一种语音信号未知情绪状态识别方法
1.本发明属于语音信号情绪识别领域,特别是涉及一种语音信号未知情绪状态识别方法。
背景技术:
2.语音情绪识别(speech emotion recognition;简称ser)在人机交互等领域有着广泛的应用背景,可以通过研究语音信号中的情绪信息,判断说话人在语音段中所需要传达的主观意图,以及说话人更深层次的情绪表达。除此之外,还能够通过分析语音中的情绪信息,针对语音信号进行情绪表达的语音合成。在心理疾病诊断方面,可以通过相关技术实现对抑郁症等病人的初步筛查,并为进一步诊断和治疗提供依据;在虚拟现实方面,能够使得机器人具有更强大的情感分析和表达能力。
3.现有技术方案存在着无法有效识别语音信号中未知情绪状态的问题,在与ser相关的大量现有工作中,都无法对一种在训练样本中从未见过的情绪状态进行认知,因此无法对语音信号样本进行未知情绪类别的判断识别。例如在人机交互中,机器可能会在接收到话语时决定说话人是可信的、友好的,还是暴力的等复杂情绪。然而,如果不教它如何估计这些说话人复杂的情绪或意图,机器将无法完成这项任务。
4.而已有针对语音信号中未知情绪成分进行识别的方案中,例如公开文献:xu x,deng j,cummins n,et al.autonomous emotion learning in speech:aview ofzero
‑
shot speech emotion recognition[c]//proc.interspeech 2019,2019:949
‑
953。公开的识别方案中,需要对已知情绪样本的训练中各样本对应的情绪空间维度值进行标注,这一过程可能带来高额的人工工作量和标注成本,同时增加了计算过程的复杂性。
技术实现要素:
[0005]
针对现有技术中无法识别语音信号中未知情绪的问题,以及已有识别语音信号未知情绪方案中,需要对已知情绪样本进行各样本情绪空间各维度标注的问题,本发明提出一种语音信号未知情绪状态识别方法。
[0006]
为解决上述技术问题,本发明采用以下技术方案:
[0007]
一种语音信号未知情绪状态识别方法,首先建立语音情绪数据库,其中包括若干语段样本,每个样本有其对应的情绪类别标签;将语音情绪数据库划分为已知情绪类别样本所组成的训练集,以及未知情绪类别样本所组成的测试集;每个样本都拥有已知且唯一的情绪类别标签。该方法包括顺序执行以下步骤:
[0008]
步骤一、提取生成n
f
维原始特征:对训练样本集和测试样本集中的每个语段样本,分别经过处理,提取出对应的副语言特征,作为原始特征,并对原始特征做规整化处理,得到n
(s)
个训练样本对应的规整化特征以及任一测试样本对应的规整化特征x
(u)
;
[0009]
步骤二、对已知情绪类别名称进行语义嵌入映射,生成各已知情绪类别语义嵌入
原型其中c
(s)
为已知情绪类别数,n
a
为情绪类别名称的语义嵌入维数;
[0010]
步骤三、由已知情绪类别原型矩阵a
(s)
,以及虚拟类别原型矩阵计算得到已知情绪类别原型权重矩阵
[0011]
步骤四、使用已知情绪类别语段样本副语言特征x
(s)
及其对应样本的情绪类别标签已知情绪类别语义嵌入原型a
(s)
、情绪类别原型权重矩阵s,按优化目标f对线型虚拟分类器进行优化:
[0012][0013]
求得最优虚拟分类器
[0014]
步骤五、测试:对于每个未知情绪类别语段测试样本特征x
(u)
,使用经步骤四得到的分类器对每个测试样本进行未知情绪类别的分类判决。
[0015]
进一步的,步骤一中的规范化处理的方法如下:
[0016]
规整化前的所有语段样本中的任一样本的特征列向量为x
(0)
,其中n
(s)
个已知情绪类别训练样本的特征列向量组成的训练样本集为设为的第j个特征元素;
[0017]
对于任一样本的特征列向量x
(0)
,特征j对应元素的规整化处理的计算公式为:
[0018][0019]
其中表示x
(0)
第j行中最大的元素,表示x
(0)
第j行中最小的元素;x
·
j
为规整化处理后的结果;
[0020]
将任一样本中的所有的元素按照式(2)进行计算,得到任一训练或测试样本规整化后的特征列向量x=[x
·1,x
·2,...,x
·
n
]
t
,其中,属于已知情绪类别训练样本集的语段信号样本的规整化后的特征向量组成训练样本的规整化特征向量集
[0021]
进一步的,步骤二中所述语义嵌入映射可通过对情绪类别名称使用词向量预训练模型实现:
[0022]
通过向预训练输入情绪类别名称,得到该类别对应的n
a
维的情绪类别语义嵌入向量,对训练集对应的已知情绪类别,其语义嵌入向量表示为对测试样本集中待预测的c
(u)
个未知情绪类别,其语义嵌入向量表示为
[0023]
进一步的,步骤三中所述已知情绪类别原型权重矩阵中虚拟类别c
p
、已知情绪类别c
s
对应的元素为:
[0024][0025]
其中间的距离测度其中σ2为距离权重。
[0026]
进一步的,步骤三中所述虚拟类别原型矩阵b的构建可选择以下两种方式:
[0027]
(1)按0
‑
1间均匀分布,随机生成n
a
×
c(
p
)维的矩阵;
[0028]
(2)设置为已知情绪类别语义嵌入矩阵a
(s)
。
[0029]
进一步的,步骤四中求取最优虚拟分类器的优化目标为:
[0030][0031]
其中,正则化项权重τ>0,已知情绪类别线性分类器:
[0032][0033]
损失函数:
[0034][0035]
其中,为第c个已知情绪类别标签信息,当时,否则
[0036]
进一步的,步骤五中所述对未知情绪类别测试样本的分类判决包括顺序执行的以下步骤:
[0037]
(1)根据计算未知情绪类别语义嵌入原型计算类别m的情绪类别原型权重向量
[0038][0039]
(2)对测试样本对应的副语言特征x
(u)
,预测该样本所属未知情绪类别对应的标号
[0040][0041]
即得到对测试样本的未知情绪类别判决结果。
[0042]
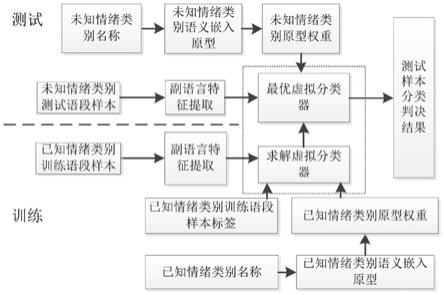
有益效果:如图1所示,本发明提供的一种语音信号未知情绪状态识别方法,对带有未知情绪状态信息的语段信号样本进行副语言特征提取,并结合情绪状态标签的语义嵌入,通过合成分类器的方法进行分类判决。具体地,在训练阶段首先对已知情绪类别训练语段样本提取副语言特征,同时根据已知情绪类别名称处理得到已知情绪类别原型权重,进而结合已知情绪类别训练语段样本标签,求解得到最优虚拟分类器;在测试阶段使用最优虚拟分类器,结合未知情绪类别测试语段样本的副语言特征,以及未知情绪类别原型权重,对测试样本进行未知情绪类别判决。
[0043]
现有的语音情绪识别方法中存在两个问题:对于一般的ser方法,仅能够用于识别训练集中提供样本的情绪类别,而对未知类别的识别处理存在问题;已有针对语音信号未知情绪识别的工作中虽然给出了解决方案,但该方案的顺利执行仍依赖于对训练样本情绪空间各维度的充分标注。
[0044]
因此,本发明一种语音信号未知情绪状态识别方法中采用基于合成分类器和语义嵌入的语音信号未知情绪状态识别方法,能够在不增加人工标注成本的基础上,为语音信号中未知情绪的认知提供帮助,从而实现对语音中未知情绪的有效识别。
[0045]
通过实验证明,本发明在语音信号情感识别方面基于语义嵌入提出了识别未知情绪语音信号的方法,能够针对语音信号有效地分辨出未知情绪。
附图说明
[0046]
图1为本发明的一种语音信号未知情绪状态识别方法流程图。
具体实施方式
[0047]
下面结合附图及具体实施方式对本发明作更进一步的说明。
[0048]
如图1所示,本发明方法首先对带有未知情绪状态信息的语段信号样本进行副语言特征提取,并结合情绪状态标签的语义嵌入,通过合成分类器的方法进行分类判决。在训练阶段首先对已知情绪类别训练语段样本提取副语言特征,同时根据已知情绪类别名称处理得到已知情绪类别原型权重,进而结合已知情绪类别训练语段样本标签,求解得到最优虚拟分类器;在测试阶段使用最优虚拟分类器,结合未知情绪类别测试语段样本的副语言特征,以及未知情绪类别原型权重,对测试样本进行未知情绪类别判决。
[0049]
下面对通过实验的方法将本发明的方法与现有零样本学习方法进行不加权精度
(unweighted accuracy;ua)识别率对比。
[0050]
实验采用gemep(geneva multimodal emotion portrayals)数据库中的语音信号部分对本发明实施例的方法进行有效性验证。
[0051]
双模态数据库gemep包含语音样本集及其对应的视频样本集gemep
‑
fera。数据库共含有18个情绪类别,即admiration、amusement、anxiety、coldanger、contempt、despair、disgust、elation、hot anger、interest、panic fear、pleasure、pride、relief、sadness、shame、surprise、tenderness。数据库用法语录制,共1260个样本,分属于10个说话人,其中包括5个女性。本次实验使用其中的12类情绪类别,具体为amusement、anxiety、cold anger、despair、elation、hot anger、interest、panic fear、pleasure、pride、relief、sadness,平均每类90个样本,共1080个样本;数据集按每两类情绪的所有样本作为未知情绪测试语段样本集,其他情绪类别样本作为已知情绪训练语段样本集,不同的样本类型组合方式有66种,因此,本次实验共进行训练测试66次。
[0052]
实验的原始副语言特征采用日内瓦简约声学参数集(extended geneva minimalistic acoustic parameter set;egemaps)特征集,原始特征维数n
f
=88,特征来源于结合高级统计函数(high
‑
level statistic functionals;hsfs)的25个低级描述符(low
‑
level descriptors;llds),以及时态特征和等效声级,具体的本次实验中采用opensmile 2.3工具箱提取这些特征。
[0053]
情绪类别的语义嵌入原型使用n
a
=300维的英语单词语义向量,这些原型是基于word2vec、glove和fasttext的预训练模型得到的。实验中的语义嵌入模型是google预训练的word2vec模型,该模型是在包含300万个单词的google news语料库上训练的;实验中的glove模型使用wikipedia 2014和gigaword 5作为训练数据,包含40万个词;fasttext分别使用基于网络爬取数据上训练的200万个单词向量和在wikipedia 2017、umbc webbase和statmt.org news数据集上训练得到的100万个词向量。
[0054]
实验中,为了体现本发明方法的效果,用于进行比较的方法分别为:sae(semantic autoencoder)、dem(deep embedding model;dem)、latem(latent embedding)、eszsl(embarrassingly simple zero
‑
shot learning)、exem(exemplar synthesis)的识别模型。
[0055]
本发明的语音信号情绪状态识别模型包括两种,分别为:sync(origin)(实施例1,采用已知情绪类别原型作为步骤三中虚拟类别原型矩阵b,即b=a
(s)
)、sync(rand)(实施例2,采用已知情绪类别原型作为步骤三中虚拟类别原型矩阵b,其中虚拟类别数c
(p)
=1000)。
[0056]
实验中对训练集采用情绪类别独立的五折交叉验证进行最优参数选取,实验时步骤三中对虚拟类别原型的随机生成重复实验10次。其中对于本发明实施例,选取参数的范围为:正则化项权重τ={2
‑
24
,2
‑
23
,
…
,2
‑9},距离权重σ2={2
‑5,2
‑4,
…
,25}。
[0057]
得到gemep数据库上所有语义嵌入原型的最优ua平均结果如表1中所示:
[0058]
表1
[0059] 采用方法ua对比例1sae57.2%对比例2dem59.3%对比例3latem64.2%
对比例4eszsl64.6%对比例5exem62.3%实施例1sync(origin)64.4%实施例2sync(rand)65.0%
±
0.9%
[0060]
由表1可知,本实施例1和实施例2中的sync方法相比于其他相关的对比例方法,能够针对语音信号未知情绪的识别取得更好的ua性能。
[0061]
进一步的,我们给出采用sync(rand)方法的实施例2在10次重复实验中最好性能的三个结果,与sync(origin)的结果比较,制成表2。由表2可知,随机选取的虚拟类别原型矩阵可使得本发明方法取得更好的性能。
[0062]
表2
[0063]
方法uasync(origin)64.4%sync(rand)best66.6%sync(rand)2
nd
best66.2%sync(rand)3
rd
best65.7%
[0064]
综上所述,本实施例中所采用的sync方法能够针对语音信号情绪识别所使用的副语言特征,通过对已知情绪类别间判别信息的学习,在语音信号未知情绪的识别问题上给出更优的性能。
[0065]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1