一种车用主动声音合成方法与流程
1.本发明属于车辆主动声音技术领域,特别涉及一种车用主动声音合成方法。
背景技术:
2.传统汽车由于电子控制系统普及水平的不足和技术实现条件的限制,车载设备的提示音和警示音,多是通过仪器仪表的本身的简易蜂鸣、机械继电器等装置发出的简单机械的声音,现阶段随着用户消费的升级,主机厂及设计单位对整车声品质要求的进一步提升,传统的仪器仪表的简单机械的提示声音,已经不能满足要求,现阶段对声音的设计和评价以声品质的改善,提出了新的要求;整车声品质设计,也成为了现阶段整车设计的关键设计要素。
3.为改善声品质,现有的方法是将声音切成小片段后,再进行平滑处理,这样得到的声音容易出现断层,听感不佳。同时,现在的设计的声音以引擎声或排气声增强为主的合成音,声音风格不够丰富且趣味性低。
技术实现要素:
4.针对现有技术存在的上述不足,本发明的目的就在于提供一种车用主动声音合成方法,该方法合成的声音连贯性好,听感佳且自然真实,同时风格类型多,有利于提高声品质。
5.本发明的技术方案是这样实现的:一种车用主动声音合成方法,包括以下步骤:s1:获取车辆对目标车型的声音需求,然后采集目标车型实车在不同工况下的所有声音;s2:对s1中采集的所有声音进行分析,并提取所有声音的阶次声音特性,然后对阶次声音特征进行增强或削弱,以得到若干声音方案,并选取符合车辆风格的声音方案作为合成声音;s3:对s2得到的合成声音进行声音参数化处理,从而得到声音参数化acu文件;s4:获取车辆的转速、车速和油门踏板开度,并将车辆的转速、车速和油门踏板开度参数初始化为算法可识别的参数;s5:构建声音参数化acd文件与车辆转速、车速和油门踏板开度参数一一对应的声音数据库;s6:将s5中的声音数据库植入整车中,在车辆运行过程中,车辆输出的转速、车速和油门踏板开度参数信号与声音数据库内的声音参数化acd文件进行匹配,然后实时将对应的声音参数化acd文件还原为音频流,并驱动车辆扬声器发出。
6.进一步地,所述工况包括但不限于wot、pot、cruise coastdown。
7.进一步地,s2中合成声音中具有多种风格声音类型,具体地,抓取多种风格声音类型的阶次声音特征与抓取得到的目标车型不同工况下声音的阶次声音特征进行耦合,合成
得到具有多种风格声音的合成声音。
8.进一步对,所述多种风格声音类型包括但不限于科技、运动、田园、静谧、休闲。
9.进一步地,s2中,提取所有声音的阶次声音特征后,对声品质有害的声音频率段和阶次声音进行局部优化,保证最终声音的连贯性。
10.进一步地,s2中通过若干评价因素主观选取符合车辆风格的声音方案作为合成声音。
11.进一步地,评价因素包括但不限于频率成分、声音响度、声音连贯性和声音风格。
12.进一步地,s6车辆发出的声音为合成声音发出的声音或车辆固有的声音和合成声音协同发出的声音。
13.与现有技术相比,本发明具有如下有益效果:1、本发明通过采集目标车型不同工况下的声音,并提取声音中的阶次声音进行分析及参数化,使得合成的声音连贯性好,听感佳且自然真实。
14.2、本发明可以通过将不同阶次特点的声音进行耦合,合成具有科技、运动、田园、静谧、休闲等多种风格的声音,并且在实际应用时刻根据用户需求进行定制,相对于传统的引擎声和排气声,丰富了声音风格类型,提高了声音的趣味性。
附图说明
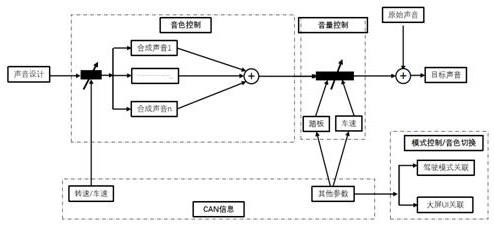
15.图1-本发明声音处理的硬件框架图。
16.图2-本发明声音处理的流程图。
17.图3-声浪增强前后的示意图。
具体实施方式
18.下面结合附图和具体实施方式对本发明作进一步详细说明。
19.一种车用主动声音合成方法,包括以下步骤:s1:获取车辆对目标车型的声音需求,然后采集目标车型实车在不同工况下的所有声音;s2:对s1中采集的所有声音进行分析,并提取所有声音的阶次声音特性,然后对阶次声音特征进行增强或削弱,以得到若干声音方案,并选取符合车辆风格的声音方案作为合成声音;s3:对s2得到的合成声音进行声音参数化处理,从而得到声音参数化acu文件;这里的acu文件是通过pc端软件,以二进制的形式将声音数据化,将所有的二进制数据写入一个文件所形成的一个文件。
20.s4:获取车辆的转速、车速和油门踏板开度,并将车辆的转速、车速和油门踏板开度参数初始化为算法可识别的参数;车辆的转速、车速和油门踏板开度等在算法前端输入具体算法中,从而得到算法可以识别的参数。
21.s5:构建声音参数化acd文件与车辆转速、车速和油门踏板开度参数一一对应的声音数据库;这样车速与声音、转速与声音、油门开度和声音都有各自对应的声音数据库。
22.s6:将s5中的声音数据库植入整车中,在车辆运行过程中,车辆输出的转速、车速和油门踏板开度参数信号与声音数据库内的声音参数化acd文件进行匹配,然后实时将对应的声音参数化acd文件还原为音频流,并驱动车辆扬声器发出。
23.不同车型的车辆,车辆发出的声音是不相同的,这样,当四缸发动机的车型想拥有六缸或者八缸车型的声音,以提升整车动力感的时候,可以采集六缸或者八缸车型的声音来进行设计,从而获得目标车型的声音。同时同一车辆,当车速、转速和油门踏板开度等参数发生变化,车辆的声音在车内的表现是不一致的,例如在不同的车速下,发动机声音由于转速的变化,会出现发动机声音在车内突变的现象,无论是从低变高还是从高变低,都会给司乘人员不好的感受。这里就可以采用nvh方法通过车内信号的采集与分析,找出这些不好的声音特性,通过声音补偿或者平滑处理等方式,将分析的结果运用在声浪设计上,以此来达到在该工况下改善目标声音的效果。
24.这样,将车辆的车速、转速和油门踏板开度等和合成声音相关联,当车辆车速、转速和油门踏板开度任意一参数发生变化时,其声音随之发生变化,使得声音和车辆运行工况保持一致性,以此提高声品质。
25.这里,将软件算法生成的声音参数化acu文件植入到包含声音还原算法的声音处理控制器中,并将声音处理控制器植入整车;通过获取整车的can激励,声音处理控制器通过声音还原算法,将声音参数化acu文件还原为音频流,然后驱动扬声器使车辆可发出已设计的声音。其声音处理的硬件结构框架图和流程图分别如图1和图2所示。图2中其他参数指后续因算法的优化可能扩展的信号。
26.图3为声音声浪增强前后的示意图,图3的左图为原始声音,图3的右图为增强后的声音。
27.具体实施时,所述工况包括但不限于wot、pot、cruise coastdown。
28.具体实施时,s2中合成声音中具有多种风格声音类型,具体地,抓取多种风格声音类型的阶次声音特征与抓取得到的目标车型不同工况下声音的阶次声音特征进行耦合,合成得到具有多种风格声音的合成声音。
29.具体实施时,所述多种风格声音类型包括但不限于科技、运动、田园、静谧、休闲。
30.这样,在设计声音前,预先对不同风格类型的声音进行采集,然后将不同风格的声音的阶次信息和目标车型采集得到的阶次声音进行耦合,就可以合成具有科技、运动、田园、静谧、休闲等多种风格的声音,并且在实际应用时刻根据用户需求进行定制,相对于传统的引擎声和排气声,有利于丰富声音风格类型,提高声音的趣味性。
31.具体实施时,s2中,提取所有声音的阶次声音特征后,对声品质有害的声音频率段和阶次声音进行局部优化,保证最终声音的连贯性。
32.具体实施时,s2中通过若干评价因素主观选取符合车辆风格的声音方案作为合成声音。
33.具体实施时,评价因素包括但不限于频率成分、声音响度、声音的连贯性和声音风格。
34.对合成声音进行评价,主要是使声音能符合的车型的风格,保持声音和车型风格的一致性,能有效的通过合成声音提升车辆的声音品质。
35.具体实施时,s6车辆发出的声音为合成声音发出的声音或车辆固有的声音和合成
声音协同发出的声音。
36.最后需要说明的是,本发明的上述实施例仅是为说明本发明所作的举例,而并非是对本发明实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化和变动。这里无法对所有的实施方式予以穷举。凡是属于本发明的技术方案所引申出的显而易见的变化或变动仍处于本发明的保护范围之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1