一种语音识别方法和电子设备与流程
本技术涉及终端领域,尤其涉及一种语音识别方法和电子设备。
背景技术:
1、目前,用户可以根据自身需求在个人的手机等终端设备上设置个性化的唤醒词,即自定义唤醒词。与默认唤醒词相比,自定义唤醒词缺少了针对唤醒词的涵盖各种音量、噪声、情绪的训练样本,所以识别自定义唤醒词的可靠性远低于默认唤醒词。
技术实现思路
1、本技术提供了一种语音识别方法,实施该方法手机等终端设备可以利用语音合成器合成各种场景下的内容为自定义唤醒词的语音样本,然后利用上述语音样本,终端设备可以优化当前使用的自定义唤醒词识别模型,使之成为可以在各种场景下识别到自定义唤醒词的识别模型。
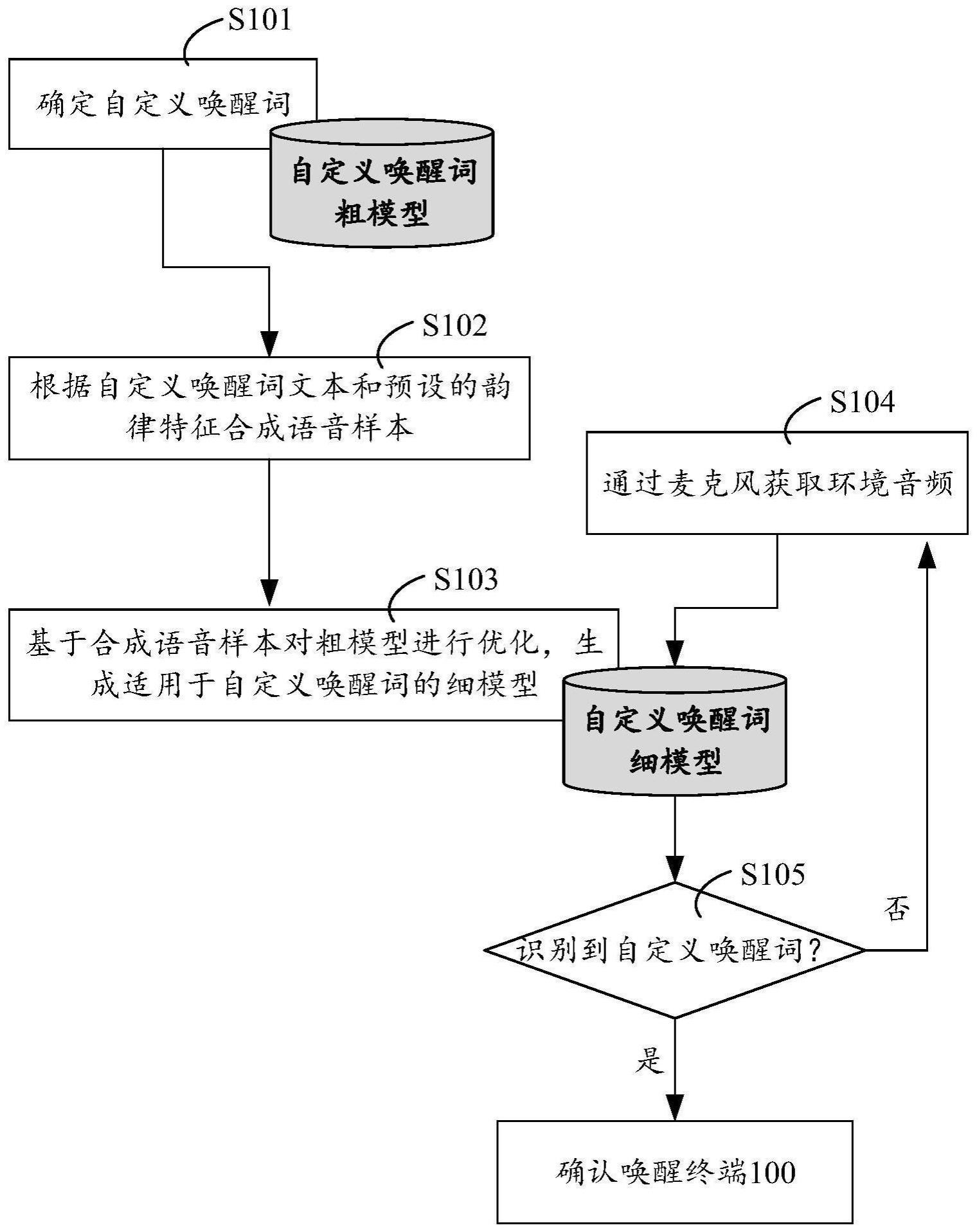
2、第一方面,本技术提供了一种语音识别方法,该方法包括:确定第一唤醒词,第一唤醒词是用户设定的;根据第一唤醒词和预设的控制参数合成语音样本,语音样本是语音内容包括第一唤醒词的音频数据,控制参数用于控制合成的语音样本中所表现出的说话方式和/或说话场景;利用合成的语音样本对第一语音识别模型进行训练得到第二语音识别模型;第一语音识别模型为训练前用于识别第一唤醒词的语音识别模型,第二语音识别模型为训练后用于识别第一唤醒词的语音识别模型;使用第二语音识别模型识别麦克风采集的音频数据;当从麦克风采集的音频数据中识别到第一唤醒词时,唤醒终端设备。
3、实施第一方面提供的方法,手机等终端设备可以接收用户输入的自定义唤醒词,并合成各种场景下内容为自定义唤醒词的语音样本,然后,终端设备可利用上述语音样本优化当前使用的自定义唤醒词识别模型,从而提升该模式的识别准确率,使得优化后的模型可以在任何背景环境下都能识别到用户说出的自定义唤醒词。
4、结合第一方面提供的实施例,在一些实施例中,该方法还包括:确定麦克风采集的音频数据中成功唤醒终端设备的音频数据为有效音频数据;利用有效音频数据和合成的语音样本对第二语音识别模型进行优化,得到第三语音识别模型;使用第三语音识别模型处理麦克风采集的音频数据。
5、实施上述实施例提供的方法,终端设备还可在实施自定义唤醒词检测中,将包括自定义唤醒词并成功唤醒终端设备的环境音频确定为有效音频数据。然后终端设备可使用有效音频设备和合成语音样本优化当前使用的语音识别模型,从而周期地更新语音识别模型,提升语音识别模型的识别效果,提升用户使用体验。
6、结合第一方面提供的实施例,在一些实施例中,该方法还包括:确定麦克风采集的音频数据中成功唤醒终端设备的音频数据为有效音频数据;利用有效音频数据对第二语音识别模型进行优化,得到第三语音识别模型;使用第三语音识别模型处理麦克风采集的音频数据。
7、实施上述实施例提供的方法,终端设备还可在实施自定义唤醒词检测中,将包括自定义唤醒词并成功唤醒终端设备的环境音频确定为有效音频数据。然后终端设备可使用有效音频设备优化当前使用的语音识别模型,从而周期地更新语音识别模型,提升语音识别模型的识别效果,提升用户使用体验。
8、结合第一方面提供的实施例,在一些实施例中,在利用有效音频数据和合成的语音样本对第二语音识别模型进行优化之前,该方法还包括:确认有效音频数据的数量大于等于第一数量阈值,第一数量阈值为预设的。
9、实施上述实施例提供的方法,终端设备可以积累有效音频数据,在累积的有效音频数据的数量达到预设的第一数量阈值之后,终端设备再利用有效音频数据和合成的语音样本对第二语音识别模型进行优化,以避免每确定一条有效音频数据就立即更新当前使用的语音识别模型造成的计算资源浪费。
10、结合第一方面提供的实施例,在一些实施例中,在利用有效音频数据对第二语音识别模型进行优化之前,该方法还包括:确认有效音频数据的数量大于等于第二数量阈值,第二数量阈值为预设的。
11、实施上述实施例提供的方法,终端设备可以积累有效音频数据,在累积的有效音频数据的数量达到预设的第二数量阈值之后,终端设备再利用有效音频数据对第二语音识别模型进行优化,以避免每确定一条有效音频数据就立即更新当前使用的语音识别模型造成的计算资源浪费。
12、结合第一方面提供的实施例,在一些实施例中,在对第二语音识别模型进行优化之前,该方法还包括:确认当前时刻在预设的更新时间范围内。
13、实施上述实施例提供的方法,终端设备可以避免在用户正在使用终端设备时更新语音识别模型,从而避免超负荷导致系统卡顿或异常、影响用户使用体验。
14、结合第一方面提供的实施例,在一些实施例中,控制参数包括韵律特征;韵律特征用于控制合成的语音样本中说话人的说话方式,说话人的说话方式包括下一项或多项:说话人的说话时的情绪、停顿。
15、这样,终端设备在合成语音样本时,可通过韵律特征控制合成语音样本中说话人的说话方式说话情景,以模拟各种情绪状态下说话人说出自定义唤醒词的音频。
16、结合第一方面提供的实施例,在一些实施例中,根据第一唤醒词和预设的控制参数合成语音样本,具体包括:将第一唤醒词和预设的韵律特征输入语音合成器;利用语音合成器合成n条语音样本,n≥1;
17、结合第一方面提供的实施例,在一些实施例中,该方法还包括:依次对n条语音样本进行数据增强处理,得到m条语音样本,述m≥n。
18、实施上述实施例提供的方法,终端设备可以通过数据增强处理将合成的多条语音样本进行进一步扩充,得到数量更多的语音样本。这些语音样本之间存在些微的速度差异、音量差异、音调差异等等,从而进一步丰富合成的语音样本,模拟更多不同场景下的说话人说出的自定义唤醒词音频。
19、结合第一方面提供的实施例,在一些实施例中,控制参数还包括噪声参数,噪声参数用于控制合成的语音样本中说话人的说话场景,依次对n条语音样本进行数据增强处理,具体包括:通过噪声参数对n条语音样本进行数据加噪。
20、实施上述实施例提供的方法,终端设备可以通过数据加噪模拟说话人在不同遭横环境中说出自定义唤醒词的音频数据。
21、结合第一方面提供的实施例,在一些实施例中,数据增强处理包括数据加噪,数据加噪所使用的噪声包括以下一项或多项:人声噪声、风声噪声、建筑噪声、交通噪声;或者,数据加噪所使用的噪声包括以下一项或多项:居家噪声、办公室噪声、商场噪声、公园噪声。
22、这样,终端设备在合成语音样本时,可通过数据加噪进一步获得基于不同使用环境的说话人说出自定义唤醒词的音频,从而获得更丰富的训练样本,以提升语音识别模型的鲁棒性。
23、结合第一方面提供的实施例,在一些实施例中,该方法还包括:从有效音频数据中提取韵律特征;利用第一唤醒词、控制参数中的韵律特征和提取的韵律特征更新合成的语音样本。
24、实施上述实施例提供的方法,终端设备还可从确定的包括自定义唤醒词并成功唤醒终端的有效音频数据中提取说话人的韵律特征。然后,终端可将上述提取的说话人的韵律特征与语音合成器中预设的韵律特征参数结合,合成新的语音样本,从而使得合成语音样本更加丰富。这样,基于更丰富的语音样本,终端可以得到更有的唤醒词识别模型。
25、结合第一方面提供的实施例,在一些实施例中,第一语音识别模型的输入层与第二语音识别模型的输入层中包括的数据处理层的数量相同;第一语音识别模型的输入层与第二语音识别模型的输入层中对应的数据处理层的参数相同。
26、实施上述实施例提供的方法,终端设备在优化模型的过程中,可以保持在前的数据处理层的数量相同以及参数相同,从而节省优化过程中的算法成本、时间成本等,提升模型优化的效率。
27、第二方面,本技术提供了一种电子设备,该电子设备包括一个或多个处理器和一个或多个存储器;其中,一个或多个存储器与一个或多个处理器耦合,一个或多个存储器用于存储计算机程序代码,计算机程序代码包括计算机指令,当一个或多个处理器执行计算机指令时,使得电子设备执行如第一方面以及第一方面中任一可能的实现方式描述的方法。
28、第三方面,本技术提供一种计算机可读存储介质,包括指令,当上述指令在电子设备上运行时,使得上述电子设备执行如第一方面以及第一方面中任一可能的实现方式描述的方法。
29、可以理解地,上述第二方面提供的电子设备、第三方面提供的计算机存储介质均用于执行本技术所提供的方法。因此,其所能达到的有益效果可参考对应方法中的有益效果,此处不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!