用于在参数化多声道操作与单独声道操作之间切换的多声道音频编码器、解码器、方法和计算机程序与流程
1.本技术涉及用于立体声、双声道或多于双声道应用的多声道音频编码和解码。更具体地,它涉及一般音频编码/解码、或语音编码/解码、或使用具有缩放因子的变换域编码/解码和/或基于线性预测系数的编码/解码的编码/解码。
背景技术:
2.为了传输以具有两个或更多个麦克风的麦克风布置(这些麦克风之间具有一定距离)捕获的立体声语音信号,在需要低比特率时,可以使用参数化立体声技术。[1]中描述了示例性参数化立体声技术。对于其中麦克风布置的周围存在两个或更多个讲话者并且在相同时间段内多于一个讲话者同时讲话的情况,参数化立体声系统可以在大多数情况下充分地执行。然而,存在一些情况,其中参数化模型可能无法重现立体声映像并且针对干扰讲话者场景传递了可理解的语音输出。例如,在两个或更多个讲话者中的每一个以不同的itd(声道间时间差)捕获、itd值较大(麦克风之间的距离较大)和/或讲话者正坐在麦克风布置轴周围的相反位置时,会发生这种情况。
[0003]
此外,在如[1]中描述的参数化立体声方案中,提取一些参数以重现空间立体声场景,并将立体声信号推导为被进一步编码的单声道降混。在干扰讲话者的情况下,可以使用诸如[2]中描述的celp之类的语音编码器对降混信号进行编码。然而,这样的编码方案是语音产生的源滤波器模型,被设计来表示单个讲话者语音。对于干扰讲话者,可能违反了核心编码模型,并且感知质量下降。
[0004]
本发明的目的是至少部分地克服传统方法的缺点。
技术实现要素:
[0005]
该目的通过根据权利要求1的多声道音频编码器、根据权利要求26的多声道音频解码器、根据权利要求26的经编码的多声道音频表示、根据权利要求30的多声道音频编码的方法、根据权利要求31的多声道音频解码的方法和根据权利要求32的计算机程序来解决。
[0006]
提供了一种多声道音频编码器。多声道音频编码器可以是立体声、或者双声道或多于双声道的音频编码器。音频编码器可以是一般音频编码器、或语音编码器、或在使用缩放因子的变换域编码与基于线性预测系数的编码之间进行切换的编码器。编码器被配置用于基于输入音频表示来提供经编码的音频表示。编码器被配置为根据输入音频表示的特性,在多个声道(例如输入音频表示的多个声道)的参数化多声道编码与多个声道(例如输入音频表示的多个声道)的单独编码之间进行切换。
[0007]
参数化多声道编码可以对组合了多个声道信号的组合信号进行编码,并且以参数形式对两个或更多个声道之间的关系进行编码。参数可以包括声道间时间差参数、和/或声道间电平差参数、和/或声道间相位参数和/或声道间相关参数。
[0008]
根据输入音频表示的特性,在参数化多声道编码与单独编码之间进行切换,有利地允许了使编码适于输入音频表示的特性。参数化多声道编码与单独编码之间的选择性切换,可以导致选择更适合对潜在的输入音频表示进行编码的编码,使得得到的经编码的音频表示可以具有关于例如感知性能的有利属性。
[0009]
换言之,本发明涉及以下二者之间的权衡:获得输入音频表示的特性然后根据特性进行动作(例如切换)所付出的努力,以及通过使用例如就性能标准而言可能对某个输入音频表示(或其一部分)有利的编码对输入音频表示进行编码的益处。
[0010]
根据实施例,多声道编码器可以被配置为确定输入音频表示是否满足参数化多声道编码下的模型的假设,并且根据该确定进行切换。假设可以包括:存在单个扬声器,例如,每个时频部分中存在单个显著声道间时间差/耳间时间差(itd)。例如,输入音频表示的特性可以提供两个或更多个讲话者干扰的指示,因此可能违反了参数化多声道编码下的模型关于单个扬声器的假设。
[0011]
根据实施例,多声道编码器可以被配置为:如果不满足参数化多声道编码下的模型的假设,则切换到单独编码。例如,对于一些输入音频表示,可能不满足参数化多声道编码下的模型关于扬声器数量和这些扬声器的itd/多个itd的假设。然而,可以满足单独编码下的模型的假设。因此,切换到单独编码可以导致有利的性能。
[0012]
根据实施例,多声道编码器可以被配置为确定输入音频表示是否与主导源(例如单个主导源)相对应。在这种情况下,其他源(例如所有其他源)可能较弱,例如至少相差预定强度差。编码器可以被配置为根据该确定进行切换。主导源存在或不存在可以提供关于参数化编码还是单独编码可能在性能方面有利的指示。
[0013]
根据实施例,多声道编码器可以被配置为确定在多个时频部分中是否存在单个主导源,和/或确定在给定时频部分中是否存在两个或更多个源,两个或更多个源的多声道编码参数至少相差预定偏差或相差超过预定偏差。多声道编码器可以被配置为根据该确定进行切换。多个时频部分可以备选地包括所有时频部分。两个或更多个源可以满足源的显著性条件,例如,是处于不同位置的相关和/或显著和/或值得注意的源。多声道编码参数可以是itd。确定单个源可以允许选择编码,该编码下的模型适合处理单个源,例如,参数化编码。确定一个或多个时频部分中的单个源可以允许针对满足编码下的模型(例如参数化模型)的假设的一个或多个部分,选择编码。确定给定时频部分中的两个或更多个源可以指示具有基于单个源的潜在模型的编码可能无法提供给定时频部分期望的性能,因此切换给定部分的编码可以导致有利的性能。确定多声道参数是否至少相差预定偏差(或超过预定偏差)可以允许确定两个或更多个源是否可能导致编码下的模型的假设被违反,因此可以是切换到不同编码的指示。
[0014]
在实施例中,多声道编码器可以被配置为确定参数化多声道编码下的模型的参数,并且根据模型的参数进行切换。例如,模型的参数可以是声道间时间差、耳间时间差itd。参数可以描述输入音频表示的两个或更多个声道之间的关系。确定参数化多声道编码下的模型的参数,可以允许对参数化模型针对输入音频表示的两个或更多个声道之间的给定关系传递期望性能的能力进行评估,并且执行切换,以便实现有利的性能。
[0015]
在实施例中,多声道编码器可以被配置为确定定义输入音频表示的声道之间的关系的特性是允许多声道编码参数的明确确定,还是指示多声道编码参数的两个或更多个不
同的可能值,并且根据该确定进行切换。例如,定义声道之间的关系的特性可以是广义互相关相位变换(gcc
‑
phat)在滞后参数上的演变,或者两个或多个声道之间的互相关函数在滞后参数上的演变。多声道编码参数可以是itd。两个或更多个不同的可能(例如有意义的)值可以至少相差预定值,并且可以与本底噪声区分开。特性可以包括关于它们的显著性至多相差一(预定的或信号自适应的)差异(例如值)的两个或更多个值(例如峰值、或满足显著性条件的值),或者特性仅包括满足显著性条件的单个值。通过使用广义互相关相位变换的演变或互相关函数的演变来确定输入音频表示的声道之间的关系,可以允许对声道之间的关系进行量化,以获得特性。确定多声道编码参数的两个或更多个不同值是否至少相差预定值且多声道编码参数的两个或更多个不同值是否能够与本底噪声区分开,允许有利地、可靠地确定多声道编码参数的明确确定是否可能,或者是否可以确定多声道编码参数的两个或更多个不同的有意义值。备选地或附加地,例如通过使用显著性条件来确定特性是否包括关于所确定的它们的显著性至多相差一差异的两个或更多个值,允许有利地、可靠地确定多声道编码参数的明确确定是否可能,或者是否可以确定多声道编码参数的两个或更多个不同的有意义值。
[0016]
在实施例中,多声道编码器可以被配置为确定定义输入音频表示的声道之间的关系的特性是否仅包括满足显著性条件的单个显著值,或者定义输入音频表示的声道之间的关系的特性是否包括满足显著性条件的两个或更多个(例如不同的)显著值,并且根据改确定例如在多个声道的参数化多声道编码与单独编码之间进行切换。定义声道之间的关系的特性可以是gcc
‑
phat在滞后参数上的演变,或者两个或多个声道之间的互相关函数在滞后参数上的演变。单个显著值可以涉及单个显著峰,其表示单个itd值。显著性条件可以包括两个或更多个局部峰或最大值之间的幅度关系、和/或两个局部峰或最大值之间的距离关系、和/或距本底噪声的距离。显著性条件可以是预定的或者是信号自适应的,例如,可以基于输入音频表示的特性信号自适应。两个或更多个显著值可以包括至少两个显著峰,其表示两个或更多个不同的itd值。可以在单个时频部分中确定显著性条件的满足。通过使用gcc
‑
phat或互相关函数的演变来确定输入音频表示的声道之间的关系,可以有利地允许对声道之间的关系进行量化,以获得特性。确定特性是否仅包括单个显著值或者特性是否包括两个或更多个值,可以有利地允许确定哪种编码(例如参数化多声道编码或单独编码)可能更适合给定的输入音频表示。显著性条件可以有利地允许使用一个或多个标准来评估值,例如时域(例如时间滞后)中或频域中的两个局部峰或最大值之间的幅度、两个局部峰或最大值之间的距离、和/或距本底噪声的距离,以便确定在确定特性是仅包括单个显著值还是两个或更多个显著值时,可以考虑演变上包括的哪些值。
[0017]
在实施例中,多声道编码器可以被配置为确定(例如经编码的音频表示的)先前帧的参数,并且根据先前帧的参数进行切换。先前帧的参数可以是sad标志。确定先前帧的参数,可以有利地用于例如确定先前帧是否包括活动信号,使得可以选择性地避免在信号部分的第一帧处进行切换。
[0018]
在实施例中,多声道编码器可以被配置为确定输入音频表示中是否存在干扰源,并且根据该确定进行切换。干扰源可以包括两个或更多个干扰声源、或者两个或更多个干扰扬声器、或者两个或更多个干扰讲话者。输入音频表示中的干扰源(或扬声器或讲话者)可以例如在时频部分中或者例如在重叠时频资源或部分中确定。确定是否存在干扰源,可
以有利地允许例如基于输入音频表示包括干扰源的确定来在参数化多声道编码与单独编码之间进行切换,这例如可以导致参数化多声道编码的性能下降,并且例如导致单独编码的有利性能。
[0019]
在实施例中,多声道编码器可以被配置为确定是否存在描述输入音频表示的两个或更多个声道之间的关系的两个或更多个值,并且根据该确定进行切换,该两个或更多个值满足显著性条件且与单个时频部分相关联。两个或更多个值可以包括相关值或显著值。确定是否存在满足显著性条件且与单个时频部分相关联的两个或更多个值,可以有利地允许确定输入音频表示例如可以导致例如参数化多声道编码的性能下降,并且例如导致单独编码的有利性能。
[0020]
在实施例中,多声道编码器可以被配置为确定输入音频表示的两个或更多个声道之间的互相关(例如gcc
‑
phat)中是否存在两个或更多个峰,并且根据该确定进行切换。互相关可以与给定时频部分有关。确定两个或更多个声道之间的互相关中是否存在两个或更多个峰,可以有利地允许定量地确定输入音频表示中是否可能存在干扰讲话者,这可能会降低例如参数化多声道编码的性能,并且在确定之后切换到例如单独编码。
[0021]
在实施例中,多声道编码器可以包括估计器,该估计器被配置为基于互相关来估计输入音频表示的两个或更多个声道之间的关系。估计器可以被配置为针对多个时频部分单独地估计关系。估计器可以是itd估计器。互相关可以是gcc
‑
phat、或经平滑的互相关。互相关可以在时域中执行,或者可以在频域中执行。多声道编码器还可以被配置为确定与不同的互相关滞后相关联的两个峰值(例如由估计器估计的相关值和/或显著值)之间的差是否大于一个值(例如预定值或信号自适应值),并且根据该确定进行切换。估计器(例如itd估计器)可以存在于编码器中,例如使用参数化多声道编码的编码器,因此使用估计器来确定与不同互相关滞后相关联的两个峰值之间的差是否大于阈值可能不会引入大量的额外复杂性。
[0022]
在实施例中,多声道编码器可以被配置为确定描述输入音频表示的两个或更多个声道之间的关系的两个或更多个值(例如相关值或显著值)之间的距离是否大于一个值(例如预定值或信号自适应值),并且根据该确定进行切换,该两个或更多个值满足显著性条件且与相同的时频部分相关联。可以例如在时域中相对于时间滞后或互相关滞后来确定距离。两个或更多个值可以是输入音频表示的两个或更多个声道之间的互相关的峰,并且可以由估计器(例如itd估计器)提供。峰值可以是满足显著性条件的值。确定满足显著性条件且与相同的时频部分相关联的两个或更多个值之间的距离是否大于阈值,允许有利地在以下二者之间区分:例如位于可能归因于单个源的小距离处的两个或更多个峰,以及位于可能归因于多于单个源的显著(例如较大)距离处的两个或更多个峰。
[0023]
在实施例中,多声道编码器可以被配置为基于互相关(例如在滞后参数上的)的演变来确定第一特性值,并且基于该确定进行切换。第一特性值可以是主峰或主要峰。互相关可以包括gcc
‑
phat。第一特性值可以满足显著性条件。峰值可以是演变中的最大(例如绝对)值。该确定可以包括对一个或多个帧(包括例如一个或多个先前帧)的演变进行评估。该确定还可以包括确定值是否满足稳定性条件。例如,如果对于多个先前帧(例如预定数量的先前帧或者信号自适应数量的先前帧),该值在范围(例如预定范围或信号自适应范围)内,则可以满足稳定性条件。此外,备选地或附加地,可以基于滞后机制来确定稳定性标准的满
足,该滞后机制具有针对多个帧(例如预定数量的先前帧或者信号自适应数量的先前帧)的值作为输入。确定第一特性值(例如主峰值),可以允许单独地或结合另外一个或多个值有利地评估所确定的值(在许多情况下,是互相关的演变中的最大值)是否引起在参数化多声道编码与单独编码之间切换编码。此外,可选地考虑显著性条件和/或稳定性条件,可以有利地允许确定例如如果检测到的值随时间不够稳定和/或不够远离例如本底噪声,则例如是否要选择性地避免切换。
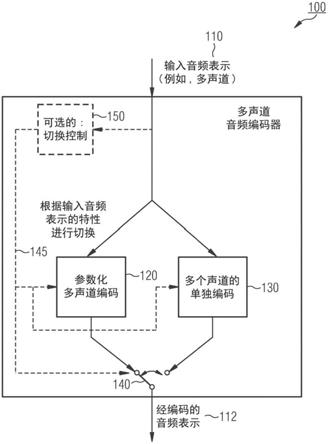
[0024]
在实施例中,多声道编码器可以被配置为基于互相关的演变来确定一个或多个从属特性值,并且基于该确定进行切换。一个或多个从属特性值可以是次峰或第二峰。可以基于互相关的演变的一部分来确定从属值。例如,该部分的每个元素到第一特性值的距离(例如在时域中,如相对于时间滞后)可以超过(例如预定的或信号自适应的)阈值。一个或多个从属特性值可以满足显著性条件。一个或多个从属特性值可以是演变的部分中的一个或多个最大(例如绝对)值。一个或多个从属特性值可以满足稳定性条件。确定一个或多个从属特性值,可以有利地允许评估所确定的值(例如第一特性值和/或一个或多个从属特性值)是否引起在参数化多声道编码与单独编码之间切换编码。此外,可选地对互相关的演变的部分中距第一特性值一定距离的一个或多个从属值进行评估,可以有利地允许将输入音频表示可靠地归因于单个源或多个源。备选地或附加地,多声道编码器可以被配置为基于互相关的演变来确定是否存在一个或多个从属特性值,并且根据该确定进行切换。换言之,可以例如基于例如模式识别算法等来确定仅存在一个或多个从属特性值。
[0025]
在实施例中,多声道编码器可以被配置为确定主峰与一个或多个从属峰满足显著性条件,并且根据该确定进行切换。例如,针对满足稳定性条件的多个帧,如果主峰与一个或多个从属峰之间的差(例如相对差)大与阈值(例如预定阈值,或信号自适应阈值),则满足显著性条件。例如,可以相对于峰的幅度、或者相对于峰的相位、或者相对于峰的时间滞后来确定峰之间的差异。备选地或附加地,多声道编码器可以被配置为确定互相关中是否存在满足相关性标准的一个或多个从属峰,并且根据该确定进行切换。例如,可以相对于主峰和/或相对于互相关的本底噪声来定义相关性标准。确定主峰与一个或多个从属峰之间的显著差异,有利地允许可靠地确定输入音频表示中存在多于一个源,并且例如基于该确定切换到单独编码。
[0026]
在实施例中,多声道编码器可以被配置为如果在给定帧之前的一个或多个帧中已经存在一个或多个对应的从属峰,则选择性地考虑输入音频表示的给定帧中的从属峰。例如,一个或多个对应的从属峰可以位于与所考虑的从属峰相同的自相关滞后处,或者在所考虑的从属峰的自相关滞后周围的自相关滞后的预定范围内。考虑一个或多个先前帧中的一个或多个对应的从属峰,以选择性地考虑给定帧中的从属峰,有利地允许确定某些空间和/或电平/相位/频率稳定性是否可以归因于切换编码之前的一个/多个源。稳定性可以包含一个或多个帧,因此可以与一个/多个源的环境有关,而不受帧长度的限制。
[0027]
在实施例中,多声道编码器可以被配置为确定描述输入音频表示的两个或更多个声道之间的关系的一个或多个特性值是否满足稳定性条件,并根据该确定进行切换。特性值可以是主峰和/或一个或多个从属峰。例如,如果该值在范围(例如预定范围或信号自适应范围)内或者大于阈值(例如预定阈值或信号自适应阈值),则可以对多个先前帧(例如预定数量的先前帧,或信号自适应数量的先前帧)满足稳定性条件。备选地或附加地,可以基
于滞后机制来确定稳定性条件的满足,该滞后机制具有针对多个(例如预定数量的先前帧,或者信号自适应数量的先前帧)帧(例如先前帧)的值作为输入。确定稳定性条件的满足,可以有利地允许避免在嘈杂的输入音频表示或其部分上(例如在嘈杂的帧上)进行切换。
[0028]
在实施例中,多声道编码器可以被配置为针对多个帧(例如预定数量的帧或信号自适应数量的帧),确定是否满足噪声条件,并且如果满足噪声条件,则选择性地避免切换。这些帧可以包括当前帧。例如,如果帧(或多个帧)的噪声特性(例如本底噪声)大于阈值(例如预定阈值,或信号自适应阈值),则可以满足噪声条件。确定噪声条件的满足,可以有利地允许避免在嘈杂的输入音频表示或其部分上(例如在嘈杂的帧上)进行切换。
[0029]
在实施例中,多声道编码器可以被配置为针对多个帧,确定是否满足特性值的显著性条件和/或稳定性条件,并且根据该确定进行切换。特性值可以是主峰和/或一个或多个从属峰。帧的数量可以是预定的或信号自适应的。这些帧可以包括一个或多个先前帧和/或当前帧。针对多个帧,确定显著性条件和/或稳定性条件的满足,可以有利地允许选择性地避免在不稳定的信号(例如,输入音频表示的不稳定和/或噪声部分)上进行切换。
[0030]
在实施例中,多声道编码器可以被配置为确定一个或多个从属峰的距离是否在预定范围内,并且根据该确定进行切换和/或选择性地避免切换。例如,一个或多个从属峰可以具有最大值(例如最大绝对值)并且可以被称为峰(2)。距离可以相对于时间滞后(例如绝对时间滞后或相对时间滞后)确定,和/或可以在时域或频域中确定。可以针对多个帧(例如,预定数量的帧或信号自适应数量的帧)确定距离。这些帧可以包括一个或多个先前帧和/或当前帧。确定一个或多个峰的距离是否在预定范围内并且基于此进行切换和/或选择性地避免切换,可以有利地允许选择性地避免在不稳定的信号(例如,输入音频表示的不稳定和/或噪声部分)上进行切换。
[0031]
在实施例中,多声道编码器可以被配置为在输入音频表示的非活动帧之后的第一帧处或在第一帧之后,选择性地避免切换。非活动帧可以包括噪声帧。备选地或附加地,多声道编码器可以被配置为确定帧中的给定标志是否已经相对于一个或多个先前帧改变,并且根据该确定选择性地避免切换。例如,该标志可以指示活动信号并且可以是sad标志。选择性地避免切换可以包括在标志取活动值的第一帧处或第一帧之后避免切换。因此,可以有利地选择性地避免在信号部分的第一帧处进行切换。
[0032]
在实施例中,多声道编码器可以被配置为响应于检测到输入音频表示的特性的改变大于阈值(例如预定阈值或信号自适应阈值),选择性地切换到单独编码。输入音频表示的特性可以是例如itd、或主峰、或峰(1)。响应于检测到特性中的改变大于阈值而选择性地切换到单独编码,可以有利地允许对突然改变采取动作而无需评估额外的特性/参数。
[0033]
在实施例中,多声道编码器可以被配置为确定描述声源的方向的参数是否已经(例如相对于先前帧/最后帧)改变了至少一个值(例如阈值),并且根据该确定进行切换。参数可以是互相关中(例如gcc
‑
phat中)的主峰在时频部分中的位置。切换可以包括切换到单独编码。确定描述声源的方向的参数是否已经改变了至少一个阈值,可以有利地允许如果声源例如相对于麦克风快速移动,或者附加的声源突然出现并且在时频部分中与现有声源发生干扰,则切换到某个编码,例如单独编码。
[0034]
此外,提供了一种多声道音频解码器。多声道音频解码器可以是立体声、或者双声道或多于双声道的音频解码器。音频解码器可以是一般音频解码器、或语音解码器、或者在
使用缩放因子的变换域解码与基于线性预测系数的解码之间切换的解码器。解码器被配置用于基于经编码的音频表示来提供经解码的音频表示。解码器被配置为在多个声道(例如输入音频表示的多个声道)的参数化多声道解码与多个声道(例如输入音频表示的声道)的单独解码之间进行切换。
[0035]
对于参数化多声道解码,可以对组合了多个声道信号的组合信号进行编码,并且可以以参数形式对两个或更多个声道之间的关系进行编码。参数可以包括声道间时间差参数、和/或声道间电平差参数、和/或声道间相位参数和/或声道间相关参数。
[0036]
在参数化多声道解码与单独解码之间进行切换,有利地允许解码(因此也使编码)适于输入音频表示的特性。在参数化多声道解码与单独解码之间选择性切换,可以允许选择更适合对潜在的输入音频表示进行编码的编码,使得得到的经编码的音频表示可以具有关于例如感知性能的有利属性。
[0037]
换言之,本发明涉及以下二者之间的权衡:获得输入音频表示的特性然后根据该特性进行动作(例如切换)所付出的努力,以及通过使用例如就性能标准而言可能对某个输入音频表示(或其一部分)有利的编码对输入音频表示进行编码(因此可用于解码)的益处。
[0038]
在实施例中,多声道音频解码器可以被配置为根据包括在经编码的音频表示中的信令,在参数化多声道解码与单独解码之间进行切换。相对于例如基于所获得的经编码的音频表示的上下文来推断潜在的编码方案的解码器,包括在经编码的音频表示中的信令可以简化解码器。
[0039]
此外,提供了经编码的多声道音频表示。多声道音频表示可以是立体声、或者双声道或多于双声道的音频表示。经编码的多声道音频表示包括(例如输入音频表示的)多个声道的经编码的参数化多声道表示和(例如输入音频表示的)多个声道的经编码的单独表示。
[0040]
参数化多声道编码可以对组合了多个声道信号的组合信号进行编码,并且以参数形式对两个或更多个声道之间的关系进行编码。参数可以包括声道间时间差参数、和/或声道间电平差参数、和/或声道间相位参数和/或声道间相关参数。
[0041]
换言之,本发明的多声道音频表示有利地允许选择性地使用更适合对潜在的输入音频表示进行编码的编码,使得得到的经编码的音频表示可以具有例如关于感知性能或任何其他标准的有利属性。
[0042]
在实施例中,经编码的多声道音频表示还可以包括(例如向解码器)指示在参数化多声道表示与单独表示之间进行切换的信令。该信令可以在例如对经编码的多声道音频表示进行解码的同时,指示进行切换。
[0043]
此外,提供了一种多声道音频编码的方法。多声道编码可以包括立体声、或者双声道或多于双声道的音频编码。音频编码可以由一般音频编码器、或语音编码器、或者在使用缩放因子的变换域编码与基于线性预测系数的编码之间切换的编码器来执行。编码基于输入音频表示来提供经编码的音频表示。该方法包括根据输入音频表示的特性,在多个声道(例如输入音频表示的多个声道)的参数化多声道编码与多个声道(例如输入音频表示的多个声道)的单独编码之间进行切换。
[0044]
参数化多声道编码可以对组合了多个声道信号的组合信号进行编码,并且以参数形式对两个或更多个声道之间的关系进行编码。参数可以包括声道间时间差参数、和/或声道间电平差参数、和/或声道间相位参数和/或声道间相关参数。
[0045]
根据输入音频表示的特性,在参数化多声道编码与单独编码之间进行切换,有利地允许了使编码适于输入音频表示的特性。在参数化多声道编码与单独编码之间选择性切换,可以导致选择更适合对潜在的输入音频表示进行编码的编码,使得得到的经编码的音频表示可以具有关于例如感知性能或任何其他性能标准的有利属性。
[0046]
此外,提供了一种多声道音频解码的方法。多声道音频解码可以包括立体声、或者双声道或多于双声道的音频解码。音频解码可以由一般音频解码器、或语音解码器、或在使用缩放因子的变换域解码与基于线性预测系数的解码之间进行切换的解码器来执行。解码基于经编码的音频表示来提供经解码的音频表示。该方法包括在多个声道(例如输入音频表示的多个声道)的参数化多声道解码与多个声道(例如输入音频表示的多个声道)的单独解码之间进行切换。
[0047]
对于参数化多声道解码,可以对组合了多个声道信号的组合信号进行编码,并且可以以参数形式对两个或更多个声道之间的关系进行编码。参数可以包括声道间时间差参数、和/或声道间电平差参数、和/或声道间相位参数和/或声道间相关参数。
[0048]
在参数化多声道解码与单独解码之间进行切换,有利地允许使解码(因此也使编码)适于输入音频表示的特性。参数化多声道解码与单独解码之间的选择性切换,可以允许选择更适合对潜在的输入音频表示进行编码的编码,使得得到的经编码的音频表示可以具有关于例如感知性能的有利属性。
[0049]
该方法可以可选地由本文公开中还关于装置的任何特征、功能和细节补充。该方法可以可选地由这些特征、功能和细节单独地和组合地补充。
[0050]
此外,提供了一种计算机程序,当该计算机程序在计算机上运行时用于执行上述方法之一。
[0051]
在下文中将参考附图讨论本发明的实施例。
附图说明
[0052]
随后将通过附图描述根据本发明的实施例,其中:
[0053]
图1示出了根据实施例的音频编码器的示意性框图;
[0054]
图2示出了根据实施例的音频解码器的示意性框图;
[0055]
图3示出了根据实施例的用于提供经编码的音频表示的方法的流程图;
[0056]
图4示出了根据实施例的用于提供经解码的音频表示的方法的流程图;
[0057]
图5示出了根据实施例的音频编码器的示意性框图;
[0058]
图6示出了音频信号及相关峰的表示;
[0059]
图7示出了相关函数的表示;以及
[0060]
图8示出了根据实施例的音频编码器的示意性框图。
具体实施方式
[0061]
1.根据图1的音频编码器
[0062]
图1示意性地示出了多声道音频编码器100。向多声道音频编码器100提供输入音频表示110作为输入。例如,输入音频表示110可以包括多个声道。多声道音频编码器100提供经编码的音频表示112作为输出。
[0063]
多声道音频编码器100包括:用于执行参数化多声道编码的功能块120和用于执行多个声道的单独编码的功能块130。将输入音频表示110提供给功能块120和130中的每一个。功能块120和130中的每一个的输出由切换元件140选择性地切换,使得由多声道音频编码器100提供经编码的音频表示112。
[0064]
多声道音频编码器100根据输入音频表示110的特性,通过使用切换控制信号145来控制切换元件140。控制信号145可以由用于执行切换控制150的可选功能块提供,切换控制150包括在多声道音频编码器100或任何其他合适的设备中。
[0065]
备选地或附加地,还可以将切换控制信号145提供给功能块120和130中的任一个,使得块120和130可以选择性地被禁用(例如关断)。例如,如果切换控制信号145指示用于执行多个声道130的单独编码的功能块要用于对输入音频表示110进行编码,则可以基于切换控制信号145来禁用用于执行参数化多声道编码的功能块120。
[0066]
备选地,如果切换控制信号145指示用于执行参数化多声道编码的功能块120要用于对输入音频表示110进行编码,则可以基于切换控制信号145来禁用用于执行多个声道的单独编码的功能块130。
[0067]
音频编码器100可以可选地由本文公开的任何特征、功能和细节单独地和组合地补充。
[0068]
2.根据图2的音频解码器
[0069]
图2示意性地示出了多声道音频解码器200。向多声道音频解码器200提供经编码的音频表示210作为输入。多声道音频解码器200提供经解码的音频表示212。例如,经解码的音频表示212可以包括多个声道。
[0070]
多声道解码器200包括:用于执行参数化多声道解码的功能块220和用于执行多个声道的单独解码的功能块230。将经编码的音频表示210提供给功能块220和230中的每一个。功能块220和230中的每一个的输出由切换元件240选择性地切换,使得由多声道音频解码器200提供经解码的音频表示212。
[0071]
切换元件240是控制器,例如,通过包括在经编码的音频表示210中的隐式或显式信令(未示出)。
[0072]
音频解码器200可以可选地由本文公开的任何特征、功能和细节单独地和组合地补充。
[0073]
3.根据图3的用于提供经编码的音频表示的方法
[0074]
图3示意性地示出了多声道音频编码的方法300。方法300包括步骤310,根据输入音频表示的特性,在多个声道的参数化多声道编码与多个声道的单独编码之间进行切换。此外,方法300包括步骤320,其中提供经编码的音频表示。
[0075]
请注意,方法300可以可选地执行结合任何装置(例如根据本方面的多声道编码器)公开的其他适合的动作。
[0076]
4.根据图4的用于提供经编码的音频表示的方法
[0077]
图4示意性地示出了多声道音频解码的方法400。方法400包括步骤410,在多个声道的参数化多声道解码与多个声道的单独解码之间进行切换。此外,方法400包括步骤420,其中提供经解码的音频表示。
[0078]
请注意,方法400可以可选地执行结合任何装置(例如根据本方面的多声道解码
器)公开的其他适合的动作。
[0079]
5.根据图5的音频编码器
[0080]
图5示意性地示出了多声道音频编码器500的实施例。向多声道音频编码器500提供两个输入音频表示信号,即音频表示信号510a和音频表示信号510b,音频表示信号510a与左声道相对应并由l指定,音频表示信号510b与右声道相对应并由r指定。
[0081]
输入音频表示信号510a和510b中的每一个分别在功能块520a和520b中进行可选的频域分析。功能块520a和520b中的每一个获得时域中的信号,即随时间的信号演变,并且提供关于信号相对于信号在频率范围上的给定频带中的幅度和/或相位的信息。功能块520a和520b分别提供输出信号522a和522b。备选地,功能块520a和520b可以不存在,并且信号522a可以等同于信号510a,信号522b可以等同于信号510b。
[0082]
可以将信号522a和522b提供给功能块530。块530对信号530执行互相关操作,并且提供指示在输入音频表示信号510a和510b中是否检测到干扰讲话者的检测信号532。更具体地,块530对信号522a和522b执行广义互相关相位变换,其也被称为gcc
‑
phat。gcc
‑
phat采用加权函数执行互相关操作,该加权函数对信号频谱密度进行归一化,以便获得相对于例如本底噪声有利地可区分的峰。gcc
‑
phat提供指示其输入信号的相似性度量的值作为参数,该输入信号具有这两个信号之间的时间滞后。因此,通过分析gcc
‑
phat操作的结果中的峰,块530确定声道间时间差(也被称为耳间时间差或itd),并且断定音频表示信号510a和510b中是否存在干扰讲话者。为了确定信号510a和510b中是否存在干扰讲话者,块530可以可选地使用结合本发明的其他实施例讨论的显著性条件、稳定性条件和/或噪声条件。信号532还可以包括对itd的估计。
[0083]
将信号532提供给控制器540。控制器540还获得信号522a和522b作为输入。控制器根据块530提供的检测信号,选择性地将信号522a、522b和itd的估计提供给参数化立体声编码器550(即用于参数化多声道编码的功能块)或者l
‑
r编码块560(即用于各个声道的编码的功能块)。更具体地,控制器540响应于获得信号510a和510b中不存在干扰讲话者的指示,将itd估计以及信号522a和522b提供给参数化立体声编码器550。响应于此,编码器550根据参数化多声道编码提供经编码的音频表示552,作为多声道音频编码器500的输出。备选地,响应于获得信号510a和510b中存在干扰讲话者的指示,控制器540将信号522a和522b提供给l
‑
r编码块560。响应于此,编码块560根据单独编码(例如左
‑
右、l
‑
r编码)来提供编码音频表示562。
[0084]
参数化立体声编码器550可以由[1]或[2]中描述的编码实现。应当理解,(例如mpeg
‑
4标准第3部分或he
‑
aac v2中的)定义参数化立体声编码的适当标准(或更多地,规则集)可以被编码器550使用。编码块560可以如[4]中描述的实现编码器。应当理解,定义多个声道的单独编码的适当标准(或规则集)可以被编码块560使用。编码块560还可以实现联合立体声编码、m/s立体声编码等。
[0085]
图6可视化出gcc
‑
phat功能单元的示例性操作,例如包括在上面结合图5讨论的块530中的gcc
‑
phat功能单元。更具体地,图6是gcc
‑
phat的值的二维呈现和在确定一个或多个峰值并基于其检测干扰讲话者方面对这些值的分析。图6所示的呈现的横坐标与以帧为单位表达的时间进展有关。为了以下说明的目的,通过识别示例性时间点,例如,t1、t2等来定义不同的时间范围,这些示例性时间点是各个范围的端点。图5中示出的呈现的纵坐标与
gcc
‑
phat的参数有关,即与提供给执行gcc
‑
phat的功能单元的两个信号之间的时间滞后(例如表示为itd)有关。图6中的二维平面上的颜色与针对给定帧和给定时间滞后的gcc
‑
phat值相对应。
[0086]
在t1与t2之间的示例性时间范围(即帧范围)中,示出了由gcc
‑
phat功能单元确定的多个主峰(在图6的图例中,每个主峰通过使用叉并被指定为“峰1”来表示)。根据本发明的一个或多个实施例,gcc
‑
phat功能单元可以确定主峰。在t1至t2的范围中,还示出了由gcc
‑
phat功能单元确定的多个从属峰(在图6的图例中,每个从属峰通过使用圆圈并被指定为“峰2”来表示)。根据本发明的一个或多个实施例,gcc
‑
phat功能单元可以确定从属峰。
[0087]
在t1至t2的范围中,gcc
‑
phat函数可以确定其中包括的多个主峰610满足稳定性条件,例如,鉴于峰610的位置(在时间滞后方面)(在连续帧的范围上)彼此相差至多某个阈值。此外,例如,尽管峰620的位置示出了t1至t2的范围中与t2相邻的部分中的至少一系列连续帧的一些散射,但是gcc
‑
phat函数可以确定包括在t1至t2范围中的多个从属峰615满足(与主峰610相同的或不同参数化的)稳定性条件。因此,鉴于峰610和615满足稳定性条件,gcc
‑
phat函数(或者例如包括在块530中的不同功能单元)可以确定存在干扰讲话者。
[0088]
在另一示例性范围t3至t4中,主峰620表现出与范围t1至t2中类似的图案。因此,可以由gcc
‑
phat功能确定满足稳定性条件。对于多个从属峰625,gcc
‑
phat功能可以确定:考虑到散射图案(即在针对连续帧的至少一些子范围的时间滞后方面显著不同的位置),峰625中的至少一些不满足稳定性条件。因此,鉴于仅满足两个所评估的稳定性条件中的一个,可以确定不存在干扰讲话者。
[0089]
对于示例性范围t5至t6以及t6至t7,鉴于主峰的稳定性和从属峰的散射,该确定可以与范围t3至t4中的确定相对应。对于示例性范围t8至t9,鉴于主峰和从属峰的稳定性,该确定可以与对范围t1至t2做出的确定相对应。
[0090]
图7示出了针对示例性单个帧(例如图6中所示的帧之一)的gcc
‑
phat的演变。在图7中,横坐标与时间滞后参数有关,并且与图6的纵坐标相对应。图7的纵坐标与互相关的值有关,例如与gcc
‑
phat函数提供的值有关。对于图7中的演变,主峰(被表示为峰1、710)和从属峰(被表示为峰2、720)由gcc
‑
phat函数确定。根据本发明的一个或多个实施例,鉴于主峰710和从属峰720各自的幅度(即互相关值)到本底噪声730的互相关值的距离大于(例如根据本发明的一个或多个实施例所定义的)阈值,可以确定主峰710和从属峰720二者满足噪声条件。
[0091]
此外,根据本发明的一个或多个实施例,鉴于峰710和从属峰720在时间滞后方面(即沿着横坐标)的距离大于(例如根据本发明的一个或多个实施例所定义的)阈值,(例如通过gcc
‑
phat函数或图5的块530)可以确定峰710和从属峰720可以满足显著性条件。
[0092]
另外,根据本发明的一个或多个实施例,鉴于峰710和从属峰720中的每个峰的互相关值大于阈值(例如根据本发明的一个或多个实施例所定义的阈值,具体地,例如大于下面选项1中针对峰(1)定义的值0.15),(例如通过gcc
‑
phat函数或图5的块530)可以确定峰710和从属峰720满足不同示出的显著性条件。
[0093]
此外,根据本发明的一个或多个实施例,鉴于峰710和720的互相关值的关系具有阈值(例如根据本发明的一个或多个实施例所定义的阈值,并且在下文通过使用具有常数c=0.8的示例来说明)以下的比例,(例如通过gcc
‑
phat函数或图5的块530)可以确定峰710
和从属峰720满足不同示出的显著性条件。
[0094]
请注意,本发明不限于使用gcc
‑
phat,而是任何能够提供互相关值的指示的技术,即任何合适的互相关技术,而且可以使用合适的模式识别技术,例如,涉及神经网络的模式识别技术。
[0095]
在下文中,描述了本发明的其他实施例。除了上面公开的方面之外,下面描述的实施例可以构成备选方案或者可以被考虑。下面描述的实施例涉及检测使用立体声麦克风设置捕获的干扰讲话者。下面描述的实施例是例如用于立体声语音编解码器的有用工具,该立体声语音编解码器可用于通信应用。
[0096]
参考以上描述,对于一些特定情况,为了更好的性能,两个立体声声道的离散编码可能是优选的。对于干扰讲话者的情况,有利的实施例可以在参数化模型(模式a)与离散模型(模式b)之间切换。另一方面涉及能够自动检测何时从模式a切换到模式b以及何时从模式b切换到模式a。以下考虑一般适用于第一种情况,即何时从模式a切换到模式b。
[0097]
当两个讲话者具有不同的itd(耳间时间差)并且两个itd之间的差较大(显著)时,示例性解决方案认为是重要情况(例如仅最关键的情况)。
[0098]
在一些实施例中,例如,如[3]中所述,可以假设编解码器已经具有itd估计器并且该itd估计器基于gcc
‑
phat(广义互相关相位变换)。这种估计器的基本原理是检测gcc
‑
phat中的峰,并且该峰与立体声信号的itd相对应。然而,当两个讲话者同时说话并且他们具有两个不同的itd时,在大多数情况下gcc
‑
phat中有两个峰。一些实施例检测gcc
‑
phat中是否仅存在一个峰(模式a)或者存在彼此远离的两个峰(模式b)。
[0099]
在一个实施例中,起点可以是模式a。可能使用交叉频谱的平滑版本或任何其他处理,可以计算立体声信号的gcc
‑
phat。可以估计gcc
‑
phat的主峰。在大多数情况下,这可以与gcc
‑
phat的绝对值的最大值相对应。备选地或附加地,可以应用一些滞后机制以获得更稳定的itd估计。可以选择gcc
‑
phat中离主峰足够远的部分。主峰与该部分的边界之间的距离可以在某个阈值以上。可以发现所选择的部分中的第二峰:例如,这可以是gcc
‑
phat的绝对值的最大值。如果第二峰的值在某个阈值以上,例如如果峰(2)>c*峰(1),其中峰(1)和峰(2)分别为第一峰和第二峰的值,并且c可以是常数(例如c=0.8)或信号自适应变量,则可以认为gcc
‑
phat包含两个显著峰并且可以发生到模式b的切换。否则,没有显著的第二峰,并且模式a仍在使用。
[0100]
此外,以下公开了实施例/选项:
[0101]
在选项1中,可以执行峰(1)在某个阈值(例如0.15)以上的检查,以避免在嘈杂帧上进行切换。
[0102]
在选项2中,可能需要在两个连续帧上验证上述两个实施例的两个条件。这可以避免在不稳定的信号上进行切换。
[0103]
在选项3中,可能需要两个连续帧的峰(2)彼此接近(例如它们的差可能在4以下)。这可以避免在不稳定的信号上进行切换。
[0104]
在选项4中,先前帧的sad标志必须为1(意味着它是活动信号)。这可以避免在信号部分的第一帧处进行切换。
[0105]
在选项5中,峰(1)可以从一帧到下一帧突然改变很大。在这种情况下,可能不需要检查第二峰,并且可以认为第二讲话者开始说话,并可以发生到模式b的切换。
[0106]
在一些实施例中,在gcc
‑
phat检测器确定是否存在上述一个或多个实施例中描述的干扰讲话者之后:如果未检测到干扰讲话者,则系统保持在它的默认参数化模式下,并且可以将所估计的itd值转发给例如[1]中所述的参数化处理。如果检测到干扰讲话者,则系统可以切换到l
‑
r编码方案,例如,使用evs编解码器对每个声道单独进行编码[4]。
[0107]
所描述的实施例实现了在某些条件下检测立体声语音信号的干扰语音片段,对于这些条件可以优选从参数化立体声编码系统切换到离散编码系统。以这种方式,可以改善编解码器的感知质量。对于参数化编码方案,在一些编解码器中可以存在声道间时间差(itd)检测器。因此,附加的复杂度开销或附加的延迟可能是可接受的。
[0108]
以下方面被进一步公开并且可以单独使用,或者可选地与本文公开的任何特征、功能和细节结合使用:
[0109]
方面一:一种立体声语音编码系统,其中一旦分类器/信号分析器确定满足从参数化编码模式(模式a)切换到离散l
‑
r编码模式(模式b)的条件,编解码器就可以从参数化编码模式(模式a)切换到离散l
‑
r编码模式(模式b)。
[0110]
方面2:一种立体声语音编码系统,其中一旦分类器/信号分析器检测到信号违反了参数化编码方案下的模型,编解码器就可以从参数化编码模式(模式a)切换到离散l
‑
r编码模式(模式b)。
[0111]
方面3:一种立体声语音编码系统,其中一旦系统检测到干扰讲话者,编解码器就从参数化编码模式(模式a)切换到离散l
‑
r编码模式(模式b)。
[0112]
方面4:对于立体声语音编码,使用phat广义互相关来检测第一最大绝对值(峰)和第二高的绝对值,并且根据适用于第二高的绝对值的条件来检测干扰语音片段。
[0113]
上面讨论的图6是上面说明的步骤/方面/实施例的可视化,其中绘制了信号的散点图,并且在图7中,示出了单个帧表示的缩放。
[0114]
6.根据图8的音频编码器
[0115]
图8示出了根据本发明的实施例的音频编码器800的示意性框图。
[0116]
音频编码器800接收输入音频表示810,其可以例如包括多个声道(例如声道l、r)。音频编码器800提供经编码的音频表示812,其可以例如表示输入音频表示的音频内容。
[0117]
音频编码器800可选地包括第一频域分析820,其接收例如输入音频表示的第一声道810a,并且基于输入音频表示的第一声道810a来提供该第一声道810a的频域表示822。音频编码器800可选地包括第二频域分析824,其接收例如输入音频表示的第二声道810b,并且基于输入音频表示的第二声道810b来提供该第二声道810b的频域表示826。例如,第一和第二频域分析可以例如使用短期傅立叶变换、mdct变换、滤波器组等提供输入音频表示的声道的频域表示或频谱域表示822、826。
[0118]
音频解码器800还包括参数化多声道编码830和多个声道的单独编码834。例如,多声道编码830可以接收输入音频表示的声道810a、810b,或者备选地,接收由频域分析820、824提供的频域表示822、826。然而,备选地,多声道编码可以接收输入音频表示的声道的不同表示。参数化多声道编码将两个或更多个声道输入的经编码的表示提供给参数化多声道表示832,其中,输入信号表示的声道例如可以使用组合信号(例如降混信号)并使用参数化辅助信息来表示,组合信号例如表示在输入信号表示的所有声道(或者至少在一些声道中,例如两个或更多个声道)中类似的信号分量,参数化辅助信息例如以参数值的形式描述输
入音频表示的两个或更多个声道之间的相似度和/或差。例如,参数化辅助信息可以包括声道间电平差值和/或声道间相位差值和/或声道间时间差值和/或声道间相关值和/或描述输入音频表示的声道之间的关系的任何其他参数。参数化辅助信息可以优选地在音频解码器侧可使用,以至少基于组合信号近似地重构输入音频表示的声道。例如,可以针对不同的时频范围或针对不同的频谱仓,单独地提供参数化辅助信息的参数值。例如,参数化多声道编码可以考虑“参数化立体声”概念,其例如用作mpeg4高效率高级音频编码(he
‑
aac)的扩展,并且可以提供输入音频表示的声道的对应表示。
[0119]
音频编码器800还包括多个声道的单独编码834,其中,例如,输入音频表示的不同声道例如使用频谱值的单独编码被单独编码。因此,单独编码834提供了与输入音频表示的不同声道相关联的单独编码的信息836,这例如允许在音频解码器侧对输入音频表示的声道进行单独解码。
[0120]
此外,音频编码器被配置为在参数化多声道编码830与单独编码834之间进行切换,使得可以由音频编码器的控制块来选择将参数化多声道表示832还是单独编码的信息包括在经编码的音频表示812中。关于这个问题,以下是无关紧要的:针对给定帧是否执行了参数化多声道编码830和单独编码834二者并且进行是将参数化多声道编码提供的编码表示832还是单独编码提供的编码表示836实际包括在经编码的音频表示812中的判定,或者针对给定帧,是否仅选择了参数化多声道编码或单独编码(其中,后一种解决方案通常更有效,但可能引入额外的延迟)。
[0121]
在下文中,将描述应如何将应选择参数化多声道编码830还是单独编码834(或者等效地,是参数化多声道表示832还是与输入音频表示的不同声道相关联的单独编码的信息836)包括在经编码的音频表示812中。
[0122]
为此目的,音频编码器800包括去相关信息确定840,其可以例如基于输入音频表示的声道的频域表示822、826来确定输入音频表示的两个或更多个声道之间的相关(例如互相关)。然而,应当注意,相关信息确定840可以例如基于输入音频表示的声道的时域表示来进行操作。此外,应当注意,相关信息确定可以针对输入音频表示的不同频率范围或时频部分提供单独的相关信息842。因此,不仅可以存在针对输入音频表示的后续帧的单独相关信息842,而且甚至可以存在针对单独频率范围或频率仓的单独相关信息842。此外,应当注意,相关信息842可以采用相关函数(例如每个时频部分)的表示的形式,该相关函数包括针对不同相关滞后值(也被指定为滞后或时间滞后)的不同相关值。
[0123]
例如,可以使用所谓的“gcc
‑
phat”技术来获得相关信息,该“gcc
‑
phat”技术已被发现带来特别有意义的结果。然而,也可以使用用于确定(互)相关信息的不同概念。
[0124]
音频解码器800还包括主峰确定850,其可以被配置为基于互相关信息来确定输入音频表示的两个或更多个声道之间的互相关的主峰(例如gcc_phat的绝对值的最大值),并且提供描述主峰的信息852(例如包括峰声道间时间差、或峰值、或峰强度)。例如,主峰确定850可以确定:对于哪个相关滞后(或者等效地对于哪个时间滞后,或者等效地对于哪个声道间时间差),互相关信息(或由互相关信息表示的互相关函数)包括(全局)最大值。可选地,主峰确定器也可以自己确定峰值(或峰强度)。然而,应当注意,主峰确定器不一定需要将互相关函数的最大值识别为主峰。相反,主峰确定器可以例如不考虑“零星”或“不稳定”的峰,并且将稳定的峰(例如在多个帧上稳定并且可以分类为“显著”的峰,例如大于阈值或
超过本底噪声至少预定值)识别为主峰(其中,例如可以使用滞后机制以具有更稳定的itd估计)。应当注意,可以使用本领域技术人员已知的用于识别相关函数的峰或主峰的不同算法。
[0125]
可选地,音频解码器还包括峰检查器852,其接收主峰信息852并检查主峰信息的可靠性。例如,峰检查器可以识别不可靠的主峰信息,该主峰信息包括随时间的(例如峰itd的和/或峰强度的)大波动,和/或该主峰信息指示过小的峰强度。例如,可以检查主峰的值是否在某个阈值以上,以避免在嘈杂帧上进行切换。可选地,还可以确定主峰是否在多个帧上(例如关于峰值)满足一个或多个条件。总之,可以通过默认信息抑制和/或替代、和/或以信号通知这种不可靠的主峰信息。
[0126]
此外,音频解码器可以包括第二峰确定860,其可以被配置为基于互相关信息842来确定输入音频表示的两个或更多个声道之间的互相关的第二峰,并且提供描述第二峰的信息862(例如包括峰声道间时间差、或峰值、或峰强度)。例如,第二峰可以是由互相关信息842描述的互相关函数的局部最大值,其包括主峰的峰值之后的第二大的峰值。另外,可以可选地需要将互相关信息的局部最大值识别为第二峰,该局部最大值满足关于互相关函数的主峰和/或关于本底噪声的一个或多个预定条件。例如,第二峰确定可以从主峰确定850接收关于主峰的信息,并且在识别第二峰时考虑该信息。例如,第二峰确定860可以检查第二峰候选(例如互相关函数的局部最大值)的距离是否包括距主峰的预定距离条件(例如在相关滞后或itd方面),其中,例如,可能需要第二峰包括距主峰的预定最小距离。备选地,第二峰的确定可以基于gcc
‑
phat的“远离主峰”的(所选择的)的部分来执行,例如,在itd方面与主峰间隔预定距离,其中,例如,可以将gcc
‑
phat的所选择的部分中gcc
‑
phat的绝对值的(绝对)最大值识别为第二峰。
[0127]
备选地或附加地,第二峰确定可以检查第二峰候选(例如在主峰与第二峰的峰值之间的关系方面)是否满足预定峰值条件。例如,可能需要第二峰的值在某个阈值以上,该阈值可以相对于主峰的值来定义。
[0128]
此外,第二峰确定可以检查第二峰候选的峰值是否足够在互相关信息的本底噪声以上。
[0129]
因此,第二峰确定860可以判定是否存在满足要求的第二峰将被识别为第二峰,并且提供(例如在相关滞后和/或itd和/或峰值和/或峰强度方面)描述第二峰的第二峰信息862。可选地,第二峰信息可以指示不存在满足条件的第二峰。
[0130]
可选地,音频解码器还可以包括第二峰显著性评估864,其可以例如接收第二峰信息862,并且确定第二峰信息862描述的第二峰是否显著和/或可靠。例如,第二峰显著性评估可以检查第二峰是否在多个帧上满足一个或多个条件。例如,第二峰显著性评估可以确定第二峰是否针对多个帧在某个阈值(例如相对于主峰)以上。备选地或附加地,第二峰显著性评估可以检查第二峰的相关滞后值或itd值在两个或更多个(后续)帧上是否足够接近。然而,也可以可选地检查第二峰的其他条件。
[0131]
应当注意,关于主峰检查854描述的功能可以可选地集成到主峰确定850中。此外,第二峰显著性评估的功能可以可选地被包括在第二峰确定860中。此外,应当注意,在确定描述主峰的信息856和描述第二峰的信息866时,可以不检查上述条件、检查上述条件中的一些或全部、或者检查另外的条件。
[0132]
此外,应当注意,描述主峰的信息856可以可选地仅指示是否已经找到有效的主峰。此外,描述第二峰的信息866可以可选地仅指示是否已经找到有效的第二峰。然而,信息856、866也可以可选地描述关于峰的细节,例如相关滞后和/或itd和/或峰值。
[0133]
音频编码器800可以可选地包括检测主峰的相关滞后或itd的改变的检测870,该改变大于阈值,并且提供描述是否存在这种改变的信息872。
[0134]
音频编码器800还包括切换判定880,其被配置为确定应将参数化多声道表示832还是与输入音频表示的不同声道相关联的单独编码信息836包括在经编码的音频表示中。
[0135]
在简单的情况下,切换判定880可以简单地检查显著的(或有效的)第二峰是否可用。如果仅存在单个峰(即主峰),则可以使用参数化多声道编码830(或者可以将参数化多声道表示832包括在经编码的音频表示中)。如果描述第二峰的信息866指示存在显著的(或有效的)第二峰,则切换判定可以决定使用单独编码834(或者将与输入音频表示的不同声道相关联的单独编码信息836包括到经编码的音频表示中)。
[0136]
然而,切换判定可以可选地使用一个或多个附加标准,来决定应将哪个信息包括在经编码的音频表示中。
[0137]
例如,切换判定可以可选地考虑是否存在大于(预定的或可变的)阈值的主峰的改变,其中,响应于发现主峰的改变大于阈值(例如可以通过信息872以信号通知),切换判定可以切换为使用单独编码834(或者将与输入音频表示的不同声道相关联的单独编码信息836包括到经编码的音频表示中)。
[0138]
作为另一示例,切换判定可以可选地考虑指示先前帧是否已经活动的指示(例如sad标志)。例如,如果切换判定发现先前帧已经不活动,则切换判定可以选择性地抑制切换。
[0139]
然而,切换判定还可以可选地对关于输入音频表示的其他信号特性的信息进行评估,并且基于该信息来决定应将哪些信息包括到经编码的音频表示中。
[0140]
总之,音频编码器800基于对输入音频表示的特性的分析(例如基于对互相关函数中存在多少“显著的”或“有效的”峰的确定)来(例如在逐帧基础上)判断是将参数化多声道表示832还是与输入音频表示的不同声道相关联的单独编码信息836包括到经编码的音频表示中。
[0141]
然而,应当注意,将功能具体分配到不同的功能块不是必要的。相反,如果需要,可以将一些或所有功能组合为单个功能块。
[0142]
此外,应当注意,音频编码器800可以可选地由本文公开的任何特征、功能和细节来单独地和组合地补充。
[0143]
此外,本文公开的任何特征、功能和细节可以可选地单独地和组合地引入到本文公开的任何实施例中。
[0144]
7.实现备选方案
[0145]
虽然已经在装置的上下文中描述了一些方面,但是将清楚的是,这些方面还表示对应方法的描述,其中块或设备与方法步骤或方法步骤的特征相对应。类似地,在方法步骤上下文中描述的方面也表示对相应块或项或者相应装置的特征的描述。可以由(或使用)硬件装置(诸如,微处理器、可编程计算机或电子电路)来执行一些或全部方法步骤。在一些实施例中,可以由这种装置来执行最重要方法步骤中的一个或多个方法步骤。
[0146]
新颖的编码音频信号可以存储在数字存储介质上,或者可以在诸如无线传输介质或有线传输介质(例如,互联网)等的传输介质上传输。
[0147]
取决于某些实现要求,可以在硬件中或在软件中实现本发明的实施例。可以使用其上存储有电子可读控制信号的数字存储介质(例如,软盘、dvd、蓝光、cd、rom、prom、eprom、eeprom或闪存)来执行实现,该电子可读控制信号与可编程计算机系统协作(或者能够与之协作)从而执行相应方法。因此,数字存储介质可以是计算机可读的。
[0148]
根据本发明的一些实施例包括具有电子可读控制信号的数据载体,其能够与可编程计算机系统协作以便执行本文所述的方法之一。
[0149]
通常,本发明的实施例可以实现为具有程序代码的计算机程序产品,程序代码可操作以在计算机程序产品在计算机上运行时执行方法之一。程序代码可以例如存储在机器可读载体上。
[0150]
其他实施例包括存储在机器可读载体上的计算机程序,该计算机程序用于执行本文所述的方法之一。
[0151]
换言之,本发明方法的实施例因此是具有程序代码的计算机程序,该程序代码用于在计算机程序在计算机上运行时执行本文所述的方法之一。
[0152]
因此,本发明方法的另一实施例是其上记录有计算机程序的数据载体(或者数字存储介质或计算机可读介质),该计算机程序用于执行本文所述的方法之一。数据载体、数字存储介质或记录介质通常是有形的和/或非瞬时性的。
[0153]
因此,本发明方法的另一实施例是表示计算机程序的数据流或信号序列,所述计算机程序用于执行本文所述的方法之一。数据流或信号序列可以例如被配置为经由数据通信连接(例如,经由互联网)传送。
[0154]
另一实施例包括处理装置,例如,计算机或可编程逻辑器件,所述处理装置被配置为或适于执行本文所述的方法之一。
[0155]
另一实施例包括其上安装有计算机程序的计算机,该计算机程序用于执行本文所述的方法之一。
[0156]
根据本发明的另一实施例包括被配置为向接收机(例如,以电子方式或以光学方式)传送计算机程序的装置或系统,该计算机程序用于执行本文所述的方法之一。接收机可以是例如计算机、移动设备、存储设备等。装置或系统可以例如包括用于向接收机传送计算机程序的文件服务器。
[0157]
在一些实施例中,可编程逻辑器件(例如,现场可编程门阵列)可以用于执行本文所述的方法的功能中的一些或全部。在一些实施例中,现场可编程门阵列可以与微处理器协作以执行本文所述的方法之一。通常,方法优选地由任意硬件装置来执行。
[0158]
本文描述的装置可以使用硬件装置、或者使用计算机、或者使用硬件装置和计算机的组合来实现。
[0159]
本文描述的装置或本文描述的装置的任何组件可以至少部分地以硬件和/或以软件实现。
[0160]
本文描述的方法可以使用硬件装置、或者使用计算机、或者使用硬件装置和计算机的组合来执行。
[0161]
本文描述的方法或本文描述的装置的任何组件可以至少部分地由硬件和/或由软
件执行。
[0162]
上述实施例对于本发明的原理仅是说明性的。应当理解的是,本文所述的布置和细节的修改和变形对于本领域其他技术人员将是显而易见的。因此,旨在仅由所附专利权利要求的范围来限制而不是由借助对本文的实施例的描述和解释所给出的具体细节来限制。
[0163]
参考文献
[0164]
[1]s.bayer,m.dietz,s.doehla,e.fotopoulou,g.fuchs,w.jaegers,g.markovic,m.multrus,e.ravelli及m.schnell,"apparatuses and methods for encoding or decoding a multi
‑
channel audio signal using frame control synchronization,"wo17125562,2017年7月27日。
[0165]
[2]m.schroeder及b.atal,"code
‑
excited linear prediction(celp):high
‑
quality speech at very low bit rates,"icassp'85.ieee international conference on acoustics,speech,and signal processing,坦帕,佛罗里达州,美国(tampa,fl,usa),1985。
[0166]
[3]s.bayer,m.dietz,s.doehla,e.fotopoulou,g.fuchs,w.jaegers,g.markovic,m.multrus,e.ravelli及m.schnell,"apparatus and method for encoding or decoding a multi
‑
channel signal using a broadband alignment parameter and a plurality of narrowband alignment parameters",wo17125558,2017年7月27日。
[0167]
[4]3gpp ts 26.445,codec for enhanced voice services(evs);detailed algorithmic description。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1