一种基于声波特性的键盘指纹身份信息安全认证方法
1.本发明属于键盘指纹技术领域,涉及一种基于声波特性的键盘指纹身份信息安全认证方法。
背景技术:
2.近年来,互联网、物联网、移动终端、云计算、大数据等相关技术的飞速发展带动了信息产业的发展,我国网络身份认证信息安全发展迅猛。
3.身份认证是信息安全体系的重要组成部分,它是保护信息系统安全的第一道大门,当前常用的身份信息安全认证方法有密码、证件、指纹、人脸识别、虹膜等。
4.目前,在身份信息安全认证领域,由于与用户个人身份信息的可分离性,常常会造成丢失、伪造、盗用、被破译的现象,因此像密码、证件这样的传统个人身份信息安全认证具有一定的局限性,而目前生物特征识别像指纹、人脸识别、虹膜等就受到了更为广泛的应用,但是目前应用的生物特征也相对容易被为伪造,已经有研究人员伪造出指纹、人脸识别、虹膜等生物特征攻破现有安全认证系统。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种基于声波特性的键盘指纹身份信息安全认证方法,该方法利用sk-30麦克风对用户通过键盘输入的密码声波进行采集,通过降噪方法最大限度保留键盘指纹特征后,将wav音频文件预处理训练转换成频谱图,读入pytorch框架通过resnet34网络训练,测试数据再根据生成的训练模型进行分类,最终实现基于声波特性的键盘指纹身份信息安全认证。
6.为达到上述目的,本发明提供如下技术方案:
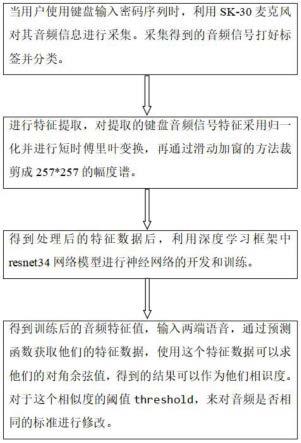
7.一种基于声波特性的键盘指纹身份信息安全认证方法,该方法使用麦克风采集键盘输入密码信息并据此加强身份安全认证,该方法具体包括以下步骤:s1、通过麦克风采集用户使用键盘打字时发出的声音,进行音频信号特征提取;s2、对提取的音频信号特征进行分析处理,进行按键检测;s3、根据不同按键产生的声音信号的轻微区别,基于分类技术方案实现细粒度击键识别,完成键盘指纹身份信息安全认证。
8.进一步,在步骤s1中,首先创建数据列表,以格式为《音频文件路径\t分类标签》创建这个列表,便于之后的读取,音频分类标签是指键盘输入密码的唯一id,不同的音频数据集,通过编写对应的生成数据列表的函数,把这些数据集都写在同一个数据列表中。
9.进一步,在步骤s2中,对音频信号进行数据分割,基于击键声音的波形呈现两个不同的峰值:手指按下峰值和释放峰值,只使用按下峰值来分割数据,设置如下机制:
10.1)均值标准化,使其均方根为1,x
scale
=x-u/s,其中x为要归一化的值,x
scale
为归一化之后的值,u为音频的平均值,s为音频样本的标准差;
11.2)然后,将10毫秒小窗口上的fft系数相加,以获得每个窗口的能量;当窗口的能量高于某个阈值时,检测到一个按压事件,这是一个可调参数。
12.进一步,在步骤s2中,利用librosa计算音频特征,进行stft短时傅里叶变换以及数据裁剪,librosa是python中的一个工具包,该库主要是用于音频处理,对于机器学习音频分类的初步处理工作比较有用,短时傅里叶变换公式为:
[0013][0014]
其中,w是窗函数,用于决定计算傅里叶变换的时域信号长度,当n取不同值时,窗函数w(n-m)沿着x(m)滑动,n代表时域第几个采样点的离散变量,ω代表频率的连续变量,返回得到一个的矩阵;然后调用librosa中的magphase将之前得到的复数矩阵分离成幅值和时间,再对幅值和时间进行随机裁剪最终得到257*257的幅度谱,其中shape代表返回矩阵的规格大小,nfft代表经过快速傅里叶变换的点数,和采样频率有关系,一般应为2的n次方,t代表时域信号长度,magphase代表声谱图。
[0015]
进一步,在步骤s3中,具体包括:
[0016]
训练模型:使用的是变形后的resnet34模型,resnet34代表残差网络34层,模型使用残差结构的思想:数据输入层设置为[none,1,257,257],此大小就是stft幅度谱的shape,每训练一轮结束后执行一次模型评估,计算模型的准确率和观察模型的收敛情况,每一轮训练结束后保存一次模型,分别保存了可以恢复训练的模型参数,也可作为预训练模型参数;还保存预测模型,用于之后预测;
[0017]
所述模型采用的优化算法是sgd随机梯度下降法,公式为其中代表计算梯度,θ代表参数,xi;yi一起代表每个样本,f(θ;xi;yi)表示为每个样本的损失函数,为正则项;损失函数使用的是交叉熵损失函数,公式为m表示分类数量,y
ic
表示符号函数,p
ic
表示观测样本i属于类别c的预测概率,l代表损失loss,n代表当前batch中的样本量;
[0018]
训练完成后,使用预测模型来预测测试集中的音频特征,然后使用音频特征进行两两对比,阈值从0到1,步长为0.01进行控制,找到最佳的阈值并且计算准确率,计算准确度的方法是使用余弦相似度其中cosθ表示余弦相似度,ai代表a向量,bi代表b向量;在编写模型的时候,模型是有两个输出的,第一个是模型的分类输出,第二个是音频特征输出,所以在这里要输出的是音频的特征值,有了音频的特征值就可以进行声纹认证了。
[0019]
进一步,输入两个语音,通过预测函数获取他们的特征数据,使用这个特征数据可以求他们的对角余弦值,得到的结果可以作为他们相识度。对于这个相似度的阈值threshold,来对音频是否相同的标准进行修改。
[0020]
本发明的有益效果在于:
[0021]
本发明提供的方法在传统个人身份信息安全认证方式上加上一层保护机制,更加安全,更难伪造,不仅有助于经常使用键盘的用户提升自身的安全意识以及隐私保护,也对键盘研发的工作人员有一定的启发;另一方面,pytorch是目前深度学习的主流框架,使用pytorch来对数据进行训练,形式非常灵活,更易搭建好神经网络,会使得系统的整体性能和准确率大大提高,更加方便用户开发,此外通过resnet34网络模型训练数据分类更加精
准,识别率大大提升。
[0022]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0023]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0024]
图1为本发明所述方法的系统流程图。
具体实施方式
[0025]
下面结合附图对本发明技术方案进行详细说明。
[0026]
图1为本发明所述方法的系统流程图,在本实施例中,该方法使用sk-30麦克风采集用户通过键盘输入的密码声波,通过降噪方法最大限度保留键盘指纹特征后,将wav音频文件预处理训练转换成频谱图,读入pytorch框架通过resnet34网络训练,测试数据再根据生成的训练模型进行分类,通过分类的类别从而判定密码正误,最终实现基于声波特性的键盘指纹身份信息安全认证。该方法的主要步骤如下所示:
[0027]
s1、通过麦克风采集用户使用键盘打字时发出的声音,进行音频信号特征提取;
[0028]
步骤s1中,首先创建数据列表,以格式为《音频文件路径\t分类标签》创建这个列表,便于之后的读取,音频分类标签是指键盘输入密码的唯一id,不同的音频数据集,通过编写对应的生成数据列表的函数,把这些数据集都写在同一个数据列表中,这里的数据列表可以理解为测试集。
[0029]
s2、对提取的音频信号特征进行分析处理,从而进行按键检测;在步骤s2中,对音频信号进行数据分割,基于击键声音的波形呈现两个不同的峰值:手指按下峰值和释放峰值,只使用按下峰值来分割数据,因为按下峰值会比释放峰值更明显。为了自动隔离击键,在分析处理的时候设置如下机制:
[0030]
1)均值标准化,使其均方根为1,x
scale
=x-u/s,其中x为要归一化的值,x
scale
为归一化之后的值,u为音频的平均值,s为音频样本的标准差;
[0031]
2)然后,将10毫秒小窗口上的fft系数相加,以获得每个窗口的能量;当窗口的能量高于某个阈值时,检测到一个按压事件,这是一个可调参数。
[0032]
进一步,在步骤s2中,利用librosa计算音频特征,进行stft短时傅里叶变换以及数据裁剪,librosa是python中的一个工具包,该库主要是用于音频处理,对于机器学习音频分类的初步处理工作比较有用,短时傅里叶变换公式为:
[0033][0034]
其中,w是窗函数,用于决定计算傅里叶变换的时域信号长度,当n取不同值时,窗函数w(n-m)沿着x(m)滑动,n代表时域第几个采样点的离散变量,ω代表频率的连续变量,返回得到一个的矩阵;然后调用librosa中的magphase将之前得到的复数矩
阵分离成幅值和时间,再对幅值和时间进行随机裁剪最终得到257*257的幅度谱,其中shape代表返回矩阵的规格大小。nfft代表经过快速傅里叶变换的点数,和采样频率有关系,一般应该是2的n次方。t代表时域信号长度,magphasee代表声谱图。
[0035]
s3、根据不同按键产生的声音信号的轻微区别,基于分类技术方案实现细粒度击键识别,完成键盘指纹身份信息安全认证。s3具体包括训练模型:使用的是变形后的resnet34模型,resnet34代表残差网络34层,resnet34在pytorch环境下搭建,模型使用残差结构的思想:数据输入层设置为[none,1,257,257],此大小就是stft幅度谱的shape,每训练一轮结束后执行一次模型评估,计算模型的准确率和观察模型的收敛情况,每一轮训练结束后保存一次模型,分别保存了可以恢复训练的模型参数,也可作为预训练模型参数;还保存预测模型,用于之后预测;
[0036]
所述模型采用的优化算法是sgd随机梯度下降法,公式为其中代表计算梯度,θ代表参数,xi;yi一起代表每个样本,f(θ;xi;yi)表示为每个样本的损失函数,为正则项;损失函数使用的是交叉熵损失函数,公式为m表示分类数量,y
ic
表示符号函数,p
ic
表示观测样本i属于类别c的预测概率,l代表损失loss,n代表当前batch中的样本量;
[0037]
训练完成后,使用预测模型来预测测试集中的音频特征,然后使用音频特征进行两两对比,阈值从0到1,步长为0.01进行控制,找到最佳的阈值并且计算准确率,计算准确度的方法是使用余弦相似度其中cosθ表示余弦相似度,ai代表a向量,bi代表b向量;在编写模型的时候,模型是有两个输出的,第一个是模型的分类输出,第二个是音频特征输出,所以在这里要输出的是音频的特征值,有了音频的特征值就可以进行声纹认证了。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1