一种基于SVM-KNN的语音情感识别方法
一种基于svm
‑
knn的语音情感识别方法
技术领域
1.本发明涉及语音情感识别,具体涉及一种基于svm
‑
knn的语音情感识别方法。
背景技术:
2.语音情感识别是当前信号处理、模式识别、人工智能等领域的热点研究课题,其研究的最终目的是赋予计算机情感识别能力,构建和谐自然的人机交互环境.目前语音情感识别的方法中,支持向量机(svm,support vector machine)被证明是一个比较有效的分类工具,但在情感混淆程度较大的情况下,使用svm依然难以进行精确识别。
3.长期以来,生理和心理学领域的专家们一直在对情绪进行研究。随着人工智能的快速发展,人机交互中的情感研究引起了广大专家的极大兴趣。在人机交互中,人们希望人与机器能够更自然地交流,这就要求机器能够理解人类的情绪,因此对情绪进行分类和识别就显得尤为重要。在人类的交流中,语言包含着丰富的信息,因此机器可以利用语言来分类和识别情感。专家们在语音情感分类与识别方面做了大量的研究和分析,包括建立语音情感数据库、提取情感特征、分类识别方法等。为了提高语音情感的识别率,前人对每个环节都进行了改进研究,但并没有一个统一的系统,识别率也不是很高。以往使用mfcc作为识别特征,但在识别前没有对其进行进一步处理,导致大量冗余信息影响识别效果。为了消除这种影响,提高识别率,选择合适的分类器成为研究的重点。为了提高情感识别率,正确处理情感特征,选择合适的分类方法就显得尤为重要。
技术实现要素:
4.为了克服上述现有技术的不足,本发明的目的是提供一种基于svm
‑
knn的语音情感识别方法,通过麦克风阵列延时对齐的方法进行语音增强处理,采用基于shl结构的bn
‑
dnn进行特征提取,并采用基于模糊集理论的方法进行特征选择,随后采用优化的svm
‑
knn方法进行情感识别。最终形成一种精度高、低计算负荷的语音情感识别方法。
5.为了实现上述目的,本发明采用的技术方案是:
6.一种基于svm
‑
knn的语音情感识别方法,不同的语音信号预处理方式、特定特征提取、模糊特征选择、svm
‑
knn支持向量机分类,包括以下步骤:
7.(1)对输入的语音信号预处理;所述预处理包括预加重滤波和加窗分帧,其中预加重滤波的预加重系数α为0.95,加窗分帧的帧长为26ms;
8.(2)用麦克风阵列解决方案对不同的麦克风通道的数据进行延迟和对齐,以实现声源的定位,提高音频质量:
9.1)由9个麦克风组成的嵌套麦克风阵列结构,实际上是4组线性麦克风阵列,分别由5个等距(2.5am.5am、10am、20am)的麦克风组成,从而确保所录取的语音信号的频域范围在3003400hz.
10.2)同时兼顾麦克风间距与人到麦克风阵列的距离之间的比例关系符合声场为远场的假设条件房间的冲激响应使用mage模型
11.(3)采用基于shl结构的bn
‑
dnn进行特征提取,特征提取过程如下:
12.1)实验中bn
‑
dnn模型设置5个隐含层,将第3个隐含层设置为瓶颈层,其余各隐含层的神经元个数均为1024;输入数据为连续11帧的40维mfcc瓶颈特征,
13.2)输入层的神经元均设为440(40x11)。将dnn网络结构设置为:440
‑
[1024
‑
1024
ꢀ‑
1024
‑
1024
‑
1024]
‑
440。
[0014]
3)确定最优参数每组神经元个数о和稀疏组重叠系数α。实验设置о为64、128、256,重叠系数α为0%、20%、30%、40%。
[0015]
4)利用神经元中激活概率h等于0的比例来度量网络的稀疏性,稀疏度定义为:
[0016][0017]
其中,d表示一层神经元个数,hai=1,2,
…
,d)表示神经元,稀疏度越大表示该隐含层中神经元越稀疏,即权值为о的神经元个数越多。对于每个模型,首先使用训练集对模型进行训练,得出每一层神经元中的激活概率,然后将其代即可计算出该层的稀疏度,最后,计算出所有隐含层稀疏度的平均值作为整个神经网络的稀疏度,最后提取出语音瓶颈特征。
[0018]
(4)采用基于模糊集理论的方法进行特征选择:
[0019]
1)在n维空间r中,对于c类问题,训练样本集合为x=x,x:,
…
,xn},n为样本数,对于待测样本x,首先确定待测样本的k个近邻的k值﹔
[0020]
2)确定待测样本与所有训练样本的距离,本文选择采用欧式距离:
[0021][0022]
对这n个距离进行排序
[0023]
d(1)≤d(2)≤d(3)≤.≤d(k)≤d(k+1)≤
……
≤d(n)
[0024]
其中,d(1),..d(k)就是待测样本与k个最近邻的距离.
[0025]
4)根据式(1)计算待测样本的类别隶属度,其中,m为模糊权重调节因子.对于n=1,2...c;如果ui(x)=max{un(x)},则判定x属于第i类.重复上述算法直至所有待测样本都处理完毕。
[0026]
(5)采用优化的svm
‑
knn方法进行情感识别:
[0027]
1)设每个样本属于所在类的隶属度为s
q
,则模糊化的输入样本为s={(x1,y1,s1),(x2,y2,s2)
……
(x
i
,y
i
,s
i
)},其中x
i
∈r,y
i
∈{1,
‑
1},σ≤s
i
≤1,σ为充分小的正数s
i
表示第i个样本属于正类的程度。
[0028]
2)在非线性情况下引入变换0:r
→
f,把样本从输入空间r映射到高维特征空间f,在高维特征空间中利用结构风险最小化原理和分类间隔最大化思想确定最优分类超平面,于是求解fsvm最优超平面问题可以转化为如下的优化问题
[0029]
[0030][0031]
ξ
i
≥0,i=1,^
…
,1.
[0032]
3)建立lagrange函数
[0033][0034]
其中μi>0,βi>0为lagrange乘子,c0>0为惩罚因子,w为线性分类函数y,的权系数。
[0035]
4)得到如下的对偶规划问题.
[0036][0037][0038]
0≤μ
i
≤s
i
c0,i=1
…
l.
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0039]
其中k(x
i
,x
j
)为核函数,考虑kkt条件,对应于μ=0的样本x;为能够被正确分类的样本,即非支持向量。对应于的样本为界上的支持向量,即样本xi位于间隔边界上的正确划分区。
附图说明
[0040]
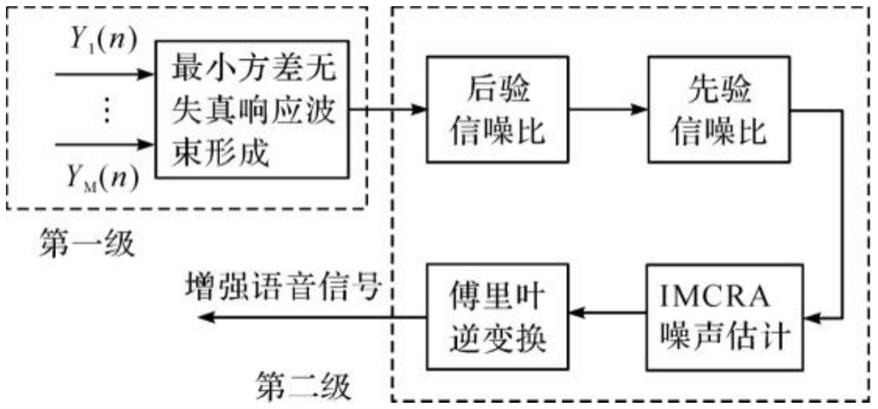
图1为本发明的语音信号增强流程图;
[0041]
图2为本发明的多级svm分类器流程图;
[0042]
图3为本发明的svm
‑
knn分类步骤。
[0043]
图4为本发明的流程图。
具体实施方式
[0044]
以下结合附图对本发明进一步叙述。
[0045]
如图1、2、3所示,一种基于svm
‑
knn的语音情感识别方法,不同的语音信号预处理方式、多种特征提取、模糊knn特征选择、svm支持向量机
‑
k近邻分类,包括以下步骤:
[0046]
(1)对原始数据预处理;使用预加重,分帧,加窗,端点检测的方法对原始数据进行预处理。
[0047]
1)信号s(1)加床后变为sw(n),公式如下:sw(n)=s(n)*w(n)
[0048]
2)采用滤波器对数据进行滤波处理,预加重滤波的预加重系数α为0.95
[0049]
(2)设计相应的麦克风阵列,利用麦克风阵列解决方案对不同麦克风通道的数据进行延时对齐,实现音源定位,提高音频质量。
[0050]
1)由9个麦克风组成的嵌套麦克风阵列结构,4组线性麦克风阵列,分别由5个等距(2.5am、5am、10am、20am)的麦克风组成,从而确保所录取的语音信号的频域范围在3003400hz.
[0051]
3)使用mage模型来兼顾麦克风间距与人到麦克风阵列的距离之间的比例关系符合声场为远场的假设条件房间的冲激响应。
[0052]
(3)对处理后的数据基于shl结构的bn
‑
dnn进行特征提取。
[0053]
1)在bn
‑
dnn模型中设置5个隐含层,其中第3个隐含层设置为瓶颈层,将各隐含层的神经元个数均为1024;以连续11帧的40维数据作为mfcc的瓶颈特征,
[0054]
2)dnn网络结构为:440
‑
[1024
‑
1024
‑
1024
‑
1024
‑
1024]
‑
440。
[0055]
3)确定最优参数每组神经元个数о和稀疏组重叠系数α。实验设置о为64、128、256,重叠系数α为0%、20%、30%、40%。
[0056]
4)神经元中激活概率越大,代表网络越稀疏,稀疏度定义为:
[0057][0058]
最后,计算出所有隐含层稀疏度的平均值作为整个神经网络的稀疏度,最后提取出语音瓶颈特征。
[0059]
(4)对提取出的特征基于模糊集理论的方法进行特征选择:
[0060]
1)使用函数提取能量、短时幅度、短时过零率和基音频率特征。
[0061]
2)将提取到的特征参数组成特征向量,作为模糊集的输入.
[0062]
3)对于c类情感的识别,对训练样本集x统计出c种不同情感状态下同一个特征参数的平均值,记为m;;(i=1,2...c,j=1,2,..,n,n为情感特征参数的个数),再分别对每
‑‑
种情感状态下的每一句语音样本的每个特征参数mjm(n为该情感状态下的样本,n=1表示为第一句,以此类推)进行归一化,归一化公式如式
[0063][0064]
计算出某种特定情感下该特征参数的离散度:
[0065][0066]
5)求出每种情感下每个特征参数的离散度后,根据离散度的大小来计算每种情感下每个特征参数的贡献度大小.特征参数θ
i
的贡献度u
ij
:
[0067][0068]
并在对待分类样本使用模糊k近邻进行判别时将情感特征参数的贡献度与欧式距离加权.
[0069][0070]
最终提取出对于情感识别贡献最大的特征。
[0071]
(5)采用优化的svm
‑
knn方法进行情感识别:
[0072]
1)根据多级分类策略构建出语音情感识别模型。
[0073]
2)所述情感混淆度:两种不同情感的相似程度。
[0074]
定义第i类情感bi与第j类情感b;的混淆度为i
ij
,其具体含义:第i类情感错判为第j类情感的概率与第j类情感错判为第i类情感的概率的平均值,其数学表达式为:
[0075][0076]
其中,x为测试数据,t为测试数据x所对应的识别结果。
[0077]
3)多级分类的构造算法具体步骤为:
[0078]
a.利用传统支持向量机(svmd)方法计算出语音情感识别混淆矩阵;
[0079]
b.构造第
‑
级分类器,设定第一级分类器概率p1,将混淆度超过概率p1的情感归为一类,即若i
ab
>p
l
,i
cd
>p1,则将a、b归为一组,c、d归为一组;若i
ab
>p
l
且i
bc
>p
l
,则将a、b、c归为一组。
[0080]
在上级分类器构造完成的基础之上,构造第二二级分类器时,再次设定第二级分类器概率p2,若i
a
>p2且i
bc
>p2,也将a.b.c归为一组。本文在设计第一级分类器时p
l
设为10%,之后每级分类器概率都是在其上级分类器概率的基础之上依次递增2%,比如第二级分类器的p'就以第一级分类器概率p
l
为基础,然后再在该基础生依次递增2%,即依次为10%、12%、14%、16%等,以此类推;
[0081]
c.对未分组的情感状态,根据式(1.1)计算其情感混淆度,转至步骤b,将其归入已有组或单独成组;
[0082]
d.四种情感都得到正确分组,结束。
[0083]
实施例
[0084]
步骤1:对原始数据预处理,包括以下步骤:
[0085]
(1)在本实施例采用emo
‑
db数据集,该数据集是由柏林工业大学录制的德语情感语音库,由10位演员(5男5女)对10个语句(5长5短)进行7种情感(中性/nertral、生气/anger、害怕/fear、高兴/joy、悲伤/sadness、厌恶/disgust、无聊/boredom)的模拟得到,共包含800句语料,采样率48khz(后压缩到16khz),16bit量化。语料文本的选取遵从语义中性、无情感倾向的原则,且为日常口语化风格,无过多的书面语修饰。语音的录制在专业录音室中完成,要求演员在演绎某个特定情感前通过回忆自身真实经历或体验进行情绪的酝酿,来增强情绪的真实感。经过20个参与者(10男10女)的听辨实验,得到84.3%的听辨识别率。
[0086]
这个数据集经过听辨测试后保留男性情感语句233句,女性情感语句302句,共535句。其中语句内容包含日常生活用语的5个短句和5个长句,具有较高情感自由度,不包含某一特定情感倾向。采用16khz采样,16bit量化,并以wav格式保存文件。
[0087]
(2)预处理:设定预加重系数,对语音信号进行预加重处理,并设定加窗分帧帧长对语音信号进行分帧处理。
[0088]
步骤2:将预处理后的数据进行特定通道选择,用麦克风阵列解决方案对不同的麦克风通道的数据进行延迟和对齐,以实现声源的定位,提高音频质量。
[0089]
(3)采用基于shl结构的bn
‑
dnn进行特征提取。设置层数和每层参数,构造bn
‑
dnn神经网络。训练神经网络,输入mfcc,最终输出语音瓶颈特征。
[0090]
(4)把提取出来的多种特征进行模糊特征选择。将提取出来的特征根据公式计算各个特征的类别隶属度,判定x特征属于第i类,直至所有样本都处理完。
[0091]
(5)采用优化的svm
‑
knn方法进行情感识别。计算情感混淆程度,归入相应的分组。
[0092]
(6)统计准确率,得出最后的结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1