确定用于语音处理引擎的输入
1.相关申请的交叉引用
2.本技术要求于2019年3月1日提交的美国临时申请第62/812,959号的优先权,其内容通过引用整体并入本文。
技术领域
3.本公开总体上涉及用于处理语音信号的系统和方法,并且特别地涉及用于处理语音信号以呈现给语音处理引擎的系统和方法。
背景技术:
4.用于语音识别的系统的任务是通常经由一个或多个麦克风接收表示人类语音的音频输入,并处理音频输入以确定与该音频输入对应的词、逻辑结构、或其它输出。例如,自动语音识别(asr)系统可以基于与音频输入信号对应的人类语音生成文本输出;并且自然语言处理(nlp)工具可以生成与人类语音的含义对应的逻辑结构或计算机数据。虽然此类系统可能包含任何数量的组件,但此类系统的核心是语音处理引擎,其中该组件接受音频信号作为输入,对输入执行一些识别逻辑,并输出与该输入对应的一些文本。(虽然在此参考了语音处理引擎,但在本公开的范围内还应考虑除语音识别之外的其它形式的语音处理)。
5.历史上,诸如经由麦克风检测的音频输入以结构化的可预测的方式被提供给语音处理引擎。例如,用户可能响应第一提示(prompt)(例如,“现在开始讲话”)会直接对着台式计算机的麦克风讲话;在按下第一按钮输入(例如,“开始”或“录制”按钮,或软件界面中的麦克风图标)后立即;或在一段相当长的沉默之后。类似地,用户可能响应第二提示(例如,“停止讲话”)停止提供麦克风输入;在按下第二按钮输入(例如,“停止”或“暂停”按钮)之前立即;或保持沉默一段时间。此类结构化的输入序列对于用户何时向语音处理引擎提供输入几乎没有任何疑问(例如,在第一提示与第二提示之间,或在按下开始按钮与按下停止按钮之间)。此外,由于此类系统通常需要用户有意识地采取动作,并且因此通常可以假设用户的语音输入是针对语音处理引擎的,而不是针对某个其他听众(例如,相邻房间中的人)。因此,当时的许多语音处理引擎可能没有任何特别需要从麦克风输入中识别输入的哪些部分针对语音处理引擎并旨在提供语音识别输入,以及相反,哪些部分不是。
6.用户提供语音识别输入的方式已经改变,因为语音处理引擎变得更加普遍并且更加完全地融入用户的日常生活。例如,一些自动语音助手现在安装在家用电器、汽车仪表板、智能手机、可穿戴设备、“客厅”设备(例如,具有集成“智能”语音助手的设备)和远离传统台式计算机的其它环境或以其它方式与其集成。在许多情况下,语音处理引擎在日常生活中的该集成水平可以得到更广泛的使用。然而,这些系统会因系统提示、按钮输入和用于将麦克风输入划分到语音处理引擎的其它传统机制而变得笨重。相反,一些此类系统将一个或多个麦克风置于“始终开启”状态,其中麦克风监听表示开始语音识别输入序列的“唤醒词”(例如,设备的“名称”、或任何其它预定词或短语)。在检测到唤醒词时,语音处理引擎
可以处理麦克风输入接下来的序列作为语音处理引擎的输入。
7.虽然唤醒词系统取代了语音处理引擎对离散提示或按钮输入的需要,但它存在误报的风险,诸如用户说出无意激活语音处理引擎的唤醒词,或者被语音处理引擎附近的电视或音乐扬声器无意“说出”的唤醒词。可能需要用一种更智能的方式来取代唤醒词系统,该方式基于语音输入来确定用户是否旨在让该语音向语音处理引擎提供输入——也就是说,用户的语音是否是“输入语音”,而不是“非输入语音”。这将允许用户更自然地与语音处理引擎交互(例如,无需调用专用唤醒词),并鼓励在日常环境和情况下使用此类系统。
8.占据日常空间的语音处理引擎的相关问题是这些引擎可能检测到大量环境噪声、不针对引擎的语音,或不旨在作为输入的其它音频信号。例如,客厅中的语音处理引擎不仅会检测用户有意的语音处理引擎输入(例如,“星期二的天气预报是什么?”),还会检测来自宠物、设备(例如,电视扬声器)、或其他人的声音和语音;环境噪音;或用户讲话的针对附近其他人的部分。处理音频信号的这些非输入部分会浪费计算资源,并且可影响语音处理引擎的准确性——这在一些不受控制的环境中(例如,户外)可能已经受到限制。期望语音处理引擎从麦克风输入中识别麦克风输入中的表示旨在用于语音处理引擎的输入的部分(输入语音);并忽略并不旨在用于语音处理引擎的输入的部分(非输入语音)。
9.还希望使用配备传感器的系统,包括并入可穿戴头戴式单元的那些系统,以提高语音处理引擎识别和忽略不旨在用于语音处理引擎的音频输入的能力。语音处理引擎可以使用传感器数据(例如,来自单个传感器的数据、或来自与惯性测量单元融合在一起的多个传感器的数据)来帮助识别和处理音频输入信号中属于输入语音的那些部分,允许这些系统的输出生成更准确和更可靠的结果。特别是可穿戴设备的传感器可能特别有用;例如,此类传感器可以指示用户的位置和取向;用户的眼睛运动和眼睛注视目标;用户手部的运动;以及生物度量数据(例如,诸如心率和呼吸频率的生命体征)。在许多情况下,这些指示可以向语音识别系统提供与人类用来直观地理解另一个人正在和谁讲话的同类非语言线索(诸如用户的运动和身体语言)。此外,可穿戴系统非常适合移动的户外应用——正是在这种应用类型中,许多传统的语音处理引擎可能表现得特别差。
技术实现要素:
10.本公开的示例描述了用于向语音处理引擎呈现信号的系统和方法。根据示例方法,经由一个或多个麦克风接收音频信号。识别音频信号的一部分,并且确定该部分包括由语音处理引擎的用户将其作为输入定向到语音处理引擎的语音的概率。根据概率超过阈值的确定,音频信号的部分作为输入被呈现给语音处理引擎。根据概率不超过阈值的确定,音频信号的部分不作为输入呈现给语音处理引擎。
附图说明
11.图1示出根据本公开的一些实施例的示例可穿戴系统。
12.图2示出根据本公开的一些实施例的可以与示例可穿戴系统结合使用的示例手持式控制器。
13.图3示出根据本公开的一些实施例的可以与示例可穿戴系统结合使用的示例辅助单元。
14.图4示出根据本公开的一些实施例的示例可穿戴系统的示例功能框图。
15.图5示出根据本公开的一些实施例的用于处理声学语音信号的示例系统的流程图。
16.图6a至6d示出根据本公开的一些实施例的处理声学语音信号的示例。
17.图7a至7c示出根据本公开的一些实施例的用于处理声学语音信号的示例系统的流程图。
18.图8示出了示出根据本公开的一些实施例的用于处理声学语音信号的示例系统的部分的流程图。
19.图9示出了示出根据本公开的一些实施例的用于处理声学语音信号的示例系统的部分的流程图。
20.图10示出根据本公开的一些实施例的与一个或多个接收者交互的用户。
21.图11示出根据本公开的一些实施例的用于捕获音频和非音频分类器训练数据的示例过程。
具体实施方式
22.在以下示例的描述中,参考了形成其一部分的附图,并且在附图中通过图示的方式示出了可以实践的特定示例。应当理解,在不脱离所公开示例的范围的情况下,可以使用其它示例,并且可以进行结构改变。
23.示例可穿戴系统
24.图1示出被配置为佩戴在用户的头部上的示例可穿戴头部设备100。可穿戴头部设备100可以是更广泛的可穿戴系统的一部分,该系统包括一个或多个组件,诸如头部设备(例如,可穿戴头部设备100)、手持式控制器(例如,以下所述的手持式控制器200)、和/或辅助单元(例如,下面描述的辅助单元300)。在一些示例中,可穿戴头部设备100可以用于虚拟现实、增强现实、或混合现实系统或应用。可穿戴头部设备100可以包括一个或多个显示器,诸如显示器110a和110b(其可以包括左和右透射显示器,以及用于将光从显示器耦合到用户的眼睛的相关联组件,诸如正交光瞳扩展(ope)光栅组112a/112b和出射光瞳扩展(epe)光栅组114a/114b);左和右声学结构,诸如扬声器120a和120b(其可以分别安装在镜腿122a和122b上,并且与用户的左耳和右耳相邻定位);一个或多个传感器,诸如红外传感器、加速度计、gps单元、惯性测量单元(imu,例如imu 126)、声学传感器(例如麦克风150);正交线圈电磁接收器(例如,所示出的安装到左镜腿臂122a的接收器127);远离用户取向的左和右相机(例如,深度(飞行时间)相机130a和130b);以及朝向用户取向的左眼和右眼相机(例如,用于检测用户的眼睛运动)(例如,眼睛相机128a和128b)。然而,可穿戴头部设备100可以结合任何合适的显示技术,以及任何合适数量、类型或组合的传感器、或不脱离本发明的范围的其它组件。在一些示例中,可穿戴头部设备100可以结合一个或多个麦克风150,该麦克风150被配置为检测由用户的语音生成的音频信号;此类麦克风可以定位与用户的嘴相邻。在一些示例中,可穿戴头部设备100可以结合连网特征(例如,wi
‑
fi能力),以与包括其它可穿戴系统的其它设备和系统通信。可穿戴头部设备100可进一步包括诸如电池、处理器、存储器、存储单元或各种输入设备(例如,按钮、触摸板)的组件;或可以耦合到包括一个或多个此类组件的手持式控制器(例如,手持式控制器200)或辅助单元(例如,辅助单元300)。在一
些示例中,传感器可以被配置为输出头戴式单元相对于用户环境的一组坐标,并且可以向执行同步定位和映射(slam)过程和/或视觉测距算法的处理器提供输入。在一些示例中,如下面进一步描述,可穿戴头部设备100可以耦合到手持式控制器200和/或辅助单元300。
25.图2示出示例可穿戴系统的示例移动手持式控制器组件200。在一些示例中,手持式控制器200可以与以下描述的可穿戴头部设备100和/或辅助单元300进行有线或无线通信。在一些示例中,手持式控制器200包括要由用户握持的手柄部220,以及沿着顶表面210设置的一个或多个按钮240。在一些示例中,手持式控制器200可以被配置为用作光学跟踪目标;例如,可穿戴头部设备100的传感器(例如,相机或其它光学传感器)可以配置为检测手持式控制器200的位置和/或取向,从而通过扩展可以指示握持手持式控制器200的用户的手的位置和/或取向。在一些示例中,诸如上述,手持式控制器200可以包括处理器、存储器、存储单元、显示器、或一个或多个输入设备。在一些示例中,手持式控制器200包括一个或多个传感器(例如,以上关于可穿戴头部设备100所述的任何传感器或跟踪组件)。在一些示例中,传感器可以检测手持式控制器200相对于可穿戴头部设备100或相对于可穿戴系统的另一组件的位置或取向。在一些示例中,传感器可以定位在手持式控制器200的手柄部220中,和/或可以机械地耦合到手持式控制器。手持式控制器200可以被配置为提供一个或多个输出信号,例如,对应于按钮240的按下状态;或者,手持式控制器200的位置、取向和/或运动(例如,经由imu)。此类输出信号可以用作可穿戴头部设备100的处理器、辅助单元300、或可穿戴系统的另一组件的输入。在一些示例中,手持式控制器200可以包括一个或多个麦克风以检测声音(例如,用户的语音、环境声音),并且在一些情况下,将与所检测的声音相对应的信号提供给处理器(例如,可穿戴头部设备100的处理器)。
26.图3示出示例可穿戴系统的示例辅助单元300。在一些示例中,辅助单元300可以与可穿戴头部设备100和/或手持式控制器200进行有线或无线通信。辅助单元300可以包括电池,以提供能量来操作可穿戴系统的一个或多个组件,诸如可穿戴头部设备100和/或手持式控制器200(包括显示器、传感器、声学结构、处理器、麦克风和/或可穿戴头部设备100或手持式控制器200的其它组件)。在一些示例中,如上所述,辅助单元300可以包括处理器、存储器、存储单元、显示器、一个或多个输入设备、和/或一个或多个传感器。在一些示例中,辅助单元300包括用于将辅助单元附接至用户(例如,由用户佩戴的皮带)的夹子310。使用辅助单元300来容纳可穿戴系统的一个或多个组件的优点是,这样做可以使大型或沉重的组件被携带在用户的腰部、胸部或背部上(它们相对非常适合于支撑较大和较重的对象),而不是安装到用户的头部(例如,如果容纳在可穿戴头部设备100中)或由用户的手携带(例如,如果容纳在手持式控制器200中)。对于相对较重或笨重的组件(诸如电池)这可能是特别有利的。
27.图4示出可以对应于示例可穿戴系统400(诸如可以包括上述示例可穿戴头部设备100、手持式控制器200、和辅助单元300)的示例功能框图。在一些示例中,可穿戴系统400可以用于虚拟现实、增强现实、或混合现实应用。如图4中所示,可穿戴系统400可以包括示例手持式控制器400b,在此称为“图腾”(并且可以对应于上述手持式控制器200);手持式控制器400b可包括图腾至头盔(headgear)的六个自由度(6dof)图腾子系统404a。可穿戴系统400还可以包括示例头盔设备400a(其可以对应于上述可穿戴头部设备100);头盔设备400a包括图腾至头盔的6dof头盔子系统404b。在该示例中,6dof图腾子系统404a和6dof头盔子
系统404b共同确定手持式控制器400b相对于头盔设备400a的六个坐标(例如,三个平移方向中的偏移和沿三个轴的旋转)。六个自由度可以相对于头盔设备400a的坐标系表达。在此类坐标系中,三个平移偏移量可以表达为x、y和z偏移量,可以表达为平移矩阵、或一些其它表示。旋转自由度可以表达为一序列的偏航、俯仰和滚动旋转;表达为矢量;表达为旋转矩阵;表达为四元数;或表达为一些其它表示。在一些示例中,头盔设备400a中包括的一个或多个深度相机444(和/或一个或多个非深度相机);和/或一个或多个光学瞄准(例如,如上所述的手持式控制器200的按钮240、或手持式控制器中包括的专用光学瞄准)可用于6dof跟踪。在一些示例中,如上所述,手持式控制器400b可以包括相机;并且头盔设备400a可包括与相机一起用于光学跟踪的光学瞄准。在一些示例中,头盔设备400a和手持式控制器400b各自包括一组三个正交取向的螺线管,其用于无线地发送和接收三个可区分的信号。通过测量在用于接收的每个线圈中所接收到的三个可区分信号的相对幅度,可以确定手持式控制器400b相对于头盔设备400a的6dof。在一些示例中,6dof图腾子系统404a可以包括惯性测量单元(imu),该惯性测量单元可用于提供有关快速运动的手持式控制器400b的改进的精度和/或更及时的信息。
28.在一些涉及增强现实或混合现实应用的示例中,可能希望将坐标从本地坐标空间(例如,相对于头盔设备400a固定的坐标空间)变换为惯性坐标空间或环境坐标空间。例如,此类变换对于头盔设备400a的显示器可能是必要的,以在相对于真实环境的预期位置和取向而不是显示器上的固定位置和取向(例如,头盔设备400a的显示器中的相同位置处)呈现虚拟对象(例如,坐在真实椅子上,面向前方的虚拟人,无论头盔设备400a的位置和取向如何)。这可以保持虚拟对象存在于真实环境中的幻觉(并且例如随着头盔设备400a移动和旋转而不会不自然地出现定位在真实环境中)。在一些示例中,可以通过处理来自深度相机444的图像(例如,使用同时定位和映射(slam)和/或视觉测距过程)来确定坐标空间之间的补偿变换,以便确定头盔设备400a相对于惯性或环境坐标系的变换。在图4中所示的示例中,深度相机444可以耦合到slam/视觉测距模块406,并且可以向模块406提供图像。slam/视觉测距模块406的实现方式可以包括处理器,该处理器被配置为处理该图像并确定用户的头部的位置和取向,该位置和取向然后可以用于识别头部坐标空间与实际坐标空间之间的变换。类似地,在一些示例中,关于用户的头部姿势和位置的附加信息源从头盔设备400a的imu 409获得。来自imu 409的信息可以与来自slam/视觉测距模块406的信息集成在一起,以提供关于用户的头部姿势和位置的快速调节的改进的准确性和/或更及时的信息。
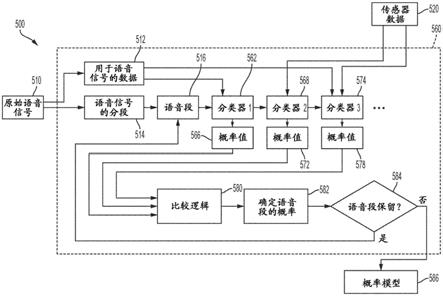
29.在一些示例中,深度相机444可以将3d图像提供给手势跟踪器411,这可以在头盔设备400a的处理器中实现。手势跟踪器411可以例如通过将从深度相机444接收的3d图像与表示手势的存储图案(pattern)进行匹配来识别用户的手势。识别用户手势的其它合适技术将显而易见。
30.在一些示例中,一个或多个处理器416可以被配置为从头盔子系统404b、imu 409、slam/视觉测距模块406、深度相机444、麦克风450、和/或手势跟踪器411接收数据。处理器416还可以发送和接收来自6dof图腾系统404a的控制信号。诸如在手持式控制器400b不受束缚的示例中,处理器416可以无线地耦合到6dof图腾系统404a。处理器416可以进一步与附加组件通信,诸如视听内容存储器418、图形处理单元(gpu)420和/或数字信号处理器(dsp)音频声场定位器(spatializer)422。dsp音频声场定位器422可以耦合到头部相关传
输函数(hrtf)存储器425。gpu 420可以包括耦合到成影像调制光的左源424的左通道输出和耦合到成影像调制光的右源426的右通道输出。gpu 420可将立体图像数据输出到成影像调制光424、426的源。dsp音频声场定位器422可以将音频输出到左扬声器412和/或右扬声器414。dsp音频声场定位器422可以从处理器419接收指示从用户到虚拟声源的方向矢量的输入(该虚拟声源可以由用户例如经由手持控制器400b来移动)。基于方向矢量,dsp音频声场定位器422可以确定对应的hrtf(例如,通过访问hrtf,或者通过内插多个hrtf)。然后,dsp音频声场定位器422可以将所确定的hrtf应用于音频信号,诸如与由虚拟对象生成的虚拟声音相对应的音频信号。通过在混合现实环境中结合用户相对于虚拟声音的相对位置和取向,也就是说,通过呈现与虚拟声音听起来像是在真实环境中的真实声音的用户期望相匹配的虚拟声音,可以增强虚拟声音的可信度和真实性。
31.在一些示例中,诸如图4中所示,处理器416、gpu 420、dsp音频声场定位器422、hrtf存储器425、和音频/视频内容存储器418中的一个或多个可以被包括在辅助单元400c(其可以对应于上述辅助单元300)中。辅助单元400c可以包括电池427,以对其组件供电和/或向头盔设备400a和/或手持式控制器400b供电。将此类组件包括在可以安装到用户腰部的辅助单元中,可以限制头盔设备400a的大小和重量,这进而可以减少用户头部和颈部的疲劳。
32.尽管图4呈现了与示例可穿戴系统400的各个组件相对应的元件,但是这些组件的各种其它合适的布置对于本领域技术人员而言将变得显而易见。例如,与辅助单元400c相关联的图4中呈现的元件可以替代地与头盔设备400a或手持式控制器400b相关联。此外,一些可穿戴系统可以完全放弃手持式控制器400b或辅助单元400c。此类改变和修改应被理解为包括在所公开的示例的范围内。
33.语音处理引擎
34.语音识别系统通常包括语音处理引擎,该语音处理引擎可以接受与人类语音对应的输入音频信号(源信号);处理和分析输入音频信号;并且作为分析的结果生成与人类语音对应的输出。例如,在自动语音识别(asr)系统的情况下,语音处理引擎的输出可以是人类语音的文本转录。在自然语言处理系统的情况下,输出可以是人类语音所指示的一个或多个命令或指令;或人类语音的语义的一些表示(例如,逻辑表达或数据结构)。其它类型的语音处理系统(例如,自动翻译系统),包括不一定“识别”语音的那些系统,都被考虑在内并且在本公开的范围内。
35.语音识别系统存在于多种产品和应用中:传统电话系统;自动语音消息系统;语音助手(包括独立和基于智能手机的语音助手);车辆和飞机;桌面和文件处理软件;数据输入;家用电器;医疗设备;语言翻译软件;隐藏式字幕系统;和其它。语音识别系统的优点是它们可以允许用户使用自然口语向计算机系统提供输入,诸如呈现给一个或多个麦克风,而不是传统的计算机输入设备,诸如键盘或触摸板;因此,语音识别系统在传统输入设备(例如,键盘)可能不可用或不切实际的环境中可能特别有用。此外,通过允许用户提供直观的基于语音的输入,语音处理引擎可以增强沉浸感。因此,语音识别可能非常适合可穿戴系统,并且特别是可穿戴系统的虚拟现实、增强现实、和/或混合现实应用,其中用户沉浸是主要目标;并且其中可能需要限制使用传统计算机输入设备,这些设备的存在可能会降低沉浸感。
36.通常,任何语音处理引擎的输出都不能完全确定地对应于源人类语音;由于许多变量可影响作为输入提供的音频信号,即使是复杂的语音处理引擎也无法始终如一地为所有讲话者生成完美的文本输出。例如,语音处理引擎的可靠性可能高度取决于输入音频信号的质量。在理想条件下记录输入音频信号的情况下——例如,在声控环境中,单个人类扬声器从近距离清晰且直接地向麦克风发音——可以更容易地从音频信号中确定源语音。然而,在实际应用中,输入音频信号可能会偏离理想条件,使得确定源人类语音变得更加困难。例如,除了用户之外,输入音频信号可能包括显著的环境噪声或来自多个扬声器的语音;例如,来自其他人、宠物或电子设备(例如电视)的语音可以在输入信号中与用户语音混合。此外,即使用户的语音也可能不仅包括针对语音处理引擎的语音(输入语音),还包括针对其他听众(例如其他人、宠物、或其它设备)的语音。通过将输入语音与更广泛的输入音频信号隔离,可以提高语音处理引擎所处理的输入的保真度;并且语音处理引擎的输出的准确性也可以相应提高。
37.对输入语音进行识别和分段
38.本公开涉及用于通过从原始语音信号中去除那些信号中未被用户定向到语音处理系统的部分来提高语音处理系统的准确性的系统和方法。如在此所述,可以基于语音信号本身的音频特性(例如,语音词汇、语义或语法的突然变化)来识别(例如,分类)此类非输入部分;和/或通过使用来自与可穿戴设备(例如,诸如上面关于图1所述的头戴式设备)相关联的传感器的输入。此类非输入部分在语音处理的移动应用中、在语音处理系统的家庭使用中、或在不受控制的环境(诸如可能存在其它语音或环境噪声的室外环境)中的语音处理应用中特别突出。可穿戴系统通常用于此类应用,并且因此可能特别容易受到非定向语音的影响。例如,在一些可穿戴系统旨在用于不受控制的环境中时,环境噪声(或其他人的语音)很可能会与目标人类语音一起被记录下来。如在此所述,可穿戴系统的传感器(诸如上面关于图1
‑
4所描述的)非常适合于解决该问题。然而,在一些示例中,如在此所述,即使没有传感器输入的益处,也可以仅基于语音信号来确定方向性(directivity)。
39.图5示出根据一些实施例的示例系统500,其中语音处理引擎550基于作为输入提供的原始语音信号510生成文本输出552(诸如上述)。在一些示例中,原始语音信号510可以在由一个或多个麦克风检测到时提供,但在一些示例中可以从数据文件(例如,音频波形文件)、从音频流(例如,经由网络提供),或从任何其它合适的来源提供。在系统500中,可以通过将“定向”语音信号540呈现为语音处理引擎550的输入来实现改进准确度的文本输出552,该“定向”语音信号540仅包括原始输入语音信号510中被确定为构成定向到语音处理引擎550的输入语音的那些部分(与例如诸如上述的无关(extraneous)语音相反)。定向语音信号540可以在阶段530处从原始输入语音信号510和/或传感器数据520确定,该传感器数据可以对应于来自诸如上面关于图1中的示例可穿戴头部设备100描述的传感器的数据。
40.在阶段530处,原始语音信号510可以被分成单独的(individual)语音片段;然后,对于每个片段,可以确定该片段对应于旨在作为语音处理引擎550的输入的输入语音的概率。在一些情况下,概率建模或机器学习技术可以为原始语音信号510的每个片段指示该概率。然后可以通过从原始语音信号510过滤原始语音信号510中不满足对应于输入语音(而不是非输入语音)的阈值概率的片段来生成定向语音信号540。(如在此所使用的,输入语音可以包括由特定用户提供并且也由用户朝向语音识别系统定向的输入音频)。
41.图6a
‑
6d分别示出原始语音信号、语音信号的分段版本、原始语音信号的概率模型(尽管在一些实施例中可以使用机器学习技术)、以及根据原始语音信号生成的定向语音信号的示例。图6a示出诸如可能由一个或多个麦克风检测到和/或在波形音频文件中表示的表达为时间的函数的(例如,电压的)幅度v(t)的示例音频波形600(其可以对应于原始语音信号510)。在示例中,波形600对应于用户说出示例序列“天气怎么样...不是现在,charlie...明天”。在该示例中,语音序列包括旨在作为对语音处理引擎(例如,语音处理引擎550)的询问的至少一个部分(“天气怎么样”);不旨在作为语音处理引擎而是作为另一个听众(大概是charlie)的输入的至少一个部分(“不是现在,charlie”);以及在语义上可以合理地属于语音识别输入部分(“天气怎么样
…
明天”)或非输入部分(“不是现在,charlie
…
明天”)的至少一个部分(“明天”)。此外,原始语音信号510包括口语部分之间的非语言噪声。如果将原始语音信号510作为输入直接应用到语音处理引擎550,则系统可能会产生意外的结果,因为非输入语音的存在(“不是现在,charlie”,并且可能是“明天”)可能会干扰系统的能够对输入语音(“天气怎么样”,可能带有限定词“明天”)做出有意义的响应。通过在向语音处理引擎550提供输入之前过滤原始语音信号600以生成包括针对语音处理引擎550的语音(例如,“天气怎么样
…
明天”)的定向音频信号,以排除不针对语音处理引擎550的非输入语音(例如,“不是现在,charlie”),可以获得更高质量的结果(如在此所使用的,非输入语音可以包括不是由特定用户提供和/或不是朝向语音处理系统定向的输入音频)。
42.分段过程可以将原始语音信号划分为单独的音频片段,该单独的音频片段可以被单独评估为对应于输入语音或非输入语音。图6b示出将原始语音信号600分段成音频片段的示例。片段可以包括音素、单词、短语、句子、话语、或上述任何内容的组合。对于每个片段,示例系统500可以确定该片段是对应于输入语音还是非输入语音,其中确定的结果用于确定该片段是应该包括在定向语音信号540中还是应该从定向语音信号540中排除。如图6b中所示,信号600的片段可以表达为信号600的位于两个时间点之间(例如,沿不变的t轴)的区域。例如,在图中,第一片段601(例如,对应于“天气怎么样”)位于点t0和t1之间;第二片段602(例如,对应于非语音,例如背景噪声)位于点t1和t2之间;第三片段603(例如,对应于“不是现在”)位于点t2和t3之间;第四片段604(例如,对应于“charlie”)位于点t3和t4之间;第五片段605(例如,对应于非语音,例如背景噪声)位于点t4和t5之间;第六片段606(例如,对应于“明天”)位于点t5和t6之间;以及第七片段607(例如,对应于非语音,例如背景噪声)位于点t6和t7之间。
43.可以根据一种或多种合适的技术来确定此类片段的边界。例如,可以使用本领域已知的各种技术来确定口语单词或短语的边界。根据一些此类技术,片段之间的边界可以基于例如如下来确定:相对沉默的时间段(指示语音“块”之间的间隙);音高或语调的变化(可指示单词、短语或想法的开始或结束);讲话节奏的变化(可以指示开始或结束,或者一个单词、短语或想法,或从一个单词、短语或想法到另一个的过渡);呼吸模式(这可以指示讲话者即将开始一个新单词、短语或想法);等等。在一些示例中,语音信号的统计分析可用于识别片段边界;例如,语音信号中的表示信号中统计异常值的部分(例如,语音信号中包括在信号的其它地方不常见的频率分量的部分)可以表示单词、短语或想法的开始或结束。各种机器学习技术也可用于识别片段边界。
44.在一些示例中,传感器数据520可用于通过指示用户可能改变其语音目标(例如,从对语音处理引擎讲话转换为对房间中的另一个人讲话)的潜在分离点来分段语音信号(例如,原始语音信号510)。例如,传感器数据可以指示用户何时转动头部、改变眼睛注视的焦点、或移动到房间中的不同位置。此类传感器数据的突然变化可用于指示语音片段之间的边界。
45.语音片段的长度(例如,平均时间或音节数)可以变化。在一些示例中,片段通常可以是几个单词的数量级,诸如可以组成口语短语。在一些示例中,片段可以更长(例如,构成一个或多个完整的句子或话语),或更短(例如,构成单个单词,或甚至单个音节)。如在此所述,可以基于每个片段从定向语音信号540中包括或排除语音,使得对于每个片段,包括整个片段或排除整个片段。利用更长的片段可增加单个片段将包括输入语音和非输入语音二者的风险,这可导致不希望的结果:从定向语音信号540中排除此类片段将导致无法将用户的输入语音呈现给语音处理引擎550,而包括它将向语音处理引擎550呈现非输入语音——生成定向语音信号540的相反目标。虽然使用较短的片段可以减少该问题,但它在处理单个语音信号的附加片段所需的计算开销(以及伴随的延迟)方面可能存在折衷。片段大小的所需平衡可以是在可能的程度上将单个相关单词或想法分组在单个片段中,使得整个片段被定向或不被定向到语音处理引擎550。例如,在示例信号600中,“天气怎么样”和“不是现在”每个都构成一起上升或下降的单个语音块,并且因此可能有利于分组为单个片段。然而,片段可以任意大或任意小(包括小到单个数字音频样本的片段),并且本公开不限于任何特定的片段大小。
46.在一些示例中,可以对预先记录的语音信号执行分段,其中在对其进行分段之前捕获整个语音信号。在此类示例中,分段可能相对更准确和/或更有效,因为可以使用整个语音信号的知识来生成更有意义的语音片段;也就是说,当整个信号已知时,语音信号的哪些部分应该被分段在一起可以更容易地确定。然而,在一些示例中,可以在检测到“现场(live)”语音时对其进行分段。用于对预先记录的语音信号进行分段的技术也可以用于对现场语音信号进行分段(例如,通过将此类技术应用于缓冲的现场语音块)。在一些情况下,可能需要定期重新审视(revisit)现场语音的分段决策,因为新语音阐明了先前语音的意图。此外,语音的一部分可以标记为手动检查(review),稍后可以手动评估和校正。
47.图6c展示了与语音信号600对应的示例概率模型610。在该示例中,概率模型610可以表达作为时间t的函数的概率p(t),概率p(t)表达对应音频信号600在时间t的片段是定向给语音处理引擎550的用户语音。(可替代地,在一些示例中,p(t)可以描述该片段不是定向给语音处理引擎的用户语音的概率)。例如,在该示例中,在落在t0和t1之间的时间t
k1
,p(t
k1
)等于0.9,指示语音信号600在时间t
k1
的部分(v(t
k1
),例如“天气”)具有90%的概率是定向给语音处理引擎550的用户语音。类似地,在落在t3和t4之间的时间t
k2
,p(t
k2
)等于0.1,指示语音信号600在时间t
k2
的部分(v(t
k2
),例如“charlie”)具有10%的概率是定向给语音处理引擎550的用户语音。
48.如图所示,概率p(t)可以基于每个片段确定,使得对于在时间t0开始并在时间t1结束的片段,p(t)在p(t0)和p(t1)之间保持恒定(也就是说,整个片段将具有相同的概率值)。因此,在概率模型610中,片段601(“天气怎么样”)具有0.9的对应概率值611;片段603(“不是现在”)具有0.3的对应概率值613;片段604(“charlie”)具有0.1的对应概率值614;并且
片段606(“明天”)具有0.6的对应概率值616。在图中,其余片段(即,可对应于背景噪声或其它非语音音频的片段602、605和607)具有为零的对应概率值(即,分别为612、615和617)。
49.对输入语音进行分类
50.确定语音片段的概率值可以被称为对语音片段进行“分类”,并且用于执行该确定的模块或过程(例如,562、568、574)可以被称为“分类器”。图7a、7b和7c示出示例系统500的示例分类器,用于确定语音信号片段(例如,上述语音信号600的片段610)的概率值。该确定可以如下来执行:使用语音信号本身(例如,如图7a中所示);使用与用户相关联的传感器数据(例如,如图7b中所示);或使用语音信号和传感器数据的一些组合(例如,如图7c中所示)。
51.在图7a中所示的示例中,分类器562使用语音片段516、语音信号的统计数据512、和/或语音数据存储库527来确定概率值566,语音片段516采用该概率值与输入语音(例如,定向给语音识别系统的用户语音)对应。在阶段563处,语音片段516可以诸如通过使用语音信号的统计数据512根据一个或多个参数被参数化/表征。这可以促进基于语音数据存储库527对语音片段进行分类。语音数据存储库527可以存储在数据库中。可以执行基于时间的语音片段516的傅立叶变换以便提供语音片段的频谱表示(例如,指示语音片段516中各种频率参数的相对普遍性的频率函数)。在一些情况下,可以将语音片段516与统计数据512进行比较以确定语音片段516偏离其所属的较大语音信号的程度。例如,这可以指示语音片段的音量或分量频率的水平(或变化),这可以在阶段564处用于表征语音片段。在一些示例中,讲话者的方面——例如讲话者的年龄、性别和/或母语——可以用作表征语音片段516的参数。可以参数化语音片段516的其它方式对于本领域技术人员将是显而易见的,其中此类参数用于表征在阶段564处的语音片段。作为示例,语音片段516可以用预加重(pre
‑
emphasis)、频谱分析、响度分析、dct/mfcc/lpc/mq分析、梅尔(mel)滤波器组滤波、降噪、信号带通滤波到最有用的语音范围(例如,85至8000hz)、以及动态范围压缩进行预处理。然后可以将剩余的信号参数化为一组时不变特征(例如讲话者识别/生物度量、性别识别、平均基频、平均响度)和时变特征向量(例如共振峰中心(formant center)频率和带宽、基频、dct/mfcc/lpc/mq系数、音素识别、辅音识别、音高轮廓、响度轮廓)。
52.在示例的阶段564处,确定语音片段516对应于输入语音的概率值566。可以使用语音数据存储库527来确定概率值566。例如,包括语音数据存储库527的数据库可以针对数据库中的语音元素识别那些元素是否对应于输入语音。语音数据存储库527中可以表示各种类型的数据。在一些示例中,语音数据存储库527可以包括与语音片段对应的一组音频波形;并且可以针对每个波形指示对应的语音片段是否属于输入语音。在一些示例中,代替音频波形或除了音频波形之外,语音数据存储库527可以包括与语音片段对应的音频参数。语音片段516可以与语音数据存储库527的语音片段进行比较——例如,通过将语音片段516的音频波形与语音数据存储库527的音频波形进行比较,或者通过将语音片段516的参数(诸如可以在阶段563处被表征)与语音数据存储库527的类似参数进行比较。基于此类比较,可以确定语音片段516的概率566。(在下面描述用于在语音数据存储库527中创建数据的方法)。
53.本领域技术人员将熟悉用于确定概率566的技术。例如,在一些示例中,可以在阶段564处使用最近邻内插来将语音片段516与n维空间中的相似语音片段进行比较(其中n维
可以包括例如上述的音频参数和/或音频波形数据);并且基于语音片段516与其在n维空间中的近邻之间的相对距离来确定概率值566。作为另一个示例,支持向量机可以在阶段564处用于基于语音数据存储库527确定将语音片段分类为输入语音片段或非输入语音片段的基础;并且用于根据该基础对语音片段516进行分类(例如,确定该语音片段是输入语音的概率值566)。用于分析语音片段516和/或语音数据存储库527、将语音片段516与语音数据存储库527进行比较,和/或基于语音数据存储库527对语音片段516进行分类以便确定概率566的其它合适的技术将是显而易见的;本公开不限于任何特定技术或技术组合。
54.在一些示例中,机器学习技术可以单独使用或与在此描述的其它技术组合使用来确定概率值566。例如,神经网络可以在语音数据存储库527上训练,并且应用于语音片段516来确定语音片段516的概率值566。作为另一个示例,可以使用遗传算法来基于语音数据存储库527确定函数,用于确定语音片段516的概率566。对本领域技术人员来说是熟悉的其它合适的机器学习技术将是显而易见的;本公开不限于任何特定技术或技术组合。
55.在一些示例中,语音片段516的概率值566可能受到相同语音信号的其它语音片段影响。例如,用户可能不太可能在短时间内提供输入,被非输入语音包围(反之亦然);相反,用户可能更有可能以大量连续的序列提供语音识别输入。也就是说,在所有其它因素相同的情况下,如果紧接在语音片段516之前或之后的片段也是输入语音片段,则语音片段516更有可能是输入语音片段;反之亦然。在此类示例中,概率技术(例如,贝叶斯网络、隐马尔可夫模型)可在阶段564处单独或与在此描述的其它技术组合使用,以确定概率566。各种概率技术可适用于该目的,并且本公开不限于任何特定技术或技术组合。
56.在一些示例中,语音数据存储库527可以通过记录各种语音源的语音信号的集合并且针对每个语音信号的每个部分识别该部分的语音目标来生成。例如,当用户的语音(和/或其它音频)被记录时,可以观察到用户与一组人进行交互,其中在同一房间中存在语音识别系统。对于所记录语音的每个区域,观察器可以识别该语音区域是从用户(而不是一些其它来源)定向作为语音识别系统的输入还是一些其它目标的输入。通过观察用户讲话的上下文,观察器可以清楚地看到该信息——通常,人类(与机器不同)很容易且直观地基于对用户的观察来确定用户是在对语音识别系统讲话,还是在对别的东西讲话。该过程可以对多个用户重复,并且在一些情况下对非人类讲话者(例如,宠物、电视扬声器、电器)重复,直到足够大和多样化的语音数据集(例如,与上述语音相关联的音频波形数据和/或参数)被生成。从该语音数据中,可以确定各个语音片段;这些语音片段可以与观察器对对应语音是否由用户定向到语音识别系统的确定相关联。
57.在图7a所示的示例中,如上所述,概率值566是基于由一个或多个麦克风检测到的用户自己的语音来确定的。因此,该系统相对于概率值566的预测值——也就是说,图7a的示例使得概率值566能够比其它方式更准确地确定的程度——受语音信号的音频特性之间的相关程度以及语音信号是否是输入语音的限制。相关程度越大,语音信号在确定信号的哪些部分是输入语音方面就越有用。虽然在语音音频和预期目标之间可能至少存在一些此类相关性,但是在语音的预期目标和与讲话者相关联的传感器数据(诸如传感器数据520)之间也可能存在相关性;因此,系统的整体预测值可以通过单独地或除了原始语音信号510之外并入传感器数据520来提高,诸如下面关于图7b和图7c所述。
58.图7b示出示例系统500的示例部分,其中传感器数据520被分类器568用来确定语
音片段516是输入语音的概率值572。在一些示例中,如上所述,传感器数据520可以对应于来自诸如上面关于图1中的示例可穿戴头部设备100所描述的传感器的数据。如上所述,此类可穿戴系统可以包括一个或多个传感器,该传感器可以提供关于用户和/或可穿戴系统的环境的输入。例如,可穿戴头部设备100可以包括相机(例如,图4中描述的相机444)以输出与环境对应的视觉信号;在一些示例中,相机可以是头戴式单元上的前向相机,示出当前在可穿戴系统的用户前面的内容。在一些示例中,可穿戴头部设备100可以包括lidar单元、雷达单元和/或声学传感器,其可以输出与用户环境的物理几何形状(例如,墙壁、物理对象)对应的信号。在一些示例中,可穿戴头部设备100可以包括gps单元,该gps单元可以指示与可穿戴系统的当前位置对应的地理坐标。在一些示例中,可穿戴头部设备100可以包括加速度计、陀螺仪;和/或惯性测量单元(imu)以指示可穿戴头部设备100的取向。在一些示例中,可穿戴头部设备100可以包括环境传感器,诸如温度或压力传感器。在一些示例中,可穿戴头部设备100可以包括生物度量传感器,诸如虹膜相机;指纹传感器;眼睛跟踪传感器(例如,眼电图(eog)传感器),用于测量用户的眼睛运动或眼睛注视;或用于测量用户的生命体征的传感器。在可穿戴头部设备100包括头戴式单元的示例中,此类取向可以对应于用户头部的取向(并且,推而广之,用户的嘴和用户讲话的定向)。其它合适的传感器可以被包括并且可以提供传感器数据520。此外,在一些示例中,可以适当地利用与可穿戴系统的传感器不同的传感器。例如,与语音识别系统的一个或多个麦克风相关联的传感器(例如,gps、imu)可用于结合可穿戴系统的传感器来确定用户与语音识别系统之间的相对距离和取向。
59.在图7b所示的示例中,阶段569可以根据一个或多个参数来参数化/表征语音片段516,诸如上面关于阶段563所描述的,关于传感器数据520的方面。这可以促进基于传感器数据520对语音片段进行分类。例如,阶段569可以执行传感器数据520的信号的傅立叶变换以便确定那些信号的频谱表示(例如,作为语音片段期间经过的时间的函数,描述用户位置或取向的信号(例如,来自gps、声学、雷达或imu传感器))。作为示例,语音片段516可以根据用户的眼睛运动(例如,来自eog传感器)、眼睛注视目标(例如,来自相机或eog传感器)、和/或视觉目标(例如,来自rgb相机或lidar单元)来表征。在一些示例中,传感器数据520可以与更宽范围的传感器数据(例如,在语音信号开始之前的几分钟时间段内捕获的传感器数据)进行比较以确定传感器数据520偏离更宽范围的传感器数据的程度。传感器数据520可以被参数化的其它方式对于本领域技术人员来说将是显而易见的,其中此类参数用于在阶段564处表征语音片段。如上面关于语音片段516所述,语音片段564可以用预加重、频谱分析、响度分析、dct/mfcc/lpc/mq分析、梅尔滤波器组滤波、降噪、信号带通滤波到最有用的语音范围(例如,85
‑
8000hz)、和动态范围压缩进行预处理。然后可以将剩余的信号参数化为一组时不变特征(例如讲话者识别/生物度量、性别识别、平均基频、平均响度)和时变特征向量(例如共振峰中心频率和带宽、基频、dct/mfcc/lpc/mq系数、音素识别、辅音识别、音高轮廓、响度轮廓)。
60.在示例的阶段570处,确定语音片段516对应于输入语音的概率值572。在一些方法中,可以使用传感器数据存储库528来确定概率值572,该传感器数据存储库528可以包括针对数据库中的语音元素识别那些元素是否对应于输入语音的数据库。在一些示例中,传感器数据存储库528可以包括表示与语音片段对应的传感器测量(例如,随时间推移的一序列的用户的头部位置、取向和/或眼睛注视)的数据集;并且可以针对每个数据集指示对应的
语音片段是否属于输入语音。在一些示例中,代替传感器数据集或除了传感器数据集之外,传感器数据存储库528可以包括与语音片段对应的参数。语音片段516可以与传感器数据存储库528进行比较——例如,通过将原始传感器数据520与传感器数据存储库528的对应信号进行比较,或者通过将语音片段516的参数(诸如可以在阶段569处被表征)与传感器数据存储库528的类似参数进行比较。基于此类比较,可以确定语音片段516的概率572。
61.本领域技术人员将熟悉用于确定概率572的技术。例如,上面关于确定概率值566所描述的技术——例如,最近邻内插、支持向量机、神经网络、遗传算法、概率技术,诸如贝叶斯网络或马尔可夫网络,或以上的任何组合——可以以类似的方式应用于传感器数据存储库528和传感器数据520。其它技术将是显而易见的,并且本公开不限于任何特定技术或技术组合。
62.在一些示例中,传感器数据存储库528不需要由分类器568直接访问以便在阶段570处对语音片段516进行分类。例如,阶段570可以应用一个或多个规则来基于传感器数据520确定语音片段516对应于输入语音的概率值572。例如,可以在阶段570处,基于传感器数据520(例如,来自位置和取向传感器的数据)确定用户正面对麦克风(或在说出语音片段516之前不久转身面对麦克风);并且然后可以根据该信息确定语音片段516很可能是输入语音。相反,可以在阶段570处确定用户背对语音处理引擎麦克风(或最近转向背对麦克风),并且语音片段516不太可能是输入语音。这是因为人类通常倾向于面对他们的语音所定向的对象,无论该对象是人还是设备。类似地,可以在阶段570处基于传感器数据520(例如,来自相机或eog传感器的数据)确定用户正在注视麦克风(或最近将他们的眼睛注视移向麦克风),以及语音片段516很可能是输入语音。相反,可以确定用户没有注视麦克风,并且语音片段不太可能是输入语音。作为另一个示例,如果传感器数据520(例如,相机数据)指示用户在说出语音片段516时正注视另一个人,则可以确定语音片段516不太可能是输入语音(即,相反,语音是被定向给用户正在注视的人)。可以使用本领域技术人员熟悉的机器学习技术,诸如神经网络或遗传算法,使用传感器数据存储库528作为训练集来确定用于确定如何基于传感器数据对概率值572进行分类的规则。
63.在一些示例中,传感器数据存储库528可以类似于如上所述的语音数据存储库527来生成。例如,传感器数据存储库528中的数据可以通过记录各种语音源的语音信号的集合来生成,伴随的传感器数据与语音信号同时生成;并且针对每个语音信号的每个部分识别该部分的语音目标。例如,当用户的语音被记录时,可以观察到用户与一群人进行交互,其中在同一个房间中存在语音识别系统。对于所记录语音的每个区域,观察器可以识别该语音区域是作为用户到语音识别系统还是一些其它目标的输入来定向。从该语音和/或传感器数据,可以确定各个语音片段;这些语音片段及其伴随的传感器数据可以与观察器对对应语音是否由用户定向到语音识别系统的确定相关联。
64.传感器数据520还可以在阶段570处用于识别麦克风输入是否属于特定用户。例如,如由一个或多个麦克风检测到的用户语音的幅度可以预期落在可预测的范围内,该可预测的范围作为麦克风和用户之间的距离的函数而下降,并且作为用户相对于麦克风的相对取向的函数而改变(例如,当用户背对麦克风时下降)。(在一些情况下,该范围可以针对特定用户通过实验确定)。如果传感器数据520(例如,gps数据、相机数据、声学数据、雷达数据)指示用户距麦克风特定距离,则可以确定该特定距离的该用户语音的预期幅度范围。超
出该幅度范围的麦克风输入可以被拒绝,因为它属于用户以外的来源。同样,可以基于用户的位置、取向或其它传感器数据520预测其它语音特性(例如,高频内容);并且可以拒绝与该传感器数据不一致的麦克风输入。类似地,在用户的位置和取向保持不变时,可以拒绝显著变化的麦克风输入(例如,音量或频率特性)(或反之亦然)。相反,基于传感器数据,与用户语音的预测特征一致的麦克风输入可以强化麦克风输入属于该用户。基于传感器数据,识别麦克风输入源的其它技术对于本领域技术人员来说将是显而易见的。
65.在如上所述的图7b中,基于由一个或多个麦克风检测到的用户自己的语音来确定概率值572。如图7a和概率值566中所示的示例,该系统相对于概率值572的预测值受语音信号的预期目标与与语音信号一起产生的伴随传感器数据之间的相关程度的限制。相关性越大,传感器数据在确定信号的哪些部分是输入语音方面就越有用。此类相关性反映了传感器数据(诸如来自可穿戴系统的传感器,如上所述的那些)可以提供许多与人类用来解释和情境化他人语音相同的肢体语言线索。例如,人类习惯于使用如下来确定讲话者的预期语音目标:讲话者的位置(例如讲话者的运动和距听众的距离)、取向(例如,讲话者面对的是谁);眼睛注视(例如,讲话者正在与谁进行目光接触);手势(例如,手部和手臂的运动、面部表情);等等。即使当讲话者对设备(诸如启用麦克风的语音识别系统)讲话时,这些肢体语言线索中的许多也适用。传感器数据可以对应于该肢体语言,诸如通过提供指示讲话者的位置、取向、眼图、运动等的数据。因此,使用诸如上述的传感器数据可以提供关于对应语音的预期目标的有价值的信息。
66.在一些示例中,可以通过利用语音数据(例如,如关于图7a所描述的)和与相同的语音信号对应的传感器数据(例如,如上面关于图7b所描述的)两者来改进系统的预测值。例如,在语音片段对应于语音提示(例如,用户提高他们的声音)和传感器提示(例如,用户快速转动他们的头部)两者的情况下,组合的两个提示可以提供语音片段旨在作为从用户到语音处理引擎的输入的强有力的预测证据。
67.图7c示出示例系统500的示例部分,其中语音信号(例如,语音信号510)的分析数据512和传感器数据520两者都被分类器574用来确定用户将语音片段516定向到语音处理引擎的概率值578。所示的示例系统的阶段可以如上面关于图7a和7b所述的那样进行。例如,阶段575可以基于从语音信号510和/或语音信号分析数据512确定的语音特性来参数化/表征语音片段516,诸如上面关于图7a的阶段563所述;以及阶段575还可以基于传感器数据520来参数化/表征语音片段516,诸如上面关于图7b的阶段569所述。在阶段576处,可以基于语音片段516的语音特性来确定其概率值578,诸如上面关于图7a的阶段564所述;并且进一步基于其对应的传感器数据来确定其概率值,诸如上面关于图7b的阶段570所述。该概率值确定可以利用语音和/或传感器数据,诸如在语音/传感器数据存储库529中。语音/传感器数据存储库529可以包括数据库,该数据库包括将语音数据与该语音的预期目标相关的信息,诸如上面关于图7a的语音数据存储库527所述;并且可以进一步包括将传感器数据与其对应语音的预期目标相关的信息,诸如上面关于图7b的传感器数据存储库528所述。此外,语音/传感器数据存储库529可以包括将语音数据和传感器数据的组合与预期语音目标相关的信息。这在语音数据和传感器数据本身都不能独立预测预期语音目标的情况下可能很有用,但两者的组合与预期语音目标密切相关并且具有更大的预测值。
68.生成概率模型
69.图8是示出根据一些实施例的示例系统500的一部分的流程图,示出了从原始语音信号510生成概率模型586的示例。在图8中,阶段560从原始语音信号510(其可对应于上面关于图6a
‑
6b描述的信号600)和传感器数据520生成概率模型586(其可对应于上面关于图6c描述的概率模型610)。在阶段560处,可以根据本领域技术人员熟悉的技术生成语音信号的统计数据512(例如,表示诸如上述的语音信号510的统计分析)。在阶段560的阶段514处,语音信号510可以被分段成单独的语音片段516,诸如上面关于图6a
‑
6d所述。对于每个语音片段516,可以应用一个或多个分类器(例如,上述562、568、574)来生成概率值,对应于该片段是输入语音的概率。在图8中所示的示例中,应用了三个分类器:第一分类器(562)基于语音片段516和语音数据512生成第一概率值566,诸如上面关于图7a所述;第二分类器(568)基于语音片段516和传感器数据520生成第二概率值572,诸如上面关于图7b所述;以及第三分类器(574)基于语音片段516、语音数据512和传感器数据520生成第三概率值578,诸如上面关于图7c所述。然而,在一些示例中,只需要使用一个分类器(例如,分类器574);并且在一些示例中,除了这里描述的三个之外的附加分类器可以用于生成附加的相应概率值。在一些情况下,不同的分类器可以应用不同的度量来确定相应的概率值。
70.在使用多个分类器来确定语音片段516的多个相应概率值的一些示例中——诸如图8中所示的示例,其中分类器562、568和574分别用于生成概率值566、572和578——可能有必要基于由它们相应的分类器生成的各个概率值来确定语音片段516的总体概率582。在此类示例中,比较逻辑580可以用于在各个概率值之间进行调解以确定总体概率582。在一些示例中,比较逻辑580可以将总体概率582计算为各个概率的平均值(例如,566、572、578)。在一些示例中,比较逻辑580可以将总体概率582计算为各个概率的加权平均值,例如通过输入数据(例如,语音数据512、传感器数据520)的保真度进行加权。本领域技术人员将熟悉比较逻辑580可以采用的其它合适的技术,并且本公开不限于任何此类技术或技术的组合。组合多个分类器输出的示例技术包括集成学习;贝叶斯最优分类器、装袋(自举汇聚法(bootstrap aggregating))、提升(boosting)技术(例如adaboost);桶模型;以及堆叠。
71.一旦确定了语音片段516的概率值,诸如如上所述,确定概率值的过程可以针对任何剩余的语音片段516重复(阶段584)。例如,上面关于图6a
‑
6d所述的语音信号600可以分为七个语音片段(601到607),诸如上述;如果该语音信号600作为输入510提供给图8中所示的系统,阶段562、568和574中的每一个可能应用于七个语音片段中的每一个,从而产生每个片段的概率值582。一旦确定了每个语音片段516的概率值,就可以使用该概率值来生成概率模型586。如上所述,概率模型586可以指示语音信号的每个语音片段的概率值。例如,在图6c中,概率模型610指示语音信号600的每个语音片段的概率值。生成语音信号的概率模型586可以包括将概率值表达为语音信号的经过时间的函数;采用此类模型,诸如图6c中所示的模型610,时间t可以作为输入应用到模型,并且模型将指示语音信号的与时间t对应的部分(例如,经过t秒之后的语音信号600的部分)作为输入定向给语音处理引擎的概率。然而,概率模型586的其它合适的实现方式将是显而易见的并且在本公开的范围内。
72.确定定向语音信号
73.图9示出示例系统500的一部分,系统500通过该部分从原始语音信号510和/或传感器数据520确定定向语音信号540,诸如通过使用上述概率模型586。如图9中所示,在阶段530处,系统500可以生成定向音频信号540,该定向音频信号540可以是到语音处理引擎的
输入语音信号,包括由用户定向到语音处理引擎的语音,同时排除不是由用户定向到语音处理引擎的语音。定向音频信号540可以对应于上面关于图6d描述的信号620。参考图9,生成定向音频信号540的阶段530的示例可以如下进行。在阶段560处,原始语音信号510和/或传感器数据520可用于针对原始语音信号510的一个或多个片段中的每一个确定该片段对应于由用户将其作为输入定向到语音处理引擎的语音的概率。上面关于图8描述了阶段560的示例实现方式。如上所述,目标确定阶段560的输出可以表示为概率模型586,该概率模型可以例如表达作为经过时间的函数的语音信号510的一部分是定向给语音处理引擎的用户语音的概率。例如,模型586可以是数学函数,其表达对于具有一个或多个片段的原始语音信号的每个时间t,与该时间t对应的原始语音信号的片段被定向给语音处理引擎的概率。如图9中的示例所示,阶段560还可以输出直通(passthrough)信号588,该直通信号588可以是与提供给目标确定阶段560的原始语音信号510对应的缓冲信号。
74.在图9中的示例的阶段590处,可以基于概率模型586对原始语音信号(例如,直通信号588)进行滤波,使得原始语音信号510的以足够高的概率对应于输入语音的片段可以包括在定向音频信号540中;并且相反地,原始语音信号510的不与输入语音对应的片段可以从定向音频信号540中排除。阶段590可以使用阈值概率值作为截止来确定什么构成了音频片段被包括在定向音频信号540中的足够高的概率。例如,如上所述,图6c示出与图6a和图6b中所示的原始语音信号600对应的概率模型610。如上面关于图6c所述,概率模型610针对语音信号600的语音片段601至607中的每一个指示语音片段对应于输入语音的概率。在图6c中,阈值618是为0.5的值;然而,可以视情况使用其它阈值。在阶段590处,具有满足或超过阈值618的对应概率值的语音片段(例如,语音片段601和606)可以被包括在定向音频波形540中;并且可以从定向音频波形540中排除对应概率值不满足阈值618的片段(例如,语音片段602、603、604、605和607)。结果将是图6d中所示的音频波形620,其中只有具有足够高概率的语音片段(“天气怎么样”和“明天”)被包括在波形620中,而其余的片段被排除。与向语音识别系统提供原始语音信号600相比,向语音识别系统提供音频波形620作为输入提高了准确性和计算效率,因为语音识别系统不需要将计算资源浪费在有生成错误结果的风险的不相关的语音(或其它音频)上。
75.训练分类器
76.图10示出根据本公开的一个或多个示例的用于捕获音频和非音频分类器训练数据的示例过程1000。过程1000可以应用于人类测试对象1012,与语音处理引擎交互(如用户可能)(例如,如包括在具有集成语音助手的设备中)。一个或多个麦克风和一个或多个传感器可以被配置为分别从测试对象1012捕获音频数据和非音频数据(例如,传感器数据)。在一些实施例中,非音频数据可以是非麦克风传感器数据,诸如例如惯性测量单元数据、视觉数据等。在该过程的步骤1010处,测试对象592的语音的原始音频数据可以经由一个或多个麦克风被捕获。类似地,在步骤1020处,可以经由一个或多个传感器捕获测试对象的非音频数据。在一些情况下,测试对象1012可以配备单个设备,诸如诸如上述的可穿戴头部设备,其可以包括一个或多个麦克风和一个或多个传感器。这些麦克风和传感器可以被配置为分别在步骤1010处捕获音频数据和在步骤1020处捕获非音频数据。步骤1010和1020可以同时执行。
77.在步骤1030处,可以将在步骤1010处捕获的音频分段并标记为输入语音或非输入
语音。这可以是自动化过程、手动过程、或其一些组合。例如,可以将在步骤1010处捕获的音频数据呈现给语音活动检测器(vad)或观察测试对象1012的人类“标记器”,并且标记器可以将音频数据手动分离为单独的短语或其部分。然后,标记器可以基于标记器对与语音识别引擎交互的测试对象1012的观察,手动将每个短语识别为输入语音或非输入语音。在一些情况下,标记器可以用各种元数据来注释每个短语(例如,每个短语的预期接收者,或每个短语的音频源)。标记器输入的其它元数据可以包括关于讲话者的方面(例如,讲话者的年龄、性别、和/或母语)。在一些示例中,标记器还可以分段和标记非语音音频(例如,背景噪声、和/或来自除讲话者之外的人的语音)。
78.类似地,在步骤1040处,在步骤1020处捕获的非音频数据也可以被分段和标记为要么被定向到语音处理引擎,要么不被定向。在一些示例中,人类标记器可以识别和/或隔离与上述测试对象1012说出的各个短语相关联的非音频数据(例如,传感器数据)。在一些情况下,标记器可以手动将非音频数据与其对应的音频数据相关联。在一些示例中,基于来自步骤1030的分段和分类短语的开始和结束时间,非音频数据可以自动与每个短语相关联。在一些示例中,非音频数据可以包括关于用户的头部姿势、注视、手势、相对于目标接收者短语的位置、或捕获的任何其它传感器数据的信息。
79.在步骤1050处,在步骤1010处捕获的音频、来自步骤1030的分段和标记的短语(例如,输入语音和非输入语音,包括背景噪声或非语音音频)、在步骤1020处捕获的非音频数据,和/或来自步骤1040的分段和标记的非音频数据可以存储在用于分类器训练的存储库中。例如,上述语音数据存储库527可以存储来自步骤1010的音频和/或来自步骤1030的短语;传感器数据存储库528可以存储来自步骤1020和/或步骤1040的非音频数据;并且语音/传感器数据存储库529可以存储以上任何内容。在一些示例中,在步骤1010处捕获的音频和/或来自步骤1030的分段和标记的短语与步骤1020捕获的非音频数据和/或来自步骤1040的分段和标记的非音频数据分开存储(例如,音频数据和非音频数据存储在单独的数据库中)。诸如上述,存储的音频数据和/或非音频数据可用于训练分类器。
80.在一些实施例中,音频和/或非音频特性可以从来自图10的步骤1050的一个或多个数据库中存储的输入语音、非输入语音、或非语音(例如,背景噪声)中提取。音频特性的示例可以包括音量(或信号幅度)的水平(或变化)、发音前的犹豫、话语内的犹豫、不流畅(例如,口吃、重复)、语速、句法、语法、词汇、短语长度(例如,持续时间、字数)、音高(例如,波动和轮廓)、和/或韵律。可以从非音频数据中提取的非音频特性的示例包括手势、注视(及其变化)、头部姿势(及其变化)、和物理和/或虚拟对象的位置(例如,距离和取向)(及其变化)。在一些示例中,每个语音和/或非语音片段(例如,与输入语音、非输入语音和/或非语音对应的每个音频和/或非音频片段)的傅立叶变换在图10的步骤1050中存储(例如,输入语音和非输入语音二者)并提供每个语音片段的频谱表示(例如,指示语音片段中各种频率参数的相对普遍性的频率函数)。本领域技术人员将熟悉提取音频和非音频数据的时间、频率和组合时频参数表示的其它方法。在一些示例中,提取的音频和/或非音频特性可以与对应的输入语音、非输入语音、和/或非语音一起存储。
81.在一些实施例中,通过图10的过程1000捕获的分段和注释的音频数据和非音频数据(例如,输入语音、非输入语音和/或具有对应元数据的非语音)可以被馈送到一个或多个分类器中用于训练目的,诸如上述。通过通过一个或多个分类器运行输入语音、非输入语音
和非语音的样本类,可以训练该一个或多个分类器以识别输入语音、非输入语音和/或非语音。在一些示例中,分段和注释的音频数据和非音频数据的多数子集(例如,60%)通过一个或多个分类器运行,并且少数子集或剩余的(例如,40%)分段和注释的音频数据和非音频数据用于评估一个或多个分类器。评估技术是本领域技术人员熟悉的。在一些实施例中,可以通过使用户能够确认或拒绝分类来进一步训练这些分类器。
82.如上所述,一个或多个分类器(例如,朴素贝叶斯分类器、支持向量机、k
‑
最近邻分类器、adaboost分类器、决策树、或人工神经网络)以区分输入语音和非输入语音。可以训练这些分类器以识别与输入语音和/或非输入语音相关联的音频特性和非音频特性以改进语音处理。根据本公开的训练分类器的方法可以包括捕获音频和/或非音频数据;提取输入语音和非输入语音的音频和/或非音频特性;训练一个或多个分类器,例如,使用机器学习技术,和/或,在一些示例中,更新分类器以改进输入语音识别(例如,通过确认和/或拒绝分类),如下所述。
83.图11示出可以用于生成用于分类器训练的音频数据和传感器数据的示例环境。该图示出环境591中包括语音目标(诸如包括语音处理引擎的语音辅助设备)的测试对象592(其可以对应于上述测试对象1012),以及一个或多个“干扰”源593a
‑
593h。干扰源被配置为向测试对象592呈现音频或视觉“干扰”刺激,测试对象592可以对此做出响应。可以检测与测试对象592对这些干扰刺激的响应相关联的音频数据和非音频数据(例如,传感器数据);该音频数据和非音频数据可以描述测试对象592(如由麦克风和传感器检测到的)对来自对应干扰源的位置的外部刺激的响应。该音频数据和非音频数据可相应地用于训练分类器(诸如上述)以区分输入语音与非输入语音(例如,定向给外部刺激的语音,由干扰源表示)。
84.可以将干扰源593a
‑
593h放置在距测试对象592不同距离和角度处,诸如图中所示。干扰源593a
‑
593h可以呈现为扬声器或视觉效果,或者呈现为可以产生声音和/或视觉效果的任何其它合适的对象(例如,人类、动物、电子设备等)。例如,干扰源593a可以表示智能家居设备(例如,具有集成“智能”语音助手的扬声器(“智能扬声器”)),并且干扰源593b可以表示人类;基于干扰源的明显身份,音频数据和非音频数据可以反映测试对象592的响应的差异。环境591可以表示受控环境(例如,隔音室,或干扰源593a
‑
593h以受控方式产生声音的房间)或不受控制的环境(例如,在测试对象592的家中或在公共场所)。例如,在受控环境中,测试对象592可以自由地与具有集成语音助手的可穿戴设备(例如,可穿戴头部设备100)交互(例如,几乎没有方向或脚本)以指示该设备执行特定操作(例如,打开应用,播放音乐,例如从互联网上查询信息,在日历中输入信息,从日历中读取信息,拨打电话,发送文本消息,控制智能温控器,控制智能锁定,控制一个或多个智能灯、或任何其它操作)。测试人员(由干扰源593a
‑
593h表示)可以与测试对象592进行对话。这提示测试对象592与可穿戴设备和测试人员交互。在一些示例中,干扰源593a
‑
593h可以是虚拟源;例如,在可穿戴系统上运行的软件应用可以从由干扰源593a
‑
593h表示的一个或多个虚拟声源产生声音。在一些示例中,干扰源593a
‑
593h可以经由测试对象592佩戴的可穿戴头部设备(例如,经由可穿戴头部设备的扬声器和/或显示器)呈现,音频数据和非音频数据可能由同一可穿戴设备的麦克风和传感器捕获。
85.根据本公开,诸如图11中所示的交互(例如,在环境591中说出的口语短语594a
‑
594d)可被检测并用于训练一个或多个分类器。例如,口语短语594a
‑
594d可以(例如,通过
可穿戴头戴设备100上的一个或多个麦克风150或通过声源594a上的一个或多个麦克风)作为连续音频流记录在音频文件中:“hey magic leap,打开...妈妈,我可以吗...不是现在,charlie...打开地图”。类似地,与一个或多个干扰源593a
‑
593h交互的测试对象592的非音频数据可以与音频数据同时被捕获。在一些示例中,来自测试对象592上的可穿戴系统(例如,图1中的可穿戴头部设备100和/或图2中的手持式控制器200)上的一个或多个传感器的数据可用于捕获关于如下的信息:测试对象592的头部位置(例如,如由可穿戴头部设备的位置和取向传感器检测到)、手势(例如,如由手持式控制器200的运动或由配置在可穿戴头部设备100上的一个或多个相机130a和130b检测到)、眼睛注视(例如,如由配置在可穿戴头部设备100上的一个或多个相机128a和102b检测到)、和/或测试对象592距一个或多个干扰源593a
‑
593h的距离(例如,如由一个或多个相机130a和130b和/或gps、声学、雷达或imu传感器所测量从可穿戴头部设备100到一个或多个干扰源593a
‑
593h)。
86.关于上述系统和方法,该系统和方法的元件可以由一个或多个计算机处理器(例如,cpu或dsp)适当地实现。本公开不限于用于实现这些元件的计算机硬件的任何特定配置,包括计算机处理器。在一些情况下,可以采用多个计算机系统来实现上述系统和方法。例如,可以采用第一计算机处理器(例如,耦合到一个或多个麦克风的可穿戴设备的处理器)来接收输入的麦克风信号,并执行那些信号的初始处理(例如,信号调节和/或分段,诸如以上所述)。然后可以采用第二(并且也许是更强大的计算能力的)处理器来执行更多的计算密集型处理,诸如确定与那些信号的语音片段关联的概率值。诸如云服务器的另一计算机设备可以托管(host)语音处理引擎,最终向其提供输入信号。其它合适的配置将是显而易见的,并且在本公开的范围内。
87.尽管已经参考附图充分描述了所公开的示例,但是应当注意,各种改变和修改对于本领域技术人员将变得显而易见。例如,一个或多个实现方式的元素可以被组合、删除、修改或补充以形成进一步的实现方式。此类的改变和修改应被理解为包括在由所附权利要求限定的所公开示例的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
精彩留言,会给你点赞!
专利分类正在加载中....