用于情感音乐推荐和创作的方法、系统和介质与流程
1.至少一些示例性实施方案涉及音乐推荐和音乐创作系统,并且具体来说涉及用于创作和推荐旨在引发听者情感状态的特定改变的音乐的系统。
背景技术:
2.情感是心理学中用来描述情绪、心情或感觉体验的概念。人类在不同的条件下会经历不同的情感状态。外部刺激会影响一个人的心情或者情感。
3.许多人对各种音乐刺激都有特别敏锐的情感反应。音乐在人类文化中发挥着相当大的作用,这在很大程度上是因为它能有效地在听者中引发特定情感状态。个体听者通常基于维持或实现目标情感状态的愿望来选择要听的音乐,例如,充满活力的、放松的、忧郁的、怀旧的、快乐的或激进的。
4.音乐推荐系统尝试基于对听者可能偏好的推断向听者推荐音乐。这些推断通常基于从听者收集到的数据。可以通过在推荐时或在指示总体听者偏好的先前交互期间与听者的交互来收集数据。推荐系统可以向听者呈现一组主题,并基于听者选择的主题来推荐音乐。这些主题可以根据许多原则进行组织,包括流派(古典、乡村、说唱)、季节或背景(圣诞音乐、海滩音乐)或历史时期(20世纪60年代、20世纪80年代、当代)。一些主题可以围绕心情或其他情感状态信息来组织,诸如旨在引发或符合听者的情感状态(悲伤、快乐、放松、充满活力)的音乐。主题也可以围绕暗示针对特定情感状态的活动来组织(用于烹饪或冥想的平静音乐、用于锻炼的激进音乐、用于跳舞的欢快节奏音乐)。
5.一些音乐推荐系统还通过将听者与特定音乐作品相关联的数据来推断听者偏好。所述系统可以例如收集关于听者先前的音乐收听选择或听者先前购买的音乐记录的数据。这些选择或购买可以与其他可用的音乐作品相互参照,诸如通过识别具有与听者偏好的那些特性相似特性的作品。一些系统可以使用协作过滤来识别具有与听者相似的品味或相似的选择或购买历史的其他用户所偏好的作品。一些系统可以从听者收集与系统的推荐相关的反馈,并相应地更新他们的用户偏好模型和他们对其推断的信心。
6.包括情感相关主题的系统通常基于作品的总体特性来识别与给定主题匹配的音乐作品,所述特性并不特定于个体听者。音乐作品的情感相关特性通常相对于整个作品来识别。通常雇用在音乐分类方面训练有素的专家根据被称为音乐信息检索(mir)的过程来聆听和表征音乐作品。mir涉及提取和表示音乐的特征。用于表示mir特征的标准已经由声学/音乐研究与协调研究所(ircam)颁布,并且存在辅助mir的软件,诸如用于matlab的mirtoolbox软件包。一些现有的mir数据集合包括与特定音乐作品相关联的情感相关标记或特征,这是基于专业听者对整个作品的情感相关特征的评估。
7.音乐创作通常没有与音乐元素相关的人类情感的复杂形式模型的辅助。旨在在听者中实现特定情感状态改变的音乐通常由人类作曲家基于其所持有的主观标准来创作。
技术实现要素:
8.本公开描述了用于情感音乐推荐和创作的示例性设备、方法、系统和非暂时性介质。在一些实施方案中,识别听者的当前情感状态和目标情感状态,并且生成音频流(诸如音乐播放列表、声音设计或一首算法创作的音乐),目的是实现听者的情感状态从当前状态到目标状态的受控轨迹。音频流由使用来自听者和/或其他用户的数据训练的机器学习模型生成,所述数据指示特定音频片段或具有特定特征的音频片段在实现期望情感轨迹方面的有效性。在一些实施方案中,可以基于特定听者或听者群体如何对特定音乐元素做出情感反应的模型来创作歌曲,以实现特定目标情感状态或特定情感轨迹。
9.示例性实施方案涉及一种生成用于在听者中引发情感状态改变的音频流的方法。所述方法包括以下步骤:识别所述听者的当前情感状态;识别所述听者的目标情感状态;识别从所述当前情感状态到所述目标情感状态的情感轨迹;使用经训练的片段识别机器学习模型来识别第一音频片段,所述第一音频片段在作为听觉刺激呈现给所述听者时,可能在所述听者中引发对应于所述情感轨迹的至少初始部分的期望情感反应;至少部分地基于所述第一音频片段生成所述音频流;和向听者设备发送基于所述音频流的音频流数据。
10.第二实施方案涉及一种生成用于在听者中引发情感状态改变的音频流的系统。所述系统包括处理器系统、通信系统和存储器系统。所述存储器系统在其上存储有可执行的经训练的片段识别机器学习模型和可执行指令。所述可执行指令在由所述处理器系统执行时使得所述系统:基于由所述通信系统接收到的听者状态数据识别所述听者的当前情感状态;基于由所述通信系统接收到的目标情感状态数据识别所述听者的目标情感状态;识别从所述当前情感状态到所述目标情感状态的情感轨迹;执行所述经训练的片段识别机器学习模型以识别第一音频片段,所述第一音频片段在作为听觉刺激呈现给所述听者时,可能在所述听者中引发对应于所述听者中的所述情感轨迹的至少初始部分的期望情感反应;至少部分地基于所述第一音频片段生成所述音频流;并且使用所述通信系统向听者设备发送基于所述音频流的音频流数据。
11.根据可以与本文公开的其他实施方案组合的另一方面,在使用所述经训练的片段识别机器学习模型来识别所述第一音频片段之后,基于所述当前情感状态和所述第一音频片段的一组音频特征值,使用所述情感推断机器学习模型来推断新的推断情感状态。识别从所述新的推断情感状态数据到所述目标情感状态的经更新的情感轨迹。使用所述经训练的片段识别机器学习模型来识别后续音频片段,所述后续音频片段在作为听觉刺激呈现给所述听者时,可能在所述听者中引发对应于所述经更新的情感轨迹的至少初始部分的后续期望情感反应。至少部分地基于所述第一音频片段和所述后续音频片段生成所述音频流。
12.根据可以与本文公开的其他实施方案组合的另一方面,使用从所述情感推断过程接收到的奖励数据来训练所述经训练的片段识别机器学习模型,并且所述情感推断过程通过以下操作生成所述奖励数据:推断所述听者对所述音频流的一组音频特征值的推断的情感反应;和基于所述推断的情感反应与所述期望情感反应的比较来生成所述奖励数据。
13.根据可以与本文公开的其他实施方案组合的另一方面,所述情感推断过程包括经训练的情感推断机器学习模型,并且使用训练数据来训练所述经训练的情感推断机器学习模型,所述训练数据包括:对应于多个训练音频片段的训练音频特征数据;和与每个人类主体暴露于对应于所述多个训练音频片段的多个音频刺激中的每个音频刺激相关联地从一
个或多个人类主体收集的情感状态数据。
14.根据可以与本文公开的其他实施方案组合的另一方面,所述一个或多个人类主体包括所述听者。
15.根据可以与本文公开的其他实施方案组合的另一方面,所述经训练的片段识别机器学习模型包括强化学习模型。
16.根据可以与本文公开的其他实施方案组合的另一方面,所述经训练的片段识别机器学习模型包括深度学习神经网络。
17.根据可以与本文公开的其他实施方案组合的另一方面,所述音频流数据包括推荐所述音频流的推荐数据。
18.根据可以与本文公开的其他实施方案组合的另一方面,所述音频流数据包括所述音频流。
19.根据可以与本文公开的其他实施方案组合的另一方面,在向所述听者设备发送所述音频流数据之后,从所述听者接收经更新的当前情感状态数据。所述经训练的情感推断机器学习模型使用运行时训练数据,所述运行时训练数据包括:对应于以下各项中的每一者的音频特征数据:所述第一音频片段和所述多个后续音频片段;和所述经更新的当前情感状态数据。
20.根据可以与本文公开的其他实施方案组合的另一方面,识别所述听者的目标情感状态包括经由所述听者设备从所述听者接收目标情感状态数据,和基于所述目标情感状态数据识别所述听者的目标情感状态。
21.根据可以与本文公开的其他实施方案组合的另一方面,识别所述听者的当前情感状态包括经由所述听者设备从所述听者接收情感自我评估数据,和基于所述情感自我评估数据识别所述听者的当前情感状态。
22.根据可以与本文公开的其他实施方案组合的另一方面,识别所述听者的当前情感状态包括接收与所述听者的一个或多个生理状态相关的生理数据,和基于所述生理数据识别所述听者的当前情感状态。
23.另一实施方案涉及一种包括用于执行上述方法中的一种或多种方法的指令的非暂时性处理器可读介质。
24.另一实施方案涉及一种包括由上述方法中的一种或多种方法生成的音频流的非暂时性存储介质。
25.另一实施方案涉及一种用于训练机器学习模型预测人类对音乐特征的情感反应的方法,所述方法包括:向听者呈现具有一组音乐特征的音乐;从所述听者获得情感反应数据,所述情感反应数据指示所述听者对所述音乐的呈现的情感反应;用所述情感反应数据标记所述音乐的所述音乐特征,以生成经标记的音乐特征数据;和使用所述经标记的音乐特征数据作为训练数据来训练所述机器学习模型,以基于所述音乐特征数据来预测所述情感反应数据。
26.另一实施方案涉及一种用于预测人类对音乐的反应的系统,所述系统包括:处理器系统;和存储器系统,所述存储器系统在其上存储有:根据上述方法中的一种方法来训练的机器学习模型。
27.根据可以与本文公开的其他实施方案组合的另一方面,所述机器学习模型是用于
进行以下操作的生成模型:接收指示期望情感反应的期望情感反应数据;和生成具有由所述机器学习模型预测的音乐特征的音乐,以在听者中引发所述期望情感反应。
28.根据可以与本文公开的其他实施方案组合的另一方面,生成所述音乐包括:使用所述生成模型来处理所述期望情感反应数据,以生成指示所述音乐特征的音乐特征数据;和基于所述音乐特征数据生成所述音乐。
29.根据可以与本文公开的其他实施方案组合的另一方面,所述音乐特征数据是音乐信息检索(mir)数据。
30.根据可以与本文公开的其他实施方案组合的另一方面,所述mir数据是所述音乐的mir蓝图。
31.根据可以与本文公开的其他实施方案组合的另一方面,所述生成模型是生成对抗网络(gan)。
32.根据可以与本文公开的其他实施方案组合的另一方面,所述gan包括生成器网络、概率网络和控制网络。
33.根据可以与本文公开的其他实施方案组合的另一方面,所述gan包括条件gan。
34.根据可以与本文公开的其他实施方案组合的另一方面,所述生成器网络包括生成器神经网络。
35.根据可以与本文公开的其他实施方案组合的另一方面,所述概率网络包括鉴别器神经网络。
36.根据可以与本文公开的其他实施方案组合的另一方面,所述生成器神经网络和所述鉴别器神经网络各自包括具有长短期记忆(lstm)的递归神经网络(rnn)。
37.根据可以与本文公开的其他实施方案组合的另一方面,基于所述音乐特征数据生成所述音乐包括:基于所述音乐特征数据生成乐谱;和基于所述乐谱生成所述音乐。
38.根据可以与本文公开的其他实施方案组合的另一方面,所述乐谱是乐器数字接口(midi)乐谱。
39.根据可以与本文公开的其他实施方案组合的另一方面,生成所述乐谱包括:接收创作意图信息;和基于所述音乐特征数据和所述创作意图信息生成所述乐谱。
40.根据可以与本文公开的其他实施方案组合的另一方面,所述创作意图信息包括以下各项中的一者或多者:乐谱类型信息、乐器信息和乐谱长度信息。
41.根据可以与本文公开的其他实施方案组合的另一方面,所述创作意图信息由从用户接收到的创作意图用户输入来指示。
42.根据可以与本文公开的其他实施方案组合的另一方面,所述存储器进一步存储乐谱生成机器学习模型;并且生成所述乐谱包括使用所述乐谱生成机器学习模型来处理所述音乐特征数据以生成所述乐谱。
43.根据可以与本文公开的其他实施方案组合的另一方面,所述乐谱生成机器学习模型是乐谱生成对抗网络(gan)。
44.根据可以与本文公开的其他实施方案组合的另一方面,所述乐谱生成gan包括生成器网络、概率网络和控制网络。
45.根据可以与本文公开的其他实施方案组合的另一方面,所述乐谱生成gan包括条件gan。
46.根据可以与本文公开的其他实施方案组合的另一方面,所述生成器网络包括生成器神经网络。
47.根据可以与本文公开的其他实施方案组合的另一方面,所述概率网络包括鉴别器神经网络。
48.根据可以与本文公开的其他实施方案组合的另一方面,所述生成器神经网络和所述鉴别器神经网络各自包括具有长短期记忆(lstm)的递归神经网络(rnn)。
49.根据可以与本文公开的其他实施方案组合的另一方面,基于所述乐谱生成所述音乐包括:向用户呈现所述乐谱;从所述用户接收初步混音用户输入;基于所述初步混音用户输入生成初步混音;和基于所述初步混音生成所述音乐。
50.根据可以与本文公开的其他实施方案组合的另一方面,基于所述乐谱生成所述音乐还包括:基于所述音乐特征数据生成创作功能谱;和将所述创作功能谱呈现给所述用户。
51.根据可以与本文公开的其他实施方案组合的另一方面,基于所述初步混音生成所述音乐包括:基于所述音乐特征数据和所述初步混音生成制作功能谱;向所述用户呈现所述创作功能谱;从所述用户接收最终混音用户输入;基于所述最终混音用户输入生成最终混音;和基于所述最终混音生成所述音乐。
52.根据可以与本文公开的其他实施方案组合的另一方面,所述存储器进一步存储母带处理机器学习模型;并且生成所述最终混音包括使用所述母带处理机器学习模型来处理所述音乐特征数据和所述最终混音以生成所述音乐。
53.根据可以与本文公开的其他实施方案组合的另一方面,所述母带处理机器学习模型被进一步配置为:接收现有的一首音乐;并且处理所述音乐特征数据和所述现有的一首音乐以生成具有所述音乐特征的所述音乐。
54.根据可以与本文公开的其他实施方案组合的另一方面,所述母带处理机器学习模型被进一步配置为基于多个现有的音乐子总线生成具有所述音乐特征的所述音乐。
55.根据可以与本文公开的其他实施方案组合的另一方面,所述母带处理机器学习模型包括递归深度q网络(dqn)。
56.根据可以与本文公开的其他实施方案组合的另一方面,所述母带处理机器学习模型包括分支递归dqn。
57.根据可以与本文公开的其他实施方案组合的另一方面,所述母带处理机器学习模型包括长短期记忆(lstm)。
58.另一实施方案涉及一种包括由上述系统生成的音频流的非暂时性存储介质。
59.根据可以与本文公开的其他实施方案组合的另一方面,所述机器学习模型被进一步配置为:接收现有的多首音乐;接收所述期望情感反应数据;并且识别所述现有的多首音乐中可能在听者中引发所述期望情感反应的现有的一首音乐。
附图说明
60.现在将参考附图以示例的方式描述实施方案,在附图中,相同的附图标记可以用于指示相似的特征。
61.图1是根据本文描述的示例性实施方案的用于情感音乐推荐的示例性系统的框图。
62.图2a是根据本文描述的示例性实施方案的用于在流生成模式下操作的情感音乐推荐的示例性系统的系统图。
63.图2b是根据本文描述的示例性实施方案的用于在训练模式下操作的情感音乐推荐的示例性系统的系统图。
64.图3是根据本文描述的示例性实施方案的用于情感音乐推荐的示例性方法的流程图。
65.图4a是示出根据本文描述的示例性实施方案的用于情感状态推断的简化神经网络的示意图。
66.图4b是示出根据本文描述的示例性实施方案的用于情感状态推断的简化递归神经网络的示意图。
67.图5是示出根据本文描述的示例性实施方案的用于识别可能实现目标情感反应的音频片段的神经网络的示意图。
68.图6是示出根据本文描述的示例性实施方案的刺激前听者交互的听者设备的示例性用户界面屏幕的序列。
69.图7是示出根据本文描述的示例性实施方案的刺激后听者交互的听者设备的示例性用户界面屏幕的序列。
70.图8是示出根据本文描述的示例性实施方案的个性化听者交互的听者设备的示例性用户界面屏幕的序列。
71.图9是根据本文描述的示例性实施方案的作为简档创建过程的一部分呈现给用户的听者设备的示例性用户界面屏幕。
72.图10是示出根据本文描述的示例性实施方案的上下文信息收集交互的听者设备的示例性用户界面屏幕。
73.图11是根据本文描述的示例性实施方案的用于情感音乐推荐的示例性多模型系统的框图。
74.图12是根据本文描述的示例性实施方案的示例性音乐享受评级用户界面屏幕1202。
75.图13是根据本文描述的示例性实施方案的示例性mir特征预测系统。
76.图14是示出根据本文描述的示例性实施方案的用于为听者创建音乐模型数据库的示例性过程的步骤和部件的框图。
77.图15是示出由图14的个性化模型转移学习过程使用的个性化因素的示意图。
78.图16是根据本文描述的示例性实施方案的用于情感音乐创作的示例性系统的框图。
79.图17a是示出图16的示例性情感音乐创作系统的第一部分的过程之间的关系的框图。
80.图17b是示出图16的示例性情感音乐创作系统的第二部分的过程之间的关系的框图。
81.图17c是示出图16的示例性情感音乐创作系统的第三部分的过程之间的关系的框图。
82.图17d是示出图16的示例性情感音乐创作系统的第四部分的过程之间的关系的框
图。
83.图18是示出由图16的情感音乐创作系统使用的用于情感状态推断的简化递归神经网络的示意图。
84.图19是示出由图16的情感音乐创作系统使用的mir生成器过程的框图。
85.图20是示出由图16的情感音乐创作系统使用的乐谱生成器过程的框图。
86.图21a是示出由图16的情感音乐创作系统使用的母带处理代理的第一部分的框图。
87.图21b是示出由图16的情感音乐创作系统使用的母带处理代理的第二部分的框图。
88.图22a是示出由图16的情感音乐创作系统使用的自适应音乐代理的第一部分的框图。
89.图22b是示出由图16的情感音乐创作系统使用的自适应音乐代理的第二部分的框图。
90.图22c是示出由图16的情感音乐创作系统使用的自适应音乐代理的第三部分的框图。
91.图23是示出由图16的情感音乐创作系统使用的创作功能谱过程的框图。
92.图24a是由图23的创作功能谱过程生成的创作功能谱的示例性情感空间指示符。
93.图24b是由图23的创作功能谱过程生成的示例性创作功能谱。
94.图25是示出由图16的情感音乐创作系统使用的制作功能谱过程的框图。
95.图26是由图25的制作功能谱过程生成的示例性制作功能谱。
96.图27是使用本文描述的实施方案的示例性专辑再混音用例的框图。
97.图28是使用本文描述的实施方案的以健康播放列表为目标的示例性音乐再混音用例的框图。
98.图29是使用本文描述的实施方案来生成具有不同情感目标的多个专辑的示例性音乐集再混音用例的框图。
99.图30是使用本文描述的实施方案使用现有子总线库生成情感音乐的示例性音乐改编用例的框图。
具体实施方式
100.现在将关于用于情感音乐推荐和创作的方法、系统和非暂时性介质来描述示例性实施方案。首先将参考图1至图15描述音乐推荐系统;这些音乐推荐系统的部件将随后在参考图16至图30描述音乐创作系统时被提及。
101.所描述的音乐推荐系统和方法生成用于在听者中引发情感状态改变的音频流。一些实施方案利用两个单独的机器学习模型来生成可能在听者中引发期望情感反应的音频流,诸如音乐播放列表。一种机器学习模型是情感推断模型,所述情感推断模型估计对音频片段的一组音频特征值(诸如音乐片段的mir特征值)的情感反应。另一种机器学习系统是具有深度学习神经网络(也称为深度q网络(dqn))的强化学习模型,所述强化学习模型被训练为使用一组音频片段(诸如歌曲或从歌曲摘录的时期(epoch))并使用来自基于音频片段的音频特征值(例如mir特征值)的情感推断模型的反馈来估计对音频片段的情感反应。
102.现在将参考图1描述生成用于在听者中引发情感状态改变的音频流的情感音乐推荐系统100的第一示例性实施方案。
103.图1示出了情感音乐推荐系统100,所述情感音乐推荐系统包括用于执行计算机程序指令的处理器系统102、用于存储可执行指令和数据的存储器系统104,以及用于与其他设备或部件进行数据通信的通信系统106。
104.情感音乐推荐系统100可以在一个或多个计算机系统上实施。所述情感音乐推荐系统可以由单个计算机、多个计算机、虚拟机、分布式计算或云计算平台或者能够执行本文描述的方法步骤的任何其他平台来体现。在一些实施方案中,情感音乐推荐系统100可以包括由听者使用的一个或多个电子设备(听者设备190),而在其他实施方案中,情感音乐推荐系统100使用通信系统106直接或间接地(例如经由通信网络170)与此类设备通信。
105.处理器系统102可以体现为能够执行计算机程序指令的任何处理资源,诸如计算机或计算平台上的一个或多个处理器。存储器系统104可以被体现为任何数据存储资源,诸如一个或多个计算平台上的一个或多个磁盘驱动器、随机存取存储器或者易失性或非易失性存储器。通信系统106可以体现为一个或多个通信链路或接口,包括有线或无线通信接口,诸如以太网、wifi或蓝牙接口。在一些实施方案中,一个或多个听者设备190可以在与情感音乐推荐系统100相同的平台上实施;在此类实施方案中,通信系统106可以包括内部通信总线或其他平台内数据转移系统。
106.存储器系统104可以具有以可执行指令的形式存储在其上的几种类型的计算机程序。所述存储器系统上可以存储用于执行本文描述的方法步骤的一组可执行指令110。还可以存在用于识别旨在在听者中引发特定情感反应的音频片段的一个或多个机器学习模型,这里示出为多个深度q网络(也称为深度学习神经网络):第一深度q网络122、第二深度q网络124等,直到第n深度q网络126。存储器系统104还可以在其上存储用于推断由听者暴露于具有特定一组音频特征值的音频片段而引发的情感状态的情感推断机器学习模型,这里示出为情感推断神经网络140。这些机器学习模型可以在如下文进一步描述的那样被训练之后部署在情感音乐推荐系统100上。
107.存储器系统104可以在其上存储几种类型的数据180。数据180可以包括与情感推荐系统100的先前体验记录有关的数据(例如情感数据和片段选择)。数据180还可以包括音频库184,所述音频库包括多个音频片段186和对应于多个音频片段186中的每个音频片段的音频特征数据。音频片段186可以包括存储为单独音频剪辑的数字音频数据,或者所述音频片段可以是从存储在音频库184中的音频剪辑中提取的,诸如从可变持续时间的歌曲中提取的固定持续时间的时期。音频特征数据在这里示出为库mir数据182。它可以包括与每个音频片段186相关联的mir元数据,所述mir元数据用对应值指示音频片段186的mir特征。在一些实施方案中,音频特征数据还可以包括非mir数据或元数据。
108.听者设备190可以是由情感音乐推荐系统100的听者或终端用户操作的电子设备,诸如经由通信网络170与情感音乐推荐系统100通信的计算机或智能电话。情感音乐推荐系统100可以支持多种类型的听者设备190。一些听者设备190包括用户界面部件,诸如用于显示视觉数据和接收用户输入的触摸屏194,以及音频输出192,诸如扬声器和/或耳机的有线或无线接口。与情感音乐推荐系统100的通信由通信系统196实现,所述通信系统可以经由通信网络170进行通信。
109.图2a示出了情感音乐推荐系统100的功能系统图。情感音乐推荐系统100通过使用处理器系统102执行存储在存储器系统104中的可执行指令110来执行各种功能步骤。
110.情感音乐推荐系统100执行指令110以执行生成用于在听者中引发情感状态改变的音频流234的方法。为了执行所述方法步骤,情感音乐推荐系统100使用通过执行指令110、片段识别机器学习模型(例如深度q网络122、124到126)和情感推断机器学习模型(例如情感推断神经网络140)实施的多个功能块。情感音乐推荐系统100以两种不同的模式操作:音频流生成模式,其通常发生在用户会话期间;以及训练模式,其可以发生在用户会话之间。将首先参考图2a描述情感音乐推荐系统100在音频流生成模式下的操作,随后参考图2b描述训练模式。
111.经由通信系统106接收与听者相关的听者状态数据,并在当前状态识别过程202中使用所述听者状态数据来识别听者的当前情感状态212。在各种实施方案中,听者状态数据可以包括情感自我评估数据206、生理数据208和/或与识别听者的情感状态潜在相关的其他类型的数据。听者状态数据可以从一个或多个源接收,包括从听者设备190、从其他设备和/或从情感音乐推荐系统100内部的源接收。情感自我评估数据206可以由听者设备190生成,如下文进一步详细描述。生理数据208可从听者设备190或被配置为从听者收集生理传感器数据的另一设备接收,如下文进一步描述。用于确定听者的情感状态的其他听者状态数据可以包括显示听者面部表情或行为的相机数据、指示听者语调或语音内容的语音数据,或者可以用于帮助识别听者的情感状态的任何其他数据。
112.在情感计算领域,存在许多用于使用生理的、自我报告的和/或其他数据类型来识别人类情感状态以及用于在数据中表示情感状态的已知技术。用于表示情感状态的一种常见模型是二维情感模型,有时称为环状模型,其中给定的情感状态被表示为效价值(表示积极或消极情绪的程度)和唤醒或激活值(表示情绪警觉性或精力的程度)。在二维效价-激活情感模型中,例如,悲伤可以表示为负效价和低激活,愤怒可以表示为负效价和高激活,热情可以表示为正效价和高激活,并且放松可以表示为正效价和低激活。本文描述的示例通常指的是具有效价和激活值的二维情感模型。然而,一些实施方案可以使用其他情感模型,包括使用多于或少于两个维度来表征情感状态的模型,使用时变情感值来模拟情感状态的模型,以及使用离散情感状态列表而不使用数值的模型。
113.在一些实施方案中,当前状态识别过程202可以接收明确识别听者当前情感状态的听者状态数据。在其他实施方案中,当前状态识别过程202可以使用情感识别引擎,诸如被训练来识别特定听者或一般人类的情感状态的另一机器学习模型,以基于听者状态数据来识别听者的情感状态。从生理数据推断的额外生物标记物也可以用作当前状态识别过程的输入,甚至超出二维效价和激活值,诸如焦虑水平、专注水平、激动水平等。
114.一些实施方案可以在情感音乐推荐系统100的操作期间的特定时间接收听者状态数据,诸如在用户会话开始时和用户会话结束时。其他实施方案可以连续地或者在由用户输入的定时确定的时间接收听者状态数据。例如,一些实施方案可以接收生理数据208的恒定流,而其他实施方案可以在听者指定的时间接收用户发起的情感自我评估数据206。
115.目标状态识别过程204用于基于从诸如听者设备190的源接收到的目标情感状态数据210来识别听者的目标情感状态214。在一些实施方案中,目标情感状态数据210可以由预期应用的性质预先确定:例如,放松应用可以总是提供指示低激活、正价态的目标情感状
态数据210,而专注应用可以提供指示高激活、正到中性价态的目标情感状态数据210。其他实施方案可以基于在用户会话之前或期间从听者设备190接收到的听者偏好数据来识别听者的目标情感状态214。
116.在一些实施方案中,基于当前情感状态212和目标情感状态214,情感轨迹过程216识别从当前情感状态212到目标情感状态214的情感轨迹218。在采用二维情感模型的实施方案中,情感轨迹218可以被表示为二维曲线250。示例性曲线250被绘制在例如由水平维度中的效价(左=负,右=正)和垂直维度中的激活(主动=上,被动=下)定义的示例性情感空间中。听者的当前情感状态212被绘制为曲线250的起点252。目标情感状态214被绘制为曲线250的终点254。可以沿着曲线250绘制一个或多个中间路点,诸如第一路点256和第二路点258,从而指示情感轨迹218上的中间情感状态。曲线250的初始部分260由起点252和第一路点256定义。曲线250的第二后续部分262由第一路点256和第二路点258定义。曲线250的第三和最后的后续部分264由第二路点258和终点254定义。还可以实施机器学习技术以学习使用系统的个体的最佳轨迹,从而基于先前在实现用户的目标情感状态方面的成功来使这些轨迹动态化。在其他实施方案中,此轨迹可以被完全省略,并且用户的当前情感状态和目标情感状态可以是会话的唯一驱动因素。在使用情感轨迹过程的实施方案中,目的是通过dqn的移动目标随时间强制受控的情感状态改变。
117.音频片段识别过程222用于选择或识别音频片段,所述音频片段在作为听觉刺激呈现给听者时,可能在听者的情感状态中至少引发情感轨迹218的初始部分260。使用示出为dqn 120的经训练的片段识别机器学习模型来识别音频片段230,所述模型从存储在音频库184中的音频片段220的子集中选择音频片段230。基于由dqn 120进行的评估来选择音频片段230,所述评估认为音频片段230比音频片段220的子集中的其他音频片段更有可能在听者中引发情感轨迹218的至少初始部分260,即,音频片段230在作为听觉刺激播放给听者时,可能在听者中引发接近由情感轨迹218上的第一路点256或后续点258、254中的一者所表示的状态的情感状态。
118.音频片段识别过程222还可以使用从听者设备190接收到的上下文提示191作为输入,诸如一天中的时间、听者是否在私人环境中、听者是否在嘈杂环境中等等。
119.在不同的情况下,情感音乐推荐系统100使用的dqn 120可以是来自图1的各种dqn中的任何一种dqn(第一dqn 122到第n dqn 126)。在一些实施方案中,多个dqn 122、124到126中的每一者用于从来自音频库184的音频片段220的不同子集中进行选择。音频片段的这些子集可以基于各种标准生成:音频片段的示例性子集可以包括基于由听者指示的偏好数据、基于音乐流派或基于其他分组标准而选择的歌曲。使用子集而不是整个音频库184的一个目的可以是通过将包括在音频片段220的子集中的音频片段的数目限制为最大集合大小,诸如100或120个音频片段,来简化由dqn 120执行的计算。多个dqn(例如,dqn 122、124到126)可以在不同的用户会话中用作彼此的替代物,以根据上下文从不同的音频片段子集220中选择音频片段。
120.在一些实施方案中,dqn 120然后可以识别一个或多个后续音频片段230,所述音频片段在作为听觉刺激呈现给听者时,可能在听者中引发对应于情感轨迹218的后续部分(例如部分262和/或264)的一个或多个后续期望情感反应。
121.识别音频片段230的过程的一次迭代可以被称为一个―步骤”。在每个步骤之后
(即,在识别第一音频片段之后,以及在识别多个后续音频片段中的每个后续音频片段之后),可以使用经训练的情感推断机器学习模型(这里示出为情感推断神经网络140)来生成新的推断情感状态数据226,并将新的推断情感状态数据226反馈给dqn 120,以便通知由dqn 120做出的决定。这作为情感推断过程224的一部分来执行,所述情感推断过程接收目标情感数据214和由音频片段识别过程222识别出的音频片段230,使用情感推断神经网络140来推断听者的新的推断情感状态226,所述新情感状态可能是由于听者暴露于具有与音频片段230的音频特征(例如片段mir数据183)匹配的音频特征的音频刺激而产生的。
122.在一些实施方案中,情感推断过程224可以使用不同的技术来生成新的推断情感状态226,诸如不同的机器学习或人工智能模型,或者一组预定的相关性或规则。
123.因此,情感推断神经网络140模拟由dqn 120操作的环境,并向所述dqn提供反馈和强化:即,情感推断神经网络140通过使用音频特征数据(例如,分段mir数据183)和听者的一个或多个当前情感状态212来推断由情感推断神经网络140的先前训练所确定的用户的可能情感反应,来模拟听者的情感反应。下面详细描述示例性情感推断神经网络140的训练。
124.在一些实施方案中,情感推断过程224也可以完全或部分地被来自实际用户的实时情感数据测量流所替代。在这些实施方案中,数据流足够可靠以提供必要的情感状态数据来通知dqn 120做出的决策过程的下一个―步骤”。
125.流生成过程240基于由音频片段识别过程222识别出的一个或多个音频片段230生成音频流234。在一些实施方案中,音频流可以是音乐播放列表,其可以被表示为一系列标识符和/或对应于一个或多个音频片段230的其他元数据。流生成过程240还生成音频流数据236,用于通过通信系统106传输到听者设备190。在一些实施方案中,音频流数据可以包括对应于包括在音频流234中的一个或多个音频片段230的元数据。此元数据可被发送到听者设备,以允许听者查阅所提议的播放列表,并经由触摸屏194提供输入来播放或更改所述播放列表。在一些实施方案中,音频流数据可以包括对应于一个或多个音频片段230的音频片段数据。听者设备可以被配置为经由音频输出192将此音频数据作为听觉刺激呈现给听者。情感音乐推荐系统100与听者设备190之间的通信(包括在不同时间和不同条件下传输不同种类的音频流数据236)在各种实施方案中可以包括用户与在线音乐推荐、管理或播放列表服务之间的典型交互。
126.由轨迹识别过程216识别出的情感轨迹218的曲线250在不同的实施方案和/或不同的环境中可以具有不同的特性。一些实施方案还可以包括过程,诸如另一机器学习模型,用于基于随时间收集的情感反馈数据将曲线250成形为用户相关或用户无关的形状。曲线250可以是从第一状态到第二状态的简单线性轨迹(即,二维的直线斜坡),或者它可以根据从科学文献或情感数据分析中提取的原理或模式而弯曲。在不使用使用数值的情感模型的实施方案中,情感轨迹218可以不在情感空间中绘制,而是可以通过一个或多个中间情感状态来进行,所述中间情感状态被识别为从当前状态转变到目标状态所必需的中间情感状态。
127.本文描述的实施方案被配置为在引发最终目标情感状态214之前,沿着情感轨迹218引发一个或多个中间情感状态(例如,路点256、258)。这种使用音乐刺激来改变情感状态的方法遵循用于心情管理的音乐疗法中使用的iso原则,所述原则指出音乐最初应该与
听者的当前心情相匹配,然后随着时间的推移逐渐向期望目标心情迁移。然而,一些实施方案可以采用不同的方法来引发情感反应,诸如尝试使用单个音频片段来引发情感状态改变的实施方案,或者使用非线性情感轨迹曲线250的实施方案。
128.上面的描述提供了由情感音乐推荐系统100在音频流生成模式下使用的各种功能块和数据的操作的概述。在训练模式下,图2a中所示的各种功能块和数据可以用于不同的目的,并且可以由额外功能块和数据来补充,如下面参考图2b所描述的。
129.图2b示出了在训练模式下操作的图2a的情感音乐推荐系统100。例如,在训练模式下,推断的训练过程228将新的推断情感状态226与目标情感状态214进行比较,并基于此比较生成奖励数据273。在一些实施方案中,如果新的推断情感状态226与目标情感状态214相似,则奖励数据273向dqn 120提供正奖励,但是如果新的推断情感状态226不同于目标情感状态214,则所述奖励数据向所述dqn提供负奖励。
130.在一些实施方案中,推断训练过程228可以使用奖励函数272来生成奖励数据273。奖励函数272可以在多个会话的过程中变化。在直接训练过程270中,奖励功能272在会话结束时(或者在用户结束收听音频流234之后)从听者设备190接收情感自我评估数据206和/或生理数据208,从而指示听者的最终情感状态。奖励函数272基于在会话结束时听者的当前情感状态212(即听者在收听音频片段230后的最终情感状态)与目标情感状态214之间的比较来生成奖励数据273,在整个会话期间奖励(即正奖励)或惩罚(即负奖励)dqn 120的决策。
131.在一些实施方案中,最终情感状态数据包括在整个会话期间从听者收集的所有情感状态数据,以及在会话结束时或之后从听者收集的当前情感状态数据212。奖励数据273用于重新训练dqn 120,以在未来的会话中做出更好的决策,从而有效地个性化模型。在其他实施方案中,可以设置中间情感状态目标和长期情感状态目标,以便奖励在各个步骤采取的行动,以及奖励完整的序列。一些实施方案还可以使用从听者设备190收集的额外反馈数据(未示出)。一些实施方案还可以通过负面地奖励重复选择来阻止对同一音频片段230的重复选择,或者如果用户在收听音频流234时―跳过”特定音频片段,则可以负面地奖励对所述特定音频片段的选择。
132.在一些实施方案中,与在整个会话中播放的音频片段的片段mir数据183相关的最终情感状态数据(即,在会话结束时收集的当前情感状态数据212)也可以用于重新训练情感推断神经网络140,以在未来的会话中做出更好的预测。
133.在一些实施方案中,情感轨迹218的形状可以通过使用轨迹成形机器学习模型来适应特定用户以实施情感轨迹过程216。最终情感状态数据(即,在会话结束时收集的当前情感状态数据212)和轨迹奖励函数262可以被轨迹成形反馈过程260使用,以基于来自先前会话的成功结果来成形情感轨迹218。在实施轨迹成形机器学习模型以优化特定用户的最佳情感轨迹的实施方案中,最终情感状态数据和额外奖励数据263用于训练和优化模型,以基于用户个性化轨迹。
134.在一些实施方案中,可以完全跳过情感轨迹218,并且奖励函数272可以通过简单地将用户的最终情感状态与目标情感状态214进行比较来生成奖励数据273,并且相应地奖励由dqn 120预测的完整序列。
135.在一些实施方案中,dqn 120可以用任何机器学习算法代替,所述机器学习算法通
过在与用户的体验期间(在运行时)在真实世界中的试错并且通过模拟环境(运行时之外)进行学习。这可以通过任何基于模型或无模型的强化学习算法来实现。在一些实施方案中,本文描述的dqn 120的功能的所有实例可以用不同的无模型或基于模型的强化学习代理来代替,包括但不限于诸如mbac(基于模型的参与者评价者)、具有优势的a3c(具有优势的无模型的参与者评价者)、q学习、深度q学习和tdm(时间差异模型)的方法。
136.图3示出了生成用于在听者中引发情感状态改变的音频流的示例性方法300的流程图。在步骤302,识别听者的当前情感状态212,如上所述。在步骤304,识别听者的目标情感状态214,如上所述。在步骤306,识别情感轨迹218,如上所述。在步骤308,使用经训练的片段识别机器学习模型(例如,dqn 120)来识别第一音频片段(例如,音频片段230),所述第一音频片段在作为听觉刺激呈现给听者时,可能在听者中引发对应于情感轨迹218的至少初始部分(例如,初始部分256)的期望情感反应,如上所述。
137.在步骤310,情感推断过程224使用经训练的情感推断机器学习模型140来预测由深度学习神经网络120在步骤308选择的音频片段将如何影响用户。在步骤310,此新的推断情感状态数据226由情感推断机器学习模型140生成,并在步骤312作为状态数据输入发送到dqn 120。
138.在步骤316,情感音乐推荐系统100可以确定方法300是否已经到达多个此类步骤中的最终音频片段识别步骤,或者是否还有一个或多个后续音频片段要被识别并添加到音频流234。在一些实施方案中,音频流可以具有固定长度和/或需要固定数目的音频片段识别步骤:音频流234可以总是第一固定持续时间(例如,240秒的持续时间),并且每个音频片段可以是第二固定持续时间(例如,从歌曲中摘录的80秒时期),从而需要三个音频片段识别步骤来生成音频流234。如果方法300在步骤316确定还没有到达最终步骤,则可能引发情感轨迹的后续部分的后续音频片段被识别,如上面参考图2a所描述。方法返回到步骤308,以识别后续音频片段,并返回到步骤316,直到最后的步骤已经完成。深度神经网络然后在步骤308使用在步骤310从情感推断模型140推断的情感状态数据226作为用于下一个音频片段预测的―当前”情感状态212。
139.一旦最终步骤完成,就在步骤318生成音频流234,如上所述。在步骤320,生成音频流数据236并将其发送给听者设备190,如上所述。这就完成了生成音频流并将其发送给听者以作为听觉刺激进行潜在呈现的过程。
140.在一些实施方案中,可以向听者提示或呈现在收听音频流234的全部或部分之后提供经更新的当前情感状态数据的选项。此经更新的当前情感状态数据可用于训练情感推断机器学习模型,并改进其关于听者对组成音频流234的音频片段的音频特征的可能情感反应的推断。此数据还可以用于使用奖励函数272生成奖励数据273,以加强dqn 120在图3中概述的方法的步骤308中做出的选择。
141.在步骤322,例如经由通信系统106从听者设备190接收经更新的当前情感状态数据。在步骤324,使用经更新的当前情感状态数据来训练情感推断机器学习模型(例如情感推断神经网络140),如下面详细描述。此步骤通常会结束用户会话。
142.在本文描述的实施方案中,还使用推断训练过程224和/或直接训练过程270中的一者或两者来训练片段识别机器学习模型(例如,dqn 120)。此训练可以在用户会话结束时或者在听者不使用系统100的空闲时间期间进行。在步骤326,使用推断训练过程228来重新
训练片段识别机器学习模型(例如,dqn 120)。奖励数据273由奖励函数272基于新的推断情感状态226和目标情感状态214生成。此训练步骤可以重复dqn 120的初始训练,如下面进一步详细描述。此训练可以异步和/或离线进行。
143.在步骤328,使用直接训练过程270来重新训练片段识别机器学习模型(例如,dqn 120)。奖励数据273由奖励函数272使用在会话结束时通过听者设备190从听者接收到的经更新的当前情感状态数据212来生成。此训练也可以异步和/或离线进行。
144.在一些实施方案中,有可能在步骤308之后立即执行步骤318和320,从而在308做出第一预测之后生成音频流。在这些实施方案中,从用户接收可靠的当前情感状态数据212的连续流,从而避免了对推断的情感状态数据226的需要。在这些实施方案中,步骤318发生在步骤308之后,接着是步骤320和步骤322,通过直接用户反馈获取新的情感状态数据226返回到步骤308。此过程可以重复多次,直到完成期望长度的音频体验。在这些实施方案中,仅使用直接用户反馈来完成dqn 120的训练过程,从而无需步骤310、312、324和326。
145.现在分别参考图4a至图4b和图5更详细地描述情感推断机器学习模型和片段识别机器学习模型的示例性实施方式,包括用于训练每个模型的过程。
146.图4a示出了作为情感推断神经网络140的情感推断机器学习模型的示例性实施方案的示意图。情感推断神经网络140至少包括神经元408的输入层402、一个或多个中间层404和输出层406。输入层402接收数据输入值(这里显示为
第1
mir特征值412到第m mir特征值414以及一个或多个非mir数据值416),并使用已知技术转换这些输入,以向第一中间层404中的神经元提供输出410。每个中间层404的神经元408对从前一层接收到的每个输出410进行加权,并变换加权后的输出值,以产生下一层的另一组输出410。输出层406的神经元408类似地对它们接收到的输出410进行加权,并变换加权后的输出以生成输出值(这里示出为效价420和激活422)。通过在训练期间调整施加到每个神经元408的输入的权重,情感推断神经网络140可以被训练来推断听者对一组音频特征(诸如mir特征值412到414)的可能的情感反应(这里定义为推断的效价值420和激活值422)。额外非mir或非音频特征值也可以用于训练和运行情感推断神经网络140:例如,一些实施方案可以使用诸如一天中的时间或听者环境的变量来帮助情感推断神经网络140做出关于用户的可能的情感反应的推断。
147.在其他实施方案中,可以使用不同的机器学习模型来代替图4a至图4b和图5中所示的神经网络。情感推断神经网络140可以由各种形式的受监督和不受监督机器学习系统代替,同时保持基于音乐和/或音频的选择来推断用户的情感状态所需的相同核心输入和输出。类似地,dqn 120可以由各种形式的受监督和不受监督机器学习系统代替,同时保持基于在听众中引发期望情感轨迹的推断有效性来选择音频片段所需的相同核心输入和输出。
148.在一些实施方案中,递归神经网络可以用于情感推断神经网络140,从而允许将时间序列上的mir特征用作一系列输入,并且产生基于音乐特征序列而不是整个音乐片段的基于时间的mir特征的平均表示的推断的状态的输出。这可以允许情感推断神经网络140的预测更细粒度并且在时间序列上,从而提供音乐体验的更逼真的表示(因为人类认知随着时间的推移而不是随着作为统一整体的曲目而感知音乐)。
149.图4b示出了示例性递归情感推断神经网络(ainn)430。mir提取过程225用于从由
音频片段识别过程222选择的音频片段230中提取片段mir特征183,这里称为音频片段230的全局mir特征的n长度阵列433,并示出为
第1
全局mir特征435到第n全局mir特征436。全局mir特征可以表示整个音频片段230的音乐特征,例如速度。还通过mir提取过程225分析音频片段230的一系列短子片段(也称为时期)(例如,30秒子片段)中的每个短子片段的mir特征以生成多个时间序列mir特征阵列,每个时间序列mir特征阵列434对应于子片段,并且包括当前子片段的
第1
时间序列mir特征438到第n时间序列mir特征440。时间序列mir特征阵列434的时间序列mir特征438
…
440各自表示音频片段230的当前时期的特征,例如音频片段230的特定时期的梅尔频率倒谱(mfc)频谱图值。
150.在每个时间步,全局mir特征阵列433的每个全局mir特征和当前时期(例如,以第一30秒子片段开始)的时间序列mir特征阵列434的每个mir特征被提供作为循环情感推断神经网络430的输入,以及诸如当前情感状态212的其他输入数据和诸如上下文信息432的其他数据。上下文信息432可以包括例如被存储来表示用户简档(例如,个性、年龄、性别等)、品味简档(例如,音乐偏好)、一天中的时间、天气等的值。在每个后续时间步,后续时期(例如,第二30秒子片段)的时间序列mir特征阵列434与其他输入212、432、435
…
436一起被提供作为输入438
…
440,并且时间序列神经元的输出被提供作为另一组反馈输入,从而提供基于时间的递归。基于这些输入,递归情感推断神经网络430预测将通过收听音频片段230而在听者中引发的推断的情感状态450(例如,效价和激活值)。
151.在作为情感音乐推荐系统100的一部分部署之前,情感推断神经网络140可以首先经历初始训练过程。一些实施方案可以使用类似于在以下出版物中描述的技术和/或数据集来执行初始训练:vempala,naresh&russo,frank.(2012).predicting emotion from music audio features using neural networks.第九届计算机音乐建模与检索(cmmr)国际研讨会(以下称为vempala)的论文集,其全部内容通过引用结合于此。vempala描述了使用音乐集的mir特征的选定子集来训练神经网络以预测收听音乐的人类主体的情感反应。具体来说,vempala使用与动态、节奏、音色、音高和音调有关的13个低级和中级mir特征:rms、低能量、事件密度、速度、脉冲清晰度、零交叉、质心、扩展、滚降、亮度、不规则性、不和谐性和模式。音乐的这些mir特征被用作前馈神经网络的输入,所述前馈神经网络产生效价和唤醒(即激活)输出值。听完音乐后,从主体那里收集自我报告的情感效价和唤醒信息。然后使用反向传播来训练神经网络,使用损失函数将预测的效价/唤醒输出与用户自我报告数据进行比较。
152.示例性实施方案可以使用与vempala中使用的13个特征不同的一组音频特征来执行情感推断神经网络140的初始训练。
153.vempala在从0到1的尺度上对感兴趣的各种mir特征值进行归一化。类似地,示例性实施方案可以对情感推断神经网络140使用的mir数据和/或其他音频数据或非音频数据进行归一化。
154.一旦初始训练已经完成,情感推断神经网络140可以被认为在预测对音频特征的独立于听者的情感反应方面是有效的。然而,为了训练情感推断神经网络140预测特定听者的情感反应,可以使用来自所述听者的情感反馈来训练所述情感推断神经网络。部署的情感推断神经网络140也可以使用更多的音频特征和非音频特征作为输入,以便识别不太普遍的因素对听者的情感反应的影响。通过将在步骤310做出的情感推断与在步骤322从听者
接收到的经更新的当前情感状态数据进行比较,情感推断神经网络140可以使用反向传播或其他训练技术来更新其神经元408使用的权重,以改进其对听者对音频特征值集合的情感反应的建模。
155.一些实施方案可以提供推断训练过程,允许听者通过收听音频片段并在之前和之后提供情感状态数据来按需训练他或她的个性化情感推断神经网络140。此数据可以用来训练情感推断神经网络140,如上所述。
156.在使用中或训练期间,情感推断神经网络140有时会遇到异常值:在听者中引起情感反应的音频刺激与情感推断神经网络140的预测非常不同。为了避免过度拟合,来自这些异常刺激的反馈数据可以与用于训练的反馈数据分开。这种分开的数据可以被单独的分析过程用来提取特定于听者的数据,所述数据可以帮助识别听者对刺激的特殊反应中的模式。例如,由于听者环境中与音频片段无关的其他事件,听者可能在收听音频片段时具有极端的情感反应,或者听者可能对与所述歌曲的音频特征无关的特定歌曲具有情绪关联。这些非音频特征相关的关联可以不用于训练情感推断神经网络140,而是例如可以用于识别可以潜在地用作情感推断神经网络140的输入的非音频数据,以帮助未来预测的准确性。
157.图5示出了作为深度学习神经网络或深度q网络(dqn)120的音频片段识别机器学习模型的示例性实施方案的示意图。dqn 120至少包括神经元508的输入层502、一个或多个中间层504和输出层506。如同在图4a的情感推断神经网络140中一样,输入层502接收数据输入值,并使用已知技术转换这些输入,以向第一中间层504中的神经元提供输出510。每个中间层504的神经元508对从前一层接收到的每个输出510进行加权,并变换加权的输出值,以产生下一层的另一组输出510。输出层506的神经元508类似地对其接收到的输出510进行加权,并变换加权后的输出以生成输出值。
158.dqn 120实际上与标准深度学习神经网络相同,关键区别在于,当所述dqn在强化学习(rl)环境531中导航时,它被用作强化学习(rl)代理530的核心预测部件。此类型的深度学习神经网络也使用如反向传播的训练技术,但是在dqn模型中,使用奖励数据273而不是如在情感推断神经网络140中使用的标准深度学习神经网络的训练过程中看到的相关数据集来驱动训练过程。仿照q学习系统,此系统用深度q网络代替标准q表,从而允许rl代理530以指数方式更快地被训练。在标准q表中,基于环境的当前状态的所有可能动作的q值基于训练期间的先前会话以表格形式示出。这需要在rl代理530能够优化其性能之前对每个状态-动作关系进行多次迭代。当存在大量的状态和动作时,此训练变得昂贵且低效。通过用深度学习神经网络或dqn 120代替q表,网络的输入代表所有可能的状态关系,输出代表所有可能动作的q值。这些网络允许近似每次迭代的所有动作的值的关系训练,从而大大减少了优化rl代理的性能所花费的时间例如,参见lecun,yann&bengio,y.&hinton,geoffrey.(2015).deep learning.nature.521.436-44.10.1038/nature14539,以及mnih等人,2013,playing atari with deep reinforcement learning,nature.518.529-533.10.1038/nature14536,其全部内容各自通过引用结合于此。
159.如图5所示,q值520
…
522被馈送到强化学习代理530,所述强化学习代理通过选择音频片段530并将音频片段530馈送到两个替代环境中的一个环境来采取动作532:实际环境,即用户的实际情感状态,或者模拟环境,即情感推断过程224。在前一种情况下,流生成过程240生成音频流并将其发送给听者设备190,然后在听者已经暴露于音频流之后,听者
设备190提供经更新的当前情感状态数据212。在后一种情况下,音频片段234被馈送给情感推断过程224,所述情感推断过程生成新的推断情感状态226。
160.图5所示的输入(第一dqn输入512、目标状态值514和当前状态值516)是示例性实施方案中使用的输入的部分和简化列表。在一些实施方案中,dqn输入(诸如第一dqn输入512)可以包括上文参考图2a至图2b描述的上下文线索191。示例性实施方案可以在运行时使用以下输入列表:模式(指示目标情感状态,例如―平静”、―专注”或―充满活力”)、步骤计数(指示要按顺序包括在音频流234中的音频片段230的总数)、当前步骤(指示音频片段230的序列中的哪一个音频片段当前正被识别)、初始状态效价(在会话开始时识别出的听者的当前情感状态212的效价值)、初始状态激活(在会话开始时识别出的听者的当前情感状态212的激活值)、经更新的状态效价(在当前步骤之前新的推断情感状态226或经更新的当前情感状态212的效价),以及经更新的状态激活(在当前步骤之前新的推断情感状态226或经更新的当前情感状态212的激活值)。
161.根据用户的感受和他们当前的音乐品味偏好,用户对音乐的反应可能在任何给定的一天都有很大的不同。因此,在一些实施方案中,系统100可以通过向深度q网络120和情感推断神经网络140提供额外的输入来实施额外的个性化方法,从而允许其他因素影响预测过程。在一些实施方案中,用户在那个时刻正在寻求的期望的音乐美感可以被识别并作为另一输入被提供。例如,如果用户悲伤并且他们感觉想听大声且叛逆的音乐(例如,摇滚音乐),则他们可能对mir特征、曲目库或音频片段的选择的组合具有与他们悲伤并且感觉想听反思且复杂的音乐(例如,古典音乐)不同的反应。当前情感状态(例如,悲伤)与音乐的当前期望情绪内容(例如,大声且叛逆与反思且复杂)之间的此区别可以使用数据值来表示,并且作为另外的输入提供给图4a至图4b和/或图5中的神经网络120和140(例如,输入到输入层402或502的―当前音乐品味偏好”)。
162.用户简档数据也可以被用作对图4a至图4b和图5中表示的神经网络120和140的潜在输入(例如,对输入层402或502的一个或多个―用户简档数据”输入)。用户简档数据可以包括数据字段,诸如用户人口统计、基线音乐品味简档、基线心情简档和个性简档。这些和其他用户简档数据在预测用户将如何对音乐曲目或mir特征做出反应时可能全部具有价值。此数据中的一些数据可以使用下面参考图8和图9描述的用户界面屏幕从用户处收集。一些此类数据也可以由系统100基于用户经由图6至图7的用户界面屏幕提供的用户输入来推断;例如,用户的音乐流派偏好可以从他们在多个会话期间在图6中的ui屏幕608中的流派选择中推断出来。
163.上下文信息,诸如一天中的时间和用户的环境(例如,他们是在嘈杂的地方还是安静的地方),也可以被系统100用作相关数据的源,并且可以作为一个或多个额外数据输入被提供给图4a至图4b和/或图5的神经网络的输入层402和/或502。用户的当前环境和上下文可能对用户如何认知地接收音乐有很大影响,并且可以向系统100提供有价值的输入数据。系统100可以收集上下文数据,例如,通过图6的屏幕604和610以及图10的屏幕1002中所示的用户交互。
164.用户的当前状态值516也可以作为输入提供给图4a的输入神经元402。通过使用用户的当前状态值516来通知对情感推断神经网络140的预测,系统100可以在预测他们的情感结果将被给予暴露于mir特征的组合时考虑用户的当前情感状态。例如,一段音乐可以唤
起两种截然不同的情绪,这取决于用户开始时的情绪状态。
165.在推断训练模式期间,输入层神经元502将接收来自情感推断神经网络140的输出数据,以便为dqn 120设置初始权重。随机生成目标状态值514以及所有其他可变参数(例如,步骤数),然后rl代理530使用输出的音频片段q值520到522来选择音频片段230。此音频片段230被mir提取过程225转换成片段mir数据183,并且有效地充当rl环境531的情感推断神经网络140基于rl代理530采取的动作来预测下一个情感状态会是什么。然后,此新状态(即新的推断情感状态226)被用作预测序列的下一步骤的当前状态值516,并且此循环继续,直到所有步骤都完成。这个完整的序列经过数千次迭代,每次都会随机生成新目标和新的步骤数。在初始训练期间,此过程通常通过200000-500000次迭代来完成,以便完全优化dqn 120。
166.在一些实施方案中,mir提取过程225实时地从音频片段230中提取片段mir特征183,或者参考先前提取的特征的表格。可以使用已知的技术来执行从音频片段中提取mir特征。
167.通过在训练期间调整应用于每个神经元508的输入的权重,dqn 120可以被训练来选择或识别相对于其他音频片段候选具有最佳q值520
…
522的音频片段230,指示在一系列步骤上或者如果利用情感轨迹218,以每步骤的敏锐方式引发目标情感状态的可能性很高。训练可以以两种模式进行:初始训练,以及在空闲时间进行重新训练或更新。
168.在部署每个dqn 120之前,执行dqn 120的初始训练。情感音乐推荐系统100的每个用户具有与其个人账户相关联的多个dqn(例如dqn122、124到126),以及个人情感推断神经网络140。情感推断神经网络140被训练来模拟用户(听者)对音频特征和其他非音频变量的不同组合的情感反应,如上所述。情感推断神经网络140然后用于对每个dqn 120操作的环境进行建模,即它代表用户的实际情感反应。情感推断神经网络140提供所有新的推断情感状态226数据,所述数据充当用于训练dqn120的当前状态数据516。在初始训练中,奖励函数272也被馈送来自情感推断神经网络140的新的推断情感状态226数据,避免了用户提供最终情感状态数据(即在会话结束时提供的当前情感状态数据212)的需要。在初始训练中,每个dqn 120都经历包括不同输入变量组合的训练方案。训练方案可以随机生成,例如,通过为每个输入变量生成随机值,并且针对预定数目的强化迭代,迭代不同随机输入集合。在其他实施方案中,训练方案可以包括不同输入值的系统调查,例如覆盖整个情感空间,初始和目标情感状态输入的效价和激活值在每次强化迭代后都改变预定的量。在一些实施方案中,在训练期间使用的对dqn 120的输入不同于如上所述在运行时期间使用的输入:例如,dqn 120可以简单地单独评估每个音频片段选择步骤的准确性,而不是跟踪步骤数和朝向最终目标情感状态214的进展。
169.在一些实施方案中,在空闲时间期间dqn 120的重新训练或更新也可以使用新更新的情感推断神经网络140来完成。如上所述,在用户会话之后,使用来自听者的实际更新的当前情感状态反馈来更新情感推断神经网络140。一旦情感推断神经网络140被更新,每个dqn 120就可以在用户不参与系统时使用系统空闲时间来使用经更新的情感推断神经网络140重新训练它自己。初始训练方案被再次应用于每个dqn 120,以使用经更新的情感推断神经网络140作为其环境模拟来重新训练它。
170.在使用不同的强化学习方法代替dqn 120的实施方案中,图5中所示的dqn 120可
能是不同的强化学习算法表示,并且作为输入512
…
514
…
516提供给输入层神经元502的所有数据(诸如步骤计数值或目标状态值)可以被视为表示所选强化学习算法所使用的环境状态的输入数据的向量。此输入向量仍将被视为实现代替dqn 120的算法的推断行为的数据。在一些实施方案中,dqn 120和强化学习代理230的功能可以由将使用输入向量512
…
514
…
516来预测代理的动作532的单个模型或算法来执行,从而产生如上所述的音频片段230。代替dqn 120和/或rl代理230的算法可以是不同的dqn、简单的q表、参与者/评价者模型,或基于模型的rl算法内的环境模型/规划者实施方式。不同的方法可能提供各种优点和缺点,但是它们理论上都可以提供可比较的结果。
171.使用生理数据208来确定用户的当前情感状态212可以采用情感计算领域中已知的传感器和技术,诸如可穿戴传感器、相机和/或其他传感器。皮肤电反应(gsr)、脑电图(eeg)信号、呼吸模式、心率、瞳孔扩张、皮下血流、肌肉张力和其他生物标记物可以与人类的各种情感现象相关。这些生物标记物可以使用生物传感器来检测,诸如gsr传感器、呼吸传感器、心电图或脑电图电极、使用可见和/或不可见光谱的主动或被动视觉传感器、眼睛跟踪系统和肌电图电极。一个或多个这样的传感器可以与系统100结合使用来收集生理数据208,所述生理数据可以由情感音乐推荐系统100或系统100外部的过程来处理,以识别听者的情感状态。在一些情况下,生理数据208由听者设备190收集和/或处理。收集和/或处理生理数据208可以使用诸如在以下中描述的技术来执行:shu l,xie j,yang m等人a review of emotion recognition using physiological signals.sensors(basel).2018;18(7):2074.2018年6月28日出版。数字对象唯一标识符:10.3390/s18072074,其全部内容通过引用结合于此。在其他实施方案中,当其他生物标记物与来自使用此系统的期望结果相关联时,除了情感状态数据之外,此类生理数据也可以用作单独的输入。例如,在期望结果包括目标情感状态以及目标生理结果(即心率降低10%)的实施方案中,生理数据也可以用作表示用户当前状态516和目标状态514的元素。
172.从听者收集的其他数据也可以用来推断情感状态。相机数据可用于分析与情感状态或情感反应相关的面部表情或其他行为模式。语音记录或转录可以揭示与情感状态或情感反应相关的韵律、语调或语音内容的模式。在一些实施方案中,听者设备190或系统100内部或外部的另一个过程可以用于收集和/或处理相机、语音或其他用户数据,以帮助识别听者的当前情感状态212。例如,可以根据诸如在以下中描述的技术来分析示出用户面部的相机数据以获得情感状态信息:samara,a.,galway,l.,bond,r等人affective state detection via facial expression analysis within a human
–
computer interaction context.j ambient intell human comput 10,2175
–
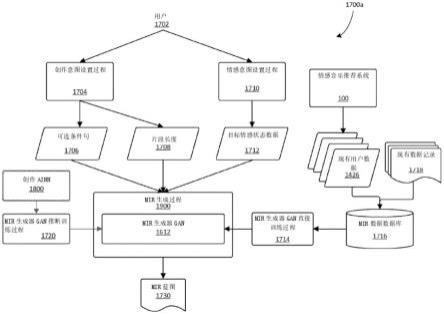
2184(2019)数字对象唯一标识符:10.1007/s12652-017-0636-8,其全部内容通过引用结合于此。
173.图6至图10示出了示例性用户界面(ui)屏幕。这些屏幕可以在听者设备190的触摸屏194上显示给用户,并且可以用于收集用户输入以及向用户提供信息。参考图6,示出了ui屏幕的会话启动序列600,所述会话启动序列被呈现给用户以开始与情感音乐推荐系统100的交互会话。第一屏幕602向用户呈现一组模式选项,每个模式对应于目标情感状态214。此屏幕602上显示的模式是―专注”(例如,对应于高激活)和―平静”(例如,对应于低激活)。还呈现了―训练您的ai”输入区,当选择所述区时,可以允许用户进入如上所述的情感推断神经网络140的推断训练过程。
174.一旦用户选择了目标情感模式,系统100就可以使用此输入来确定将在用户会话期间使用的目标情感状态214。然后向用户呈现第二屏幕604,允许用户识别他或她的当前设置或环境的性质,例如环境是安静且私密的、嘈杂且私密的、安静且公共的、嘈杂且公共的,还是由于行进而随时间变化的。第三屏幕606允许用户在播放列表模式与沉浸式模式之间进行选择。此屏幕606可以例如允许(在播放列表模式下)向用户呈现示出播放列表的流数据236,或者只是使流数据236包括音频流234本身,直接发送到听者设备190用于听觉呈现,而无需进一步的用户交互。在一些实施方案中,此模式选择屏幕606可以允许用户指定来自音乐库184的音频片段的哪个子集220用于用户会话(并且因此从dqn 122、124到126中选择哪个dqn)。
175.第四屏幕608允许用户选择用于用户会话的音乐流派。这可以选择或进一步缩小用于用户会话的音频片段的可能子集220。第五屏幕610允许用户选择音频流234的持续时间。用户选择的持续时间可以用于确定要包括在音频流234中的音频片段230的数目,这又确定了dqn 120执行了多少片段识别步骤。在一些实施方案中,用户还可以使用此屏幕610来选择环境曲目并确定他们的会话的长度(即,dqn 120要采取的步骤数)或音频流234的其他音频特性。
176.第六屏幕612允许用户识别他或她的当前情感状态212。所示出示例使用情感空间的二维表示,其中激活作为垂直轴并且效价作为水平轴。二维空间进一步填充有对应于命名的情感状态的多个区域:例如,空间的右上象限中的绿色区域被命名为―充满活力的”,左上象限中的红色区域被命名为―紧张的”,左下象限中的白色区域被命名为―悲伤的”,右下象限中的蓝色区域被命名为―平静的”,左中区中的深灰色或黑色区域被命名为―恐惧的”,并且中心周围的灰色区域被命名为―中性的”。用户可以将状态指示光标(这里示出为空间中心附近的白色圆圈)移动到空间中对应于他或她自我评估的当前情感状态或心情的位置。一些实施方案还可以包括额外输入,诸如在屏幕612底部示出的焦虑量表滑块,以指示第三维度或额外数据来补充上面的二维情感状态自我报告指示。
177.第七屏幕614允许用户提供面部表情数据,以补充或替代来自第六屏幕612的自我报告数据。如果用户选择拍照,则使用听者设备190的相机控制界面呈现第八屏幕616。一旦用户在屏幕八616上拍摄了他或她的脸部的照片,第九屏幕618就示出系统的用基于例如用户的面部表情的情感分析来注释的照片。
178.一些实施方案可以使用从诸如屏幕六612处的用户输入收集的自我报告数据来训练或校准面部情感分析过程或用于将情感与用户数据(例如,如上所述的生理信号、语音数据等)相关联的其他过程。
179.一旦基于来自屏幕六612和/或屏幕九618的输入识别了用户的当前情感状态212,系统100就生成音频流234并将音频流数据236发送到听者设备190,如上所述。可以向用户呈现第十屏幕620,所述第十屏幕在屏幕620底部的音乐控制显示中示出了对应于第一音频片段的元数据,在此示出为歌曲―feeling good”的标题和持续时间,以及音乐回放控件。在屏幕620的顶部和中部,为用户提供经更新的当前情感状态输入区,以在用户会话期间启动他或她的当前情感状态的更新,如上所述。
180.图7示出了呈现给用户以结束与情感音乐推荐系统100的交互会话的ui屏幕的会话结束序列700。第一屏幕702呈现情感状态输入显示,用于在听完音频流234之后,在用户
会话结束时报告用户的经更新的当前情感状态。如上所述,此经更新的当前情感状态数据用于更新情感推断神经网络140。第二屏幕704呈现用面部图像数据补充或代替来自第一屏幕702的自我报告数据的选项,遵循与会前屏幕七614到会前屏幕九618相同的过程来收集和分析此数据并产生第三屏幕706。然后,第四屏幕708可以基于来自屏幕612和618的用户的初始报告的当前情感状态212以及来自屏幕620、702和706的用户的随后更新的当前情感状态向用户显示情感反应结果。屏幕708顶部的图表可以示出用户在会话期间的情感轨迹,并且可以包括一个或多个命名的情感状态随时间的标识和/或幅度。屏幕708底部的一组条形图可以通过活动和效价和/或通过自我报告和面部分析来分解用户的情感反应。
181.一旦用户会话已经结束,系统100就可以使用空闲时间来重新训练dqn 120,如上所述。
182.图8示出了呈现给新用户或已经选择更新或深化由系统存储的他或她的个人简档的用户的ui屏幕的用户定制序列800。第一屏幕802提示用户提供诸如出生日期和性别身份的个人数据。第二屏幕804提示用户识别他或她经历数个命名的情感状态中的每个情感状态的频率。第三屏幕606提示用户关于另一组命名的情感状态的频率以及关于用户睡眠困难的频率。第四屏幕808提示用户识别他或她经历压力或焦虑的频率。基于通过此序列800中的滑块和其他用户输入元素提供的用户输入,系统可以校准或定制系统100的各个部分的训练和/或操作。例如,经常感到悲伤但很少感到精力充沛的用户可以校准他或她的情感推断神经网络140,以基于特定于所述用户的情感状态值的基线或平均集合来归一化给予这些状态的权重。所述系统还可以使用此用户输入数据来向用户推荐如何使用所述系统来实现用户的目标,诸如精神健康或心情管理目标。图9示出了作为简档创建过程的一部分呈现给用户的示例性用户简档数据集合ui屏幕902。ui屏幕902顶部的进度条示出了用户在用户简档创建过程中已经前进了多远。ui屏幕902的底部示出了供用户指示通常他们感到不安的程度的输入区。
183.图10示出了示例性上下文信息收集ui屏幕1002。可以使用此屏幕1002的上下文信息收集交互来收集用作图4a至图4b和图5的神经网络或强化学习算法的输入的上下文信息。屏幕1002的顶部示出了作为二维情感状态指示符的当前情感状态输入区。屏幕1002的底部将当前环境输入区示出为指示当前环境是安静还是嘈杂以及它是私密还是公共的两个开关。可以与时间戳相关联地收集上下文信息,时间戳可以被系统100用来确定一天中的时间。
184.在一些实施方案中,多个系统100或系统100的各种部件的多个版本(例如dqn 120或情感推断网络140)可以用于与不同的用户交互。各种系统100或部件可以由用户个性化,并且存储机制可以用于存储由用户标识符索引的不同系统或不同模型(例如120或140)。
185.图11示出了示例性多模型系统1100。此类多模型系统1100的每个用户可以拥有他们自己的一个或多个模型,这些模型可以被训练来学习个体用户如何对音乐做出反应的独特动态。在多模型系统1100中,听者的设备190向数据库1102提供用户标识符1104(例如,用户id号),所述数据库存储个体用户的个体化机器学习模型,诸如个体化dqn 120和个体化训练的情感推断算法140。在一些实施方案中,此类系统1100的用户也将能够创建他们自己的音频片段186的集合(即子集220),并且这些也可以由数据库1102存储或识别。dqn 122、124
…
126可以由对所述用户唯一的动作(或音频片段186的子集220)构成,或者可以是来自
所述用户的音乐库的选择。
186.在多模型系统1100的一些实施方案中,可以通过收集关于用户的基线音乐品味的信息(例如,作为上面参考图8至图9描述的用户简档创建过程的一部分)并将用户与包括与那些品味一致的音乐的音频片段186的dqn 120和/或子集220进行匹配来从数据库1102中选择音频片段186的dqn 120和/或子集220。因此,如图11所示的给定多模型系统1100可以特定于特定用户和从音频库184中选择的音频片段186的特定子集220。音频片段186的子集220可以基于用户的选择(例如,用户的音乐库)或者通过确定在当前上下文中哪个集合对于用户将是最佳的算法(例如,基于用户的当前情感状态212、设置和/或环境)来选择。
187.在一些实施方案中,多模型系统1100的个体个性化分几个阶段进行。用户可以从已经基于所有用户或基于类似简档的用户(例如,分享他们的音乐品味、基线心情简档、个性简档和/或人口统计)训练的模型开始。门控过程可用于使用户开始使用这些更通用的模型,并逐渐训练用户自己的个体模型。一旦这些个性化模型达到了性能的阈值,它们就将代替更通用的模型以供运行时使用。
188.在使用个性化模型的实施方案中,还可以添加音乐享受量表,以在dqn训练过程中提供重要的输入数据。如果用户不喜欢一个音频片段,他们可以注释表示所述音频片段的曲目。直接训练过程270内的奖励函数272可以根据评级考虑奖励或惩罚。这将允许系统快速了解用户是否喜欢给定的音频片段,当在所述用户中引发情感状态时,这可能会对音频片段的有效性产生重大影响。
189.图12示出了示例性音乐享受评级用户界面屏幕1202,其允许用户提供关于他们对正在播放的当前音频片段的享受的输入。屏幕1202的顶部示出了情感状态更新输入区。屏幕1202的底部示出了回放控件。屏幕1202的中间部分示出了音乐享受输入区,其允许用户移动滑块以指示对正在播放的当前音频片段的享受程度。
190.多模型系统1100的元素可以允许随时间进行深度的、高度特定的个性化,从上下文个性化开始,进展到简档个性化(一旦每个简档组中有足够多的用户在网络中变得活跃),甚至个体个性化(一旦个体用户有足够多的记录会话)。上下文个性化可以包括诸如初始情感状态、当前音乐偏好和一天中的时间的数据。简档个性化可以包括诸如个性、人口统计和基线音乐品味简档的数据。
191.在一些实施方案中,dqn 120和强化学习代理230的输出是从库mir数据182中选择mir特征,而不是从音频库184中选择音频片段230。
192.图13示出了示例性mir特征预测系统1300。在一些此类系统1300中,dqn 120的输出神经元506将包括每个mir特征一个神经元,这将用于确定每个mir特征的水平或值。dqn 120输出的集合可以表示mir向量1302,所述mir向量然后可以通过向库1306发送包括mir向量1302的查询1304而与音频段230(例如,与给定库(诸如用户选择的库1306)内的mir特征最佳拟合的音频片段)匹配,作为代理动作532的一部分。这些mir特征(例如,mir向量1302)然后可以被馈送到情感推断过程224中,和/或mir特征可以由用户在直接训练过程270期间直接注释。在此类实施方案中,用户可以只有一个dqn(因为dqn现在将决定mir特征组合),但是用户可以改为具有一个或多个音频片段库186,这取决于用户当前的音乐品味要求、基线简档或他们自己创建的库(诸如库1306),可以基于音频片段230与mir特征的匹配度从所述库中选择所述音频片段。
193.图14示出了用于创建特定于给定听者的情感推断模型(例如,ainn140)和/或深度q网络122、124、126的模型数据库1402的示例性模型数据库生成过程1400的步骤和部件。模型数据库1402可以用于例如为多模型系统1100的每个用户生成和训练模型。
194.模型数据库生成过程1400包括两个阶段:通才模型训练过程1450和个性化模型训练过程1460。模型数据库1402填充有一组通才模型1432和一组个性化模型1434。每组模型1432、1434可以包括例如ainn 140和多个dqn 122、124、126。通才模型1432可以用于在推断模式下推荐音乐,直到个性化模型1434达到性能阈值,此时系统(例如多模型系统1100)可以切换到使用个性化模型1434向用户推荐音乐。
195.通才模型训练过程1450开始于基于使用音乐曲目的mir数据的管理过程1422从音乐目录1420中提取音乐曲目的子集。在一些实施方案中,音乐目录1420可以是包括音乐曲目的音频库184。在一些实施方案中,音乐曲目可以是音频片段230。在一些实施方案中,与每个音乐曲目相关联的mir数据可以作为库mir数据182存储在音乐目录1420中;在其他实施方案中,可以从音乐曲目中提取与音乐曲目相关联的mir数据,例如使用mir提取过程225。
196.因此,在一些实施方案中,管理过程1422需要描述与每个曲目相关联的主题mir元数据的标记数据集(即,音频库184)。例如,音乐目录1420可以包括一组来自20世纪20年代的关于爱情的爵士音乐,和/或一组来自20世纪60年代的具有一般平静能量的摇滚音乐。可以使用多种已知计算方法中的任何一种计算方法(诸如受监督聚类算法)在算法上执行监管过程1422。
197.由管理过程1422生成的音乐曲目的子集由dqn分组过程1424使用,以生成与要训练的每个通才深度q网络相关联的音乐曲目的组。上文参考图2a描述了具有特定mir特征的音频片段230与给定dqn之间的关系。
198.通才模型训练过程1450还使用从听音设备190收集的来自整个用户群体的现有用户数据1426,如以上参考图2a至图2b所述。现有用户数据1426可以包括用户简档数据、用户收听与其情感反应相关的音乐的记录等。用户分组过程1428可以对现有用户数据1426进行聚类或分段,以识别用户类型或用户类型组。在feiyun zhu,jun guo,zheng xu,peng liao,junzhou huang,―group-driven reinforcement learning for personalized mhealth intervention”,2017,arxiv:1708.04001,https://arxiv.org/abs/1708.04001中描述了用户组或类型识别的示例,其全部内容通过引用结合于此。
199.通才模型转移学习过程1408用于训练一组或多组通才模型1432。通才模型转移学习过程1408可以包括用于训练通才ainn 140的情感推断神经网络(ainn)通才模型训练过程1430和用于训练一组通才dqn 122、124、126的深度q网络(dqn)通才模型训练过程1431。各种转移学习技术在机器学习领域是已知的。示例性转移学习过程由kieran woodward and eiman kanjo and david j.brown and t.m.mcginnity:―on-device transfer learning for personalising psychological stress modelling using a convolutional neural network”,2020,arxiv:2004.01603,https://arxiv.org/abs/2004.01603描述,其全部内容通过引用结合于此。
200.ainn通才模型训练过程1430可以使用各种用户组(即,由用户分组过程1428输出的用户组)中的用户的ainn 140来使用转移学习训练一组通才模型1432的通才ainn 140。
dqn通才模型训练过程1431可以使用通才模型1432的通才ainn 140和由dqn分组过程1424输出的由dqn分组的音乐曲目,来使用转移学习训练一组通才模型1432的通才dqn122、124、126。例如,由用户分组过程1428识别的特定用户组可以与特定通才ainn 140相关联,并且来自那些用户的现有用户数据1426可以用于训练给定的通才ainn 140,而与用户组结合的特定音乐曲目子集可以与特定通才dqn相关联,并且所述用户组的通才ainn 140可以用于训练给定的dqn。
201.个性化模型训练过程1460开始于将新用户1404添加到系统1100。可向新用户1404呈现基线化过程1406以初始化用户简档,例如使用上文参考图11描述的用户简档创建过程。基线化过程1406还可以引起用户输入,以帮助识别新用户1404的音乐偏好:例如,可以提示新用户1404填写基线简档,和/或系统1100可以让新用户1404快速连续地收听音乐剪辑,以了解新用户1404的品味和/或对音乐的行为反应。
202.基于音乐品味、个性、用户简档和/或在基线化过程1406期间收集的其他信息来执行匹配过程1410。在一些实施方案中,匹配过程1410可以使用机器学习技术或其他排序或匹配算法在算法上完成。基于基线化过程1406的输出,例如从数据库1102中选择与新用户1404良好匹配的一组通才模型(例如ainn 140和dqn 122、124、126)。标记过程1436用于通过基于用户分组(来自用户分组过程1428)和音乐曲目子集(来自dqn分组过程1424)来标记通才模型1432以促进匹配过程。标记过程1436使用的标记数据可以是任何种类的识别向量。匹配过程1410可以基于由基线化过程1406输出的数据(例如,用户简档数据)将新用户1404与特定用户组进行匹配,并且可以基于所述匹配来选择一组通才模型1432,并将其用于最初填充模型数据库1402。
203.然后为新用户1404生成一组个性化模型1430。最初,个性化模型1430可以是基于匹配过程1410为新用户1404选择的通才模型1432的副本。然而,当个性化模型1430被训练并且由此使用来自新用户1404的数据来个性化时,所述个性化模型将提高准确性,直到它们达到性能阈值并且被系统110用于推断,如上所述。
204.在音乐选择过程1412中,新用户1404手动创建他或她希望系统1100管理的音乐子集。音乐选择过程1412例如通过允许新用户1404识别来自本地或远程目录或音乐曲目库的音乐曲目来填充用户音乐目录1414。
205.个性化模型训练过程1460的dqn分组过程1416的操作类似于上述通才模型训练过程1450的dqn分组过程1424。来自用户音乐目录1414的音乐曲目的子集被识别并用于与要训练的个性化模型1430的每个深度q网络相关联地对音乐曲目进行分组。
206.从新用户1404收集的数据用于在使用个性化模型转移学习过程1418的每个用户体验之后训练个性化模型1430,特别是个性化模型1430的ainn 140,所述个性化模型转移学习过程类似于上述通才模型转移学习过程1408。个性化模型转移学习过程1418也可以使用从基线化过程1406收集的数据。下面参考图15描述个性化模型转移学习过程1418使用的因素。
207.dqn个性化模型训练过程1417与上述dqn个性化模型训练过程1417类似地操作,以使用个性化模型1430的个性化ainn 140训练个性化模型1430的dqn 122、124、126。
208.图15示出了由图14的个性化模型转移学习过程1418使用的个性化因素1500。个性化模型转移学习过程1418的目标是从对应于上下文个性化1504的金字塔顶层1502开始,通
过对应于简档个性化1506的金字塔中间层1502,直到到达对应于每个用户(例如新用户1404)的个体模型1508的金字塔底层1502。
209.上下文个性化1504可以包括基于初始状态(例如,用户的情感状态)、用户当前表达的音乐偏好或其他环境变量(例如,一天中的时间)的模型(例如,ainn 140和dqn 122、124、126)的个性化。上下文个性化1504因此可以对应于在传统音乐推荐系统中考虑的因素。简档个性化1506可以包括基于用户的个性、人口统计成员资格、基线音乐品味简档和其他一般用户特征的模型的个性化。在一些实施方案中,简档个性化1506可以基于由用户分组过程1428确定的用户组内的用户成员资格。个体模型1508是使用特定用户的情感反应训练以准确地推断特定用户对音乐的情感反应的个体个性化模型,如上文例如参考图2a至图2b所述。
210.因此,可以使用模型数据库生成过程1400来选择和训练个性化模型1430的层级,其范围从使用上下文个性化1504的轻微个性化到使用简档个性化1506的更具体个性化到使用个体模型1508的非常具体个性化。
211.本文描述的系统的各个元件也可以用于除了情感音乐推荐之外的应用。情感推断神经网络140可以用于音乐分析、营销或见解领域,允许基于其预测的情感影响对新内容进行评估。例如,可以切换情感推断神经网络140的输入和输出,从而提供在给定特定用户简档的情况下具有引发目标心情状态的可能性的mir特征序列。由本文描述的各种系统生成的数据可以用于音乐产业内的各种目的,诸如提供关于人类心理如何对音乐做出反应的新见解,这可以通过人口统计组、用户简档组和各种品味简档来进一步分类。有了足够的数据,本文描述的系统的情感推断能力可能能够创建关于音乐作品的新的元数据,增加功能应用(例如,电影同步、音乐治疗等)的确定性。
212.现在将参考图16至图30描述用于情感音乐创作的方法、系统和非暂时性介质的示例。所描述的音乐创作系统可以在音乐创作过程的一个或多个阶段使用,以生成旨在引起听者情感状态改变的歌曲的mir蓝图、乐谱、创作功能谱、制作功能谱、混音和/或母带。上文在情感音乐推荐的上下文中描述的各种部件,诸如情感推断模型(例如ainn)和mir提取过程,可以用在本文描述的音乐创作系统的各种实施方案中。
213.图16示出了示例性情感音乐创作系统1600。情感音乐创作系统1600可以使用包括硬件和软件部件的计算平台或系统来实施,非常类似于图1的情感音乐推荐系统100。这里所示的示例包括与处理器系统1640通信的存储器系统1638,所述处理器系统又与用于与用户交互的用户界面1642通信。
214.存储器系统1638存储用于实施本文描述的情感音乐创作的方法和过程的软件和数据:由处理器系统1640执行以实施本文描述的技术的软件指令1610,包括使用机器学习技术的各种模型的训练和操作;多个mir生成器生成对抗网络(gan),用于为不同的听者简档、流派和/或风格生成mir数据,示出为第一mir生成器gan 1612到第n mir生成器gan 1614;多个乐谱生成器gan,用于生成不同流派和/或风格的乐谱,示出为第一乐谱生成器gan 1616到第n乐谱生成器gan 1618;多个情感推断模型,用于预测不同听者简档的情感反应,示出为第一情感推断神经网络1620到第n情感推断神经网络1622;以及多个自适应音乐代理模型,用于改编现有曲目或音频子总线1628,以针对不同听者简档、流派和/或风格实现目标情感状态或轨迹,示出为第一自适应音乐代理模型1624到第n自适应音乐代理模型
1626。应当理解,尽管每组模型示出为包括n个模型,但是n的值对于每组可以是不同的。
215.存储器系统1638还存储数据,包括音频子总线1628、一个或多个mir生成器训练数据库1630、乐谱生成器训练数据库1632、母带处理代理训练数据库1634和自适应音乐代理训练数据库1636。
216.下面参考图17a至图17d描述情感音乐谱写系统1600的各种软件和数据部件之间的关系,以及它们通过用户界面1642与用户的交互。然后参考图18至图26描述图17a至图17d所示的各种子系统的操作。
217.图17a示出了图16的示例性情感音乐创作系统1600的第一部分1700a的过程之间的关系,包括mir生成器过程1900。mir生成器过程1900用于生成音频片段(例如,歌曲)的mir蓝图,所述音频片段旨在在听者中引发特定的情感反应。由mir生成器过程1900生成的mir蓝图通常整体识别歌曲的mir特征,以及音频片段的多个时期(即,时间子片段)中的每个时期的mir特征,其将引发期望情感反应。用户1702(可以是艺术家、制作人或参与音乐创作或制作的其他用户)经由用户界面1642与系统1600交互。用户1702可以与创作意图设置过程1704交互,所述创作意图设置过程通知下面描述的系统1600的各种子系统关于要在创作过程期间生成的音乐数据的期望特性。图17a所示的mir生成器过程1900可以通过提供诸如以下的信息来管理:用户1702是想要制作完整的音频片段230(例如,音乐曲目)还是仅仅制作一个子总线(即,一组相似的声源,诸如歌曲的弦乐器部分或主唱部分)?用户1702想要音乐曲目或子总线有多长?创作意图设置过程1704确定用于可选地约束mir生成的可选条件1706,诸如指定的调、速度和/或歌曲结构。创作意图设置过程1704还确定片段长度1708(例如,音乐曲目或子总线的长度)。
218.用户1702还可以与情感意图设置过程1710交互,所述情感意图设置过程通知下面描述的系统1600的各种子系统关于在创作过程中要生成的音乐数据的听者中要引起的期望情感状态或轨迹。情感意图设置过程1710可以生成目标情感状态数据1712,所述目标情感状态数据指示用户1702希望听者在听了创作过程期间生成的音乐后的感受。
219.可选条件1706、片段长度1708和目标情感状态数据1712被用作mir生成过程1900的输入,下面参考图19更详细地描述。
220.mir生成器过程1900包括mir生成器gan,这里示为第一mir生成器gan 1612。在一些实施方案中,mir生成器过程1900被实施为具有控制网络的条件gan;可选条件1706、片段长度1708和目标情感状态数据1712被用作mir生成gan 1612的条件输入。目标情感状态数据1712也可以用作控制网络的输入,如下面更详细描述的。
221.mir生成器gan 1612由mir生成器gan直接训练过程1714训练,使用用情感状态数据和可选的其他条件标记的mir数据数据库1716作为训练数据。mir数据数据库1716可通过使用各种数据源来填充或以其他方式生成,诸如从用户群体的听音设备190收集的现有用户数据1426(如上文参考图14所述),和/或现有数据记录1718,其将mir数据与情感反应和/或其他条件数据(例如,可选条件1706,诸如调、速度和/或歌曲结构)相关联。在一些实施方案中,可以使用如上所述的情感音乐推荐系统100来收集现有用户数据1426。
222.mir生成器gan 1612也由mir生成器gan推断训练过程1720使用如下参考图18所述的创作ainn 1800来训练。
223.mir生成器过程1900生成mir蓝图1730,所述mir蓝图在一些实施方案中可以包括
梅尔频率倒谱(mfc)频谱图,可能连同其他mir特征。情感音乐创作系统1600的其他部件可以使用mir蓝图1730来帮助生成音乐数据(例如,乐谱、曲目或子总线)。
224.图18示出了表示由情感音乐创作系统1600使用的创作ainn 1800的简化递归神经网络。创作ainn 1800的操作非常类似于上面参考图4b描述的ainn 140。然而,不是使用个体用户的当前情感状态212作为输入,而是使用来自mir数据数据库1716的训练数据来训练创作ainn 1800,所述训练数据包括用情感反应数据标记的mir数据,以及与mir数据相关联的上下文信息432。因此,创作ainn 1800在推断模式下操作,以预测普通用户对一组mir特征(包括全局mir特征433以及特定于时期的mir特征434的时间序列)的情感反应,而不管用户的当前情感状态如何。
225.图19示出了由情感音乐创作系统1600使用的示例性mir生成器过程1900。mir生成器过程1900可以被构造为具有控制网络1906的mir生成器gan(包括生成器网络1902和概率网络1904),如在cong jin,yun tie,yong bai,xin lv,shouxun liu,―a style-specific music composition neural network”,9june 2020,neural processing letters(2020)52:1893
–
1912,https://doi.org/10.1007/s11063-020-10241-8(以下称为―jin”)中所描述,其全部内容通过引用结合于此。mir生成器gan本身,尤其是生成器网络1902,可以被构造为条件gan,如在yi yu,simon canales,―conditional lstm-gan for melody generation from lyrics”,2019,arxiv:1908.05551,https://arxiv.org/abs/1908.05551中所描述,其全部内容通过引用结合于此。生成器网络1902包括生成器神经网络1907,概率网络1904包括鉴别器神经网络1908;每个神经网络1907、1908可以是具有长短期记忆(lstm)的递归神经网络(rnn)、卷积神经网络、标准多层感知器神经网络或一些其他类型的神经网络或机器学习模型。mir生成过程1900的功能也可以通过其他生成式深度学习模态来实现,如变分自动编码器(vae)或简单的递归神经网络(rnn)本身。gan模型已被评估为执行所需功能的有效手段,但另外,类似的算法也可能是有效的,特别是随着机器学习的进步。
226.mir生成器过程1900在具有两个训练阶段的训练模式下操作,或者在mir蓝图生成模式下操作。在训练模式的第一训练阶段,概率网络1904的鉴别器神经网络1908被训练成使用来自mir数据数据库1716的实际存储的mir蓝图1910(即,对应于由人类艺术家创作的实际歌曲的mir蓝图)来识别mir蓝图。
227.在第二训练阶段,生成网络1902从mir数据数据库1716接收可选条件1706、片段长度1708和目标情感状态数据1712作为输入(即,条件)。生成网络1902包括生成神经网络1907,所述生成神经网络被配置为生成mir蓝图(示出为生成的mir蓝图1912)。在训练过程的开始,每个生成的mir蓝图1912本质上是随机数据。然而,概率网络1904用于向由控制网络1906调节的生成网络1902提供反馈,以训练生成网络1902生成越来越可信的mir蓝图。鉴别器神经网络1908将每个生成的mir蓝图1912与来自mir数据数据库1716的实际存储的mir蓝图1910进行比较。此比较的结果是概率值1916(例如,从0到1的值),其指示鉴别器神经网络1908关于生成的mir蓝图1912是否是实际歌曲的mir蓝图的推断可能性。
228.控制网络1906包括情感推断模型(示出为创作ainn 1800)和评价者1914(如jin参考文献中所述)。评价者1914操作以将生成的mir蓝图1912约束到满足目标情感标准的那些mir蓝图。因此,在第二训练阶段,评价者1914接收三个输入:由概率网络1904基于生成的
mir蓝图1912生成的概率值1916、由创作ainn 1800基于生成的mir蓝图1912生成的预测情感1920(即,听者对匹配mir蓝图的音乐的预测情感反应),以及从mir数据数据库1716接收到的目标情感状态数据1712。评价者1914将奖励函数应用于概率值1916、预测情感1920和目标情感状态数据1712,以基于生成的mir蓝图1912的可信度以及它满足目标情感状态数据1712的可能性来生成奖励1918。奖励1918被用作训练生成器神经网络1907的反馈,从而提高其生成满足由奖励函数指定的目标情感状态数据1712的可信的生成的mir蓝图1912的能力。评价者1914的奖励函数由情感推断模型驱动,诸如创作ainn 1800。
229.在控制网络1906的辅助下,生成网络1902和概率网络1904因此共同构成mir生成器gan(例如第一mir生成器gan 1612)。在mir蓝图生成模式下,可选条件1706、片段长度1708和目标情感状态数据1712由用户1702经由创作意图设置过程1704和情感意图设置过程1710提供,而不是由mir数据数据库1716提供。生成器网络1902用于生成与目标情感状态数据1712匹配的生成的mir蓝图1912(例如,图17a的mir蓝图1730)。
230.图17b示出了示例性情感音乐创作系统1600的第二部分1700b的过程之间的关系,包括乐谱生成器过程2000。音乐创作是指创作一首音乐,并且创作的最终结果是是生成乐谱,即,标识应当在什么时间以及以什么方式由哪些乐器演奏哪些音符以生成歌曲记录的音频特性的文档。如图17a所示,用户1702可以与创作意图设置过程1704交互,以通过提供诸如以下信息来管理乐谱生成器过程2000:用户1702想要和声进行、旋律、节奏还是完整乐谱?用户1702想要什么乐器?用户1702希望乐谱是多长?创作意图设置过程1704因此确定乐谱类型1732、乐器1734和乐谱长度1736。乐谱类型1732可以指定节奏、和声进行和/或旋律。
231.乐谱生成过程2000接收乐谱类型1732、乐器1734和乐谱长度1736作为条件输入。乐谱生成过程2000还接收要生成的乐谱所需的一组mir数据1738,其被用作条件输入和/或对乐谱生成过程2000的控制网络的输入。在一些实施方案中,所需的所述一组mir数据1738可以从由mir生成过程1900生成的mir蓝图1730中提取,或者它可以从另一个mir蓝图或mir数据源中提取。在一些实施方案中,乐谱生成过程2000使用的所需的所述一组mir数据1738可以仅仅是包括在mir蓝图1730中的mir数据的一部分;在其他实施方案中,它可以包括mir蓝图1730中包括的所有mir数据。
232.乐谱生成过程2000包括乐谱生成器gan,这里示出为第一乐谱生成器gan 1616。乐谱生成过程2000对其输入进行操作,以生成作为输出的乐谱1742,诸如乐器数字接口(midi)乐谱。下面参考图20更详细地描述乐谱生成过程2000对其输入生成其输出的操作。
233.乐谱生成过程2000由乐谱生成器训练过程1744使用由标记乐谱数据数据库1746提供的标记乐谱数据在训练模式下训练。标记乐谱数据可以包括用mir蓝图和/或其他条件输入标记的人工创作乐谱,以用于训练乐谱生成器过程200及其乐谱生成器神经网络(例如,第一乐谱生成器神经网络1616)。
234.图20示出了上面参考图17b描述的示例性乐谱生成器过程2000。乐谱生成器过程2000可以类似于mir生成器过程1900来构造:条件gan包括生成器网络2002和概率网络2004,以及控制网络2006。生成器网络2002包括生成器神经网络2007,概率网络2004包括鉴别器神经网络2008;每个神经网络2007、2008可以是具有长短期记忆(lstm)的递归神经网络(rnn)、卷积神经网络、标准多层感知器神经网络或一些其他类型的神经网络或机器学习模型。乐谱生成过程2000的功能也可以通过其他生成式深度学习模态来实现,如变分自动
编码器(vae)或简单递归神经网络(rnn)本身。gan模型已被评估为执行所需功能的有效手段,但另外,类似的算法也可能是有效的,特别是随着机器学习的进步。
235.乐谱生成器过程2000在具有两个训练阶段的训练模式或者乐谱生成模式下操作。在训练模式的第一训练阶段,概率网络2004的鉴别器神经网络2008被训练成使用来自标记乐谱数据数据库1746的实际存储乐谱2010(即,由人类艺术家创作的乐谱)来识别乐谱。
236.在第二训练阶段,生成网络2002接收可选的所需mir数据1738、乐谱长度1736、乐器1734和乐谱类型1732作为来自标记乐谱数据数据库1746的输入(即,条件)。生成网络2002包括生成神经网络2007,所述生成神经网络被配置为生成乐谱(示出为生成的乐谱2012)。在训练过程的开始,每个生成的乐谱2012本质上是随机数据。然而,概率网络2004用于向由控制网络2006调节的生成网络2002提供反馈,以训练生成网络2002来生成越来越可信的乐谱。鉴别器神经网络2008将每个生成的乐谱2012与来自标记乐谱数据数据库1746的实际存储的乐谱2010进行比较。此比较的结果是概率值2016(例如,从0到1的值),其指示鉴别器神经网络2008关于生成的乐谱2012是否是实际乐谱的推断可能性。
237.控制网络2006包括评价者2014。评价者2014操作以将生成的乐谱2012约束为满足一组音乐理论规则2020的乐谱,所述一组音乐理论规则可以被存储为例如音乐理论规则数据库。因此,在第二训练阶段,评价者2014接收三个输入:由概率网络2004基于生成的乐谱2012生成的概率值2016、音乐理论规则2020以及由标记乐谱数据数据库1746提供的所需mir数据1738。评价者2014将奖励函数应用于概率值2016、音乐理论规则2020和所需mir数据1738,以基于生成的乐谱2012的可信度、满足音乐理论规则2020的可能性以及生成的乐谱2012与一组mir数据(即,由标记乐谱数据数据库1746提供的所需mir数据1738)的匹配程度来生成奖励2018。奖励2018用作训练生成器神经网络2007的反馈,从而提高其生成满足音乐理论规则2020并匹配所需mir数据1738的可信的生成的乐谱2012的能力。
238.在控制网络2006的辅助下,生成网络2002和概率网络2004因此共同构成乐谱生成器gan(例如第一乐谱生成器gan 1616)。在乐谱生成模式下,乐谱长度1736、乐器1734和乐谱类型1732由用户1702经由创作意图设置过程1704提供,并且可选的所需mir数据1738由mir蓝图1730经由所需mir数据提取过程1740提供,而不是由mir数据数据库1716提供。生成器网络2002用于生成与mir蓝图1730匹配并且遵守音乐理论规则2020的可信的生成的乐谱2012(例如,图17a的乐谱1742)。
239.回到图17b,由乐谱生成器过程2000生成的乐谱1742可以被人类艺术家用作后续音乐制作过程的乐谱。然而,乐谱1742也可以被情感音乐创作系统1600的后续过程使用,以使音乐制作的一个或多个后续步骤自动化。在一些实施方案中,用户(例如,与系统1600交互以生成乐谱1742的艺术家或制作人或另一用户)可以与音乐创作过程1748交互,以基于乐谱1742和/或创作功能谱2400生成音乐曲目或子总线的初步混音1750。可以基于mir蓝图1730通过创作功能谱过程2300来生成创作功能谱2400。下面参考图23详细描述创作功能谱过程2300,并且参考图24a至图24b描述示例性创作功能谱2400。
240.用户1702可以通过诸如数字音频工作站(daw)或其他音频工作站的用户界面1642与音乐创作过程1748交互。
241.图23示出了由图16的并在图17b示出的情感音乐创作系统1600使用的创作功能谱过程2300。创作功能谱过程2300对mir蓝图1730执行数据变换2302,以生成创作功能谱
2400。
242.图24a是由图23的创作功能谱过程生成的创作功能谱的示例性情感空间指示符2420。情感空间指示符2420类似于图6、图7、图10和图12中的ui屏幕所使用的情感状态的2维视觉指示符:它标识位于2维情感空间内的创作功能谱的情感状态2424(基于mir蓝图1730),其中水平轴2430是效价(向右正),并且垂直轴2428是激活(向上高)。多种心情被示出为区域,诸如温柔2422和宁静2426。在此示例中,创作功能谱的情感状态2424位于温柔2422与宁静2426之间,指示非常正的效价和略微低的激活。
243.图24b示出了由图23的创作功能谱过程2300生成的示例性创作功能谱2400。创作功能谱2400指示与要被执行以产生音乐片段(例如,音乐曲目或子总线)的创作过程相关的各种类型的信息。
244.各个字段表示整个音乐片段的特性。混音音色字段2402提供与混音音色有关的信息,这里示出为文本―乐器选择和演出应该提供具有强低频存在的宽频谱范围(eq)”。速度字段2412提供与音乐片段长度相关的信息,这里示出为文本―111”。节拍字段2414提供与音乐片段长度相关的信息,这里示出为文本―简单”。结构字段2416提供与音乐片段长度相关的信息,这里示出为文本―5个部分”。调字段2418提供与音乐片段长度相关的信息,这里示出为文本―a大调”。调清晰度字段2420提供与音乐片段长度相关的信息,这里示出为文本―低”。和声复杂度字段2422提供与音乐片段长度相关的信息,这里示出为文本―高”。和声均衡字段2424提供与音乐片段长度相关的信息,这里示出为文本―倾向小调”。音调不和谐字段2426提供与音乐片段长度相关的信息,这里示出为文本―中等”。
245.音乐片段数据的若干时间序列指示音乐片段在不同时间时期2442、2444、2446、2448、2450、2452、2454或音乐片段内的子片段(从第一时期2442到第七时期2454)的各种特性。节奏复杂度时间序列2434绘制了复杂(高)与简单(低)之间的每个时期的节奏复杂度。音高中心时间序列2436绘制了高(high)与低(low)之间的每个时期的音高中心。强度时间序列2438绘制了高(高)与低(低)之间的每个时期的强度。密度时间序列2440绘制了厚(高)与薄(低)之间的每个时期的密度。
246.创作功能谱2400还可以包括情感空间指示符2420或如参考图24a所述的其他情感状态数据。
247.回到图17b,与音乐创作过程1748交互的用户1702可以依赖于在创作功能谱2400中提供的信息来指导初步混音1750的准备,无论有或没有乐谱1742的帮助。或者,用户1702在准备初步混音1750时可以依赖于乐谱1742本身。
248.如参考图17c至图17d所示的系统1600的第三部分1700c和第四部分1700d所述,初步混音1750可以通过系统1600的后续操作进一步细化。
249.图17c示出了示例性情感音乐谱写系统1600的第三部分1700c的过程之间的关系,包括自动化母带处理过程2100。母带处理指的是设置各种乐器曲目(即子总线)的音量和其他声音均衡设置,以生成母带录音(也称为母带),即准备呈现给观众的歌曲的最终正式录音。母带被用作制作歌曲的所有后续副本的源。用户1702——其可以是与音乐创作过程1748、创作意图设置过程1704和/或情感意图设置过程1710交互的用户1702相同的用户或不同的用户——与音乐制作过程1758交互以生成初步混音1750或最终混音1760。如同音乐创作过程1748一样,用户1702可以通过诸如数字音频工作站(daw)或其他音频工作站的用
户界面1642与音乐制作过程1758交互,并且用户1702可以得到创作功能谱2600(下面参考图26描述)和/或预先存在的初步混音1750(诸如由音乐创作过程1748生成的初步混音1750)的帮助。
250.可以基于mir蓝图1730(诸如在系统1600的较早部分1700a、1700b中生成的mir蓝图1730),通过制作功能谱过程2500(下面参考图25描述)来生成制作功能谱2600。
251.自动化母带处理过程2100可以用于使音乐制作的母带处理阶段自动化。自动化母带处理过程2100包括母带处理代理2102,所述母带处理代理可以使用强化学习模型来实施,如下面参考图21a至图21b更详细地描述。自动化母带处理过程2100可以对由音乐制作过程1758生成的最终混音1760执行自动化母带处理、对立体声格式的现有曲目1762执行自动化母带处理(以对现有曲目进行重新母带处理)或对改编的最终混音1790执行自动化母带处理(下面参考图17d描述)。自动化母带处理过程2100可以在一次或多次迭代(下面描述)中基于其输入生成最终母带1770,所述最终母带可以作为最终母带音乐曲目(即,音频片段)保存在音频库184中。在一些示例中,自动化母带处理过程2100可以在制作中间使用:即,用户1702可以与音乐制作过程1758交互,以使得自动化母带处理过程2100对已经达到母带处理阶段的人类创作的歌曲执行一次或多次迭代的母带处理过程。
252.母带处理代理2102可以使用母带处理代理训练过程1754来训练,所述过程使用母带处理标准和/或规则数据库1752来提供训练数据。下面将参考图21a至图21b更详细地描述母带处理代理训练过程1754和自动化母带处理过程2100的操作。
253.如在系统1600的第二部分1700b中,所需mir数据提取过程1756可以用于从mir蓝图1730中提取自动化母带处理过程2100所需的所需mir数据1757,并向其提供所需mir数据1757。
254.图21a是示出由图16的情感音乐创作系统使用的自动化母带处理过程2100的第一部分2100a的框图。自动化母带处理过程2100在多次迭代中操作,本文也称为事件(episode)。作为输入接收的原始音频片段2104(即,最终混音1760、立体声格式的现有曲目1762或改编的最终混音1790)在时期分割过程2106被分解成n个时期。每个原始(预母带处理)时期2108被发送到时期母带处理过程2152,用于对一个或多个时间(称为―遍数”或―迭代”)进行母带处理。在每一遍数中,时期母带处理过程2152将母带处理动作(下面描述)应用于时期2108,直到时期2108满足所述时期的mir目标。在第一时期2108满足其相应的mir目标之后,时期2108的母带控制被认为完成,并且下一个时期2108经历时期母带控制过程2152一次或多次,直到它满足其相应的mir目标。这个循环继续,直到片段2104的每个时期2108都被母带处理。
255.mir特征由mir提取过程2110从每个原始音频时期2108中提取,为时期的开始(即,预母带处理)mir特征提供参考。提取的mir特征被称为当前mir时期2112。当前mir时期2112还可以考虑由对母带处理后的音频时期执行的mir提取、预测或参考过程2124生成的额外mir信息(下面参考图21b更详细地描述)。mir提取、预测或参考过程2124可以经由类似mirtoolbox的工具提取mir数据,从先前提取的mir特征的表中参考mir数据,或使用接收原始音频作为输入并输出mir数据预测的模型来预测mir数据。
256.自动化母带处理过程2100所需的mir特征作为所需mir数据1757被接收。所需mir数据1757被mir时期分割过程2114分解成对应于母带处理后的音频片段的每个时期所需的
mir特征的mir数据的时期(即,时间段)。mir数据的这些时期被称为目标mir时期2116,指示给定时期的母带处理过程的mir特征目标。时期大小在时期分割过程2106与mir时期分割过程2114之间同步,以便在整个母带处理过程中保持相同的时间线。
257.短期奖励网络2120生成用于训练母带处理代理2102的短期奖励2122。短期奖励2122用于训练母带处理代理2102的强化学习过程。短期奖励网络2120包括将奖励函数应用于以下三个输入的评价者2118:指示当前时期中期望的mir特征的目标mir时期2116;指示当前时期的预母带处理的mir特征的当前mir时期2112;以及来自母带处理标准和规则数据库1752中的母带处理标准和/或规则。由评价者2118应用的奖励函数生成受母带处理规则和/或标准约束的短期奖励2122,并且基于当前mir时期2112是否满足目标mir时期2116的mir特征。
258.短期奖励2118作为输入被提供给母带处理代理2102,所述母带处理代理可以被实施为强化学习代理,诸如分支递归深度q网络(dqn)。分支递归dqn可以包括lstm,以实施在每个时期执行的母带处理动作的记忆。示例性分支q学习网络在arash tavakoli,fabio pardo,and petar kormushev,―action branching architectures for deep reinforcement learning”,2018,arxiv:1711.08946,https://arxiv.org/abs/1711.08946中描述,其全部内容通过引用结合于此。示例性深度递归q学习网络在matthew hausknecht and peter stone,―deep recurrent q-learning for partially observable mdps”,2017,arxiv:1507.06527,https://arxiv.org/abs/1507.06527中描述,其全部内容通过引用结合于此。可以用于自动化母带处理过程2100的额外强化学习算法是基于模型的参与者评价者算法、a3c算法或上下文多臂老虎机算法。与深度递归q学习配对的分支深度q网络为此功能提供了有效的算法解决方案。
259.图21b是示出自动化母带处理过程2100的第二部分2100b的框图。母带处理代理2102包括在状态-动作网络2130中。使用下面描述的短期奖励2122以及长期奖励2144来训练母带处理代理2102。母带处理代理2102还接收目标mir时期2116和当前mir时期2112形式的状态数据。通过将目标mir时期2116与当前mir时期2112进行比较,母带处理代理2102做出关于适当的参数值的决定,以用于多个母带处理工具中的每个母带处理工具,从而在当前的母带处理遍数中应用于当前的原始音频时期2108。关于每个母带处理工具的参数值的决定由母带处理代理2102的相应动作分支做出,示出为第一动作分支2132、第二动作分支2134、第三动作分支2136等等,直到第n动作分支2138,其中n可以是任何正整数。由母带处理工具应用的母带处理动作可以包括诸如限制和均衡的母带处理动作。
260.时期母带处理过程2152将来自每个动作分支2132
…
2138的母带处理工具参数值应用于被母带处理的原始音频时期2108,以执行母带处理过程,即音频母带处理过程。在已执行母带处理之后,检查产生的音频时期是否完成母带处理。如果音频时期现在被认为完全被母带处理,则母带处理后的时期被存储以供将来参考,并用作对长期奖励网络2140的评论者2142的输入。母带处理后的时期还被存储用于与其他母带处理后的时期的级联,以便由音频级联过程2162最终级联,从而生成最终的母带2170,即包括级联在一起的所有母带处理后的时期的最终母带歌曲。母带处理后的时期还被提供给mir提取、预测或参考过程2124,用于生成当前mir时期2112,如上所述。
261.长期奖励网络2140使用其评论者2142将奖励函数应用于来自母带处理标准和规
则数据库1752的一个或多个所存储的母带处理后的时期和母带处理标准和/或规则数据,以生成长期奖励2144,指示随时间推移的多个时期满足母带处理标准和/或规则的程度。
262.一旦生成了最终母带2170,它就可以被系统1600的其他过程使用,例如通过将其存储在音频库184中作为最终母带1770。
263.图25示出了由情感音乐创作系统1600用来生成由音乐制作过程1758使用的制作功能谱2600的示例性制作功能谱过程2500。由mir提取过程2506从作为输入接收到的当前混音2504(例如,初步混音1750)中提取mir数据,以生成当前混音mir数据2508。将mir蓝图1730与当前混音mir数据2508进行比较,并且由差异计算过程2510计算它们之间的差异,以生成当前混音mir数据2508的每个mir特征匹配mir蓝图1730所需的一组改变2512。对所需的一组改变2512执行数据变换过程2514,以生成制作功能谱2600。例如,音乐制作过程1758可以使用制作功能谱2600来在制作人(即,用户1702)做出制作决策时指导制作人。由mir准确性模块2502执行的此过程2500可以循环通过对应于自动化母带处理过程2100的多次迭代的多次迭代。
264.图26示出了由制作功能谱过程2500生成的示例性制作功能谱2600。制作功能谱2600包括几个全局字段,指示音频片段的整体mir数据中所需的一组改变2512,这里示出为频谱变化字段2602、频谱平衡字段2604、频谱平坦度字段2606和静音比字段2608中所需的百分比改变。制作功能谱2600还包括若干时间序列图,其指示音频片段的每个时期的每时期mir数据中所需的所述一组改变2512,这里示出为亮度时间序列图2612、密度时间序列图2614(指示粗糙度)、响度时间序列图2616(测量为均方根响度差)和强度时间序列图2618(指示事件密度)。每个图2612、2614、2616、2618将时期的当前mir数据示出为实线,将mir目标(来自mir蓝图1730)示出为虚线,其中时期从左到右按时间顺序指示。应当理解,为了简单起见,所示出示例示出了每个图的相同值,但是实际的制作功能谱2600可能对于每个图具有不同的时间序列值。
265.制作功能谱2600还可以包括情感空间指示符2420或其他情感状态数据,如参考图24a所描述的。
266.图17d示出了示例性情感音乐创作系统1600的第四部分1700d的过程之间的关系,包括改编过程2200。改编指的是一种过程,通过所述过程,音乐作品被安排用于以与最初指定的乐器或声音不同的乐器或声音演奏。因此,改编可以将现有的混音、录音或创作作为输入,并生成新的混音作为输出,所述新的混音用新元素代替输入中指定的一个或多个元素。在被称为―再混音”示例的第一示例中,输入可以是多曲目格式1774的现有曲目,即现有歌曲记录(诸如最终母带1770),其被格式化为使得每个乐器曲目与其他曲目分离(与立体声格式的曲目相反,在所述立体声格式中,各个乐器曲目被组合在一起成为左声道和右声道)。在下面描述的称为―新曲目”示例的第二示例中,子总线(即乐器曲目或乐器曲目的时间子片段)被用作原材料来组装现有乐谱的改编。
267.在再混音示例中,改编过程2200接收多曲目格式的现有曲目1774作为输入,将现有曲目1774分解成其组成子总线,并在不同的子总线中交换,以便改编现有曲目1774的歌曲,以满足由作为输入接收到的mir数据(这里示出为改编过程所需的mir数据1783)指定的特定情感反应标准。所需mir数据1783可以通过mir数据提取过程1782从mir蓝图1730中提取。在一些实施方案中,如在每个其他mir数据提取过程1756、1740中,可以省略mir数据提
取过程1782,并且所需mir数据1783可以只是mir蓝图1730的全部内容。
268.自适应音乐代理训练过程1772使用先前描述的音乐理论规则数据库2020来训练改编过程2200的自适应音乐代理2202,如下面参考图22a至图22b更详细描述的。
269.改编过程2200利用音频子总线库1776和乐器音色简档数据库1778来识别和选择要换入的子总线,以替换现有曲目1774的原始子总线。一旦换入了子总线以改编现有曲目1774来满足所需mir数据1783的mir特征,改编过程2200就输出新的混音作为改编后的初步混音1780,和/或输出混音模板1786,指示艺术家或制作人如何手动改编现有曲目1774来实现指定的mir特征,包括对期望的或所需的mir特征1783本身的指示。
270.用户1702然后与音乐制作过程1758交互,以生成改编后的最终混音1790。如同音乐创作过程1748,用户1702可以通过诸如数字音频工作站(daw)或其他音频工作站的用户界面1642与音乐制作过程1758交互。用户1702可以得到混音模板1786的帮助和/或可以开始与作为输入的改编后的初步混音1780的交互。
271.在一些示例中,改编过程2200可以在制作过程中使用:即,用户1702可以与音乐制作过程1758交互,以使得改编过程2200对已经达到改编阶段的人类创作的歌曲执行改编过程的一次或多次迭代。
272.图22a是示出改编过程2200的第一部分2200a的框图。改编过程2200可用于生成音乐曲目(称为―曲目”示例)或mir模板,以指导用户或另一系统生成曲目(称为―模板”示例)。在这些示例中的任一个示例中,正在生成的曲目或模板可以是现有曲目的再混音(称为―再混音”示例)或全新的曲目(称为―新曲目”示例)。在―再混音”示例中,改编过程2200开始于将现有曲目1774分割成其组成子总线(示出为子总线1 2204、子总线2 2206和子总线3 2208)。这些组成子总线2204、2206、2208通过使用上述mir提取或预测技术的mir提取或预测过程2210提取或预测它们的mir数据,从而为每个子总线生成相应的一组mir数据:子总线1的mir 2214、子总线2的mir 2216和子总线3的mir 2218。现有曲目的每个子总线的mir数据然后由现有子总线排序过程2220排序,这将在下面参考第二部分2200b进行描述。来自现有曲目1774的组成子总线也可以被添加到音频子总线库1776(未示出)。
273.图22b是示出改编过程2200的第二部分2200b的框图。现有子总线排序过程2220使用每个子总线2214、2216、2218的mir数据来识别现有曲目1774的哪些子总线与所需mir数据1783紧密匹配,并根据子总线2204、2206、2208与所需mir数据1783的相似性对它们进行排序。排序过程可以使用k最近邻向量相似性计算,如由madison schott,―k-nearest neighbors(knn)algorithm for machine learning”,at https://medium.com/capital-one-tech/k-nearest-neighbors-knn-algorithm-for-machine-learning-e883219c8f26所描述,其全部内容通过引用结合于此。子总线拒绝过程2222基于由现有子总线排序过程2220生成的排序和一组音乐理论规则来确定拒绝哪些子总线。在一些实施方案中,子总线拒绝过程2222可以在算法上执行(例如,通过使用音乐理论规则数据库2020(未示出)),而在其他实施方案中,所述子总线拒绝过程可以由人类制作人来执行。音乐理论规则的使用对于子总线拒绝过程2222是重要的,因为保留歌曲结构的基础的一些子总线可能是有意义的,即使所述子总线与mir蓝图1730(或所需mir数据1783)冲突也是如此。
274.未被拒绝的现有曲目1774的子总线(这里示出为子总线2 2206和子总线3 2208)被前馈到级联过程2236,所述级联过程将保留子总线(即未被拒绝的子总线)级联成立体声
混音。在―曲目”示例中,它们还被前馈以级联到最终再混音曲目的初步混音1780中,如下面参考第三部分2200c所描述。如前所述,进一步的mir提取或预测过程2238用于提取或预测由级联过程2236生成的立体声混音的mir特征,从而生成曲目mir数据2239。在―模板”示例中,从保留子总线提取的曲目mir数据2239被前馈以级联到最终再混音曲目的混音模板1786中,如下面参考第三部分2200c所描述。时期分离过程2244执行将曲目mir数据2239分离成曲目mir时期2250,每个时期的持续时间由原始曲目1774的部分的持续时间定义(如由诸如音乐理论规则的规则定义)。
275.除了向现有子总线排序过程2220提供输入之外,所需mir数据1783可以用于为现有曲目1774的再混音或者使用子总线库改编乐谱的新曲目而生成mir时期。在再混音示例中,所需mir数据1783基于被再混音的曲目的部分被分成时期(即,现有曲目1774的时期):所需mir数据1783被再混音mir分离过程2246分成时期,每个时期的持续时间由原始曲目1774的部分的持续时间定义。在―新曲目”示例中,新曲目mir分离过程2248将所需mir数据1783分成具有基于mir蓝图1730的部分(或所需mir数据1783)而不是现有曲目1774的部分(因为在此示例中没有现有曲目1774)的持续时间的时期。
276.下一阶段一次进行一个时期。每次一个时期地将每个曲目mir时期2250和每个对应的目标mir时期2252作为状态数据提供给自适应音乐代理2202,下面参考第三部分2200c进行描述。类似于图21a的短期奖励网络2120,短期奖励网络2260使用评价者2262将奖励函数应用于三个输入:来自先前时期的mir组合过程2251(下面描述)的输出、来自先前时期的目标mir时期2252,以及来自音乐理论规则数据库2020的音乐理论规则。评价者2262的奖励函数基于音乐理论规则2020被遵守的紧密程度以及目标mir时期2252与曲目mir时期2250匹配的程度来生成短期奖励2264。因此,作为生成时期n的输入而生成的短期奖励2264基于时期(n-1)的mir组合过程2251和目标mir时期2252。
277.图22c是示出改编过程2200的第三部分2200c的框图。状态-动作网络2270包括自适应音乐代理2202,所述自适应音乐代理被配置为响应于输入数据的每个时期(即,每个曲目mir时期2250、每个对应的目标mir时期2252和每个对应的短期奖励2264),为多个动作分支(示出为第一动作分支、第二动作分支、第三动作分支等等,直到第n动作分支,其中n可以是任何正整数)中的每个动作分支选择子总线。每个动作分支对应于混音中的一个层:即,通常是一个乐器层,诸如鼓、贝斯、吉他等。如果相应的乐器已经存在于从现有曲目1774保留子总线中,并且不需要额外的层,则可以省略分支。从由音频子总线库1776提供的可用子总线中选择每个动作分支的子总线。
278.在一些实施方案中,自适应音乐代理2202可以被实施为具有lstm的深度递归分支q学习网络,用于存储迄今为止所有时期采取的动作(即选择的子总线)。lstm记录来自一个或多个先前时间步长(例如,时期)的曲目的mir特征,在此表示为n个时间步长,即n个先前目标mir时期2252和n个先前曲目mir时期2250,并且向自适应音乐代理2202的策略提供这些先前mir特征的状态向量。自适应音乐代理2202的规划器接收此状态向量和短期奖励2264,以及先前采取的改编动作(即,为每个分支选择的子总线,如下所述),并且计划器相应地更新策略。使用来自先前改编会话的数据来训练规划器。使用强化学习来训练自适应音乐代理2202,其中音频子总线库1776定义动作空间,并且短期奖励2264和长期奖励2282(下面描述)提供奖励反馈。自适应音乐代理2202的时间步长可以对应于一个时期,诸如4小
节音乐。与mir生成器gan 1612、乐谱生成器gan 1616和母带处理代理2102一样,自适应音乐代理2202在所描述的实施方案中使用参与者-评价者行为进行强化学习和深度学习。在其他实施方案中,自适应音乐代理2202可以使用其他模型来实施,诸如基于模型的参与者评价者模型、a3c模型或任何其他合适的机器学习模型。
279.在―曲目”示例中,子总线级联过程2272级联由音频子总线库1776提供的所选子总线,以生成所生成的音频时期2274(即,当前时期的子总线混音),所述音频时期包括由自适应音乐代理2202选择的将在现有曲目的保留子总线上分层的新子总线(在―再混音”示例中),或者包括被选择来构成整个歌曲的新子总线(在―新曲目”示例中)。或者,在―模板”实例中,子总线级联过程2272使用乐器音色简档数据库1778来生成mir简档,以创建用于所生成的时期的所生成的时期模板2276,所述乐器音色简档数据库包括与用于创建新的曲目或再混合模板的不同乐器选择相关联的mir数据。所生成的时期模板2276包括所述时期的mir数据。
280.一旦生成了所生成的音频时期2274或所生成的时期模板2276,则在步骤2282将所生成的音频或模板的长度与曲目或模板的总期望长度进行比较(基于现有曲目1774的部分和/或所需mir数据1783)。如果已经达到期望长度,则所生成的时期模板2276被彼此组合,并且与原始曲目的保留子总线的mir数据(在第二部分2200b中示出为曲目mir数据2239)组合,以生成混音模板1786,或者所生成的音频时期2274被彼此组合,并且与原始曲目的保留子总线(在第二部分2200b中示出为子总线2 2206和子总线3 2208)组合,以生成改编后的初步混音1780。混音模板1786或改编后的初步混音1780也被提供给长期奖励网络2280(下面描述)以训练自适应音乐代理2202。如果提供了改编后的初步混音1780,则它首先通过mir提取过程2284提取、预测或查找其mir数据。如上所述,mir数据可以经由诸如mirtoolbox的工具提取,从先前提取的mir特征的表中引用(即,查找),或者使用输入原始音频并输出mir预测的模型来预测。提取的(或预测的,或查找的)mir数据然后被提供给长期奖励网络2280。然后,改编过程结束。在一些实施方案中,当正在生成当前曲目或模板时,迄今生成的整个曲目或模板(原始的和生成的子总线)可以被提供给长期奖励网络2280,以在改编过程完成之前训练自适应音乐代理2202。
281.如果在步骤2282,没有达到曲目或模板的总期望长度,则当前生成的音频时期2274或所生成的时期模板2276作为反馈被提供给mir组合过程2251。在―曲目”示例中,当前生成的音频时期2274首先通过mir提取过程2286来提取、预测或查找当前生成的音频时期2274的mir数据,如上所述,以生成对应于当前生成的音频时期2274的mir数据。在―再混音”示例中,mir组合过程2251将从原始曲目的保留子总线提取的mir(即,曲目mir数据2239)与反馈mir数据(来自mir提取过程2286或所生成的时期模板2276)组合,以生成时期的组合mir数据,包括保留子总线和新的子总线。此组合的mir数据被提供给评价者2262,以生成后续时期的短期奖励2264:因此,时期(n-1)的组合的mir数据与时期(n-1)的目标mir时期2252一起被提供给评价者2262,以生成自适应代理2202在选择时期(n)的子总线时使用的短期奖励2264。可以理解,在―新曲目”示例中,没有保留子总线,因为没有原始曲目被再混音。因此,mir组合过程2251的输出仅仅是从mir提取过程2286或所生成的时期模板2276接收到的反馈mir数据。
282.长期奖励网络2280包括将奖励函数应用于三个输入的评价者2278:所需mir数据
1783、来自音乐理论规则数据库2020的音乐理论规则,以及由mir提取块2284从改编后的初步混音1780提取的mir数据或者混音模板1786。奖励函数基于音乐理论规则和应用于整个改编曲目(或整个模板)的mir数据的所需mir数据1783生成长期奖励2282。
283.情感音乐推荐系统100和/或情感音乐创作系统1600,和/或其方面和部件,可以在各种配置中重新组合,以解决与选择或创建音乐相关的特定用例,从而在一个或多个听者中引发特定情感反应。这些用例可能涉及治疗、娱乐或生活方式应用。现在将参考图27至图30描述本文描述的示例性实施方案的几个示例性用例。
284.图27示出了使用本文描述的实施方案的示例性专辑再混音用例2700。客户2732(其是拥有现有歌曲专辑的艺术家)与制作人2734一起工作,以在解释情感创作过程和情绪框架(例如,情感的gems/russel circumplex模型)的数据数字化文档2738的帮助下为专辑的歌曲建立一组健康目标2736。制作人2734从客户2732接收当前专辑混音2702(即专辑中歌曲的混音),并将它们提供给mir提取过程2704,以将它们转换成mir数据。经训练的情感推断模型(诸如创作ainn 1800)被用来生成曲目2706的预测情感动态。预测情感动态2706被变换成歌曲的情绪动态的可视化2708。在步骤2710,客户端2732查看可视化2708,并选择要优化的第一曲目以及要由所选曲目引发的期望情感轨迹,从而提供曲目2712和情感目标2714(例如,期望情感轨迹)作为用例2700的后续过程的输入。将曲目2712的曲目mir数据2716作为第一输入提供给情感准确度模型2720(诸如mir生成过程1900)。对应于情感目标2714的mir蓝图1730被用作情感准确度模型2720的第二输入。情感准确度模型2720用于生成制作功能谱(诸如由情感音乐创作系统1600生成的制作功能谱2600)和标识需要改变的mir特征的mir蓝图,示出为文档2722,所述文档被工程师2724用来执行混音和母带处理过程(诸如经由情感音乐创作系统1600的音乐制作过程1758)以生成被配置为实现期望情感目标的所选曲目的最终母带2730。在此示例中,将母带处理技术应用于曲目的片段(例如,修改钢琴的音色),将环境曲目添加到混音以更好地满足mir目标,并将双耳夹音(2hz)添加到曲目。
285.图28示出了使用本文描述的实施方案以健康播放列表为目标的示例性音乐创作用例2800。使用与用例2700中相同的入职过程,但是在此示例中,目标建立步骤2836包括挑选播放列表(例如,现有在线音乐服务的播放列表)以针对客户2732的专辑的健康目标并对其进行策略化,选择曲目的情绪轨迹,并且识别所需的曲目长度和曲目数目。例如,选择怀旧曲目和宁静曲目来以―放松”播放列表为目标,选择两个―专注”曲目和一个忧郁曲目来以―悲伤节拍”播放列表为目标,所有这些曲目的持续时间都是3分钟+/-20秒。
286.通过使用创作系统1600的mir生成过程1900来生成曲目的mir蓝图1730,以开始每个所选曲目的创作。生成乐谱(例如,midi乐谱1742)和创作功能谱2400(例如,使用创作系统1600),并且制作人2734和客户2732可以通过根据mir蓝图1730改变各种参数,在所述过程的一次或多次额外迭代中细化乐谱1742和创作功能谱2400。举例来说,midi乐谱1742可被调整以提供与目标2836一致的曲目级和弦进行和旋律。
287.制作人2734和客户2732一起工作来生成各种曲目的初步混音1750。情感准确度模型2720使用初步混音1750和mir蓝图1730来生成改变和创建制作功能谱2600所需的音乐特征的数据集。制作人2734随后将混音技术(例如,使用音乐制作过程1758)应用于曲目,以更好地满足由制作功能谱设定的mir目标,从而生成一组最终混音1760。母带处理代理2102然
后可以用于执行最终混音1760的自动化母带处理,以生成最终母带1770。
288.图29示出了使用本文描述的实施方案来生成具有不同情感目标的多个专辑的示例性音乐集改编用例2900。客户2732是拥有现有歌曲集的艺术家,他想将所述歌曲作为三个专辑发行,每个专辑具有一组特定的情感目标。艺术家2732与制作人2734一起工作来设置目标2836,如在用例2800中。从客户2732接收曲目集2902,并将其提供给mir提取过程,如在用例2700中。用例2900作为每个曲目的用例2700继续进行,但是客户1732通常通过选择接近期望情感目标的曲目来选择多个曲目2712以在步骤2910处进行优化。
289.在数据数字化2836期间由客户1732选择的情感目标2714用于为每个曲目生成mir蓝图1730。每个曲目2712的曲目mir数据2716与每个曲目的mir蓝图1730一起被提供给情感准确度模型2720,以为每个曲目生成识别需要改变的音乐特征的制作功能谱2600。制作人2734使用制作功能谱2600来执行混音2912,所述混音的输出(例如,初步混音1760)被提供给母带处理代理2102,所述母带处理代理的输出由管理代理2914管理以生成最终母带1770。管理代理2914可以是来自情感音乐推荐系统100的深度q网络,所述深度q网络已经用创作ainn 1800进行了训练。
290.图30示出了示例性音乐改编用例3000,其使用本文描述的实施方案使用现有子总线库来生成情感音乐。客户1732提供未使用的子总线库1776,用于为专辑生成新歌曲。mir生成过程1900用于基于情感目标2714生成mir蓝图1730。自适应音乐代理2202利用子总线库1776来生成旨在匹配mir蓝图1730的所生成的曲目3002。在这个阶段,曲目3002可以与客户2732分享以供批准并提供添加额外元素的机会。然后,在2704,曲目3002被转换成mir数据,以生成曲目mir数据2716。情感准确度模型2720使用mir蓝图1730和曲目mir数据2716来生成曲目的制作功能谱2600。制作人2734执行混音2912,随后使用母带处理代理2102和管理代理2914来生成最终母带1770。
291.在一些实施方案中,代替上述音频数据和听觉刺激或除此之外,所描述的系统和方法可以使用非听觉刺激和非音频数据。在一些实施方案中,可以使用触觉或视觉数据使用类似于上述的技术来收集和预测用户对触觉或视觉刺激的情感反应。
292.在一些实施方案中,音频片段可以包括单耳或双耳节拍数据,或者单独地或者与其他听觉数据集成在一起。单耳和双耳节拍已经被证明具有在某些条件下在人类中引发特定情感反应的能力。参见例如chaieb等人的比较文学研究―auditory beat stimulation and its effects on cognition and mood states”,frontiers in psychiatry,vol.6,2015,https://www.frontiersin.org/article/10.3389/fpsyt.2015.00070,其全部内容通过引用结合于此。
293.尽管可以至少部分地根据方法和设备来描述本公开,但是本领域普通技术人员将理解,本公开还针对用于执行所描述的方法的至少一些方面和特征的各种部件,无论是通过硬件部件、软件还是两者的任意组合。因此,本公开的技术方案可以以软件产品的形式体现。合适的软件产品可以存储在预先记录的存储设备或其他类似的非易失性或非暂时性计算机或处理器可读介质中,包括例如dvd、cd-rom、usb闪存盘、可移动硬盘或其他存储介质。所述软件产品包括有形地存储在其上的指令,这些指令使得处理设备(例如,个人计算机、服务器或网络设备)能够执行本文公开的方法或系统的示例。
294.本领域技术人员还将理解,上述方法和设备的输出,即包括音频片段230本身的音
频流234,可以作为音乐数据(诸如音频文件)存储在存储介质上,所述存储介质诸如非易失性或非暂时性计算机或处理器可读介质,包括dvd、cd-rom、usb闪存盘、可移动硬盘或其他存储介质。音乐也可以存储在适合用于音频应用或音频回放或广播设备的其他数字或模拟存储介质上,诸如盒式磁带、黑胶唱片或用于数字或模拟音乐数据的任何其他存储介质。在一个实施方案中,音频流可以被识别为可能引发特定的情感轨迹,无论是用户特定的或者是用户独立的,并且此音频流可以被存储以供用户稍后收听。
295.在所描述的方法或框图中,框可以表示事件、步骤、功能、过程、模块、消息和/或基于状态的操作等。虽然以上示例中的一些示例已经被描述为以特定的顺序发生,但是本领域技术人员将会理解,一些步骤或过程可以以不同的顺序执行,只要任何给定步骤的顺序改变的结果不会阻止或损害后续步骤的发生。此外,在其他实施方案中,上述消息或步骤中的一些消息或步骤可以被去除或组合,并且在其他实施方案中,上述消息或步骤中的一些消息或步骤可以被分成多个子消息或子步骤。此外,根据需要,可以重复步骤中的一些或所有步骤。被描述为方法或步骤的元素类似地适用于系统或子部件,反之亦然。对诸如―发送”或―接收”这样的词的引用可以互换,这取决于特定设备的视角。
296.上述实施方案被认为是说明性的而非限制性的。被描述为方法的示例性实施方案将类似地应用于系统,反之亦然。
297.可以对一些示例性实施方案进行变型,这些变型可以包括上述组合和子组合中的任何组合和子组合。上面呈现的各种实施方案仅仅是示例,并不意味着限制本公开的范围。对于本领域普通技术人员来说,本文描述的创新的变型是显而易见的,此类变型在本公开的预期范围内。具体而言,可以选择来自一个或多个上述实施方案的特征来创建包括上面可能没有明确描述的特征的子组合的替代实施方案。此外,来自上述实施方案中的一个或多个实施方案的特征可以被选择和组合,以创建包括上面没有明确描述的特征的组合的替代实施方案。在阅读本公开作为整体时,适合于此类组合和子组合的特征对于本领域技术人员将是显而易见的。本文描述的主题旨在涵盖和包括技术中所有合适的变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1