基于Wav2vec2.0和BERT的多级融合多模态情感识别的方法及系统
基于wav2vec2.0和bert的多级融合多模态情感识别的方法及系统
技术领域
1.本发明涉及文本和语音的多模态处理领域,具体地,涉及基于wav2vec2.0和bert的多级融合多模态情感识别的方法及系统。
背景技术:
2.人类拥有丰富的情感,情感的表达在生活中是普遍的。人类也拥有很强的能力去辨别这些情感,以产生合适的回应。同样地,拥有辨别情感能力的机器可以使其更接近人类,所以能有很多应用场景。因此情感识别是一个很重要的任务。
3.本发明考虑文本和语音的多模态情感识别任务。这两个模态均可以单独用来识别情感,但两者补充使用可以提升识别的效果。这是因为只有文本没有语音的情况中,模型无法辨别讽刺等情况,如果配合语音信息则有助于判断;如果只有语音没有文本,则很难准确获得用词的情况,而说话人的用词会直接地或间接地反映其情感。对于两个模态,如何分别提取其特征并有效地融合便是多模态情感识别的重点。
4.专利文献cn112489635a,申请号202011397667.1公开了一种基于增强注意力机制的多模态情感识别方法,对语音信息提取了fbank声学特征,文本信息则通过大规模预训练模型bert提取特征向量,在融合阶段分别对两个模态使用了自注意力模型,然后通过点乘获得对齐矩阵,再与模态原有特征进行校准得到更多交互信息,最后又分别将两个模态通过了自注意力模型。上述专利对于文本考虑了强大的预训练模型提取特征,但对语音却只使用了简单的频域特征,这样会导致文本模态性能强,语音性能弱,不利于融合;在融合时只考虑了与本专利共同注意力类似的前期融合步骤,而未考虑到后期融合步骤,而这两个步骤是在不同阶段进行的融合,可以得到不同层次的信息;同时也没有考虑到使用音素级,词级,音节级语音特征来辅助识别,而这些特征都是与韵律相关的,而韵律能反映语句的特性,如情感状态,这是因为它包含了语音信号的抑扬顿挫的信息。
5.专利文献cn113506562a(申请号:202110812076.4)公开了一种基于声学特征与文本情感特征融合的端到端语音合成方法及系统,构建了端到端语音合成模型,可以根据音素序列的嵌入向量获得文本的韵律隐特征,进行音素与mel频谱对齐,通过声学编码器从中分别获取音素级和句子级别的声学特征,并在声学特征中加入隐特征,与此同时从文本中获取文本情感特征;再次将声学特征与文本情感特征进行特征融合,输入到fastspeech2的方差适配器进行特征增强与扩充;最后将方差适配器的输出输入到fastspeech2的mel解码器实现并行解码,得到合成语音的频谱图;使用声码器将频谱图特征映射为声音波形,得到合成的语音。
技术实现要素:
6.针对现有技术中的缺陷,本发明的目的是提供一种基于wav2vec2.0和bert的多级融合多模态情感识别的方法及系统。
7.根据本发明提供的一种基于wav2vec2.0和bert的多级融合多模态情感识别的方法,包括:
8.步骤s1:利用wav2vec 2.0模型提取输入语音的帧级语音特征向量;
9.步骤s2:利用输入文本与输入语音对帧级语音特征向量进行词级强制对齐得到词级语音特征向量;
10.步骤s3:利用输入文本与输入语音对帧级语音特征向量进行音素级强制对齐得到音素级语音特征向量;
11.步骤s4:利用输入文本与输入语音对帧级语音特征向量进行音节级强制对齐得到音节级语音特征向量;
12.步骤s5:利用bert模型提取输入文本的文本特征向量;
13.步骤s6:使用语音特征向量,词级语音特征向量,音素级语音特征向量,音节级语音特征向量分别与文本特征向量分别通过共同注意力模型后拼接得到特征向量,将拼接得到的特征向量通过线性模型进行融合得到前期融合各个情感类别的概率分布;
14.步骤s7:使用语音特征向量,词级语音特征向量,音素级语音特征向量,音节级语音特征向量以及文本特征向量分别通过线性模型得到更新后的特征向量,对更新后的特征向量求平均,再通过线性模型进行融合得到后期融合各个情感类别的概率分布;
15.步骤s8:对前期融合各个情感类别的概率分布和后期融合各个情感类别的概率分布求平均,得到前后期组合融合概率分布;
16.所述输入文本是输入的语音对应的文本形式内容。
17.优选地,所述步骤s1采用:
18.固定wav2vec 2.0模型参数,将语音输入wav2vec 2.0模型,提取wav2vec 2.0模型中预设数量的transformer编码层每层的隐状态,并对不同层求加权平均,公式如下:
[0019][0020]
其中,表示输入的第n个语音样本;w表示wav2vec 2.0模型;f表示帧级特征;
[0021][0022]
其中,表示帧级语音特征向量的第l层的权重,表示u
f,n
的第l层的第f帧;ln表示层归一化操作。
[0023]
优选地,所述步骤s2采用:利用输入文本与输入音频得到词级强制对齐标注,利用词级强制对齐标注分割帧级语音特征向量,得到词级语音特征向量,并对不同层求加权平均,公式如下:
[0024][0025]
其中,表示第n个样本的第l层词级语音特征向量的第k部分,s表示起始帧,e表示结束帧,表示u
f,n
的第l层的第f帧;
[0026][0027]
其中,表示词级语音特征向量的第l层的权重;ln表示层归一化操作。
[0028]
优选地,所述步骤s3采用:利用输入文本与输入音频得到音素级强制对齐标注,利用音素级强制对齐标注分割帧级语音特征向量,得到音素级语音特征向量,并对不同层求加权平均,公式如下:
[0029][0030]
其中,表示第n个样本的第l层音素级语音特征向量的第k部分;s表示起始帧,e表示结束帧;表示u
f,n
的第l层的第f帧;
[0031][0032]
其中,表示音素级语音特征向量的第l层的权重;ln表示层归一化操作。
[0033]
优选地,所述步骤s4采用:利用输入文本与输入音频得到音节级强制对齐标注,利用音节级强制对齐标注分割帧级语音特征向量,得到音节级语音特征向量,并对不同层求加权平均,公式如下:
[0034][0035]
其中,表示第n个样本的第l层音节级语音特征向量的第k部分;s表示起始帧;e表示结束帧;表示u
f,n
的第l层的第f帧;
[0036][0037]
其中,表示词音节语音特征向量的第l层的权重;ln表示层归一化操作。
[0038]
优选地,所述步骤s5采用:固定bert模型参数,将文本输入bert模型,提取bert模型中预设数量的transformer编码层每层的隐状态,并对不同层求加权平均,公式如下:
[0039][0040]
其中,表示输入的第n个文本样本;b表示bert模型;t表示文本特征;
[0041][0042]
其中,表示文本特征向量的第l层的权重;表示u
t,n
的第l层的第k部分;ln表示层归一化操作。
[0043]
优选地,所述步骤s6采用:
[0044]
步骤s6.1:分别将音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量与文本特征向量分别通过四个共同注意力模型并通过全局平均,得到了融合文本信息的音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量;
[0045]
步骤s6.2:拼接融合文本信息的音素级语音特征向量,词级语音特征向量,音节级语音特征向量以及帧级语音特征向量,并通过线性模型进行融合并输出预测概率分布;
[0046][0047]
其中,代表拼接操作;cn表示含有文本,四种语音信息的特征向量;c
p,n
表示第n个样本融合文本信息的音素级语音特征向量,c
w,n
表示表示第n个样本融合文本信息的词级语音特征向量,c
s,n
表示表示第n个样本融合文本信息的音节级语音特征向量,c
f,n
表示表示第n个样本融合文本信息的帧级语音特征向量;
[0048]
拼接后送入线性模型:
[0049]gn
=ln(relu(w7cn+b7)+cn)
[0050][0051]
其中,gn表示线性变化后的含有文本与四种语音信息的特征向量,w7,w8表示权重参数;b7,b8表示偏置参数;表示前期融合步骤得到的情感预测概率分布。
[0052]
优选地,所述步骤s7采用:
[0053]
步骤s7.1:分别将音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量以及文本特征向量通过线性模型得到更新的音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量以及文本特征向量;
[0054][0055][0056]
其中,p,w,s,f,t分别代表音素级,词级,音节级,帧级,文本;relu代表relu非线性函数,w和b均为参数;表示第n个样本模态i一次线性变化后的特征向量的第k部分,表示表示第n个样本模态i二次线性变化后的特征向量的第k部分;
[0057]
步骤s7.2:分别对所述音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,文本特征向量使用全局平均来融合不同部分的特征得到代表所有部分的音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,文本特征向量;
[0058][0059]
其中,l
i,n
为句长,p,w,s,f,t分别代表音素级,词级,音节级,帧级,文本;
[0060]
步骤s7.3:将所述音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,文本特征向量通过线性模型进行融合并输出预测概率分布;
[0061]
[0062]
其中w和b均为参数,p,w,s,f,t分别代表音素级,词级,音节级,帧级,文本;softmax代表softmax函数;表示后期融合步骤得到的情感预测概率分布,为权重参数,表示偏置参数。
[0063]
优选地,所述步骤s8采用:
[0064]
所述前后期组合融合步骤为取前期融合步骤输出与后期融合步骤输出平均值,公式如下:
[0065][0066]
根据本发明提供的一种基于wav2vec2.0和bert的多级融合多模态情感识别的系统,包括:
[0067]
模块m1:利用wav2vec 2.0模型提取输入语音的帧级语音特征向量;
[0068]
模块m2:利用输入文本与输入语音对帧级语音特征向量进行词级强制对齐得到词级语音特征向量;
[0069]
模块m3:利用输入文本与输入语音对帧级语音特征向量进行音素级强制对齐得到音素级语音特征向量;
[0070]
模块m4:利用输入文本与输入语音对帧级语音特征向量进行音节级强制对齐得到音节级语音特征向量;
[0071]
模块m5:利用bert模型提取输入文本的文本特征向量;
[0072]
模块m6:使用语音特征向量,词级语音特征向量,音素级语音特征向量,音节级语音特征向量分别与文本特征向量分别通过共同注意力模型后拼接得到特征向量,将拼接得到的特征向量通过线性模型进行融合得到前期融合各个情感类别的概率分布;
[0073]
模块m7:使用语音特征向量,词级语音特征向量,音素级语音特征向量,音节级语音特征向量以及文本特征向量分别通过线性模型得到更新后的特征向量,对更新后的特征向量求平均,再通过线性模型进行融合得到后期融合各个情感类别的概率分布;
[0074]
模块m8:对前期融合各个情感类别的概率分布和后期融合各个情感类别的概率分布求平均,得到前后期组合融合概率分布;
[0075]
所述输入文本是输入的语音对应的文本形式内容。
[0076]
与现有技术相比,本发明具有如下的有益效果:
[0077]
1、本发明探索了均使用大规模预训练模型来提取语音和文本的特征,将语音和文本均看作多模态情感识别的主模态,而非仅将语音看作是文本的辅助模态。语音和文本均获得强大的特征,是进行有效的融合的前提;
[0078]
2、本发明提出不仅使用常规帧级语音特征,也利用强制对齐后的信息得到音节级,音素级,词级语音特征向量来辅助情感识别任务。这三种语音特征向量与韵律相关,而韵律能传递语句的特性,如情感状态,这是因为它包含了语音信号的抑扬顿挫的信息,因此适合作为情感识别的辅助信息;
[0079]
3、本发明对于上述多模态的特征,提出了基于不同层次的前后期组合融合方法,这种方法不仅使用了基于共同注意力的前期融合方法,也使用了后期融合方法,而这两种方法从不同层次融合了两种模态,因此得到的信息的角度有所不同,本发明组合其信息,得
到了更为完整的融合的结果,提升了多模态情感识别的效果。
附图说明
[0080]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0081]
图1为本发明实施例中方法流程图;
[0082]
图2为本发明实施例中系统原理图;
[0083]
图3为本发明实施例中共同注意力模型结构图。
具体实施方式
[0084]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
[0085]
实施例1
[0086]
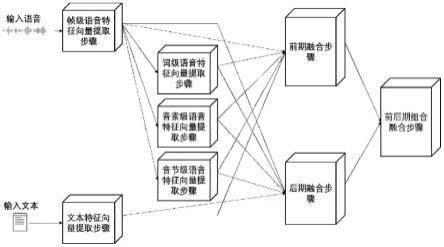
根据本发明提供的一种基于wav2vec2.0和bert的多级融合多模态情感识别的方法,如图1所示,包括:
[0087]
帧级语音特征向量提取步骤:对输入的语音,使用大规模语音预训练模型wav2vec2.0提取帧级语音特征向量;
[0088]
词级语音特征向量提取步骤:对所述帧级语音特征向量进行词级强制对齐,得到词级语音特征向量;
[0089]
音素级语音特征向量提取步骤:对所述帧级语音特征向量进行音素级强制对齐,得到音素级语音特征向量;
[0090]
音节级语音特征向量提取步骤:对所述音节级语音特征向量进行音节级强制对齐,得到音节级语音特征向量;
[0091]
文本特征向量提取步骤:对输入的文本,使用大规模文本预训练模型bert提取文本特征向量;
[0092]
前期融合步骤:使用所述语音帧级特征向量,语音词级特征向量,语音音素级特征向量,语音音节级特征向量分别与文本特征向量通过共同注意力模型,拼接得到的特征向量后通过线性模型,得到前期融合各个情感类别的概率分布。
[0093]
后期融合步骤:使用所述语音帧级特征向量,语音词级特征向量,语音音素级特征向量,语音音节级特征向量,文本特征向量分别通过线性模型,并对得到的特征向量求平均,得到后期融合各个情感类别的概率分布。
[0094]
前后期组合融合步骤:对所述前期融合概率分布和后期融合概率分布求平均,得到前后期组合融合概率分布。
[0095]
具体地,所述帧级语音特征向量提取步骤包括:固定wav2vec 2.0模型参数,将语音输入模型,提取wav2vec 2.0模型中12层transformer编码层每层的隐状态,并对不同层求加权平均,公式如下:
[0096]
[0097]
其中,代表输入的第n个语音样本,w代表wav2vec 2.0模型,f代表帧级特征。
[0098][0099]
其中,代表帧级语音特征向量的第l层的权重,这个权重是可学习的,是u
f,n
的第l层的第f帧。
[0100]
具体地,所述词级语音特征向量提取步骤包括:利用输入文本与输入音频得到词级强制对齐标注,利用词级强制对齐标注分割帧级语音特征向量,得到词级语音特征向量,并对不同层求加权平均,公式如下:
[0101][0102]
其中是第n个样本的第l层词级语音特征向量的第k部分,s是起始帧,e是结束帧,是u
f,n
的第l层的第f帧。
[0103][0104]
其中代表词级语音特征向量的第l层的权重,这个权重是可学习的。ln代表层归一化操作。
[0105]
具体地,所述音素级语音特征向量提取步骤包括:利用输入文本与输入音频得到音素级强制对齐标注,利用音素级强制对齐标注分割帧级语音特征向量,得到音素级语音特征向量,并对不同层求加权平均,公式如下:
[0106][0107]
其中是第n个样本的第l层音素级语音特征向量的第k部分,s是起始帧,e是结束帧,是u
f,n
的第l层的第f帧。
[0108][0109]
其中代表音素级语音特征向量的第l层的权重,这个权重是可学习的。ln代表层归一化操作。
[0110]
具体地,所述音节级语音特征向量提取步骤包括:利用输入文本与输入音频得到音节级强制对齐标注,利用音节级强制对齐标注分割帧级语音特征向量,得到音节级语音特征向量,并对不同层求加权平均,公式如下:
[0111]
[0112]
其中是第n个样本的第l层音节级语音特征向量的第k部分,s是起始帧,e是结束帧,是u
f,n
的第l层的第f帧。
[0113][0114]
其中代表词音节语音特征向量的第l层的权重,这个权重是可学习的。ln代表层归一化操作。
[0115]
具体地,所述文本特征向量提取步骤包括:固定bert模型参数,将文本输入模型,提取bert模型中12层transformer编码层每层的隐状态,并对不同层求加权平均,公式如下:
[0116][0117]
其中,代表输入的第n个文本样本,b代表bert模型,t代表文本特征。
[0118][0119]
其中代表文本特征向量的第l层的权重,这个权重是可学习的,是u
t,n
的第l层的第k部分,ln代表层归一化操作。
[0120]
具体地,所述后期融合步骤包括:所述后期融合步骤分别将所述音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,文本特征向量通过线性模型得到更新的音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,文本特征向量,公式如下:
[0121][0122][0123]
其中p,w,s,f,t分别代表音素级,词级,音节级,帧级,文本。relu代表relu非线性函数,w和b均为参数,是可学习的。
[0124]
然后分别对所述音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,文本特征向量使用全局平均来融合不同部分的特征得到代表所有部分的音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,文本特征向量,公式如下:
[0125][0126]
其中l
i,n
为句长,p,w,s,f,t分别代表音素级,词级,音节级,帧级,文本。
[0127]
然后将所述音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,文本特征向量通过线性模型进行融合并输出预测概率分布,公式如下:
[0128]
[0129]
其中w和b均为参数,是可学习的,p,w,s,f,t分别代表音素级,词级,音节级,帧级,文本。softmax代表softmax函数。
[0130]
具体地,所述前期融合步骤包括:分别将所述音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量与文本特征向量通过四个共同注意力模型并通过全局平均,得到了融合文本信息的音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,公式如下:
[0131]
在每个共同注意力模型中包含三个相同的前后相连的共同注意力层,共同注意力模型如图3所示。共同注意力层的输入为一种语音特征向量与文本特征向量。分别将语音特征向量与文本特征向量作为多头注意力模型的q值送入两个多头注意力模型中,不失一般性的,这里介绍单头注意力模型:
[0132][0133][0134][0135]
其中i和j代表它们来自不同模态。然后可得到单头注意力模型的输出:
[0136][0137]
其中d代表特征的维度。多头注意力模型执行这个过程多次,目的是从不同的表征子空间中学到更多的信息。两个多头注意力模型的输出会分别通过两次层归一化层,全连接层。共同注意力层重复三次后得到共同注意力模型的输出,再通过全局平均得到c
i,n
,其中i∈{p,w,s,f},p,w,s,f,t分别代表音素级,词级,音节级,帧级。全局平均的公式同公式1。
[0138]
然后拼接所述音素级语音特征向量,词级语音特征向量,音节级语音特征向量,帧级语音特征向量,并通过线性模型进行融合并输出预测概率分布,公式如下:
[0139][0140]
其中代表拼接操作。拼接后送入线性模型:
[0141]gn
=ln(relu(w7cn+b7)+cn)
[0142][0143]
具体地,所述前后期组合融合步骤为取前期融合步骤输出与后期融合步骤输出平均值,公式如下:
[0144][0145]
根据本发明的第二个方面,提供一种基于wav2vec 2.0和bert的多级融合多模态情感识别的系统,如图2所示,包括:
[0146]
帧级语音特征向量提取模块:对输入的语音,使用大规模语音预训练模型wav2vec2.0提取帧级语音特征向量;
[0147]
词级语音特征向量提取模块:对所述帧级语音特征向量进行词级强制对齐,得到词级语音特征向量;
[0148]
音素级语音特征向量提取模块:对所述帧级语音特征向量进行音素级强制对齐,得到音素级语音特征向量;
[0149]
音节级语音特征向量提取模块:对所述音节级语音特征向量进行音节级强制对齐,得到音节级语音特征向量;
[0150]
文本特征向量提取模块:对输入的文本,使用大规模文本预训练模型bert提取文本特征向量;
[0151]
前期融合模块:使用所述语音帧级特征向量,语音词级特征向量,语音音素级特征向量,语音音节级特征向量分别与文本特征向量通过共同注意力模型,拼接得到的特征向量后通过线性模型,得到前期融合各个情感类别的概率分布。
[0152]
后期融合模块:使用所述语音帧级特征向量,语音词级特征向量,语音音素级特征向量,语音音节级特征向量,文本特征向量分别通过线性模型,并对得到的特征向量求平均,得到后期融合各个情感类别的概率分布。
[0153]
前后期组合融合模块:对所述前期融合概率分布和后期融合概率分布求平均,得到前后期组合融合概率分布。
[0154]
本发明采用了交叉熵作为训练损失函数,adam优化器作为优化器,前期融合步骤使用学习率为5e-5,后期融合步骤使用学习率为1e-3,批量大小为32,在训练中使用了早停。dropout层被加到了除了最后的线性层外的所有线性层来防止过拟合,概率为0.2。大规模预训练模型分别使用了wav2vec 2.0-base与bert-baseun-cased模型,其特征维度均为768维。
[0155]
综上,本发明提供了一种基于wav2vec2.0和bert的多级融合多模态情感识别的方法。本发明探索了均使用大规模预训练模型来提取语音和文本的特征,将语音和文本均看作多模态情感识别的主模态,而非仅将语音看作是文本的辅助模态。语音和文本均获得强大的特征,是进行有效的融合的前提;本发明提出不仅使用常规帧级语音特征,也利用强制对齐后的信息得到音节级,音素级,词级语音特征向量来辅助情感识别任务。这三种语音特征向量与韵律相关,而韵律能传递语句的特性,如情感状态,这是因为它包含了语音信号的抑扬顿挫的信息,因此适合作为情感识别的辅助信息;本发明对于上述多模态的特征,提出了基于不同层次的前后期组合融合方法,这种方法不仅使用了基于共同注意力的前期融合方法,也使用了后期融合方法,而这两种方法从不同层次融合了两种模态,因此得到的信息的角度有所不同,本发明组合其信息,得到了更为完整的融合的结果,提升了多模态情感识别的效果。
[0156]
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
[0157]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1