修音方法及装置与流程
1.本技术涉及音频技术领域,尤其涉及一种修音方法及装置。
背景技术:
2.对于喜欢音乐的用户来说,用户可以在电子设备上安装音乐应用程序(application,app),音乐应用程序可以提供录音和k歌等模式(也可以称为功能),用户通过音乐app的录音模式或k歌模式完成一首歌曲的演唱,以得到该歌曲的音频数据。但是在用户演唱过程中,用户的音准和节奏可以影响歌曲的效果,因此如何提高歌曲的效果是亟需解决的问题。
技术实现要素:
3.本技术提供了一种修音方法及装置,目的在于提高用户录制歌曲的效果。为了实现上述目的,本技术提供了以下技术方案:第一方面,本技术提供一种修音方法,方法包括:获取第一语音数据,第一语音数据具有第一对象的音色;对第一语音数据进行划分,得到至少两条第二语音数据;确定第二语音数据对应的第二对象;其中,第二对象中存在至少一个第二对象的类型为第一类型,且存在至少一个第二对象的类型为第二类型;对第二语音数据进行音色转换,得到第三语音数据,第三语音数据具有第二语音数据对应的第二对象的音色;至少对第三语音数据进行融合,获得第四语音数据,第四语音数据至少具有第一类型的第二对象的音色和第二类型的第二对象的音色。在本实施例中,电子设备可以对具有第一对象的音色的第一语音数据进行划分,得到至少两条第二语音数据,然后确定第二语音数据对应的第二对象,对第二语音数据进行音色转换,得到具有第二对象的音色的第三语音数据,根据第三语音数据获得第四语音数据,第四语音数据至少具有第一类型的第二对象的音色和第二类型的第二对象的音色,即第四语音数据至少具有两种类型的第二对象的音色,通过音色转换达到多人合成一条语音数据的效果。对第三语音数据的融合可以是对第三语音数据的拼接/组合,例如电子设备在对每条第二语音数据进行音色转换后,按照第二语音数据在第一语音数据中的顺序,对所有第三语音数据进行拼接,得到第四语音数据,第四语音数据的语音内容与第一语音数据的语音内容相同,但第四语音数据的音色和第一语音数据的音色不同。
4.其中第一类型和第二类型可以有多种形式,在一种示例中,第一类型和第二类型可以指第二对象的音色,通过音色区分第二对象。在另一种示例中,第一类型和第二类型可以指第二对象的性别和/或年龄,通过性别和/或年龄区分第二对象。例如,成年男性和青少年男性是不同的第二对象。在其他示例中,第一类型和第二类型可以指第二对象的音色、性别和年龄中的至少一个;在其他示例中,第一类型和第二类型可以指第二对象的对象类别,如真实人物、虚拟人物等等。
5.在一些示例中,修音方法的一种场景可以是没有原唱场景(如用户录用场景);在一些示例中,修音方法的一种场景可以是有原唱场景(如用户k歌场景);在这两个场景下,
电子设备可以获取到用户的语音数据(对应第一语音数据),该语音数据具有用户(对应第一对象)的音色。电子设备可以对该语音数据进行划分,并对划分出的每部分(对应第二语音数据)进行音色转换,得到至少具有两个目标用户的音色的语音数据(对应第四语音数据),目标用户为第二对象。其中第一语音数据可以是从一个音频数据中提取出,如对该音频数据进行背景音乐和语音分离,得到第一语音数据,分离是可选的,在完成音色转换后,电子设备可以将第四语音数据和背景音乐数据合成,得到目标音频数据,目标音频数据具有至少两种类型的第二对象的音色,达到多人合成一条音频数据的目的;如果音频数据中没有背景音乐,那么音频数据可以视为是第一语音数据。
6.在一种可能的实现方式中,方法还包括:获取第五语音数据,第五语音数据具有第三对象的音色,第五语音数据和第一语音数据对应同一内容;从第五语音数据中提取出内容参数;基于内容参数,对第一语音数据进行美音处理,得到第六语音数据;基于第四语音数据和第六语音数据,得到第七语音数据,第七语音数据至少具有第一类型的第二对象的音色和第二类型的第二对象的音色,第七语音数据的内容参数与从第五语音数据中提取出的内容参数匹配。电子设备可以获取到对应同一内容的第一语音数据和第五语音数据,利用第五语音数据的内容参数,对第一语音数据进行美音处理,得到第六语音数据,第六语音数据的内容参数与从第五语音数据中提取出的内容参数匹配;然后基于第四语音数据和第六语音数据,得到第七语音数据,使得第七语音数据可以具有至少两种类型的第二对象的音色,且第七语音数据的内容参数与从第五语音数据中提取出的内容参数匹配,其中匹配是指两条语音数据的内容参数相似或相接近。
7.例如将第四语音数据和第六语音数据融合,使得第七语音数据保留第四语音数据的音色、第七语音数据保留第六语音数据的内容参数,达到多人合成一条语音数据的效果的同时,可以使其内容参数与其他语音数据的内容参数相匹配,因为第六语音数据是基于第三语音数据的内容参数进行美音处理得到,即第六语音数据是美音处理后的语音数据,第六语音数据可以保留第三语音数据的内容参数,第七语音数据可以保留第六语音数据的内容参数,所以第七语音数据可以保留第三语音数据的内容参数。比如在有原唱场景中,电子设备可以获取到原唱的语音数据(对应第三语音数据),利用原唱的语音数据的内容参数对用户的语音数据进行美音处理,从而在达到多人合唱歌曲的目的的同时降低跑调几率。在原唱场景中,第七语音数据可以和背景音乐数据合成,得到目标音频数据,目标音频数据在达到多人合唱歌曲的目的的同时降低跑调几率。
8.在一种可能的实现方式中,内容参数包括:每句的起始位置和结束位置、每个字的起始位置和结束位置、每个字的发音和每个字的音高;基于内容,对第一语音数据进行美音处理包括:基于每个字的起始位置和结束位置,得到每个字的基频和包络;基于每个字的发音,得到每个字的辅音信息;利用每个字的基频、每个字的包络、每个字的辅音信息、每个字的音高、每个字的起始位置和结束位置、每句的起始位置和结束位置,对第一语音数据的音调和语速进行调整,使得第六语音数据的音调与第三语音数据的音调相匹配、第六语音数据的语速与第三语音数据的语速相匹配。
9.其中,对第一语音数据的音调和语速的调整是通过对第一语音数据中每个字和每句调整实现,例如利用每个字的基频和包络,调整第一语音数据中该字的基频和包络,使两条语音数据(第一语音数据和第三语音数据)中该字的基频之间的差异缩小;利用每个字的
辅音信息,调整第一语音数据中该字的辅音信息,使两条语音数据该字的辅音信息相同;利用每字的音高,调整第一语音数据该字的音高,使两条语音数据中该字的音高之间的差异缩小,通过基频、包络、辅音信息和音高的调整,实现对第一语音数据的音调的调整。利用每个字的起始位置和结束位置,调整该字在第一语音数据中的时长,在完成一句中字的时长调整后,可以利用该句的起始位置和结束位置,对第一语音数据中该句的时长进行调整,实现对第一语音数据的语速的调整。因为美音处理后的第一语音数据(即第六语音数据)中每个字的参数与第三语音数据中对应字的参数相一致,以及美音处理后的第一语音数据中每句的参数与第三语音数据中对应句的参数相一致,所以美音处理后的第一语音数据可以保留第三语音数据的特性。在有原唱场景中,美音处理后的第一语音数据可以包括原唱的语音数据的特性,使得美音处理后的第一语音数据可以接近原唱的语音数据,从而降低跑调几率。
10.在一种可能的实现方式中,对第一语音数据进行划分,得到至少两条第二语音数据包括:对第一语音数据进行声纹识别,以确定第一语音数据中至少一部分的识别结果;基于至少一部分的识别结果,对第一语音数据进行划分,得到至少两条第二语音数据,实现通过声纹识别对第一语音数据的划分。在一些示例中,识别结果可以是每部分所属历史对象(如所属历史用户),基于每部分所属历史对象对第一语音数据进行划分。例如电子设备可以将属于一个历史对象的一部分划分成一条第二语音数据,也可以将属于两个不同历史对象的相连的至少两部分划分成一条第二语音数据,实现将一条第一语音数据划分成多条第二语音数据的目的。
11.在一些示例中,识别结果可以是每部分所属对象性别,将对应一个对象性别的一部分划分成一条第二语音数据。例如识别结果可以是每部分所属用户性别,如男性或女性,电子设备可以将属于男性的一部分划分成一条第二语音数据。如果属于男性的多部分之间穿插有属于女性的部分,电子设备可以以穿插有女性的部分作为分割点进行划分。例如0秒(s)至3s属于男性,3s至10s属于男性,10s至20s属于女性,20s至35s属于男性,电子设备可以将0s至10s划分成一条第二语音数据,10s至20s划分成一条第二语音数据,20s至35s划分成一条第二语音数据。
12.在一种可能的实现方式中,基于至少一部分的识别结果,对第一语音数据进行划分,得到至少两条第二语音数据包括:基于至少一部分的识别结果,对第一语音数据进行划分,得到划分结果;接收针对划分结果的调整指令;响应调整指令,基于调整指令中的调整参数,对划分结果进行调整,以得到至少两条第二语音数据。也就是说,电子设备通过声纹识别的识别结果对第一语音数据进行一次划分后,可以对划分结果再次进行划分,在粗划分基础上进行细化分。例如用户可以对划分结果再次进行划分,用户可以调整划分结果的时长,以使得第二语音数据满足用户要求。
13.在一种可能的实现方式中,对第一语音数据进行声纹识别,以确定第一语音数据中至少一部分的识别结果包括:从第一语音数据中提取第一特征数据;调用声纹判别模型对第一特征数据进行处理,获得声纹判别模型输出的声纹判别结果,声纹判别结果包括第一语音数据中每部分的识别结果;其中,声纹判别模型利用多个历史对象的语音数据训练得到。每部分的识别结果可以是每部分历史对象,或者是每部分的识别结果为对象的性别,通过声纹判别模型自动完成声纹识别。
14.在一种可能的实现方式中,对第一语音数据进行划分,得到至少两条第二语音数据包括:接收针对第一语音数据的划分指令;响应划分指令,基于划分指令中的划分参数,对第一语音数据进行划分,得到至少两条第二语音数据。例如用户可以对第一语音数据进行划分,划分参数是用户给出的参数,这样用户可以手动划分第一语音数据。
15.在一种可能的实现方式中,划分参数包括时间参数和/或歌词参数。时间参数可以为用户手动输入时长或用户手动控制时间控件选择时长,时间控件可以是进度条;歌词参数可以为用户手动输入的所述第二语音数据包含的歌词数量,通过时长和/或歌词来划分第一语音数据。以基于歌词参数进行划分为例,如指定x句歌词划分成一段,x为大于或等于1的自然数,每条第二语音数据含有的歌词数量可以相同也可以不同。当然电子设备也可以根据歌词自动划分,如每间隔两段歌词划分一条第二语音数据,或者使每条第二语音数据中的歌词数量相同或相接近。
16.在一种可能的实现方式中,时间参数为用户手动输入时长或用户手动控制时间控件选择时长;方法还包括:如果用户手动控制时间控件选择时长,在检测到选择一个时长后,输出提示信息;基于划分指令中的时间参数,对第一语音数据进行划分包括:响应针对提示信息的确认指令,基于所选择的时长对第一语音数据进行划分。其中,提示信息是一个划分提示,用于提示是否在该时间点进行划分。确认指令表示在该时间点进行划分,由此在接收到确认指令后,电子设备可以基于该时间点对第一语音数据进行划分,从而在划分时达到提示的目的。
17.在一种可能的实现方式中,对第一语音数据进行划分,得到至少两条第二语音数据包括:对第五语音数据进行声纹识别,以确定第五语音数据中至少一部分的识别结果,第五语音数据具有第三对象的音色,第五语音数据和第一语音数据对应同一内容;基于至少一部分的识别结果,对第一语音数据进行划分,得到至少两条第二语音数据,实现利用第五语音数据的识别结果对第一语音数据的划分。例如在有原唱场景中,电子设备可以获取到原唱的语音数据和用户的语音数据,对原唱的语音数据进行声纹识别,得到原唱的语音数据中每部分的识别结果,利用原唱的语音数据中每部分的识别结果对用户的语音数据进行划分。
18.在一种可能的实现方式中,确定第二语音数据对应的第二对象包括:获取用户为第二语音数据确定的第二对象;或者,获取隶属不同对象的音色的得分,从得分满足预设条件的对象中选择第二语音数据对应的第二对象;或者,获取第一对象的音色特征和第二对象的音色特征之间的相似度,基于相似度选择第二语音数据对应的第二对象;或者,确定第一对象的音色所属类型,基于第一对象的音色所属类型选择第二语音数据对应的第二对象。用户确定是一种手动选择方式,基于得分、相似度和音色所属类型是自动选择方式。
19.如果用户为第二语音数据确定第二对象,用户可以为每条第二语音数据确定第二对象,或者根据第二语音数据对应的性别确定第二对象,如相同性别对应一个第二对象。如果基于不同对象的音色的得分确定第二对象,电子设备可以从得分较高的音色中选择,在选择过程中也可以考虑性别,选择与第一对象的性别相同的第二对象,其中得分可根据使用次数得到,使用次数越多得分越高。如果基于音色特征选择,电子设备可以基于相似度选择音色接近或音色差距较大的第二对象,音色接近那么在播放时可以降低突兀感,音色差距较大那么在播放时可以更好的引起用户的注意。如果基于音色所属类型选择,电子设备
可以选择音色与第一对象的音色属于同一类型的第二对象。
20.在一种可能的实现方式中,对第二语音数据进行音色转换,得到第三语音数据包括:获取第二语音数据的音色特征;调用第二对象的音色表征模型,对音色特征进行处理,以获得音色表征模型输出的第三语音数据,其中,音色表征模型利用第二对象的多条语音数据训练得到,第二对象和音色表征模型是一对一的关系,因为每个对象的音色各种不同,所以为每个第二对象训练一个音色表征模型,使得该音色表征模型可以学习到该第二对象的音色特性,提高准确度。
21.在一种可能的实现方式中,获取第二语音数据的音色特征包括:从第二语音数据中提取第二特征数据;调用音色提取模型对第二特征数据进行处理,获得音色提取模型输出的音色特征。
22.在一种可能的实现方式中,至少对第三语音数据进行融合,获得第四语音数据包括:如果所有第二语音数据中的部分第二语音数据没有进行音色转换,对所有第二语音数据中没有进行音色转换的第二语音数据和第三语音数据进行融合,获得第四语音数据,第四语音数据具有第二对象的音色和第一对象的音色。其中第四语音数据可以保留第一对象的音色,使得第四语音数据的音色更加多样化,且能够保留第一对象的音色特性。
23.第二方面,本技术提供一种电子设备,电子设备包括:处理器和存储器;其中,存储器用于存储一个或多个计算机程序代码,计算机程序代码包括计算机指令,当处理器执行计算机指令时,处理器执行上述修音方法。
24.第三方面,本技术提供一种计算机存储介质,计算机存储介质包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行上述修音方法。
附图说明
25.图1为本技术提供的电子设备的硬件结构图;图2为本技术提供的电子设备的软件架构图;图3为本技术提供的一种修音方法的示意图;图4为本技术提供的训练声纹判别模型和音色表征模型的流程图;图5为本技术提供的一种修音方法的流程图;图6为本技术提供的另一种修音方法的示意图;图7为本技术提供的修音方法中美音处理的流程图;图8至图10为本技术提供的修音方法对应的ui示意图。
具体实施方式
26.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。以下实施例中所使用的术语只是为了描述特定实施例的目的,而并非旨在作为对本技术的限制。如在本技术的说明书和所附权利要求书中所使用的那样,单数表达形式“一个”、“一种”、“所述”、“上述”、“该”和“这一”旨在也包括例如“一个或多个”这种表达形式,除非其上下文中明确地有相反指示。还应当理解,在本技术实施例中,“一个或多个”是指一个、两个或两个以上;“和/或”,描述关联对象的关联关系,表示可以存在三种关系;例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b的情况,其中a、b可以是单数
或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。
27.在本说明书中描述的参考“一个实施例”或“一些实施例”等意味着在本技术的一个或多个实施例中包括结合该实施例描述的特定特征、结构或特点。由此,在本说明书中的不同之处出现的语句“在一个实施例中”、“在一些实施例中”、“在其他一些实施例中”、“在另外一些实施例中”等不是必然都参考相同的实施例,而是意味着“一个或多个但不是所有的实施例”,除非是以其他方式另外特别强调。术语“包括”、“包含”、“具有”及它们的变形都意味着“包括但不限于”,除非是以其他方式另外特别强调。
28.本技术实施例涉及的多个,是指大于或等于两个。需要说明的是,在本技术实施例的描述中,“第一”、“第二”等词汇,仅用于区分描述的目的,而不能理解为指示或暗示相对重要性,也不能理解为指示或暗示顺序。
29.在用户录制(如录歌)过程中,电子设备可以获取用户的音频数据,并对音频数据可以进行后期处理,如对音频数据可以进行修音处理。其中,对音频数据的修音处理可以是对音色和音调等中的至少一种进行调整。修音处理方式可以包括如下两种:一种方式是,调整音频数据的音色。例如电子设备可以接收音色转换指令,加载目标角色的音色转换模型,通过该音色转换模型将原始角色输出的第一音频数据转换为目标角色输出的第二音频数据,实现将音频数据转换为目标角色。不同角色的音色不同,电子设备在得到目标角色的第二音频数据后,以目标角色的音色播放语音。在进行音频数据转换时,用户可以选择喜欢的目标角色,由用户喜欢的目标角色的音色转换模型来转换音频数据,电子设备所播放的音频是目标角色复述的音频,满足用户的听觉需求,提高了用户体验。
30.另一种方式是,在保留用户的音色的基础上,调整音频数据的基频。其中基频的高低可以影响音调,通过调整基频实现对音调的调整。
31.例如电子设备获取到用户的音频数据后,通过特征提取算法,提取出用户的音频数据中每个字的基频、包络和辅音信息,每个字提取出预设数量的基频,预设数量根据提取频率确定,用户的音频数据可以是用户念出歌曲的歌词的音频数据;对于每个字,将字的预设数量的基频调整为歌曲中字的音高频率,歌曲中每个字的音高频率为歌曲中每个字的音高对应的频率;对调整后的基频、每个字的包络和辅音信息进行合成处理,得到合成音频;根据歌曲中每个字的时长,对合成音频中每个字的时长进行调整,得到合成的歌声,这样对于唱歌不好的用户来说,用户可以念出歌曲的歌词,电子设备可以获取到该歌曲的音频数据,然后通过调整基频和每个字的时长的方式,合成出与用户声音接近的歌曲。
32.因为电子设备合成过程中保留了用户的声音的包络和辅助信息,使得用户的音色被保留,所以合成出的歌声与用户声音接近,在美音的同时可以保留用户的声音。在合成过程中,电子设备对音频数据中基频的调整,实现对音调的调整。此外电子设备还可以对音频数据中每个字的时长进行调整。
33.一种场景是,电子设备上可以安装音乐app,音乐app可以提供录音模式和k歌模式等模式。录音模式和k歌模式可以向用户提供录制歌曲的功能,通过录制歌曲的功能获取到用户的音频数据,用户的音频数据能够还原出一首歌曲。在得到用户的音频数据后,电子设备可以调用音乐app中的修音模式对用户的音频数据进行修音。在一种示例中,电子设备调用修音模式,将音频数据的音色调整成单一目标角色的音色,虽然电子设备可以调整音频
数据的音色,但是缺少个性化调整,也无法达到多人合唱歌曲的效果。在另一种示例中,电子设备可以调用修音模式,对用户的音频数据进行美音。例如电子设备可以通过修音模式,调整音频数据的基频和音频数据中每个字的时长。在基频和字的时长调整过程中,电子设备没有改变音频数据的音色,保留了用户的音色。
34.针对上述技术问题,本技术提供一种修音方法,在获取到用户的音频数据后,将用户的音频数据划分成至少两部分,对至少两部分进行音色转换,使得用户的音频数据具有至少两个目标音色,通过音色转换达到多人合成歌曲的效果。除了对至少两部分进行音色转换之外,修音方法还可以对用户的音频数据进行美音处理,如通过调整用户的音频数据的基频来调整音频数据的音调,通过调整每个字的时长来调整音频数据的语速。
35.修音方法可以应用到电子设备中。在一些实施例中,该电子设备可以是手机、平板电脑、桌面型电脑、膝上型电脑、笔记本电脑、超级移动个人计算机(ultra-mobile personal computer,umpc)、手持计算机、上网本、个人数字助理(personal digital assistant,pda)、可穿戴电子设备、智能手表等设备。本技术对电子设备的具体形式不做特殊限定。
36.如图1所示,该电子设备可以包括:处理器,外部存储器接口,内部存储器,通用串行总线(universal serial bus,usb)接口,充电管理模块,电源管理模块,电池,天线1,天线2,移动通信模块,无线通信模块,传感器模块,按键,马达,指示器,摄像头,显示屏,以及用户标识模块(subscriber identification module,sim)卡接口等。其中音频模块可以包括扬声器,受话器,麦克风,耳机接口等,传感器模块可以包括压力传感器,陀螺仪传感器,气压传感器,磁传感器,加速度传感器,距离传感器,接近光传感器,指纹传感器,温度传感器,触摸传感器,环境光传感器,骨传导传感器等。
37.可以理解的是,本实施例示意的结构并不构成对电子设备的具体限定。在另一些实施例中,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
38.处理器可以包括一个或多个处理单元,例如:处理器可以包括应用处理器(application processor,ap),调制解调处理器,图形处理器(graphics processing unit,gpu),图像信号处理器(image signal processor,isp),控制器,视频编解码器,数字信号处理器(digital signal processor,dsp),基带处理器,和/或神经网络处理器(neural-network processing unit,npu)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。处理器是电子设备的神经中枢和指挥中心,控制器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。
39.显示屏用于显示图像,视频、一系列图形用户界面(graphical user interface,gui)等,如显示k歌app的界面、显示k歌app中的修音模式、显示用户的音频数据等。
40.外部存储器接口可以用于连接外部存储卡,例如micro sd卡,实现扩展电子设备的存储能力。外部存储卡通过外部存储器接口与处理器通信,实现数据存储功能。例如将修音方法使用的模型等保存在外部存储卡中。内部存储器可以用于存储计算机可执行程序代码,所述可执行程序代码包括指令。处理器通过运行存储在内部存储器的指令,从而执行电子设备的各种功能应用以及数据处理。例如,在本技术中,处理器通过运行内部存储器中存储的指令,使得电子设备执行本技术提供的修音方法。
41.电子设备可以通过音频模块、扬声器、受话器、麦克风、耳机接口以及应用处理器等实现音频功能。例如音乐播放,录音等。
42.音频模块用于将数字音频信息转换成模拟音频信号输出,也用于将模拟音频输入转换为数字音频信号。音频模块还可以用于对音频信号编码和解码。在一些实施例中,音频模块可以设置于处理器中,或将音频模块的部分功能模块设置于处理器中。
43.扬声器,也称“喇叭”,用于将音频电信号转换为声音信号。电子设备可以通过扬声器收听音乐,或收听免提通话,或播放歌曲等。
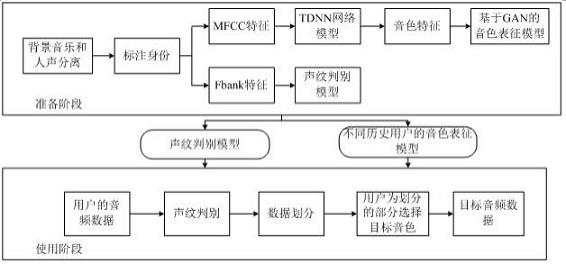
44.受话器,也称“听筒”,用于将音频电信号转换成声音信号。当电子设备接听电话或音频数据时,可以通过将受话器靠近人耳接听音频。
45.麦克风,也称“话筒”,“传声器”,用于将声音信号转换为电信号,声音信号和电信号中携带有用户的音频数据。例如当拨打电话或发送音频数据时,用户可以通过人嘴靠近麦克风发声,将声音信号输入到麦克风。电子设备可以设置至少一个麦克风。在另一些实施例中,电子设备可以设置两个麦克风,除了采集声音信号,还可以实现降噪功能。在另一些实施例中,电子设备还可以设置三个,四个或更多麦克风,实现采集声音信号,降噪,还可以识别声音来源,实现定向录音功能等。
46.耳机接口用于连接有线耳机。耳机接口可以是usb接口,也可以是3.5mm的开放移动电子设备平台(open mobile terminal platform,omtp)标准接口,美国蜂窝电信工业协会(cellular telecommunications industry association of the usa,ctia)标准接口。
47.电子设备的无线通信功能可以通过天线1,天线2,移动通信模块,无线通信模块,调制解调处理器以及基带处理器等实现。电子设备可以利用无线通信功能下载音频数据,处理器可以基于所下载的音频数据,训练出声纹判别模型和音色表征模型。电子设备可以调用声纹判别模型和音色表征模型,实施修音方法。
48.另外,在上述部件之上,运行有操作系统。例如苹果公司所开发的ios操作系统,谷歌公司所开发的android开源操作系统,微软公司所开发的windows操作系统等。在该操作系统上可以安装运行应用程序。
49.电子设备的操作系统可以采用分层架构,事件驱动架构,微核架构,微服务架构,或云架构。本技术实施例以分层架构的android系统为例,示例性说明电子设备的软件结构。图2是电子设备的软硬件结构框图。软件结构采用分层架构,分层架构将软件分成若干个层,每一层都有清晰的角色和分工。层与层之间通过软件接口通信。以android系统为例,在一些实施例中,将android系统分为四层,从上至下分别为应用程序层,应用程序框架层(framework),硬件抽象层(hal)以及系统内核层(kernel)。
50.其中,应用程序层可以包括一系列应用程序包。应用程序包可以包括相机,图库,日历,通话,地图,wlan,音乐,视频,录音和k歌等app。应用程序框架层为应用程序层的应用程序提供应用编程接口(application programming interface,api)和编程框架。应用程序框架层包括一些预先定义的函数。例如应用程序框架层可以包括窗口管理器,内容提供器,视图系统,电话管理器,资源管理器,通知管理器等。
51.hal可以包含多个库模块和多个模型,其中库模块和模型可以被调用。例如hal包括声纹判别模型和音色表征模型。应用程序层中的录音app和k歌app在运行过程中,录音app和k歌app可以调用声纹判别模型和音色表征模型。例如录音app和k歌app通过麦克风可
以获取到用户的音频数据,声纹判别模型可以识别音频数据的声纹,利用声纹对音频数据进行划分,以按照声纹将音频数据划分成至少两部分;音色表征模型可以对划分的至少两部分进行音色转换,以通过对声纹判别模型和音色表征模型的调用,实施本技术所述的修音方法。系统内核层是硬件和软件之间的层。内核层至少包含显示驱动,摄像头驱动,音频驱动,传感器驱动。
52.声纹判别模型可以选择卷积神经网络(convolutional neural network,cnn)、长短期记忆人工神经网络(long-short term memory,lstm)、卷积循环神经网络(convolutional recurrent neural network,crnn)等基础网络模型。音色表征模型可以选择生成式对抗网络(generative adversarial networks,gan)。如在一些示例中,电子设备可以选择crnn模型作为声纹判别模型,利用训练样本对crnn模型进行训练,训练结束后的crnn模型可以学习到不同用户的声纹特性,训练结束后的crnn模型可以基于不同用户的声纹特征识别出音频数据所属用户身份,训练结束后的crnn可以作为声纹判别模型使用。对于音色表征模型来说,电子设备可以选择gan模型作为音色表征模型,利用训练样本对gan模型进行训练,训练结束后的gan模型可以学习到用户的音色特性,完成从一个音色向另一个音色的转换,那么训练结束后的gan模型可以作为音色表征模型使用。声纹判别模型的训练样本和音色表征模型的训练样本可以相同也可以不同。
53.下面结合场景对本技术提供的修音方法、声纹判别模型和音色表征模型进行说明。请参见图3,其示出了本技术实施例提供的一种修音方法的示意图,图3所示修音方法针对的是没有原唱场景,没有原唱场景可以是用户录音场景。如用户录制歌曲场景,在用户录音过程中没有播放原唱,或者,用户录制一首新歌等等。其中,修音方法可以包括准备阶段和使用阶段,在准备阶段,电子设备完成声纹判别模型和音色表征模型的训练。在使用阶段,电子设备可以调用音色表征模型对用户的音频数据进行音色转换,电子设备还可以调用声纹判别模型对用户的音频数据进行划分,以将用户的音频数据划分成至少两个部分。
54.声纹判别模型和音色表征模型可以以不同历史用户的音频数据为训练样本,历史用户的音频数据可以是历史用户在唱歌过程中采集到,历史用户可以包括明星(如原唱歌手、翻唱歌手、演员)、网络歌手、直播用户、虚拟人物和普通用户等。电子设备可以获取到不同历史用户的多条音频数据,电子设备也可以获取到同一个历史用户的多条音频数据。电子设备利用不同历史用户的多条音频数据对声纹判别模型进行训练,使得声纹判别模型可以学习到每个历史用户的声纹特性,得到与多个历史用户的声纹特性匹配的声纹判别模型;利用任一历史用户的多条音频数据对音色表征模型进行训练,使得音色表征模型可以识别到该历史用户的音色特性,得到与该历史用户的音色特性匹配的音色表征模型。
55.也就是说,声纹判别模型和历史用户的关系是,一个声纹判别模型对应多个历史用户,电子设备可以利用多个历史用户的音频数据,训练声纹判别模型。音色表征模型和历史用户的关系是,一个音色表征模型对应一个历史用户,即音色表征模型和历史用户是一对一的关系,电子设备可以以任一历史用户的音频数据为训练样本,训练出与该历史用户的音色特性匹配的音色表征模型。电子设备以不同历史用户的音频数据,训练声纹判别模型和音色表征模型的过程可以参见图4所示,包括以下步骤:s101、对每个历史用户的音频数据进行背景音乐和人声分离,得到历史用户的语音数据。历史用户的语音数据可以还原历史用户的声音。
56.s102、对语音数据进行身份标注,以标注出语音数据中每部分对应的历史用户身份标识。历史用户身份标识可以是历史用户的姓名,历史用户身份标识可以是历史用户的性别。
57.s103、从语音数据中提取出梅尔频率导频系数(mel-frequency cepstral coefficients,mfcc)特征,从语音数据中提取出fbank(filter bank)特征。mfcc特征和fbank特征可以体现历史用户的声纹特性,fbank特征中的信息量大于mfcc特征中的信息量,且在提取mfcc特征过程中增加了离散余弦变换(discrete cosine transform,dct),在某种程度上可能损失语音数据,使得mfcc特征的准确度低于fbank特征的准确度,因此在训练声纹判别模型时使用fbank特征,在训练音色表征模型时使用mfcc特征。
58.s104、将fbank特征输入到声纹判别模型中,声纹判别模型输出声纹判别结果,声纹判别结果可以指示语音数据中各部分所属历史用户。
59.s105、基于声纹判别结果(如预测的历史用户身份标识)、标注的历史用户身份标识和损失函数,调整声纹判别模型的模型参数。
60.电子设备通过对声纹判别模型的模型参数的多次调整,以完成对声纹判别模型的训练。在完成对声纹判别模型的训练后,声纹判别模型可以学习到每个历史用户的声纹特性,这样在使用声纹判别模型进行声纹判别时,声纹判别模型可以判别出语音数据所属用户身份是否是训练时的历史用户,如果是,声纹判别模型可以输出语音数据所属历史用户身份标识;如果不是,声纹判别模型的输出为空。由此,电子设备在获取到用户的音频数据后,电子设备可以对用户的音频数据进行背景音乐和人声分离,得到用户的语音数据,从语音数据中提取出fbank特征,然后调用声纹判别模型对语音数据中各部分的用户身份进行识别,得到语音数据中各部分所属用户身份标识。
61.s106、将mfcc特征输入到音色提取模型中,音色提取模型输出音色特征。
62.s107、将音色特征输入到音色表征模型的生成器中,生成器输出音频数据。
63.s108、将生成器输出的音频数据输入到音色表征模型的判别器中,判别器输出判别结果,判别结果可以指示生成器输出的音频数据与mfcc特征所属历史用户的音频数据之间的差异。一种示例中,判别结果用于指示生成器输出的音频数据是真实音频数据还是伪造音频数据,真实音频数据表明生成器输出的音频数据与mfcc特征所属历史用户的音频数据相同/相似,伪造音频数据表明生成器输出的音频数据与mfcc特征所属历史用户的音频数据不同/不相似。
64.s109、基于判别结果调整生成器和判别器的模型参数。
65.生成器的损失函数可以是:;判别器的损失函数可以是:。其中d表示判别器,表示判别器的输入为真实音频数据时判别器输出的判别结果,g表示生成器,表示生成器输出的音频数据,表示判别器的输入为伪造音频数据时判别器输出的判别结果,a、b和c是常数,a、b和c的一种设置方式可以是b=c=1,a=-1。在判别器的损失函数中,
的取值接近1,的取值接近-1。在生成器的损失函数中,的取值接近1。真实音频数据是指生成器生成的音频数据与历史用户的音频数据匹配/接近;伪造音频数据是指生成器生成的音频数据与历史用户的音频数据不匹配/不接近。
66.电子设备通过对生成器和判别器的模型参数的多次调整,以完成对音色表征模型的训练。在基于一个历史用户的多条音频数据完成对音色表征模型的训练后,判别器提高了识别真实音频数据和伪造音频数据的能力,生成器可以学习到该历史用户的音色特性,使生成器输出与该历史用户的音色匹配的音频数据,与该历史用户的音色匹配的音频数据相当于是历史用户说话时电子设备采集到的音频数据,达到以假乱真的目的。
67.电子设备利用图4所示流程完成对声纹判别模型和音色表征模型的训练,电子设备在获取到用户的音频数据后,可以对当前获取到的音频数据进行修音,在修音过程中电子设备可以调用声纹判别模型和音色表征模型,修音方法的流程图如图5所示,可以包括以下步骤:s201、电子设备获取用户的音频数据。在没有原唱场景中,电子设备可以运行录音app,录音app可以录制歌曲等音频数据。在电子设备运行录音app过程中,电子设备可以调用麦克风采集用户的音频数据。
68.s202、对当前获取到的用户的音频数据进行背景音乐和人声分离,得到用户的语音数据。在本实施例中,步骤s202是可选的,如果用户的音频数据中没有背景音色,用户的音频数据即是用户的语音数据,那么电子设备可以跳过步骤s202,执行步骤s203。
69.s203、从用户的语音数据中提取出fbank特征。
70.s204、将fbank特征输入到声纹判别模型中,获得声纹判别模型输出的声纹判别结果,声纹判别结果可以指示语音数据中各部分所属历史用户。也就是说通过声纹判别模型可以将语音数据中的各部分与历史用户对应,从而通过声纹判别模型完成对语音数据中各部分所属用户身份的自动标注。
71.在一种示例中,声纹判别模型可以记录历史用户的声纹特征向量,利用历史用户的声纹特征向量得到声纹判别结果。例如,电子设备可以从语音数据的各部分中提取出fbank特征,将各部分的fbank特征输入到声纹判别模型中,声纹判别模型可以生成fbank特征所属部分的声纹特征向量,将当前生成的声纹特征向量与记录的所有历史用户的声纹特征向量进行距离计算,以确定当前生成的声纹特征向与记录的声纹特征向量是否匹配,如果与记录的声纹特征向量匹配,那么fbank特征所属部分的用户身份标识是匹配的声纹特征向量对应的历史用户,从而将fbank特征所属部分的用户身份标识标注为匹配的声纹特征向量对应的历史用户,完成对fbank特征所属部分的声纹识别。
72.在一种示例中,声纹判别结果可以是声纹判别模型预测的历史用户身份标识,如声纹判别模型预测出历史用户的姓名,对于历史用户的语音数据的各部分,声纹判别模型可以识别各部分对应的历史用户的姓名。例如对于语音数据中的任一部分,声纹判别模型输出该部分隶属不同历史用户的概率,将概率最大的历史用户标注为该部分所属用户身份。
73.s205、参照声纹判别模型输出的声纹判别结果,将用户的语音数据划分成至少两部分。
74.在一种示例中,声纹判别结果指示出语音数据中各部分所属历史用户,那么在对
语音数据进行划分时,按照各部分所属历史用户,对用户的语音数据进行划分,例如属于一个历史用户的部分被划分成独立段落,从而将属于不同历史用户的各部分独立出来,完成对语音数据的自动划分。
75.在另一种示例中,声纹判别结果作为语音数据划分的参照,电子设备可以输出声纹判别结果,然后用户可参照声纹判别结果对语音数据进行划分。例如语音数据中0秒(s)至3s属于历史用户a,3s至10s属于历史用户b,10s至20s属于历史用户a,20s至35s属于历史用户c,电子设备可以按照此种方式对语音数据进行划分,也可以在此种划分基础上进行调整,如将0s至20s划分成一部分,将20s至35s划分成一部分。
76.s206、获取用户为划分出的每部分选择的目标用户。其中,目标用户是所有历史用户中的一个历史用户,用户可以为语音数据被划分的每个部分选择一个目标用户,即语音数据被划分的一个部分对应一个目标用户,目标用户的音色为该部分的目标音色。语音数据被划分的不同部分对应的目标用户可以相同,也可以不同。
77.s207、调用目标用户的音色表征模型,以语音数据中与该目标用户对应的部分为输入,获得该目标用户的音色表征模型输出的目标语音数据,该目标语音数据的音色为目标用户的音色,完成语音数据从一个用户的音色向目标用户的音色的转换。例如对于语音数据划分出的每部分,电子设备提取该部分的mfcc特征,将该部分的mfcc特征输入到音色提取模型中,由音色提取模型输出该部分的音色特征,将该部分的音色特征和该部分输入到目标用户的音色表征模型中,获得目标用户的音色表征模型输出的目标语音数据,完成对语音数据中该部分的音色转换。
78.s208、组合各目标语音数据,以得到目标音频数据。其中,目标音频数据包括各目标语音数据,各目标语音数据的音色为目标用户的音色,使得目标音频数据至少具有目标用户的音色,目标音频数据可以作为用户的音频数据输出,这样电子设备可以输出至少具有目标用户的音色的音频数据,完成对音频数据的音色转换。
79.例如在用户录制歌曲的场景中,电子设备可以采集到用户的音频数据,用户的音频数据具有用户的音色,如果是一个用户录制歌曲,那么用户的音频数据具有单一音色。电子设备可以利用上述图5所示修音方法对该用户的音频数据进行音色转换,得到至少具有目标用户的音色的目标音频数据,目标音频数据可以具有至少两个目标用户的音色,从而经过图5所示修音方法的处理后,电子设备获取到一个具有至少两个目标用户的音色的目标音频数据,在单一用户录制歌曲场景中可以实现多人合唱的目的。
80.上述修音方法中,电子设备采集到一个用户的音频数据后,对当前采集到的音频数据进行背景音乐和人声分离,得到用户的语音数据。电子设备可以调用声纹判别模型对用户的语音数据进行声纹判别,利用声纹判别模型输出的声纹判别结果对语音数据进行划分,以将语音数据划分成至少两部分。在为划分的各部分选择目标用户后,分别调用每个目标用户的音色表征模型,对与目标用户对应的部分进行音色转换,得到每个目标用户的音色表征模型输出的目标语音数据,然后组合各目标语音数据,以得到目标音频数据,电子设备可以输出目标音频数据。目标音频数据可以具有至少两个目标用户的音色,使得电子设备可以以至少两个目标用户的音色输出目标音频数据,达到音频数据从单一音色向多音色的转换的目的,实现多人参与录音的目的。
81.请参见图6,其示出了本技术实施例提供的另一种修音方法的示意图,图6所示修
音方法针对的是有原唱场景,有原唱场景可以是用户录音场景,在用户录音过程中播放原唱,或者,有原唱场景可以是用户k歌场景等等。其中,图6所示修音方法可以包括准备阶段和使用阶段,在准备阶段,电子设备完成声纹判别模型和音色表征模型的训练,声纹判别模型和音色表征模型的训练过程请参见上述图4所示流程,此处不再详述。在使用阶段,电子设备可以调用音色表征模型对用户的音频数据进行音色转换,电子设备还可以调用声纹判别模型对用户的音频数据进行划分,以将用户的音频数据划分成至少两个部分,至少两个部分的音色转换可通过音色表征模型完成,在使用阶段中音色表征模型和声纹判别模型的使用过程请参见上述图5所示流程,此处不再详述。除了对用户的音频数据进行音色转换之外,在使用阶段,电子设备可以对用户的音频数据进行美音处理。电子设备将完成音色转换后的音频数据和完成美音处理后的音频数据合成,输出合成后的音频数据。
82.在实施图6所示修音方法时,电子设备可以开启两个线程,一个线程用于进行音色转换,另一个线程用于进行美音处理。音色转换可以在完成音频数据采集后进行,美音处理可以在采集音频数据过程中进行,以在采集音频数据的同时进行美音处理,这样在采集到完整的音频数据后,电子设备完成对音频数据的美音处理。电子设备可以利用更多资源对音频数据进行音色转换,提高对音频数据的处理效率。在有原唱场景中,电子设备可以采集到两个音频数据,一个是用户的音频数据,一个是原唱的音频数据。音色转换和美音处理是针对用户的音频数据的。
83.例如在用户k歌场景中,当用户利用k歌软件演唱歌曲时,电子设备开启两个线程,一个线程在电子设备采集到完整的用户的音频数据后启用,该线程对用户的音频数据进行划分,以将用户音频数据划分成至少两部分,再对至少两部分进行音色转换;另一个线程可以在采集用户的音频数据的过程中对用户的音频数据进行美音处理。在完成音色转换和美音处理后,电子设备可以将音色转换后的音频数据和美音处理后的音频数据合成,输出合成后的音频数据,合成后的音频数据可以作为用户演唱的歌曲的音频数据。音色转换使得音频数据可以具有多种音色,美音处理使得音频数据除音色之外的音频特征与原唱的音频特征相匹配,那么歌曲的音频数据可以具有多种音色、除音色之外的音频特征与原唱的音频特征匹配。电子设备播放歌曲的音频数据时可以以多种音色和原唱的音频特征来播放歌曲,降低跑调几率、达到多人合唱歌曲的目的,原唱是歌曲的演唱者。
84.在本实施例中,电子设备对用户的音频数据进行美音处理的过程如图7所示,可以包括以下步骤:s301、从原唱的音频数据中提取出歌曲信息,歌曲信息包括每句的起始位置和结束位置、每个字的起始位置和结束位置、每个字的发音和每个字的音高等。歌曲信息主要是从原唱的音频数据的语音数据中提取。
85.电子设备可以利用语音对齐技术或者语音活动检测(voice activity detection,vad)技术等对原唱的音频数据中每句及每个字的起始位置和结束位置进行标注,起始位置和结束位置可以以毫秒(ms)或者帧长为划分单位。发音通过获取原唱的音频数据中每个字的拼音得到,例如原唱的音频数据是一首歌曲的音频数据,将歌词转换为拼音来获得发音。
86.音高可以通过多音部音高提取算法从原唱的音频数据中提取出,例如通过polyphonic music(多音部)音高提取算法,提取原唱的音频数据的音高数据,多音部音高
提取算法可以是melodia(一种算法名称)算法等。原唱的音频数据的音高数据可以记做x=[x(1),x(2)
…
x(n)],其中,n为正整数,x(n)为音频数据中不同时间点的音高值。原唱的音频数据可能包括多个演唱者的语音数据,电子设备可以利用monophnic music(单音部)音高提取算法,分别提取每个演唱者的人声音高数据,单音部音高提取算法可以是pyin(一种算法名称)算法等。单个演唱者的人声音高数据可以记做yk=[yk(1),yk(2)
…
yk(n)],其中,n为正整数,k=1、2、
…
k,yk(n)为音频数据中任一人声音频在不同时间点的音高值。此外,电子设备可以通过乐器数字接口(musical instrument digital interface,midi)文件获取到音高。
[0087]
s302、基于每个字的起始位置和结束位置,得到每个字的基频和包络;基于每个字的发音,得到每个字的辅音信息。
[0088]
包络是将不同频率的振幅最高点连接形成的曲线,也就是说包络对应的是不同频率的振幅最高点,基频是所有频率中的最小频率。电子设备可以利用时域提取方法或频域提取方法提取每个字的基频,获得音频数据的线性预测编码系数;根据线性预测编码系数得到每个字的包络。
[0089]
其中,利用时域提取方法提取字的基频的过程可以是,通过分析字的波形的周期变化来提取字的基频,其中字的波形的周期变化可基于该字的起始位置和结束位置得到。字的自相关函数也是周期的,所以字的自相关函数也是根据周期的性质估计字的基频。字在基音周期的各个整数点的位置对应一个大峰值,通过分析自相关函数的第一个大峰值和k=0点的距离,以估算出字的基频,k表示的是延时。当k=0时,自相关函数具有最大的峰值。利用频域提取方法提取字的基频的过程可以是,对时域的字的波形进行傅里叶变换并取对数,处理后的波形在频域内是一个准周期性信号,这个信号周期即为字的基频。
[0090]
字的发音是由元音和辅音等组成,由此,电子设备可以直接从字的发音中提取到辅音信息。
[0091]
s303、利用每个字的基频、每个字的包络、每个字的辅音信息、每个字的音高、每个字的起始位置和结束位置、每句的起始位置和结束位置,对用户的音频数据的音调和语速进行调整,以完成对用户的音频数据的美音处理。其中,对用户的音频数据的音调和语速的调整是对用户的音频数据中语音数据的音调和语速的调整。
[0092]
在本实施例中,对用户的音频数据的音调和语速的调整可以是对用户的音频数据中每个字的信息进行调整实现的,如对用户的音频数据中每个字的基频、每个字的包络、每个字的辅音信息、用户的音频数据中每句的起始位置和结束位置的调整。
[0093]
一种实现方式是,利用步骤s302从原唱的音频数据中获取到的任意一个字的基频和包络,调整用户的音频数据中该字的基频和包络,使该字的基频与步骤s302中提取到的基频之间的差异缩小;利用步骤s302从原唱的音频数据中获取到的任意一个字的辅音信息,调整用户的音频数据中该字的辅音信息,使该字的辅音信息与步骤s302中提取到的辅音信息相同;利用步骤s301从原唱的音频数据中获取到的任意一个字的音高,调整该字的音高,使该字的音高与步骤s301中提取到的音高之间的差异缩小,通过基频、包络、辅音信息和音高的调整,实现对用户的音频数据的音调的调整。其中所调整的该字在用户的音频数据中的位置和在原唱的音频数据中的位置可以相同。
[0094]
利用步骤s301从原唱的音频数据中获取到的任意一个字的起始位置和结束位置,
调整该字在用户的音频数据中的时长,在完成一句中字的时长调整后,可以利用步骤s301中提取到的该句的起始位置和结束位置,对该句的时长进行调整,实现对用户的音频数据的语速的调整。其中所调整的该字在用户的音频数据中的位置和在原唱的音频数据中的位置可以相同,所调整的句子在用户的音频数据中的位置和在原唱的音频数据中的位置可以相同。
[0095]
在完成对用户的音频数据的美音处理后,电子设备可以对美音处理后的音频数据和音色转换后的音频数据进行合成,即将两个音频数据融合成一个音频数据,两个音频数据的合成可以是两个音频数据的频谱的合成。一种示例中,基于两个音频数据中一个音频数据的频谱,调整另一个音频数据的频谱,例如以音色转换后的音频数据的频谱为主,缩小美音处理后的音频数据的频谱与音色转换后的音频数据的频谱之间的差异;又例如按照音色转换后的音频数据的频谱的比例调整美音处理后的音频数据的频谱。另一种示例中,将两个音频数据的频谱进行相加处理,如将两个音频数据的频谱进行加权求和。频谱合成可以是针对两个音频数据中的语音数据的频谱,对两个音频数据中的语音数据的频谱进行合成。
[0096]
上述图3至图6阐述了对用户的音频数据进行音色转换,音色转换可以将用户的语音数据划分成至少两部分,由用户指定每部分对应的目标用户,再调用目标用户的音色表征模型,对该目标用户对应的部分进行音色转换。对用户的语音数据的划分可以是基于声纹判别模型输出的声纹判别结果,对应的用户界面(user interface,ui)如图8所示。
[0097]
在图8所示ui中,声纹判别模型对用户的语音数据进行声纹判别,确定语音数据对应两个声纹,两个声纹分别是明星1和明星2。并且图8所示ui中显示一个提示信息,该提示信息指示是否按人声自动分段,如果电子设备接收到按人声自动分段后,那么电子设备可以按照声纹判别模型判别出的两个声纹对语音数据进行自动分段,例如声纹判别模型判别出语音数据中的0s至10s对应明星1,10s至25s对应明星2,25s至40s对应明星1,那么电子设备可以按照0s至10s、10s至25s和25s至40s进行自动分段。
[0098]
在图8所示ui中,用户可以指定目标音色,例如可以指定目标用户,目标用户的音色作为目标音色使用,如在图8中指定将明星1的音色转换为明星3的音色,将明星2的音色转换为明星4的音色。在用户点击确认后,电子设备调用明星3的音色表征模型对0s至10s、25s至40s的音频数据进行音色转换,调用明星4的音色表征模型对10s至25s的音频数据进行音色转换。
[0099]
在没有原唱场景中,电子设备可以采集到一个音频数据,调用声纹判别模型对采集到的音频数据中的语音数据进行声纹判别,然后利用声纹判别结果对语音数据进行自动划分。在有原唱场景中,电子设备可以采集到两个音频数据,一个是原唱的音频数据,一个是用户(也可以称为演唱者)的音频数据,电子设备可以调用声纹判别模型对两个音频数据中的语音数据分别进行声纹判别,利用原唱的声纹判别结果或者用户的声纹判别结果对用户的音频数据中的语音数据进行自动划分。
[0100]
声纹判别模型除了可以判别出语音数据所属用户身份之外,声纹判别模型可以判别语音数据所属用户性别,那么电子设备在对语音数据进行划分时可以根据性别进行划分。如图9示出了按照性别对语音数据进行自动划分,用户可以指定与性别相匹配的目标用户;例如性别是男,则选择男性目标用户,性别是女,则选择女性目标用户。之后电子设备调
用目标用户的音色表征模型进行音色转换。
[0101]
图8和图9是电子设备利用声纹判别模型的声纹判别结果对语音数据的自动划分,图8和图9中的对号表示利用声纹判别结果对语音数据的自动划分。除了自动划分之外,用户可以手动划分语音数据,用户手动划分语音数据可以是根据时间划分,按照时间划分的方式可以是每间隔m秒划分或者用户手动选择划分时间点,在手动选择划分时间点时用户可以拖动进度条划分,拖动到一个位置弹出划分提示,划分提示用于提示用户是否在该时间点进行划分,如果选择是则在该时间点进行划分,否则不进行划分,m为自然数。用户手动划分语音数据可以根据歌词划分,如指定x句歌词划分成一段,x为大于或等于1的自然数,每部分含有的歌词数量可以相同也可以不同。当然电子设备也可以根据歌词自动划分。图10示出了用户按照时间划分语音数据,用户可以手动输入每部分的起始时间点和结束时间点,也可以手动输入每部分对应的目标用户。之后电子设备调用目标用户的音色表征模型进行音色转换。
[0102]
目标音色可以是由用户指定,目标音色还可以采用其他方式指定。在一种示例中,电子设备可以统计不同音色的得分,将得分较高的至少一个音色作为目标音色,不同音色的得分可以是根据使用次数得到,使用次数越多得分越高。在另一种示例中,获得用户的音色特征和历史用户的音色特征之间的相似度,基于相似度确定出目标音色,如基于相似度选择音色接近或音色差距较大的音色作为目标音色。在另一种示例中,电子设备可以预先对音色进行类型划分,在确定当前采集到的音频数据的音色所属类型后,基于音色所属类型选择一个音色作为目标音色,如从音色所属类型中选择一个音色作为目标音色。
[0103]
此外,电子设备在对音频数据进行音色转换时,电子设备可以对音频数据中的部分数据进行音色转换。例如用户利用图10所示ui指定音频数据中进行音色转换的部分;又例如电子设备预先指定音频数据中的待划分数据,调用声纹判别模型对待划分数据进行划分,或者,用户手动划分待划分数据,或者在声纹判别模型划分的基础上进行调整等等,这样音频数据既可以具有用户原本的音色,又增加了目标音色。在其他示例中,电子设备对音频数据进行音色转换后,将音色转换得到的音频数据与电子设备采集到的用户的音频数据进行融合,得到一个音频数据,融合过程可以是两个音频数据的频谱的融合,此处不再详述。
[0104]
本技术实施例还提供一种电子设备,电子设备包括:处理器和存储器;其中,存储器用于存储一个或多个计算机程序代码,计算机程序代码包括计算机指令,当处理器执行计算机指令时,处理器执行上述修音方法。
[0105]
本技术实施例还提供一种计算机存储介质,计算机存储介质包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行上述修音方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1