用于舒适噪声生成模式选择的装置和方法与流程
本申请是申请日为2015年7月16日、申请号为201580040583.3的中国发明专利申请“用于舒适噪声生成模式选择的装置和方法”的分案申请。
本发明涉及音频信号编码、处理和解码,特别地涉及一种用于舒适噪声生成模式选择的装置和方法。
背景技术:
通信语音和音频编解码器(例如amr-wb,g.718)通常包括不连续传输(dtx)机制和舒适噪声生成(cng)算法。dtx/cng操作被用于通过在非活动信号时段期间模拟背景噪声来降低传输率。
cng可以例如以若干方式来实现。
最常用的方法,如在amr-wb(itu-tg.722.2附录a)和g.718(itu-tg.718第6.12和7.12节)的编解码器中采用的方法,基于激励+线性预测(lp)模型。首先生成随机激励信号,然后通过增益进行缩放,最后使用lp逆滤波器进行合成,从而产生时域cng信号。被传输的两个主要参数是激励能量和lp系数(通常使用lsf或isf表示)。这种方法在本文中称为lp-cng。
另一种方法是最近提出的并描述在例如专利申请wo2014/096279“generationofacomfortnoisewithhighspectro-temporalresolutionindiscontinuoustransmissionofaudiosignals”中,该方法基于背景噪声的频域(fd)表示。在频域上产生(例如fft,mdct,qmf)随机噪声,然后使用背景噪声的fd表示进行塑形,最后从频域转换到时域,从而产生时域cng信号。被传输的两个主要参数是全局增益和一组频带噪声电平。这种方法在本文中称为fd-cng。
技术实现要素:
本发明的目的是提供用于舒适噪声生成的改善构思。本发明的目的通过根据权利要求1所述的装置、根据权利要求10所述的装置、根据权利要求13所述的系统、根据权利要求14所述的方法、根据权利要求15所述的方法、根据权利要求16所述的计算机程序来解决。
提供了一种用于对音频信息进行编码的装置。所述用于对音频信息进行编码的装置包括:选择器,用于根据音频输入信号的背景噪声特性,从两个或更多个舒适噪声生成模式中选择舒适噪声生成模式;以及,编码单元,用于对所述音频信息进行编码,其中所述音频信息包括指示所选的舒适噪声生成模式的模式信息。
特别地,实施例基于以下发现:fd-cng对于高度倾斜的背景噪声信号(例如,汽车噪声)给出较好的质量;而lp-cng对于频谱上较平坦的背景噪声信号(办公室噪音)给出较好的质量。
为了从dtx/cng系统获得最佳可能质量,根据实施例,两种cng方法都被使用,并且根据背景噪声特性来选择其中之一。
实施例提供了选择器,其决定应当使用哪种cng模式,如lp-cng或fd-cng。
根据实施例,该选择器可以例如被配置为:将音频输入信号的背景噪声的倾斜确定为背景噪声特性。选择器可以例如被配置为:根据所确定的倾斜,从两个或更多个舒适噪声生成模式中选择所述舒适噪声生成模式。
在实施例中,所述装置可以例如还包括噪声估计器,其用于针对多个频带中的每个频带估计背景噪声的每频带估计。选择器可以例如被配置为根据所述多个频带的估计的背景噪声来确定倾斜。
根据实施例,噪声估计器可以例如被配置为:通过估计多个频带中的每个频带的背景噪声的能量来估计背景噪声的每频带估计。
在实施例中,噪声估计器可以例如被配置为:根据多个频带中的第一组中的每个频带的背景噪声的每频带估计,确定指示所述多个频带中的第一组的第一背景噪声能量的低频背景噪声值。
而且,在这样的实施例中,噪声估计器可以例如被配置为:根据多个频带中的第二组中的每个频带的背景噪声的每频带估计,确定指示所述多个频带中的第二组的第二背景噪声能量的高频背景噪声值。所述第一组中的至少一个频带可以例如具有比所述第二组中的至少一个频带的中心频率低的中心频率。在特定实施例中,第一组的每个频带可以例如具有比第二组的每个频带的中心频率低的中心频率。
此外,选择器可以例如被配置为:根据低频背景噪声值和高频背景噪声值来确定倾斜。
根据实施例,噪声估计器可以例如被配置为按照下式确定所述低频背景噪声值l:
其中i表示第一组频带中的第i个频带,11表示所述多个频带中的第一频带,i2表示所述多个频带中的第二频带,以及n[i]表示第i个频带的背景噪声能量的能量估计。
在实施例中,噪声估计器可以例如被配置为按照下式确定所述高频背景噪声值h:
其中i表示第二组频带中的第i个频带,i3表示所述多个频带中的第三频带,i4表示所述多个频带中的第四频带,以及n[i]表示第i个频带的背景噪声能量的能量估计。
根据实施例,选择器可以例如被配置为:
按照公式
按照公式
按照公式t=l-h,或者
按照公式t=h-l,
根据所述低频背景噪声值l和所述高频背景噪声值h来确定倾斜t。
在实施例中,选择器可以例如被配置为将倾斜确定为当前短期倾斜值。而且,选择器可以例如被配置为根据当前短期倾斜值和先前的长期倾斜值来确定当前长期倾斜值。此外,选择器可以例如被配置为根据当前长期倾斜值选择两个或更多个舒适噪声生成模式之一。
根据实施例,选择器可以例如被配置为按照下述公式确定当前长期倾斜值tclt:
tclt=αtplt+(1-α)t,
其中,t是当前短期倾斜值,tplt是所述先前的长期倾斜值,以及α是实数,且0<α<1。
在实施例中,所述两个或更多个舒适噪声生成模式中的第一个可以例如是频域舒适噪声生成模式。而且,所述两个或更多个舒适噪声生成模式中的第二个可以例如是线性预测域舒适噪声生成模式。此外,选择器可以例如被配置为:如果先前选择的生成模式(由选择器先前选择的)是线性预测域舒适噪声生成模式并且当前长期倾斜值大于第一阈值,则选择频域舒适噪声生成模式。而且,选择器可以例如被配置为:如果先前选择的生成模式(由选择器先前选择的)是频域舒适噪声生成模式并且当前长期倾斜值小于第二阈值,则选择线性预测域舒适噪声生成模式。
而且,提供了一种用于基于接收的编码音频信息生成音频输出信号的装置。所述装置包括:解码单元,用于对编码音频信息进行解码以获得在所述编码音频信息内编码的模式信息,其中所述模式信息指示两个或更多个舒适噪声生成模式中的所指示的舒适噪声生成模式。而且,所述装置包括:信号处理器,用于通过根据所指示的舒适噪声生成模式生成舒适噪声来生成所述音频输出信号。
根据实施例,所述两个或更多个舒适噪声生成模式中的第一个可以例如是频域舒适噪声生成模式。信号处理器可以例如被配置为:如果所指示的舒适噪声生成模式是频域舒适噪声生成模式,则在频域中生成舒适噪声,并且对在频域中生成的所述舒适噪声进行频率到时间的转换。例如,在特定实施例中,信号处理器可以例如被配置为:如果所指示的舒适噪声生成模式是频域舒适噪声生成模式,则通过在频域中生成随机噪声,对频域中的所述随机噪声进行塑形以获得塑形后的噪声,以及将塑形后的噪声从频域转换到时域,来生成舒适噪声。
在实施例中,所述两个或更多个舒适噪声生成模式中的第二个可以例如是线性预测域舒适噪声生成模式。信号处理器可以例如被配置为:如果所指示的舒适噪声生成模式是线性预测域舒适噪声生成模式,则通过使用线性预测滤波器来生成所述舒适噪声。例如,在特定实施例中,信号处理器可以例如被配置为:如果所指示的舒适噪声生成模式是线性预测域舒适噪声生成模式,则通过生成随机激励信号,对所述随机激励信号进行缩放以获得缩放后的激励信号,以及使用lp逆滤波器合成缩放后的激励信号,来生成舒适噪声。
此外,提供了一种系统。所述系统包括:根据上述实施例之一的用于对音频信息进行编码的装置,根据上述实施例之一的用于基于接收的编码音频信息生成音频输出信号的装置。所述用于对音频信息进行编码的装置的选择器被配置为:根据音频输入信号的背景噪声特性从两个或更多个舒适噪声生成模式中选择舒适噪声生成模式。所述用于对音频信息进行编码的装置的编码单元被配置为:对所述音频信息进行编码以获得编码音频信息,其中所述音频信息包括将所选的舒适噪声生成模式指示为所指示的舒适噪声生成模式的模式信息。而且,所述用于生成音频输出信号的装置的解码单元被配置为接收所述编码音频信息,并且还被配置为对所述编码音频信息进行解码以获得在所述编码音频信息内编码的模式信息。所述用于生成音频输出信号的装置的信号处理器被配置为:通过根据所指示的舒适噪声生成模式生成舒适噪声来生成所述音频输出信号。
而且,提供了一种用于对音频信息进行编码的方法。所述方法包括:
-根据音频输入信号的背景噪声特性从两个或更多个舒适噪声生成模式中选择舒适噪声生成模式;以及
-对所述音频信息进行编码,其中所述音频信息包括指示所选的舒适噪声生成模式的模式信息。
此外,提供了一种用于基于接收的编码音频信息生成音频输出信号的方法。所述方法包括:
-对所述编码音频信息进行解码以获得在所述编码音频信息内编码的模式信息,其中所述模式信息指示两个或更多个舒适噪声生成模式中的所指示的舒适噪声生成模式,以及
-通过根据所指示的舒适噪声生成模式生成舒适噪声来生成所述音频输出信号。
而且,提供了一种用于当在计算机或信号处理器上执行时实现上述方法的计算机程序。
因此,在一些实施例中,所提出的选择器可以例如主要基于背景噪声的倾斜。例如,如果背景噪声的倾斜为高,则选择fd-cng,否则选择lp-cng。
背景噪声倾斜和滞后的平滑版本可被例如用于避免经常从一种模式切换到另一种模式。
背景噪声的倾斜可以例如使用低频背景噪声能量和高频背景噪声能量的比来估计。
背景噪声能量可以例如使用噪声估计器在频域中估计。
附图说明
在下文中,将参考附图更详细地描述本发明的实施例,在附图中:
图1示出了根据实施例的用于对音频信息进行编码的装置,
图2示出了根据另一实施例的用于对音频信息进行编码的装置,
图3示出了根据实施例的用于选择舒适噪声生成模式的逐步方法,
图4示出了根据实施例的用于基于接收的编码音频信息生成音频输出信号的装置,以及
图5示出了根据实施例的系统。
具体实施方式
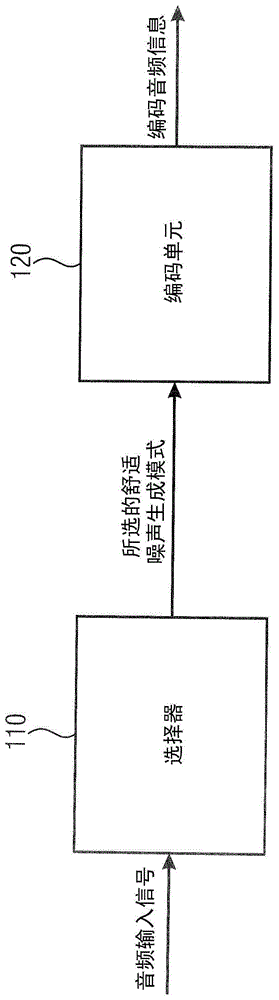
图1示出了根据实施例的用于对音频信息进行编码的装置。
用于对音频信息进行编码的装置包括:选择器110,用于根据音频输入信号的背景噪声特性从两个或更多个舒适噪声生成模式中选择舒适噪声生成模式。
而且,该装置包括:编码单元120,用于对音频信息进行编码,其中,音频信息包括指示所选的舒适噪声生成模式的模式信息。
例如,所述两个或更多个舒适噪声生成模式中的第一个可以例如是频域舒适噪声生成模式。以及/或者,例如,所述两个或更多个生成模式中的第二个可以例如是线性预测域舒适噪声生成模式。
例如,如果在解码器侧接收到编码音频信息,其中在编码音频信息内编码的模式信息指示所选的舒适噪声生成模式是频域舒适噪声生成模式,则解码器侧的信号处理器可以例如通过下述方式来生成舒适噪声:在频域中生成随机噪声,对频域中的所述随机噪声进行塑形以获得塑形后的噪声,以及将塑形后的噪声从频域转换到时域。
然而,如果例如在编码音频信息内编码的模式信息指示所选的舒适噪声生成模式是线性预测域舒适噪声生成模式,则解码器侧的信号处理器可以例如通过下述方式来生成舒适噪声:生成随机激励信号,对所述随机激励信号进行缩放以获得缩放后的激励信号,以及使用lp逆滤波器合成缩放后的激励信号。
在编码音频信息内,不仅可以编码关于舒适噪声生成模式的信息,还可以编码附加信息。例如,频带特定的增益因子也可被编码,例如,其中针对每个频带编码一个增益因子。或者,例如,一个或多个lp滤波器系数或lsf系数或isf系数可被编码在编码音频信息内。被编码在编码音频信息内的关于所选的舒适噪声生成模式的信息和附加信息于是可被传输给解码器侧,例如在sid帧(sid=静音插入描述符)内传输。
关于所选的舒适噪声生成模式的信息可被显式地编码或隐式地编码。
当对所选的舒适噪声生成模式进行显式编码时,可以例如使用一个或多个比特来指示所选的舒适噪声生成模式是两个或更多个舒适噪声生成模式中的哪一个。在这样的实施例中,于是所述一个或多个比特是编码的模式信息。
然而,在其他实施例中,所选的舒适噪声生成模式被隐式地编码在音频信息内。例如,在上述示例中,频带特定的增益因子和一个或多个lp(或lsf或isf)可以例如具有不同的数据格式,或者可以例如具有不同的比特长度。例如,如果频带特定的增益因子被编码在音频信息内,这可以例如指示频域舒适噪声生成模式是所选的舒适噪声生成模式。然而,如果一个或多个lp(或lsf或isf)系数被编码在音频信息内,这可以例如指示线性预测域舒适噪声生成模式是所选的舒适噪声生成模式。当使用这种隐式编码时,频带特定的增益因子或一个或多个lp(或lsf或isf)系数于是表示被编码在编码音频信号内的模式信息,其中该模式信息指示所选的舒适噪声生成模式。
根据实施例,选择器110可以例如被配置为将音频输入信号的背景噪声的倾斜确定为背景噪声特性。选择器110可以例如被配置为:根据所确定的倾斜从两个或更多个舒适噪声生成模式中选择所述舒适噪声生成模式。
例如,可以利用低频背景噪声值和高频背景噪声值,并且可以例如根据低频背景噪声值和高频背景噪声值来计算背景噪声的倾斜。
图2示出了根据另一实施例的用于对音频信息进行编码的装置。图2的装置还包括:噪声估计器105,用于估计多个频带中的每个频带的背景噪声的每频带估计。选择器110可以例如被配置为根据多个频带的估计的背景噪声来确定倾斜。
根据实施例,噪声估计器105可以例如被配置为:通过估计多个频带中的每个频带的背景噪声的能量来估计背景噪声的每频带估计。
在实施例中,噪声估计器105可以例如被配置为:根据多个频带中的第一组中的每个频带的背景噪声的每频带估计,确定指示所述多个频带中的第一组的第一背景噪声能量的低频背景噪声值。
而且,噪声估计器105可以例如被配置为:根据多个频带中的第二组中的每个频带的背景噪声的每频带估计,确定指示所述多个频带中的第二组的第二背景噪声能量的高频背景噪声值。所述第一组中的至少一个频带可以例如具有比所述第二组中的至少一个频带的中心频率低的中心频率。在特定实施例中,第一组的每个频带可以例如具有比第二组的每个频带的中心频率低的中心频率。
此外,选择器110可以例如被配置为:根据低频背景噪声值和高频背景噪声值来确定倾斜。
根据实施例,噪声估计器105可以例如被配置为按照下式确定所述低频背景噪声值l:
其中i表示第一组频带中的第i个频带,i1表示所述多个频带中的第一频带,i2表示所述多个频带中的第二频带,以及n[i]表示第i个频带的背景噪声能量的能量估计。
类似地,在实施例中,噪声估计器105可以例如被配置为按照下式确定所述高频背景噪声值h:
其中i表示第二组频带中的第i个频带,i3表示所述多个频带中的第三频带,i4表示所述多个频带中的第四频带,以及n[i]表示第i个频带的背景噪声能量的能量估计。
根据实施例,选择器110可以例如被配置为:
按照公式
按照公式
按照公式t=l-h,或者
按照公式t=h-l,
根据所述低频背景噪声值l和所述高频背景噪声值h来确定倾斜t。
例如,当l和h在对数域中表示时,可以采用减法公式之一(t=l-h或t=h-l)。
在实施例中,选择器110可以例如被配置为:将倾斜确定为当前短期倾斜值。而且,选择器110可以例如被配置为根据当前短期倾斜值和先前的长期倾斜值来确定当前长期倾斜值。此外,选择器110可以例如被配置为根据当前长期倾斜值选择两个或更多个舒适噪声生成模式之一。
根据实施例,选择器110可以例如被配置为按照下述公式确定当前长期倾斜值tclt:
tclt=αtplt+(1-α)t,
其中,t是当前短期倾斜值,tplt是所述先前的长期倾斜值,以及α是实数,且0<α<1。
在实施例中,所述两个或更多个舒适噪声生成模式中的第一个可以例如是频域舒适噪声生成模式fd_cng。而且,所述两个或更多个舒适噪声生成模式中的第二个可以例如是线性预测域舒适噪声生成模式lp_cng。此外,选择器110可以例如被配置为:如果先前选择的生成模式cng_mode_prev(由选择器110先前选择的)是线性预测域舒适噪声生成模式lp_cng并且当前长期倾斜值大于第一阈值thr1,则选择频域舒适噪声生成模式fd_cng。而且,选择器110可以例如被配置为:如果先前选择的生成模式cng_mode_prev(由选择器110先前选择的)是频域舒适噪声生成模式fd_cng并且当前长期倾斜值小于第二阈值thr2,则选择线性预测域舒适噪声生成模式fd_cng。
在一些实施例中,第一阈值等于第二阈值。然而,在另一些实施例中,第一阈值不等于第二阈值。
图4示出了根据实施例的基于接收的编码音频信息生成音频输出信号的装置。
该装置包括:解码单元210,用于对编码音频信息进行解码以获得在编码音频信息内编码的模式信息。该模式信息指示两个或更多个舒适噪声生成模式中的所指示的舒适噪声生成模式。
而且,该装置包括:信号处理器220,用于通过根据所指示的舒适噪声生成模式生成舒适噪声来生成音频输出信号。
根据实施例,两个或更多个舒适噪声生成模式中的第一个可以例如是频域舒适噪声生成模式。信号处理器220可以例如被配置为:如果所指示的舒适噪声生成模式是频域舒适噪声生成模式,则在频域中生成舒适噪声,并且对在频域中生成的所述舒适噪声进行频率到时间的转换。例如,在特定实施例中,信号处理器可以例如被配置为:如果所指示的舒适噪声生成模式是频域舒适噪声生成模式,则通过在频域中生成随机噪声,对频域中的所述随机噪声进行塑形以获得塑形后的噪声,以及将塑形后的噪声从频域转换到时域,来生成舒适噪声。
例如,可以采用wo2014/096279a1中描述的概念。
例如,可以应用随机生成器来通过生成一个或多个随机序列以在fft域和/或qmf(fft=快速傅立叶变换;qmf=正交镜像滤波器)域中激励每个单独的频谱带。随机噪声的塑形可以例如通过分别计算每个频带中的随机序列的幅度来进行,使得所生成的舒适噪声的频谱类似于例如在比特流中存在的实际背景噪声的频谱,所述比特流包括例如音频输入信号。于是,例如,所计算的幅度可以例如被应用于随机序列,例如通过将随机序列与所计算的每个频带中的幅度相乘。然后,可采用将塑形后的噪声从频域转换到时域。
在实施例中,两个或更多个舒适噪声生成模式中的第二个可以例如是线性预测域舒适噪声生成模式。信号处理器220可以例如被配置为:如果所指示的舒适噪声生成模式是线性预测域舒适噪声生成模式,则通过使用线性预测滤波器来生成所述舒适噪声。例如,在特定实施例中,信号处理器可以例如被配置为:如果所指示的舒适噪声生成模式是线性预测域舒适噪声生成模式,则通过生成随机激励信号,对所述随机激励信号进行缩放以获得缩放后的激励信号,以及使用lp逆滤波器合成缩放后的激励信号,来生成舒适噪声。
例如,可以采用如g.722.2(参见itu-tg.722.2附录a)和/或如g.718(参见itu-tg.718第6.12和7.12节)中描述的舒适噪声生成。通过缩放随机激励信号以获得缩放后的激励信号以及使用lp逆滤波器合成缩放后的激励信号实现的这种随机激励域的舒适噪声生成对于本领域技术人员而言是公知的。
图5示出了根据实施例的系统。该系统包括:根据上述实施例之一的用于对音频信息进行编码的装置100;以及,根据上述实施例之一的用于基于接收的编码音频信息生成音频输出信号的装置200。
用于对音频信息进行编码的装置100的选择器110被配置为:根据音频输入信号的背景噪声特性从两个或更多个舒适噪声生成模式中选择舒适噪声生成模式。用于对音频信息进行编码的装置100的编码单元120被配置为:对音频信息进行编码以获得编码音频信息,其中所述音频信息包括将所选的舒适噪声生成模式指示为所指示的舒适噪声生成模式的模式信息。
而且,用于生成音频输出信号的装置200的解码单元210被配置为接收编码音频信息,并且还被配置为对编码音频信息进行解码以获得在编码音频信息内编码的模式信息。用于生成音频输出信号的装置200的信号处理器220被配置为:通过根据所指示的舒适噪声生成模式生成舒适噪声来生成音频输出信号。
图3示出了根据实施例的用于选择舒适噪声生成模式的逐步方法。
在步骤310中,使用噪声估计器来估计频域中的背景噪声能量。这通常按照每个频带的基础上执行,从而产生每频带的能量估计n[i],其中0≤i<n并且n是频带数目(如n=20)。
可以使用产生背景噪声能量的每频带估计的任何噪声估计器。一个示例是在g.718(itu-tg.718第6.7节)中使用的噪声估计器。
在步骤320中,使用下式计算低频中的背景噪声能量:
其中i1和i2可取决于信号带宽,例如对于nb,i1=1,i2=9,以及对于wb,i1=0,i2=10。
l可被视为上述的低频背景噪声值。
在步骤330中,使用下式计算高频中的背景噪声能量:
其中,i3和i4可取决于信号带宽,例如对于nb,i3=16,i4=17以及对于wb,i3=19,i4=20。
h可被视为上述的高频背景噪声值。
步骤320和330可以例如随后执行或彼此独立地执行。
在步骤340中,使用下式计算背景噪声倾斜
一些实施例可以例如根据步骤350继续进行。在步骤350中,对背景噪声倾斜进行平滑,从而产生背景噪声倾斜的长期版本tlt=αtlt+(1-α)t
其中α例如是0.9。在该递归等式中,等号左侧的tlt是上文提到的当前长期倾斜值tclt,而等号右侧的tlt是上文提到的先前的长期倾斜值tplt。
在步骤360中,使用下述具有滞后的分类器最终选择cng模式:
if(cng_mode_prev==lp_cngandtlt>thr1)thencng_mode=fd_cng
if(cng_mode_prev==fd_cngandtlt<thr2)thencng_mode=lp_cng
其中,thr1和thr2可取决于带宽,例如,对于nb,thr1=9,thr2=2,以及对于wbthr1=45,thr2=10。
cng_mode是选择器110(当前)选择的舒适噪声生成模式。
cng_mode_prev是先前选择的(舒适噪声)生成模式,其是选择器110先前已经选择的。
当没有满足步骤360中的上述条件中的任何一个时会发生什么将取决于实现。在一个实施例中,例如,如果没有满足步骤360中的两个条件中的任何一个,则cng模式可以保持与原来相同,使得
cng_mode=cng_mode_prev。
其他实施例可以实现其他选择策略。
在图3的实施例中,thr1不等于thr2,然而在另一些实施例中,thr1等于thr2。
可以通过以下实施例进一步实现本发明,这些实施例可以与本文描述和要求保护的任何示例和实施例相组合:
1.一种用于对音频信息进行编码的装置,包括:
选择器(110),用于根据音频输入信号的背景噪声特性,从两个或更多个舒适噪声生成模式中选择舒适噪声生成模式;以及
编码单元(120),用于对所述音频信息进行编码,其中所述音频信息包括指示所选的舒适噪声生成模式的模式信息,
其中所述两个或更多个舒适噪声生成模式中的第一个是频域舒适噪声生成模式,并且所述频域舒适噪声生成模式指示:应在频域中生成所述舒适噪声,并且在频域中生成的所述舒适噪声应被执行频率到时间的转换。
2.根据实施例1所述的装置,
其中所述选择器(110)被配置为:将所述音频输入信号的背景噪声的倾斜确定为所述背景噪声特性;以及
其中所述选择器(110)被配置为:根据所确定的倾斜从两个或更多个舒适噪声生成模式中选择所述舒适噪声生成模式。
3.根据实施例2所述的装置,
其中,所述装置还包括:噪声估计器(105),用于针对多个频带中的每个频带估计所述背景噪声的每频带估计;以及
其中,所述选择器(110)被配置为根据所述多个频带的估计的背景噪声来确定所述倾斜。
4.根据实施例3所述的装置,
其中,所述噪声估计器(105)被配置为:根据所述多个频带中的第一组中的每个频带的背景噪声的每频带估计,确定指示所述多个频带中的第一组的第一背景噪声能量的低频背景噪声值,
其中所述噪声估计器(105)被配置为:根据所述多个频带中的第二组中的每个频带的背景噪声的每频带估计,确定指示所述多个频带中的第二组的第二背景噪声能量的高频背景噪声值,其中所述第一组中的至少一个频带具有的中心频率比所述第二组中的至少一个频带的中心频率低,以及
其中所述选择器(110)被配置为:根据所述低频背景噪声值和所述高频背景噪声值来确定所述倾斜。
5.根据实施例4所述的装置,
其中所述噪声估计器(105)被配置为按照下式确定所述低频背景噪声值l:
其中i表示第一组频带中的第i个频带,i1表示所述多个频带中的第一频带,i2表示所述多个频带中的第二频带,以及n[i]表示第i个频带的背景噪声能量的能量估计,
其中所述噪声估计器(105)被配置为按照下式确定所述高频背景噪声值h:
其中i表示第二组频带中的第i个频带,i3表示所述多个频带中的第三频带,i4表示所述多个频带中的第四频带,以及n[i]表示第i个频带的背景噪声能量的能量估计。
6.根据实施例4所述的装置,
其中,所述选择器(110)被配置为:
按照公式
按照公式
按照公式t=l-h,或者
按照公式t=h-l,
根据所述低频背景噪声值l和所述高频背景噪声值h来确定倾斜t。
7.根据实施例2所述的装置,
其中,所述选择器(110)被配置为将所述倾斜确定为当前短期倾斜值(t),
其中,所述选择器(110)被配置为根据当前短期倾斜值和先前的长期倾斜值来确定当前长期倾斜值,
其中,所述选择器(110)被配置为根据当前长期倾斜值选择两个或更多个舒适噪声生成模式之一。
8.根据实施例7所述的装置,
其中,所述选择器(110)被配置为按照下述公式确定当前长期倾斜值tclt:
tclt=αtplt+(1-α)t,
其中
t是当前短期倾斜值,
tplt是所述先前的长期倾斜值,以及
α是实数,且0<α<1。
9.根据实施例7所述的装置,
其中所述两个或更多个舒适噪声生成模式中的第一个是频域舒适噪声生成模式,
其中,所述两个或更多个舒适噪声生成模式中的第二个是线性预测域舒适噪声生成模式,
其中,所述选择器(110)被配置为:如果先前选择的生成模式是线性预测域舒适噪声生成模式并且当前长期倾斜值大于第一阈值,则选择频域舒适噪声生成模式,其中所述先前选择的生成模式是由所述选择器(110)先前选择的,以及
其中所述选择器(110)被配置为:如果先前选择的生成模式是频域舒适噪声生成模式并且当前长期倾斜值小于第二阈值,则选择线性预测域舒适噪声生成模式,其中所述先前选择的生成模式是由所述选择器(110)先前选择的。
10.一种用于基于接收的编码音频信息生成音频输出信号的装置,包括:
解码单元(210),用于对编码音频信息进行解码以获得在所述编码音频信息内编码的模式信息,其中所述模式信息指示两个或更多个舒适噪声生成模式中的所指示的舒适噪声生成模式;以及
信号处理器(220),用于通过根据所指示的舒适噪声生成模式生成舒适噪声来生成所述音频输出信号,
其中所述两个或更多个舒适噪声生成模式中的第一个是频域舒适噪声生成模式,以及
其中所述信号处理器被配置为:如果所指示的舒适噪声生成模式是频域舒适噪声生成模式,则在频域中生成舒适噪声,并且对在频域中生成的所述舒适噪声进行频率到时间的转换。
11.根据实施例10所述的装置,
其中所述两个或更多个舒适噪声生成模式中的第二个是线性预测域舒适噪声生成模式,以及
其中所述信号处理器(220)被配置为:如果所指示的舒适噪声生成模式是线性预测域舒适噪声生成模式,则通过使用线性预测滤波器来生成所述舒适噪声。
12.一种系统,包括:
根据实施例1至9之一所述的用于对音频信息进行编码的装置(100),
根据实施例10或11所述的用于基于接收的编码音频信息生成音频输出信号的装置(200),
其中根据实施例1至9之一所述的装置(100)的选择器(110)被配置为:根据音频输入信号的背景噪声特性从两个或更多个舒适噪声生成模式中选择舒适噪声生成模式,
其中根据实施例1至9之一所述的装置(100)的编码单元(120)被配置为:对所述音频信息进行编码以获得编码音频信息,其中所述音频信息包括将所选的舒适噪声生成模式指示为所指示的舒适噪声生成模式的模式信息,
其中,根据实施例10或11所述的装置(200)的解码单元(210)被配置为接收所述编码音频信息,并且还被配置为对所述编码音频信息进行解码以获得在所述编码音频信息内编码的模式信息,以及
其中,根据实施例10或11所述的装置(200)的信号处理器(220)被配置为:通过根据所指示的舒适噪声生成模式生成舒适噪声来生成所述音频输出信号。
13.一种用于对音频信息进行编码的方法,包括:
根据音频输入信号的背景噪声特性从两个或更多个舒适噪声生成模式中选择舒适噪声生成模式;以及
对所述音频信息进行编码,其中所述音频信息包括指示所选的舒适噪声生成模式的模式信息,
其中所述两个或更多个舒适噪声生成模式中的第一个是频域舒适噪声生成模式,并且所述频域舒适噪声生成模式指示:应在频域中生成所述舒适噪声,并且在频域中生成的所述舒适噪声应被执行频率到时间的转换。
14.一种用于基于接收的编码音频信息生成音频输出信号的方法,包括:
对所述编码音频信息进行解码以获得在所述编码音频信息内编码的模式信息,其中所述模式信息指示两个或更多个舒适噪声生成模式中的所指示的舒适噪声生成模式,以及
通过根据所指示的舒适噪声生成模式生成舒适噪声来生成所述音频输出信号,
其中所述两个或更多个舒适噪声生成模式中的第一个是频域舒适噪声生成模式,以及
其中所述信号处理器被配置为:如果所指示的舒适噪声生成模式是频域舒适噪声生成模式,则在频域中生成舒适噪声,并且对在频域中生成的所述舒适噪声进行频率到时间的转换。
15.一种计算机可读介质,存储有用于当在计算机或信号处理器上执行时实现根据实施例13或14所述的方法的计算机程序。
虽然已经在装置的上下文中描述了一些方面,但是将清楚的是,这些方面还表示对相应方法的描述,其中,框或设备对应于方法步骤或方法步骤的特征。类似地,在方法步骤的上下文中描述的方案也表示对相应块或项或者相应装置的特征的描述。
新颖的解构信号可以存储在数字存储介质上,或者可以在诸如无线传输介质或有线传输介质(例如,互联网)等的传输介质上传输。
取决于某些实现要求,可以在硬件中或在软件中实现本发明的实施例。可以使用其上存储有电子可读控制信号的数字存储介质(例如,软盘、dvd、cd、rom、prom、eprom、eeprom或闪存)来执行该实现,该电子可读控制信号与可编程计算机系统协作(或者能够与之协作)从而执行相应方法。
根据本发明的一些实施例包括具有电子可读控制信号的非瞬时数据载体,该电子可读控制信号能够与可编程计算机系统协作从而执行本文所述的方法之一。
通常,本发明的实施例可以实现为具有程序代码的计算机程序产品,程序代码可操作以在计算机程序产品在计算机上运行时执行方法之一。程序代码可以例如存储在机器可读载体上。
其他实施例包括存储在机器可读载体上的计算机程序,该计算机程序用于执行本文所述的方法之一。
换言之,本发明方法的实施例因此是具有程序代码的计算机程序,该程序代码用于在计算机程序在计算机上运行时执行本文所述的方法之一。
因此,本发明方法的另一实施例是其上记录有计算机程序的数据载体(或者数字存储介质或计算机可读介质),该计算机程序用于执行本文所述的方法之一。
因此,本发明方法的另一实施例是表示计算机程序的数据流或信号序列,所述计算机程序用于执行本文所述的方法之一。数据流或信号序列可以例如被配置为经由数据通信连接(例如,经由互联网)传送。
另一实施例包括处理装置,例如,计算机或可编程逻辑器件,所述处理装置被配置为或适于执行本文所述的方法之一。
另一实施例包括其上安装有计算机程序的计算机,该计算机程序用于执行本文所述的方法之一。
在一些实施例中,可编程逻辑器件(例如,现场可编程门阵列)可以用于执行本文所述的方法的功能中的一些或全部。在一些实施例中,现场可编程门阵列可以与微处理器协作以执行本文所述的方法之一。通常,方法优选地由任意硬件装置来执行。
上述实施例对于本发明的原理仅是说明性的。应当理解的是:本文所述的布置和细节的修改和变形对于本领域其他技术人员将是显而易见的。因此,旨在仅由所附专利权利要求的范围来限制而不是由借助对本文的实施例的描述和解释所给出的具体细节来限制。
- 还没有人留言评论。精彩留言会获得点赞!