一种基于声纹技术的音频信号实时追踪比对方法与流程
1.本发明属于信号处理领域,尤其涉及一种基于声纹技术的音频信号实时追踪比对方法。
背景技术:
2.在广播转播台的安全播出监测中,为了客观分析和度量发射机的性能指标,需要对送入发射机的播出信号(以下简称播出信号)和发射后播出空收回传信号(以下简称空收信号)进行对比。
3.广播信号,特别是中波信号极易受到天气、环境等影响和干扰,诸如太阳黑子活动、大气层变化的影响,空收信号与播出信号差异较大。因此,播出信号和空收信号对齐一直是难题,传统采用音频包络对比和能量值比对的方法,在一定程度内可以实现信号的动态对齐,但是随着干扰的增大,极易造成对齐同步丢失。
技术实现要素:
4.本发明目的在于提供一种基于声纹技术的音频信号实时追踪比对方法,以解决当环境干扰较大时,播出信号和空收信号对齐同步丢失的技术问题。
5.为解决上述技术问题,本发明的一种基于声纹技术的音频信号实时追踪比对方法的具体技术方案如下:一种基于声纹技术的音频信号实时追踪比对方法,包括如下步骤:p1:计算声纹,定义播出音频为源音频,空收音频为目标音频,对播出音频和空收音频进行预处理,分别获取源声纹和目标声纹向量,并置入相应矩阵缓存;p2:计算向量距离,以目标声纹为轴,按最小步进以秒为单位分别计算源声纹与目标声纹的欧式距离,计算得到欧式距离矩阵dxs;p3:初步判定延时时间,通过欧式距离矩阵dxs,判断上次延迟时间t
last
、dxs最小值对应延迟时间t
min
、dxs行算数平均数最小值对应延迟时间t
line
;p4:细化判定延迟时间,分别计算t
last
、t
min 、t
line
对应相似度,通过相似度进行延迟时间二次判定;p5:跃变判定,对于延迟时间相似与不相似状态跃变,引入延迟处理机制;p6:对齐音频,通过输出延迟时间对齐源音频与目标音频;p7:计算源音频与目标音频相应通道在线指标;p8:重复p1
‑ꢀ
p7,循环动态跟踪源音频与目标音频。
6.进一步地,所述预处理包括如下步骤:s1:预加重,补偿高频部分;s2:分帧,多个采样点划分为帧;s3:加窗,使用汉明窗用于平滑信号,减弱fft以后旁瓣大小以及频谱泄露;s4:快速傅里叶变换,将时域特征转换为频域上分布;
s5:幅度谱平方,转换为功率谱;s6:梅尔带通滤波器滤波,对频谱进行平滑化,消除谐波,突显共振峰;s7:对数功率,加上一帧的对数能量;s8:离散余弦变换,把梅尔滤波器的对数能量进行离散余弦变换,取低频部分,得出l阶的mfcc系数;s9:动态差分提取(包括一阶差分和二阶差分),语音的动态特性用静态特征的差分谱来描述;s10:计算声纹,mfcc系数与一阶差分、二阶差分叠加为最终声纹。
7.进一步地,所述p1是对比方法的起点,对源音频进行预处理,音频采样频率为16khz,hop=500,1秒mfcc特征信息输出{13*32}矩阵,mfcc特征信息、deltas一阶微分系数、delta
‑
deltas二阶加速度系数三组向量叠加{39*32},并以20s为分析时隙,输出{39*640}矩阵;同样对目标音频进行预处理,获取到39维目标声纹特征向量,输出{39*640}矩阵。
8.进一步地,所述p2的欧式距离矩阵dxs,从目的音频中间n/2秒处,逐秒顺序计算与源音频的欧几里得距离,计算秒数n/2;设置目标音频步进为1,对应音频偏移rate/hop,重复上述计算,得到下一组;直至目标音频步进到矩阵最后一秒为止,最终生成对角线矩阵dxs。
9.进一步地,所述p3初步判定延时时间,对上次延迟时间t
last
、dxs最小值对应延迟时间t
min
、dxs行算数平均数最小值对应延迟时间t
line
判定,如果三者对应延时一致,则无需进行二次细化判定,如计算延时超出阈值,则判定为不相似音频。
10.进一步地,所述p4细化判定延迟时间,把上次延迟时间t
last
、dxs最小值对应延迟时间t
min
、dxs行算数平均数最小值对应延迟时间t
line
代入到音频波形中,分别计算经过延时对齐的音频的余弦相似度,若相似度大于规范值,则选择余弦相似度最高值对应延时,如均小于规范值,则二次判定为不相似。
11.进一步地,所述p5跃变判定,若发生相似到不相似状态跃变,或者不相似到相似状态跃变,则定义sim_min下限阈值和sim_max上限阈值,分别对应两个状态的跃变,如n次均低于或高于阈值,表示状态跃变成功。
12.进一步地,所述p6对齐音频,若源音频与目标音频波形相似,则输出延迟时间,并对齐源音频与目标音频;使用对齐后的波形,计算音频通道在线指标。
13.本发明的一种基于声纹技术的音频信号实时追踪比对方法具有以下优点:本发明基于声纹技术,利用倒谱分析,在环境干扰较大时,播出信号和空收信号能持续动态对齐,计算出播出信号和空收信号的延迟量。
附图说明
14.图1为本发明的倒谱分析流程框图;图2为本发明的基于声纹技术的音频信号实时追踪比对方法流程图;图3为本发明基于声纹技术的音频信号实时追踪比对方法具体应用流程图。
具体实施方式
15.为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明一种基于声
纹技术的音频信号实时追踪比对方法做进一步详细的描述。
16.本发明基于声纹技术为基础。根据语音生成的理论模型,语音信号是由激励信号和信道冲激响应信号卷积产生的,而解卷就是把卷积信号的各种分量分开。发明方法采用声纹向量技术,本质是非参数解卷(又叫同态解卷积),也就是倒谱分析。
17.梅尔倒谱系数(mel
‑
scale frequency cepstral coefficients,简称mfcc),mfcc特征提取包含梅尔声谱图、倒谱分析两个关键步骤。
18.梅尔声谱图首先对时域信号进行傅里叶变换转换到频域,然后使用梅尔频率刻度的滤波器组对应频域信号进行切分,最后每个频率段对应一个数值。
19.梅尔刻度是一种基于人耳对等距的音高(pitch)变化的听觉特性,与频率关系为:,其中m为梅尔刻度,f为频率。
20.频谱由频谱包络和频谱细节,倒谱分析目的是从频谱中分离得到频谱包络,声音频域的包络是辨别声音的重要信息,用于作为语音特征。倒谱分析首先对梅尔声谱图取log,然后做离散余弦变换dct,保留前13个系数就得到了mfcc特征值。
21.mfcc获取一帧语音上的能量谱包络,为提高语音识别力,提升对噪声的鲁棒性,提高抗干扰能力,加入语音信号的动态信息,一阶差分deltas和二阶差分deltas
‑
deltas表示微分系数和加速度系数。其中,,t为帧序列,n为帧的大小。
22.首先对语音信号进行预处理,如图1所示,为本发明的预处理流程,用来获取播出信号和空收信号的声纹。主要包含以下步骤:s1:预加重,补偿高频部分;s2:分帧,多个采样点划分为帧;s3:加窗,使用汉明窗用于平滑信号,减弱fft以后旁瓣大小以及频谱泄露;s4:快速傅里叶变换,将时域特征转换为频域上分布;s5:幅度谱平方,转换为功率谱;s6:梅尔带通滤波器滤波,对频谱进行平滑化,消除谐波,突显共振峰;s7:对数功率,音量也是语音的重要特征,加上一帧的对数能量;s8:离散余弦变换,把梅尔滤波器的对数能量进行离散余弦变换,取低频部分,得出l阶的mfcc系数;s9:动态差分提取(包括一阶差分和二阶差分),语音的动态特性用静态特征的差分谱来描述,提高系统的识别性能;s10:声纹,mfcc与一阶、二阶差分叠加为最终声纹。
23.其中,s1预加重,设定高通滤波器,=0.97。实施中使用公式。
24.s2分帧,音频监测中,采样频率为16khz,帧长度为512采样点,帧时间为512/16000
×
1000=32ms。
25.s3加汉明窗,实施中使用公式,其中,n为帧的大小。
26.s4
‑
s5快速傅里叶变化,实现时域信号转化到频域分析,过程包括转换为幅度谱,然后平方转换到功率谱。
27.s6梅尔滤波,采用的滤波器为三角滤波器。音频采样率为16khz,最低频率为0hz,fmax=8khz滤波器个数为26,帧大小为512,则傅里叶变换点数为512。利用,换算mel频率,最低mel频率为0,最高mel频率为2840.02,中心频率距离为:(2840.02
‑
0)/(26+1)=105.19,得到mel滤波器组的中心频率:[0,105.19,210.38,...,2840.02],最后计算实际频率组对应的fft点下标组:[0,2,4,7,10,13,16,...,256]。
[0028]
s8离散余弦变换,把每个滤波器的对数能量带入离散余弦变换,取l阶mfcc系数,本方法l=13。
[0029]
s9 动态差分提取声纹向量为mfcc向量叠加一阶差分系数、二阶差分系数,获取39维向量,即n维声纹向量=(n/3 mfcc系数+ n/3 一阶差分参数+ n/3 二阶差分参数),n=39。
[0030]
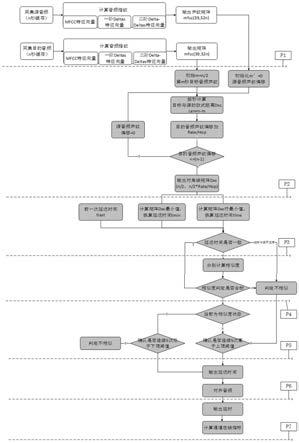
如图2所示,为本发明的音频信号动态追踪对比方法,主要包含以下步骤:p1计算声纹,定义播出音频为源音频,空收音频为目标音频,按照预处理的算法分别获取源声纹和目标声纹向量,并置入相应矩阵缓存;p2计算向量距离,以目标声纹为轴,按最小步进以秒为单位分别计算源声纹与目标声纹的欧式距离,计算得到欧式距离矩阵dxs;p3初步判定延时时间,通过欧式距离矩阵dxs,判断上次延迟时间t
last
、dxs最小值对应延迟时间t
min
、dxs行算数平均数最小值对应延迟时间t
line
;p4 细化判定延迟时间,分别计算t
last
、t
min 、t
line
对应相似度,通过相似度进行延迟时间二次判定;p5 跃变判定,对于延迟时间相似与不相似状态跃变,为了提升系统稳定性,引入延迟处理机制;p6对齐音频,通过输出延迟时间对齐源音频与目标音频;p7 计算音频与目标音频通道在线指标。以此循环动态跟踪。
[0031]
其中,p1是对比方法的起点,对源音频进行预处理,音频采样频率为16khz,hop=500,1秒mfcc特征信息输出{13*32}矩阵,mfcc特征信息、deltas一阶微分系数、delta
‑
deltas二阶加速度系数三组向量叠加{39*32},并以20s为分析时隙,输出{39*640}矩阵。同样对目标音频进行预处理,获取到39维目标声纹特征向量,输出{39*640}矩阵。
[0032]
p2中欧式距离矩阵dxs,考虑到目的音频滞后于源音频,从目的音频中间n/2秒处,逐秒顺序计算与源音频的欧几里得距离,注意目标音频不可能超前与源音频,计算秒数n/2。设置目标音频步进为1,对应音频偏移rate/hop,重复上述计算,得到下一组。直至目标音频步进到矩阵最后一秒为止,最终生成对角线矩阵dxs。
[0033]
p3初步判定延时时间,对上次延迟时间t
last
、dxs最小值对应延迟时间t
min
、dxs行算数平均数最小值对应延迟时间t
line
判定,如果三者对应延时一致,则无需进行二次细化
判定,如计算延时超出阈值,则判定为不相似音频。
[0034]
p4细化判定延迟时间,把三项延迟时间代入到音频波形中,分别计算经过延时对齐的音频的余弦相似度,若相似度大于规范值,则选择余弦相似度最高值对应延时,如均小于规范值,则二次判定为不相似。
[0035]
p5跃变判定,若发生相似到不相似状态跃变,或者不相似到相似状态跃变,则定义sim_min下限阈值和sim_max上限阈值,分别对应两个状态的跃变,如n次均低于或高于阈值,表示状态跃变成功。
[0036]
p6对齐音频,若源音频与目标音频波形相似,则输出延迟时间,并对齐源音频与目标音频。使用对齐后的波形,计算音频通道在线指标。
[0037]
以此循环,实现在线动态的实时追踪比对。
[0038]
如图3所示,本发明专利已经在新昌转播台投入实际应用,用以对浙江之声、中国之声和中国经济三个频率中波广播的播出信号进行实时监测,同时监测通道的指标情况。
[0039]
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本技术的权利要求范围内的实施例都属于本发明所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1