一种基于MFCC差分混合频谱的语音情感识别方法
一种基于mfcc差分混合频谱的语音情感识别方法
技术领域
1.本发明涉及一种基于mfcc差分混合频谱的语音情感识别方法,属于语音情感识别技术领域。
背景技术:
2.随着感知与交互智能机器人日益成为医疗教育和社会服务等国家重大战略的需求,其研发工作也迫在眉睫,具有极其重要的科学研究价值,语音情感识别技术在谎言检测、心理学研究、以及对诸多疾病诊断具有辅助作用。
3.现有的语音情感识别技术主要方法采用单一的梅尔频率倒谱系数或一阶差分梅尔频率倒谱系数特征频谱作为输入,由于由于单一梅尔频率倒谱系数只反映了语音参数的静态特性,和单帧的功率谱包络线,一阶差分梅尔频率倒谱系数特征频谱只反映了能量的变化,在日常交流中,语音情感不仅仅与能量变化有关,同时与能量变化的加速度也有关系,因此将混合频谱作为输入。
技术实现要素:
4.本发明要解决的技术问题是提供一种基于mfcc差分混合频谱的语音情感识别方法,用以解决上述问题。
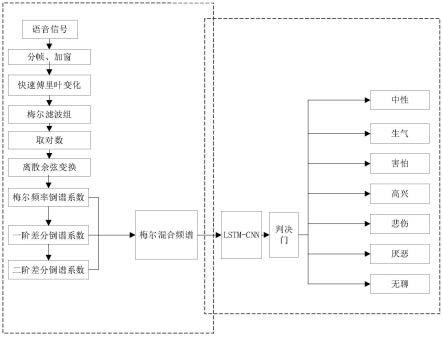
5.本发明的技术方案是:一种基于mfcc差分混合频谱的语音情感识别方法,首先提取语音信号的梅尔频率倒谱系数(mfcc)特征频谱,并对此mfcc特征频谱进行差分运算,得到一阶差分mfcc特征频谱,在频谱图上表现的是能量的变化。再对一阶差分mfcc进行差分运算,得到二阶差分mfcc特征频谱,在频谱图上的二阶差分mfcc表现的是加速度的变化。然后将mfcc,一阶差分mfcc,二阶差分mfcc频谱特征图谱从左往右依次进行水平堆叠,以得到动、静结合的混合频谱图。再对该混合频谱图采用z-score法进行预处理,最后通过采用了稀疏交叉熵法的bi-lstm-cnn深度学习模型进行训练,最终实现对输入语音的情感进行预测、并判断出语音情感的类别。
6.具体步骤为:
7.step1:将语音信号按照16khz的采样频率进行采样、以16bit进行量化、再进行梅尔倒谱系数特征提取,得到一个二维矩阵形式的mfcc特征频谱,对该频谱进行一阶差分运算,其物理意义是当前语音帧与前一帧之间的关系,体现相邻两帧之间的联系,在频谱图上表现出来的是能量的变化。对一阶差分梅尔频率倒谱系数再进行差分运算,即二阶差分运算,分别得到两个同样尺寸的差分频谱特征图,即二阶差分特征频谱图,体现到帧上是相邻三帧之间的动态关系,在频谱图上表现出的是一阶梅尔频率倒谱系数变化加速度大小。然后将mfcc,一阶差分mfcc,二阶差分mfcc频谱特征图谱从左往右依次水平堆叠,从而得到一个特征数更多的二维动、静结合的混合频谱特征图。
8.step2:将上述动静结合的混合频谱图输入到bi-lstm深度学习模型中,通过捕获分帧后语音片段之间关系,进行特征提取,保留语音信号中包含的情感特征,再利用cnn神
经网络对提取的情感特征进一步提取。
9.step3:对提取后的特征频谱做z-score法进行预处理,将经过bi-lstm-cnn模型提取特征,在网络的输出层采用softmax激活函数对结果进行预测判断,对输出值进行归一化操作,使得输出值转化为在0到1之间的概率值,语音情感分为7类,在判决门电路中,系统判定最大概率值所对应的线路为真实情感标签。
10.所述step1具体为:
11.step1.1:特征频谱提取过程之前,将语音数据分帧为帧长为20ms,帧移为10ms的一段数据,以此保证进行语音信号的平稳性。
12.step1.2:再对分帧后语音进行加汉明窗操作。
13.step1.3:再对信号进行傅里叶变换,将时域信号转化为频域信号,展现信号强度和频率的关系。
14.step1.4:将上述变化的信号通过梅尔滤波组,增强三角波区域中间信号,削弱两边信号,对信号进一步提取特征。
15.step1.5:计算每帧谱线能量与梅尔滤波组函数相乘取对数得到对数能量,使梅尔特征频谱输出具有更好的抗干扰作用。
16.step1.6:对梅尔特征频谱做离散余弦变换得到mfcc特征频谱,以防止梅尔滤波器组后得到的系数相关性很高,并取低频信号特征值以减少运算量。
17.所述step2具体为:将差分混合频谱图输入到深度学习模型中,所述深度学习模型包含1个输入层、3个bi-lstm层、3个一维卷积层、3个最大池化层、1个dropout层和1个全连接层,在三个bi-lstm层中均包含128个记忆神经元,通过bi-lstm层后分别得到3个二维矩阵。
18.step2.2:将3个二维矩阵再次输入到三个一维卷积层,每个卷积层分别包含128个不同大小的卷积核,采用扩展指数线性单元激活函数。
19.step2.3:将通过卷积层的后得到的三个矩阵进行最大池化操作,提取窗口区域内最大值。
20.step2.4:将池化后的三个矩阵从左往右进行水平排列,合并特征,提高情感识别准确率。
21.本发明的有益效果是:本发明利用梅尔频率倒谱系数及其一阶、二阶差分的混合频谱作为输入。动静结合的的频谱特征,使得bi-lstm-cnn神经网络对情感特征提取更多,识别准确率也有一定提高,同时对语音情感识别的计算简单,易于实现。
附图说明
22.图1是本发明的步骤流程图;
23.图2是本发明实施例中的差分频谱图;
24.图3是本发明实施例中频谱混合过程图;
25.图4是本发明实施例中不同情感混合频谱图;
26.图5是本发明实施例中深度学习网络结构模型图;
27.图6是本发明实施例中不同情绪输出概率值图。
具体实施方式
28.下面结合附图和具体实施方式,对本发明作进一步说明。
29.实施例1,如图1所示,一种基于mfcc差分混合频谱的语音情感识别方法,具体步骤为:
30.step1:语音信号特征频谱提取。
31.将语音信号根据fs=16khz进行采样,再以16bit进行量化,设置特征数mfcc=40,设置帧移inc=512,语音平均时长为t=4s,梅尔倒谱系数的尺寸大小为(a,mfcc)。根据公式a=fs*t/inc+1,得到一个二维矩阵(126,40)形式的mfcc特征频谱,再对该频谱进行一阶差分运算和二阶差分运算,分别得到两个同样尺寸大小的差分频谱特征图,其次将此三个频谱特征图谱从左到右依次进行水平堆叠,从而得到一个二维矩阵(378,40)的动、静结合的混合频谱特征图。
32.step2:语音情感信息提取。
33.将上述动静结合的混合频谱图输入到具有判断信息是否有用的记忆单元处理模块的bi-lstm深度学习模型中,进行特征提取,再利用cnn神经网络对提取的情感特征进一步提取,保留下更重要的情感特征频谱,以提高语音情感识别的准确率。
34.step3:识别语音情感类别判断。
35.对混合频谱特征图z-score法进行预处理,以均值为中心,按分量比例缩放至单位方差,因此经过处理后的混合频谱矩阵均值为0,标准差为1。再经过bi-lstm-cnn模型提取情感特征后,在网络的输出层采用softmax激活函数对结果进行预测判断,对输出值进行归一化操作,使得输出值转化为在(0,1)之间的概率值,语音情感包含7类,在判决门限中,系统判断最大概率值对应的线路为真实情感标签。
36.所述step1具体步骤为:
37.step1.1:特征频谱提取过程之前,将语音数据分帧为帧长为20ms,帧移为10ms的一小段数据,以此保证进行语音信号的平稳性。
38.step1.2:再对分帧后语音进行加汉明窗操作。
39.step1.3:再对信号进行傅里叶变换,将时域信号转化为频域信号,展现信号强度和频率的关系。
40.step1.4:将上述变化的信号通过梅尔滤波组,增强三角波区域中间信号,削弱两边信号,对信号进一步提取特征。
41.step1.5:并计算每帧谱线能量与梅尔滤波组函数相乘取对数得到对数能量,使梅尔特征频谱输出具有更好的抗干扰作用,。
42.step1.6:对梅尔特征频谱做离散余弦变换得到mfcc特征频谱,以防止梅尔滤波器组后得到的系数相关性很高,并取低频信号特征值以减少运算量。
43.所述step2具体步骤为:
44.step2.1:将差分混合频谱图(378,40)输入到深度学习模型中,该深度学习模型包含1个输入层、3个双向lstm层、3个一维卷积层、3个最大池化层、1个dropout层和1个全连接层。在三个bi-lstm层中均包含128个记忆神经元,通过bi-lstm层后分别得到3个二维矩阵(378,256)。
45.step2.2:将上述得到的三个二维矩阵再次输入到三个一维卷积层,每个卷积层分
别包含128个不同大小的卷积核,采用扩展指数线性单元激活函数。
46.step2.3:将通过卷积层的后得到的三个矩阵进行最大池化操作,提取窗口区域内最大值。
47.step2.4:将池化后的三个矩阵从左往右进行水平排列,合并特征,以提高情感识别准确率。
48.下面在技术方案的基础上对本实施例进行进一步的说明:
49.选取语音信号以16khz采样频率对语音信号进行采样,再以16bit进行量化,设定语音平均时长为4s。
50.将语音信号分帧为帧长为20ms,帧移为10ms的一小段数据得到输入数据x(n),以此保证进行语音信号的平稳性。
51.并对分帧后数据进行加汉明窗操作,汉明窗函数为:
52.再进行快速傅里叶变换n为傅里叶点数,将时域信号转化为频域信号,展现信号强度和频率的关系,有利于获取语音信号中情感的特性。
53.将快速傅里叶变换后,从时域变为频域的信号再经过梅尔滤波组可增强三角波区域中间信号,削弱两边信号,因此能对信号进一步提取特征,m代表第几个滤波器。
54.计算每帧谱线能量e(k)=|x(a,k)|2并与梅尔滤波组函数相乘取对数得到对数能量
55.通过梅尔滤波器组后得到的系数相关性很高,进行离散余弦变化
56.语音信号在时域上是连续的,通过一阶差分运算以获得一阶差分梅尔频率倒谱频谱特征图。
57.再对一阶差分进行差分运算得到二阶差分梅尔频率倒谱系数,各阶差分如图2所示。
58.将所述三个语音频谱特征图从左往右进行水平堆叠合并,并作为bi-lstm-cnn的输入,如图3所示。
59.对堆叠后特征频谱图进行归一化操作,以均值为中心,按分量比例缩放至单位方差,其转化公式为经过处理后的混合频谱矩阵均值为0,标准差为1,不同情绪混合频谱图如图4所示。
60.在bi-lstm-cnn深度学习模型中对归一化后的语音情感特征进行提取,深度学习网络结构模型如图5。
61.在网络的输出层采用softmax激活函数对结果进行预测判断,对输出值进行归一化操作,使得输出值转化为概率值,并且概率值之和为1,语音情感包含7类,分别是中性(netral)、生气(anger)、害怕(fear)、高兴(happiness)、悲伤(sadness)、厌恶(disgust)、无聊(boredom),在判决门限中,系统判断最大概率值为真实情感标签,如图6所示。
62.本发明判断语音情感类别,较为简单,计算量相较于现有技术较小,且识别准确率较高。
63.以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1