼾声语料数据的声学特征,生成声学模型。
[0097]
声学模型是进行鼾声识别的数据库,通过以上步骤获得大量声学特征并以此构建出声学模型,这样就可以从各种混杂的声音中识别出鼾声数据,识别速度更快、准确率更高。
[0098]
步骤s204,对所述声学模型进行训练。
[0099]
声学模型训练:搜集更多的语料信息,不断完善声学模型,进而逐渐提高识别率,减少误触发,这个过程是不断完善的过程,后期通过对模型的不断升级提高产品的性能。所以,我们的产品是可以持续学习升级的。
[0100]
步骤s205,采集声音信号。
[0101]
步骤s206,对所述声音信号进行分帧,计算每一帧自相关函数的主峰比值以及对数能量。
[0102]
步骤s207,将主峰比值和对数能量分别进行归一化。
[0103]
步骤s208,将所述自相关函数主峰比值除以所述对数能量,得到均值。
[0104]
步骤s209,根据如下公式(2)、(3)分别计算第一门限阈值和第二门限阈值:
[0105]
t1=α*mean
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2);
[0106]
t2=β*mean
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3);
[0107]
其中,t1表示第一门限阈值,t2表示第二门限阈值,mean表示所述自相关函数主峰比值除以所述对数能量得到的均值,α表示第一阈值系数,β表示第二阈值系数,且0<α<β<1。
[0108]
t1为噪声的临界点,波形数值小于t1则为噪声。t2为人声临界点,波形数值大于t2则为人声(起点)。波形数值从大于t2降至小于t1则人声结束(止点)。
[0109]
步骤s210,计算所述声音信号的波形数值。
[0110]
步骤s211,若所述声音信号的波形数值大于第二门限阈值,则判定所述音源包含人类声音,即端点的起点,
[0111]
当波形跌落低于t1则认为不再包含人类声音,即端点检测的止点。
[0112]
通过对声音信息进行自相关端点检测,确定所述声音信息的音源,即声音是否来自于人类。
[0113]
步骤s212,若所述声音信号的音源包含人类声音,则提取所述声音信号的声学特征。
[0114]
步骤s213,若所述声音信号的音源不包含人类声音,则继续采集声音信号,重新执行步骤s205。
[0115]
重复的采集数据,并分析判断,可以使系统全天24小时实时检测鼾声,以便及时发现鼾声。
[0116]
步骤s214,将所述声学特征与预设声学模型进行匹配。
[0117]
步骤s215,若匹配成功,则初步判定所述声音信号为人类鼾声,并记录初步判定所述声音信号为人类鼾声的时间点。
[0118]
步骤s216,若匹配失败,则舍弃所述声学特征。
[0119]
舍弃相关数据,释放存储空间,保证持续的数据采集分析有足够的存储空间,使整个系统更加流畅,提高整体运算速度。
[0120]
步骤s217,若在预设时长内,所述时间点的数量超过预设数量阈值,则最终判定所述声音信号为人类鼾声。
[0121]
步骤s218,控制电动床执行预设的动作。
[0122]
电动床包括至少一块可向上翻转的床板,床板根据预设动作进行翻转,翻转角度为0至60度。通过床板角度的改变,对人体局部进行支撑,贴合人体生理曲线,改变咽喉部肌肉状态,减轻人体局部压力,实现止鼾功效,给身体充分的放松,给用户更舒适的体验。
[0123]
图4为本发明实施例的人类鼾声识别装置的结构示意图,如图4所示,本发明实施例一种用于电动床鼾声识别装置的控制模块,所述人类鼾声识别的装置400包括:
[0124]
采集模块401,用于采集声音信号。
[0125]
采集周围环境中的声音信号,以便后续进行识别,最终实现本装置的功能。
[0126]
分析模块402,用于对所述声音信号进行自相关端点检测,以确定所述声音信息的音源。
[0127]
自相关端点检测就是判断音节的开始和结束,是后续数据计算的预处理部分。基音周期是语音信号最重要的参数之一,它描述了语音激励源的一个重要特征,反映了声门相邻两次开闭之间的时间间隔或开闭的频率。
[0128]
自相关端点检测采用短时自相关函数进行基音周期检查。短时自相关函数具有以下特性,当原信号具有周期性,那么它的自相关函数也具有周期性,并且周期性与原信号的周期相同,且在时间延迟量是周期整数倍时会出现峰值。通常取第一最大峰值点作为基音周期点。自相关函数法基音检测利用这一性质来进行基音周期检查,基音检测点定为端点,即数据要处理计算的开始点。
[0129]
鼾声与其他声音在音色、响度、频率、音调有明显区别,通过这些区别可以准确的捕捉鼾声,过滤掉人类声音以外的声音信号,减少其他声源的干扰,自相关端点检测还能提高识别率,并降低中央处理器(cpu)运算的数据量。
[0130]
特征提取模块403,用于提取包含人类声音的声音信号的声学特征。
[0131]
梅尔倒普系数(mfcc),即声学特征。进行声学特征提取,首先对预处理数据的每一帧进行快速傅立叶变换(fft)得到频谱,进而计算出幅度谱,再对幅度谱加mel滤波器组,最后对所有的滤波器输出值做对数运算,再进一步做离散余弦变换(dct)得到梅尔倒普系数(mfcc)。人通过声道产生声音,声道的形状决定了发出怎样的声音,声道的形状包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素phoneme进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而梅尔倒普系数(mfcc)就是一种准确描述这个包络的一种特征,所以说梅尔倒普系数(mfcc)作为声学特征非常重要,相较于传统的分贝仪、频域分析对声音的识别更有效更可靠。
[0132]
匹配模块404,用于将所述声学特征与预设声学模型进行匹配,以初步判断所述声音信号是否为人类鼾声,并记录初步判定所述声音信号为人类鼾声的时间点。
[0133]
比较模块405,用于比较预设时长内所述时间点的数量超过预设数量阈值。
[0134]
具体地,所述比较模块405根据如下公式(1)计算累加时间:
[0135][0136]
其中,ct表示累加时间,t
n
表示检测到鼾声相近两个时间点的差值,k为自然数,n为正整数。
[0137]
具体地,所述分析模块402包括:
[0138]
第一计算模块4021,用于对所述声音信号进行分帧,计算每一帧自相关函数的主峰比值以及对数能量;
[0139]
语音从宏观上看是不平稳的,但是从微观上来看,在较短的时间内,语音信号就可以看成平稳的,我们称之为短时平稳信号,进行分帧处理以便把声音信号的每一帧当成平稳信号处理。同时为了减少帧与帧之间的变化,相邻帧之间取重叠。一般帧长取25ms,帧移取帧长的一半。这样,就满足了后续计算的需求,避免后续计算因声音信号不平稳导致数据失真,提高鼾声识别的准确性。
[0140]
第二计算模块4022,用于将主峰比值和对数能量分别进行归一化;
[0141]
归一化就是要把需要处理的数据经过处理后限制在你需要的一定范围内,方便后续数据处理并保证程序运行时收敛加快。加快了梯度下降求最优解的速度,有助于提高精度。
[0142]
第三计算模块4023,用于将所述自相关函数主峰比值除以所述对数能量,得到均值;
[0143]
第四计算模块4024,用于根据如下公式(2)、(3)分别计算第一门限阈值和第二门
限阈值:
[0144]
t1=α*mean
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2);
[0145]
t2=β*mean
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3);
[0146]
其中,t1表示第一门限阈值,t2表示第二门限阈值,mean表示所述自相关函数主峰比值除以所述对数能量得到的均值,α表示第一阈值系数,β表示第二阈值系数,且0<α<β<1;
[0147]
t1为噪声的临界点,波形数值小于t1则为噪声。t2为人声临界点,波形数值大于t2则为人声(起点)。波形数值从大于t2降至小于t1则人声结束(止点)。
[0148]
第五计算模块4025,用于计算所述声音信号的波形数值;
[0149]
利用波形数值对声音信号进行量化,以便从混杂的声音信号中辨别出人类声音,计算量较小,简单快速。
[0150]
第六计算模块4026,用于判断所述声音信号的波形数值是否大于第二门限阈值,以判定所述音源是否包含人类声音。
[0151]
t2是人声有无的临界点,波形数值大于t2则为人类声音。信号小于t1认为时噪声,信号大于t1,再到大于t2,这个上升的过程,直到大于t2时刻判定为开始有人声(也就是说信号上升过程中从小于t2到大于t2这个跳变认为人声开始,即起点);从t2下降到t1,最后到小于t1时判定为人声结束(也就是说信号下降过程中从大于t1到小于t1这个跳变,认为人声结束,即止点)。
[0152]
进一步地,所述人类鼾声识别的装置400还包括:
[0153]
模型计算模块406,用于建立声学模型;
[0154]
声学模型是进行鼾声识别的数据库,通过以上步骤获得大量声学特征并以此构建出声学模型,便于从各种混杂的声音中识别出鼾声数据,识别速度更快、准确率更高。
[0155]
训练模块407,用于对所述声学模型进行训练。
[0156]
搜集更多的语料信息,不断完善声学模型,进而逐渐提高识别率,减少误触发,不断完善的过程,通过对模型的不断升级提高产品的性能,提升识别速度和准确度。
[0157]
进一步地,所述人类鼾声识别的装置400还包括:
[0158]
样本采集模块408,用于采集打鼾语料样本;
[0159]
搜集语音及打鼾语料样本是由于每个人发出的声音是不一样的,同样的话每个人有不同的音色,男人女人小孩声音的频率都不同,所以搜集大量的语料能提取更多的语音特征参数,保证后续的处理的可行性,提高识别率。
[0160]
语料处理模块409,用于对所述打鼾语料样本进行预加重、分帧和加窗处理,得到鼾声语料数据;
[0161]
采集的打鼾语料样本中有很多杂波,对打鼾语料样本进行相关处理,方便后续的计算,减少运算量,有助于提升识别速度和准确度。
[0162]
语料特征提取模块410,用于执行梅尔倒普系数法提取所述鼾声语料数据的声学特征。
[0163]
基于声音频率的非线性梅尔刻度(mel scale)的对数能量频谱的线性变换。梅尔频率倒谱的频带划分是在梅尔刻度上等距划分的,它比用于正常的对数倒频谱中的线性间隔的频带更能近似人类的听觉系统。
[0164]
梅尔倒普系数法在纯净人声及噪声环境中具有较好的识别性能,识别速度快,有
助于降低人类鼾声识别的装置400的能耗和散热需求,提升了整体性能。
[0165]
进一步地,所述人类鼾声识别的装置400还包括:指令模块411,用于控制电动床执行预设的动作。
[0166]
电动床包括至少一块可向上翻转的床板,当收到指令模块406的指令后,床板根据预设动作进行翻转,翻转角度为0至60度。通过床板角度的改变,对人体局部进行支撑,贴合人体生理曲线,减轻人体局部压力,给身体充分的放松,给用户更舒适的体验。
[0167]
本发明实施例的人类鼾声识别装置本发明实施例的人类鼾声识别方法的实现装置,具体原理请见本发明实施例的控制方法,此处不再赘述。
[0168]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本申请旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。
[0169]
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1