会议终端及反馈抑制方法与流程
1.本发明涉及一种语音会议,尤其涉及一种会议终端及反馈抑制方法。
背景技术:
2.远程会议可让不同位置或空间中的人进行对话,且会议相关设备、协议和应用程序也发展相当成熟。当多人电话会议进行时,若在同空间中有两台以上的行动装置一起运作,则扬声器可能会播出不舒服的嚣叫声(howling)。
3.举例而言,图1为现有的声音处理架构的示意图。请参照图1,行动装置d1的声音信号s1经过扬声器s播放出来。麦克风r接收到的声音信号s2可利用回声消除机制c消除经由回声路径ep并属于声音信号s1的回声成分,并据以产生声音信号s3。这声音信号s3经过网络传到行动装置d2后可通过其扬声器s播放出来。然而,若行动装置d2所播放的声音被行动装置d1的麦克风r接收,则形成了封闭回路系统(例如,嚣叫声路径hp),还容易产生不舒服的嚣叫声。
4.图2是一范例说明嚣叫声的时间-频率图。请参照图2,嚣叫声大概在0.8千赫兹(khz)并随时间越来越大声。值得注意的是,目前针对嚣叫声的抑制技术,都是消除特定频率的声音信号。然而,原先欲保留的主要声音信号中的特定频率的信号也一并被消除,进而造成声音听觉感受的失真。
技术实现要素:
5.本发明是针对一种会议终端和反馈抑制方法,可消除嚣叫声,亦能保留主要声音信号中的所有频带的信号。
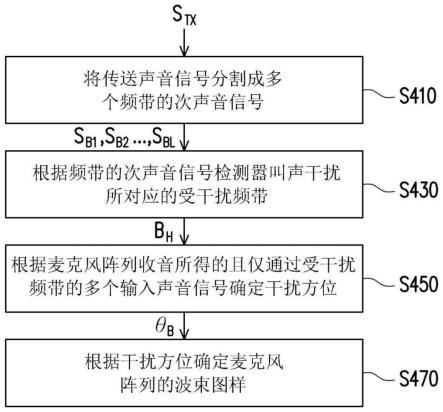
6.根据本发明的实施例,反馈抑制方法适用于会议终端。这会议终端包括麦克风阵列(microphone array)和扬声器。这反馈抑制方法包括(但不仅限于)下列步骤:将传送声音信号分割成多个频带的次声音信号。传送声音信号用于经由网络传送。不同次声音信号对应于不同频带。根据那些频带的次声音信号检测嚣叫声干扰所对应的受干扰频带。这些频带中的受干扰频带的次声音信号的功率随时间增加。受干扰频带受嚣叫声干扰影响。根据麦克风阵列收音所得的且仅通过受干扰频带的多个输入声音信号确定干扰方位。这干扰方位的声音引起嚣叫声干扰。根据干扰方向确定麦克风阵列的波束图样(beam pattern)。降低波束图样在那干扰方向的增益。
7.根据本发明的实施例,会议终端包括(但不仅限于)麦克风阵列、扬声器、通信收发器和处理器。麦克风阵列用以收音。扬声器用以播放声音。通信收发器用以传送或接收数据。处理器耦接麦克风阵列、扬声器和通信收发器。处理器经配置用以将传送声音信号分割成多个频带的次声音信号,根据那些频带的次声音信号检测嚣叫声干扰所对应的受干扰频带,根据麦克风阵列收音所得的且仅通过受干扰频带的多个输入声音信号确定干扰方位,并根据干扰方向确定麦克风阵列的波束图样。传送声音信号用于通过通信收发器经由网络传送。不同次声音信号对应于不同频带。这些频带中的受干扰频带的次声音信号的功率随
时间增加。受干扰频带受嚣叫声干扰影响。这干扰方位的声音引起嚣叫声干扰。降低波束图样在那干扰方向的增益。
8.基于上述,根据本发明实施例的会议终端和反馈抑制方法,自多个频带中检测其功率随时间增加的次声音信号和其对应受干扰频带,通过麦克风阵列确定引起嚣叫声干扰的干扰方位,并通过波束成型(beamforming)抑制干扰方位的增益。藉此,可保留主要语音信号中的所有频带,亦可抑制嚣叫声。
附图说明
9.包含附图以便进一步理解本发明,且附图并入本说明书中并构成本说明书的一部分。附图说明本发明的实施例,并与描述一起用于解释本发明的原理。
10.图1为现有的声音处理架构的示意图;
11.图2是一范例说明嚣叫声的时间-频率图;
12.图3是根据本发明一实施例的会议通话系统的示意图;
13.图4是根据本发明一实施例的反馈抑制方法的流程图;
14.图5是根据本发明一实施例的反馈抑制的示意图;
15.图6a是根据本发明一实施例的波束图样的示意图;
16.图6b是根据本发明一实施例的波束图样的示意图。
17.附图标号说明
18.d1、d2:行动装置;
19.s1~s3:声音信号;
20.s:扬声器;
21.r:麦克风;
22.c:回声消除;
23.ep:回声路径;
24.hp:嚣叫声路径;
25.1:语音通信系统;
26.10、20:会议终端;
27.50:网络;
28.11、21:收音器;
29.13、21:扬声器;
30.15、25:通信收发器;
31.17、27:存储器;
32.19、29:处理器;
33.s
rx
:通话接收声音信号;
34.s
tx
:传送声音信号;
35.s410~s470、s510~s570:步骤;
36.s
b1
~s
bl
:次声音信号;
37.bh:受干扰频带;
38.θb:干扰方位;
39.s
m1
~s
mn
、s
h1
~s
hn
、sb:输入声音信号;
40.m1~mn:麦克风;
41.pb1、pb2:波束图样;
42.ms:主瓣;
43.ss:侧瓣。
具体实施方式
44.现将详细地参考本发明的示范性实施例,示范性实施例的实例说明于附图中。只要有可能,相同组件符号在附图和描述中用来表示相同或相似部分。
45.图3是根据本发明一实施例的会议通话系统1的示意图。请参照图3,会议通话系统1包括(但不仅限于)会议终端10,20和云端服务器50。
46.会议终端10,20可以是有线电话、移动电话、网络电话、平板计算机、桌面计算机、笔记本电脑或智能喇叭。
47.会议终端10包括(但不仅限于)麦克风阵列11、扬声器13、通信收发器15、存储器17和处理器19。
48.麦克风阵列11包括动圈式(dynamic)、电容式(condenser)、或驻极体电容(electret condenser)等类型的多个麦克风。麦克风阵列11也可包括其他可接收声波(例如,人声、环境声、机器运作声等)而转换为声音信号的电子组件、模拟至数字转换器、滤波器、和音频处理器的组合。在一实施例中,麦克风阵列11用以对发话者收音/录音,以取得输入声音信号。在一些实施例中,这输入声音信号可能包括发话者的声音、扬声器13,23所发出的声音和/或其他环境音。
49.扬声器13可以是喇叭或扩音器。在一实施例中,扬声器13用以播放声音。
50.通信收发器15例如是支持以太网络(ethernet)、光纤网络、或电缆等有线网络的收发器(其可能包括(但不仅限于)连接接口、信号转换器、通信协议处理芯片等组件),也可能是支持wi-fi、第四代(4g)、第五代(5g)或更后世代行动网络等无线网络的收发器(其可能包括(但不仅限于)天线、数字至模拟/模拟至数字转换器、通信协议处理芯片等组件)。在一实施例中,通信收发器15用以经由网络50(例如,因特网、局域网络或其他类型网络)传送或接收数据。
51.存储器17可以是任何型态的固定或可移动随机存取存储器(radom access memory,ram)、只读存储器(read only memory,rom)、闪存(flash memory)、传统硬盘(hard disk drive,hdd)、固态硬盘(solid-state drive,ssd)或类似组件。在一实施例中,存储器17用以存储程序代码、软件模块、组态配置、数据(例如,声音信号、受干扰频带、干扰方位或波束图样)或文件。
52.处理器19耦接麦克风阵列11、扬声器13、通信收发器15和存储器17。处理器19可以是中央处理单元(central processing unit,cpu)、图形处理单元(graphic processing unit,gpu),或是其他可程序化的一般用途或特殊用途的微处理器(microprocessor)、数字信号处理器(digital signal processor,dsp)、可程序化控制器、现场可程序化逻辑门阵列(field programmable gate array,fpga)、特殊应用集成电路(application-specific integrated circuit,asic)或其他类似组件或上述组件的组合。在一实施例中,处理器19
用以执行所属会议终端10的所有或部份作业,且可加载并执行存储器17所存储的各软件模块、档案和数据。
53.会议终端20包括(但不仅限于)麦克风阵列21、扬声器23、通信收发器25、存储器27和处理器29。麦克风阵列21、扬声器23、通信收发器25、存储器27和处理器29的实施态样和功能可参酌前述针对麦克风阵列11、扬声器13、通信收发器15、存储器17和处理器19的说明,于此不再赘述。而处理器29用以执行所属会议终端20的所有或部份作业,且可加载并执行存储器27所存储的各软件模块、档案和数据。
54.下文中,将搭配会议通信系统1中的各项装置、组件和模块说明本发明实施例所述的方法。本方法的各个流程可依照实施情形而调整,且并不仅限于此。
55.另需说明的是,为了方便说明,相同组件可实现相同或相似的操作,且将不再赘述。例如,会议终端10的处理器19和会议终端20的处理器19皆可实现本发明实施例相同或相似的方法。
56.图4是根据本发明一实施例的反馈抑制方法的流程图。请参照图4,会议终端10的处理器19可将传送声音信号s
tx
分割成多个频带b1,b2,
…
,bl的次声音信号s
b1
,s
b2
,
…
,s
bl
(l为正整数)(步骤s410)。具体而言,传送声音信号s
tx
是用于通过通信收发器15经由网络50传送给会议终端20声音信号。一般而言,处理器19可对麦克风阵列11录音所得的输入声音信号s
m1
~s
mn
进行诸如滤波、回声消除、增益调整等声音处理,并据以产生传送声音信号s
tx
。在一实施例中,处理器19可通过傅立叶变换(fourier transform)、小波转换或脉冲响应等方式将传送声音信号s
tx
分割成l个(例如,64、128或512个)频带b1~bl的次声音信号s
b1
~s
bl
。其中,不同的次声音信号s
b1
~s
bl
对应于不同的频带b1~bl。例如,例如,次声音信号s
b1
仅涵盖600hz至700hz的频带b1,且次声音信号s
b2
仅涵盖700hz至800hz的频带b2。
57.处理器19可根据那些频带b1~bl的次声音信号s
b1
~s
bl
检测嚣叫声干扰所对应的受干扰频带bh(步骤s430)。具体而言,嚣叫声干扰的特征在于某特定频率的声音信号随时间越来越大声。由此可知,若那频带中的一个或更多个受干扰频带bh受嚣叫声干扰影响,则这受干扰频带bh的次声音信号的功率随时间增加。
58.在一实施例中,处理器19可根据功率变化和单频比例确定受干扰频带。功率变化相关于这受干扰频带的次声音信号的功率在不同时间点的差异或变化量。例如,这受干扰频带在时间点t-1与时间点t之间的最高、平均或其他统计量的功率差异。若功率变化越大,则这频带遭受嚣叫声干扰的机率越大。另一方面,若功率变化越小,则这频带遭受嚣叫声干扰的机率越小。此外,单频比例为受干扰频带的次声音信号的功率所占所有或部分次声音信号s
b1
~s
bl
的比例。若单频比例越大,则这频带遭受嚣叫声干扰的机率越大。另一方面,若单频比例越小,则这频带遭受嚣叫声干扰的机率越小。
59.在一实施例中,处理器19可确定受干扰频带的功率变化与单频比例的乘积大于临界值。假设在时间点t每个b1~bl的次声音信号s
b1
~s
bl
所对应的功率分别为则频带bb(b为1~l中的值)为受干扰频带bh可能性为:
60.61.左半边反映功率经时间变化带来的影响(即,前述功率变化)。若随着时间推移而增加频带bb的功率,则这数值(介于-1至1)会越来越接近1。另一方面,右半边反映频带bb的功率占整体次声音信号s
b1
~s
bl
的功率的比例(介于0至1)(即,前述单频比例)。因此,若频带bb的次声音信号s
bb
越来越大声,则可能性的数值(即,功率变化与单频比例的乘积)会越来越大。此外,若可能性超过所定义的临界值th(例如,0.5、0.4或0.45),则很有可能在这频带bb发生嚣叫声干扰的情形。另一方面,若可能性未超过临界值th,则处理器19可确定这频带bb未发生嚣叫声干扰的情形。在t时间点嚣叫声干扰检测的判断式(2)可定义为:
[0062][0063]
由此可知,当嚣叫声干扰发生时,其可能性最大者、次高者或其他高于临界值者为受干扰频带bh。
[0064]
须说明的是,同时间下的受干扰频带bh的数量不限于一个。只要符合检测条件(例如,其可能性或功率变化超过对应临界值)者,即可视为受干扰频带bh。
[0065]
处理器19可根据麦克风阵列11收音所得的且仅通过受干扰频带bh的多个输入声音信号s
m1
~s
mn
确定干扰方位θb(步骤s450)。具体而言,图5是根据本发明一实施例的反馈抑制的示意图。请参照图5,假设麦克风阵列11包括n个麦克风m1~mn(n为大于1的正整数)。这些麦克风m1~mn录音所得到的声音信号分别为输入声音信号s
m1
~s
mn
。假设会议终端10,20建立通话会议。例如,通过视讯软件、语音通话软件或拨打电话等方式建立会议,发话者即可开始说话。通过麦克风m1~mn录音/收音后,处理器19可取得输入声音信号s
m1
~s
mn
。
[0066]
处理器19可对输入声音信号s
m1
~s
mn
分别进行滤波处理(步骤s510)。具体而言,这滤波处理例如是仅允许受干扰频带bh的信号通过,并阻挡受干扰频带bh以外的信号通过。在一实施例中,处理器19可通过傅立叶变换、小波转换或脉冲响应等方式分别将输入声音信号s
m1
~s
mn
分割成l个频带b1~bl,并只撷取出属于受干扰频带bh的输入声音信号s
h1
~s
hn
。在另一实施例中,可根据受干扰频带bh设定带通滤波器,处理器19并通过这带通滤波器这分别对输入声音信号s
m1
~s
mn
滤波,以得出输入声音信号s
h1
~s
hn
。
[0067]
在一实施例中,处理器19根据输入声音信号s
h1
~s
hn
之间的相关性确定输入声音信号s
h1
~s
hn
之间的时间差
△
t。此处所指相关性对应到输入声音信号s
h1
~s
hn
中的两者之间的相位/时间延迟。以两个麦克风m1,m2为例,处理器19对输入声音信号s
h1
,s
h2
使用叉相关(cross-correlation)或其他相关算法,以得出相关性。各相关性对应到相位/时间延迟,且处理器19可基于这相位/时间延迟得出时间差
△
t。
[0068]
值得注意的是,来自干扰方位θb的声音引起嚣叫声干扰。例如,会议终端20位于会议终端10的干扰方位θb。而处理器19可根据时间差
△
t与麦克风阵列11中的多个麦克风m1~mn之间的距离确定干扰方位θb。即,声音经时间差
△
t所行走的距离为干扰方位θb在直角三角形中的邻边,且两麦克风之间的距离为干扰方位θb的斜边。以两个麦克风m1,m2为例,两个麦克风m1,m2之间的距离为d,而干扰方位θb为:
[0069][0070]
,vs为声音传播的速度。
[0071]
在其他实施例中,处理器19也可通过其他声源定位算法得出干扰方位θb。
[0072]
请参照图4,处理器19可根据干扰方位θb确定麦克风阵列11的波束图样(步骤s470)。具体而言,波束成型(beamforming)技术通过调整相位阵列的基本单元的参数(例如,相位和振幅),使得某些角度的信号获得相长干涉,而另一些角度的信号获得相消干涉。因此,不同参数将形成不同波束图样。
[0073]
请参照图5,若检测到嚣叫声干扰,处理器19根据嚣叫声干扰对应的干扰方位θb进行嚣叫声消除(步骤s530)。处理器19可根据干扰方位θb确定波束成型的参数(步骤s550),并降低波束图样在这干扰方位θb的增益。
[0074]
在一实施例中,处理器19将波束图样的零转向(null steering)对准干扰方位θb。在另一实施例中,处理器19将波束图样中的主瓣(main lobe)与侧瓣(sidelobe)之间对准干扰方位θb。
[0075]
在一实施例中,存储器17记录波束成型的参数(例如,不同麦克风m1~mn对应的振幅和相位)与各干扰方位θb的对应关系,并供处理器19使用。例如,当干扰方位θb为30度时,这波束图样中的零转向朝向30度。在另一实施例中,处理器19可通过基于机器学习算法的模型推论干扰方位θb合适的波束图样,并据以产生对应参数。
[0076]
处理器19可根据波束成型的参数产生输入声音信号sb。此时,这输入声音信号sb仍保留所有频带的信号。
[0077]
在一实施例中,即使未检测到嚣叫声干扰,处理器19仍可基于波束成型技术将主波束或主瓣对准会议终端10的发话者。
[0078]
举例而言,图6a是根据本发明一实施例的波束图样pb1的示意图。请参照图6a,假设未检测到嚣叫声干扰,则波束图样pb1朝向前方,并据以接收前方的声音信号。
[0079]
图6b是根据本发明一实施例的波束图样pb2的示意图。请参照图6b,波束图样pb2包括主瓣ms和侧瓣ss。而会议终端20位于会议终端10的干扰方位θb。干扰方位θb大致介于主瓣ms和侧瓣ss之间的零转向。
[0080]
另一方面,请参照图5,处理器19仍可根据通话接收声音信号s
rx
(即将通过其扬声器13播放的声音信号)对经波束成型处理的输入声音信号sb进行回声消除(步骤s570)。
[0081]
综上所述,在本发明实施例的会议终端和反馈抑制方法中,使用麦克风阵列技术判断嚣叫声干扰对应的干扰方位并基于波束成型消除嚣叫声干扰。藉此,可消除特定频率的嚣叫声,亦可保留输入声音信号的所有频带。
[0082]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽
管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1