并行化Tacotron:非自回归且可控的TTS的制作方法
本公开涉及并行化tacotron(parallel tacotron)非自回归且可控的文本到语音(tts)。
背景技术:
1、文本到语音(tts)系统向用户出声地阅读数字文本并且在移动设备上变得越来越流行。某些tts模型旨在合成语音的各个方面,诸如说话风格,以产生类似人的自然话语语音。tts模型中的合成是一对多映射问题,因为对于文本输入的不同原语可能存在多个可能的语音输出。许多tts系统利用基于先前值预测当前值的自回归模型。尽管自回归tts模型能够合成文本并且生成高度自然的语音输出,但是所需要的数百次计算降低推断期间的效率。
技术实现思路
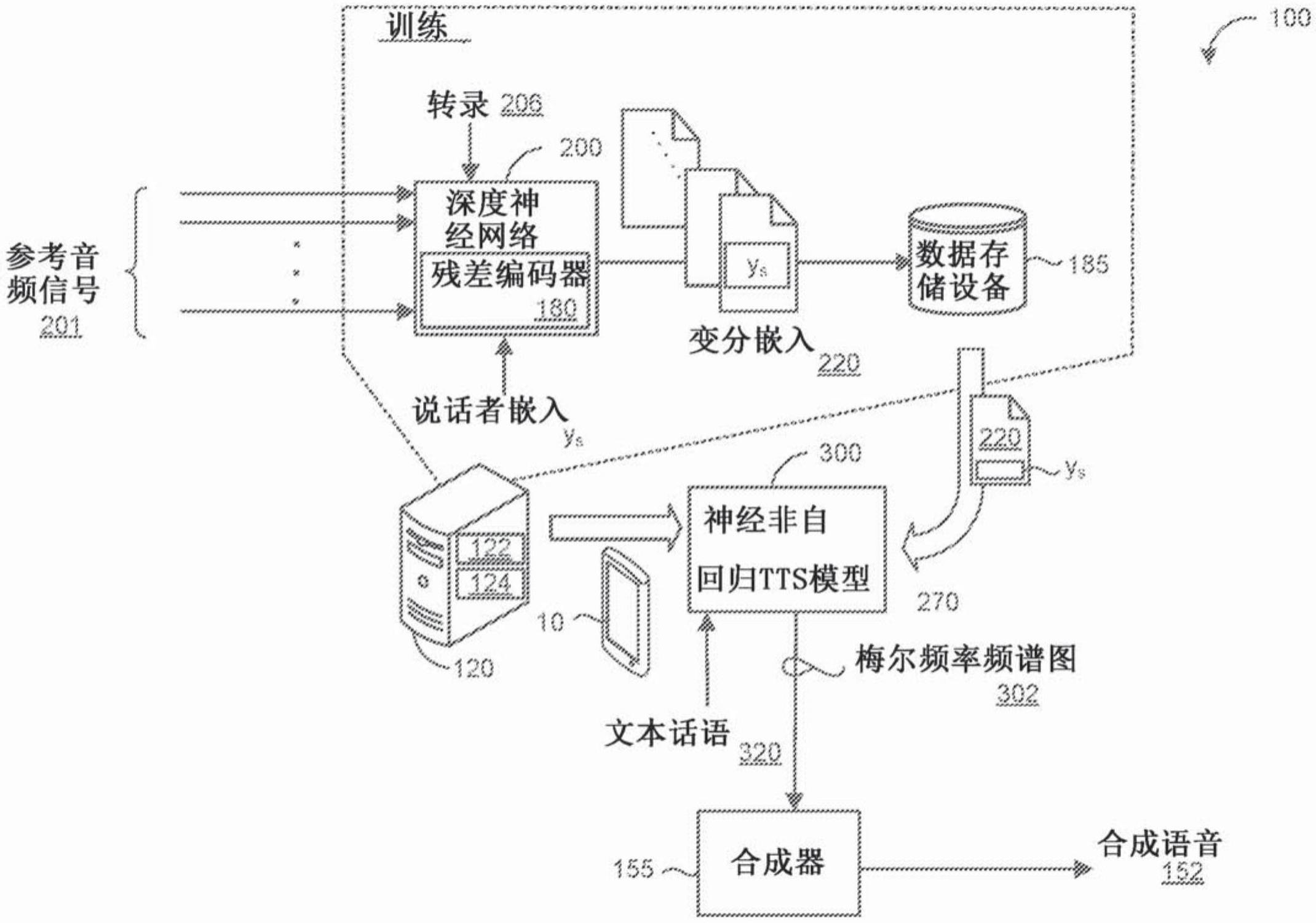
1、本公开的一个方面提供了一种计算机实现的方法,该方法当在数据处理硬件上执行时使数据处理硬件执行用于训练非自回归文本到语音(tts)模型的操作。该操作包括接收包括参考音频信号和对应输入文本序列的训练数据。该参考音频信号包括口头话语,并且输入文本序列对应于参考音频信号的转录。该操作还包括使用残差编码器将参考音频信号编码为变分嵌入,该变分嵌入从参考音频信号中分离(disentangle)风格/韵律信息,并且使用文本编码器将输入文本序列编码为编码文本序列。该操作还包括使用持续时间解码器并且基于编码文本序列和变分嵌入来针对输入文本序列中的每个音素预测音素持续时间。该操作还包括基于预测音素持续时间和来自用于输入文本序列中的每个音素的参考音频信号的参考音素持续时间来确定音素持续时间损失。该操作还包括:从包括自注意力块的堆栈的频谱图解码器并且基于持续时间解码器的输出来生成用于输入文本序列的一个或多个预测梅尔频率频谱图序列作为输出。该操作还包括基于一个或多个预测梅尔频率频谱图序列和从参考音频信号采样的参考梅尔频率频谱图序列来确定最终频谱图损失,并且基于该最终频谱图损失和针对输入文本序列中的每个音素确定的对应音素持续时间损失来训练tts模型。
2、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,自注意力块的堆栈中的每个自注意力块包括相同轻量级卷积(lconv)块。在其它实施方式中,自注意力块的堆栈中的每个自注意力块包括相同变换器(transformer)块。输入文本序列可以包括各自具有一个或多个音素的单词、所有单词边界处的静音、以及标点符号。
3、在一些示例中,残差编码器包括全局变分自动编码器(vae),并且将参考音频信号编码为变分嵌入包括:从参考音频信号中采样参考梅尔频率频谱图序列;使用全局vae将参考梅尔频谱图序列编码为变分嵌入。在一些实施方式中,残差编码器包括音素级细粒度变分自动编码器(vae),并且将参考音频信号编码为变分嵌入中包括:从参考音频信号中采样参考音频频谱图序列;将参考梅尔频率频谱图序列与从输入文本序列中提取的音素序列中的每个音素对齐;使用音素级细粒度vae基于将参考梅尔频率频谱图序列与音素序列中的每个音素对齐来对音素级变分嵌入的序列进行编码。
4、可选地,残差编码器可以包括轻量级卷积(lconv)块的堆栈,其中lconv块的堆栈中的每个lconv块包括:门线性单元(glu)层;lconv层,其被配置为接收glu层的输出;残差连接,其被配置为将lconv层的输出与glu层的输入进行级联;以及最终前馈层,其被配置为接收将lconv层的输出与glu层的输入进行级联的残差连接作为输入。该操作还可以包括使用从用于输入文本序列中的每个音素的参考音频信号中采样的参考音素持续时间将持续时间解码器的输出上采样为多个帧,并且获得表示用于输入文本话语中的每个音素的音素位置信息的位置嵌入。这里,生成用于输入文本序列的一个或多个预测梅尔频率频谱图序列基于位置嵌入和持续时间解码器的输出到多个帧的上采样。
5、在一些示例中,生成用于输入文本序列的一个或多个预测梅尔频率频谱图序列包括从频谱图解码器的自注意力块的堆栈中的每个自注意力块生成相应梅尔频率频谱图序列作为输出。在这些示例中,确定最终频谱图损失包括,针对每个相应预测梅尔频率频谱图序列,基于预测梅尔频率频谱图序列和参考梅尔频率频谱图序列来确定相应频谱图损失,以及聚合针对预测梅尔频率频谱图序列确定的相应频谱图损失以生成最终频谱图损失。在一些实施方式中,持续时间解码器包括自注意力块的堆栈,其后是两个独立投影,并且针对输入文本序列中的每个音素预测音素持续时间包括:使用在两个独立投影中的第一个投影之后的sigmoid激活来针对每个音素预测非零持续时间的概率;以及使用在两个独立投影中的第二个投影之后的softplus激活来针对每个音素预测音素持续时间。该操作还可以包括,在每个音素处,确定针对对应音素预测的非零持续时间的概率是否小于阈值,并且当非零持续时间的概率小于阈值时,将针对对应音素预测的音素持续时间调零。
6、在一些示例中,该操作还包括将编码文本序列、变分嵌入和表示发出参考音频信号的参考说话者的身份的参考说话者嵌入进行级联,以及基于持续时间解码器接收编码文本序列、变分嵌入和参考说话者嵌入的级联作为输入来生成持续时间解码器的输出。可选地,输入文本序列可以包括音素序列,并且将输入文本序列编码为编码文本序列包括:从音素查找表接收音素序列中的每个音素的相应嵌入;针对音素序列中的每个音素,使用文本编码器的编码器预网(encoder pre-net)神经网络处理相应嵌入以生成该音素的相应变换嵌入;使用一堆卷积块处理相应变换嵌入以生成卷积输出;以及使用自注意力块的堆栈处理卷积输出以生成编码文本序列。
7、本公开的另一方面提供了一种用于训练非自回归文本到语音(tts)模型的系统,该系统包括数据处理硬件和存储指令的存储器硬件,该指令在数据处理硬件上执行时使数据处理硬件执行操作。该操作包括接收包括参考音频信号和对应输入文本序列的训练数据。该参考音频信号包括口头话语,并且输入文本序列对应于参考音频信号的转录。该操作还包括使用残差编码器将参考音频信号编码为变分嵌入,该变分嵌入从参考音频信号中分离风格/韵律信息,并且使用文本编码器将输入文本序列编码为编码文本序列。该操作还包括使用持续时间解码器并且基于编码文本序列和变分嵌入来针对输入文本序列中的每个音素预测音素持续时间。该操作还包括基于预测音素持续时间和来自用于输入文本序列中的每个音素的参考音频信号的参考音素持续时间来确定音素持续时间损失。该操作还包括:从包括自注意力块的堆栈的频谱图解码器并且基于持续时间解码器的输出来生成用于输入文本序列的一个或多个预测梅尔频率频谱图序列作为输出。该操作还包括基于一个或多个预测梅尔频率频谱图序列和从参考音频信号采样的参考梅尔频率频谱图序列来确定最终频谱图损失,并且基于最终频谱图损失和针对输入文本序列中的每个音素确定的对应音素持续时间损失来训练tts模型。
8、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,自注意力块的堆栈中的每个自注意力块包括相同轻量级卷积(lconv)块。在其它实施方式中,自注意力块的堆栈中的每个自注意力块包括相同变换器块。输入文本序列可以包括各自具有一个或多个音素的单词、所有单词边界处的静音、以及标点符号。
9、在一些示例中,残留编码器包括全局变分自动编码器(vae),并且将参考音频信号编码为变分嵌入包括:从参考音频信号中采样参考梅尔频率频谱图序列;使用全局vae将参考梅尔频谱图序列编码为变分嵌入。在一些实施方式中,残差编码器包括音素级细粒度变分自动编码器(vae),并且将参考音频信号编码为变分嵌入中包括:从参考音频信号中采样参考音频频谱图序列;将参考梅尔频率频谱图序列与从输入文本序列中提取的音素序列中的每个音素对齐;使用音素级细粒度vae基于将参考梅尔频率频谱图序列与音素序列中的每个音素对齐来对音素级变分嵌入的序列进行编码。
10、可选地,残差编码器可以包括轻量级卷积(lconv)块的堆栈,其中lconv块的堆栈中的每个lconv块包括:门线性单元(glu)层;lconv层,其被配置为接收glu层的输出;残差连接,其被配置为将lconv层的输出与glu层的输入进行级联;以及最终前馈层,其被配置为接收将lconv层的输出与glu层的输入进行级联的残差连接作为输入。该操作还可以包括使用从用于输入文本序列中的每个音素的参考音频信号中采样的参考音素持续时间将持续时间解码器的输出上采样为多个帧,并且获得表示用于输入文本话语中的每个音素的音素位置信息的位置嵌入。这里,生成用于输入文本序列的一个或多个预测梅尔频率频谱图序列基于位置嵌入和持续时间解码器的输出到多个帧的上采样。
11、在一些示例中,生成用于输入文本序列的一个或多个预测梅尔频率频谱图序列包括从频谱图解码器的自注意力块的堆栈中的每个自注意力块生成相应梅尔频率频谱图序列作为输出。在这些示例中,确定最终频谱图损失包括,针对每个相应预测梅尔频率频谱图序列,基于预测梅尔频率频谱图序列和参考梅尔频率频谱图序列来确定相应频谱图损失,以及聚合针对预测梅尔频率频谱图序列所确定的相应频谱图损失以生成最终频谱图损失。在一些实施方式中,持续时间解码器包括自注意力块的堆栈,其后是两个独立投影,并且针对输入文本序列中的每个音素预测音素持续时间包括:使用在两个独立投影中的第一个投影之后的sigmoid激活来针对每个音素预测非零持续时间的概率;以及使用在两个独立投影中的第二个投影之后的softplus激活来针对每个音素预测音素持续时间。该操作还可以包括,在每个音素处,确定针对对应音素预测的非零持续时间的概率是否小于阈值,并且当非零持续时间的概率小于阈值时,将针对对应音素预测的音素持续时间调零。
12、在一些示例中,该操作还包括将编码文本序列、变分嵌入和表示发出参考音频信号的参考说话者的身份的参考说话者嵌入进行级联,以及基于持续时间解码器接收编码文本序列、变分嵌入和参考说话者嵌入的级联作为输入来生成持续时间解码器的输出。可选地,输入文本序列可以包括音素序列,并且将输入文本序列编码为编码文本序列包括:从音素查找表接收音素序列中的每个音素的相应嵌入;针对音素序列中的每个音素,使用文本编码器的编码器预网神经网络处理相应嵌入以生成该音素的相应变换嵌入;使用一堆卷积块处理相应变换嵌入以生成卷积输出;以及使用自注意力块的堆栈处理卷积输出以生成编码文本序列。
13、本公开的另一方面提供了一种计算机实现的方法,该方法当在数据处理硬件上执行时使数据处理硬件执行操作。该操作包括接收要被合成为语音的文本话语,并且使用非自回归tts模型的文本编码器将从文本话语提取的音素序列编码为编码文本序列。该操作还包括选择用于文本话语的变分嵌入,该变分嵌入指定用于将文本话语合成为语音的预期韵律/风格。针对音素序列中的每个音素,该操作还包括使用非自回归tts模型的持续时间解码器基于编码文本序列和所选择的变分嵌入来针对对应音素预测音素持续时间。该操作还包括:从包括自注意力块的堆栈的非自回归tts模型的频谱图解码器基于持续时间解码器的输出和预测音素持续时间生成用于文本话语的预测梅尔频率频谱图序列作为输出。预测梅尔频率频谱图序列具有由所选择的变分嵌入指定的预期韵律/风格。
14、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,所选择的变分嵌入包括从基于变分自动编码器(vae)的残差编码器采样的先前变分嵌入。该操作还可以包括使用合成器将预测梅尔频率频谱图序列转换为合成语音。在一些示例中,从文本话语中提取的编码文本序列中的音素序列包括:从音素查找表中接收音素序列中的每个音素的相应嵌入;针对音素序列中的每个音素,使用文本编码器的编码器预网神经网络处理相应嵌入以生成该音素的相应变换嵌入;使用一堆卷积块处理相应变换嵌入以生成卷积输出;并且使用自注意力块的堆栈处理卷积输出以生成编码文本序列。
15、可选地,频谱图解码器的自注意力块的堆栈中的每个自注意力块可以包括相同轻量级卷积(lconv)块或相同变换器块中的一个。在一些实施方式中,该操作还包括使用预测音素持续时间将持续时间解码器的输出上采样为多个帧并且获得表示音素序列中的每个音素的音素位置信息的位置嵌入。这里,生成用于文本话语的预测梅尔频率频谱图序列基于位置嵌入和持续时间解码器的输出到多个帧的上采样。该操作还可以包括将编码文本序列、所选择的变分嵌入和参考说话者嵌入进行级联,该参考说话者嵌入表示与所选择的变分嵌入相关联的参考说话者的标识,并且基于持续时间解码器接收编码文本序列、变分嵌入和参考说话者嵌入的级联作为输入来生成持续时间解码器的输出。
16、本发明的另一方面提供一种用于执行经训练的非自回归文本到语音(tts)模型的系统,该系统包括数据处理硬件和存储指令的存储器硬件,该指令当在数据处理硬件上执行时使数据处理硬件执行操作。该操作包括接收要被合成为语音的文本话语,并且使用非自回归tts模型的文本编码器将从文本话语提取的音素序列编码为编码文本序列。该操作还包括选择用于文本话语的变分嵌入,该变分嵌入指定用于将文本话语合成为语音的预期韵律/风格。针对音素序列中的每个音素,该操作还包括使用非自回归tts模型的持续时间解码器基于编码文本序列和所选择的变分嵌入来针对对应音素预测音素持续时间。该操作还包括:从包括自注意力块的堆栈的非自回归tts模型的频谱图解码器基于持续时间解码器的输出和预测音素持续时间生成用于文本话语的预测梅尔频率频谱图序列作为输出。预测梅尔频率频谱图序列具有由所选择的变分嵌入指定的预期韵律/风格。
17、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,所选择的变分嵌入包括从基于变分自动编码器(vae)的残差编码器采样的先前变分嵌入。该操作还可以包括使用合成器将预测梅尔频率频谱图序列转换为合成语音。在一些示例中,从文本话语中提取的编码文本序列中的音素序列包括:从音素查找表中接收音素序列中的每个音素的相应嵌入;针对音素序列中的每个音素,使用文本编码器的编码器预网神经网络处理相应嵌入以生成该音素的相应变换嵌入;使用一堆卷积块处理相应变换嵌入以生成卷积输出;并且使用自注意力块的堆栈处理卷积输出以生成编码文本序列。
18、可选地,频谱图解码器的自注意力块的堆栈中的每个自注意力块可以包括相同轻量级卷积(lconv)块或相同变换器块中的一个。在一些实施方式中,该操作还包括使用预测音素持续时间将持续时间解码器的输出上采样为多个帧并且获得表示音素序列中的每个音素的音素位置信息的位置嵌入。这里,生成用于文本话语的预测梅尔频率频谱图序列基于位置嵌入和持续时间解码器的输出到多个帧的上采样。该操作还可以包括将编码文本序列、所选择的变分嵌入和参考说话者嵌入进行级联,该参考说话者嵌入表示与所选择的变分嵌入相关联的参考说话者的身份,并且基于持续时间解码器接收编码文本序列、变分嵌入和参考说话者嵌入的级联作为输入来生成持续时间解码器的输出。
19、本公开的一个或多个实施方式的细节在附图和以下描述中阐述。从描述和附图以及从权利要求中,其他方面、特征和优点将是显而易见的。
- 还没有人留言评论。精彩留言会获得点赞!