一种基于机器学习的单声道角色识别方法和系统与流程
1.本发明涉及语音识别领域,特别是指一种基于机器学习的单声道角色识别方法和系统。
背景技术:
2.asr(自动语音识别技术)是一种将人的语言转换为文本的技术,识别过程中涉及到角色识别的概念,如果是双声道可支持对应声道准确的角色分离进行识别,将a、b角色的录音进行文字转换,如果是单声道则会根据音色的不同通过技术去进行角色的拆分,但是单声道的拆分出来的结果无法区分出业务上的业务角色和客户角色,导致进行业务逻辑处理的时候无法准确识别出来而影响业务质检等。
技术实现要素:
3.本发明的主要目的在于克服现有技术中的上述缺陷,提出一种基于机器学习的单声道角色识别方法,通过建立不同场景建立不同模型,针对单声道的录音识别结果进行模型识别处理,准确的识别出坐席测和客户侧。
4.本发明采用如下技术方案:
5.一种基于机器学习的单声道角色识别方法,包括如下步骤:
6.利用实时自动语音识别对单声道的语音数据进行识别,得到单角色语音对应的文本数据;
7.对文本数据进行文本分词、关键词提取,得到特征向量;所述关键词至少包括身份关键词、目的关键词和诉求关键词;
8.根据语音特征向量输入到不同的角色识别模型,所述角色识别模型包括客服场景模型、贷后场景模型、电销场景模型;
9.通过模型识别出坐席侧和客户侧。
10.具体地,还包括通过监督性学习对角色识别模型进行完善,具体包括:
11.采用文字匹配和正则表达进行角色识别模型的应用,得出客户方和坐席方的概率分数,取最大的概率分;
12.收集人工复检后进行角色更换的数据进行人工打标;
13.打完标签后数据进行录入模型,实现角色识别模型的完善。
14.具体地,实时自动语音识别对单声道的语音数据进行识别,具体包括:
15.获取语音输入的波形声音,并通过移动窗函数对声音进行切段分帧得到不同的声音帧段,
16.通过提取梅尔频率倒谱系数特征,将波形转换为观察序列矩阵,输入预先训练好的语音识别模型,得到可能的文本集合,从中寻找全局最优路径,将矩阵转为最终的文本。
17.具体地,对文本数据进行文本分词、关键词提取,具体包括:
18.文本分词,基于前缀词典进行扫描,生成句子文字所有可能成词所构成的有向无
环图,通过动态规划查找最大概率路径,得到基于词频的最大切分组合;对于前缀词典中不包含的词语,采用隐马尔科夫模型对词语进行预测,并在结巴分词算法基础上,结合预先建立的角色识别词典,对文本内容进行分词处理,根据最大切分组合,得到分词结果;
19.关键词提取,根据分词结果计算词语的词频-逆文档频率,将词频-逆文档频率与预先建立的词语的权重列表结合,提取权重占比大的词语,得到关键词,组成特征向量。
20.本发明另一方面还包括一种基于机器学习的单声道角色识别系统,包括:
21.语音识别单元:利用实时自动语音识别对单声道的语音数据进行识别,得到单角色语音对应的文本数据;
22.特征向量获取单元:对文本数据进行文本分词、关键词提取,得到特征向量;所述关键词至少包括身份关键词、目的关键词和诉求关键词;
23.模型输入单元:根据语音特征向量输入到不同的角色识别模型,所述角色识别模型包括客服场景模型、贷后场景模型、电销场景模型;
24.角色识别单元:通过模型识别出坐席侧和客户侧。
25.具体地,还包括模型完善单元,通过监督性学习对角色识别模型进行完善,具体包括:
26.采用文字匹配和正则表达进行角色识别模型的应用,得出客户方和坐席方的概率分数,取最大的概率分;
27.收集人工复检后进行角色更换的数据进行人工打标;
28.打完标签后数据进行录入模型,实现角色识别模型的完善。
29.具体地,所述语音识别单元中,实时自动语音识别对单声道的语音数据进行识别,具体包括:
30.获取语音输入的波形声音,并通过移动窗函数对声音进行切段分帧得到不同的声音帧段,
31.通过提取梅尔频率倒谱系数特征,将波形转换为观察序列矩阵,输入预先训练好的语音识别模型,得到可能的文本集合,从中寻找全局最优路径,将矩阵转为最终的文本。
32.具体地,所述特征向量获取单元中,对文本数据进行文本分词、关键词提取,具体包括:
33.文本分词,基于前缀词典进行扫描,生成句子文字所有可能成词所构成的有向无环图,通过动态规划查找最大概率路径,得到基于词频的最大切分组合;对于前缀词典中不包含的词语,采用隐马尔科夫模型对词语进行预测,并在结巴分词算法基础上,结合预先建立的角色识别词典,对文本内容进行分词处理,根据最大切分组合,得到分词结果;
34.关键词提取,根据分词结果计算词语的词频-逆文档频率,将词频-逆文档频率与预先建立的词语的权重列表结合,提取权重占比大的词语,得到关键词,组成特征向量。
35.本发明再一方面提供一种基于机器学习的单声道角色识别设备,包括:
36.至少一个处理器;以及,
37.与所述至少一个处理器通信连接的存储器;其中,
38.所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够:
39.利用实时自动语音识别对单声道的语音数据进行识别,得到单角色语音对应的文
本数据;
40.对文本数据进行文本分词、关键词提取,得到特征向量;所述关键词至少包括身份关键词、目的关键词和诉求关键词;
41.根据语音特征向量输入到不同的角色识别模型,所述角色识别模型包括客服场景模型、贷后场景模型、电销场景模型;
42.通过模型识别出坐席侧和客户侧。
43.本发明又一方面提供一种计算机可读存储介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现上述一种基于机器学习的单声道角色识别。
44.由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
45.本发明提供了一种基于机器学习的单声道角色识别方法,利用实时自动语音识别对单声道的语音数据进行识别,得到单角色语音对应的文本数据;对文本数据进行文本分词、关键词提取,得到特征向量;所述关键词至少包括身份关键词、目的关键词和诉求关键词;根据语音特征向量输入到不同的角色识别模型,所述角色识别模型包括客服场景模型、贷后场景模型、电销场景模型;通过模型识别出坐席侧和客户侧;本发明提供的方法,能够通过建立不同场景建立不同模型,针对单声道的录音识别结果进行模型识别处理,准确的识别出坐席测和客户侧。
附图说明
46.图1为本发明实施例提出的一种基于机器学习的单声道角色识别方法流程图;
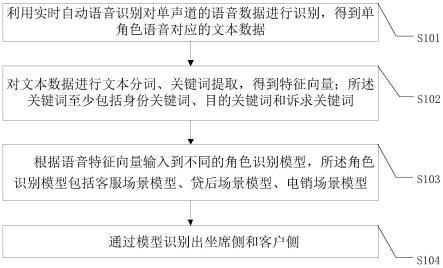
47.图2为本发明实施例提供的一种基于机器学习的单声道角色识别系统结构图;
48.图3为本发明实施例提供的一种电子设备的实施例示意图;
49.图4为本发明实施例提供的一种计算机可读存储介质的实施例示意图。
50.以下结合附图和具体实施例对本发明作进一步详述。
具体实施方式
51.本发明提供了一种基于机器学习的单声道角色识别方法,能够通过建立不同场景建立不同模型,针对单声道的录音识别结果进行模型识别处理,准确的识别出坐席测和客户侧。
52.如图1,为本发明实施例提出的一种基于机器学习的单声道角色识别方法流程图,包括如下步骤:
53.s101:利用实时自动语音识别对单声道的语音数据进行识别,得到单角色语音对应的文本数据;
54.首先获得语音识别所需要的模型,即对预先获取的大量语音输入并预处理,提取语音的特征,在此基础上建立语音识别所需的模型(此为训练过程),其次当计算机在新语音识别过程中,要根据语音识别的模型,将计算机中存放的语音模型与经处理得到的语音特征进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板,然后根据此模板的定义,就可以给出计算机的识别结果(此为识别过程)。语音的训练是对预先收集好的语音、语言进行信号处理和知识挖掘,得到语音识别所需要的“声学模型”和“语言模型”,此过程通常离线完成;识别过程是对用户实时的语音进行自动识别,此过程为在
线完成。识别过程又分为“前端”和“后端”两个模块,“前端”功能为端点检测、降噪、特征提取等,“后端”功能为利用训练好的“声学模型”和“语言模型”对用户语音的特征向量进行统计模式识别(又称“解码”),得到语音包含的文字信息。
55.具体地,实时自动语音识别对单声道的语音数据进行识别,具体包括:
56.获取语音输入的波形声音,并通过移动窗函数对声音进行切段分帧得到不同的声音帧段,
57.通过提取梅尔频率倒谱系数特征,将波形转换为观察序列矩阵,输入预先训练好的语音识别模型,得到可能的文本集合,从中寻找全局最优路径,将矩阵转为最终的文本。
58.s102:对文本数据进行文本分词、关键词提取,得到特征向量;所述关键词至少包括身份关键词、目的关键词和诉求关键词;
59.具体地,对文本数据进行文本分词、关键词提取,具体包括:
60.文本分词,基于前缀词典进行扫描,生成句子文字所有可能成词所构成的有向无环图,通过动态规划查找最大概率路径,得到基于词频的最大切分组合;对于前缀词典中不包含的词语,采用隐马尔科夫模型对词语进行预测,并在结巴分词算法基础上,结合预先建立的角色识别词典,对文本内容进行分词处理,根据最大切分组合,得到分词结果;
61.关键词提取,根据分词结果计算词语的词频-逆文档频率,将词频-逆文档频率与预先建立的词语的权重列表结合,提取权重占比大的词语,得到关键词,组成特征向量。
62.所述关键词至少包括身份关键词、目的关键词和诉求关键词。
63.s103:根据语音特征向量输入到不同的角色识别模型,所述角色识别模型包括客服场景模型、贷后场景模型、电销场景模型;
64.场景1:
65.客服系统场景,客服系统的业务场景是为了解决用户的来电问题,在与用户的对话中大概率会有,代表身份的如
‘
您好,xxx号客服为您服务’,明确来电人身份的如
‘
您的身份证号是多少’,解决问题的如
‘
正在为您查询,请稍等’;
66.场景2:
67.贷后系统场景,贷后系统的业务场景是为了解决公司催收场景而存在的系统,在对话中大概率存在,代表身份如
‘
这里是xxx公司’,表达目的如
‘
您欠款xxx元’,最终诉求
‘
需要您在xx点前还清’,影响如
‘
否则会影响个人征信’;
68.场景3:
69.电销系统场景,电销系统的业务场景是用户电话销售使用,在对话中大概率存在,代表身份如
‘
这里是xxx公司’,表达目的
‘
产品功能’;
70.可以看出,场景中均有描述身份、目的和诉求;因此在进行语义分析时,身份关键词、目的关键词和诉求关键词。
71.s104:通过模型识别出坐席侧和客户侧。
72.具体地,还包括通过监督性学习对角色识别模型进行完善,具体包括:
73.采用文字匹配和正则表达进行角色识别模型的应用,得出客户方和坐席方的概率分数,取最大的概率分;
74.收集人工复检后进行角色更换的数据进行人工打标;
75.打完标签后数据进行录入模型,实现角色识别模型的完善。
76.如图2,本发明实施例还包括一种基于机器学习的单声道角色识别系统,包括:
77.语音识别单元201:利用实时自动语音识别对单声道的语音数据进行识别,得到单角色语音对应的文本数据;
78.具体地,所述语音识别单元中,实时自动语音识别对单声道的语音数据进行识别,具体包括:
79.获取语音输入的波形声音,并通过移动窗函数对声音进行切段分帧得到不同的声音帧段,
80.通过提取梅尔频率倒谱系数特征,将波形转换为观察序列矩阵,输入预先训练好的语音识别模型,得到可能的文本集合,从中寻找全局最优路径,将矩阵转为最终的文本。
81.特征向量获取单元202:对文本数据进行文本分词、关键词提取,得到特征向量;所述关键词至少包括身份关键词、目的关键词和诉求关键词;
82.具体地,所述特征向量获取单元中,对文本数据进行文本分词、关键词提取,具体包括:
83.文本分词,基于前缀词典进行扫描,生成句子文字所有可能成词所构成的有向无环图,通过动态规划查找最大概率路径,得到基于词频的最大切分组合;对于前缀词典中不包含的词语,采用隐马尔科夫模型对词语进行预测,并在结巴分词算法基础上,结合预先建立的角色识别词典,对文本内容进行分词处理,根据最大切分组合,得到分词结果;
84.关键词提取,根据分词结果计算词语的词频-逆文档频率,将词频-逆文档频率与预先建立的词语的权重列表结合,提取权重占比大的词语,得到关键词,组成特征向量。
85.模型输入单元203:根据语音特征向量输入到不同的角色识别模型,所述角色识别模型包括客服场景模型、贷后场景模型、电销场景模型;
86.场景1:
87.客服系统场景,客服系统的业务场景是为了解决用户的来电问题,在与用户的对话中大概率会有,代表身份的如
‘
您好,xxx号客服为您服务’,明确来电人身份的如
‘
您的身份证号是多少’,解决问题的如
‘
正在为您查询,请稍等’;
88.场景2:
89.贷后系统场景,贷后系统的业务场景是为了解决公司催收场景而存在的系统,在对话中大概率存在,代表身份如
‘
这里是xxx公司’,表达目的如
‘
您欠款xxx元’,最终诉求
‘
需要您在xx点前还清’,影响如
‘
否则会影响个人征信’;
90.场景3:
91.电销系统场景,电销系统的业务场景是用户电话销售使用,在对话中大概率存在,代表身份如
‘
这里是xxx公司’,表达目的
‘
产品功能’;
92.可以看出,场景中均有描述身份、目的和诉求;因此在进行语义分析时,身份关键词、目的关键词和诉求关键词。
93.角色识别单元204:通过模型识别出坐席侧和客户侧。
94.具体地,还包括模型完善单元,通过监督性学习对角色识别模型进行完善,具体包括:
95.采用文字匹配和正则表达进行角色识别模型的应用,得出客户方和坐席方的概率分数,取最大的概率分;
96.收集人工复检后进行角色更换的数据进行人工打标;
97.打完标签后数据进行录入模型,实现角色识别模型的完善。
98.如图3所示,本发明实施例提供了一种电子设备300,包括存储器310、处理器320及存储在存储器320上并可在处理器320上运行的计算机程序311,处理器320执行计算机程序311时实现本发明实施例提供的一种基于机器学习的单声道角色识别方法。
99.在具体实施过程中,处理器320执行计算机程序311时,可以实现图1对应的实施例中任一实施方式。
100.由于本实施例所介绍的电子设备为实施本发明实施例中一种数据处理装置所采用的设备,故而基于本发明实施例中所介绍的方法,本领域所属技术人员能够了解本实施例的电子设备的具体实施方式以及其各种变化形式,所以在此对于该电子设备如何实现本发明实施例中的方法不再详细介绍,只要本领域所属技术人员实施本发明实施例中的方法所采用的设备,都属于本发明所欲保护的范围。
101.请参阅图4,图4为本发明实施例提供的一种计算机可读存储介质的实施例示意图。
102.如图4所示,本实施例提供了一种计算机可读存储介质400,其上存储有计算机程序411,该计算机程序411被处理器执行时实现本发明实施例提供的一种基于机器学习的单声道角色识别方法;
103.在具体实施过程中,该计算机程序411被处理器执行时可以实现图1对应的实施例中任一实施方式。
104.需要说明的是,在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详细描述的部分,可以参见其它实施例的相关描述。
105.本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
106.上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1