使用真实世界噪声的语音个性化和联合训练的制作方法
本公开涉及使用真实世界噪声的语音个性化和联合训练。
背景技术:
1、自动语音识别(asr)是在移动设备和其他设备中使用的重要技术。一般来说,自动语音识别会尝试提供一个人已说内容的准确转录。实施asr的设备还可以使用热词或唤醒词,所述热词或唤醒词帮助辨别给定话语何时针对系统,而不是针对环境中存在的另一个人的话语。
2、asr系统面临的一个主要挑战是单个模型需要能够处置来自其中跨不同用户在口音、词汇和背景噪声类型方面存在巨大差异的单个场所中所有用户的语音输入。对于个性化语音识别模型的另一个挑战是需要准确的转录来标记音频数据,这使得在用户设备上从头开始训练整个语音识别模型变得不可行。
技术实现思路
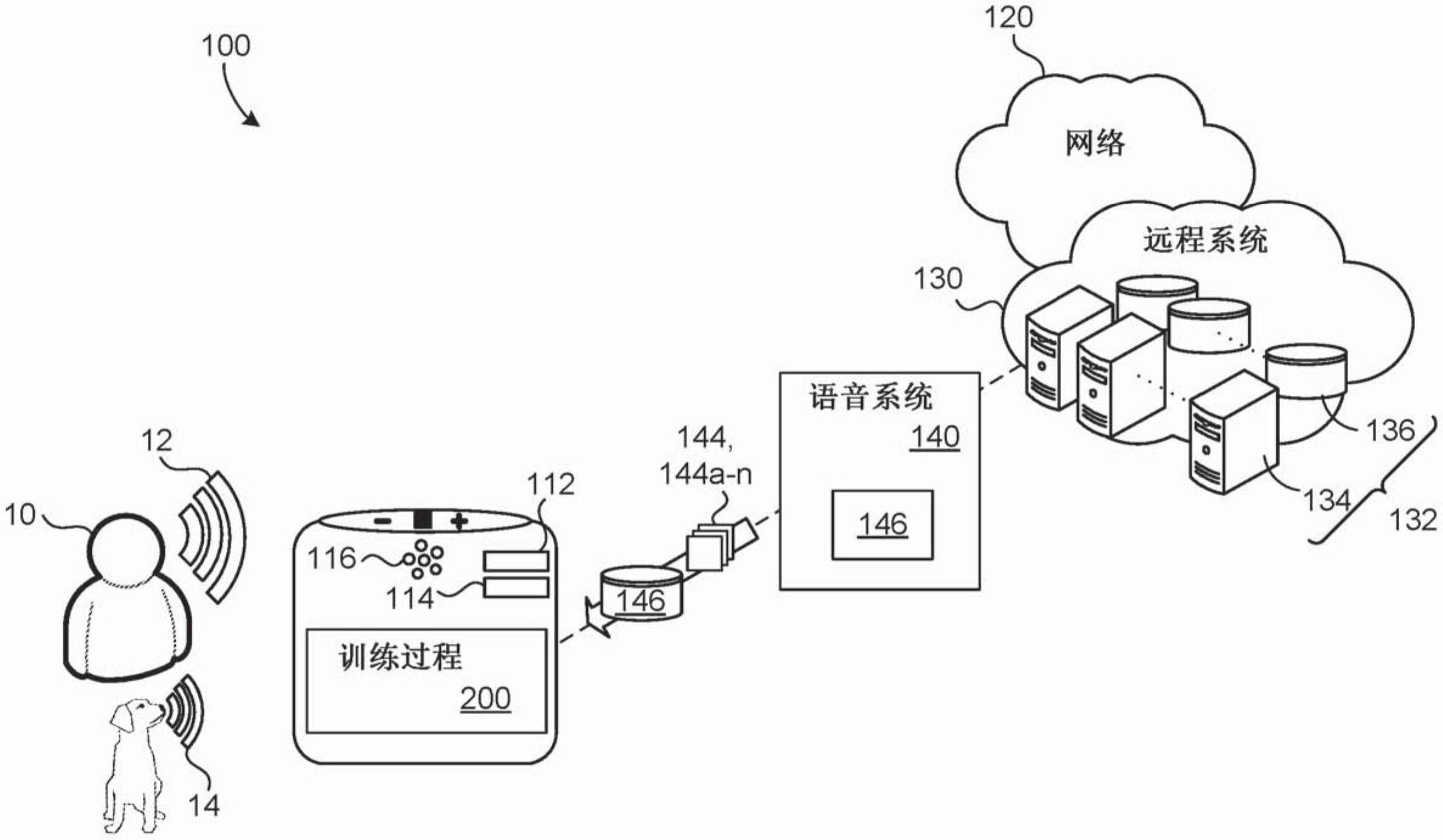
1、本公开的一个方面提供了一种训练语音模型的方法。该方法包括在启用话音的设备的数据处理硬件处接收训练话语的固定集合,其中,训练话语的固定集合中的每个训练话语包括与对应训练话语的对应语音表示配对的对应转录。该方法还包括由数据处理硬件从启用话音的设备的环境中采样带噪声音频数据。对于训练话语的固定集合中的每个训练话语,该方法包括:由数据处理硬件使用从启用话音的设备的环境中采样的带噪声音频数据增强对应训练话语的对应语音表示以生成一个或多个对应的带噪声音频样本;以及,由数据处理硬件将一个或多个对应的带噪声音频样本中的每个与对应训练话语的对应转录配对。该方法还包括由数据处理硬件在为训练话语的固定集合中的每个语音表示生成的一个或多个对应的带噪声音频样本上训练语音模型。
2、在一些示例中,该方法还包括,在增强对应训练话语的对应语音表示之前,由数据处理硬件对于对应语音表示去噪,以去除任何先前存在的噪声。在一些实施方式中,该方法进一步包括,在将一个或多个对应的带噪声音频样本中的每个与对应训练话语的对应转录配对之后,由数据处理硬件在与数据处理硬件通信的存储器硬件上存储一个或多个对应带噪声样本中的每个与对应训练话语的对应转录的配对。
3、在一些配置中,当语音模型包括语音识别模型时,该方法还包括,对于训练话语的固定集合中的每个语音表示和为对应语音表示生成的一个或多个带噪声音频样本的每个带噪声音频样本,由数据处理硬件确定在对应语音表示或对应带噪声音频样本的可能语音识别假设上的对应概率分布以由语音模型输出;以及,由数据处理硬件基于在对应语音表示或对应带噪声音频样本的可能语音识别假设上的对应概率分布来生成损失项。在这些配置中,训练语音模型可以包括使用为训练话语的固定集合中的每个语音表示和为训练话语的固定集合中的每个对应语音表示生成的一个或多个带噪声音频样本的每个带噪声音频样本生成的损失项来更新语音识别模型的参数。训练语音模型可以附加地或备选地包括向中央服务器传输为训练话语的固定集合中的每个语音表示和为训练话语的固定集合中的每个对应语音表示生成的一个或多个带噪声音频样本中的每个带噪声音频样本生成的损失项。中央服务器可以被配置为使用联合学习来基于下述部分更新服务器端语音识别模型的参数:从启用话音的设备的数据处理硬件接收到的损失项;以及,从其他启用话音的设备接收的其他损失项,其中,其他损失项基于由对应的其他启用话音的设备采样的不同带噪声音频数据从每个其他启用话音的设备接收。
4、在一些示例中,对于训练话语的固定集合中的至少一个训练话语,该方法还包括:由数据处理硬件获取从启用话音的设备的环境中采样的对应口述话语,该对应口述话语在发音上类似于对应训练话语的对应语音表示并且与相应转录配对,所述相应转录不同于与至少一个训练话语的对应语音表示配对的对应转录。在这些示例中,在训练话语的固定集合和一个或多个对应的带噪声音频样本上训练语音模型进一步基于为训练话语的固定集合中的至少一个训练话语获取的对应的口述话语。为训练话语的固定集合中的至少一个训练话语获取对应口述话语可以包括:从启用话音的设备的环境中采样对应口述话语;基于为对应口述话语生成的相应嵌入和为至少一个训练话语的对应语音表示生成的相应嵌入的比较,确定从环境采样的对应口述话语在发音上类似于至少一个对应训练话语的对应语音表示;获取从启用话音的设备的环境中采样的对应口述话语的相应转录;以及,确定对应口述话语的相应转录不同于与至少一个训练话语的对应语音表示配对的对应转录。嵌入模型或语音模型的一部分可以为对应口述话语和至少一个训练话语的对应语音表示中的每个生成相应嵌入。在这些示例中,至少一个训练话语的对应语音表示表示特定固定词项的口述表示。语音模型可以包括被训练以检测特定固定词项的热词检测模型。对于热词检测模型,训练热词检测模型以检测特定固定词项包括使用针对至少一个训练话语获取的对应口述话语作为负训练样本。
5、本公开的另一方面提供了一种用于训练语音模型的系统。该系统包括数据处理硬件和与数据处理硬件通信的存储器硬件。存储器硬件存储指令,该指令当在数据处理硬件上执行时使数据处理硬件执行操作。这些操作包括在启用话音的设备处接收训练话语的固定集合,其中,训练话语的固定集合中的每个训练话语包括与对应训练话语的对应语音表示配对的对应转录。这些操作还包括从启用话音的设备的环境中采样带噪声音频数据。对于训练话语的固定集合中的每个训练话语,该操作包括:使用从启用话音的设备的环境中采样的带噪声音频数据增强对应训练话语的对应语音表示以生成一个或多个对应带噪声音频样本;以及,将一个或多个对应的带噪声音频样本中的每个与对应训练话语的对应转录配对。该操作还包括在为训练话语的固定集合中的每个语音表示生成的一个或多个对应的带噪声音频样本上训练语音模型。该方面可以包括以下可选特征中的一个或多个。
6、在一些示例中,该操作还包括,在增强对应训练话语的对应语音表示之前,对于对应语音表示去噪,以去除任何先前存在的噪声。在一些实施方式中,该操作进一步包括,在将一个或多个对应的带噪声音频样本中的每个与对应训练话语的对应转录配对之后,在与数据处理硬件通信的存储器硬件上存储一个或多个对应带噪声样本中的每个与对应训练话语的对应转录的配对。
7、在一些配置中,当语音模型包括语音识别模型时,该操作还包括,对于训练话语的固定集合中的每个语音表示和为对应语音表示生成的一个或多个带噪声音频样本的每个带噪声音频样本,确定在对应语音表示或对应带噪声音频样本的可能语音识别假设上的对应概率分布以由语音模型输出;以及,基于在对应语音表示或对应带噪声音频样本的可能语音识别假设上的对应概率分布来生成损失项。在这些配置中,训练语音模型可以包括使用为训练话语的固定集合中的每个语音表示和为训练话语的固定集合中的每个对应语音表示生成的一个或多个带噪声音频样本的每个带噪声音频样本生成的损失项来更新语音识别模型的参数。训练语音模型可以附加地或备选地包括向中央服务器传输为训练话语的固定集合中的每个语音表示和为训练话语的固定集合中的每个对应语音表示生成的一个或多个带噪声音频样本中的每个带噪声音频样本生成的损失项。中央服务器可以被配置为使用联合学习来基于下述部分更新服务器端语音识别模型的参数:从启用话音的设备的数据处理硬件接收到的损失项;以及,从其他启用话音的设备接收的其他损失项,其中,其他损失项基于由对应的其他启用话音的设备采样的不同带噪声音频数据从每个其他启用话音的设备接收。
8、在一些示例中,对于训练话语的固定集合中的至少一个训练话语,该操作还包括:获取从启用话音的设备的环境中采样的对应口述话语,该对应口述话语在发音上类似于对应训练话语的对应语音表示并且与相应转录配对,所述相应转录不同于与至少一个训练话语的对应语音表示配对的对应转录。在这些示例中,在训练话语的固定集合和一个或多个对应的带噪声音频样本上训练语音模型进一步基于为训练话语的固定集合中的至少一个训练话语获取的对应的口述话语。为训练话语的固定集合中的至少一个训练话语获取对应口述话语可以包括:从启用话音的设备的环境中采样对应口述话语;基于为对应口述话语生成的相应嵌入和为至少一个训练话语的对应语音表示生成的相应嵌入的比较,确定从环境采样的对应口述话语在发音上类似于至少一个对应训练话语的对应语音表示;获取从启用话音的设备的环境中采样的对应口述话语的相应转录;以及,确定对应口述话语的相应转录不同于与至少一个训练话语的对应语音表示配对的对应转录。嵌入模型或语音模型的一部分可以为对应口述话语和至少一个训练话语的对应语音表示中的每个生成相应嵌入。在这些示例中,至少一个训练话语的对应语音表示表示特定固定词项的口述表示。语音模型可以包括被训练以检测特定固定词项的热词检测模型。对于热词检测模型,训练热词检测模型以检测特定固定词项包括使用针对至少一个训练话语获取的对应口述话语作为负训练样本。
9、该系统或方法的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,从启用话音的设备的环境中采样带噪声音频数据包括:在启用话音的设备和与启用话音的设备相关联的用户之间的语音交互紧前、期间或紧后中的至少一个,从启用话音的设备的环境中随机采样噪声。在其他实施方式中,从启用话音的设备的环境中采样带噪声音频数据包括:获取启用话音的设备的用户频繁与启用话音的设备交互的场境和/或时间窗口;以及,在所获取的启用话音的设备的用户频繁与启用话音的设备交互的场境和/或时间窗口期间从启用话音的设备的环境中采样带噪声音频数据。在又一些实施方式中,从启用话音的设备的环境中采样带噪声音频数据包括:全天从启用话音的设备的环境中随机采样带噪声音频数据;以及,将权重应用于在启用话音的用户更频繁与启用话音的设备交互的场境和/或时间窗口期间从环境采样的任何带噪声音频数据。数据处理硬件的数字信号处理器(dsp)可以从启用话音的设备的环境中采样带噪声音频数据。在一些示例中,至少一个训练话语的对应语音表示包括对应训练话语的原始音频波形。在其他示例中,至少一个训练话语的对应语音表示包括对应训练话语的音频特征表示。
10、本公开的一个或多个实施方式的细节在附图和下面的描述中阐述。其他方面、特征和优点将从描述和附图以及权利要求中显而易见。
- 还没有人留言评论。精彩留言会获得点赞!