基于深度学习的音乐多模态数据情感识别方法
1.本发明涉及音乐情感深度学习技术领域,尤其涉及基于深度学习的音乐多模态数据情感识别方法。
背景技术:
2.随着移动终端设备的不断普及,在线电子音乐市场取得了飞速发展,人们可以从多种渠道访问到海量的音乐资源。为了方便听众获取音乐作品,各大音乐平台会使用情感、流派等标签来整理和组织音乐作品。由于音乐是情感的载体,因此利用情感来管理音乐作品显得尤为重要。然而对音乐作品进行人工情感标注不仅费时费力,并且出错率高,因此,利用人工智能技术自动识别音乐情感的研究具有现实意义。
3.在智能搜索和推荐领域,另一方面也方便用户使用情感来搜索音乐,并结合用户的历史数据来为用户更好的推荐音乐,为用户带来更好的体验感。低层音频特征与音乐的语义和情感之间没有联系;数据集的匮乏限制了研究人员进行特征提取和模型设计的空间,使得利用歌词进行情感识别的性能较差;利用音频或歌词等单一模态数据进行音乐情感识别已经触及天花板,提升空间有限。因此我们提出基于音乐情感识别的多模态深度学习方法。
技术实现要素:
4.本发明的目的是针对背景技术中存在的现有音乐学习单一模态识别情感提升的空间有限,不能深度挖掘音乐数据集中的特征向量,识别性能差等的问题,提出基于深度学习的音乐多模态数据情感识别方法。
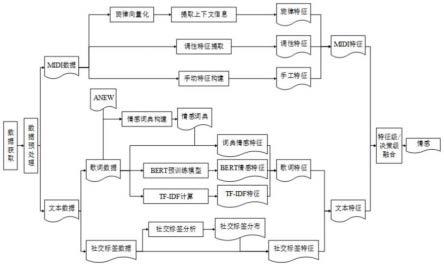
5.本发明的技术方案:基于深度学习的音乐多模态数据情感识别方法,包括以下学习步骤:
6.s1:音乐数据的预处理;音频数据清洗:采用python的midi文件处理工具包pretty_midi对数据进行遍历,判断报错的数据为无效音频,删除数据集中无效的音频数据;主音轨提取:第一步删掉不满足条件的音轨,留下的音轨为候选音轨;第二步为每一个候选音轨求六个特征量,之后将六个特征量求和作为该音轨的得分,得分最高者为主音轨;
7.s2:midi数据的特征提取;ermslm模型的特征提取模块由:旋律特征提取、调性特征提取和手工特征提取三部分组成;
8.旋律特征提取:用于完成从第i首音乐的音符音高集pi中提取出旋律特征向量mi;调性特征提取:用于从音乐的调性数据中提取调性特征ki,通过预训练的方式让mlp的参数学习到调性与情感的联系,用真正的标签yi来计算损失并反向调参;手工特征提取:从音乐的主音轨中提取出音符的音高、力度、时值和音乐的速度四种信息来构建手工特征hcfi;
9.s3:文本数据的特征提取;所述文本数据特征包括歌词特征和社交标签特征,歌词特征提取包括三部分:第一部分是利用预训练好的bert模型获取歌词中每个单词的词向量,并计算每个词向量与四个类别标签词向量的相似度,利用计算的相似度来构建bert情
感特征;第二部分是基于anew列表构建包含四种情感的情感词典,并利用该情感词典构建词典情感特征;第三部分是计算歌词中每个单词在四个情感类别上的tf-idf值,将所有单词在某一类别上的tf-idf值累加作为该类别的数值,四个类别的数值构成歌词的tfidf特征;
10.社交标签特征提取包括三步:第一步数据集预处理;数据集预处理用于对原始数据进行整理,以便输入社交标签分布分析算法以获取社交标签分布表;第二步社交标签分布分析算法;根据数据预处理得到的社交标签集tag和标签汇总集t来设计算法,用于分析社交标签与音乐情感的联系,并基于该算法得到社交标签分布表;第三步社交标签特征提取;社交标签特征提取用于提取第i首音乐的社交标签特征ftai=[t1...tc],c为情感类别数,该特征的每个维度对应一个情感类别;
[0011]
s4:多模态融合;多模态融合用于融合音乐的midi和文本数据来进行多模态音乐情感识别;多模态融合包括特征级融合模型和决策级融合模型。
[0012]
优选的,所述s1中音轨要满足的条件包括以下:(1)通道数不为10;(2)音符数量不少于各音轨音符平均数的一半;(3)音符发声总时长不少于各音轨音符平均发声时间的一半,所述主音轨提取第二步中的六个特征量包括:音符数特征量f
nc
、发声时间特征量f
nd
、平均音高特征量f
p
、平均音强特征量fv、发音面积特征量f
p_d
和响度面积特征量f
v_d
;音符数指的是一条音轨的音符数量,用note_count表示,从midi文件中提取;音高指的是音符频率的高低,用pitch表示,音高可直接从midi文件中提取,发声时间指的是某个音符的音长,用duration表示,可直接从midi文件中提取;音强指的是音符的力度,用intensity表示,音强可直接从midi文件中提取;音符的发音面积指的是该音符音高与发声时间的乘积,音符的响度面积为该音符音强与发声时间的乘积。
[0013]
优选的,所述s2中调性特征提取在反向调参过程中用到的损失函数为交叉熵损失函数,具体计算公式为:其中yi为真实标签,y
′i为预测标签,n为样本数量;mlp进行预训练后,将其表示为pre-trained mlp,则调性特征的计算方式为:ki=pre-trainedmlp(keyi)。
[0014]
优选的,s2中ermslm模型的步骤算法为:
[0015]
输入:包含音符音高集p,音强集i,音长集d,速度bmp和调性key的数据集ms;
[0016]
输出:midi数据的音乐情感识别结果;
[0017]
begin;
[0018]
row1:读取数据集中的每首音乐数据msi;
[0019]
row2:设迭代次数为n,批处理大小为b;
[0020]
row3:for each msi in ms;
[0021]
row4:经过旋律特征提取模块得到旋律特征mi;
[0022]
row5:经过调性特征提取模块得到调性特征ki;
[0023]
row6:经过手动特征提取模块得到手工特征hcfi;
[0024]
row7:将上述三个特征进行连接得到特征向量fi;
[0025]
row8:end for;
[0026]
row9:使用公式得到情感识别结果;
[0027]
row10:for each n in n;
[0028]
row11:for each b in b;
[0029]
row12:使用公式计算误差损失;
[0030]
row13:使用梯度下降优化算法adam更新网络参数;
[0031]
row14:end for;
[0032]
row15:end for;
[0033]
row16:end。
[0034]
优选的,所述s3中社交标签特征ftai中维度tj使用公式tak∈stdtj计算,其中n表示第i首音乐所拥有的社交标签数,tsk为社交标签tak在社交标签分布表中的得分;stdtj包含了与情感ej相关的重要性排在前α的社交标签。
[0035]
优选的,所述特征级融合模型用于将s2和s3中得到midi特征和文本特征进行连接得到融合后的特征fui,最后输入mlp和softmax层得到情感结果y'i,所述y'i的计算公式为:的计算公式为:h
ef
分别为各层的隐藏层输出,w
ef
和b
ef
为各层的参数。
[0036]
优选的,决策级融合模型用于提取不同模态的特征,并将每个模态的特征单独使用一个分类器进行结果预测,再将每个模态分类器的结果进行融合,得到最终的分类结果。
[0037]
优选的,结果融合采用线性加权求和法,所述决策级融合模型包括以下处理步骤:步骤a:利用数据集中的midi和文本数据,通过midi和文本特征提取的方式提取特征,得到midi特征fi和文本特征ftei;步骤b:将步骤a中获得的两种特征输入各自的mlp和softmax层进行情感分类训练,预测结果分别为和其中和分别表示midi模态和文本模态在第j类情感上的概率预测值;步骤c:将ym和y
t
进行先行加权求和得到融合结果rfi=[rf1,rf2,rf3,rf4];步骤d:将rfj经过softmax层,得到多模态融合的结果y'i。
[0038]
优选的,所述ym、y
t
和rfj的计算公式为:的计算公式为:的计算公式为:
[0039]
其中h
lft
分别为各层的隐藏层输出,w
lft
和b
lft
为各层的参数,表示midi模态分类结果所占的比重,且
[0040]
与现有技术相比,本发明具有如下有益的技术效果:
[0041]
1、本发明通过利用深度学习模型对音乐的midi数据进行情感分类,解决现在常用的低层音频特征是为了其他音频任务而设计的,这些特征与音乐情感之间缺乏直接联系,因此情感识别的效果有限,且可解释性差的问题;从而提高音乐可能会提高情感识别的准确率。
[0042]
2、本发明通过文本数据构建的情感识别模型ermbt,利用音乐的文本数据识别音
乐情感,提出一种社交标签分布分析算法来分析社交标签与情感类别的关系,并利用分析结果构建社交标签特征。基于anew列表构建情感词典,依据该词典识别歌词的情感倾向。将特征提取分为了歌词特征提取和社交标签特征提取两部分。
[0043]
3、本发明通过融合多种模态数据对音乐情感识别进行研究,研究方法主要有特征级融合方法和决策级融合方法;特征级融合的实现较为简单,且只需要一次分类器学习过程,减少了训练时间,并且可以考虑各种模态特征之间的关联性。决策级融合不需要考虑多模态同步的问题,可扩展性较强。
[0044]
4、综上所述,本发明利用决策级融合的思路进行多模态融合能够比特征级融合取得更好的情感分类效果,对音乐文本的情感深度学习,促进深度学习在音乐情感识别中的应用,提高音乐的分析效果,减少人工情感标注的作业量,提高准确率。
附图说明
[0045]
图1是本方案中多模态mer研究框架图;
[0046]
图2是特征级融合情感识别模型示意图;
[0047]
图3是决策级融合情感识别模型示意图;
[0048]
图4为本方案中四种模型的对比结果柱状图。
具体实施方式
[0049]
下文结合附图和具体实施例对本发明的技术方案做进一步说明。
[0050]
实施例
[0051]
如图1-4所示,本发明提出的基于深度学习的音乐多模态数据情感识别方法,包括以下学习步骤:s1:音乐数据的预处理;音频数据清洗:采用python的midi文件处理工具包pretty_midi对数据进行遍历,判断报错的数据为无效音频,删除数据集中无效的音频数据;主音轨提取:第一步删掉不满足条件的音轨,留下的音轨为候选音轨;第二步为每一个候选音轨求六个特征量,之后将六个特征量求和作为该音轨的得分,得分最高者为主音轨;
[0052]
音轨要满足的条件包括以下:(1)通道数不为10;(2)音符数量不少于各音轨音符平均数的一半;(3)音符发声总时长不少于各音轨音符平均发声时间的一半,所述主音轨提取第二步中的六个特征量包括:音符数特征量f
nc
、发声时间特征量f
nd
、平均音高特征量f
p
、平均音强特征量fv、发音面积特征量f
p_d
和响度面积特征量f
v_d
;音符数指的是一条音轨的音符数量,用note-count表示,从midi文件中提取;音高指的是音符频率的高低,用pitch表示,音高可直接从midi文件中提取,发声时间指的是某个音符的音长,用duration表示,可直接从midi文件中提取;音强指的是音符的力度,用intensity表示,音强可直接从midi文件中提取;音符的发音面积指的是该音符音高与发声时间的乘积,音符的响度面积为该音符音强与发声时间的乘积;
[0053]
s2:midi数据的特征提取;ermslm模型的特征提取模块由:旋律特征提取、调性特征提取和手工特征提取三部分组成;
[0054]
旋律特征提取用于完成从第i首音乐的音符音高集pi中提取出旋律特征向量mi;调性特征提取用于从音乐的调性数据中提取调性特征ki,通过预训练的方式让mlp的参数学习到调性与情感的联系,用真正的标签yi来计算损失并反向调参;手工特征提取:从音乐的
主音轨中提取出音符的音高、力度、时值和音乐的速度四种信息来构建手工特征hcfi;
[0055]
调性特征提取在反向调参过程中用到的损失函数为交叉熵损失函数,具体计算公式为:其中yi为真实标签,y
′i为预测标签,n为样本数量;mlp进行预训练后,将其表示为pre-trained mlp,则调性特征的计算方式为:ki=pre-trainedmlp(keyi)。
[0056]
s2中ermslm模型的步骤算法为:
[0057]
输入:包含音符音高集p,音强集i,音长集d,速度bmp和调性key的数据集ms;
[0058]
输出:midi数据的音乐情感识别结果;
[0059]
begin;
[0060]
row1:读取数据集中的每首音乐数据msi;
[0061]
row2:设迭代次数为n,批处理大小为b;
[0062]
row3:for each msi i nms;
[0063]
row4:经过旋律特征提取模块得到旋律特征mi;
[0064]
row5:经过调性特征提取模块得到调性特征ki;
[0065]
row6:经过手动特征提取模块得到手工特征hcfi;
[0066]
row7:将上述三个特征进行连接得到特征向量fi;
[0067]
row8:end for;
[0068]
row9:使用公式得到情感识别结果;
[0069]
row10:for each n in n;
[0070]
row11:for each b in b;
[0071]
row12:使用公式计算误差损失;
[0072]
row13:使用梯度下降优化算法adam更新网络参数;
[0073]
row14:end for;
[0074]
row15:end for;
[0075]
row16:end。
[0076]
s3:文本数据的特征提取;文本数据特征包括歌词特征和社交标签特征,歌词特征提取包括三部分:第一部分是利用预训练好的bert模型获取歌词中每个单词的词向量,并计算每个词向量与四个类别标签词向量的相似度,利用计算的相似度来构建bert情感特征;第二部分是基于anew列表构建包含四种情感的情感词典,并利用该情感词典构建词典情感特征;第三部分是计算歌词中每个单词在四个情感类别上的tf-idf值,将所有单词在某一类别上的tf-idf值累加作为该类别的数值,四个类别的数值构成歌词的tfidf特征;
[0077]
社交标签特征提取包括三步:第一步数据集预处理;数据集预处理用于对原始数据进行整理,以便输入社交标签分布分析算法以获取社交标签分布表;第二步社交标签分布分析算法;根据数据预处理得到的社交标签集tag和标签汇总集t来设计算法,用于分析社交标签与音乐情感的联系,并基于该算法得到社交标签分布表;第三步社交标签特征提取;社交标签特征提取用于提取第i首音乐的社交标签特征ftai=[t1...tc],c为情感类别数,该特征的每个维度对应一个情感类别;社交标签特征ftai中维度tj使用公式
计算,其中n表示第i首音乐所拥有的社交标签数,tsk为社交标签tak在社交标签分布表中的得分;stdtj包含了情感ej相关的重要性排在前α的社交标签;
[0078]
s4:多模态融合:多模态融合用于融合音乐的midi和文本数据来进行多模态音乐情感识别;多模态融合包括特征级融合模型和决策级融合模型。
[0079]
特征级融合模型用于将s2和s3中得到midi特征和文本特征进行连接得到融合后的特征fui,最后输入mlp和softmax层得到情感结果y'i,所述y'i的计算公式为:的计算公式为:h
ef
分别为各层的隐藏层输出,w
ef
和b
ef
为各层的参数。
[0080]
决策级融合模型用于提取不同模态的特征,并将每个模态的特征单独使用一个分类器进行结果预测,再将每个模态分类器的结果进行融合,得到最终的分类结果。
[0081]
结果融合采用线性加权求和法,所述决策级融合模型包括以下处理步骤:步骤a:利用数据集中的midi和文本数据,通过midi和文本特征提取的方式提取特征,得到midi特征fi和文本特征ftei;步骤b:将步骤a中获得的两种特征输入各自的mlp和softmax层进行情感分类训练,预测结果分别为和其中和分别表示midi模态和文本模态在第j类情感上的概率预测值;步骤c:将ym和y
t
进行先行加权求和得到融合结果rfi=[rf1,rf2,rf3,rf4];步骤d:将rfj经过softmax层,得到多模态融合的结果y'i[0082]
ym、y
t
和rfj的计算公式为:的计算公式为:的计算公式为:的计算公式为:
[0083]
其中h
lft
分别为各层的隐藏层输出,w
lft
和b
lft
为各层的参数,表示midi模态分类结果所占的比重,且
[0084]
由于本方案特征级融合方法与决策级融合方法中对对结果影响较大的参数为midi模态分类结果所占的比重因此对进行了不同的取值并进行了实验,实验结果如下表所示:
[0085]
midi模态权重值accuracy0.10.72990.20.73360.30.73720.40.73720.50.67880.60.57660.70.56930.80.57300.90.5730
[0086]
由上述表格所示:当midi模态分类结果的权重逐渐变大时,准确率上升;当权重超过0.4时,准确率下降,因此将权重的取值设为0.3。该实验结果也说明文本模态对于情感的区分度而言更为重要。
[0087]
本实施例中还从整体准确率以及在各个情感类别上的准确率来对比四个模型的性能,四个模型分别为仅使用midi模态模型(ermslm)、仅使用文本模态模型(ermbt)、特征级融合模型(ff-erm)和决策级融合模型(df-erm)的性能,其中df-erm模型的参数取值为0.3;
[0088]
四种模型的对比结果如下所示:
[0089]
模型名称v
+a+
v-a
+
v-a-v
+
a-四类ermslm0.5380.550.63640.50.5693ermbt0.72260.750.84850.63330.7262ff-erm0.71150.70.78790.60.708df-erm0.73720.750.87880.70.7372
[0090]
将上述数据表格转换为柱状图如附图4所示:
[0091]
由上述数据表以及柱状图可以得知:
[0092]
(1)在使用两种单模态数据进行情感识别时,文本模态能够取得更好的情感识别效果,其在四分类上的准确率比midi模态要高15.69%,并且文本模态在每种情感类别上的分类准确率均高于midi模态;
[0093]
(2)在使用多模态数据进行情感识别时,决策级融合的效果比特征级融合的效果要好,其在四分类上的准确率比特征级融合要高2.92%,而特征级融合的效果比仅使用文本模态还要低1.82%;
[0094]
(3)四种分类模型均在v-v-情感类别上取得了最高的情感识别准确率;
[0095]
四种分类模型均在v
+
v-情感类别上取得了最低的情感识别准确率。
[0096]
由此可以得知结论:使用两种单模态数据进行音乐情感识别时,文本模态能够取得更优的效果;使用多模态数据进行音乐情感识别时,决策级融合的多模态情感识别模型能够获得比特征级融合和单模态数据更好的情感识别效果。
[0097]
上述具体实施例仅仅是本发明的一种优选的实施例,基于本发明的技术方案和上述实施例的相关启示,本领域技术人员可以对上述具体实施例做出多种替代性的改进和组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1