基于PDAN的跨库语音情感识别方法及装置
基于pdan的跨库语音情感识别方法及装置
技术领域
1.本发明涉及语音情感识别技术,尤其涉及一种基于渐进式分布适配神经网络的跨库 语音情感识别方法及装置
背景技术:
2.语音是人类日常生活中的一种主要交流方式,其中包含着丰富的情感信息。想象一 下,如果计算机能够从人类的语音信号中理解情绪状态,那么人机交互无疑会更加自然。 因此,从语音信号中自动识别情绪状态的研究,例如,语音情感识别(ser)在情感计 算、人机交互和语音信号处理领域引起了广泛关注。在过去的几十年中,已经提出了许 多性能良好的ser方法,并在广泛使用的公开可用的语音情感数据库上取得了可喜的 性能。然而,值得注意的是,他们中的大多数没有考虑训练和测试语音信号可能由不同 相同的麦克风或在不同的环境下记录的现实场景。在这种情况下,训练和测试语音样本 之间可能存在特征分布不匹配,因此这些原本表现良好的ser方法的性能可能会急剧 下降,这就带来了ser中一项有意义且更具挑战性的任务,即跨库ser。与传统的 ser不同,跨库ser中的标记训练和未标记测试样本来自不同的语音数据库库。遵循 跨库ser中的命名约定,将在本文件中将训练和测试样本/数据库/特征集称为源集和 目标集。
技术实现要素:
3.发明目的:本发明针对现有技术存在的问题,提供一种识别准确度更高的基于渐进 式分布适配神经网络的跨库语音情感识别方法。
4.技术方案:本发明所述的基于渐进式分布适配神经网络的跨库语音情感识别方法包 括:
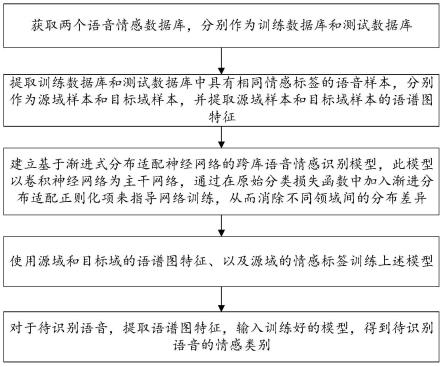
5.(1)获取两个语音情感数据库,分别作为训练数据库和测试数据库;
6.(2)提取训练数据库和测试数据库中具有相同情感标签的语音样本,分别作为源 域样本和目标域样本,并提取源域样本和目标域样本的语谱图特征;
7.(3)建立基于渐进式分布适配神经网络的跨库语音情感识别模型,此模型以卷积 神经网络为主干网络,通过在原始分类损失函数中加入渐进分布适配正则化项来指导网 络训练,从而消除不同领域间的分布差异;
8.(4)使用源域和目标域的语谱图特征、以及源域的情感标签训练上述模型;
9.(5)对于待识别语音,提取语谱图特征,输入训练好的模型,得到待识别语音的 情感类别。
10.进一步的,步骤(2)具体包括:
11.(2-1)提取训练数据库和测试数据库中具有相同情感标签的语音样本,分别作为源 域样本和目标域样本;
12.(2-2)对源域样本和目标域样本依次进行分帧、加窗预处理;
13.(2-3)对预处理后的样本进行短时离散傅里叶变换,得到语谱图特征。
14.进一步的,所述基于渐进式分布适配神经网络的跨库语音情感识别模型具体包括:
15.卷积神经网络,包括依次连接的若干层卷积层、第一全连接层、第二全连接层和第 三全连接层;
16.损失计算模块,分别包括用于计算情感辨别损失的第一损失计算单元、用于计算源 域特征和目标域特征之间的边缘分布差异损失的第二损失计算单元、用于计算细粒度的 情感标签信息引导的条件分布适配损失的第三损失计算单元、用于计算粗糙的情绪类感 知条件分布适应正则化项的第四损失计算单元以及用于计算四项损失之和的总损失计 算单元。
17.进一步的,所述第一损失计算单元连接第三全连接层,具体用于基于下式计算情感 辨别损失:
[0018][0019]
式中,是情感辨别损失,是连接源域样本语谱图特征及其相应情感标签的交 叉熵损失,ns表示源域样本数目,g1、g2和g3分别表示第一全连接层、第二全连接层、 第三全连接层的参数,表示第i个源域样本的语谱图特征,f表示卷积神经网络的参 数,表示第i个源域样本的情感标签。
[0020]
进一步的,所述第二损失计算单元连接所述第一全连接层,用于基于下式计算边缘 分布差异损失:
[0021][0022]
式中,是边缘分布损失,ns表示源域样本数目,n
t
表示目标域样本数目,g1表 示第一全连接层参数,表示第i个源域样本的语谱图特征,表示第i个目标域样本 的语谱图特征,f表示卷积神经网络的参数,φ(
·
)是核映射算子,代表再生核希尔 伯特空间。
[0023]
进一步的,所述第三损失计算单元连接所述第三全连接层,用于基于下式计算条件 分布适配损失:
[0024][0025]
式中,表示条件分布适配损失,和分别表示源域和目标域属于第j类情 感的第i个样本,c表示情感类别数,和分别表示源域和目标域中属于第j类情 感样本数,且满足和ns表示源域样本数目,n
t
表 示目标域样本数目,f表示卷积神经网络的参数,g1、g2和g3分别表示第一全连接层、 第二全连接层、第三全连接层的参数,代表再生核希尔伯特空间。
[0026]
进一步的,所述第四损失计算单元连接所述第二全连接层,用于基于下式计算情
绪 类感知条件分布适应正则化项:
[0027][0028]
式中,cr是粗糙情感类别数,cr小于情感类别数c,和分别表示源域和目 标域属于第j类情感的第i个样本,φ(
·
)是核映射算子,和分别表示源域和目标 域中属于第j类情感样本数,且满足和ns表示 源域样本数目,n
t
表示目标域样本数目,f表示卷积神经网络的参数,g1、g2分别表示 第一全连接层、第二全连接层的参数,代表再生核希尔伯特空间。
[0029]
进一步的,所述总损失计算单元用于按照下式计算总损失:
[0030][0031]
式中,为总损失,λ1、λ2、和λ3是使得最小的权衡系数。
[0032]
进一步的,步骤(4)具体包括:
[0033]
(4-1)对跨库语音情感识别模型的参数进行随机初始化;
[0034]
(4-2)预测目标域样本的伪情感标签
[0035]
(4-3)根据计算总损失
[0036]
(4-4)根据总损失使用经典的随机梯度下降优化算法更新跨库语音情感识别 模型的参数;
[0037]
(4-5)判断总损失是否收敛,若不收敛,则根据当前跨库语音情感识别模型的参数, 更新伪情感标签并返回步骤(4-3),若收敛则网络训练完成。
[0038]
本发明所述的基于渐进式分布适配神经网络的跨库语音情感识别装置,包括处理器 及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现 上述方法。
[0039]
有益效果:本发明与现有技术相比,其显著优点是:
[0040]
1、本发明提出了一种新的端到端深度迁移学习模型,称为渐进式分布适配神经网 络(progressive distribution adapted neural networks,pdan),以应对跨库ser任务。 与现有的大多数方法不同,pdan可以利用深度神经网络和语音频谱的非线性映射能力, 直接从原始语音信号中学习跨库不变和情感判别语音特征。
[0041]
2、本发明通过向不同的全连接层添加三个不同的mmd损失函数来逐步适配源语 音样本和目标语音样本之间的特征分布;
[0042]
3、本发明准确性更高。
附图说明
[0043]
图1是本发明提供的基于渐进式分布适配神经网络的跨库语音情感识别方法的一个 实施例的流程示意图;
[0044]
图2是本发明提供的的渐进式分布适配神经网络的结构图。
具体实施方式
[0045]
本实施例提供了一种基于渐进式分布适配神经网络的跨库语音情感识别方法,如图 1所示,包括:
[0046]
(1)获取两个语音情感数据库,分别作为训练数据库和测试数据库。
[0047]
(2)提取训练数据库和测试数据库中具有相同情感标签的语音样本,分别作为源 域样本和目标域样本,并提取源域样本和目标域样本的语谱图特征。
[0048]
该步骤包括:
[0049]
(2-1)提取训练数据库和测试数据库中具有相同情感标签的语音样本,分别作为源 域样本和目标域样本;
[0050]
(2-2)对源域样本和目标域样本依次进行分帧、加窗预处理;
[0051]
(2-3)对预处理后的样本进行短时离散傅里叶变换,得到语谱图特征。
[0052]
(3)建立基于渐进式分布适配神经网络的跨库语音情感识别模型,此模型以卷积 神经网络为主干网络,通过在原始分类损失函数中加入渐进分布适配正则化项来指导网 络训练,从而消除不同领域间的分布差异。
[0053]
本发明建立的基于渐进式分布适配神经网络的跨库语音情感识别模型如图2所示, 具体包括:卷积神经网络和损失计算模块,卷积神经网络具体为alexnet,包括依次连 接的若干层卷积层、第一全连接层、第二全连接层和第三全连接层;损失计算模块分别 包括用于计算情感辨别损失的第一损失计算单元、用于计算源域特征和目标域特征之间 的边缘分布差异损失的第二损失计算单元、用于计算细粒度的情感标签信息引导的条件 分布适配损失的第三损失计算单元、用于计算粗糙的情绪类感知条件分布适应正则化项 的第四损失计算单元以及用于计算四项损失之和的总损失计算单元。
[0054]
所述第一损失计算单元连接第三全连接层,具体用于基于下式计算情感辨别损失, 用于实现使网络具有情感辨别性的目标:
[0055][0056]
式中,是情感辨别损失,是连接源域样本语谱图特征及其相应情感标签的交 叉熵损失,ns表示源域样本数目,g1、g2和g3分别表示第一全连接层、第二全连接层、 第三全连接层的参数,表示第i个源域样本的语谱图特征,f表示卷积神经网络的参 数,表示第i个源域样本的情感标签,对于yi,如果对应语音样本的标签是第j个情 感,则只有第j个条目设为1,其他条目设为0。
[0057]
所述第二损失计算单元连接所述第一全连接层,用于基于下式计算边缘分布差异损 失:
[0058][0059]
式中,是边缘分布损失,ns表示源域样本数目,n
t
表示目标域样本数目,g1表 示第一全连接层参数,表示第i个源域样本的语谱图特征,表示第i个目标域样本 的语谱图特征,f表示卷积神经网络的参数,φ(
·
)是核映射算子,代表再生核希尔 伯特空间(reproducing kernel hilbert space,rkhs)。
[0060]
所述第三损失计算单元连接所述第三全连接层,用于基于下式计算条件分布适配损 失:
[0061][0062]
式中,表示条件分布适配损失,和分别表示源域和目标域属于第j类情 感的第i个样本,c表示情感类别数,和分别表示源域和目标域中属于第j类情 感样本数,且满足和ns表示源域样本数目,n
t
表 示目标域样本数目,f表示卷积神经网络的参数,g1、g2和g3分别表示第一全连接层、 第二全连接层、第三全连接层的参数,代表再生核希尔伯特空间。
[0063]
所述第四损失计算单元连接所述第二全连接层,用于基于下式计算情绪类感知条件 分布适应正则化项:
[0064][0065]
式中,cr是粗糙情感类别数,cr小于情感类别数c,和分别表示源域和目 标域属于第j类情感的第i个样本,φ(
·
)是核映射算子,和分别表示源域和目标 域中属于第j类情感样本数,且满足和ns表示 源域样本数目,n
t
表示目标域样本数目,f表示卷积神经网络的参数,g1、g2分别表示 第一全连接层、第二全连接层的参数,代表再生核希尔伯特空间。
[0066]
看起来像是的升级版本,但是,它们实际上是非常不同的。具体来说,是 根据细粒度情感类别在“效价-唤醒”情绪轮中按照效价维度上的分布将它们分为高效价 组与低效价组,然后根据新的分组计算条件mmd。设计的主要原因是因为细粒度 情感在唤醒维度上是不好区分的,因为大多数现有的典型情绪都是高唤醒的,只有少数 情绪,例如“伤心”是低唤醒的。换句话说,由于这些情绪中的大多数难以区分,因此在 最后一个全连接层中直接对齐源和目标语音特征之间的精细情绪类别感知条件分布差 距可能是一项艰巨的任务。然而,有趣的是,沿着效价维度,这些情绪之间的可分离性 会显着提高。因为根据分组“愤怒”、“厌恶”、和“恐惧”属于低效价组,而“惊讶
”ꢀ
和“开心”属于高效价组,即使它们在唤醒维度上均属于高唤醒组。出于此原因,将粗 粒度情感信息引导的条件分布(即,效价维度的对齐)应用于第二个全连接层中,因此 设计以有利于减小域间差异。根据计算特征分布适配使用的情感类信息的复杂性,可 以看出本发明所提模型中的特征分布适应操作呈现出一种渐进的方式,因此将其称之为 渐进式分布适配神经网络。
[0067]
和主要旨在模型消除域间差异性。这三个损失函数都是基于最大平均 差异(maximum mean discrepancy,mmd)计算的。mmd的具体计算公式如下:
[0068][0069]
其中k(
·
)是一个核函数,它用计算预定义函数代替了φ(
·
)生成的rkhs中向量之间的内 积运算。和表示xs,x
t
中的第i列。
[0070]
所述总损失计算单元用于按照下式计算总损失:
[0071][0072]
式中,为总损失,λ1、λ2、和λ3是使得最小的权衡系数。
[0073]
(4)使用源域和目标域的语谱图特征、以及源域的情感标签训练上述模型。
[0074]
该步骤具体包括:
[0075]
(4-1)对跨库语音情感识别模型的参数(即,f,g1,g2,g3)进行随机初始化;
[0076]
(4-2)预测目标域样本的伪情感标签
[0077]
(4-3)根据计算总损失
[0078]
(4-4)根据总损失使用经典的随机梯度下降优化(stochastic gradient descent, sgd)算法更新跨库语音情感识别模型的参数;
[0079]
(4-5)判断总损失是否收敛,若不收敛,则根据当前跨库语音情感识别模型的参数, 更新伪情感标签并返回步骤(4-3),若收敛则网络训练完成。
[0080]
(5)对于待识别语音,提取语谱图特征,输入训练好的模型,得到待识别语音的 情感类别。
[0081]
本实施例还提供了一种基于渐进式分布适配神经网络的跨库语音情感识别装置,包 括处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程 序时实现上述方法。
[0082]
为了评估本发明提出的pdan模型在跨库语音情感识别任务中的性能,基于 emo-db,casia,和enterface三个数据库进行了大量的实验。具体地说,使用上 述语音情感数据库中的任意两个作为源和目标样本集,从而获得6个典型的跨库ser 任务,如表1所示,其中b、e、c分别为emodb、enterface、casia的缩写,箭 头的左右数据库库分别对应源域数据库和目标域数据库。此外,由于这些数据库库具有 不同的情感,在每个跨库的ser任务中,提取具有相同情感标签的语音样本,以确保标 签的一致性。所选数据库库的详细样本统计如表1所示。此外,对于本方法中的基于高 低效价维度信息引导的条件概率分布适配约束项,仍然需要将数据库中离散情感标签根 据效价-唤醒度情感轮模型中的情感效价维度重新划分,具体参见表2。在实验中,为了 凸显方法设计的通用性。此外选择了多种基于深度学习的领域自适应方法作为对比,包 括dan(deep adaptation networks)、dann(domain-adversarial neutral network)、 deep-coral、dsan(deep subdomain adaptation network)等方法,并以alexnet作 为它们的主干网络。为了同时体现深度神经网络相比于传统方法的优越之处,这里也将 svm作为基准方法,并选取了一系列优秀且经典的领域自适应方法作为对比,其中包 括transfer component analysis(tca)、subspace alignment(sa)、domain adaptivesubspace learning(dosl)、geodesic flow kernel(gfk)、和
joint distribution adaptiveregression(jdar)。请注意传统方法使用的特征集为interspeech 2009emotionchallenge和interspeech 2010paralinguistic challenge。而对于实验结果评价指标, 实验中使用加权平均召回率(unweighted average recall,uar)作为评价标准。所有验 证结果如表3所示。
[0083]
表1
[0084][0085]
表2
[0086][0087]
表3
[0088]
[0089]
实验结果表明,基于本发明提出的语音情感识别方法,取得了较高的跨语库语音情 感识别率。
[0090]
以上所揭露的仅为本发明一种较佳实施例而已,不能以此来限定本发明之权利范围, 因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1