一种语音转换方法、装置、设备及存储介质与流程
1.本发明涉及数据处理技术领域,更具体地说,涉及一种语音转换方法、装置、设备及存储介质。
背景技术:
2.在互联网产业高速发展的时代,企业间的交流变得愈发紧密,并购、交流、学习、会议、培训及业务转移等皆会产生大量的材料,其中音视频材料作为最为直观、高效的材料,被广泛采用。目前通常是由相应工作人员将音视频材料中的语音转换为相应的文本数据,以供对文本数据进行使用等操作,但是这种方式转换效率较低。
技术实现要素:
3.本发明的目的是提供一种语音转换方法、装置、设备及存储介质,能够全自动将音视频中的语音转换为相应的文本数据,有效提高语音转换效率。
4.为了实现上述目的,本发明提供如下技术方案:
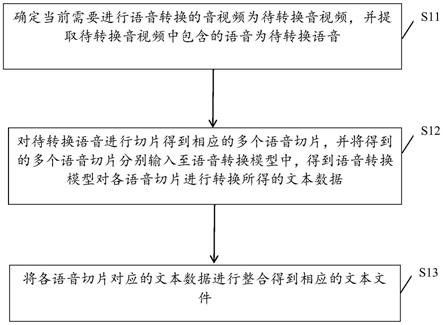
5.一种语音转换方法,包括:
6.确定当前需要进行语音转换的音视频为待转换音视频,并提取所述待转换音视频中包含的语音为待转换语音;
7.对所述待转换语音进行切片得到相应的多个语音切片,并将得到的多个语音切片分别输入至语音转换模型中,得到所述语音转换模型对各所述语音切片进行转换所得的文本数据;
8.将各所述语音切片对应的文本数据进行整合得到相应的文本文件。
9.优选的,对所述待转换语音进行切片得到相应的多个语音切片之前,还包括:
10.使用谱减法语音降噪方法或者傅里叶降噪方法对所述待转换语音进行降噪处理。
11.优选的,提取所述待转换音视频中包含的语音为待转换语音,包括:
12.使用librosa库或scipy库中的scipy.io.wavfile方法,提取所述待转换音视频中包含的语音为待转换语音。
13.优选的,对所述待转换语音进行切片得到相应的多个语音切片,包括:
14.按照时长或者按照所占空间大小,对所述待转换语音进行切片得到相应的多个语音切片。
15.优选的,将得到的多个语音切片分别输入至语音转换模型中,包括:
16.将得到的多个语音切片分别输入至本地深度学习模型或者异地迁移学习模型中。
17.优选的,将各所述语音切片对应的文本数据进行整合得到相应的文本文件,包括:
18.将各所述语音切片对应的文本数据处理为统一格式的文本数据,并将处理所得的统一格式的文本数据按照相应语音切片在所述待转换语音中的位置进行拼接,得到相应的文本文件。
19.优选的,还包括:
20.获取包含有多段测试用音视频及相应文本文件的测试数据集;
21.将每段测试用音视频作为待转换音视频执行提取待转换语音的步骤,直至得到每段测试用音视频进行语音转换所得的文本文件;
22.通过比对每段测试用音视频转换所得文本文件及所述测试数据集中的相应文本文件,得到语音转换的准确度;
23.如果所述准确度未达到准确度阈值,则修改当前使用的降噪方法和/或当前使用的提取语音的方法和/或当前进行切片的依据和/或当前所使用的语音转换模型,并返回执行将每段测试用音视频作为待转换音视频执行提取待转换语音的步骤的步骤,直至所述准确度达到所述准确度阈值为止;其中,进行切片的依据包括按照时长进行切片及按照所占空间大小进行切片。
24.一种语音转换装置,包括:
25.提取模块,用于:确定当前需要进行语音转换的音视频为待转换音视频,并提取所述待转换音视频中包含的语音为待转换语音;
26.转换模块,用于:对所述待转换语音进行切片得到相应的多个语音切片,并将得到的多个语音切片分别输入至语音转换模型中,得到所述语音转换模型对各所述语音切片进行转换所得的文本数据;
27.整合模块,用于:将各所述语音切片对应的文本数据进行整合得到相应的文本文件。
28.一种语音转换设备,包括:
29.存储器,用于存储计算机程序;
30.处理器,用于执行所述计算机程序时实现如上任一项所述语音转换方法的步骤。
31.一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上任一项语音转换方法的步骤。
32.本发明提供了一种语音转换方法、装置及设备,该方法包括:确定当前需要进行语音转换的音视频为待转换音视频,并提取所述待转换音视频中包含的语音为待转换语音;对所述待转换语音进行切片得到相应的多个语音切片,并将得到的多个语音切片分别输入至语音转换模型中,得到所述语音转换模型对各所述语音切片进行转换所得的文本数据;将各所述语音切片对应的文本数据进行整合得到相应的文本文件。本技术在确定出需要进行语音转换的音视频后,提取该音视频中的语音,将该语音切片得到多个语音切片后,通过语音转换模型将该多个语音切片进行转换得到相应的文本数据,最终对得到的全部文本数据进行整合得到相应的文本文件。可见,本技术能够全自动将音视频中的语音转换为相应的文本数据,有效提高语音转换效率。
附图说明
33.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
34.图1为本发明实施例提供的一种语音转换方法的流程图;
35.图2为本发明实施例提供的一种语音转换方法的实现架构图;
36.图3为本发明实施例提供的一种语音转换装置的结构示意图。
具体实施方式
37.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
38.请参阅图1,其示出了本发明实施例提供的一种语音转换方法的流程图,可以包括:
39.s11:确定当前需要进行语音转换的音视频为待转换音视频,并提取待转换音视频中包含的语音为待转换语音。
40.本技术中需要进行语音转换的音视频(即音视频文件)中包含的语音可以中文语音,也可以为英文语音,当然还可以为根据实际需要设定的其他语种的语音,均在本发明的保护范围之内。需要说明的是,音视频可以为对会议等进行录像所得音视频,任意需要进行语音转换的音视频均可以称之为待转换音视频,进而提取待转换音视频中的语音,以实现后续的语音转换。
41.其中,提取待转换音视频中包含的语音为待转换语音,可以包括:使用librosa库或scipy库中的scipy.io.wavfile方法,提取待转换音视频中包含的语音为待转换语音。具体来说,本技术实施例可以使用python进行音视频中语音(即音频数据)的提取,以便和其他操作进行无缝整合;可选择使用librosa库或scipy库中的scipy.io.wavfile方法进行语音的有效提取,且可以根据当前场景选择能够使得当前场景下语音提取效果最好的librosa库中的scipy.io.wavfile方法或scipy库中的scipy.io.wavfile方法实现语音提取,当然也可以是使得当前场景下语音提取效果最好的其他语音提取方法,均在本发明的保护范围之内。
42.s12:对待转换语音进行切片得到相应的多个语音切片,并将得到的多个语音切片分别输入至语音转换模型中,得到语音转换模型对各语音切片进行转换所得的文本数据。
43.本技术实施例在确定出待转换语音后,可以对待转换语音进行切片,并分别将切片得到的多个语音切片依次输入至语音转换模型中,或者是分别将切片得到的多个语音切片并行输出至多个语音转换模型中(此时语音切片与语音转换模型的数量相同),进而得到语音转换模型输出的对输入其中的语音切片进行语音转换所得的文本数据,有利于数据的稳定转换和效率。
44.其中,对待转换语音进行切片得到相应的多个语音切片,可以包括:按照时长或者按照所占空间大小,对待转换语音进行切片得到相应的多个语音切片。具体来说,本技术实施例提供按时长切片和按大小切片两种模式,可以根据当前场景选择能够使得当前场景下切片进行语音转换时效果最好的按时长切片或者按大小切片,当然也可以是使得当前场景下切片进行语音转换时效果最好的其他模式,均在本发明的保护范围之内;按时长切片例如待转换语音为1个小时,则将该待转换语音中的每10分钟作为一个语音切片实现对待转换语音的切片,按大小切片例如待转换语音为10m,则将该待转换语音中的每1m作为一个语
音切片实现对待转换语音的切片。本技术实施例中对待转换语音进行切片可以依赖python脚本实现,例如使用pydub库等。
45.另外,将得到的多个语音切片分别输入至语音转换模型中,可以包括:将得到的多个语音切片分别输入至本地深度学习模型或者异地迁移学习模型中。具体来说,为确保转换的准确性和可靠性,本技术实施例可以提供多种语音转换模型,以灵活应对不同的使用场景,也即在选择实现语音转换的语音转换模型时选择能够使得当前场景下语音转换效果最好的语音转换模型,而语音转换模型可以包括本地深度学习模型和异地迁移学习模型。本地深度学习模型可以是利用大量的带有正确文本的标签化音频数据进行d
‑
learning(deep learning,深度学习)网络的训练,且为保证模型的性能需要大量的优质数据和算力;本技术实施例中可利用自身数据或者现有的常用数据库,例如librispeech、voxforge、ted
‑
lium等,辅以具有高算力的gpu或者人工智能服务器以进行模型的训练和测试,常见的算法模型可以包括cnn
‑
hmm(深度卷积神经网络
‑
隐马尔科夫模型)、rnn
‑
hmm(深度循环神经网络
‑
隐马尔科夫模型)、ctc
‑
lstm(连接时序分类
‑
长短时记忆模型)、attention(注意力模型)等,该方式的好处是模型可存在于本地,便于修改、调参、再训练等以适用不同的应用场景,并可以最快速度获取返回文本数据。异地迁移学习模型可以包括t
‑
learning(transfer learning,迁移学习)模型和云端模型,t
‑
learning模型是利用开源的经典已成型神经网络,根据自身需求对网络输出层加以修改以获取所需的结果,这种方式的优势在于可最大程度上节省设备成本和训练所需的时间成本;云端模型则是厂商已经训练成且部署于云端的网络,使用时可使用相应api以及验证所需的id、password等参数上传音频数据,并按需设置参数,待处理结束即可返回结果,该方法的优点类似于t
‑
learning模型。上述语音转换模型均可以按照自身需求和条件灵活选择和配置,当然根据实际需要进行的其他设置也均在本发明的保护范围之内;无论采用本技术实施例所提供的上述任何一种模型,皆可有效避免内存溢出、带宽限制、网络传输失败所带来的影响。
46.s13:将各语音切片对应的文本数据进行整合得到相应的文本文件。
47.为了便于查看等,本技术实施例将语音切片对应文本数据进行整合得到相应的文本文件,并将整合得到的文本文件进行输出或者保存等。
48.其中,将各语音切片对应的文本数据进行整合得到相应的文本文件,可以包括:将各语音切片对应的文本数据处理为统一格式的文本数据,并将处理所得的统一格式的文本数据按照相应语音切片在待转换语音中的位置进行拼接,得到相应的文本文件。具体来说,语音转换模型输出的文本数据可以为多种形式,例如string,dict,json等,本技术实施例可以将不同类型的文本数据处理为统一形式(即统一格式)的文本数据,然后将全部文本数据按照其对应语音切片在待转换语音中的位置进行拼接,也即任意语音切片在待转换语音中排在第几那么其对应的文本数据在文本文件中则排在第几,最终输出完整的文本文件,便于阅读、对照、学习等。
49.本技术在确定出需要进行语音转换的音视频后,提取该音视频中的语音,将该语音切片得到多个语音切片后,通过语音转换模型将该多个语音切片进行转换得到相应的文本数据,最终对得到的全部文本数据进行整合得到相应的文本文件。可见,本技术能够全自动将音视频中的语音转换为相应的文本数据,有效提高语音转换效率。
50.另外,本技术实施例在对待转换语音进行切片得到相应的多个语音切片之前,还
可以包括:使用谱减法语音降噪方法或者傅里叶降噪方法对待转换语音进行降噪处理。需要说明的是,本技术实施例可以选取当前场景下降噪效果最好的降噪方式实现待转换语音的降噪处理,具体可以利用python编写降噪脚本,而可供选择的算法包括谱减法语音降噪与傅里叶降噪,从而有效排除噪音干扰,放大人声信号,提高识别和转换的准确性。
51.本发明实施例提供的一种语音转换方法,还可以包括:
52.获取包含有多段测试用音视频及相应文本文件的测试数据集;
53.将每段测试用音视频作为待转换音视频执行提取待转换语音的步骤,直至得到每段测试用音视频进行语音转换所得的文本文件;
54.通过比对每段测试用音视频转换所得文本文件及测试数据集中的相应文本文件,得到语音转换的准确度;
55.如果准确度未达到准确度阈值,则修改当前使用的降噪方法和/或当前使用的提取语音的方法和/或当前进行切片的依据和/或当前所使用的语音转换模型,并返回执行将每段测试用音视频作为待转换音视频执行提取待转换语音的步骤的步骤,直至准确度达到准确度阈值为止;其中,进行切片的依据包括按照时长进行切片及按照所占空间大小进行切片。
56.本技术实施例中还可实现馈型的闭环测试,并提前根据实际情况设定准确度阈。具体来说,本技术可以利用语音转换方法实现测试数据级中各测试用音视频的语音转换,并将得到的文本文件与所对应的测试数据集中的文本文件进行比对,且比对所得的相同的部分占全部部分的百分比为准确度,进而在准确度未达到准确度阈值时通过改变当前使用的降噪方法和/或当前使用的提取语音的方法和/或当前进行切片的依据和/或当前所使用的语音转换模型,实现语音转换方法等参数或网络架构的调整,以保证语音转换方法实现语音转换时的准确度,且本测试过程力求提高自动化程度,减少了人工必要参与和操作,提高了效率。其中,上述闭环测试可以是利用python的pytest工具进行的,且可反馈包含有准确度的测试报告。
57.本技术实施例提供的一种语音转换方法的实现架构可以如图2所示,可见本技术实施例结合处理、转换、整合于一体,可短时高效的自动完成音视频材料的文本转换工作,提高使用效率和使用价值,最大程度上减少了开发人员对此类材料的学习困难程度,既可减少团队获取等量资源所需金钱、人力和时间投入,又能帮助个人和团队的能力提升。
58.本发明实施例还提供了一种语音转换装置,如图3所示,可以包括:
59.提取模块11,用于:确定当前需要进行语音转换的音视频为待转换音视频,并提取待转换音视频中包含的语音为待转换语音;
60.转换模块12,用于:对待转换语音进行切片得到相应的多个语音切片,并将得到的多个语音切片分别输入至语音转换模型中,得到语音转换模型对各语音切片进行转换所得的文本数据;
61.整合模块13,用于:将各语音切片对应的文本数据进行整合得到相应的文本文件。
62.本发明实施例提供的一种语音转换装置,还可以包括:
63.降噪模块,用于:对待转换语音进行切片得到相应的多个语音切片之前,使用谱减法语音降噪方法或者傅里叶降噪方法对待转换语音进行降噪处理。
64.本发明实施例提供的一种语音转换装置,提取模块可以包括:
65.提取单元,用于:使用librosa库或scipy库中的scipy.io.wavfile方法,提取待转换音视频中包含的语音为待转换语音。
66.本发明实施例提供的一种语音转换装置,转换模块可以包括:
67.切片单元,用于:按照时长或者按照所占空间大小,对待转换语音进行切片得到相应的多个语音切片。
68.本发明实施例提供的一种语音转换装置,转换模块可以包括:
69.输入单元,用于:将得到的多个语音切片分别输入至本地深度学习模型或者异地迁移学习模型中。
70.本发明实施例提供的一种语音转换装置,整合模块可以包括:
71.整合单元,用于:将各语音切片对应的文本数据处理为统一格式的文本数据,并将处理所得的统一格式的文本数据按照相应语音切片在待转换语音中的位置进行拼接,得到相应的文本文件。
72.本发明实施例提供的一种语音转换装置,还可以包括:
73.测试模块,用于:获取包含有多段测试用音视频及相应文本文件的测试数据集;将每段测试用音视频作为待转换音视频执行提取待转换语音的步骤,直至得到每段测试用音视频进行语音转换所得的文本文件;通过比对每段测试用音视频转换所得文本文件及测试数据集中的相应文本文件,得到语音转换的准确度;如果准确度未达到准确度阈值,则修改当前使用的降噪方法和/或当前使用的提取语音的方法和/或当前进行切片的依据和/或当前所使用的语音转换模型,并返回执行将每段测试用音视频作为待转换音视频执行提取待转换语音的步骤的步骤,直至准确度达到准确度阈值为止;其中,进行切片的依据包括按照时长进行切片及按照所占空间大小进行切片。
74.本发明实施例还提供了一种语音转换设备,可以包括:
75.存储器,用于存储计算机程序;
76.处理器,用于执行计算机程序时实现如上任一项语音转换方法的步骤。
77.本发明实施例还提供了一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时可以实现如上任一项语音转换方法的步骤。
78.需要说明的是,本发明实施例提供的一种语音转换装置、设备及存储介质中相关部分的说明请参见本发明实施例提供的一种语音转换方法中对应部分的详细说明,在此不再赘述。另外本发明实施例提供的上述技术方案中与现有技术中对应技术方案实现原理一致的部分并未详细说明,以免过多赘述。
79.对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1