说话人识别方法、识别装置、识别程序、性别识别模型生成方法以及说话人识别模型生成方法与流程
1.本发明涉及识别说话人的技术。
背景技术:
2.以往,已知获取识别对象的说话人的语音数据,并基于所获取的语音数据来对识别对象的说话人是否为预先登记的说话人进行识别的技术。在以往的说话人识别中,计算识别对象说话人的语音数据的特征量与登记说话人的语音数据的特征量的相似度,如果计算出的相似度在阈值以上,则判断为识别对象说话人与登记说话人是同一个人。
3.例如,在非专利文献1中公开了将被称为i-vector的说话人特有的特征量作为用于说话人识别的高精确度的特征量的技术。
4.此外,例如,在非专利文献2中公开了代替i-vector而将x-vector作为特征量的技术。x-vector是通过将语音数据输入到通过深度学习生成的深度神经网络而提取的特征量。
5.但是,在所述以往技术中,为了提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度,需要进一步改善。
6.现有技术文献
7.非专利文献
8.非专利文献1:najim dehak,patrick kenny,reda dehak,pierre dumouchel,pierre ouellet,“front-end factor analysis for speaker verification”,ieee transactions on audio,speech and language processing,2011年
9.非专利文献2:david snyder,daniel garcia-romero,gregory sell,daniel povery,sanjeev khudanpur,“x-vectors:robust dnn embeddings for speaker recognition”,ieee,icassp,2018年
技术实现要素:
10.本发明是为了解决上述问题而做出的发明,其目的在于提供能够提高对作为识别对象的说话人是否为预先登记的说话人进行识别的精确度的技术。
11.本发明一个方面涉及的说话人识别方法让计算机执行以下步骤:获取识别对象语音数据;获取预先登记的登记语音数据;提取所述识别对象语音数据的特征量;提取所述登记语音数据的特征量;在所述识别对象语音数据的说话人以及所述登记语音数据的说话人的任意其中之一的性别为男性的情况下,选择为了识别男性说话人而利用男性的语音数据进行了机器学习的第1说话人识别模型,在所述识别对象语音数据的说话人以及所述登记语音数据的说话人的任意其中之一的性别为女性的情况下,选择为了识别女性说话人而利用女性的语音数据进行了机器学习的第2说话人识别模型;以及,通过将所述识别对象语音数据的所述特征量和所述登记语音数据的所述特征量输入到所选择的所述第1说话人识别
模型以及所述第2说话人识别模型的任意其中之一,对所述识别对象语音数据的所述说话人进行识别。
12.根据本发明,能够提高对作为识别对象的说话人是否为预先登记的说话人进行识别的精确度。
附图说明
13.图1是表示本发明的实施方式1的说话人识别系统的结构的图。
14.图2是表示本发明的实施方式1的性别识别模型生成装置的结构的图。
15.图3是表示本发明的实施方式1的说话人识别模型生成装置的结构的图。
16.图4是用于说明本发明的实施方式1的说话人识别装置的登记处理的动作的流程图。
17.图5是用于说明图4的步骤s3的性别识别处理的动作的流程图。
18.图6是用于说明本实施方式1的说话人识别装置的说话人识别处理的动作的第1流程图。
19.图7是用于说明本实施方式1的说话人识别装置的说话人识别处理的动作的第2流程图。
20.图8是用于说明本实施方式1的性别识别模型生成装置的性别识别模型生成处理的动作的流程图。
21.图9是用于说明本实施方式1的说话人识别模型生成装置的说话人识别模型生成处理的动作的第1流程图。
22.图10是用于说明本实施方式1的说话人识别模型生成装置的说话人识别模型生成处理的动作的第2流程图。
23.图11是表示以往的说话人识别装置的说话人识别性能评价结果和实施方式1的说话人识别装置的说话人识别性能评价结果的图。
24.图12是用于说明本实施方式1的变形例1的性别识别处理的动作的流程图。
25.图13是用于说明本实施方式1的变形例2的性别识别处理的动作的流程图。
26.图14是表示本发明的实施方式2的说话人识别系统的结构的图。
27.图15是用于说明本实施方式2的说话人识别装置的登记处理的动作的流程图。
28.图16是用于说明本实施方式2的说话人识别装置的说话人识别处理的动作的第1流程图。
29.图17是用于说明本实施方式2的说话人识别装置的说话人识别处理的动作的第2流程图。
30.图18是表示本发明的实施方式3的说话人识别模型生成装置的结构的图。
31.图19是表示本发明的实施方式3的说话人识别系统的结构的图。
32.图20是用于说明本实施方式3的说话人识别模型生成装置的说话人识别模型生成处理的动作的第1流程图。
33.图21是用于说明本实施方式3的说话人识别模型生成装置的说话人识别模型生成处理的动作的第2流程图。
34.图22是用于说明本实施方式3的说话人识别模型生成装置的说话人识别模型生成
处理的动作的第3流程图。
35.图23是用于说明本实施方式3的说话人识别装置的说话人识别处理的动作的第1流程图。
36.图24是用于说明本实施方式3的说话人识别装置的说话人识别处理的动作的第2流程图。
37.图25是表示本发明的实施方式4的说话人识别系统的结构的图。
38.图26是表示本发明的实施方式4的说话人识别模型生成装置的结构的图。
39.图27是用于说明本实施方式4的说话人识别装置的登记处理的动作的流程图。
40.图28是用于说明本实施方式4的说话人识别装置的说话人识别处理的动作的第1流程图。
41.图29是用于说明本实施方式4的说话人识别装置的说话人识别处理的动作的第2流程图。
42.图30是用于说明本实施方式4的说话人识别模型生成装置的说话人识别模型生成处理的动作的第1流程图。
43.图31是用于说明本实施方式4的说话人识别模型生成装置的说话人识别模型生成处理的动作的第2流程图。
44.图32是表示本发明的实施方式5的说话人识别系统的结构的图。
45.图33是用于说明本实施方式5的说话人识别装置的登记处理的动作的流程图。
46.图34是用于说明本实施方式5的说话人识别装置的说话人识别处理的动作的第1流程图。
47.图35是用于说明本实施方式5的说话人识别装置的说话人识别处理的动作的第2流程图。
48.图36是表示本发明的实施方式6的说话人识别模型生成装置的结构的图。
49.图37是表示本发明的实施方式6的说话人识别系统的结构的图。
50.图38是用于说明本实施方式6的说话人识别模型生成装置的说话人识别模型生成处理的动作的第1流程图。
51.图39是用于说明本实施方式6的说话人识别模型生成装置的说话人识别模型生成处理的动作的第2流程图。
52.图40是用于说明本实施方式6的说话人识别模型生成装置的说话人识别模型生成处理的动作的第3流程图。
53.图41是用于说明本实施方式6的说话人识别装置的说话人识别处理的动作的第1流程图。
54.图42是用于说明本实施方式6的说话人识别装置的说话人识别处理的动作的第2流程图。
具体实施方式
55.(本发明的基础知识)
56.说话时的语音数据的特征量分布在男性和女性之间是不同的。但是,以往的说话人识别装置利用根据与说话人的性别无关地收集的语音数据生成的说话人识别模型来对
识别对象的语音数据的说话人进行识别。如上所述,在以往技术中,没有研究分别专门针对男性说话人和女性说话人的说话人识别技术。因此,通过进行考虑性别的说话人识别,有可能提高说话人识别的精确度。
57.为了解决以上的问题,本发明一个方面涉及的说话人识别方法让计算机执行以下步骤:获取识别对象语音数据;获取预先登记的登记语音数据;提取所述识别对象语音数据的特征量;提取所述登记语音数据的特征量;在所述识别对象语音数据的说话人以及所述登记语音数据的说话人的任意其中之一的性别为男性的情况下,选择为了识别男性说话人而利用男性的语音数据进行了机器学习的第1说话人识别模型,在所述识别对象语音数据的说话人以及所述登记语音数据的说话人的任意其中之一的性别为女性的情况下,选择为了识别女性说话人而利用女性的语音数据进行了机器学习的第2说话人识别模型;以及,通过将所述识别对象语音数据的所述特征量和所述登记语音数据的所述特征量输入到所选择的所述第1说话人识别模型以及所述第2说话人识别模型的任意其中之一,对所述识别对象语音数据的所述说话人进行识别。
58.根据该构成,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是男性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别男性而生成的第1说话人识别模型,由此对识别对象语音数据的说话人进行识别。此外,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是女性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别女性而生成的第2说话人识别模型,由此对识别对象语音数据的说话人进行识别。
59.因此,即使语音数据的特征量分布根据性别而不同,利用专门针对各性别的第1说话人识别模型和第2说话人识别模型来对识别对象语音数据的说话人进行识别,因此,也能够提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度。
60.此外,在所述的说话人识别方法中,也可以在选择所述第1说话人识别模型或所述第2说话人识别模型时,在所述登记语音数据的所述说话人的性别为男性的情况下,选择所述第1说话人识别模型,在所述登记语音数据的所述说话人的性别为女性的情况下,选择所述第2说话人识别模型。
61.根据该构成,根据登记语音数据的说话人的性别,选择第1说话人识别模型和第2说话人识别模型的任意其中之一。因此,登记时预先对登记语音数据的说话人的性别进行1次识别,从而无需每次进行说话人识别时对识别对象语音数据的性别进行识别,能够减轻说话人识别的处理负荷。
62.此外,在所述的说话人识别方法中,也可以还获取登记对象语音数据;还提取所述登记对象语音数据的特征量;还利用所述登记对象语音数据的所述特征量识别所述登记对象语音数据的说话人的性别;还将与识别出的所述性别相互对应的所述登记对象语音数据作为所述登记语音数据而进行登记。
63.根据该构成,在登记时,能够预先登记与性别相互对应的登记语音数据,在进行说话人识别时,能够利用与预先登记的登记语音数据相互对应的性别,容易地选择第1说话人识别模型和第2说话人识别模型的任意其中之一。
64.此外,在所述的说话人识别方法中,也可以在识别所述性别时,获取为了识别说话人的性别而利用男性以及女性的语音数据进行了机器学习的性别识别模型,通过将所述登
记对象语音数据的所述特征量输入到所述性别识别模型来识别所述登记对象语音数据的所述说话人的性别。
65.根据该构成,只需将登记对象语音数据输入到性别识别模型,就能够容易地识别登记对象语音数据的说话人的性别,该性别识别模型是为了识别说话人的性别而利用男性和女性的语音数据进行了机器学习的识别模型。
66.此外,在所述的说话人识别方法中,也可以在识别所述性别时,通过将所述登记对象语音数据的所述特征量和预先存储的男性的多个语音数据的各特征量输入到所述性别识别模型,从所述性别识别模型获取所述登记对象语音数据与所述男性的多个语音数据的每个语音数据之间的相似度,将获取到的多个相似度的平均作为平均男性相似度进行计算,通过将所述登记对象语音数据的所述特征量和预先存储的女性的多个语音数据的各特征量输入到所述性别识别模型,从所述性别识别模型获取所述登记对象语音数据与所述女性的多个语音数据的每个语音数据之间的相似度,将获取到的多个相似度的平均作为平均女性相似度进行计算,在所述平均男性相似度高于所述平均女性相似度的情况下,将所述登记对象语音数据的所述说话人的性别识别为男性,在所述平均男性相似度低于所述平均女性相似度的情况下,将所述登记对象语音数据的所述说话人的性别识别为女性。
67.根据该构成,在登记对象语音数据的说话人为男性的情况下,登记对象语音数据的特征量与多个男性的语音数据的特征量的平均相似度高于登记对象语音数据的特征量与多个女性的语音数据的特征量的平均相似度。此外,在登记对象语音数据的说话人为女性的情况下,登记对象语音数据的特征量与多个女性的语音数据的特征量之间的平均相似度高于登记对象语音数据的特征量与多个男性的语音数据的特征量之间的平均相似度。因此,通过比较登记对象语音数据的特征量与多个男性的语音数据的特征量之间的平均相似度和登记对象语音数据的特征量与多个女性的语音数据的特征量之间的平均相似度,能够容易地识别登记对象语音数据的说话人的性别。
68.此外,在所述的说话人识别方法中,也可以在识别所述性别时,通过将所述登记对象语音数据的所述特征量和预先存储的男性的多个语音数据的各特征量输入到所述性别识别模型,从所述性别识别模型获取所述登记对象语音数据与所述男性的多个语音数据的每个语音数据之间的相似度,将获取到的多个相似度中的最大值作为最大男性相似度进行计算,通过将所述登记对象语音数据的所述特征量和预先存储的女性的多个语音数据的各特征量输入到所述性别识别模型,从所述性别识别模型获取所述登记对象语音数据与所述女性的多个语音数据的每个语音数据之间的相似度,将获取到的多个相似度中的最大值作为最大女性相似度进行计算,在所述最大男性相似度高于所述最大女性相似度的情况下,将所述登记对象语音数据的所述说话人的性别识别为男性,在所述最大男性相似度低于所述最大女性相似度的情况下,将所述登记对象语音数据的所述说话人的性别识别为女性。
69.根据该构成,在登记对象语音数据的说话人为男性的情况下,登记对象语音数据的特征量与多个男性的语音数据的特征量之间的多个相似度中的最大相似度高于登记对象语音数据的特征量与多个女性的语音数据的特征量之间的多个相似度中的最大相似度。此外,在登记对象语音数据的说话人为女性的情况下,登记对象语音数据的特征量与多个女性的语音数据的特征量之间的多个相似度中的最大相似度高于登记对象语音数据的特征量与多个男性的语音数据的特征量之间的多个相似度中的最大相似度。因此,通过比较
登记对象语音数据的特征量与多个男性的语音数据的特征量之间的多个相似度中的最大相似度和登记对象语音数据的特征量与多个女性的语音数据的特征量之间的多个相似度中的最大相似度,能够容易地识别登记对象语音数据的说话人的性别。
70.此外,在所述的说话人识别方法中,也可以在识别所述性别时,计算预先存储的男性的多个语音数据的平均特征量,通过将所述登记对象语音数据的所述特征量和男性的多个语音数据的所述平均特征量输入到所述性别识别模型,从所述性别识别模型获取所述登记对象语音数据与男性的语音数据组之间的第1相似度,计算预先存储的女性的多个语音数据的平均特征量,通过将所述登记对象语音数据的所述特征量和女性的多个语音数据的所述平均特征量输入到所述性别识别模型,从所述性别识别模型获取所述登记对象语音数据与女性的语音数据组之间的第2相似度,在所述第1相似度高于所述第2相似度的情况下,将所述登记对象语音数据的所述说话人的性别识别为男性,在所述第1相似度低于所述第2相似度的情况下,将所述登记对象语音数据的所述说话人的性别识别为女性。
71.根据该构成,在登记对象语音数据的说话人为男性的情况下,登记对象语音数据的特征量与多个男性的语音数据的平均特征量之间的第1相似度高于登记对象语音数据的特征量与多个女性的语音数据的平均特征量之间的第2相似度。此外,在登记对象语音数据的说话人为女性的情况下,登记对象语音数据的特征量与多个女性的语音数据的平均特征量之间的第2相似度高于登记对象语音数据的特征量与多个男性的语音数据的平均特征量之间的第1相似度。因此,通过比较登记对象语音数据的特征量与多个男性的语音数据的平均特征量之间的第1相似度和登记对象语音数据的特征量与多个女性的语音数据的平均特征量之间的第2相似度,能够容易地识别登记对象语音数据的说话人的性别。
72.此外,在所述的说话人识别方法中,所述登记语音数据也可以包含多个登记语音数据,在识别所述说话人时,通过将所述识别对象语音数据的所述特征量和所述多个登记语音数据的各所述特征量输入到所选择的所述第1说话人识别模型以及所述第2说话人识别模型的任意其中之一,从所述第1说话人识别模型以及所述第2说话人识别模型的任意其中之一获取所述识别对象语音数据与所述多个登记语音数据的每个登记语音数据之间的相似度,将所获取的相似度为最高的所述登记语音数据的说话人识别为所述识别对象语音数据的说话人。
73.根据该构成,从第1说话人识别模型和第2说话人识别模型的任意其中之一获取识别对象语音数据与多个登记语音数据各自的相似度,相似度为最高的登记语音数据的说话人被识别为识别对象语音数据的说话人。因此,能够从多个登记语音数据中将最相似的登记语音数据的说话人识别为识别对象语音数据的说话人。
74.此外,在所述的说话人识别方法中,所述登记语音数据也可以包含多个登记语音数据,所述多个登记语音数据与用于识别所述多个登记语音数据的各登记语音数据的说话人的识别信息相互对应,还获取用于识别所述识别对象语音数据的说话人的识别信息;在获取所述登记语音数据时,从所述多个登记语音数据中获取与获取到的所述识别信息相一致的识别信息所对应的登记语音数据,在识别所述说话人时,通过将所述识别对象语音数据的所述特征量和所述登记语音数据的所述特征量输入到所选择的所述第1说话人识别模型以及所述第2说话人识别模型的任意其中之一,从所述第1说话人识别模型以及所述第2说话人识别模型的任意其中之一获取所述识别对象语音数据与所述登记语音数据之间的
相似度,在获取到的所述相似度高于阈值的情况下,将所述登记语音数据的说话人识别为所述识别对象语音数据的说话人。
75.根据该构成,从多个登记语音数据中获取与用于对识别对象语音数据的说话人进行识别的识别信息一致的识别信息所对应的1个登记语音数据。因此,不需要计算多个登记语音数据中的所有登记语音数据的特征量与识别对象语音数据的特征量之间的相似度,只要计算多个登记语音数据中的1个登记语音数据的特征量与识别对象语音数据的特征量之间的相似度即可,因此,能够减轻说话人识别的处理负荷。
76.此外,在所述的说话人识别方法中,也可以在机器学习时,通过将男性的多个语音数据中的2个语音数据的特征量的所有组合输入到所述第1说话人识别模型,从所述第1说话人识别模型获取所述2个语音数据的多个组合各自的相似度,计算出能够识别同一说话人的所述2个语音数据的所述相似度和互不相同的说话人的所述2个语音数据的所述相似度的第1阈值,在机器学习时,通过将女性的多个语音数据中的2个语音数据的特征量的所有组合输入到所述第2说话人识别模型,从所述第2说话人识别模型获取所述2个语音数据的多个组合各自的相似度,计算出能够识别同一说话人的所述2个语音数据的所述相似度和互不相同的说话人的所述2个语音数据的所述相似度的第2阈值,在识别所述说话人时,在从所述第1说话人识别模型获取到所述相似度的情况下,从获取到的所述相似度减去所述第1阈值,在从所述第2说话人识别模型获取到所述相似度的情况下,从获取到的所述相似度减去所述第2阈值。
77.在利用2个不同的第1说话人识别模型和第2说话人识别模型的情况下,第1说话人识别模型和第2说话人识别模型的输出值的范围有可能不同。因此,在进行登记时,分别对第1说话人识别模型和第2说话人识别模型,计算能够识别同一说话人的第1阈值以及第2阈值。此外,在识别说话人时,通过从计算出的识别对象语音数据与登记语音数据之间的相似度减去第1阈值或第2阈值,从而校正相似度。并且,通过将被校正的相似度与第1说话人识别模型以及第2说话人识别模型共同的阈值进行比较,从而能够以更高的精确度对识别对象语音数据的说话人进行识别。
78.本发明另一个方面涉及的说话人识别装置包括:识别对象语音数据获取部,用于获取识别对象语音数据;登记语音数据获取部,用于获取预先登记的登记语音数据;第1提取部,用于提取所述识别对象语音数据的特征量;第2提取部,用于提取所述登记语音数据的特征量;说话人识别模型选择部,在所述识别对象语音数据的说话人以及所述登记语音数据的说话人中的任意其中之一的性别为男性的情况下,选择为了识别男性说话人而利用男性的语音数据进行了机器学习的第1说话人识别模型,在所述识别对象语音数据的说话人以及所述登记语音数据的说话人中的任意其中之一的性别为女性的情况下,选择为了识别女性说话人而利用女性的语音数据进行了机器学习的第2说话人识别模型;以及,说话人识别部,通过将所述识别对象语音数据的所述特征量和所述登记语音数据的所述特征量输入到所选择的所述第1说话人识别模型以及所述第2说话人识别模型的任意其中之一,对所述识别对象语音数据的所述说话人进行识别。
79.根据该构成,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是男性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别男性而生成的第1说话人识别模型,由此对识别对象语音数据的说话人进行
识别。此外,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是女性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别女性而生成的第2说话人识别模型,由此对识别对象语音数据的说话人进行识别。
80.因此,即使语音数据的特征量分布根据性别而不同,利用专门针对各性别的第1说话人识别模型和第2说话人识别模型来对识别对象语音数据的说话人进行识别,因此,也能够提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度。
81.本发明又一个方面涉及说话人识别程序让计算机发挥以下功能:获取识别对象语音数据;获取预先登记的登记语音数据;提取所述识别对象语音数据的特征量;提取所述登记语音数据的特征量;在所述识别对象语音数据的说话人以及所述登记语音数据的说话人的任意其中之一的性别为男性的情况下,选择为了识别男性说话人而利用男性的语音数据进行了机器学习的第1说话人识别模型,在所述识别对象语音数据的说话人以及所述登记语音数据的说话人的任意其中之一的性别为女性的情况下,选择为了识别女性说话人而利用女性的语音数据进行了机器学习的第2说话人识别模型;以及,通过将所述识别对象语音数据的所述特征量和所述登记语音数据的所述特征量输入到所选择的所述第1说话人识别模型以及所述第2说话人识别模型的任意其中之一,对所述识别对象语音数据的所述说话人进行识别。
82.根据该构成,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是男性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别男性而生成的第1说话人识别模型,由此对识别对象语音数据的说话人进行识别。此外,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是女性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别女性而生成的第2说话人识别模型,由此对识别对象语音数据的说话人进行识别。
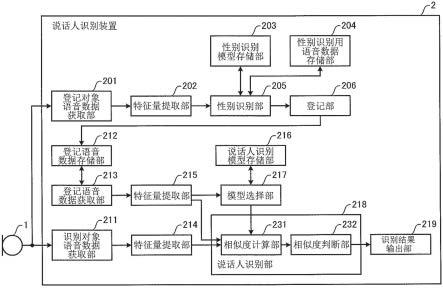
83.因此,即使语音数据的特征量分布根据性别而不同,利用专门针对各性别的第1说话人识别模型和第2说话人识别模型来对识别对象语音数据的说话人进行识别,因此,也能够提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度。
84.本发明又一个方面涉及性别识别模型生成方法让计算机执行以下步骤:获取被赋予了表示是男性还是女性的性别标签的多个语音数据;以及,通过机器学习生成性别识别模型,所述性别识别模型将所述多个语音数据中的第1语音数据和第2语音数据的各特征量以及所述第1语音数据和所述第2语音数据的各性别标签的相似度用作教师数据,将2个语音数据的各特征量作为输入,将所述2个语音数据的相似度作为输出。
85.根据该构成,通过将登记语音数据或识别对象语音数据的特征量和男性语音数据的特征量输入到通过机器学习而生成的性别识别模型,从而输出2个语音数据的第1相似度。此外,通过将登记语音数据或识别对象语音数据的特征量和女性的语音数据的特征量输入到性别识别模型,从而输出2个语音数据的第2相似度。并且,通过比较第1相似度和第2相似度,能够容易地推测登记语音数据或识别对象语音数据的说话人的性别。
86.本发明又一个方面涉及说话人识别模型生成方法让计算机执行以下步骤:获取被赋予了用于识别男性说话人的说话人识别标签的多个男性语音数据;通过机器学习生成第1说话人识别模型,所述第1说话人识别模型将所述多个男性语音数据中的第1男性语音数据和第2男性语音数据的各特征量以及所述第1男性语音数据和所述第2男性语音数据的各
说话人识别标签的相似度用作教师数据,将2个语音数据的各特征量作为输入,将所述2个语音数据的相似度作为输出;获取被赋予了用于识别女性说话人的说话人识别标签的多个女性语音数据;以及,通过机器学习生成第2说话人识别模型,所述第2说话人识别模型将所述多个女性语音数据中的第1女性语音数据和第2女性语音数据的各特征量以及所述第1女性语音数据和所述第2女性语音数据的各说话人识别标签的相似度用作教师数据,将2个语音数据的各特征量作为输入,将所述2个语音数据的相似度作为输出。
87.根据该构成,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是男性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别男性而生成的第1说话人识别模型,由此对识别对象语音数据的说话人进行识别。此外,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是女性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别女性而生成的第2说话人识别模型,由此对识别对象语音数据的说话人进行识别。
88.因此,即使语音数据的特征量分布根据性别而不同,利用专门针对男性的第1说话人识别模型和专门针对女性的第2说话人识别模型来对识别对象语音数据的说话人进行识别,因此,也能够提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度。
89.以下,参照附图说明本发明的实施方式。另外,以下的实施方式是将本发明具体化的一例,并不限定本发明的技术范围。
90.(实施方式1)
91.图1是表示本发明的实施方式1的说话人识别系统的结构的图。
92.图1所示的说话人识别系统包括麦克风1以及说话人识别装置2。另外,说话人识别装置2可以不具备麦克风1,也可以具备麦克风1。
93.麦克风1拾取说话人发出的声音,并变换为语音数据,并向说话人识别装置2输出。在预先登记语音数据时,麦克风1向说话人识别装置2输出说话人发出的登记对象语音数据。此外,在识别说话人时,麦克风1向说话人识别装置2输出说话人发出的识别对象语音数据。
94.说话人识别装置2包括登记对象语音数据获取部201、特征量提取部202、性别识别模型存储部203、性别识别用语音数据存储部204、性别识别部205、登记部206、识别对象语音数据获取部211、登记语音数据存储部212、登记语音数据获取部213、特征量提取部214、特征量提取部215、说话人识别模型存储部216、模型选择部217、说话人识别部218以及识别结果输出部219。
95.登记对象语音数据获取部201、特征量提取部202、性别识别部205、登记部206、识别对象语音数据获取部211、登记语音数据获取部213、特征量提取部214、特征量提取部215、模型选择部217、说话人识别部218以及识别结果输出部219通过处理器而实现。处理器例如由cpu(中央运算处理装置)等而形成。
96.性别识别模型存储部203、性别识别用语音数据存储部204、登记语音数据存储部212以及说话人识别模型存储部216通过存储器而实现。存储器由例如rom(read only memory,只读存储器)或eeprom(electrically erasable programmable read only memory,电可擦可编程只读存储器)等而形成。
97.另外,说话人识别装置2可以是例如计算机、智能手机、平板型计算机或服务器。
98.登记对象语音数据获取部201获取从麦克风1输出的登记对象语音数据。
99.特征量提取部202提取由登记对象语音数据获取部201获取到的登记对象语音数据的特征量。特征量例如是i-vector。i-vector是通过对gmm(gaussian mixture model,高斯混合模型)超向量应用因子分析,从语音数据提取的低维向量的特征量。另外,由于i-vector的提取方法是以往技术,因此省略详细说明。此外,特征量并不限定于i-vector,也可以是例如x-vector等其他特征量。
100.性别识别模型存储部203预先性别识别模型,该性别识别模型为了识别说话人的性别而利用男性和女性的语音数据进行了机器学习的识别模型。另外,关于性别识别模型的生成方法将在后面说明。
101.性别识别用语音数据存储部204预先存储用于识别登记对象语音数据的说话人的性别的性别识别用语音数据的特征量。性别识别用语音数据包含男性的多个语音数据和女性的多个语音数据。另外,虽然性别识别用语音数据存储部204预先存储性别识别用语音数据的特征量,但本发明并不特别限定于此,也可以预先存储性别识别用语音数据。此时,说话人识别装置2具备提取性别识别用语音数据的特征量的特征量提取部。
102.性别识别部205利用由特征量提取部202提取的登记对象语音数据的特征量识别登记对象语音数据的说话人的性别。性别识别部205从性别识别模型存储部203获取为了识别说话人的性别而利用男性和女性的语音数据进行了机器学习的性别识别模型。性别识别部205通过将登记对象语音数据的特征量输入到性别识别模型来识别登记对象语音数据的说话人的性别。
103.性别识别部205通过将登记对象语音数据的特征量和预先存储在性别识别用语音数据存储部204的男性的多个语音数据的每一个特征量输入到性别识别模型,从性别识别模型获取登记对象语音数据与男性的多个语音数据的每一个语音数据之间的相似度。并且,性别识别部205计算所获取的多个相似度的平均来作为平均男性相似度。
104.此外,性别识别部205通过将登记对象语音数据的特征量和预先存储在性别识别用语音数据存储部204的女性的多个语音数据的每一个特征量输入到性别识别模型,从性别识别模型获取登记对象语音数据与女性的多个语音数据的每一个语音数据之间的相似度。并且,性别识别部205计算所获取的多个相似度的平均来作为平均女性相似度。
105.性别识别部205在平均男性相似度高于平均女性相似度的情况下,将登记对象语音数据的说话人的性别识别为男性。另一方面,性别识别部205在平均男性相似度低于平均女性相似度的情况下,将登记对象语音数据的说话人的性别识别为女性。另外,性别识别部205在平均男性相似度与平均女性相似度相同的情况下,可以将登记对象语音数据的说话人的性别识别为男性,也可以将登记对象语音数据的说话人的性别识别为女性。
106.登记部206登记与由性别识别部205识别出的性别信息相互对应的登记对象语音数据作为登记语音数据。登记部206将登记语音数据登记到登记语音数据存储部212。
107.另外,说话人识别装置2也可以还具备受理有关登记对象语音数据的说话人的信息的输入的输入受理部。并且,登记部206也可以将登记语音数据与有关说话人的信息相互对应地登记到登记语音数据存储部212。有关说话人的信息例如是说话人的名字等。
108.识别对象语音数据获取部211获取从麦克风1输出的识别对象语音数据。
109.登记语音数据存储部212存储与性别信息相互对应的登记语音数据。登记语音数
据存储部212存储多个登记语音数据。
110.登记语音数据获取部213获取登记在登记语音数据存储部212的登记语音数据。
111.特征量提取部214提取由识别对象语音数据获取部211获取到的识别对象语音数据的特征量。特征量例如是i-vector。
112.特征量提取部215提取由登记语音数据获取部213获取到的登记语音数据的特征量。特征量例如是i-vector。
113.说话人识别模型存储部216预先存储:为了识别男性说话人而利用男性的语音数据进行了机器学习的第1说话人识别模型;和为了识别女性说话人而利用女性的语音数据进行了机器学习的第2说话人识别模型。说话人识别模型存储部216预先存储由后述的说话人识别模型生成装置4生成的第1说话人识别模型和第2说话人识别模型。另外,关于第1说话人识别模型和第2说话人识别模型的生成方法将在后面说明。
114.模型选择部217在识别对象语音数据的说话人以及登记语音数据的说话人的任意其中之一的性别为男性的情况下,选择为了识别男性说话人而利用男性的语音数据进行了机器学习的第1说话人识别模型。此外,模型选择部217在识别对象语音数据的说话人以及登记语音数据的说话人的任意其中之一的性别为女性的情况下,选择为了识别女性说话人而利用女性的语音数据进行了机器学习的第2说话人识别模型。
115.在本实施方式1中,模型选择部217在登记语音数据的说话人的性别为男性的情况下,选择第1说话人识别模型,在登记语音数据的说话人的性别为女性的情况下,选择第2说话人识别模型。登记语音数据预先与性别进行了相互对应。因此,模型选择部217在与登记语音数据相互对应的性别为男性的情况下,选择第1说话人识别模型,在与登记语音数据相互对应的性别为女性的情况下,选择第2说话人识别模型。
116.说话人识别部218通过将识别对象语音数据的特征量和登记语音数据的特征量输入到由模型选择部217选择的第1说话人识别模型和第2说话人识别模型的任意其中之一,由此对识别对象语音数据的说话人进行识别。
117.说话人识别部218具备相似度计算部231以及相似度判断部232。
118.相似度计算部231通过将识别对象语音数据的特征量和多个登记语音数据的每一个特征量输入到所选择的第1说话人识别模型和第2说话人识别模型的任意其中之一,从第1说话人识别模型和第2说话人识别模型的任意其中之一获取识别对象语音数据与多个登记语音数据的每一个登记语音数据之间的相似度。
119.相似度判断部232将所获取的相似度为最高的登记语音数据的说话人识别为识别对象语音数据的说话人。
120.另外,相似度判断部232也可以判断最高的相似度是否大于阈值。即使在登记语音数据存储部212中不存在与识别对象语音数据的说话人相同的说话人的登记语音数据的情况下,也可以计算出识别对象语音数据与各登记语音数据之间的相似度。因此,即使是相似度为最高的登记语音数据,该登记语音数据的说话人并不一定与识别对象语音数据的说话人相同。对此,通过判断最高的相似度是否大于阈值,能够可靠地识别说话人。
121.识别结果输出部219输出说话人识别部218的识别结果。识别结果输出部219例如是显示器或扬声器,在识别对象语音数据的说话人被识别出来的情况下,向显示器或扬声器输出表示识别对象语音数据的说话人是预先登记的说话人的消息。另一方面,识别结果
输出部219在没有识别出识别对象语音数据的说话人的情况下,向显示器或扬声器输出表示识别对象语音数据的说话人不是预先登记的说话人的消息。识别结果输出部219也可以将说话人识别部218的识别结果输出到说话人识别装置2以外的其它装置。
122.接着,说明本发明的实施方式1中的性别识别模型生成装置。
123.图2是表示本发明的实施方式1的性别识别模型生成装置的结构的图。
124.图2所示的性别识别模型生成装置3包括性别识别用语音数据存储部301、性别识别用语音数据获取部302、特征量提取部303、性别识别模型生成部304以及性别识别模型存储部305。
125.性别识别用语音数据获取部302、特征量提取部303以及性别识别模型生成部304通过处理器而实现。性别识别用语音数据存储部301以及性别识别模型存储部305通过存储器而实现。
126.性别识别用语音数据存储部301预先存储被赋予了表示是男性还是女性的性别标签的多个语音数据。性别识别用语音数据存储部301针对多个说话人的每一个说话人存储互不相同的多个语音数据。
127.性别识别用语音数据获取部302从性别识别用语音数据存储部301获取被赋予了表示是男性还是女性的性别标签的多个语音数据。另外,在本实施方式1中,虽然性别识别用语音数据获取部302从性别识别用语音数据存储部301获取多个语音数据,但本发明并不特别限定于此,也可以经由网络从外部设备获取(接收)多个语音数据。
128.特征量提取部303提取由性别识别用语音数据获取部302获取到的多个语音数据的特征量。特征量例如是i-vector。
129.性别识别模型生成部304将多个语音数据中的第1语音数据和第2语音数据的各特征量以及第1语音数据和第2语音数据的各性别标签的相似度用作教师数据,通过机器学习生成将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的性别识别模型。例如,性别识别模型以如果第1语音数据的性别标签与第2语音数据的性别标签相同,则输出最高的相似度,如果第1语音数据的性别标签与第2语音数据的性别标签不同,则输出最低的相似度的方式进行机器学习。
130.作为性别识别模型,采用利用概率线性判别分析(probabilistic linear discriminant analysis:plda)的模型。plda模型自动地从400维的i-vector特征量选择对说话人识别有效的特征量,并计算对数似然比作为相似度。
131.另外,作为机器学习,也可列举例如:利用对输入信息赋予标签(输出信息)的教师数据来学习输入与输出之间的关系的监督学习;仅根据无标签的输入构建数据结构的无监督学习;处理有标签和无标签双方的半监督学习;以及通过反复试验来学习将奖励最大化的行为的强化学习等。此外,机器学习的具体方法有神经网络(包括利用多层神经网络的深度学习)、遗传编程、决策树、贝叶斯网络或支持向量机(svm)等。在性别识别模型的机器学习中,利用以上列举的具体例的任意一个即可。
132.性别识别模型存储部305存储由性别识别模型生成部304生成的性别识别模型。
133.另外,性别识别模型生成装置3也可以向说话人识别装置2发送存储在性别识别模型存储部305的性别识别模型。说话人识别装置2也可以将接收到的性别识别模型存储到性别识别模型存储部203。此外,在制造说话人识别装置2时,也可以在说话人识别装置2存储
性别识别模型生成装置3生成的性别识别模型。
134.此外,在本实施方式1的性别识别模型生成装置3中,对多个语音数据赋予了表示是男性还是女性的性别标签,但本发明并不特别限定于此,也可以赋予用于识别说话人的识别信息作为标签。在该情况下,性别识别模型生成部304将多个语音数据中的第1语音数据和第2语音数据的各特征量以及第1语音数据和第2语音数据的各识别信息的相似度用作教师数据,通过机器学习生成将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的性别识别模型。例如,性别识别模型以如果第1语音数据的识别信息与第2语音数据的识别信息相同,则输出最高的相似度,如果第1语音数据的识别信息与第2语音数据的识别信息不同,则输出最低的相似度的方式进行机器学习。
135.接着,说明本发明的实施方式1的说话人识别模型生成装置。
136.图3是表示本发明的实施方式1的说话人识别模型生成装置的结构的图。
137.图3所示的说话人识别模型生成装置4包括男性语音数据存储部401、男性语音数据获取部402、特征量提取部403、第1说话人识别模型生成部404、第1说话人识别模型存储部405、女性语音数据存储部411、女性语音数据获取部412、特征量提取部413、第2说话人识别模型生成部414以及第2说话人识别模型存储部415。
138.男性语音数据获取部402、特征量提取部403、第1说话人识别模型生成部404、女性语音数据获取部412、特征量提取部413以及第2说话人识别模型生成部414通过处理器而实现。男性语音数据存储部401、第1说话人识别模型存储部405、女性语音数据存储部411以及第2说话人识别模型存储部415通过存储器而实现。
139.男性语音数据存储部401存储被赋予了用于识别男性说话人的说话人识别标签的多个男性语音数据。男性语音数据存储部401针对多个说话人的每一个说话人存储互不相同的多个男性语音数据。
140.男性语音数据获取部402从男性语音数据存储部401获取被赋予了用于识别男性说话人的说话人识别标签的多个男性语音数据。另外,在本实施方式1中,虽然男性语音数据获取部402从男性语音数据存储部401获取多个男性语音数据,但本发明并不特别限定于此,也可以经由网络从外部设备获取(接收)多个男性语音数据。
141.特征量提取部403提取由男性语音数据获取部402获取到的多个男性语音数据的特征量。特征量例如是i-vector。
142.第1说话人识别模型生成部404将多个男性语音数据中的第1男性语音数据和第2男性语音数据的各特征量以及第1男性语音数据和第2男性语音数据的各说话人识别标签的相似度用作教师数据,通过机器学习生成将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的第1说话人识别模型。例如,第1说话人识别模型以如果第1男性语音数据的说话人识别标签与第2男性语音数据的说话人识别标签相同,则输出最高的相似度,如果第1男性语音数据的说话人识别标签与第2男性语音数据的说话人识别标签不同,则输出最低的相似度的方式进行机器学习。
143.作为第1说话人识别模型,采用利用plda的模型。plda模型自动地从400维的i-vector(特征量)选择对说话人识别有效的特征量,并计算对数似然比作为相似度。
144.另外,作为机器学习,也可列举例如:利用对输入信息赋予标签(输出信息)的教师数据来学习输入与输出之间的关系的监督学习;仅根据无标签的输入构建数据结构的无监
督学习;处理有标签和无标签双方的半监督学习;以及通过反复试验来学习将奖励最大化的行为的强化学习等。此外,机器学习的具体方法有神经网络(包括利用多层神经网络的深度学习)、遗传编程、决策树、贝叶斯网络或支持向量机(svm)等。在第1说话人识别模型的机器学习中,利用以上列举的具体例的任意一个即可。
145.第1说话人识别模型存储部405存储由第1说话人识别模型生成部404生成的第1说话人识别模型。
146.女性语音数据存储部411存储被赋予了用于识别女性说话人的说话人识别标签的多个女性语音数据。女性语音数据存储部411针对多个说话人的每一个说话人存储互不相同的多个女性语音数据。
147.女性语音数据获取部412从女性语音数据存储部411获取被赋予了用于识别女性说话人的说话人识别标签的多个女性语音数据。另外,在本实施方式1中,虽然女性语音数据获取部412从女性语音数据存储部411获取多个女性语音数据,但本发明并不特别限定于此,也可以经由网络从外部设备获取(接收)多个女性语音数据。
148.特征量提取部413提取由女性语音数据获取部412获取到的多个女性语音数据的特征量。特征量例如是i-vector。
149.第2说话人识别模型生成部414将多个女性语音数据中的第1女性语音数据和第2女性语音数据的各特征量以及第1女性语音数据和第2女性语音数据的各说话人识别标签的相似度用作教师数据,通过机器学习生成将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的第2说话人识别模型。例如,第2说话人识别模型以如果第1女性语音数据的说话人识别标签与第2女性语音数据的说话人识别标签相同,则输出最高的相似度,如果第1女性语音数据的说话人识别标签与第2女性语音数据的说话人识别标签不同,则输出最低的相似度的方式进行机器学习。
150.作为第2说话人识别模型,采用利用plda的模型。plda模型自动地从400维的i-vector(特征量)选择对说话人识别有效的特征量,并计算对数似然比作为相似度。
151.另外,作为机器学习,也可列举例如:利用对输入信息赋予标签(输出信息)的教师数据来学习输入与输出之间的关系的监督学习;仅根据无标签的输入构建数据结构的无监督学习;处理有标签和无标签双方的半监督学习;以及通过反复试验来学习将奖励最大化的行为的强化学习等。此外,机器学习的具体方法有神经网络(包括利用多层神经网络的深度学习)、遗传编程、决策树、贝叶斯网络或支持向量机(svm)等。在第2说话人识别模型的机器学习中,利用以上列举的具体例的任意一个即可。
152.第2说话人识别模型存储部415存储由第2说话人识别模型生成部414生成的第2说话人识别模型。
153.另外,说话人识别模型生成装置4也可以向说话人识别装置2发送存储在第1说话人识别模型存储部405的第1说话人识别模型以及存储在第2说话人识别模型存储部415的第2说话人识别模型。说话人识别装置2也可以将接收到的第1说话人识别模型以及第2说话人识别模型存储到说话人识别模型存储部216。此外,在制造说话人识别装置2时,也可以在说话人识别装置2存储由说话人识别模型生成装置4生成的第1说话人识别模型以及第2说话人识别模型。
154.接着,说明本实施方式1的说话人识别装置2的登记处理以及说话人识别处理各自
的动作。
155.图4是用于说明本实施方式1的说话人识别装置的登记处理的动作的流程图。
156.首先,在步骤s1,登记对象语音数据获取部201获取从麦克风1输出的登记对象语音数据。希望登记自己说出的语音数据的说话人对着麦克风1说出规定的文章。此时,优选登记对象语音数据的文章比识别对象语音数据的文章长。通过获取文字数比较多的登记对象语音数据,能够提高说话人识别的精确度。此外,说话人识别装置2也可以向登记对象说话人提示预先决定的多个文章。此时,登记对象说话人说出被提示的多个文章。
157.接着,在步骤s2,特征量提取部202提取由登记对象语音数据获取部201获取到的登记对象语音数据的特征量。
158.接着,在步骤s3,性别识别部205进行利用由特征量提取部202提取的登记对象语音数据的特征量识别登记对象语音数据的说话人的性别的性别识别处理。另外,关于性别识别处理将在后面说明。
159.接着,在步骤s4,登记部206将与由性别识别部205识别出的性别信息相互对应的登记对象语音数据作为登记语音数据而存储到登记语音数据存储部212。
160.图5是用于说明图4的步骤s3的性别识别处理的动作的流程图。
161.首先,在步骤s11,性别识别部205从性别识别模型存储部203获取性别识别模型。性别识别模型是将多个语音数据中的第1语音数据和第2语音数据的各特征量以及第1语音数据和第2语音数据的各性别标签的相似度用作教师数据进行了机器学习的性别识别模型。另外,性别识别模型也可以是将多个语音数据中的第1语音数据和第2语音数据的各特征量以及第1语音数据和第2语音数据的各识别信息的相似度用作教师数据进行了机器学习的性别识别模型。
162.接着,在步骤s12,性别识别部205从性别识别用语音数据存储部204获取男性语音数据的特征量。
163.接着,在步骤s13,性别识别部205通过将登记对象语音数据的特征量和男性语音数据的特征量输入到性别识别模型来计算登记对象语音数据与男性语音数据之间的相似度。
164.接着,在步骤s14,性别识别部205判断是否已计算出登记对象语音数据与所有男性语音数据之间的相似度。在此,在判断为没有计算出登记对象语音数据与所有男性语音数据之间的相似度的情况下(在步骤s14为否),处理返回到步骤s12。然后,性别识别部205从性别识别用语音数据存储部204获取多个男性语音数据的特征量中没有计算相似度的男性语音数据的特征量。
165.另一方面,在判断为已计算出登记对象语音数据与所有男性语音数据之间的相似度的情况下(在步骤s14为是),在步骤s15,性别识别部205将计算出的多个相似度的平均作为平均男性相似度而计算。
166.接着,在步骤s16,性别识别部205从性别识别用语音数据存储部204获取女性语音数据的特征量。
167.接着,在步骤s17,性别识别部205通过将登记对象语音数据的特征量和女性语音数据的特征量输入到性别识别模型来计算登记对象语音数据与女性语音数据之间的相似度。
168.接着,在步骤s18,性别识别部205判断是否已计算出登记对象语音数据与所有女性语音数据之间的相似度。在此,在判断为没有计算出登记对象语音数据与所有女性语音数据之间的相似度的情况下(在步骤s18为否),处理返回到步骤s16。然后,性别识别部205从性别识别用语音数据存储部204获取多个女性语音数据的特征量中没有计算相似度的女性语音数据的特征量。
169.另一方面,在判断为已计算出登记对象语音数据与所有女性语音数据之间的相似度的情况下(在步骤s18为是),在步骤s19,性别识别部205将计算出的多个相似度的平均作为平均女性相似度而计算。
170.接着,在步骤s20,性别识别部205将平均男性相似度和平均女性相似度中的高的一方的性别作为识别结果而向登记部206输出。
171.图6是用于说明本实施方式1的说话人识别装置的说话人识别处理的动作的第1流程图,图7是用于说明本实施方式1的说话人识别装置的说话人识别处理的动作的第2流程图。
172.首先,在步骤s31,识别对象语音数据获取部211获取从麦克风1输出的识别对象语音数据。识别对象说话人对着麦克风1说话。麦克风1拾取识别对象说话人发出的声音,并输出识别对象语音数据。
173.接着,在步骤s32,特征量提取部214提取由识别对象语音数据获取部211获取到的识别对象语音数据的特征量。
174.接着,在步骤s33,登记语音数据获取部213从登记语音数据存储部212获取登记语音数据。此时,登记语音数据获取部213从登记在登记语音数据存储部212的多个登记语音数据中获取1个登记语音数据。
175.接着,在步骤s34,特征量提取部215提取由登记语音数据获取部213获取到的登记语音数据的特征量。
176.接着,在步骤s35,模型选择部217获取与由登记语音数据获取部213获取到的登记语音数据相互对应的性别。
177.接着,在步骤s36,模型选择部217判断获取到的性别是否为男性。在此,在判断为获取到的性别是男性的情况下(在步骤s36为是),在步骤s37,模型选择部217选择第1说话人识别模型。模型选择部217从说话人识别模型存储部216获取所选择的第1说话人识别模型,并向相似度计算部231输出获取到的第1说话人识别模型。
178.另一方面,在判断为获取到的性别不是男性的情况下,即判断为获取到的性别是女性的情况下(在步骤s36为否),在步骤s38,模型选择部217选择第2说话人识别模型。模型选择部217从说话人识别模型存储部216获取所选择的第2说话人识别模型,并向相似度计算部231输出获取到的第2说话人识别模型。
179.接着,在步骤s39,相似度计算部231通过将识别对象语音数据的特征量和登记语音数据的特征量输入到所选择的第1说话人识别模型和第2说话人识别模型的任意其中之一,来计算识别对象语音数据与登记语音数据之间的相似度。
180.接着,在步骤s40,相似度计算部231判断是否已计算出识别对象语音数据与存储在登记语音数据存储部212的所有登记语音数据之间的相似度。在此,在判断为没有计算出识别对象语音数据与所有登记语音数据之间的相似度的情况下(在步骤s40为否),处理返
回到步骤s33。然后,登记语音数据获取部213从存储在登记语音数据存储部212的多个登记语音数据中获取没有计算出相似度的登记语音数据。
181.另一方面,在判断为已计算出识别对象语音数据与所有登记语音数据之间的相似度的情况下(在步骤s40为是),在步骤s41,相似度判断部232判断最高的相似度是否大于阈值。
182.在此,在判断为最高的相似度大于阈值的情况下(在步骤s41为是),在步骤s42,相似度判断部232将相似度为最高的登记语音数据的说话人识别为识别对象语音数据的说话人。
183.另一方面,在判断为最高的相似度在阈值以下的情况下(在步骤s41为否),在步骤s43,相似度判断部232判断为多个登记语音数据中不存在说话人与识别对象语音数据相同的登记语音数据。
184.接着,在步骤s44,识别结果输出部219输出说话人识别部218的识别结果。识别结果输出部219在识别出识别对象语音数据的说话人的情况下,输出表示识别对象语音数据的说话人是预先登记的说话人的消息。另一方面,识别结果输出部219在没有识别出识别对象语音数据的说话人的情况下,输出表示识别对象语音数据的说话人不是预先登记的说话人的消息。
185.如上所述,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是男性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别男性而生成的第1说话人识别模型,由此对识别对象语音数据的说话人进行识别。此外,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是女性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别女性而生成的第2说话人识别模型,由此对识别对象语音数据的说话人进行识别。
186.因此,即使语音数据的特征量分布根据性别而不同,利用专门针对各性别的第1说话人识别模型和第2说话人识别模型来对识别对象语音数据的说话人进行识别,因此,也能够提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度。
187.另外,在本实施方式1中,模型选择部217基于登记语音数据的说话人的性别选择第1说话人识别模型以及第2说话人识别模型的任意其中之一,但本发明并不特别限定于此。模型选择部217也可以基于识别对象语音数据的说话人的性别选择第1说话人识别模型以及第2说话人识别模型的任意其中之一。在该情况下,说话人识别装置2包括:对识别对象语音数据的说话人的性别进行识别的性别识别部;预先存储为了识别说话人的性别而利用男性和女性的语音数据进行了机器学习的性别识别模型的性别识别模型存储部;以及预先存储用于对识别对象语音数据的说话人的性别进行识别的性别识别用语音数据的特征量的性别识别用语音数据存储部。性别识别部、性别识别模型存储部以及性别识别用语音数据存储部的结构与上述的性别识别部205、性别识别模型存储部203以及性别识别用语音数据存储部204相同。此外,在可识别出识别对象语音数据的说话人的性别的情况下,不需要性别识别部205、性别识别模型存储部203以及性别识别用语音数据存储部204。
188.接着,说明本实施方式1的性别识别模型生成装置3的性别识别模型生成处理的动作。
189.图8是用于说明本实施方式1的性别识别模型生成装置的性别识别模型生成处理
的动作的流程图。
190.首先,在步骤s51,性别识别用语音数据获取部302从性别识别用语音数据存储部301获取被赋予了表示是男性还是女性的性别标签的多个语音数据。
191.接着,在步骤s52,特征量提取部303提取由性别识别用语音数据获取部302获取到的多个语音数据的特征量。
192.接着,在步骤s53,性别识别模型生成部304获取多个语音数据中的第1语音数据和第2语音数据的各特征量以及第1语音数据和第2语音数据的各性别标签的相似度作为教师数据。
193.接着,在步骤s54,性别识别模型生成部304利用获取到的教师数据,机器学习将2个语音数据的特征量作为输入,将2个语音数据的相似度作为输出的性别识别模型。
194.接着,在步骤s55,性别识别模型生成部304判断是否利用多个语音数据中的所有语音数据的组合机器学习了性别识别模型。在此,在判断为没有利用所有语音数据的组合机器学习性别识别模型的情况下(在步骤s55为否),处理返回到步骤s53。然后,性别识别模型生成部304获取多个语音数据中的没有用于机器学习的组合的第1语音数据和第2语音数据的各特征量以及第1语音数据和第2语音数据的各性别标签的相似度作为教师数据。
195.另一方面,在判断为利用所有语音数据的组合机器学习了性别识别模型的情况下(在步骤s55为是),在步骤s56,性别识别模型生成部304将通过机器学习而生成的性别识别模型存储到性别识别模型存储部305。
196.如上所述,通过将登记语音数据或识别对象语音数据的特征量和男性的语音数据的特征量输入到通过机器学习而生成的性别识别模型,从而输出2个语音数据的第1相似度。此外,通过将登记语音数据或识别对象语音数据的特征量和女性的语音数据的特征量输入到性别识别模型,从而输出2个语音数据的第2相似度。然后,通过比较第1相似度和第2相似度,能够容易地推测登记语音数据或识别对象语音数据的说话人的性别。
197.接着,说明本实施方式1的说话人识别模型生成装置4的说话人识别模型生成处理的动作。
198.图9是用于说明本实施方式1的说话人识别模型生成装置的说话人识别模型生成处理的动作的第1流程图,图10是用于说明本实施方式1的说话人识别模型生成装置的说话人识别模型生成处理的动作的第2流程图。
199.首先,在步骤s61,男性语音数据获取部402从男性语音数据存储部401获取被赋予了用于识别男性说话人的说话人识别标签的多个男性语音数据。
200.接着,在步骤s62,特征量提取部403提取由男性语音数据获取部402获取到的多个男性语音数据的特征量。
201.接着,在步骤s63,第1说话人识别模型生成部404获取多个男性语音数据中的第1男性语音数据和第2男性语音数据的各特征量以及第1男性语音数据和第2男性语音数据的各说话人识别标签的相似度作为教师数据。
202.接着,在步骤s64,第1说话人识别模型生成部404利用获取到的教师数据,机器学习将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的第1说话人识别模型。
203.接着,在步骤s65,第1说话人识别模型生成部404判断是否利用多个男性语音数据
中的所有男性语音数据的组合机器学习了第1说话人识别模型。在此,在判断为没有利用所有男性语音数据的组合机器学习第1说话人识别模型的情况下(在步骤s65为否),处理返回到步骤s63。然后,第1说话人识别模型生成部404获取多个男性语音数据中的没有用于机器学习的组合的第1男性语音数据和第2男性语音数据的各特征量以及第1男性语音数据和第2男性语音数据的各说话人识别标签的相似度作为教师数据。
204.另一方面,在判断为利用所有男性语音数据的组合机器学习了第1说话人识别模型的情况下(在步骤s65为是),在步骤s66,第1说话人识别模型生成部404将通过机器学习而生成的第1说话人识别模型存储到第1说话人识别模型存储部405。
205.接着,在步骤s67,女性语音数据获取部412从女性语音数据存储部411获取被赋予了用于识别女性说话人的说话人识别标签的多个女性语音数据。
206.接着,在步骤s68,特征量提取部413提取由女性语音数据获取部412获取到的多个女性语音数据的特征量。
207.接着,在步骤s69,第2说话人识别模型生成部414获取多个女性语音数据中的第1女性语音数据和第2女性语音数据的各特征量以及第1女性语音数据和第2女性语音数据的各说话人识别标签的相似度作为教师数据。
208.接着,在步骤s70,第2说话人识别模型生成部414利用获取到的教师数据,机器学习将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的第2说话人识别模型。
209.接着,在步骤s71,第2说话人识别模型生成部414判断是否利用多个女性语音数据中的所有女性语音数据的组合机器学习了第2说话人识别模型。在此,在判断为没有利用所有女性语音数据的组合机器学习第2说话人识别模型的情况下(在步骤s71为否),处理返回到步骤s69。然后,第2说话人识别模型生成部414获取多个女性语音数据中的没有用于机器学习的组合的第1女性语音数据和第2女性语音数据的各特征量以及第1女性语音数据和第2女性语音数据的各说话人识别标签的相似度作为教师数据。
210.另一方面,在判断为利用所有女性语音数据的组合机器学习了第2说话人识别模型的情况下(在步骤s71为是),在步骤s72,第2说话人识别模型生成部414将通过机器学习而生成的第2说话人识别模型存储到第2说话人识别模型存储部415。
211.如上所述,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是男性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别男性而生成的第1说话人识别模型,由此对识别对象语音数据的说话人进行识别。此外,在识别对象语音数据的说话人和登记语音数据的说话人的任意其中之一的性别是女性的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到为识别女性而生成的第2说话人识别模型,由此对识别对象语音数据的说话人进行识别。
212.因此,即使语音数据的特征量分布根据性别而不同,利用专门针对男性的第1说话人识别模型和专门针对女性的第2说话人识别模型来对识别对象语音数据的说话人进行识别,因此,也能够提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度。
213.接着,说明本实施方式1的说话人识别装置2的说话人识别性能的评价。
214.图11是表示以往的说话人识别装置的说话人识别性能评价结果和实施方式1的说话人识别装置的说话人识别性能评价结果的图。
215.图11所示的性能评价结果表示通过以往的说话人识别装置以及本实施方式1的说话人识别装置2识别由sre19进展数据集(progress dataset)以及sre19评估数据集(eevalution(应为evalution)dataset)提供的语音数据的说话人的结果。
216.sre19是由美国国家标准与技术研究院(nist)主办的说话人识别评测大赛。sre19进展数据集以及sre19评估数据集都是由sre19提供的数据集。
217.以往的说话人识别装置利用不区分男性和女性而生成的说话人识别模型来识别了语音数据的说话人。
218.此外,本实施方式1的说话人识别装置2利用男性用的第1说话人识别模型和女性用的第2说话人识别模型来识别了语音数据的说话人。
219.评价结果用一般被用于评价说话人识别的eer(equal error rate,等错误率)(%)、作为由nist定义的成本的minc(minimum cost,最小成本)以及作为由nist定义的成本的actc(actual cost,实际成本)来表示。另外,eer、minc以及actc的值越小则性能就越高。
220.如图11所示,本实施方式1的说话人识别装置2的eer、minc以及actc均小于以往的说话人识别装置的eer、minc以及actc。由此可知,本实施方式1的说话人识别装置2的说话人识别性能高于以往的说话人识别装置的说话人识别性能。
221.接着,说明本实施方式1的变形例1的说话人识别装置2。
222.本实施方式1的变形例1的说话人识别装置2的性别识别部205的性别识别处理与上述的性别识别处理不同。
223.本实施方式1的变形例1的性别识别部205通过将登记对象语音数据的特征量和预先存储在性别识别用语音数据存储部204的男性的多个语音数据的每一个特征量输入到性别识别模型,从性别识别模型获取登记对象语音数据与男性的多个语音数据的每一个语音数据之间的相似度。并且,性别识别部205计算所获取的多个相似度中的最大值来作为最大男性相似度。
224.此外,性别识别部205通过将登记对象语音数据的特征量和预先存储在性别识别用语音数据存储部204的女性的多个语音数据的每一个特征量输入到性别识别模型,从性别识别模型获取登记对象语音数据与女性的多个语音数据的每一个语音数据之间的相似度。并且,性别识别部205计算所获取的多个相似度中的最大值来作为最大女性相似度。
225.性别识别部205在最大男性相似度高于最大女性相似度的情况下,将登记对象语音数据的说话人的性别识别为男性。另一方面,性别识别部205在最大男性相似度低于最大女性相似度的情况下,将登记对象语音数据的说话人的性别识别为女性。另外,性别识别部205在最大男性相似度与最大女性相似度相同的情况下,可以将登记对象语音数据的说话人的性别识别为男性,也可以将登记对象语音数据的说话人的性别识别为女性。
226.接着,说明本实施方式1的变形例1的性别识别处理的动作。
227.图12是用于说明本实施方式1的变形例1的性别识别处理的动作的流程图。本实施方式1的变形例1的性别识别处理是图4的步骤s3的性别识别处理的其他的动作例。
228.步骤s81~步骤s84的处理与图5所示的步骤s11~步骤s14的处理相同,因此省略说明。
229.在判断为已计算出登记对象语音数据与所有男性语音数据之间的相似度的情况
下(在步骤s84为是),在步骤s85,性别识别部205将计算出的多个相似度中的最大值作为最大男性相似度而计算。
230.步骤s86~步骤s88的处理与图5所示的步骤s16~步骤s18的处理相同,因此省略说明。
231.在判断为已计算出登记对象语音数据与所有女性语音数据之间的相似度的情况下(在步骤s88为是),在步骤s89,性别识别部205将计算出的多个相似度中的最大值作为最大女性相似度而计算。
232.接着,在步骤s90,性别识别部205将最大男性相似度和最大女性相似度中的高的一方的性别作为识别结果而向登记部206输出。
233.接着,说明本实施方式1的变形例2的说话人识别装置2。
234.本实施方式1的变形例2的说话人识别装置2的性别识别部205的性别识别处理与上述的性别识别处理不同。
235.本实施方式1的变形例2的性别识别部205计算预先存储的男性的多个语音数据的平均特征量。并且,性别识别部205通过将登记对象语音数据的特征量和男性的多个语音数据的平均特征量输入到性别识别模型,从性别识别模型获取登记对象语音数据与男性的语音数据组之间的第1相似度。
236.此外,性别识别部205计算预先存储的女性的多个语音数据的平均特征量。并且,性别识别部205通过将登记对象语音数据的特征量和女性的多个语音数据的平均特征量输入到性别识别模型,从性别识别模型获取登记对象语音数据与女性的语音数据组之间的第2相似度。
237.性别识别部205在第1相似度高于第2相似度的情况下,将登记对象语音数据的说话人的性别识别为男性。另一方面,性别识别部205在第1相似度低于第2相似度的情况下,将登记对象语音数据的说话人的性别识别为女性。另外,性别识别部205在第1相似度与第2相似度相同的情况下,可以将登记对象语音数据的说话人的性别识别为男性,也可以将登记对象语音数据的说话人的性别识别为女性。
238.接着,说明本实施方式1的变形例2的性别识别处理的动作。
239.图13是用于说明本实施方式1的变形例2的性别识别处理的动作的流程图。本实施方式1的变形例2的性别识别处理是图4的步骤s3的性别识别处理的其他的动作例。
240.首先,在步骤s101,性别识别部205从性别识别模型存储部203获取性别识别模型。性别识别模型是将多个语音数据中的第1语音数据和第2语音数据的各特征量以及第1语音数据和第2语音数据的各性别标签的相似度用作教师数据进行了机器学习的性别识别模型。另外,性别识别模型也可以是将多个语音数据中的第1语音数据和第2语音数据的各特征量以及第1语音数据和第2语音数据的各识别信息的相似度用作教师数据进行了机器学习的性别识别模型。
241.接着,在步骤s102,性别识别部205从性别识别用语音数据存储部204获取多个男性语音数据的特征量。
242.接着,在步骤s103,性别识别部205计算所获取的多个男性语音数据的平均特征量。
243.接着,在步骤s104,性别识别部205通过将登记对象语音数据的特征量和多个男性
语音数据的平均特征量输入到性别识别模型来计算登记对象语音数据与男性语音数据组之间的第1相似度。
244.接着,在步骤s105,性别识别部205从性别识别用语音数据存储部204获取多个女性语音数据的特征量。
245.接着,在步骤s106,性别识别部205计算所获取的多个女性语音数据的平均特征量。
246.接着,在步骤s107,性别识别部205通过将登记对象语音数据的特征量和多个女性语音数据的平均特征量输入到性别识别模型来计算登记对象语音数据与女性语音数据组之间的第2相似度。
247.接着,在步骤s108,性别识别部205将第1相似度和第2相似度中的高的一方的性别作为识别结果而向登记部206输出。
248.另外,在本实施方式1的性别识别处理中,计算登记语音数据与男性语音数据之间的相似度以及登记语音数据与女性语音数据之间的相似度,并比较所计算出的2个相似度来判断登记语音数据的性别,但本发明不特别限定于此。例如,性别识别模型生成部304也可以将多个语音数据中的1个语音数据的特征量和1个语音数据的性别标签用作教师数据,通过机器学习生成将语音数据的特征量作为输入,将男性和女性的任意其中之一作为输出的性别识别模型。在该情况下,性别识别模型例如是深度神经网络模型,机器学习例如是深度学习。
249.此外,性别识别模型也可以针对被输入的语音数据计算男性概率和女性概率。在该情况下,性别识别部205也可以将男性概率和女性概率中的高的一方的概率的性别作为识别结果而输出。
250.此外,说话人识别装置2也可以还具备在获取登记对象语音数据时,受理登记对象语音数据的说话人的性别的输入的输入受理部。在该情况下,登记部206也可以将由登记对象语音数据获取部201获取到的登记对象语音数据和由输入受理部受理的性别相互对应地存储到登记语音数据存储部212。据此,不需要特征量提取部202、性别识别模型存储部203、性别识别用语音数据存储部204以及性别识别部205,能够简化说话人识别装置2的结构,并且能够减轻说话人识别装置2的登记处理的负荷。
251.(实施方式2)
252.在上述的实施方式1中,计算存储在登记语音数据存储部212的所有登记语音数据各自与识别对象语音数据之间的相似度,相似度为最高的登记语音数据的说话人被识别为识别对象语音数据的说话人。而在实施方式2中,输入识别对象语音数据的说话人的识别信息,获取存储在登记语音数据存储部212的多个登记语音数据中预先与该识别信息预先进行相互对应的1个登记语音数据。并且,计算1个登记语音数据与识别对象语音数据之间的相似度,在相似度高于阈值的情况下,登记语音数据的说话人被识别为识别对象语音数据的说话人。
253.图14是表示本发明的实施方式2的说话人识别系统的结构的图。
254.图14所示的说话人识别系统包括麦克风1以及说话人识别装置21。另外,说话人识别装置21可以不具备麦克风1,也可以具备麦克风1。
255.另外,在本实施方式2中,对与实施方式1相同的结构附上相同的符号并省略说明。
256.说话人识别装置21包括登记对象语音数据获取部201、特征量提取部202、性别识别模型存储部203、性别识别用语音数据存储部204、性别识别部205、登记部2061、识别对象语音数据获取部211、登记语音数据存储部2121、登记语音数据获取部2131、特征量提取部214、特征量提取部215、说话人识别模型存储部216、模型选择部217、说话人识别部2181、识别结果输出部219、输入受理部221以及识别信息获取部222。
257.输入受理部221例如是键盘、鼠标以及触摸屏等输入装置。在登记语音数据时,输入受理部221受理说话人输入的用于识别登记语音数据的说话人的识别信息。此外,在登记语音数据时,输入受理部221受理说话人输入的用于对将要识别的语音数据的说话人进行识别的识别信息。另外,输入受理部221也可以是读卡器、rfid(radio frequency identification,射频识别)阅读器等。在该情况下,说话人利用读卡器读取记录了识别信息的卡,或者利用rfid阅读器读取记录了识别信息的rfid标签。
258.识别信息获取部222获取由输入受理部221受理的识别信息。在登记语音数据时,识别信息获取部222获取用于识别登记对象语音数据的说话人的识别信息,并向登记部2061发送所获取到的识别信息。此外,在识别语音数据时,识别信息获取部222获取用于对识别对象语音数据的说话人进行识别的识别信息,并向登记语音数据获取部2131发送所获取到的识别信息。
259.登记部2061将与性别识别部205识别出的性别信息以及识别信息获取部222获取到的识别信息进行相互对应的登记对象语音数据作为登记语音数据而进行登记。登记部2061将登记语音数据登记到登记语音数据存储部2121。
260.登记语音数据存储部2121存储与性别信息以及识别信息进行相互对应的登记语音数据。登记语音数据存储部2121存储多个登记语音数据。多个登记语音数据与用于识别多个登记语音数据各自的说话人的识别信息相互对应。
261.登记语音数据获取部2131从登记在登记语音数据存储部2121的多个登记语音数据中获取与由识别信息获取部222获取到的识别信息一致的识别信息所对应的登记语音数据。
262.说话人识别部2181具备相似度计算部2311以及相似度判断部2321。
263.相似度计算部2311通过将识别对象语音数据的特征量和登记语音数据的特征量输入到所选择的第1说话人识别模型和第2说话人识别模型的任意其中之一,从第1说话人识别模型和第2说话人识别模型的任意其中之一获取识别对象语音数据与登记语音数据之间的相似度。
264.相似度判断部2321在所获取的相似度高于阈值的情况下,将登记语音数据的说话人识别为识别对象语音数据的说话人。
265.接着,说明本实施方式2的说话人识别装置21的登记处理以及说话人识别处理各自的动作。
266.图15是用于说明本发明的实施方式2的说话人识别装置的登记处理的动作的流程图。
267.首先,在步骤s121,识别信息获取部222获取由输入受理部221受理的说话人的识别信息。输入受理部221受理说话人输入的用于识别登记语音数据的说话人的识别信息,并向识别信息获取部222输出所受理的识别信息。识别信息获取部222向登记部2061输出用于
识别登记对象语音数据的说话人的识别信息。
268.接着,在步骤s122,登记对象语音数据获取部201获取从麦克风1输出的登记对象语音数据。输入了识别信息的希望登记自己说出的语音数据的说话人对着麦克风1说出规定的文章。
269.步骤s123以及步骤s124的处理与图4所示的步骤s2以及步骤s3的处理相同,因此省略说明。
270.接着,在步骤s125,登记部2061将与性别识别部205识别出的性别信息以及识别信息获取部222获取到的识别信息进行相互对应的登记对象语音数据作为登记语音数据存储到登记语音数据存储部2121。据此,登记语音数据存储部2121存储与性别信息以及识别信息进行相互对应的登记语音数据。
271.图16是用于说明本实施方式2的说话人识别装置的说话人识别处理的动作的第1流程图,图17是用于说明本实施方式2的说话人识别装置的说话人识别处理的动作的第2流程图。
272.首先,在步骤s131,识别信息获取部222获取由输入受理部221受理的说话人的识别信息。输入受理部221受理说话人输入的用于对将要识别的语音数据的说话人进行识别的识别信息,并向识别信息获取部222输出所受理的识别信息。识别信息获取部222向登记语音数据获取部2131输出用于对识别对象语音数据的说话人进行识别的识别信息。
273.接着,在步骤s132,登记语音数据获取部2131判断在登记语音数据存储部2121是否有与识别信息获取部222获取到的识别信息一致的识别信息。在此,在判断为登记语音数据存储部2121中没有与所获取到的识别信息一致的识别信息的情况下(在步骤s132为否),说话人识别处理结束。另外,在判断为登记语音数据存储部2121中没有与所获取到的识别信息一致的识别信息的情况下,识别结果输出部219也可以输出用于向说话人通知被输入的识别信息没有被登记的通知信息。此外,在判断为登记语音数据存储部2121中没有与所获取到的识别信息一致的识别信息的情况下,识别结果输出部219也可以输出用于提示说话人登记语音数据的通知信息。
274.另一方面,在判断为登记语音数据存储部2121中有与所获取到的识别信息一致的识别信息的情况下(在步骤s132为是),在步骤s133,识别对象语音数据获取部211获取从麦克风1输出的识别对象语音数据。
275.接着,在步骤s134,特征量提取部214提取由识别对象语音数据获取部211获取到的识别对象语音数据的特征量。
276.接着,在步骤s135,登记语音数据获取部2131从登记在登记语音数据存储部2121的多个登记语音数据中获取与由识别信息获取部222获取到的识别信息相一致的识别信息所对应的登记语音数据。
277.步骤s136~步骤s141的处理与图6所示的步骤s34~步骤s39的处理相同,因此省略说明。
278.接着,在步骤s142,相似度判断部2321判断相似度计算部2311计算出的相似度是否大于阈值。
279.在此,在判断为相似度计算部2311计算出的相似度大于阈值的情况下(在步骤s142为是),在步骤s143,相似度判断部2321将登记语音数据的说话人识别为识别对象语音
数据的说话人。
280.另一方面,在判断为相似度计算部2311计算出的相似度在阈值以下的情况下(在步骤s142为否),在步骤s144,相似度判断部2321判断为识别对象语音数据的说话人不是登记语音数据的说话人。
281.接着,在步骤s145,识别结果输出部219输出说话人识别部2181的识别结果。识别结果输出部219在识别出识别对象语音数据的说话人的情况下,输出表示识别对象语音数据的说话人是预先登记的说话人的消息。另一方面,识别结果输出部219在没有识别出识别对象语音数据的说话人的情况下,输出表示识别对象语音数据的说话人不是预先登记的说话人的消息。
282.如上所述,在本实施方式2中,只计算与识别信息相对应的登记语音数据与识别对象语音数据之间的相似度。因此,与计算多个登记语音数据各自与识别对象语音数据之间的多个相似度的实施方式1相比,在实施方式2中,能够减轻计算相似度的处理负荷。
283.(实施方式3)
284.在上述的实施方式1以及实施方式2中,根据登记语音数据的说话人的性别选择第1说话人识别模型和第2说话人识别模型的任意其中之一,但是在利用2个不同的第1说话人识别模型和第2说话人识别模型的情况下,第1说话人识别模型和第2说话人识别模型的输出值的范围有可能不同。对此,在实施方式3中,在登记语音数据时,分别针对第1说话人识别模型和第2说话人识别模型,计算能够识别同一说话人的第1阈值以及第2阈值,并存储计算出的第1阈值以及第2阈值。此外,在识别语音数据时,通过从计算出的识别对象语音数据与登记语音数据之间的相似度减去第1阈值或第2阈值来校正相似度。并且,通过将校正后的相似度与第1说话人识别模型以及第2说话人识别模型共同的第3阈值进行比较,从而对识别对象语音数据的说话人进行识别。
285.首先,说明本发明的实施方式3中的说话人识别模型生成装置。
286.图18是表示本发明的实施方式3的说话人识别模型生成装置的结构的图。
287.图18所示的说话人识别模型生成装置41包括男性语音数据存储部401、男性语音数据获取部402、特征量提取部403、第1说话人识别模型生成部404、第1说话人识别模型存储部405、第1说话人识别部406、第1阈值计算部407、阈值存储部408、女性语音数据存储部411、女性语音数据获取部412、特征量提取部413、第2说话人识别模型生成部414、第2说话人识别模型存储部415、第2说话人识别部416以及第2阈值计算部417。
288.另外,在本实施方式3中,对与实施方式1以及实施方式2相同的结构附上相同的符号并省略说明。
289.第1说话人识别部406通过将男性的多个语音数据中的2个语音数据的特征量的所有组合输入到第1说话人识别模型,从第1说话人识别模型获取2个语音数据的多个组合各自的相似度。
290.第1阈值计算部407计算能够识别同一说话人的2个语音数据的相似度和互不相同的说话人的2个语音数据的相似度的第1阈值。第1阈值计算部407通过对第1说话人识别部406计算出的多个相似度进行回归分析来计算出第1阈值。
291.第2说话人识别部416通过将女性的多个语音数据中的2个语音数据的特征量的所有组合输入到第2说话人识别模型,从第2说话人识别模型获取2个语音数据的多个组合各
自的相似度。
292.第2阈值计算部417计算能够识别同一说话人的2个语音数据的相似度和互不相同的说话人的2个语音数据的相似度的第2阈值。第2阈值计算部417通过对第2说话人识别部416计算出的多个相似度进行回归分析来计算出第2阈值。
293.阈值存储部408存储第1阈值计算部407计算出的第1阈值和第2阈值计算部417计算出的第2阈值。
294.接着,说明本发明的实施方式3的说话人识别系统。
295.图19是表示本发明的实施方式3的说话人识别系统的结构的图。
296.图19所示的说话人识别系统包括麦克风1以及说话人识别装置22。另外,说话人识别装置22可以不具备麦克风1,也可以具备麦克风1。
297.另外,在本实施方式3中,对与实施方式1以及实施方式2相同的结构附上相同的符号并省略说明。
298.说话人识别装置22包括登记对象语音数据获取部201、特征量提取部202、性别识别模型存储部203、性别识别用语音数据存储部204、性别识别部205、登记部2061、识别对象语音数据获取部211、登记语音数据存储部2121、登记语音数据获取部2131、特征量提取部214、特征量提取部215、说话人识别模型存储部216、模型选择部217、说话人识别部2182、识别结果输出部219、输入受理部221、识别信息获取部222以及阈值存储部223。
299.说话人识别部2182具备相似度计算部2311、相似度校正部233以及相似度判断部2322。
300.相似度校正部233在从第1说话人识别模型获取到相似度的情况下,从获取到的相似度减去第1阈值。此外,相似度校正部233在从第2说话人识别模型获取到相似度的情况下,从获取到的相似度减去第2阈值。相似度校正部233在相似度计算部2311利用第1说话人识别模型计算出相似度的情况下,从阈值存储部223读取第1阈值,并从计算出的相似度减去第1阈值。此外,相似度校正部233在相似度计算部2311利用第2说话人识别模型计算出相似度的情况下,从阈值存储部223读取第2阈值,并从计算出的相似度减去第2阈值。
301.阈值存储部223预先存储用于校正利用第1说话人识别模型计算出的相似度的第1阈值和用于校正利用第2说话人识别模型计算出的相似度的第2阈值。阈值存储部223预先存储由说话人识别模型生成装置41生成的第1阈值和第2阈值。
302.另外,说话人识别模型生成装置41也可以向说话人识别装置22发送存储在阈值存储部408的第1阈值和第2阈值。说话人识别装置22也可以将接收到的第1阈值和第2阈值存储到阈值存储部223。此外,在制造说话人识别装置22时,由说话人识别模型生成装置41生成的第1阈值和第2阈值也可以被存储到阈值存储部223。
303.相似度判断部2322在由相似度校正部233减去第1阈值或第2阈值后的相似度高于第3阈值的情况下,将登记语音数据的说话人识别为识别对象语音数据的说话人。
304.接着,说明本实施方式3的说话人识别模型生成装置41的说话人识别模型生成处理的动作。
305.图20是用于说明本实施方式3的说话人识别模型生成装置的说话人识别模型生成处理的动作的第1流程图,图21是用于说明本实施方式3的说话人识别模型生成装置的说话人识别模型生成处理的动作的第2流程图,图22是用于说明本实施方式3的说话人识别模型
生成装置的说话人识别模型生成处理的动作的第3流程图。
306.步骤s151~步骤s156的处理与图9所示的步骤s61~步骤s66的处理相同,因此省略说明。
307.接着,在步骤s157,第1说话人识别部406从第1说话人识别模型存储部405获取第1说话人识别模型。
308.接着,在步骤s158,第1说话人识别部406从特征量提取部403提取到的多个男性语音数据的特征量中获取2个男性语音数据的特征量。
309.接着,在步骤s159,第1说话人识别部406通过将获取到的2个男性语音数据的特征量输入到第1说话人识别模型来计算2个男性语音数据的相似度。另外,2个男性语音数据是由1个说话人说出的2个男性语音数据和由2个说话人说出的2个男性语音数据的任意其中之一。此时,2个男性语音数据是由1个说话人说出的男性语音数据的情况下的相似度高于2个男性语音数据是由2个说话人说出的男性语音数据的情况下的相似度。
310.接着,在步骤s160,第1说话人识别部406判断是否已计算出所有男性语音数据的组合的相似度。在此,在判断为没有计算出所有男性语音数据的组合的相似度的情况下(在步骤s160为否),处理返回到步骤s158。然后,第1说话人识别部406从特征量提取部403获取多个男性语音数据的特征量中没有计算相似度的2个男性语音数据的特征量。
311.另一方面,在判断为已计算出所有男性语音数据的组合的相似度的情况下(在步骤s160为是),在步骤s161,第1阈值计算部407通过对由第1说话人识别部406计算出的多个相似度进行回归分析,计算出能够识别同一说话人的2个男性语音数据的相似度和互不相同的说话人的2个男性语音数据的相似度的第1阈值。
312.接着,在步骤s162,第1阈值计算部407将计算出的第1阈值存储到阈值存储部408中。
313.步骤s163~步骤s168的处理与图9及图10所示的步骤s67~步骤s72的处理相同,因此省略说明。
314.接着,在步骤s169,第2说话人识别部416从第2说话人识别模型存储部415获取第2说话人识别模型。
315.接着,在步骤s170,第2说话人识别部416从由特征量提取部413提取到的多个女性语音数据的特征量中获取2个女性语音数据的特征量。
316.接着,在步骤s171,第2说话人识别部416通过将获取到的2个女性语音数据的特征量输入到第2说话人识别模型来计算2个女性语音数据的相似度。另外,2个女性语音数据是由1个说话人说出的2个女性语音数据和由2个说话人说出的2个女性语音数据的任意其中之一。此时,2个女性语音数据是由1个说话人说出的女性语音数据的情况下的相似度高于2个女性语音数据是由2个说话人说出的女性语音数据的情况下的相似度。
317.接着,在步骤s172,第2说话人识别部416判断是否已计算出所有女性语音数据的组合的相似度。在此,在判断为没有计算出所有女性语音数据的组合的相似度的情况下(在步骤s172为否),处理返回到步骤s170。然后,第2说话人识别部416从特征量提取部413获取多个女性语音数据的特征量中没有计算相似度的2个女性语音数据的特征量。
318.另一方面,在判断为已计算出所有女性语音数据的组合的相似度的情况下(在步骤s172为是),在步骤s173,第2阈值计算部417通过对由第2说话人识别部416计算出的多个
相似度进行回归分析,计算出能够识别同一说话人的2个女性语音数据的相似度和互不相同的说话人的2个女性语音数据的相似度的第2阈值。
319.接着,在步骤s174,第2阈值计算部417将计算出的第2阈值存储到阈值存储部408。
320.接着,说明本实施方式3的说话人识别装置22的说话人识别处理的动作。
321.图23是用于说明本实施方式3的说话人识别装置的说话人识别处理的动作的第1流程图,图24是用于说明本实施方式3的说话人识别装置的说话人识别处理的动作的第2流程图。
322.步骤s181~步骤s191的处理与图16及图17所示的步骤s131~步骤s141的处理相同,因此省略说明。
323.接着,在步骤s192,相似度校正部233从阈值存储部223获取第1阈值或第2阈值。此时,在模型选择部217选择了第1说话人识别模型的情况下,相似度校正部233从阈值存储部223获取第1阈值。此外,在模型选择部217选择了第2说话人识别模型的情况下,相似度校正部233从阈值存储部223获取第2阈值。
324.接着,在步骤s193,相似度校正部233利用获取到的第1阈值或第2阈值校正由相似度计算部2311计算出的相似度。此时,相似度校正部233从相似度计算部2311计算出的相似度减去第1阈值或第2阈值。
325.接着,在步骤s194,相似度判断部2322判断由相似度校正部233校正后的相似度是否大于第3阈值。另外,第3阈值例如是0。相似度判断部2322在校正后的相似度大于0的情况下,判断为识别对象语音数据与预先登记的登记语音数据一致,在校正后的相似度在0以下的情况下,判断为识别对象语音数据与预先登记的登记语音数据不一致。
326.在此,在判断为相似度校正部233校正后的相似度大于第3阈值的情况下(在步骤s194为是),在步骤s195,相似度判断部2322将登记语音数据的说话人识别为识别对象语音数据的说话人。
327.另一方面,在判断为相似度校正部233校正后的相似度在第3阈值以下的情况下(在步骤s194为否),在步骤s196,相似度判断部2322判断为识别对象语音数据的说话人不是登记语音数据的说话人。
328.步骤s197的处理与图17所示的步骤s145的处理相同,因此省略说明。
329.在利用2个不同的第1说话人识别模型和第2说话人识别模型的情况下,第1说话人识别模型和第2说话人识别模型的输出值的范围有可能不同。对此,在本实施方式3中,在登记时,分别对第1说话人识别模型和第2说话人识别模型,计算能够识别同一说话人的第1阈值以及第2阈值。此外,在识别说话人时,通过从计算出的识别对象语音数据与登记语音数据之间的相似度减去第1阈值或第2阈值,从而校正相似度。并且,通过将校正后的相似度与第1说话人识别模型以及第2说话人识别模型共同的第3阈值进行比较,能够以更高的精确度对识别对象语音数据的说话人进行识别。
330.(实施方式4)
331.说话时间越长,说出的信息量就越多,因此,越容易识别说话人,同一个人的登记语音数据与识别对象语音数据的相似度容易变高。另一方面,说话时间越短,说出的信息量就越少,因此,越难以识别说话人,即使是同一个人的登记语音数据和识别对象语音数据,相似度也有可能变低。因此,通过利用说话时间长的语音数据进行了机器学习的说话人识
别模型识别出说话时间短的识别对象语音数据的说话人的情况下,识别说话人的精确度有可能降低。
332.对此,实施方式4的说话人识别方法让计算机执行:获取识别对象语音数据;获取预先登记的登记语音数据;提取识别对象语音数据的特征量;提取登记语音数据的特征量;在识别对象语音数据的说话人以及登记语音数据的说话人的至少一方的说话时间在规定时间以上的情况下,选择为了识别说话时间在规定时间以上的说话人而利用说话时间在规定时间以上的语音数据进行了机器学习的第3说话人识别模型,在识别对象语音数据的说话人以及登记语音数据的说话人的至少一方的说话时间短于规定时间的情况下,选择为了识别说话时间短于规定时间的说话人而利用说话时间短于规定时间的语音数据进行了机器学习的第4说话人识别模型;通过将识别对象语音数据的特征量和登记语音数据的特征量输入到所选择的第3说话人识别模型以及第4说话人识别模型中的任意其中之一来对识别对象语音数据的说话人进行识别。
333.图25是表示本发明的实施方式4的说话人识别系统的结构的图。
334.图25所示的说话人识别系统包括麦克风1以及说话人识别装置24。另外,说话人识别装置24可以不具备麦克风1,也可以具备麦克风1。
335.另外,在本实施方式4中,对与实施方式1相同的结构附上相同的符号并省略说明。
336.说话人识别装置24包括登记对象语音数据获取部201、说话时间测量部207、登记部2064、识别对象语音数据获取部211、登记语音数据存储部2124、登记语音数据获取部213、特征量提取部214、特征量提取部215、说话人识别模型存储部2164、模型选择部2174、说话人识别部2184以及识别结果输出部219。
337.说话时间测量部207测量由登记对象语音数据获取部201获取到的登记对象语音数据的说话时间。另外,说话时间是登记对象语音数据获取部201开始获取登记对象语音数据的时刻起至结束获取登记对象语音数据的时刻为止的时间。
338.登记部2064将与表示说话时间测量部207测量到的说话时间的说话时间信息相互对应的登记对象语音数据作为登记语音数据而进行登记。登记部2064将登记语音数据登记到登记语音数据存储部2124。
339.另外,说话人识别装置24也可以还具备受理有关登记对象语音数据的说话人的信息的输入的输入受理部。并且,登记部2064也可以将登记语音数据与有关说话人的信息相互对应地登记到登记语音数据存储部2124。有关说话人的信息例如是说话人的名字等。
340.登记语音数据存储部2124存储与说话时间信息相互对应的登记语音数据。登记语音数据存储部2124存储多个登记语音数据。
341.说话人识别模型存储部2164预先存储:为了识别说话时间在规定时间以上的说话人而利用说话时间在规定以上的语音数据进行了机器学习的第3说话人识别模型;和为了识别说话时间短于规定时间的说话人而利用说话时间短于规定时间的语音数据进行了机器学习的第4说话人识别模型。说话人识别模型存储部2164预先存储由后述的说话人识别模型生成装置44生成的第3说话人识别模型和第4说话人识别模型。另外,关于第3说话人识别模型和第4说话人识别模型的生成方法将在后面说明。
342.模型选择部2174在识别对象语音数据的说话人以及登记语音数据的说话人的至少一方的说话时间在规定时间以上的情况下,选择为了识别说话时间在规定时间以上的说
话人而利用说话时间在规定时间以上的语音数据进行了机器学习的第3说话人识别模型。此外,模型选择部2174在识别对象语音数据的说话人以及登记语音数据的说话人的至少一方的说话时间短于规定时间的情况下,选择为了识别说话时间短于规定时间的说话人而利用说话时间短于规定时间的语音数据进行了机器学习的第4说话人识别模型。
343.在本实施方式4中,模型选择部2174在登记语音数据的说话人的说话时间在规定时间以上的情况下,选择第3说话人识别模型,在登记语音数据的说话人的说话时间短于规定时间的情况下,选择第4说话人识别模型。登记语音数据预先与说话时间进行了相互对应。因此,模型选择部2174在与登记语音数据相对应的说话时间在规定时间以上的情况下,选择第3说话人识别模型,在与登记语音数据相对应的说话时间短于规定时间的情况下,选择第4说话人识别模型。另外,规定时间例如是60秒。
344.说话人识别部2184通过将识别对象语音数据的特征量和登记语音数据的特征量输入到由模型选择部2174选择的第3说话人识别模型和第4说话人识别模型的任意其中之一,对识别对象语音数据的说话人进行识别。
345.说话人识别部2184具备相似度计算部2314以及相似度判断部232。
346.相似度计算部2314通过将识别对象语音数据的特征量和多个登记语音数据的各特征量输入到所选择的第3说话人识别模型和第4说话人识别模型的任意其中之一,从第3说话人识别模型和第4说话人识别模型的任意其中之一获取识别对象语音数据与多个登记语音数据各自的相似度。
347.接着,说明本发明的实施方式4中的说话人识别模型生成装置。
348.图26是表示本发明的实施方式4的说话人识别模型生成装置的结构的图。
349.图26所示的说话人识别模型生成装置44包括长时间语音数据存储部421、长时间语音数据获取部422、特征量提取部423、第3说话人识别模型生成部424、第3说话人识别模型存储部425、短时间语音数据存储部431、短时间语音数据获取部432、特征量提取部433、第4说话人识别模型生成部434以及第4说话人识别模型存储部435。
350.长时间语音数据获取部422、特征量提取部423、第3说话人识别模型生成部424、短时间语音数据获取部432、特征量提取部433以及第4说话人识别模型生成部434通过处理器而实现。长时间语音数据存储部421、第3说话人识别模型存储部425、短时间语音数据存储部431以及第4说话人识别模型存储部435通过存储器而实现。
351.长时间语音数据存储部421存储被赋予用于识别说话人的说话人识别标签且说话时间在规定时间以上的多个长时间语音数据。长时间语音数据是说话时间在规定时间以上的语音数据。长时间语音数据存储部421针对多个说话人的每一个说话人存储互不相同的多个长时间语音数据。
352.长时间语音数据获取部422从长时间语音数据存储部421获取被赋予了用于识别说话人的说话人识别标签的多个长时间语音数据。另外,在本实施方式4中,虽然长时间语音数据获取部422从长时间语音数据存储部421获取多个长时间语音数据,但本发明并不特别限定于此,也可以经由网络从外部设备获取(接收)多个长时间语音数据。
353.特征量提取部423提取由长时间语音数据获取部422获取到的多个长时间语音数据的特征量。特征量例如是i-vector。
354.第3说话人识别模型生成部424将多个长时间语音数据中的第1长时间语音数据和
第2长时间语音数据的各特征量以及第1长时间语音数据和第2长时间语音数据的各说话人识别标签的相似度用作教师数据,通过机器学习生成将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的第3说话人识别模型。例如,第3说话人识别模型以如果第1长时间语音数据的说话人识别标签与第2长时间语音数据的说话人识别标签相同,则输出最高的相似度,如果第1长时间语音数据的说话人识别标签与第2长时间语音数据的说话人识别标签不同,则输出最低的相似度的方式进行机器学习。
355.作为第3说话人识别模型,采用利用plda的模型。plda模型自动地从400维的i-vector(特征量)选择对说话人识别有效的特征量,并计算对数似然比作为相似度。
356.另外,作为机器学习,也可列举例如:利用对输入信息赋予标签(输出信息)的教师数据来学习输入与输出之间的关系的监督学习;仅根据无标签的输入构建数据结构的无监督学习;处理有标签和无标签双方的半监督学习;以及通过反复试验来学习将奖励最大化的行为的强化学习等。此外,机器学习的具体方法有神经网络(包括利用多层神经网络的深度学习)、遗传编程、决策树、贝叶斯网络或支持向量机(svm)等。在第3说话人识别模型的机器学习中,利用以上列举的具体例的任意一个即可。
357.第3说话人识别模型存储部425存储第3说话人识别模型生成部424生成的第3说话人识别模型。
358.短时间语音数据存储部431存储被赋予用于识别说话人的说话人识别标签且说话时间短于规定时间的多个短时间语音数据。短时间语音数据是说话时间短于规定时间的语音数据。短时间语音数据存储部431针对多个说话人的每一个说话人存储互不相同的多个短时间语音数据。
359.短时间语音数据获取部432从短时间语音数据存储部431获取被赋予了用于识别说话人的说话人识别标签的多个短时间语音数据。另外,在本实施方式4中,虽然短时间语音数据获取部432从短时间语音数据存储部431获取多个短时间语音数据,但本发明并不特别限定于此,也可以经由网络从外部设备获取(接收)多个短时间语音数据。
360.特征量提取部433提取由短时间语音数据获取部432获取到的多个短时间语音数据的特征量。特征量例如是i-vector。
361.第4说话人识别模型生成部434将多个短时间语音数据中的第1短时间语音数据和第2短时间语音数据的各特征量以及第1短时间语音数据和第2短时间语音数据的各说话人识别标签的相似度用作教师数据,通过机器学习生成将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的第4说话人识别模型。例如,第4说话人识别模型以如果第1短时间语音数据的说话人识别标签与第2短时间语音数据的说话人识别标签相同,则输出最高的相似度,如果第1短时间语音数据的说话人识别标签与第2短时间语音数据的说话人识别标签不同,则输出最低的相似度的方式进行机器学习。
362.作为第4说话人识别模型,采用利用plda的模型。plda模型自动地从400维的i-vector(特征量)选择对说话人识别有效的特征量,并计算对数似然比作为相似度。
363.另外,作为机器学习,也可列举例如:利用对输入信息赋予标签(输出信息)的教师数据来学习输入与输出之间的关系的监督学习;仅根据无标签的输入构建数据结构的无监督学习;处理有标签和无标签双方的半监督学习;以及通过反复试验来学习将奖励最大化的行为的强化学习等。此外,机器学习的具体方法有神经网络(包括利用多层神经网络的深
度学习)、遗传编程、决策树、贝叶斯网络或支持向量机(svm)等。在第4说话人识别模型的机器学习中,利用以上列举的具体例的任意一个即可。
364.第4说话人识别模型存储部435存储第4说话人识别模型生成部434生成的第4说话人识别模型。
365.另外,说话人识别模型生成装置44也可以向说话人识别装置24发送存储在第3说话人识别模型存储部425的第3说话人识别模型以及存储在第4说话人识别模型存储部435的第4说话人识别模型。说话人识别装置24也可以将接收到的第3说话人识别模型以及第4说话人识别模型存储到说话人识别模型存储部2164。此外,在制造说话人识别装置24时,也可以在说话人识别装置24存储由说话人识别模型生成装置44生成的第3说话人识别模型以及第4说话人识别模型。
366.接着,说明本实施方式4的说话人识别装置24的登记处理以及说话人识别处理各自的动作。
367.图27是用于说明本实施方式4的说话人识别装置的登记处理的动作的流程图。
368.首先,在步骤s201,登记对象语音数据获取部201获取从麦克风1输出的登记对象语音数据。希望登记自己说出的语音数据的说话人对着麦克风1说出规定的文章。此时,规定的文章是说话时间在规定时间以上的文章以及说话时间短于规定时间的文章的任意其中之一。说话人识别装置24也可以向登记对象说话人提示预先决定的多个文章。此时,登记对象说话人说出被提示的多个文章。
369.接着,在步骤s202,说话时间测量部207测量由登记对象语音数据获取部201获取到的登记对象语音数据的说话时间。
370.接着,在步骤s203,登记部2064将与表示说话时间测量部207测量到的说话时间的说话时间信息进行相互对应的登记对象语音数据作为登记语音数据而存储到登记语音数据存储部2124。
371.图28是用于说明本实施方式4的说话人识别装置的说话人识别处理的动作的第1流程图,图29是用于说明本实施方式4的说话人识别装置的说话人识别处理的动作的第2流程图。
372.步骤s211~步骤s214的处理与图6所示的步骤s31~步骤s34的处理相同,因此省略说明。
373.接着,在步骤s215,模型选择部2174获取与登记语音数据获取部213获取到的登记语音数据相对应的说话时间。
374.接着,在步骤s216,模型选择部2174判断获取到的说话时间是否在规定时间以上。在此,在判断为获取到的说话时间在规定时间以上的情况下(在步骤s216为是),在步骤s217,模型选择部2174选择第3说话人识别模型。模型选择部2174从说话人识别模型存储部2164获取所选择的第3说话人识别模型,并向相似度计算部2314输出获取到的第3说话人识别模型。
375.另一方面,在判断为获取到的说话时间不是规定时间以上的情况下,即判断为获取到的说话时间短于规定时间的情况下(在步骤s216为否),在步骤s218,模型选择部2174选择第4说话人识别模型。模型选择部2174从说话人识别模型存储部2164获取所选择的第4说话人识别模型,并向相似度计算部2314输出获取到的第4说话人识别模型。
376.接着,在步骤s219,相似度计算部2314通过将识别对象语音数据的特征量和登记语音数据的特征量输入到所选择的第3说话人识别模型和第4说话人识别模型的任意其中之一,来计算识别对象语音数据与登记语音数据之间的相似度。
377.接着,在步骤s220,相似度计算部2314判断是否已计算出识别对象语音数据与存储在登记语音数据存储部2124的所有登记语音数据之间的相似度。在此,在判断为没有计算出识别对象语音数据与所有登记语音数据之间的相似度的情况下(在步骤s220为否),处理返回到步骤s213。然后,登记语音数据获取部213从存储在登记语音数据存储部2124的多个登记语音数据中获取没有计算出相似度的登记语音数据。
378.另一方面,在判断为已计算出识别对象语音数据与所有登记语音数据之间的相似度的情况下(在步骤s220为是),在步骤s221,相似度判断部232判断最高的相似度是否大于阈值。
379.另外,步骤s221~步骤s224的处理与图7所示的步骤s41~步骤s44的处理相同,因此省略说明。
380.如上所述,在识别对象语音数据的说话人和登记语音数据的说话人的至少一方的说话时间在规定时间以上的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到利用说话时间在规定时间以上的语音数据进行了机器学习的第3说话人识别模型,由此对识别对象语音数据的说话人进行识别。此外,在识别对象语音数据的说话人和登记语音数据的说话人的至少一方的说话时间短于规定时间的情况下,通过将识别对象语音数据的特征量和登记语音数据的特征量输入到利用说话时间短于规定时间的语音数据进行了机器学习的第4说话人识别模型,由此对识别对象语音数据的说话人进行识别。
381.因此,利用与识别对象语音数据以及登记语音数据的至少一方的说话时间的长度相对应的第3说话人识别模型和第4说话人识别模型来对识别对象语音数据的说话人进行识别,因此,能够提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度。
382.另外,在本实施方式4中,模型选择部2174基于与登记语音数据相对应的说话时间选择第3说话人识别模型以及第4说话人识别模型的任意其中之一,但本发明并不特别限定于此。说话人识别装置24也可以具备测量由登记语音数据获取部213获取到的登记语音数据的说话人的说话时间的说话时间测量部。说话时间测量部也可以向模型选择部2174输出测量到的说话时间。另外,在测量由登记语音数据获取部213获取到的登记语音数据的说话人的说话时间的情况下,不需要说话时间测量部207,登记部2064也可以只将由登记对象语音数据获取部201获取到的登记对象语音数据作为登记语音数据存储到登记语音数据存储部2124。
383.此外,在本实施方式4中,模型选择部2174基于登记语音数据的说话人的说话时间选择第3说话人识别模型以及第4说话人识别模型的任意其中之一,但本发明并不特别限定于此。模型选择部2174也可以基于识别对象语音数据的说话人的说话时间选择第3说话人识别模型以及第4说话人识别模型的任意其中之一。此时,说话人识别装置24也可以具备测量识别对象语音数据的说话人的说话时间的说话时间测量部。说话时间测量部也可以测量由识别对象语音数据获取部211获取到的识别对象语音数据的说话时间,并向模型选择部2174输出测量到的说话时间。模型选择部2174在识别对象语音数据的说话人的说话时间在规定时间以上的情况下,选择第3说话人识别模型,在识别对象语音数据的说话人的说话时
间短于规定时间的情况下,选择第4说话人识别模型。另外,规定时间例如是30秒。此外,在测量识别对象语音数据的说话人的说话时间的情况下,不需要说话时间测量部207,登记部2064也可以只将登记对象语音数据获取部201获取到的登记对象语音数据作为登记语音数据存储到登记语音数据存储部2124。
384.此外,在本实施方式4中,模型选择部2174也可以基于登记语音数据的说话人的说话时间和识别对象语音数据的说话人的说话时间双方选择第3说话人识别模型以及第4说话人识别模型的任意其中之一。模型选择部2174也可以在登记语音数据的说话人的说话时间和识别对象语音数据的说话人的说话时间这双方在规定时间以上的情况下,选择第3说话人识别模型。此外,模型选择部2174也可以在登记语音数据的说话人的说话时间和识别对象语音数据的说话人的说话时间的至少一方短于规定时间的情况下,选择第4说话人识别模型。另外,规定时间例如是20秒。在该情况下,说话人识别装置24也可以还具备测量识别对象语音数据的说话人的说话时间的说话时间测量部。此外,说话人识别装置24也可以不具备说话时间测量部207而具备测量由登记语音数据获取部213获取到的登记语音数据的说话人的说话时间的说话时间测量部。
385.进一步,在本实施方式4中,模型选择部2174也可以在登记语音数据的说话人的说话时间和识别对象语音数据的说话人的说话时间的至少一方在规定时间以上的情况下,选择第3说话人识别模型。此外,模型选择部2174也可以在登记语音数据的说话人的说话时间和识别对象语音数据的说话人的说话时间这双方短于规定时间的情况下,选择第4说话人识别模型。另外,规定时间例如是100秒。在该情况下,说话人识别装置24也可以还具备测量识别对象语音数据的说话人的说话时间的说话时间测量部。此外,说话人识别装置24也可以不具备说话时间测量部207而具备测量由登记语音数据获取部213获取到的登记语音数据的说话人的说话时间的说话时间测量部。
386.接着,说明本实施方式4的说话人识别模型生成装置44的说话人识别模型生成处理的动作。
387.图30是用于说明本实施方式4的说话人识别模型生成装置的说话人识别模型生成处理的动作的第1流程图,图31是用于说明本实施方式4的说话人识别模型生成装置的说话人识别模型生成处理的动作的第2流程图。
388.首先,在步骤s231,长时间语音数据获取部422从长时间语音数据存储部421获取被赋予用于识别说话人的说话人识别标签且说话时间在规定时间以上的多个长时间语音数据。
389.接着,在步骤s232,特征量提取部423提取由长时间语音数据获取部422获取到的多个长时间语音数据的特征量。
390.接着,在步骤s233,第3说话人识别模型生成部424获取多个长时间语音数据中的第1长时间语音数据和第2长时间语音数据的各特征量以及第1长时间语音数据和第2长时间语音数据的各说话人识别标签的相似度作为教师数据。
391.接着,在步骤s234,第3说话人识别模型生成部424利用获取到的教师数据,机器学习将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的第3说话人识别模型。
392.接着,在步骤s235,第3说话人识别模型生成部424判断是否利用多个长时间语音
数据中的所有长时间语音数据的组合机器学习了第3说话人识别模型。在此,在判断为没有利用所有长时间语音数据的组合机器学习第3说话人识别模型的情况下(在步骤s235为否),处理返回到步骤s233。然后,第3说话人识别模型生成部424获取多个长时间语音数据中的没有用于机器学习的组合的第1长时间语音数据和第2长时间语音数据的各特征量以及第1长时间语音数据和第2长时间语音数据的各说话人识别标签的相似度作为教师数据。
393.另一方面,在判断为利用所有长时间语音数据的组合机器学习了第3说话人识别模型的情况下(在步骤s235为是),在步骤s236,第3说话人识别模型生成部424将通过机器学习而生成的第3说话人识别模型存储到第3说话人识别模型存储部425。
394.接着,在步骤s237,短时间语音数据获取部432从短时间语音数据存储部431获取被赋予用于识别说话人的说话人识别标签且说话时间短于规定时间的多个短时间语音数据。
395.接着,在步骤s238,特征量提取部433提取由短时间语音数据获取部432获取到的多个短时间语音数据的特征量。
396.接着,在步骤s239,第4说话人识别模型生成部434获取多个短时间语音数据中的第1短时间语音数据和第2短时间语音数据的各特征量以及第1短时间语音数据和第2短时间语音数据的各说话人识别标签的相似度作为教师数据。
397.接着,在步骤s240,第4说话人识别模型生成部434利用获取到的教师数据,机器学习将2个语音数据的各特征量作为输入,将2个语音数据的相似度作为输出的第4说话人识别模型。
398.接着,在步骤s241,第4说话人识别模型生成部434判断是否利用多个短时间语音数据中的所有短时间语音数据的组合机器学习了第4说话人识别模型。在此,在判断为没有利用所有短时间语音数据的组合机器学习第4说话人识别模型的情况下(在步骤s241为否),处理返回到步骤s239。然后,第4说话人识别模型生成部434获取多个短时间语音数据中的没有用于机器学习的组合的第1短时间语音数据和第2短时间语音数据的各特征量以及第1短时间语音数据和第2短时间语音数据的各说话人识别标签的相似度作为教师数据。
399.另一方面,在判断为利用所有短时间语音数据的组合机器学习了第4说话人识别模型的情况下(在步骤s241为是),在步骤s242,第4说话人识别模型生成部434将通过机器学习而生成的第4说话人识别模型存储到第4说话人识别模型存储部435。
400.(实施方式5)
401.在上述的实施方式4中,计算出存储在登记语音数据存储部2124的所有登记语音数据各自与识别对象语音数据之间的相似度,相似度为最高的登记语音数据的说话人被识别为识别对象语音数据的说话人。而在实施方式5中,输入识别对象语音数据的说话人的识别信息,获取存储在登记语音数据存储部212的多个登记语音数据中与该识别信息预先进行相互对应的1个登记语音数据。并且,计算1个登记语音数据与识别对象语音数据之间的相似度,在相似度高于阈值的情况下,登记语音数据的说话人被识别为识别对象语音数据的说话人。
402.图32是表示本发明的实施方式5的说话人识别系统的结构的图。
403.图32所示的说话人识别系统包括麦克风1以及说话人识别装置25。另外,说话人识别装置25可以不具备麦克风1,也可以具备麦克风1。
404.另外,在本实施方式5中,对与实施方式1~4相同的结构附上相同的符号并省略说明。
405.说话人识别装置25包括登记对象语音数据获取部201、说话时间测量部207、登记部2065、识别对象语音数据获取部211、登记语音数据存储部2125、登记语音数据获取部2135、特征量提取部214、特征量提取部215、说话人识别模型存储部2164、模型选择部2174、说话人识别部2185、识别结果输出部219、输入受理部221以及识别信息获取部222。
406.登记部2065将与表示说话时间测量部207测量到的说话时间的说话时间信息以及识别信息获取部222获取到的识别信息进行相互对应的登记对象语音数据作为登记语音数据而进行登记。登记部2065将登记语音数据登记到登记语音数据存储部2125。
407.登记语音数据存储部2125存储与说话时间信息以及识别信息进行相互对应的登记语音数据。登记语音数据存储部2125存储多个登记语音数据。多个登记语音数据与用于识别多个登记语音数据各自的说话人的识别信息相互对应。
408.登记语音数据获取部2135从登记在登记语音数据存储部2125的多个登记语音数据中获取与由识别信息获取部222获取到的识别信息一致的识别信息所对应的登记语音数据。
409.说话人识别部2185具备相似度计算部2315以及相似度判断部2325。
410.相似度计算部2315通过将识别对象语音数据的特征量和登记语音数据的特征量输入到所选择的第3说话人识别模型和第4说话人识别模型的任意其中之一,从第3说话人识别模型和第4说话人识别模型的任意其中之一获取识别对象语音数据与登记语音数据之间的相似度。
411.相似度判断部2325在所获取的相似度高于阈值的情况下,将登记语音数据的说话人识别为识别对象语音数据的说话人。
412.接着,说明本实施方式5的说话人识别装置25的登记处理以及说话人识别处理各自的动作。
413.图33是用于说明本发明的实施方式5的说话人识别装置的登记处理的动作的流程图。
414.步骤s251以及步骤s252的处理与图15所示的步骤s121以及步骤s122的处理相同,因此省略说明。此外,步骤s253的处理与图27所示的步骤s202的处理相同,因此省略说明。
415.接着,在步骤s254,登记部2065将与说话时间测量部207测量到的说话时间信息以及识别信息获取部222获取到的识别信息进行相互对应的登记对象语音数据作为登记语音数据存储到登记语音数据存储部2125。据此,登记语音数据存储部2125存储与说话时间信息以及识别信息相互对应的登记语音数据。
416.图34是用于说明本实施方式5的说话人识别装置的说话人识别处理的动作的第1流程图,图35是用于说明本实施方式5的说话人识别装置的说话人识别处理的动作的第2流程图。
417.步骤s261~步骤s264的处理与图16所示的步骤s131~步骤s134的处理相同,因此省略说明。
418.接着,在步骤s265,登记语音数据获取部2135从登记在登记语音数据存储部2125的多个登记语音数据中获取与由识别信息获取部222获取到的识别信息相一致的识别信息
所对应的登记语音数据。
419.步骤s266~步骤s270的处理与图28所示的步骤s214~步骤s218的处理相同,因此省略说明。
420.接着,在步骤s271,相似度计算部2315通过将识别对象语音数据的特征量和登记语音数据的特征量输入到所选择的第3说话人识别模型和第4说话人识别模型的任意其中之一,从第3说话人识别模型和第4说话人识别模型的任意其中之一获取识别对象语音数据与登记语音数据之间的相似度。
421.接着,在步骤s272,相似度判断部2325判断相似度计算部2315计算出的相似度是否大于阈值。
422.在此,在判断为相似度计算部2315计算出的相似度大于阈值的情况下(在步骤s272为是),在步骤s273,相似度判断部2325将登记语音数据的说话人识别为识别对象语音数据的说话人。
423.另一方面,在判断为相似度计算部2315计算出的相似度在阈值以下的情况下(在步骤s272为否),在步骤s274,相似度判断部2325判断为识别对象语音数据的说话人不是登记语音数据的说话人。
424.步骤s275的处理与图7所示的步骤s44的处理相同,因此省略说明。
425.如上所述,在本实施方式5中,只计算出与识别信息相对应的登记语音数据与识别对象语音数据之间的相似度。因此,与计算多个登记语音数据各自与识别对象语音数据之间的多个相似度的实施方式4相比,在实施方式5中,能够减轻计算相似度的处理负荷。
426.(实施方式6)
427.在上述的实施方式4以及实施方式5中,根据登记语音数据的说话人的说话时间选择第3说话人识别模型和第4说话人识别模型的任意其中之一,但是在利用2个不同的第3说话人识别模型和第4说话人识别模型的情况下,第3说话人识别模型和第4说话人识别模型的输出值的范围有可能不同。对此,在实施方式6中,在登记语音数据时,分别针对第3说话人识别模型和第4说话人识别模型,计算能够识别同一说话人的第3阈值以及第4阈值,并存储计算出的第3阈值以及第4阈值。此外,在识别语音数据时,通过从计算出的识别对象语音数据与登记语音数据之间的相似度减去第3阈值或第4阈值来校正相似度。并且,通过将校正后的相似度与第3说话人识别模型以及第4说话人识别模型共同的第5阈值进行比较,从而对识别对象语音数据的说话人进行识别。
428.首先,说明本发明的实施方式6的说话人识别模型生成装置。
429.图36是表示本发明的实施方式6的说话人识别模型生成装置的结构的图。
430.图36所示的说话人识别模型生成装置46包括长时间语音数据存储部421、长时间语音数据获取部422、特征量提取部423、第3说话人识别模型生成部424、第3说话人识别模型存储部425、第3说话人识别部426、第3阈值计算部427、阈值存储部428、短时间语音数据存储部431、短时间语音数据获取部432、特征量提取部433、第4说话人识别模型生成部434、第4说话人识别模型存储部435、第4说话人识别部436以及第4阈值计算部437。
431.另外,在本实施方式6中,对与实施方式1-5相同的结构附上相同的符号并省略说明。
432.第3说话人识别部426通过将说话时间在规定时间以上的多个语音数据中的2个语
音数据的特征量的所有组合输入到第3说话人识别模型,从第3说话人识别模型获取2个语音数据的多个组合各自的相似度。
433.第3阈值计算部427计算能够识别同一说话人的2个语音数据的相似度和互不相同的说话人的2个语音数据的相似度的第3阈值。第3阈值计算部427通过对第3说话人识别部426计算出的多个相似度进行回归分析来计算出第3阈值。
434.第4说话人识别部436通过将说话时间短于规定时间的多个语音数据中的2个语音数据的特征量的所有组合输入到第4说话人识别模型,从第4说话人识别模型获取2个语音数据的多个组合各自的相似度。
435.第4阈值计算部437计算能够识别同一说话人的2个语音数据的相似度和互不相同的说话人的2个语音数据的相似度的第4阈值。第4阈值计算部437通过对第4说话人识别部436计算出的多个相似度进行回归分析来计算出第4阈值。
436.阈值存储部428存储第3阈值计算部427计算出的第3阈值和第4阈值计算部437计算出的第4阈值。
437.接着,说明本发明的实施方式6的说话人识别系统。
438.图37是表示本发明的实施方式6的说话人识别系统的结构的图。
439.图37所示的说话人识别系统包括麦克风1以及说话人识别装置26。另外,说话人识别装置26可以不具备麦克风1,也可以具备麦克风1。
440.另外,在本实施方式6中,对与实施方式1~5相同的结构附上相同的符号并省略说明。
441.说话人识别装置26包括登记对象语音数据获取部201、说话时间测量部207、登记部2065、识别对象语音数据获取部211、登记语音数据存储部2125、登记语音数据获取部2135、特征量提取部214、特征量提取部215、说话人识别模型存储部2164、模型选择部2174、说话人识别部2186、识别结果输出部219、输入受理部221、识别信息获取部222以及阈值存储部2236。
442.说话人识别部2186具备相似度计算部2315、相似度校正部2336以及相似度判断部2326。
443.相似度校正部2336在从第3说话人识别模型获取到相似度的情况下,从获取到的相似度减去第3阈值。此外,相似度校正部2336在从第4说话人识别模型获取到相似度的情况下,从获取到的相似度减去第4阈值。相似度校正部2336在相似度计算部2315利用第3说话人识别模型计算出相似度的情况下,从阈值存储部2236读取第3阈值,并从计算出的相似度减去第3阈值。此外,相似度校正部2336在相似度计算部2315利用第4说话人识别模型计算出相似度的情况下,从阈值存储部2236读取第4阈值,并从计算出的相似度减去第4阈值。
444.阈值存储部2236预先存储用于校正利用第3说话人识别模型计算出的相似度的第3阈值和用于校正利用第4说话人识别模型计算出的相似度的第4阈值。阈值存储部2236预先存储由说话人识别模型生成装置46生成的第3阈值和第4阈值。
445.另外,说话人识别模型生成装置46也可以向说话人识别装置26发送存储在阈值存储部428的第3阈值和第4阈值。说话人识别装置26也可以将接收到的第3阈值和第4阈值存储到阈值存储部2236。此外,在制造说话人识别装置26时,由说话人识别模型生成装置46生成的第3阈值和第4阈值也可以被存储到阈值存储部2236。
446.相似度判断部2326在由相似度校正部2336减去第3阈值或第4阈值后的相似度高于第5阈值的情况下,将登记语音数据的说话人识别为识别对象语音数据的说话人。
447.接着,说明本实施方式6的说话人识别模型生成装置46的说话人识别模型生成处理的动作。
448.图38是用于说明本实施方式6的说话人识别模型生成装置的说话人识别模型生成处理的动作的第1流程图,图39是用于说明本实施方式6的说话人识别模型生成装置的说话人识别模型生成处理的动作的第2流程图,图40是用于说明本实施方式6的说话人识别模型生成装置的说话人识别模型生成处理的动作的第3流程图。
449.步骤s281~步骤s286的处理与图30所示的步骤s231~步骤s236的处理相同,因此省略说明。
450.接着,在步骤s287,第3说话人识别部426从第3说话人识别模型存储部425获取第3说话人识别模型。
451.接着,在步骤s288,第3说话人识别部426从特征量提取部423提取到的多个长时间语音数据的特征量中获取2个长时间语音数据的特征量。
452.接着,在步骤s289,第3说话人识别部426通过将获取到的2个长时间语音数据的特征量输入到第3说话人识别模型来计算2个长时间语音数据之间的相似度。另外,2个长时间语音数据是由1个说话人说出的2个长时间语音数据和由2个说话人说出的2个长时间语音数据的任意其中之一。此时,2个长时间语音数据是由1个说话人说出的长时间语音数据的情况下的相似度高于2个长时间语音数据是由2个说话人说出的长时间语音数据的情况下的相似度。
453.接着,在步骤s290,第3说话人识别部426判断是否已计算出所有长时间语音数据的组合的相似度。在此,在判断为没有计算出所有长时间语音数据的组合的相似度的情况下(在步骤s290为否),处理返回到步骤s288。然后,第3说话人识别部426从特征量提取部423获取多个长时间语音数据的特征量中没有计算相似度的2个长时间语音数据的特征量。
454.另一方面,在判断为计算出所有长时间语音数据的组合的相似度的情况下(在步骤s290为是),在步骤s291,第3阈值计算部427通过对由第3说话人识别部426计算出的多个相似度进行回归分析,计算出能够识别同一说话人的2个长时间语音数据的相似度和互不相同的说话人的2个长时间语音数据的相似度的第3阈值。
455.接着,在步骤s292,第3阈值计算部427将计算出的第3阈值存储到阈值存储部428。
456.步骤s293~步骤s298的处理与图30及图31所示的步骤s237~步骤s242的处理相同,因此省略说明。
457.接着,在步骤s299,第4说话人识别部436从第4说话人识别模型存储部435获取第4说话人识别模型。
458.接着,在步骤s300,第4说话人识别部436从特征量提取部433提取到的多个短时间语音数据的特征量中获取2个短时间语音数据的特征量。
459.接着,在步骤s301,第4说话人识别部436通过将获取到的2个短时间语音数据的特征量输入到第4说话人识别模型来计算2个短时间语音数据之间的相似度。另外,2个短时间语音数据是由1个说话人说出的2个短时间语音数据和由2个说话人说出的2个短时间语音数据的任意其中之一。此时,2个短时间语音数据是由1个说话人说出的长时间语音数据的
情况下的相似度高于2个短时间语音数据是由2个说话人说出的短时间语音数据的情况下的相似度。
460.接着,在步骤s302,第4说话人识别部436判断是否已计算出所有短时间语音数据的组合的相似度。在此,在判断为没有计算出所有短时间语音数据的组合的相似度的情况下(在步骤s302为否),处理返回到步骤s300。然后,第4说话人识别部436从特征量提取部433获取多个短时间语音数据的特征量中没有计算相似度的2个短时间语音数据的特征量。
461.另一方面,在判断为计算出所有短时间语音数据的组合的相似度的情况下(在步骤s302为是),在步骤s303,第4阈值计算部437通过对由第4说话人识别部436计算出的多个相似度进行回归分析,计算出能够识别同一说话人的2个短时间语音数据的相似度和互不相同的说话人的2个短时间语音数据的相似度的第4阈值。
462.接着,在步骤s304,第4阈值计算部437将计算出的第4阈值存储到阈值存储部428。
463.接着,说明本实施方式6的说话人识别装置26的说话人识别处理的动作。
464.图41是用于说明本实施方式6的说话人识别装置的说话人识别处理的动作的第1流程图,图42是用于说明本实施方式6的说话人识别装置的说话人识别处理的动作的第2流程图。
465.步骤s311~步骤s321的处理与图34及图35所示的步骤s261~步骤s271的处理相同,因此省略说明。
466.接着,在步骤s322,相似度校正部2336从阈值存储部2236获取第3阈值或第4阈值。此时,在模型选择部2174选择了第3说话人识别模型的情况下,相似度校正部2336从阈值存储部2236获取第3阈值。此外,在模型选择部2174选择了第4说话人识别模型的情况下,相似度校正部2336从阈值存储部2236获取第4阈值。
467.接着,在步骤s323,相似度校正部2336利用获取到的第3阈值或第4阈值校正由相似度计算部2315计算出的相似度。此时,相似度校正部2336从相似度计算部2315计算出的相似度减去第3阈值或第4阈值。
468.接着,在步骤s324,相似度判断部2326判断由相似度校正部2336校正后的相似度是否大于第5阈值。另外,第5阈值例如是0。相似度判断部2326在校正后的相似度大于0的情况下,判断为识别对象语音数据与预先登记的登记语音数据一致,在校正后的相似度在0以下的情况下,判断为识别对象语音数据与预先登记的登记语音数据不一致。
469.在此,在判断为相似度校正部2336校正后的相似度大于第5阈值的情况下(在步骤s324为是),在步骤s325,相似度判断部2326将登记语音数据的说话人识别为识别对象语音数据的说话人。
470.另一方面,在判断为相似度校正部2336校正后的相似度在第5阈值以下的情况下(在步骤s324为否),在步骤s326,相似度判断部2326判断为识别对象语音数据的说话人不是登记语音数据的说话人。
471.步骤s327的处理与图35所示的步骤s275的处理相同,因此省略说明。
472.在利用2个不同的第3说话人识别模型和第4说话人识别模型的情况下,第3说话人识别模型和第4说话人识别模型的输出值的范围有可能不同。对此,在本实施方式6中,在登记时,分别针对第3说话人识别模型和第4说话人识别模型,计算能够识别同一说话人的第3阈值以及第4阈值。此外,在识别说话人时,通过从计算出的识别对象语音数据与登记语音
数据之间的相似度减去第3阈值或第4阈值,从而校正相似度。并且,通过将校正后的相似度与第3说话人识别模型以及第4说话人识别模型共同的第5阈值进行比较,能够以更高的精确度对识别对象语音数据的说话人进行识别。
473.另外,在上述各实施方式中,各构成要素可由专用的硬件构成,或者通过执行适于各构成要素的软件程序而实现。各构成要素可以通过由cpu或处理器等的程序执行部读取存储在硬盘或半导体存储器等存储介质中的软件程序并执行而实现。
474.本发明的实施方式所涉及的装置的功能的一部分或全部典型地作为集成电路即lsi(large scale integration)而实现。这些功能可以单独地集成到1个芯片中,也可以以包含一部分或全部功能的方式集成到1个芯片中。此外,集成电路化并不限定于lsi,也可以通过专用电路或通用处理器实现。也可以利用制造lsi后可编程的fpga(field programmable gate array)或可重新构筑lsi内部的电路元件的连接或设定的可重构处理器。
475.此外,可将本发明的实施方式所涉及的装置的功能的一部分或全部通过由cpu等处理器执行程序而实现。
476.此外,上文中使用的数字全部是为了具体说明本发明而例示的数字,本发明并不限定于例示的数字。
477.此外,上述流程图所示的各步骤被执行的顺序是为了具体说明本发明而例示的顺序,可在获得同样的效果的范围采用上述以外的顺序。此外,上述步骤的一部分也可以与其他步骤同时(并列)执行。
478.产业上的可利用性
479.本发明涉及的技术能够提高对识别对象的说话人是否为预先登记的说话人进行识别的精确度,因此,作为识别说话人的技术具有使用价值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1