用于文本到语音合成的用户接口适应的方法和系统与流程
用于文本到语音合成的用户接口适应的方法和系统
背景技术:
1.除非本文另有说明,否则此部分中描述的材料不是本技术中权利要求的现有技术,并且不因为包含在此部分中而被承认为是现有技术。
2.自动语音识别(asr)技术的目标是将特定的话语或语音样本映射到该话语的准确文本表示或其他符号表示。例如,对话语“我的狗有跳蚤”执行的asr将理想地映射到文本串“我的狗有跳蚤”,而不是无意义的文本串“我的狗有冰冻”,或者合理但不准确的文本串“我的沼泽有树”。
3.语音合成技术的目标是将书面语言转换为能够以音频格式输出的语音,例如直接地用于音频输出或者存储为适合于音频输出的音频文件。这种语音合成可以由文本到语音(tts)系统来执行。书面语言可以采取文本或符号语言表示的形式。语音可以由语音合成器生成为波形,该语音合成器产生人工的人类语音。听起来自然的人类语音也可以是语音合成系统的目标。
4.包括计算机、网络服务器、电话和个人数字助理(pda)的各种技术可以被用来实现asr系统和/或语音合成系统,或者这样的系统的一个或多个组件。通信网络可以转而在这样的设备中的一些或所有之间提供通信路径和链路,支持语音合成系统能力和可以利用asr和/或语音合成系统能力的服务。
技术实现要素:
5.在一个方面,本文给出的示例实施例提供了一种方法,包括:在采用文本到语音(tts)系统合成来自文本片段的语音并且同时在显示设备中显示该文本片段时,接收指示跟踪操作相对于显示设备中显示的文本片段的位置和运动的输入;使用所指示的跟踪操作的位置来标识在接收到跟踪操作输入的时间附近经历tts合成处理的文本片段的一部分以及tts系统已经以标准(canonical)语速为其合成了先前合成的语音的文本片段的语境部分两者,其中该语境部分包括紧接在所标识的部分之前和紧接在所标识的部分之后的文本;使用所指示的跟踪操作的运动来将所标识的部分的tts合成的语速从标准语速调整到基于所指示的运动确定的适应语速;通过对所标识的部分的tts合成处理应用该语境部分的先前合成的语音的调整的语速和合成语音特性,来适应所标识的部分的合成语音的语音特性;以及以适应的语速和适应的语音特性输出所标识的部分的合成语音。在一些实施例中,可以可选地是,在接收到跟踪操作输入附近的时间或者在所指示的位置附近的位置处,对经历tts合成处理的文本部分进行标识。跟踪操作可以指示或包括(用户)输入或潜在输入的位置的指示符的改变,并且可以与视觉指示符相关联(尽管不是必须地)。例如,当用户输入是触摸输入(或触笔输入)时,跟踪操作可以指示触摸输入的改变;触摸输入可以不一定渲染在显示设备上,但是仍然可以存在视觉指示符(以手指或触笔的形式)来指示用于跟踪操作的用户输入的位置。当用户经由物理输入设备(诸如鼠标或键盘)输入时,指示符可以是可移动的可视指示符,诸如渲染的指针。在以下描述中,与跟踪操作相关联的指示符可以由术语虚拟指向指示符和/或“光标”来指代,该术语包含用户输入或潜在用户输入的位
置的视觉(渲染的和物理的)和其他非视觉指示符两者;跟踪操作的位置和运动然后可以作为虚拟指向指示符输入或“光标输入”的一部分而被接收,用于在此描述的方法中。例如,当用户移动他们的手指(沿着触摸屏或者在基于手势的界面(interface)前面)或者移动鼠标时,指示符相对于显示在显示设备上的文本片段的位置和运动可以被提供作为指示跟踪操作的输入(诸如虚拟指向指示符或者光标输入)。
6.在另一方面,本文呈现的示例实施例提供了一种包括文本到语音(tts)系统的系统,该系统包括:一个或多个处理器;存储器;以及在存储器中所存储的机器可读指令,这些指令在由一个或多个处理器执行时使得系统执行操作,该操作包括:在采用tts系统合成来自文本片段的语音并且同时地在显示设备中显示该文本片段时,接收指示跟踪操作相对于显示设备中显示的文本片段的位置和运动的输入;使用所指示的跟踪操作的位置来标识在接收到跟踪操作输入的时间附近经历tts合成处理的文本片段的一部分以及tts系统已经以标准语速为其合成了先前合成的语音的文本片段的语境部分两者,其中该语境部分包括紧接在所标识的部分之前和紧接在所标识的部分之后的文本;使用所指示的跟踪操作的运动来将所标识的部分的tts合成的语速从标准语速调整到基于所指示的运动确定的适应语速;通过对所标识的部分的tts合成处理应用该语境部分的先前合成的语音的适应的语速和合成语音特性,来适应所标识的部分的合成语音的语音特性;以及以适应的语速和适应的语音特性输出所标识的部分的合成语音。在一些实施例中,可以可选地是,在接收到跟踪操作输入附近的时间或者在所指示的位置附近的位置处,对经历tts合成处理的文本部分进行标识。该系统可以被配置为执行本文描述或要求保护的任何方法。
7.在又一方面,本文呈现的示例实施例提供了一种包括计算机可读存储介质的制品,该计算机可读存储介质上存储有程序指令,当由包括文本到语音(tts)系统的系统的一个或多个处理器执行时,该程序指令使该系统执行操作,该操作包括:在采用tts系统合成来自文本片段的语音并且同时地在显示设备中显示该文本片段时,接收指示跟踪操作相对于显示设备中显示的文本片段的位置和运动的输入;使用所指示的跟踪操作的位置来标识在接收到跟踪操作输入的时间附近经历tts合成处理的文本片段的一部分以及tts系统已经以标准语速为其合成了先前合成的语音的文本片段的语境部分两者,其中该语境部分包括紧接在所标识的部分之前和紧接在所标识的部分之后的文本;使用所指示的跟踪操作的运动来将所标识的部分的tts合成的语速从标准语速调整到基于所指示的运动确定的适应语速;通过对所标识的部分的tts合成处理应用该语境部分的先前合成的语音的适应的语速和合成语音特征,来使所标识的部分的合成语音的语音特性适应;以及以适应语速和适应语音特性输出所标识的部分的合成语音。在一些实施例中,可选地,在接近接收到跟踪操作输入时的时间或者在接近所指示的位置的位置,识别文本的经历tts合成处理的部分。在一些实施例中,可以可选地是,在接收到跟踪操作输入附近的时间或者在所指示的位置附近的位置处,对经历tts合成处理的文本部分进行标识。还可以提供计算机程序,该计算机程序包括指令,当由一个或多个处理器执行时,该指令使得一个或多个处理器执行本文描述或要求保护的任何方法。
8.通过适当参考附图来阅读以下详细描述,这些以及其他方面、优点和替代方案对于本领域普通技术人员来说将变得明显。此外,应当理解,本文提供的此概述和其他描述以及附图旨在仅通过示例的方式来说明实施例,并且同样地,许多变化是可能的。例如,结构
元素和过程步骤可以被重新排列、组合、分布、消除或以其他方式改变,而同时保持在所要求保护的实施例的范围内。
附图说明
9.图1描绘了根据示例实施例的示例文本到语音系统的简化框图。
10.图2是根据示例实施例的示例网络和计算架构的框图。
11.图3a是根据示例实施例的服务器设备的框图。
12.图3b描绘了根据示例实施例的基于云的服务器系统。
13.图4描绘了根据示例实施例的客户端设备的框图。
14.图5描绘了根据示例实施例的文本到语音合成的示例处理流程。
15.图6示出了根据示例性实施例的语音的示例性波形和音高分布(profile)。
16.图7是根据示例实施例的具有用户接口适应的示例文本到语音应用的概念性图示。
17.图8描绘了根据示例实施例的具有用户接口适应的文本到语音合成的示例处理流程。
18.图9是示出根据示例实施例的示例方法的流程图。
具体实施方式
19.1.概述
20.语音合成系统可以是基于处理器的系统,其被配置为将书面语言转换为人工产生的语音或口头语音。书面语言可以是书面文本,诸如一个或多个书面句子或文本串。书面语言也可以采取其他符号表示的形式,诸如语音合成标记语言,其可以包括指示说话者情绪、说话者性别、说话者身份以及说话风格的信息。书面文本的来源可以从诸如便携式计算设备(例如,pda、智能电话等)的计算设备的键盘或小键盘输入,或者可以来自在一种或另一种形式的计算机可读存储介质上所存储的文件。人工产生的语音可以作为来自信号生成设备或模块(例如,语音合成器设备)的波形而生成,并且由音频播放设备输出和/或格式化并且记录为有形记录介质上的音频文件。这种系统也可以称为“文本到语音”(tts)系统,尽管书面形式不一定仅限于文本。
21.语音合成系统可以通过接收输入文本(或其他形式的书面语言)并且将该书面文本翻译成与该文本的口头呈现听起来或应该听起来如何的符号表示相对应的“语音学转写”来进行操作。语音学转写然后可以被映射到语音特征,该语音特征参数化语音学转写的声学渲染,并且其然后用作对于信号生成模块设备或元件的输入数据,该信号生成模块设备或元件可以产生适合于由音频输出设备播放的音频波形。例如,播放可能听起来像是说出输入文本串的单词(或声音)的人类语音(voice)。在语音合成的情况下,合成语音的声音(例如,对人耳而言)越自然,通常系统的语音质量排名越好。在某些情况下,更自然的声音还可以减少计算资源,因为可以减少随后与用户澄清输出含义的交流。音频波形也可以被生成为音频文件,该音频文件可以被存储或记录在适合于随后播放的存储介质上。
22.在操作中,tts系统可以用于将信息从装置(例如,基于处理器的设备或系统)传达到用户,诸如消息、提示、对于问题的答案、指令、新闻、电子邮件和语音到语音翻译等信息。
语音信号本身可以携带各种形式或类型的信息,包括语言内容、情感状态(例如,情绪和/或心情)、身体状态(例如,身体声音特征)和说话者身份等。
23.在示例实施例中,语音合成可以使用具有文本的语音和语言内容的符号描述的语音的参数表示。可以使用主要由大量语音样本和相应的文本串(或其他符号渲染)构成的数据来训练tts系统。出于实际原因,通常记录语音样本,尽管原则上不需要。通过构造,相对应的文本串是书面存储格式,或者通常适应书面存储格式。因此,记录的语音样本及其相对应的文本串可以构成tts系统的训练数据。
24.tts的一个示例基于隐马尔可夫模型(hmm)。在这种方法中,hmm用于对下述统计概率进行建模:该统计概率将输入文本串的语音学转写与要合成的相对应的语音的参数表示相关联。作为另一示例,tts可以基于某种形式的机器学习来生成语音的参数表示以合成语音。例如,通过训练人工神经网络(ann)将已知的语音学转写与语音声音的已知参数表示相关联来使用ann生成语音参数。基于hmm的语音合成和基于ann的语音合成两者可以有助于使用一种或另一种形式的统计适应来改变或调整合成语音的特征。其他形式的tts系统也是可能的。
25.感兴趣的tts和音频应用的一个领域与人类学习有关。具体地,已知的是,一些人倾向于“视觉学习者”,而另一些人更喜欢听觉模式来吸收信息。有声读物的出现和流行是服务于那些喜欢听而不是读的人的市场的示例。tts也可以用作顺应读写能力降低的用户或者患有诸如阅读障碍等残疾的用户。
26.发明人已经认识到,通过tts将文本转换为音频会带来许多与可用性相关的挑战,尤其是在人类学习背景中应用时。两个具体的可用性问题涉及由于人类生理因素以及线性度引起的注意力降低。简而言之,通过tts以听觉方式消费文本内容的一些用户报告说,与阅读相比,注意力降低了。这似乎是因为听可能被认为是比阅读更被动的参与形式,一旦音频发生器启动,就需要减少用户与音频发生器的交互。传统的基于tts的音频系统没有通过设计将交互性结合到tts处理和合成中。相反,例如,传统的系统可能提供简单的开始-停止-音量-滑动(scrub)控制。
27.线性度描述了由传统的tts音频强加的通常直接的“通读”用户接口(ui)。传统的tts系统提供有限的能力来执行等效的“重读”。虽然用户可能能够在音频作品中来回滑动(或跳转)(例如,在触摸屏系统上左滑以后退10秒),但是传统的tts系统中的控制粒度通常与在阅读时其具有的细粒度、自然体验不匹配;在阅读时,他们可能重读并且重新解析句子的复杂部分,或者后退一个短语,或者重读句子以帮助更好地理解它。
28.就传统的tts系统具有的提供对tts的ui控制的任何程度的能力而言,其他可感知的音频特征当中、在音调和步调(pace)方面,这些能力通常远远不能生成听起来自然的语音。例如,人类记录的文本到语音提供的记录通常不可以进行步调调整而没有音高失真(例如,对于较慢的步调加深语音音高,反之亦然)。并且传统的tts合成系统类似地缺少与从文本合成语音的语音合成算法相集成的ui控制,这通常导致听起来不自然的语音。
29.为了解决这些和其他挑战,发明人已经设计了用于适应语音合成的技术,这些技术克服了上述问题以及其他问题,并且从而为通过文本到语音接口消费文本的用户提供了改进的阅读和学习理解。因此,本文描述的示例实施例提供了采用诸如机器学习的技术来向用户传递合成语音的有效ui适应和增强的音频加文本体验的系统和方法。
30.根据示例实施例,跟踪显示设备中显示的文本的诸如光标或其他视觉渲染的指针的指示符的位置和运动可以用作对于从显示的文本合成语音的tts系统的输入。在一些实施例中,指示符或跟踪指示符可以不一定具有视觉渲染的图标或图形,尽管它仍然跟踪显示的文本。更具体地,当所显示的文本的部分或片段正被tts系统处理并且合成为语音时,“跟踪操作”可以向tts系统提供指示符相对于该部分或片段的位置和运动作为输入。跟踪操作可以是用户跟踪操作。跟踪操作可以采取各种形式。非限制性示例包括:在计算机鼠标设备或其他交互式跟踪设备的交互式控制下、图形地渲染的光标或指针;用户的手指,在触摸屏设备上移动时提供触觉输入;虚拟指针,以预编程的步调沿着预编程的路径跨过或穿过所显示的文本;以及指示从眼睛跟踪装置(诸如交互式虚拟和/或增强现实眼镜(或其他交互式头戴式显示设备)上的眼睛跟踪相机)导出的用户的眼睛注视方向和运动在显示文本上的虚拟投影的输入。输入位置和运动可以以适应合成处理的反馈的方式集成到语音合成处理中,以便使得生成既符合跟踪信息又忠实于被渲染为合成语音的被跟踪文本的语音和韵律语境的合成语音。因此,生成或合成的语音可以映射到用户的输入,而改进用户的预期输出和实际输出之间的匹配,并且防止用户的失调。因此,如本文所描述地生成的音频输出可以以改进用户生理反应的方式提供给用户。
31.2.示例文本到语音系统
32.tts合成系统(或者更一般地,语音合成系统)可以通过下述来操作:接收输入文本、将文本处理为文本串的语音学和语言内容的符号表示、生成与符号表示相对应的语音特征序列、以及将语音特征作为输入提供给语音合成器以便产生输入文本的口头呈现。文本的语音学和语言内容的符号表示可以采取标签序列的形式,每个标签标识语音学语音单元(诸如音素),并且进一步标识或编码语言和/或句法语境、时间参数以及用于指定如何将符号表示的声音渲染为给定语言的有意义的语音的其他信息。其他语音特征可以包括音高、频率、语速和语调(例如陈述音调、疑问音调等)。这些特征中的至少一些有时被称为“韵律”。
33.根据示例实施例,语音学转写的语音学语音单元可以是音素。音素可以被认为是给定语言的语音的最小声学片段,其包含与给定语言的其他语音片段的有意义的对比。因此,单词通常包括一个或多个音素。为了简单起见,音素可以被认为是字母的发音,尽管这不是一个完美的类比,因为一些音素可能代表多个字母。在书面形式中,音素通常被表示为某种类型的分隔符内表示代表音素的文本的一个或多个字母或符号。例如,单词“cat”的美式英语发音的音素拼写是/k//ae//t/,并且由音素/k/、/ae/和/t/构成。另一示例是单词“dog”的音素拼写是/d//aw//g/,并且由音素/d/、/aw/和/g/构成。存在不同的音素字母,并且其他音素表示也是可能的。美式英语常用的音素字母包含大约40个不同的音素。其他语言可以通过包含不同音素的不同音素字母来描述。
34.话语中的音素的语音学属性可以依赖于被说出(或意图被说出)的语境,或受其影响。例如,“三音素”是音素的三元组,其中给定音素的口头渲染由时间上在前的音素(称为“左语境”)和时间上在后的音素(称为“右语境”)形成。因此,英语三音素的音素顺序对应于英语阅读的方向。也可以考虑其他音素语境,诸如五音素。
35.语音特征将语音的声学属性表示为参数,并且在语音合成的语境下,可以用于驱动与输出语音信号相对应的合成波形的生成。一般来说,语音合成的特征考虑了语音信号
的三个主要组成,即,类似声道效果的频谱包络、模拟声门源的激励,以及如上所述的描述音高轮廓(“旋律”)和节拍(节奏)的韵律。在实践中,特征可以表示为与一个或多个时间帧相对应的多维特征向量。tts合成系统的基本操作中的一个是将语音学转写(例如,标签序列)映射到适当的特征向量序列。
36.举例来说,特征可以包括梅尔滤波器倒谱系数(mfcc)系数。mfcc可以表示输入话语的一部分的短期功率频谱,并且可以基于例如非线性梅尔频率标度上的对数功率谱的线性余弦变换。(mel标度可以是被听众主观感知为彼此距离大约相等的音高标度,即使这些音高的实际频率彼此距离不等。)
37.在一些实施例中,特征向量可以包括mfcc、一阶倒谱系数导数和二阶倒谱系数导数。例如,特征向量可以包含13个系数、13个一阶导数(“δ”)和13个二阶导数(“δ-δ”),因此长度为39。然而,在其他可能的实施例中,特征向量可以使用不同的特征组合。作为另一示例,特征向量可以包括感知线性预测(plp)系数、相对频谱(rasta)系数、滤波器组对数能量系数或它们的某种组合。每个特征向量可以被认为包括话语(或者更一般地,音频输入信号)的相对应的时间帧的声学内容的量化表征。
38.图1描绘了根据示例实施例的示例文本到语音(tts)合成系统100的简化框图。除了功能组件,图1还示出了示例操作的所选择的示例输入、输出和中间产物。tts合成系统100的功能组件包括:文本分析模块102,用于将输入文本101转换为语音学转写103;tts子系统104,用于从语音学转写103生成表示待合成语音的声学特性105的数据;以及语音生成器106,用于从声学特性105生成合成语音107。这些功能组件可以在诸如以上所描述那些的一个或多个计算平台或系统上、以集中和/或分布的方式被实现为机器语言指令。机器语言指令可以存储在一种或另一种形式的有形的、非暂时性的计算机可读介质(或其他制品)中,诸如磁盘或光盘等;并且使得作为例如制造过程、配置过程和/或执行启动过程的一部分可用于系统的处理元件。
39.应当注意,此部分中的讨论以及附图是出于示例的目的而给出的。例如,tts子系统104可以使用hmm模型来实现,用于在运行时基于已知标签和已知参数化语音之间的学习(训练)关联来生成语音特征。作为另一示例,tts子系统104可以使用诸如人工神经网络(ann)的机器学习模型来实现,用于在运行时从已知标签和已知参数化语音之间的关联来生成语音特征,其中这些关联是通过利用已知关联的训练来学习的。在又一示例中,tts子系统可以采用混合hmm-ann模型。
40.根据示例实施例,文本分析模块102可以接收输入文本101(或其他形式的基于文本的输入)并且生成语音学转写103作为输出。例如,输入文本101可以是文本消息、电子邮件、聊天输入、书籍段落、文章或其他基于文本的通信。如上所述,语音学转写可以对应于标识语音单元(诸如音素)的标签序列,可能还有语境信息。
41.如所示地,tts子系统104可以采用基于hmm或基于ann的语音合成来生成与语音学转写103相对应的特征向量。特征向量可以包括表示要生成的语音的声学特性105的量。例如,声学特性可以包括音高、基频、步调(例如,语速)和韵律。其他声学特性也是可能的。
42.声学特性可以被输入到语音生成器106,该语音生成器106生成合成语音107作为输出。合成语音107可以被生成为实际的音频输出,例如来自具有一个或多个扬声器的音频设备(例如,耳机、耳塞或扬声器等);和/或可以被记录并且从数据文件(例如,波形文件等)
播放的数字数据。
43.对示例tts系统的这种高层级描述可以用于为tts合成的描述提供语境,该tts合成具有用于适应如何合成语音的用户接口输入。首先,呈现了其中可以实现具有用户接口适应的tts合成的示例实施例的示例通信系统和设备架构的讨论。
44.3.示例通信系统和设备架构
45.根据示例实施例的方法,诸如上述的一个实施例,设备可以使用所谓的“瘦客户端”和“基于云的”服务器设备以及其他类型的客户端和服务器设备来实现。在该范例的各个方面下,诸如移动电话和平板计算机的客户端设备可以将一些处理和存储责任负载转移给远程服务器设备。至少在某些时候,这些客户端服务能够通过诸如互联网的网络与服务器设备通信。作为结果,在客户端设备上运行的应用也可以具有永久的、基于服务器的组件。尽管如此,应当注意,本文公开的方法、处理和技术中的至少一些可以能够完全地在客户端设备或服务器设备上操作。
46.此部分描述了针对这种客户端设备和服务器设备的一般系统和设备架构。然而,在随后的部分中呈现的方法、设备和系统也可以在不同的范例下操作。因此,此部分的实施例仅仅是如何能够进行这些方法、设备和系统的示例。
47.a.示例通信系统
48.图2是其中可以采用本文描述的各种实施例的通信系统200的简化框图。通信系统200包括客户端设备202、204和206,其分别地代表桌面个人计算机(pc)、平板计算机和移动电话。客户端设备还可以包括,例如,可穿戴计算设备,诸如头戴式显示器和/或增强现实显示器。这些客户端设备中的每个可以能够通过使用有线连接(由实线表示)和/或无线连接(由虚线表示)、经由网络208与其他设备(包括与彼此)通信。
49.网络208可以是,例如,互联网,或一些其他形式的公共或私有互联网协议(ip)网络。因此,客户端设备202、204和206可以使用分组交换技术进行通信。尽管如此,网络208还可以并入至少一些电路交换技术,并且客户端设备202、204和206可以替代地或者除了分组交换之外经由电路交换进行通信。
50.服务器设备210也可以经由网络208进行通信。具体地,服务器设备210可以根据一个或多个网络协议和/或应用层级协议与客户端设备202、204和206通信,以有助于在这些客户端设备上使用基于网络或基于云的计算。服务器设备210可以包括集成的数据存储(例如,存储器、磁盘驱动器等)并且还可以能够访问单独的服务器数据存储212。如图2所示,服务器设备210和服务器数据存储212之间的通信可以是直接的、经由网络208的或者是直接的和经由网络208的两者。服务器数据存储212可以存储应用数据,该应用数据被用来有助于由客户端设备202、204和206以及服务器设备210执行的应用的操作。
51.尽管在图2中仅示出了三个客户端设备、一个服务器设备和一个服务器数据存储,但是通信系统200可以包括任意数量的这些组件中的每个。例如,通信系统200可以包括数百万个客户端设备、数千个服务器设备和/或数千个服务器数据存储。此外,客户端设备可以采用不同于图2中的形式。
52.b.示例服务器设备和服务器系统
53.图3a是根据示例实施例的服务器设备的框图。具体地,图3a所示的服务器设备300可以被配置为执行服务器设备210和/或服务器数据存储212的一个或多个功能。服务器设
备300可以包括用户接口302、通信接口304、处理器306和数据存储308,这些中的所有可以经由系统总线、网络或其他连接机制314链接在一起。
54.用户接口302可以包括用户输入设备,诸如键盘、小键盘、触摸屏、计算机鼠标、轨迹球、操纵杆和/或现在已知或以后开发的其他类似设备。用户接口302还可以包括用户显示设备,诸如一个或多个阴极射线管(crt)、液晶显示器(lcd)、发光二极管(led)、使用数字光处理(dlp)技术的显示器、打印机、灯泡和/或现在已知或以后开发的其他类似设备。额外地,用户接口302可以被配置为经由扬声器、扬声器插孔、音频输出端口、音频输出设备、耳机和/或现在已知或以后开发的其他类似设备来生成听觉输出。在一些实施例中,用户接口302可以包括软件、电路或能够向外部用户输入/输出设备传送数据和/或从外部用户输入/输出设备接收数据的\另外形式的逻辑。
55.通信接口304可以包括一个或多个无线接口和/或有线接口,其可被配置为经由网络(诸如图2所示的网络208)进行通信。如果存在的话,无线接口可以包括一个或多个无线收发器,诸如蓝牙收发器、可能根据ieee 802.11标准(例如,802.11b、802.11g、802.11n)操作的wifi收发器、可能根据ieee 802.16标准操作的wimax收发器、可能根据第三代合作伙伴计划(3gpp)标准操作的长期演进(lte)收发器和/或可配置为经由局域或广域无线网络通信的其他类型的无线收发器。如果存在的话,有线接口可以包括一个或多个有线收发器,诸如以太网收发器、通用串行总线(usb)收发器或可配置为经由双绞线、同轴电缆、光纤-光链路或其他到有线设备或网络的物理连接进行通信的类似收发器。
56.在一些实施例中,通信接口304可以被配置为提供可靠的、安全的和/或认证的通信。对于本文描述的每个通信,可以提供用于确保可靠通信(例如,保证的消息传递)的信息,可能作为消息报头和/或报尾的一部分(例如,分组/消息排序信息、封装报头和/或报尾、大小/时间信息、以及诸如循环冗余校验(crc)和/或奇偶校验值的传输验证信息)。可以使用一个或多个密码协议和/或算法来使通信安全(例如,编码或加密)和/或解密/解码,该密码协议和/或算法诸如但不限于数据加密标准(des)、高级加密标准(aes)、rivest、shamir和adleman(rsa)算法、diffie-hellman算法和/或数字签名算法(dsa)。可以使用其他加密协议和/或算法来代替或补充这里列出的那些来使通信安全(然后解密/解码)。
57.处理器306可以包括一个或多个通用处理器(例如,微处理器)和/或一个或多个专用处理器(例如,数字信号处理器(dsp)、图形处理单元(gpu)、浮点处理单元(fpu)、网络处理器或专用集成电路(asic))。处理器306可以被配置为执行在数据存储308中所包含的计算机可读程序指令310和/或其他指令,以执行本文描述的各种功能。
58.数据存储308可以包括一个或多个非暂时性计算机可读存储介质,其可以被处理器306读取或访问。一个或多个计算机可读存储介质可以包括易失性和/或非易失性存储组件,诸如光、磁、有机或其他存储器或盘存储,它们可以整体或部分地与处理器306集成。在一些实施例中,数据存储308可以使用单个物理设备(例如,一个光、磁、有机或其他存储器或盘存储单元)来实现,而在其他实施例中,数据存储308可以使用两个或更多个物理设备来实现。
59.数据存储308还可以包括程序数据312,该程序数据312可以被处理器306用来执行本文描述的功能。在一些实施例中,数据存储308可以包括或可以访问附加的数据存储组件
或设备(例如,下面描述的集群数据存储)。
60.再次简要参考图2,服务器设备210和服务器数据存储设备212可以在经由网络208可访问的一个或多个场所存储应用和应用数据。这些场所可能是包含大量服务器和存储设备的数据中心。服务器设备210和服务器数据存储设备212的确切物理位置、连接性和配置对于客户端设备可能是未知的和/或不重要的。因此,服务器设备210和服务器数据存储设备212可以被称为“基于云”的设备,其被容纳在各种远程位置。这种“基于云”的计算的一个可能的优点是从客户端设备负载转移处理和数据存储,从而简化这些客户端设备的设计和要求。
61.在一些实施例中,服务器设备210和服务器数据存储设备212可以是驻留在单个数据中心的单个计算设备。在其他实施例中,服务器设备210和服务器数据存储设备212可以包括数据中心中的多个计算设备,或者甚至多个数据中心中的多个计算设备,其中数据中心位于不同的地理位置。例如,图2描绘了可能位于不同的物理位置的服务器设备210和服务器数据存储设备212中的每个。
62.图3b描绘了基于云的服务器集群的示例。在图3b中,服务器设备210和服务器数据存储设备212的功能可以分布在三个服务器集群320a、320b和320c当中。服务器集群320a可以包括由本地集群网络326a连接的一个或多个服务器设备300a、集群数据存储322a和集群路由器324a。类似地,服务器集群320b可以包括由本地集群网络326b连接的一个或多个服务器设备300b、集群数据存储322b和集群路由器324b。同样地,服务器集群320c可以包括由本地集群网络326c连接的一个或多个服务器设备300c、集群数据存储322c和集群路由器324c。服务器集群320a、320b和320c可以分别地经由通信链路328a、328b和328c与网络308通信。
63.在一些实施例中,服务器集群320a、320b和320c中的每个可以具有相等数量的服务器设备、相等数量的集群数据存储和相等数量的集群路由器。然而,在其他实施例中,服务器集群320a、320b和320c中的一些或所有可以具有不同数量的服务器设备、不同数量的集群数据存储和/或不同数量的集群路由器。每个服务器集群中的服务器设备、集群数据存储和集群路由器的数量可以依赖于分配给每个服务器集群的计算任务和/或应用。
64.例如,在服务器集群320a中,服务器设备300a可以被配置为执行诸如服务器设备210的服务器的各种计算任务。在一个实施例中,这些计算任务可以分布在服务器设备300a中的一个或多个当中。服务器集群320b和320c中的服务器设备300b和300c可以被配置为与服务器集群320a中的服务器设备300a相同或相似。另一方面,在一些实施例中,服务器设备300a、300b和300c各自可以被配置为执行不同的功能。例如,服务器设备300a可以被配置为执行服务器设备210的一个或多个功能,而服务器设备300b和服务器设备300c可以被配置为执行一个或多个其他服务器设备的功能。类似地,服务器数据存储设备212的功能可以专用于单个服务器集群,或者分布在多个服务器集群上。
65.服务器集群320a、320b和320c的集群数据存储322a、322b和322c分别地可以是包括被配置为管理对硬盘驱动器组的读写和访问的磁盘阵列控制器的数据存储阵列。磁盘阵列控制器,单独地或结合其相应的服务器设备,也可以被配置为管理存储在集群数据存储中的数据的备份或冗余拷贝,以防止:磁盘驱动器故障或阻止一个或多个服务器设备访问一个或多个集群数据存储的其他类型的故障。
66.与服务器设备210和服务器数据存储设备212的功能可以跨服务器集群320a、320b和320c分布的方式类似,这些组件的各种活动部分和/或备份/冗余部分可以跨集群数据存储322a、322b和322c分布。例如,一些集群数据存储322a、322b和322c可以被配置为存储在其他集群数据存储322a、322b和322c中所存储的数据的备份版本。
67.服务器集群320a、320b和320c中的集群路由器324a、324b和324c分别地可以包括被配置为向服务器集群提供内部和外部通信的联网设备。例如,服务器集群320a中的集群路由器324a可以包括一个或多个分组交换和/或路由设备,其被配置为提供(i)经由集群网络326a的服务器设备300a和集群数据存储322a之间的网络通信,和/或(ii)经由到网络308的通信链路328a的服务器集群320a和其他设备之间的网络通信。集群路由器324b和324c可以包括类似于集群路由器324a的网络设备,并且集群路由器324b和324c可以为服务器集群320b和320c执行集群路由器324a为服务器集群320a执行的联网功能。
68.额外地,集群路由器324a、324b和324c的配置可以至少部分地基于服务器设备和集群存储阵列的数据通信需求、集群路由器324a、324b和324c中的网络设备的数据通信能力、本地集群网络326a、326b、326c的延迟和吞吐量、广域网连接328a、328b和328c的延迟、吞吐量和成本、和/或可能对成本、速度、容错性、弹性、效率和/或系统架构的其他设计目标有贡献的其他因素。
69.c.示例客户端设备
70.图4是示出示例客户端设备400的组件中的一些的简化框图。客户端设备400可以被配置为执行客户端设备202、204、206的一个或多个功能。作为示例而非限制,客户端设备400可以是或包括“简易老式电话系统”(pots)电话、蜂窝移动电话、静态相机、摄像机、传真机、应答机、计算机(诸如桌面型、笔记本型或平板型计算机)、个人数字助理、可穿戴计算设备、家庭自动化组件、数字录像机(dvr)、数字电视、遥控器或者配备有一个或多个无线或有线通信接口的一些其他类型的设备。客户端设备400还可以采取交互式虚拟和/或增强现实眼镜的形式,诸如头戴式显示设备,有时被称为“平视”显示设备。尽管不一定在图4中示出,但是头戴式设备可以包括用于在头戴式设备的显示器组件上显示图像的显示器组件。头戴式设备还可以包括一个或多个面向眼睛的相机或被配置为跟踪头戴式设备的佩戴者的眼睛运动的其他设备。眼睛跟踪相机可以用于实时确定眼睛注视方向和佩戴者眼睛的运动。眼睛注视方向可以被提供作为各种操作、功能和/或应用的输入,诸如跟踪佩戴者的注视方向和在显示设备中显示的文本上的运动。
71.如图4所示,客户端设备400可以包括通信接口402、用户接口404、处理器406和数据存储408,所有这些可以通过系统总线、网络或其他连接机制410通信地链接在一起。
72.通信接口402用于允许客户端设备400使用模拟或数字调制与其他设备、接入网络和/或传输网络进行通信。因此,通信接口402可以有助于电路交换和/或分组交换通信,诸如pots通信和/或ip或其他分组化通信。例如,通信接口402可以包括芯片组和天线,其被布置为用于与无线电接入网络或接入点的无线通信。另外,通信接口402可以采取有线接口的形式,诸如以太网、令牌环或usb端口。通信接口402也可以采取无线接口的形式,诸如wifi、蓝牙全球定位系统(gps)或广域无线接口(例如,wimax或lte)。然而,可以在通信接口402上使用其他形式的物理层接口和其他类型的标准或专有通信协议。此外,通信接口402可以包括多个物理通信接口(例如,wifi接口、蓝牙
接口和广域无线接口)。
73.用户接口404可以用于允许客户端设备400与人类或非人类用户交互,诸如接收来自用户的输入并且向用户提供输出。因此,用户接口404可以包括输入组件,诸如小键盘、键盘、触敏或存在感面板、计算机鼠标、轨迹球、操纵杆、麦克风、静态相机和/或摄像机。用户接口404还可以包括一个或多个输出组件,诸如(例如,可以与触敏面板组合的)显示器屏幕、crt、lcd、led、使用dlp技术的显示器、打印机、灯泡和/或现在已知或以后开发的其他类似设备。用户接口404还可以被配置为经由扬声器、扬声器插孔、音频输出端口、音频输出设备、耳机和/或现在已知或以后开发的其他类似设备来生成听觉输出。在一些实施例中,用户接口404可以包括软件、电路或能够向外部用户输入/输出设备传送数据和/或从外部用户输入/输出设备接收数据的另外形式的逻辑。额外地或替选地,客户端设备400可以支持经由通信接口402或经由另一物理接口(未示出)从另一设备的远程访问。用户接口404可以被配置为接收用户输入,其位置和运动可以由本文描述的指示符或光标来指示。用户接口404可以额外地或替选地被配置为显示设备,以渲染或显示文本片段。
74.处理器406可以包括一个或多个通用处理器(例如,微处理器)和/或一个或多个专用处理器(例如,dsp、gpu、fpu、网络处理器或asic)。数据存储408可以包括一个或多个易失性和/或非易失性存储组件,诸如磁、光、闪存或有机存储,并且可以整体或部分地与处理器406集成。数据存储408可以包括可移动和/或不可移动的组件。
75.一般而言,处理器406可能能够执行在数据存储408中所存储的程序指令418(例如,编译或非编译的程序逻辑和/或机器代码),以执行本文所述的各种功能。数据存储408可以包括非暂时性计算机可读介质,其上存储有程序指令,该程序指令在由客户端设备400执行时,使得客户端设备400执行本说明书和/或附图中公开的任何方法、处理或功能。处理器406执行程序指令418可以导致处理器406使用数据412。
76.作为示例,程序指令418可以包括安装在客户端设备400上的操作系统422(例如,操作系统内核、设备驱动程序和/或其他模块)以及一个或多个应用程序420(例如,地址簿、电子邮件、网页浏览、社交网络和/或游戏应用)。类似地,数据412可以包括操作系统数据416和应用数据414。操作系统数据416可以主要地对于操作系统422可访问,并且应用数据414可以主要地对于一个或多个应用程序420可访问。应用数据414可以被布置在对客户端设备400的用户可见或隐藏的文件系统中。
77.应用程序420可以通过一个或多个应用编程接口(api)与操作系统412通信。这些api可以有助于例如应用程序420读取和/或写入应用数据414、经由通信接口402传送或接收信息、在用户接口404上接收或显示信息等等。
78.在一些行话中,应用程序420可以简称为“app(应用)”。额外地,应用程序420可以通过一个或多个在线应用商店或应用市场下载到客户端设备400。然而,应用也可以以其他方式安装在客户端设备400上,诸如经由网络浏览器或通过客户端设备400上的物理接口(例如,usb端口)。
79.4.示例系统和操作
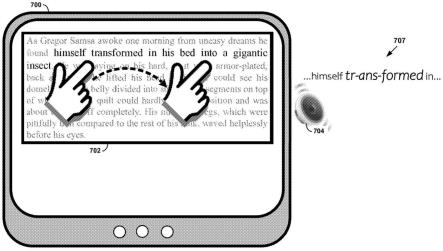
80.具有用户接口适应的文本到语音合成可以被视为通过设计并且作为处理的整体来将手动调步(pacing)合并到用于文本到语音合成的系统和方法中。根据示例实施例,当用户执行聚焦活动时,诸如在桌面型计算机上采用鼠标将光标一个接一个地悬停在单词
上,或者采用他们的手指在平板型设备上跟踪文本,或者在具有交互式显示器的设备上进行某种其他形式的手动文本跟踪,可以递增地产生语音输出。当用户这样做时,他们的跟踪移动可以被转换为对文本到语音模块或子系统的输入(例如,光标输入)。文本到语音模块可以使用输入跟踪信息来使驱动语音生成器的语音特征的生成进行适应。结果可以是与用户对文本的跟踪一致的、所说出的文本的合成语音。具体地,tts模块和语音生成器可以以用户在所显示的文本上移动其手指或光标的速率并且以听起来自然的方式,说出(或以其他方式输出)用户正指向的文本。
81.实现手动调步的文本到语音合成的技术挑战——传递高质量的语音输出而同时遵循用户跟踪文本的位置和速度——可以通过考虑下述有些朴素的方法来说明:只是观察用户当前正在指向什么单词,并且将该单词发送到tts引擎进行发音。虽然原则上这看起来是合理的,但效果却是次优的,缺乏使得合成的声音栩栩如生的韵律。为了理解原因,首先考虑标称tts操作的示例,它是在没有任何用户交互的情况下进行手动调步控制的。例如,当句子被发送到tts引擎进行发音时,在合成语音之前,首先执行许多语言操作。这些包括字素到音素的转换,其被用于消除拼写相同但发音不同的单词的歧义(诸如单词read的现在时和过去时)。句子中的每个音素被给定持续时间(以及因此给定速率)和音量。推断句子的整体含义(例如,是否为问题或感叹),并且生成音高轮廓。
82.图5中示出了标称tts合成的示例处理流程500。例如,处理流程500可以由图1的tts系统100来执行。如所示地,处理流程500以输入文本501的音素提取502开始,例如,这可以由文本分析模块102执行。音素提取502的结果可以是例如语音学转写103,其可以包括用于合成处理的给定音素,以及为给定音素应该如何发音提供“语境”的一个或多个在前和在后音素。当在本文使用时,应用于语境的术语“在前”、“在后”等指代阅读顺序。因此,在前音素(或其他语言单元)指代对应于在与给定音素(或其他语言单元)相关联的给定文本之前读出的、在前文本的音素。类似地,在后音素(或其他语言单元)指代对应于在与给定音素(或其他语言单元)相关联的给定文本之后读出的、在后文本的音素。
83.示例处理流程500中的下一操作是操作504,确定音素持续时间和音量;以及操作506,确定音高轮廓。例如,这些操作可以由图1的文本到语音子系统104来执行。在示例实施例中,音素持续时间和音量以及音高轮廓可以对应于或者被认为是“语音特性”的方面。在图1的示例中,这些可以是声学特性105,并且可以包括或表示为例如特征向量形式的数据。
84.如示地,最后的操作508是语音生成,使用音素持续时间和音量以及音高轮廓作为输入并且产生合成语音503作为输出。更一般地,语音生成可以使用语音特性(或声学特性)作为输入。再次参考图1,该操作可以由语音生成器106来执行。
85.再次参考图1中的tts子系统104以及对tts系统110的操作的描述,在示例实施例中,操作504和506可以被表征为确定所提取的音素(包括语境)到对所提取的音素的口头渲染进行参数化的语音特征的映射。如上所述,这可能需要使用基于hmm和/或基于ann的模型来识别与书面文本的语音学转写相关联的语音特征。该识别可以是概率性的,例如,具有可达到的置信水平或依赖于训练程度的一些其他似然性度量。
86.在这样的布置中,识别可以进一步涉及应用语音模型和语言模型两者,以便预测每个音素的正确发音。例如,发音描述了开头、中间和结尾的语调、持续时间和音量以及其他特性。也就是说,发音可以使用在操作504和506中做出的确定。这些确定的语音和语言环
境可以与文本被“阅读”和处理成语音的步调相关。在没有用户交互来控制或调整步调的情况下,可以使用语音和语言解释的“标准”步调来以标准语速生成听起来自然的语音。
87.例如,标准步调(或标准语速)可以是当向听众或观众朗读文本段落时人类可能说话的步调。然而,应当理解,标准步调可能不对应于精确的说话速率,而是通常可以描述自然的并且很大程度上一致的步调,典型的听众会发现该速度清晰并且易于理解。其也可以被认为是一种初始步调或默认步调,其被定义为与用户可以经由与所显示的文本的交互跟踪来指示的可调整或手动步调形成对比,如根据本文的示例实施例所描述地。在一些示例中,默认的或标准的语速或步调可以是预定的,或者可以是用户定义的。
88.图6示出了根据示例性实施例,可以根据示例性处理流程500合成的示例性语音波形和音调分布。图6中的顶部面板示出了简单句子“你想来这里吗?”的合成波形602。句子的每个音素也在波形的顶部被添加标签,并且分隔每个音素的垂直线之间的水平间距表示每个口头片段的持续时间。图6中的底部面板示出了相对应的音高分布604,覆盖有相同的音素标签和持续时间间隔。注意,音调分布可以对应于由合成波形指定的合成语音的音调分布,或者可以在例如由tts子系统执行的语音合成处理中生成。在任一情况下,音调分布表示语音特性的一个方面。图6的两个面板示出了可以以标准(或默认)步调合成的语音的示例。
89.上面提到的与通过从显示的文本中一次交互地标识一个单词或者甚至一次标识一个音素来合成语音的简化的或朴素的方法有关的问题是,语境信息可能被错误地解释或者可能完全丢失。结果可能是一个单词接一个单词或一个音素接一个音素的发音,听起来不自然或难以理解,并且在任何情况下都与下述方式不相符合:如果用户以手指(或光标)跨过文本显示的相同或相似的调整的步调可视地扫描文本,则用户自己对文本进行发音的方式。
90.作为示例,考虑上面简单句子中的单词“to”。当以标准步调说出时,其可能根本不发声。这由波形和音高分布图中音素/t/的相对地短的持续时间来指示。因此,标称tts合成建模可以在句子和周围单词的语境中以标准步调处理单词“to”。例如,简化的或朴素的方法可能导致单词“to”的完整发声的发音,其听起来与周围的作品和音素不协调并且不连续。在这个示例中,“to”的完整发音可能适合于根据用户输入确定的手动调步,但是语调、音量和音调以及其他语音特性对于人耳来说可能听起来不自然。
91.为了克服诸如上述那些问题,并且解决转换提供tts合成的手动调步的用户交互的挑战,发明人设计了可以将从标准调步的tts合成确定的语境作为反馈合并到手动调步的tts合成的技术。通过这样做,tts系统可以合成语音特性,并且以忠实地反映交互式用户对调步控制的步调输出合成语音,同时产生听起来自然并且适合于由用户交互设置的手动控制的步调的合成语音。
92.a.具有用户接口适应的示例文本到语音转换
93.图7是根据示例实施例的具有用户接口适应的示例文本到语音应用的概念性图示。作为示例,示例tts应用被示出为它可能出现在具有显示屏的用户设备700(例如,可以被实现为用户设备400)上,该用户设备诸如是膝上型计算机或平板型计算机。文本(文本片段)的视觉显示702出现在显示屏的一部分上。用户交互由在所显示的文本上的两个连续位置处示出的进行指向的手指的图标来表示。两个位置之间的弯曲虚线箭头指示用户在文本
的一部分上跟踪。作为视觉提示,大部分文本被示出为变灰,只有当前正在进行语音合成的句子部分以黑色的放大字体示出。然而,在示例实施例中,变灰或其他视觉散焦效果可以是实际显示器的明确特征。这可以作为对用户的实时视觉辅助来完成,以帮助用户将注意力集中在被跟踪的文本上,同时削弱周围的文本,否则周围的文本可能分散视觉注意力。换句话说,与文本的剩余部分相比,所标识的文本(或所标识的部分的文本)可以视觉清晰和集中地呈现或显示——这可以包括通过采用视觉散焦显示文本片段的文本而不是所标识的部分的文本,来主动地强调所标识的文本和/或主动地最小化文本的剩余部分。在所示的示例中,散焦可以是变灰,或者是文本模糊。也可以使用其他可能的散焦效果。这种视觉“散焦”和“聚焦”可能是有益的,因为更加突出地显示由用户标识的文本部分可以帮助用户将所标识的文本片段保持在他们的视觉聚焦或关注的视场内。
94.光标的运动可以用于适应语音合成的标准步调。例如,光标输入所指示的指示符或光标的运动对应于用户对所标识的部分中的文本的实时跟踪。根据示例实施例,用户的跟踪运动的速度(速率)和/或加速度可以确定合成处理和语音发音的步调。例如,第一步调和/或加速度可以转化为高于第一阈值步调但低于标准步调的第一步调,其中,标准步调是第二阈值步调。在检测第一步调时,示例系统可以以一个单词接一个单词的步调(即,tts系统合成单个单词的步调)来合成和发音语音;一个单词接一个单词的跟踪速率对应于高于第一(预定)阈值并且低于第二(预定)阈值的跟踪速率,该第二(预定)阈值对应于默认或标准步调。作为另一示例,第二步调和/或加速度可以转换为等于或低于第一阈值的第二步调,在这种情况下,示例系统可以以一个音素接一个音素的步调(即,tts系统合成单个音素的步调)来合成和发音速度;一个音素接一个音素的跟踪速率对应于等于或低于第一阈值的跟踪速率。将用户跟踪的速度和/或加速度转换为合成和发音速度的其他布置也是可能的,包括用于设置期望速度的用户接口或应用“仪表板”。
95.为了说明的目的并且作为示例,图7中的用户跟踪可以被认为足够慢(例如,低于第一阈值步调)以信号发送到合成应用以一个音素接一个音素的步调生成和输出合成语音707。合成语音因此可以从用户设备700的扬声器组件704发出。同样为了说明的目的,扬声器704被明确地示出为它是用户设备的组件的视觉提示。在实际的用户设备中,扬声器组件可能在物理上是内部的并且是不可见的。
96.在这个示例中,合成语音707的一个音素接一个音素的渲染由单词“tr-ans-formed”的连字符和放大字体来表示。根据示例实施例,手动调步的tts系统,诸如在图7中概念性地示出的系统,可以以听起来自然的方式来渲染“tr-ans-formed”的发音,例如,就好像用户在慢慢地读出单词“transformed”一样。这种能力,并且更一般地说,自然地发音的适应调步tts合成的能力,可以通过修改标称语音合成处理来实现,如现在通过示例描述地。在示例实施例中,单词或短语的一个音素接一个音素的步调的合成之后可以是以标准步调自动重读该单词或短语。如在图7中可以进一步看到地,单词“他自己”以比“转换”的发音更快的步调输出;本文描述的方法有助于两种不同步调之间的平滑过渡,这可以改进用户的人类听觉感知。通过改进用户感知,还可以减少计算资源,因为用户可能不需要重复tts请求,并且可以减少与客户端设备的后续交互。
97.根据示例实施例,文本的标准调步的tts合成可以提供“先前合成的语音”,该“先前合成的语音”可以用作对正由光标输入等跟踪的文本的语音合成的输入和/或反馈,而同
时被显示在交互式显示设备中。可以在完全在根据跟踪对tts合成进行调步之前的时间间隔期间(例如,几秒、几分钟或者甚至更早之前),或者在与根据跟踪对tts合成进行调步基本上同时的间隔期间,执行先前合成,该tts合成根据跟踪进行调步。在后一种情况下,例如,先前合成可以在适应调步合成之前一步或几步进行;例如具有足够的前导时间作为反馈。
98.适应调步或手动调步的tts的处理流程可以根据示例标称合成处理的修改以至少两种方式来描述。首先,它保留先前生成的语音的语境(例如,在当前单词或音素之前),使得它能够迭代地产生语音,而不会使每个合成样本看起来来自新的合成实例。换句话说,它将先前所说文本的语境传递给合成器,以便合成器生成语音信号的“延续”而不是新的语音信号。第二,它使生成的语音的音量、速率和音高轮廓适应,以便遵循跟踪指示的速率或步调。
99.图8描绘了根据示例实施例的具有用户接口适应的文本到语音合成的示例处理流程800。与图5的示例标称处理流程一样,处理流程800可以由例如图1的tts系统100来执行。如图所示,处理流程800从输入文本801的音素提取802开始。在处理流程800中,音素提取对应于使用整个文本的、针对整个段落的字形到音素的转换,在下文中称为全局语境。全局语境可以用于消除发音的歧义,并且推断标准音素持续时间、音量和音高轮廓。也就是说,全局语境包括整个文本和组成整个文本的tts的元素,就好像用户跟踪不存在一样——即标准处理。从这点来看,处理流程800可以被认为遵循两个大致平行的处理“管道”。第一种通常对应于标准处理,其生成上述的先前合成。第二种对应于手动调步或适应的合成处理,其使用用于语境的先前合成的方面。
100.对于先前合成(标准)处理管道,提取的音素被输入到操作804,用于确定标准音素持续时间和音量。这之后是操作808,用于根据标准处理确定当前音素持续时间和音量。接下来,操作810再次以标准调步确定当前单词音高轮廓。接下来是语音生成812。然而,标准语音没有听觉地输出。相反,在操作814中,它被提供为先前合成的音频,其被用在根据手动调步的合成管道执行的适应处理中,如现在所描述地。
101.对于手动调步或适应的合成处理管道,使用用户跟踪输入来确定当前单词803和当前速率805。当前单词803可以对应于所显示的文本内的当前跟踪位置,而当前速率805可以对应于跟踪位置的一阶和二阶时间导数(即,跟踪位置的速度和加速度)。通过图8中的示例,这些输入可以对应于光标输入,如所指示地。然而,如上所述,位置和运动(例如,速度和加速度)输入可以更一般地是任何合适的跟踪操作的位置和运动,其非限制性示例也已在上文描述。因此,应当理解,本文在手动调步或适应的tts合成的语境中对“光标输入”的引用可以被认为适用于所提供的任何非限制性跟踪操作示例等中的一个或多个。
102.跟踪位置然后可以被用于对在音素提取802中确定的全局提取的音素内的当前单词进行索引。这给予了合成器提此时要说出的音素的子集,其表示为当前单词806的音素。同时,先前合成的音频814提供用于当前单词806的音素的音素输入,然后对其进行处理以确定当前音素持续时间和音量808。
103.当前单词803还被用于确定局域语境807,其被输入到当前音素持续时间和音量808以及当前单词音高轮廓810两者。当前音素持续时间和音量808还接收标准音素持续时间和音量804以及当前速率805作为输入。这三个输入——局域语境807、标准音素持续时间
和音量804以及当前速率805——被用于确定当前音素持续时间和音量808,其中持续时间对应于当前速率,并且音素音量与标准音素音量一致。
104.下一操作810确定当前单词音高。该操作还接收局域语境807、当前速率805和先前(先前合成的)音高816作为输入,该音高816是从先前合成的音频814中导出的,如所指示地。这三个输入——局域语境807、当前速率805和先前音高816——被用于确定当前单词音高810是连续的和/或与先前合成的音高一致。例如,所标识的部分的文本的合成语音的音高和韵律可以与紧接在所标识的部分之前和紧接在所标识的部分之后两者的语境部分的文本的合成语音的音高和韵律是连续的。这种平滑过渡可以减少不和谐并且改进用户的人类听觉感知。通过改进用户感知,还可以减少计算资源,因为用户可能不需要重复tts请求。
105.局域语境807用于帮助确保韵律一致性。例如,由手动调步导致的语音输出的可能的开始-和-停止和/或不连续的性质可能引起用户如何整体理解文本的差异。例如,某些原本会被跳过、连接或者只是非常简短地说出的单词——诸如句子“i want to go home”中的单词“to”——当用户明确地跟踪它们时,可能必须被完整地发音。然而,这样的单词仍然应该被给予与其紧邻的单词的韵律重要性相关的音高、持续时间和音量值。来自全局语境的紧邻当前单词的语言信息被用于导出局域语境。例如,局域语境807可以基于所标识的文本部分周围的文本的语境部分;文本的语境部分可以是一个或多个音素、一个或多个单词或者一个或多个句子,视情况而定。语境部分包括紧接在所标识的部分之前和紧接在所标识的部分之后的文本(即,邻近所标识的部分任一端的文本片段的至少一个音素,可选地,至少一个语言单元)。
106.当前音素持续时间和音量808以及当前单词音高810然后被语音生成器处理以产生适应的合成语音809。这是合成语音,其以对应于用户跟踪文本的步调发音并且具有听起来自然的音高和其他语音特性。
107.具有用户接口适应的文本到语音合成的示例处理流程800可以概述为如表1所示。可以重复整个处理流程800和/或表1中的概述,直到文本段落或其他文本部分的整个音频渲染被完整地说出。如上所述,对“光标输入”的引用是示例性的。包括上述示例的各种其他形式的跟踪输入可以用于表1中概述的流程中。
108.[0109][0110]
表1
[0111]
示例处理流程800可以被认为是描述单词跟踪,诸如一个单词接一个单词地阅读。对于一个音素接一个因素的跟踪,处理流程可能是类似的,但是基于单词的局域语境现在也采用基于音素的(基于子单词的)局域语境来扩充。在这种情况下,当用户跟踪文本时,系统可以跟踪他们正指向哪个音节或音素,并且因此可以生成特定的阅读单位。
[0112]
注意,即使用户处于音素模式,生成特定的音素可能也不是在所有情况下都合适。因此,在跟踪文本的某一速度之上,系统可以退回到单词模式,仅当用户有意尝试按音素读出单词时才保留音素模式(由它们的速度和加速度模式确定)。
[0113]
具有用户接口适应的文本到语音应用的示例实施例以可以显著增加用户对文本的注意力的方式来有利地链接跟踪和阅读。视觉的本质是用户的视野可以贡献对大脑的大量刺激。保持跟踪操作指示符(例如,诸如鼠标控制的指针/光标、触摸屏上的手指跟踪、或映射到文本显示的测量/监控的眼睛注视方向)指向下一个要阅读的单词可以确保大部分刺激来自用户的文本,而不是来自用户环境中的分散注意力。
[0114]
通过有意地对远离用户光标的文本部分进行散焦、去饱和或模糊处理,可以进一步增强这种聚焦,从而在用户光标到达这些区域之前,减少屏幕上视觉上分散注意力的区域的刺激。这可以进一步增强用户在手动调步tts时的集中体验。例如,除了模糊或淡出之外,还可以使用各种散焦技术和/或操作。视觉散焦的非限制性示例可以包括这样的视觉效果,如与用户光标(或其他交互式聚焦/跟踪)之外的文本相比,采用不同的背景或前景色进行淡出或模糊或显示。其他散焦操作可以包括改变散焦文本的字体或字体大小(例如,相对于用户的交互式聚焦/跟踪之外的文本缩小字体大小,和/或以比用户的交互式聚焦/跟踪之外的文本相对较不权威的字体样式显示散焦文本)。另外,用户的交互式聚焦/跟踪内的文本可以在文本框内显示或加下划线,而散焦文本从文本框中排除或不带下划线显示。其他散焦效果也是可能的。
[0115]
与通过手动跟踪音素或单词来阅读单词相关的一个普遍挑战是,虽然这集中了注
意力,但也可能对学习者的工作存储器提出了更高的要求。例如,由于阅读的步调可能较慢,为了成功地解码句子,用户可能不得不在他们的存储器中保留较早时间的单词。
[0116]
本文描述的示例实施例通过在眼睛阅读文本的扫视的视觉处理上对用户调步的tts合成进行建模来解决该挑战。当流利地阅读时,眼睛通常不会一个字符到一个字符地移动,甚至不会一个单词到一个单词地移动。相反,它从一组单词跳到另一组,一次接收多个单词。例如,当阅读以窄列布置的文本时,眼睛可以简单地向下移动通过行,在一瞥中接收整个列。如果需要的话,眼睛可以前后移动来重读。
[0117]
因此,本文描述的示例实施例可以被视为实现了一种“音频扫视”,其以与上述手动跟踪互补的方式起作用。也就是说,输入文本被分成用于tts的单词和音素,并且使用依存解析和其他语言标签方法来标识更大的相关单词组。例如,tts技术可以用于将输入文本分成名词短语、从句和句子。这些不同的表示然后可以分层级地布置,其中,文本由句子组成,句子由句子片段组成,句子片段由分句组成,分句由短语组成,短语由单词搭配组成,单词搭配由单词组成。
[0118]
因此,当用户发起类似扫视的用户交互时,通过这里描述的示例实施例而成为可能的语言意识重读可以说出分层级的更高级别的表示。当在某一级别的表示的单元被完成时,这种交互也可以由系统隐含地启动。例如,系统可以被配置为在音素读出后重读单词。当用户手动读出单词的音素时,音素被说出,并且然后完整的单词可以由系统以正常的(例如,标准的)步调被说出。在另一实施例中,系统可以被配置为在读出单个单词后重读句子。在这种情况下,用户可以控制读出单个单词的步调,但是一旦跟踪了整个句子,就可以说出该句子。
[0119]
这种音频扫视模拟也可以手动地启动,例如,通过特殊的手势、键或其他应用仪表板控制。因此,当读出单个单词时可能忘记句子的跟踪的用户可以启动整个句子(或单词是其一部分的短语)的重读。这种重读可以帮助提高理解,而同时通过仅阅读与用户所处的当前语境相关的单词来帮助用户的工作存储器。
[0120]
以这种方式,通过合并智能tts和语言感知的重读,可以极大地增强阅读理解,并且文本和音频表示可以一起工作来改进用户对文本的参与和保存。
[0121]
b.示例方法
[0122]
在示例实施例中,示例方法可以被实现为机器可读指令,当由系统的一个或多个处理器执行时,该指令使得系统执行本文描述的各种功能、操作和任务。除了一个或多个处理器之外,该系统还可以包括用于存储示例方法的机器可读指令(以及可能的其他数据)的一种或多种形式的存储器,以及一个或多个输入设备/接口、一个或多个输出设备/接口以及其他可能的组件。该示例方法的一些或所有方面可以在tts合成系统中实现,该tts合成系统可以包括tts合成专用的功能和能力。然而,并非示例方法的所有方面都必须依赖于tts合成系统中的实现。
[0123]
在示例实施例中,tts合成系统可以包括一个或多个处理器、一种或多种形式的存储器、一个或多个输入设备/接口、一个或多个输出设备/接口以及机器可读指令,当由一个或多个处理器执行时,该指令使得tts合成系统执行本文描述的各种功能和任务。tts合成系统还可以包括基于一个或多个隐马尔可夫模型的实施方式。具体地,tts合成系统可以采用并入了基于hmm的语音合成以及其他可能组件的方法。额外地或替选地,tts合成系统还
可以包括基于一个或多个人工神经网络(ann)的实施方式。具体地,tts合成系统可以采用并入了基于ann的语音合成以及其他可能组件的方法。
[0124]
图9是示出根据示例实施例的示例方法的流程图。在步骤902,采用文本到语音(tts)系统合成来自文本片段的语音并且同时在显示设备中显示该文本片段的文本到语音(tts)系统可以接收指示跟踪操作相对于显示设备中显示的文本片段的位置和运动的输入。在tts系统在远离显示设备的服务器上实现的实施方式中,步骤902可以包括,在采用文本到语音(tts)系统合成来自在显示设备上显示的文本片段的语音的同时,接收指示显示该文本片段的显示设备处的跟踪操作的位置和运动的输入。
[0125]
在步骤904,tts系统可以使用所指示的跟踪操作的位置来标识文本片段中正在经历tts合成处理的部分。该部分可被标识为在接收到跟踪操作输入(或指示跟踪操作的位置和运动的输入)的时间附近正被处理的文本部分,或者该部分可被标识为位于跟踪操作的所指示的位置附近的文本片段部分。在步骤904,tts系统还可以使用跟踪操作的所指示的位置来标识文本片段的语境部分,对于该文本片段的语境部分,tts系统已经以标准语速合成了先前合成的语音。语境部分可以包括紧接在所标识的部分之前和紧接在所标识的部分之后的文本。
[0126]
在步骤906,tts系统可以使用所指示的跟踪操作的运动来将所标识部分的tts合成的语速从标准语速调整为基于所指示的运动确定的适应语速。
[0127]
在步骤908,tts系统可以通过对所标识的部分的tts合成处理应用语境部分的先前合成语音的适应的语速和合成的语音特性两者来适应所标识的部分的合成语音的语音特性。
[0128]
最后,在步骤910,tts系统可以以适应的语速和适应的语音特性来输出标识的部分的合成语音。合成的语音可以在本地渲染或播放,或者由tts系统输出到远程设备。
[0129]
根据示例实施例,示例方法可以进一步包括在与合成该部分的语音同时的时间间隔期间合成语境部分的先前合成的语音。在这种情况下,应用语境部分的先前合成的语音的适应语速和合成的语音特性可能需要应用语境部分的先前合成的语音的适应语速和合成的语音特性作为对所标识的部分的tts合成处理的反馈。
[0130]
根据示例实施例,示例方法可以进一步包括在合成该部分的语音之前的时间间隔期间合成语境部分的先前合成的语音。
[0131]
根据示例实施例,接收跟踪操作输入可能需要经由通信地连接到显示设备或作为显示设备的一部分的用户接口接收虚拟指向指示符输入(或光标输入)的输入。此外,接收指示显示设备中虚拟指向指示符相对于显示设备中显示的文本片段的位置和运动的跟踪操作输入可能需要实时接收虚拟指向指示符相对于显示的文本片段的位置、速度和加速度的跟踪。进一步根据示例实施例,虚拟指向指示符可以是(图形地)渲染的光标、触摸屏上的位置和运动的触觉输入、或者投影在显示屏上的用户的眼睛跟踪位置和运动的输入中的任何一个或多个。视情况而定,虚拟指向指示符可以被或可以不被图形地渲染。
[0132]
根据示例实施例,使用跟踪操作的所指示的位置来标识文本片段的正经历tts合成处理的部分可以涉及使用跟踪操作的位置来标识正经历tts合成处理的所标识的部分中的语言单元。此外,语言单元可以是与正在经历tts合成处理的所标识的部分中的文本相对应的音素、单词或短语中的一个或多个。
[0133]
根据示例实施例,所指示的跟踪操作的运动可以对应于以一个单词接一个单词或一个音素接一个音素的跟踪速率对所标识的部分中的文本进行实时跟踪。这样,如果跟踪速率是一个单词接一个单词的,则将适应的语速应用于所标识的部分的tts合成处理可能需要一个单词接一个单词地合成说出的语音。类似地,如果跟踪速率是一个音素接一个音素地,则将适应的语音调步应用于所标识的部分的tts合成处理可能需要一个音素接一个音素地合成说出的语音。
[0134]
根据示例实施例,所标识的部分的合成语音的语音特性可以包括所标识的部分的合成语音的音高和韵律。类似地,语境部分的先前合成语音的语音特性包括语境部分的先前合成语音的音高和韵律。这样,对所标识的部分的tts合成处理应用语境部分的先前合成语音的适应语速和合成语音特性两者可以涉及生成以适应的语速说出的所标识的部分的合成语音,并且所标识的部分的文本的合成语音的音高和韵律与紧接在所标识的部分之前和紧接在所标识的部分之后的语境部分的文本的合成语音的音高和韵律连续。这种连续的音高和韵律可以确保语音合成期间的平滑过渡,这可以减少用户的不和谐。
[0135]
根据示例实施例,所指示的跟踪操作的运动可以对应于以跟踪速率实时地跟踪所标识的部分中的文本。这样,生成以适应的语速说出的所标识的部分的合成语音,并且所标识的部分的文本的合成语音的音高和韵律与紧接在所标识的部分之前和紧接在所标识的部分之后的语境部分的文本的合成语音的音高和韵律是连续的,可以涉及合成所标识的部分的语音,其一次说出一个语言单元。具体地,所标识的部分的每个给定的说出的语言单元还可以采用与语境部分的语言单元的合成语音的音高和韵律连续的音高和韵律来说出,该语境部分紧接在所标识的部分的给定的说出的语言单元之前和之后两者。此外,如果跟踪速率不大于第一阈值速率,则每个语言单元可以是音素,或者如果跟踪速率大于第一阈值速率并且低于第二阈值速率,则每个语言单元可以是单词。
[0136]
根据示例实施例,示例方法可以进一步包括在以适应的语速和具有适应的语音特性输出所标识的部分的合成语音之后,立即以标准语速和标准语音特性重复输出所标识的部分的合成语音。通过将重复输出与以适应的语音速率和适应的语音特性合成的语音相关联,该操作可以帮助改进和/或增强用户理解和/或读写能力。
[0137]
根据示例实施例,同时地,在显示设备中显示文本片段可能需要以视觉清晰度和聚焦显示所标识的部分的文本;并且采用视觉散焦来显示除了所标识的部分的文本之外的文本片段的文本。视觉散焦的非限制性示例可以包括这样的视觉效果,如淡出或模糊,或者采用不同的背景或前景色显示。其他散焦操作可以包括改变散焦文本的字体或字体大小(例如,相对于所识别的部分的文本缩小字体大小,和/或以比所识别的部分相对较不权威的字体样式显示散焦文本)。另外,所标识的部分可以显示在文本框内或加下划线,而散焦文本从文本框中排除或不带下划线显示。其他散焦效果也是可能的。
[0138]
将理解的是,图9所示的步骤旨在说明根据示例实施例的方法。这样,可以改变或修改各种步骤,可以改变某些步骤的顺序以及可以添加额外的步骤,同时仍然实现整体期望的操作。该方法可以由客户端设备、或者由服务器、或者由客户端设备和服务器的组合来执行。该方法可以由任何合适的计算设备来执行。
[0139]
结论
[0140]
本文已经通过示例描述了说明性实施例。然而,本领域技术人员将会理解,在不脱
离权利要求所限定的该实施例所针对的元件、产品和方法的真实范围和精神的情况下,可以对该实施例进行改变和修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1