一种结合Transformer的轻量化中文语音识别方法与流程
一种结合transformer的轻量化中文语音识别方法
技术领域
1.本发明属于语音识别领域,具体涉及一种结合transformer的轻量化中文语音识别方法。
背景技术:
2.语音识别(automatic speech recognition)作为一个由计算机科学和计算机语言学(computational linguistics)组成的跨学科分支,搭建起人与机器沟通的桥梁。深度学习兴起之前,语音识别模型主要是基于高斯模型和隐马尔可夫模型的混合模型(gaussian mixture model-hidden markov model,gmm-hmm)。然而,gmm-hmm对频谱图的修改会导致原始语音信息的丢失;深度学习技术旨在减少此类信息损失,并从原始数据中搜索更有效的音频特征表示。因此,gmm也被深度神经网络(deep neural network,dnn)替代,整体框架变为dnn-hmm。然而,以hmm为代表的传统模型有着处理流程复杂和训练时间长的缺陷,阻碍了语音识别技术的发展。随着计算机算力的提高,端到端的语音识别系统将声学模型与字典结合到一起,缩短了模型的训练时间;端到端的模型因此成为了热门研究对象。2017年,vaswani等人提出了基于自注意力机制的模型transformer【vaswani a,shazeer n,parmar n,et al.attention is all you need[c]//31st conference on neural infor-mation processing systems(nips 2017),long beach,ca,usa,december 4-9,2017.】,在机器翻译和文本生成等领域展现出了强大的识别能力。随后,linhao dong等人将transformer应用到语音识别领域,提出了speech-transformer模型【dong l,shuang x,bo x.speech-transformer:a no-recurrence sequence-to-sequence model for speech recognition[c]//2018ieee international conference on acoustics,speech and signal processing(icassp 2018),calgary,ab,canada,april 15-20,2018.piscataway:ieee,2018:5884-5888.】;基于transformer的端到端语音识别系统也成为了众多研究人员的研究热门对象。由于transformer没有在其结构中显式地建模位置信息,因此使用了位置编码(positional encoding)来捕捉位置关系。然而绝对位置编码在过长文本中会丢失相对位置信息,于是zihang dai等人提出了相对位置编码(relative position representation),极大地提高了训练文本的长度【dai z,yang z,yang y,et al.transformer-xl:attentive language models beyond a fixed-length context[c]//the 57th annual meeting of the association forcomputational linguistics(acl 2019),florence,italy,july 28
–
august 2,2019.】。gulati等人发现transformer的注意力机制善于捕捉全局信息,而卷积神经网络(convolutional neural network,cnn)善于提取局部信息;并因此提出了将cnn与transformer相结合的模型:conformer【gulati a,qin j,chiu c c,et al.conformer:convolution-augmented transformer for speech recognition[c]//21st annual conference of the international speech communication association(interspeech 2020),shang-hai,china,october 25-29,2020.】。
[0003]
然而,transformer出色的识别能力和训练速度都依赖于大量的参数。例如,单个transformer模型需要10g以上的乘加运算(mult-adds)才能翻译出一个只有30个单词的句子。这种极高的计算资源需求大大超出了物联网和智能手机等边缘设备的能力,限制了transformer模型在该类设备上部署的可能性。因此,设计一种用于边缘设备的轻量、快速的语音识别transformer架构有重要的意义。felix等人提出了用动态卷积(dynamic convolutions)来代替自注意力机制【wu f,fan a,bae a,et al.pay less attention with lightweight and dynamic convolutions[c]//interantion-al conference on learning representations 2019(iclr2019),new orleans,louisana,united states,may 6-9,2019.】。然而,动态卷积核会随各时刻的学习函数而变化,因此需要占用大量的gpu内存来计算。为了解决这个问题,模型中使用了轻量卷积来减少参数和运算量,使动态卷积有了可行性。alex等人提出使用卷积神经网络代替位置编码来捕捉位置信息,并通过删除speech-transformer中影响性能较小的模块来精简模型,使其能够在边缘设备上应用。winata等人提出了低秩transformer模型(low-rank transformer,lrt),该模型将低秩矩阵分解(low-rank matrix factorization)应用到transformer的特征矩阵中,由此减少模型的参数,并加快模型的训练速度和推理速度【winata g i,cahyawijaya s,lin z,et al.lightweight and efficient end-to-end speech recognition using low-rank transformer[c]//proceedings of the 2020ieee internation-al conference on acoustics,speech and signal processing,barcelona,may 4-8,2020.piscataway:ieee,2020:6144-6148.sainath t n,kingsbury b,sindhwani v,et al.low-rank matrix factorization for deep neural network training with high-dimensional output targets[c]//2013ieee international conference on acoustics,speech and signal processing,vancouver,bc,canada,may 26-31,2013.piscataway:ieee,2013:6655-6659.】。
[0004]
由于在声学模型中均使用了深层网络,融合模型的参数量比基于transformer的端到端模型大,不适于边缘设备的模型部署。lrt作为基于transformer的模型,在vanilla transformer的编码器、解码器上均引入了低秩矩阵分解,极大程度地压缩了模型体积。然而,在多头自注意力模块使用低秩分解,导致了该模块捕获信息的能力下降,使模型的识别能力偏低。以rnn为框架的deep speech2将语音识别模块和语音增强模块进行联合训练,并通过门控递归融合(gated recurrent fusion,grf)模块将原始的带噪语音信号和增强后的语音信号在音频特征层面进行融合;在获得原始语音的保真信息的同时,也能获取增强语音信号中的降噪信息。然而deep speech2需要获取原始和增强后的语音信号特征,大大增加了模型的推理时间,阻碍了流式语音识别在移动设备上的应用。
技术实现要素:
[0005]
本发明旨在解决现有技术存在的技术问题,提供一种结合transformer的轻量化中文语音识别方法。
[0006]
本发明的技术方案:
[0007]
一种结合transformer的轻量化中文语音识别方法,步骤如下:
[0008]
步骤1.提取声学特征80fbank作为输入特征,声学特征输入部分使用2个深度可分
离卷积模块作为下采样,每个深度可分离卷积模块包括一个逐通道卷积dw-conv和一个逐点卷积pw-conv,每个深度可分离卷积模块使用relu激活函数,声学特征80fbank依次经过dw-conv、pw-conv后进行层归一化处理;
[0009]
步骤2.下采样后的声学特征经过线性层变为二维,然后利用相对位置编码提取声学特征位置信息;
[0010]
步骤3.声学特征位置信息传入编码器模块encoder中,encoder由lm结构堆叠而成,lm结构依次包括半步剩余权重的lr-ffn模块、一个多头注意力(4head)和半步剩余权重的lr-ffn模块,每个半步剩余权重的lr-ffn模块与多头注意力之间均包括残差连接、层归一化操作;每个半步剩余权重的lr-ffn模块使用低秩矩阵分解(秩优选为64),将经多头注意力(4head)处理后的特征与之前经过步骤1-3处理的音频序列特征拼接起来,然后经过线性层还原大小提取权重更高的信息;
[0011]
步骤4.将文本标签输入到文本标签处理前置层(character embedding),通过文本标签处理前置层将对应标签映射到更高维的特征;
[0012]
步骤5.利用相对位置编码提取文本标签位置信息,并将文本标签位置信息传入decoder编码器模块中;首先通过掩盖的多头自注意力模块(4head),掩盖未来文本信息,文本特征输出作为v,然后与步骤3经encoder的输出的声学特征q、k一起进入decoder的多头注意力模块,通过线性层映射到输出;
[0013]
步骤6.attention decoder使用softmax计算attention decoder出来的交叉熵损失值作为attention loss,并增加标签平滑功能;
[0014]
步骤7.推理阶段使用beamsearch(beam width=5)将decoder的输出结果作为最终结果。
[0015]
本发明的有益效果:提出了基于轻量transformer的中文语音识别系统。首先在声学特征处理模块使用了深度可分离卷积(depthwise separable convolution),将逐通道卷积(depthwise convolution)与逐点卷积(pointwise convolution)相结合;与常规卷积相比,降低了参数量与运算量。其次,本发明在transformer的编码器部分使用了macaron-net结构,并在前馈神经网络(feed-forward network,ffn)中应用了低秩矩阵分解,在保持模型识别准确率的同时,减少了模型的参数,提高了模型的推理速度。最后,本发明通过实际数据集aishell-1和aidatatang_200zh对上述模型的进行了实验验证,模型的字错误率降低至9.66%,实时率降低至0.0201。
附图说明
[0016]
图1缩放点积注意力。
[0017]
图2多头注意力。
[0018]
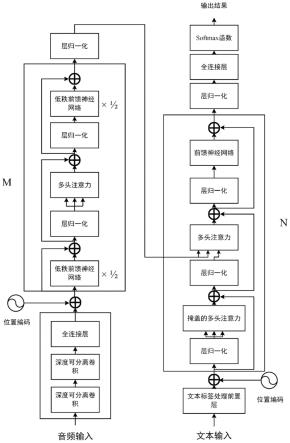
图3lm-transformer模型结构。
[0019]
图4深度可分离卷积。
[0020]
图5低秩前馈神经网络。
[0021]
图6当前主流语音识别模型参数。
具体实施方式
[0022]
1注意力机制
[0023]
transformer的编码器和解码器都使用自注意力机制,自注意力是模仿人类大脑的注意力思想构造而成。注意力函数的作用可以描述为将一项查询值和一系列的键和值对映射输出。其中,查询值q、键k、值v都是向量。
[0024]
常见的注意力机制有加性注意力机制(additiveattention)和点积注意力机制(dot-productattention)。其中乘性函数得益于已优化的矩阵乘法算法,具有计算速度更快的优势。点积注意力的输入由查询值、键的维度dk和值的维度dv组成,通过计算查询值与所有键的点积,除以dk,并应用softmax函数来获得值的权重。当dk较大时,点积的增长幅度较大,从而将softmax函数推向梯度极小的区域。为了抵消这种影响,transformer将dk缩放成并将其称为缩放点积注意力(scaleddot-productattention),如图1所示。缩放点积注意力的计算公式如式(1)所示:
[0025][0026]
多头注意力(multi-headattention)如图2所示,由h个缩放点积注意力堆叠而成,能对输入信息并行处理。相比单头的注意力,多头注意力模型能够在不同的表示子空间获取不同位置的信息。多头注意力机制通过式(2)计算出h头缩放点积注意力,再将各子空间的输出结果进行拼接。具体计算公式如式(2)、式(3)所示:
[0027]
multihead(q,k,v)concat(head1,
…
,head
t
)wo(2)
[0028][0029]
式中h表示注意力头的数量,式中h表示注意力头的数量,
[0030]
2轻量化语音识别系统
[0031]
2.1模型架构
[0032]
本发明提出的轻量化模型lm-transformer(lowrankmacaron-transformer)主要由声学处理模块、编码器和解码器组成,具体模型结构如图3所示。与序列到序列(seq2seq)模型相似,本发明的编码器将语音特征序列(x1,
…
,x
t
)转换为隐藏表示hs=(h1,
…
,h
t
);在确定hs后,解码器每次生成一个单字符的输出序列(y1,
…
,ys),并将已生成输出序列作为附加输入。最终通过softmax函数输出对应位置对应词汇的概率分布。
[0033]
2.2声学处理模块
[0034]
语音识别模型需要将语音特征序列转换为相应的字符序列。语音特征序列可以描述为具有时间和频率轴的二维频谱图,通常比字符序列长几倍。因此,本发明选择使用卷积神经网络来匹配频谱图的结构局部性,并通过跨越时间轴来减少长度的不适配性。
[0035]
本发明在时间和频率两个维度上堆叠了两个卷积层,来提升模型获取时域信息的能力;并缩减时间维度与目标输出长度相近,缓解了特征序列和目标序列长度不适配的问题。
[0036]
本发明使用深度可分离卷积来替代普通卷积网络,以达到减少参数和运算量的效果。如图4所示,深度可分离卷积由逐通道卷积和逐点卷积组成。逐通道卷积对输入层的每
个通道进行独立卷积计算,然后重新进行堆叠。然而,逐通道卷积未能有效利用不同通道在相同空间位置上的特征信息,因此在逐通道卷积后引入了逐点卷积。逐点卷积的卷积核大小都是1
×
1,会将上一步的特征图在深度方向上进行加权组合,生成新的特征图。
[0037]
假设输入特征图的大小为wi×hi
×ci
,输出特征图的大小为wo×ho
×co
,卷积核大小为dk×dk
,其中wi和wo分别为输入和输出特征图的宽度;hi和ho分别为输入和输出特征图的高度;ci和co分别为输入和输出通道数。则标准卷积和深度可分离卷积的参数量如式(4)、式(5)所示:
[0038][0039][0040]
式(5)中ci×co
值远小于可忽略不计。因此,由式(4)和式(5)可得到两种卷积方法的参数量之差,如式(6)所示:
[0041][0042]
标准卷积和深度可分离卷积的计算量如式(7)、式(8)所示:
[0043][0044][0045]
由式(7)和式(8)可得到两种卷积方法的计算量之差,如式(9)所示:
[0046][0047]
本发明模型在仅改变卷积网络的情况下,通过对比处理同一段长度约5秒的音频特征时的表现,发现两种卷积的处理效率有很大差距;表1为实验的结果,其中mult-adds为卷积网络完成的乘加运算次数,flops为卷积网络完成的浮点运算次数。由表1所示,深度可分离卷积的参数量和计算量都远小于普通卷积。
[0048]
表1不同卷积处理音频特征时对比
[0049][0050]
2.3编码器、解码器
[0051]
本发明编码器和解码器的结构如图3所示,由m个相同的编码器和n个相同的解码器模块堆叠而成。与transformer的编码器不同,本发明利用了macaron-net【gulati a,qin j,chiu c c,et al.conformer:convolution-augmented transformer for speech recognition[c]//21st annual conference of the international speech communication association(interspeech 2020),shang-hai,china,october 25-29,2020.】,将编码器模块中的原始前馈网络替换成两个半步剩余权重的前馈神经网络层。对于编码器模块i的输入xi,该模块的输出yi如式(10)所示:
[0052]
[0053]
xi″
=layernorm(xi′
+mhsa(xi′
))
[0054][0055]
其中,lr-ffn指低秩前馈神经网络模块,mhsa指多头自注意力模块;xi′
、xi″
分别为经过第一个lr-ffn模块、mhsa模块的输出。每个子层在使用残差连接后都进行了层归一化(layer-normalization),为深层神经网络的训练增加了稳定性。与单前馈神经网络层相比,该结构在识别能力上有一定的提升。
[0056]
transformer的编码器-解码器体系结构通过并行计算提高了模型的识别性能和训练速度;然而,该结构依赖深层的网络和大量的参数,这减慢了模型的推理速度,也增加了模型在边缘设备部署的难度。因此,本发明在transformer的编码器结构引入了低秩矩阵分解算法,并将该结构命名为lm结构(low-rank macaron-net)。
[0057]
lm结构使用低秩分解单元来替代原先的单一全连接层;由于自注意力模块负责处理信息,而低秩分解会导致部分信息的丢失,所以在自注意力模块应用低秩分解会导致抓取信息的能力下降,从而影响整个模型的识别能力。自注意力模块会直接评估句中词汇在不同位置的语义和相关性,并使用这些信息来捕捉句子的内部结构和表示;而前馈神经网络模块更新多头注意力中输出向量的状态信息,或逼近学习函数,并不直接参与上下文信息的获取。因此,本发明未在多头自注意力模块使用低秩分解,而是应用在前馈神经网络模块中,具体结构如图5所示。该结构可减轻低秩分解算法对模型识别能力的影响,同时压缩模型,降低参数量。
[0058]
lm结构将全连接层的矩阵近似成两个较小的矩阵和
[0059]
w≈x
×y[0060]
矩阵w需要m
×
n的参数和计算力(flops),而x和y需要r
×
(m+n)的参数和计算力。当秩r远小于m和n时,x和y的参数和计算力将比w小得多。本发明通过试验测试不同大小的r对推理速度、模型大小和识别准确率的影响。
[0061]
本发明的解码器模块具有和编码器模块类似的结构,区别是在多头自注意力模块前增加了一个掩盖的多头自注意力模块(masked multi-head attention),其目的是遮掩未来信息。
[0062]
本发明使用了lm结构压缩了模型,并通过深度可分离卷积进一步减少了参数。通过与当前部分主流语音识别模型进行对比,发现本发明模型参数量相对较少,如图6所示。
[0063]
3实验结果与分析
[0064]
3.1实验数据
[0065]
本发明使用的数据集为北京希尔贝壳有限公司录制的中文普通话开源语音数据库aishell-1,以及北京数据堂科技有限公司录制的中文普通话语料库aidatatang_200zh。aishell-1录音时长178小时,录音文本设计智能家居、无人驾驶、工业生产等11个领域;由400名来自中国不同口音区域的发言人参与录制,经过专业语音人员转写标注,并通过严格质量检验,文本正确率在95%以上。aidatang_200zh由600名来自中国不同口音区域的发言人参与录制,录音时长200小时。
[0066]
3.2实验环境
[0067]
本发明实验均在windows 10操作系统下搭建的pytorch深度学习框架中实现,硬件环境使用了intel core(tm)i7-10870h cpu@2.20ghz(处理器),nvidia geforce rtx 2060@6gb(显卡)。语音处理库主要使用了torchaudio、kaldi和scipy。
[0068]
3.3实验步骤
[0069]
实验先对数据集音频数据进行预处理,通过预加重、分帧(25ms每帧)、加窗(汉明窗)、短时傅里叶变换、mel滤波获得fbank音频特征;然后使用全局倒谱均值方差归一化(global_cmvn)对特征进行处理,使输入的声学特征符合正态分布。aishell-1的字典共有4233个字符,aidatatang_200zh的字典共有3944个字符;两个字典均包含《pad》(空白符)、《s/e》(起始/结束符)和《unk》(未知字符)共计三个特殊字符。本发明在模型训练时使用了频谱增强(spec augment),用于提升模型的鲁棒性。
[0070]
本发明模型具体主要分为声学处理模块、编码器模块和解码器模块。声学处理模块由两个深度可分离卷积组成。单个深度可分离卷积中,逐通道卷积步长为2,卷积核大小为(3,3);逐点卷积步长为1,卷积核大小为(1,1)。编码器模块由6个相同的子模块组成。单个子模块中包含一个lm结构和一个多头自注意力模块,注意力头数为4,输出的特征维度为256,自注意力模块中使用了相对位置编码(relative position embedding,rpe)。解码器模块由3个相同的子模块组成,每个子模块由一个掩盖的多头自注意力模块、一个多头自注意力模块和一个前馈神经网络模块组成,参数设置与编码器模块相同。
[0071]
本发明训练轮数为80,累计梯度accum_steps为4,为了防止梯度爆炸,设置了梯度阈值clip_grad为5。训练时使用了动态调整学习率,具体如式(11)所示:
[0072][0073]
其中,ne为训练步数,缩放因子k为10,注意力模块矩阵维度d
model
为256,热身步数warmup_n为12000。
[0074]
本发明使用的优化器为adam,其超参数设置为β1=0.9,β2=0.98,ε=10-9
。每个子模块中的dropout为0.1。
[0075]
3.4模型对比试验
[0076]
为了检验本发明模型的性能,本发明通过实验与当前主流中文语音识别模型进行对比,测试内容为模型的参数量、准确率、推理速度。其中,准确率的评价标准为字错误率(wer,word error rate),计算方式如式(12)所示:
[0077][0078]
其中s为被替换的字数,d为被删除的字数,i为新插入的字数,n
se
为句子字数。字错误率越低,模型的识别能力越高。
[0079]
推理速度的评价标准为实时率(rtf,real time factor),计算方式如式(13)所示:
[0080][0081]
其中,ta为音频的时长,wa为处理音频的时间。实时率越低,模型解码速度越快,推理速度越快。
[0082]
为了验证提出的模型框架效果,本发明将lm-transformer与对比的声学模型open-transformer在数据集aishell-1进行基于字符为建模的模型实验,并与当前其他主流模型进行对比。实验结果如表2所示。
[0083]
表2不同模型在aishell-1的实验结果
[0084][0085]
[6]dong l,shuang x,bo x.speech-transformer:a no-recurrence sequence-to-sequence model for speech recognition[c]//2018 ieee international conference on acoustics,speech and signal processing(icassp 2018),calgary,ab,canada,april 15-20,2018.piscataway:ieee,2018:5884-5888.
[0086]
[11]winata g i,cahyawijaya s,lin z,et al.lightweight and efficient end-to-end speech recognition using low-rank transformer[c]//proceedings of the 2020 ieee internation-al conference on acoustics,speech and signal processing,barcelona,may 4-8,2020.piscataway:ieee,2020:6144-6148.[22]
[0087]
[23]fan c,yi j,tao j,et al.gated recurrent fusion with joint training framework for robust end-to-end speech recognition[j].ieee/acm transactions on audio,speech,and language processing,2021,29:198-209.
[0088]
[24]tian z,yi j,tao j,et al.spike-triggered non-autoregressive transformer for end-to-end speech recognition[j]//21st annual conference of the international speech communication association(interspeech 2020),shang-hai,china,october 25-29,2020.
[0089]
[25]auvolat a,mesnard t.connectionist temporal classification:labelling unsegmented sequences with recurrent neural networks[c]//international conference onmachine learning,icml 2006.pittsburgh,pa:acm,2006:369-376.
[0090]
dfsmn-t将dfsmn作为声学模型、transformer作为语言模型,通过联结时序分类算法(connectionist temporal classification,ctc
[25]
)进行联合训练;由于在声学模型中
均使用了深层网络,该融合模型的参数量比基于transformer的模型大,不适于边缘设备的模型部署。lrt在vanilla transformer的编码器、解码器上均引入了低秩矩阵分解,使模型参数量大幅减少。然而,在多头自注意力模块使用低秩分解,导致了该模块捕获信息的能力下降,使模型的识别能力偏低。deep speech2将语音识别模块和语音增强模块进行联合训练,并通过门控递归融合(gated recurrent fusion,grf)模块将原始的带噪语音信号和增强后的语音信号在音频特征层面进行融合;在获得原始语音的保真信息的同时,也能获取增强语音信号中的降噪信息。然而deep speech2需要获取原始和增强后的语音信号特征,大大增加了模型的推理时间,阻碍了流式语音识别在移动设备上的应用。speech-transformer和open-transformer均为基于transformer的语音识别系统。speech-transformer通过2d-attention结构对时域和频域的位置信息进行建模,增强了模型对时域和频域的不变性。open-transformer基于speech-transformer的模型结构,并通过ctc产生的尖峰个数预测目标语句的长度,从而实现非自回归的语音识别系统。本发明模型lm-transformer改变lm结构中秩的大小,发现在秩为64时模型的识别效果最好,字错误率减少至9.66%;与open-transformer相比,有19.8%的相对幅度下降。
[0091]
为了进一步验证模型的泛化性,本发明在不改变模型参数设置的情况下,在aidatatang_200zh数据集上重新训练lm-transformer和open-transformer。如表3所示,与aishell-1的实验结果类似,当lm结构中的秩为64时模型的字错误率最低,为10.51%。本发明模型lm-transformer与open-transformer相比,字错误率有31%的相对下降幅度,验证了本发明模型具有一定的泛化能力。
[0092]
表3不同模型在aidatang_200zh的实验结果
[0093][0094][0095]
为了实现模型在边缘设备上的部署,除了降低模型的参数量,还需考虑模型的推理速度;过久的响应速度会影响设备的可使用性。因此,本发明在aishell-1和aidatatang_200zh两个数据集上测试了本发明模型的实时率,具体结果如表4所示。
[0096]
表4模型推理速度的实验结果
[0097][0098]
本发明模型在测试中发现,当lm结构中的秩为64和32时,实时率基本相同,因此最终选择秩为64时的模型。lm-transformer在两个数据集上与open-transformer相比,实时率分别下降32.1%和38.2%。其主要原因是lm-transformer使用了深度可分离卷积,相对常规卷积减少了计算量;引入低秩矩阵分解后模型进行了压缩,降低了内存占用,也减少了模型初始化时间。
[0099]
4结论
[0100]
本发明针对基于transformer的语音识别系统模型过大,难以在边缘设备部署的问题,提出了轻量化模型lm-transformer。本发明在模型的声学处理模块使用深度可分离卷积,降低了参数和计算量;在模型的编码器中使用macaron-net结构,并引入了低秩矩阵分解算法,实现了模型压缩、易于在边缘设备部署的目的。
[0101]
本发明在两个数据集上进行实验,通过与当前主流语音识别模型对比,验证了本发明模型具有一定的泛化能力,并在保证识别精度的同时,压缩了模型,实现了模型轻量化的目标。在后续的研究中会继续探索更多的模型轻量化策略。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1