视频处理方法、视频处理装置和电子设备与流程
1.本技术属于电子技术领域,具体涉及一种视频处理方法、视频处理装置和电子设备。
背景技术:
2.用户在使用电子设备进行拍摄时,会一并采集图像序列和音频信息。相关技术中,在进行视频播放时,电子设备会一并播放所采集的全部图像序列和音频信息。该方法使得视频生成的方式单一。
技术实现要素:
3.本技术实施例的目的是提供一种视频处理方法、视频处理装置和电子设备,能够解决视频生成的方式单一的问题。
4.第一方面,本技术实施例提供了一种视频处理方法,该方法包括:
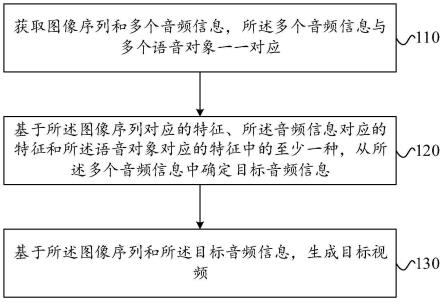
5.获取图像序列和多个音频信息,所述多个音频信息与多个语音对象一一对应;
6.基于所述图像序列对应的特征、所述音频信息对应的特征和所述语音对象对应的特征中的至少一种,从所述多个音频信息中确定目标音频信息;
7.基于所述图像序列和所述目标音频信息,生成目标视频。
8.第二方面,本技术实施例提供了一种视频处理装置,该装置包括:
9.第一获取模块,用于获取图像序列和多个音频信息,所述多个音频信息与多个语音对象一一对应;
10.第一处理模块,用于基于所述图像序列对应的特征、所述音频信息对应的特征和所述语音对象对应的特征中的至少一种,从所述多个音频信息中确定目标音频信息;
11.第二处理模块,用于基于所述图像序列和所述目标音频信息,生成目标视频。
12.第三方面,本技术实施例提供了一种电子设备,该电子设备包括处理器和存储器,所述存储器存储可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如第一方面所述的方法。
13.第四方面,本技术实施例提供了一种可读存储介质,所述可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如第一方面所述的方法。
14.第五方面,本技术实施例提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现如第一方面所述的方法。
15.第六方面,本技术实施例提供一种计算机程序产品,该程序产品被存储在存储介质中,该程序产品被至少一个处理器执行以实现如第一方面所述的方法。
16.在本技术实施例中,通过图像序列对应的特征、音频信息对应的特征和语音对象对应的特征中的至少一种,从多个音频信息中确定目标音频信息,并基于确定的目标音频信息和获取的图像序列合成目标视频,丰富了视频的生成方式。
附图说明
17.图1是本技术实施例提供的视频处理方法的流程示意图;
18.图2是本技术实施例提供的视频处理方法的界面示意图之一;
19.图3是本技术实施例提供的视频处理方法的界面示意图之二;
20.图4是本技术实施例提供的视频处理方法的界面示意图之三;
21.图5是本技术实施例提供的视频处理装置的结构示意图;
22.图6是本技术实施例提供的电子设备的结构示意图;
23.图7是本技术实施例提供的电子设备的硬件示意图。
具体实施方式
24.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员获得的所有其他实施例,都属于本技术保护的范围。
25.本技术的说明书和权利要求书中的术语“第一”、“第二”等是用于区别类似的对象,而不用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便本技术的实施例能够以除了在这里图示或描述的那些以外的顺序实施,且“第一”、“第二”等所区分的对象通常为一类,并不限定对象的个数,例如第一对象可以是一个,也可以是多个。此外,说明书以及权利要求中“和/或”表示所连接对象的至少其中之一,字符“/”,一般表示前后关联对象是一种“或”的关系。
26.下面结合附图,通过具体的实施例及其应用场景对本技术实施例提供的视频处理方法、视频处理装置、电子设备和可读存储介质进行详细地说明。
27.其中,视频处理方法可应用于终端,具体可由,终端中的硬件或软件执行。
28.该终端包括但不限于具有触摸敏感表面(例如,触摸屏显示器和/或触摸板)的移动电话或平板电脑等其它便携式通信设备。还应当理解的是,在某些实施例中,该终端可以不是便携式通信设备,而是具有触摸敏感表面(例如,触摸屏显示器和/或触摸板)的台式计算机。
29.以下各个实施例中,描述了包括显示器和触摸敏感表面的终端。然而,应当理解的是,终端可以包括诸如物理键盘、鼠标和控制杆的一个或多个其它物理用户接口设备。
30.本技术实施例提供的视频处理方法,该视频处理方法的执行主体可以为电子设备或者电子设备中能够实现该视频处理方法的功能模块或功能实体,本技术实施例提及的电子设备包括但不限于手机、平板电脑、电脑、相机、可穿戴设备等,下面以电子设备作为执行主体为例对本技术实施例提供的视频处理方法进行说明。
31.如图1所示,该视频处理方法包括:步骤110、步骤120和步骤130。
32.步骤110、获取图像序列和多个音频信息,多个音频信息与多个语音对象一一对应;
33.在该步骤中,图像序列为通过图像传感器采集的图像信息。
34.图像序列包括多帧视频帧,其中,视频帧中可以包括人物信息、动物信息以及背景等信息。
35.图像序列可以包括多个对象,如人、动物或着其它物体等。图像序列所包括的对
象,可以包括发声对象(如人以及动物等),还可以包括不发声对象(如沙滩以及楼房等)。
36.多个音频信息为通过拾音器采集的音频,其中,音频信息包括但不限于人声、动物声、背景环境声以及其他声音等。
37.语音对象为多个音频信息中的发声对象。
38.其中,每一个音频信息对应一个语音对象,语音对象可以为人、动物、其他可以发声的物体、背景环境音以及噪声等。
39.语音对象为对多个音频信息进行语音特征识别所确定的。
40.需要说明的,本技术中的语音对象包括存在于图像序列中的发声对象,也包括不存在于图像序列中的语音对象。
41.步骤120、基于图像序列对应的特征、音频信息对应的特征和语音对象对应的特征中的至少一种,从多个音频信息中确定目标音频信息;
42.在该步骤中,目标音频信息为用于生成目标视频的音频信息。
43.其中,目标视频为最终生成或用于播放的视频。
44.目标音频信息的数量可以为一个或多个。
45.每一个目标音频信息对应于一个语音对象。
46.图像序列对应的特征为图像序列中每一个对象对应的图像特征,包括但不限于图像特征本身以及图像特征对应的生理特征等。
47.音频信息对应的特征包括但不限于:音频信息对应的文本信息以及音频信息对应的音频特征本身。
48.语音对象对应的特征包括但不限于语音对象对应的生理特征。
49.下面通过具体实施例,对步骤120的实现方式进行说明。
50.在一些实施例中,步骤120可以包括:
51.对图像序列进行特征提取,得到多个图像特征;对多个音频信息进行特征提取得到多个文本信息;
52.在多个文本信息中目标文本信息与图像特征匹配的情况下,将目标文本信息对应的音频信息确定为目标音频信息。
53.在该实施例中,图像特征用于表征图像序列所包含的画面内容。
54.目标文本信息与图像特征匹配可以表现为目标文本信息的内容与图像特征的内容一致或相似。
55.例如,对图2所示的图像序列进行特征提取,得到包括年轻女人、男孩、海鸥、海浪、帆船以及沙滩等多个图像特征;
56.同时,电子设备还将对采集到的多个音频信息进行文本识别,以提取得到多个文本信息,如提取到年轻女人对应的文本信息包括:沙滩以及海边等多个关键词。
57.通过比较每一个音频信息所对应的文本信息与图像特征是否匹配,在匹配的情况下,如确定年轻女人对应的文本信息与图像特征均包括沙滩特征的情况下,则确定年轻女人对应的文本信息与图像特征匹配,则将年轻女人对应的音频信息确定为目标音频信息。
58.在该实施例中,通过在多个文本信息中目标文本信息与图像特征匹配的情况下,将目标文本信息对应的音频信息确定为目标音频信息,能够提升所生成的目标视频的画面与声音的相关性。
59.在一些实施例中,步骤120可以包括:
60.对图像序列进行特征提取,得到多个图像特征;对多个音频信息进行特征提取得到多个文本信息;
61.在多个图像特征包括多个语音对象中第一目标语音对象对应的特征的情况下,将第一目标语音对象对应的音频信息确定为目标音频信息。
62.在该实施例中,通过判断语音对象是否在图像序列的画面内,来确定是否将该语音对象的音频信息确定为目标音频信息。
63.当语音对象在图像序列的画面内时,则将该语音对象的音频信息确定为目标音频信息;而当语音对象不在图像序列的画面内时,则不将该语音对象的音频信息确定为目标音频信息。
64.在该实施例中,通过在多个图像特征包括多个语音对象中第一目标语音对象对应的特征的情况下,将第一目标语音对象对应的音频信息确定为目标音频信息,能够有效去除画外音或环境背景音等,使得最终生成的目标视频不受采集环境的影响,保证所生成的目标视频的画面与声音具有一致性。
65.在一些实施例中,步骤120可以包括:
66.对图像序列进行特征提取,得到多个图像特征;对多个音频信息进行特征提取得到多个文本信息;
67.在多个语音对象中第二目标语音对象对应的生理特征与图像特征对应的生理特征匹配的情况下,将第二目标语音对象对应的音频信息确定为目标音频信息。
68.在该实施例中,生理特征包括:年龄特征以及性别特征等。
69.在实际执行过程中,可以通过预训练的神经网络模型来确定第二目标语音对象对应的生理特征。
70.第二目标语音对象对应的生理特征与图像特征对应的生理特征匹配,可以表现为第二目标语音对象对应的生理特征与图像特征对应的生理特征相同或相似。
71.例如,对图2所示的图像序列进行特征提取,得到包括年轻女人、男孩、海鸥、海浪、帆船以及沙滩等多个图像特征,并基于各图像特征确定各图像特征对应的生理特征,如确定年轻女人对应的图像特征所对应的生理特征为年轻女人,确定男孩对应的图像特征所对应的生理特征为男孩。
72.同时,电子设备还将对采集到的多个音频信息进行特征识别,得到多个生理特征,如得到年轻女人、男孩、女孩和老人等多个生理特征。
73.经匹配,即可将年轻女人对应的音频信息和男孩对应的音频信息确定为目标音频信息。
74.在该实施例中,通过在多个语音对象中第二目标语音对象对应的生理特征与图像特征对应的生理特征匹配的情况下,将第二目标语音对象对应的音频信息确定为目标音频信息,能够保证所生成的目标视频的画面内容与声音具有较高的相关性。
75.在一些实施例中,步骤120可以包括:
76.对图像序列进行特征提取,得到多个图像特征;对多个音频信息进行特征提取得到多个文本信息;
77.在多个语音对象中第三目标语音对象对应的音频信息的质量满足目标条件的情
况下,将第三目标语音对象对应的音频信息确定为目标音频信息。
78.在该实施例中,目标条件可以包括:音频信息的目标质量、用户的历史使用习惯、使用偏好以及播放目的等。
79.音频信息的质量包括:音频信息的内容的长短、音频信息的内容是否重复、音频信息是否为方言、音频信息是否清晰以及音频信息是否完整等。
80.在实际执行过程中,电子设备可以基于音频信息的目标质量、用户的历史使用习惯、使用偏好以及播放目中的至少一项,来判断任意音频信息是否为满足目标条件的内容;在确定满足目标条件的情况下,则将该音频信息确定为目标音频信息。
81.在该实施例中,通过在多个语音对象中第三目标语音对象对应的音频信息的质量满足目标条件的情况下,将第三目标语音对象对应的音频信息确定为目标音频信息,可以使得最终生成的目标音频信息为用户喜欢的内容,或为高质量的音频。
82.当然,在其他实施例中,还可以基于其他标准来确定目标音频信息,本技术不作限定。
83.步骤130、基于图像序列和目标音频信息,生成目标视频。
84.在该实施例中,目标视频为最终生成或用于播放的视频。
85.在实际执行过程中,通过对采集到的图像序列和确定的目标音频信息进行合成,即可生成目标视频。
86.可以理解的是,所生成的目标视频包括图像序列和目标音频信息,而不包括多个音频信息中除目标音频信息之外的其他音频信息。
87.当用户播放该目标视频时,在显示图像序列的同时,还将播放目标音频信息。
88.例如,对图2所示的图像序列进行特征提取,得到包括年轻女人、男孩、海鸥、海浪、帆船以及沙滩等多个图像特征;
89.同时,电子设备还将对采集到的多个音频信息进行文本识别,以提取得到多个文本信息,如提取到年轻女人对应的文本信息包括:沙滩以及海边等多个关键词。
90.通过比较每一个音频信息所对应的文本信息与图像特征是否匹配,在匹配的情况下,如确定年轻女人对应的文本信息与图像特征均包括沙滩特征的情况下,则确定年轻女人对应的文本信息与图像特征匹配,则将年轻女人对应的音频信息确定为目标音频信息。
91.最后,电子设备将图像序列以及年轻女人对应的音频信息进行合成,即可生成目标音频信息。
92.在本技术中,在进行视频采集过程中,通过从多个音频信息中确定目标音频信息,并基于确定的目标音频信息合成目标视频,能够有效屏蔽视频采集过程中的其他干扰音频(如环境噪声以及其他画外音等),提高画面与音频的适配度,从而显著提高音频质量。
93.根据本技术实施例提供的视频处理方法,通过图像序列对应的特征、音频信息对应的特征和语音对象对应的特征中的至少一种,从多个音频信息中确定目标音频信息,并基于确定的目标音频信息和获取的图像序列合成目标视频,丰富了视频的生成方式。
94.在一些实施例中,该方法还可以包括:显示目标界面,目标界面包括图像序列和多个标签,多个标签与多个语音对象一一对应。
95.在该实施例中,目标界面可以包括:视频采集界面或视频播放界面210。
96.其中,视频采集界面为用于采集视频的界面,视频播放界面210为用于播放视频的
界面。
97.标签用于表征待播放视频所包括的语音对象的信息。
98.多个标签与多个语音对象一一对应。
99.可以理解的是,标签所对应的语音对象可能为图像序列所包括的发声对象(如男孩和年轻女人等),也可能为图像序列不包括的发声对象(如女孩等)。
100.在实际执行过程中,标签可以显示于图像序列上,即在显示图像序列的同时显示标签;或者也可以单独显示标签,本技术不作限定。
101.下面以目标界面为视频播放界面210为例,对该实施例进行说明。
102.需要说明的是,在目标界面为视频采集界面的情况下,图像序列为由图像传感器采集的图像信息。
103.在目标界面为视频播放界面210的情况下,图像序列可以为待播放视频对应的视频帧。
104.待播放视频为原始播放文件。其中,待播放视频可以为视频文件、录屏文件以及录音文件等。
105.待播放视频可以为由电子设备的传感器所采集的文件,或者可以为从与电子设备连接的服务器或网站下载的文件,或者还可以为存储于数据库中的文件。
106.在一些实施例中,视频播放界面210还可以包括多帧视频帧中的一帧视频帧,如包括多帧视频帧中的第一帧视频帧。
107.在该实施例中,多个标签可以悬浮显示于视频帧之上,如图2所示。
108.在另一些实施例中,视频播放界面210还可以包括电子设备默认的视频帧,本技术不作限定。
109.如图2所示了一种视频播放界面210,该视频播放界面210包括待播放视频的第一帧视频帧和该待播放视频对应的多个标签。
110.其中,该待播放视频的图像序列包括年轻女人、男孩以及背景环境信息(如海鸥、海浪、帆船以及沙滩等);该待播放视频对应的多个音频信息包括:男孩的说话声、年轻女人的说话声、女孩的说话声以及海浪声;其中女孩的说话声为画外音。
111.每一个音频信息对应一个语音对象,则该待播放视频包括的语音对象分别为:男孩、年轻女人、女孩和海浪。
112.图像序列所包含的发声对象包括:男孩、年轻女人和海浪。
113.根据本技术实施例提供的视频处理方法,通过显示多个标签,便于用户了解采集的全部音频信息对应的语音对象的身份以区分不同的语音对象,显示简洁明了;除此之外,还方便后续用户对单独的语音对象对应的音频信息进行相关操作,提高了操作的便捷性。
114.在一些实施例中,继续参考图2,标签包括语音对象的标识221,以及语音对象对应的文本信息222;文本信息222为对与语音对象对应的音频信息进行文本特征识别确定的。
115.在该实施例中,语音对象的标识221用于表征语音对象的身份特征,从而能够区分多个语音对象。
116.例如,标识221可以表现为语音对象对应的昵称、头像或者id等。
117.不同的语音对象对应有不同的标识221。
118.文本信息222用于表征语音对象对应的音频信息的文字内容的相关信息,可以表
现为通过对音频信息进行语音转文本所生成的全文;或者可以为通过对全文进行关键词提取所生成的文本摘要;或者可以为基于全文生成的概括描述等。
119.文本信息222为对语音对象对应的音频信息进行文本特征识别确定的,具体识别过程在此不作赘述。
120.继续参考图2,以标识221为头像为例,该视频播放界面210包括四个标签,分别为:男孩的头像以及男孩对应的文本信息222:“真好玩”;女孩的头像以及女孩对应的文本信息222:“好漂亮的海滩啊,真高兴”;年轻女人的头像以及年轻女人对应的文本信息222:“这一片海滩是本市
……”
;海浪的头像以及海浪对应的文本信息222:“海浪声”。
121.根据本技术实施例提供的视频处理方法,通过同时显示语音对象的标识221,以及语音对象对应的文本信息222,有利于用户了解该待播放视频所对应的全部语音对象的身份以及各语音对象对应的语音内容情况,显示清晰且有条理,便于用户区分不同的语音对象,使得后续用户能够通过筛选标签以选择与该标签对应的语音对象,从而对语音对象的语音信息进行增删或调整等,显著提高了便捷性和清楚性,有助于提高用户使用体验。
122.下面对语音对象的标识221的确定方式进行说明。
123.在一些实施例中,标识221可以通过如下步骤确定:
124.对多个音频信息进行语音特征识别,确定各音频信息对应的语音对象;
125.对图像序列进行图像特征识别,确定图像序列中发声对象对应的头像信息;
126.在语音对象与头像信息匹配的情况下,将头像信息确定为语音对象的标识221;
127.在语音对象与头像信息不匹配的情况下,将存储的目标预设头像确定为语音对象的标识221。
128.在该实施例中,对多个音频信息进行语音特征识别,包括对多个音频信息进行频率特征识别以及音色特征识别中的至少一种识别,基于频率特征或音色特征区分不同的音频信息,从而对多个音频信息进行分类,以将多个音频信息区分为多个不同的发声主体,将每一个音频信息对应为一个语音对象。
129.其中,频率特征识别包括声纹特征识别。
130.可以理解的是,不同年龄段或不同性别的群体其对应的频率特征或音色特征有所区别,例如女性的声音频率高于男性的声音频率;则可以基于音频信息对应的频率特征或音色特征等,将音频信息划分为相应的年龄段或性别群体。
131.在实际执行过程中,可以通过预训练的神经网络模型来执行该步骤,本技术不作赘述。
132.对图像序列进行图像特征识别,确定图像序列中发声对象对应的头像信息,包括:对图像序列进行特征提取,得到多个特征;从多个特征中确定发声对象对应的头像信息。
133.可以理解的是,在对图像序列进行图像特征识别时,还可以进一步确定各发声对象对应的生理特征,包括年龄特征以及性别特征等。
134.在实际执行过程中,同样可以通过预训练的神经网络模型来执行该步骤,本技术不作赘述。
135.继续参考如图2所示的视频播放界面210,该待播放视频的图像序列包括年轻女人、男孩、海鸥、海浪、帆船以及沙滩等;该待播放视频对应的多个音频信息包括:男孩的说话声、年轻女人的说话声、女孩的说话声以及海浪声。
136.电子设备对图像序列进行图像特征识别,得到年轻女人、男孩、海鸥、海浪、帆船以及沙滩等特征;然后对得到的特征进行筛选,确定年轻女人、男孩、海鸥以及海浪等特征为发声对象,帆船和沙滩等特征为不发声对象,从而将所提取到的年轻女人、男孩、海鸥以及海浪等特征确定为各发声特征对应的头像信息。
137.如将男孩的头像确定为男孩的头像信息,将年轻女人的头像确定为年轻女人的头像信息,将浪花确定为海浪的头像信息。
138.该待播放视频对应的多个音频信息包括:男孩的说话声、年轻女人的说话声、女孩的说话声以及海浪声。
139.电子图像同时还会对音频信息进行语音特征识别,从而确定得到男孩、女孩、年轻女人以及海浪等多个语音对象。
140.在得到语音对象和头像信息之后,对语音对象和头像信息进行匹配:包括对语音对象对应的特征与头像信息对应的特征进行匹配,在特征相同或相似的情况下,则将该头像信息确定为该语音对象的标识221;在特征不相似的情况下,则将存储的目标预设头像确定为语音对象的标识221。
141.其中,目标预设头像为系统预设头像,可以为存储于电子设备中的头像。
142.在实际执行过程中,电子设备中可以存储一个或多个预设头像,在存储有多个预设头像的情况下,目标预设头像可以为多个预设头像中的任意一个。
143.在预设头像为多个的情况下,多个预设头像可以包括多个类别,且不同类别的预设头像对应有不同的生理特征,如多个预设头像可以包括:老人对应的预设头像、小孩对应的预设头像、男性对应的预设头像以及女性对应的预设头像等。
144.在一些实施例中,每一类预设头像可以包括一个或多个同类别预设头像,在包括多个同类别的预设头像的情况下,各预设头像对应的生理特征相同且显示内容不同。
145.其中,生理特征包括:年龄、性别以及物种等特征。
146.例如,电子设备中可以存储多个男孩对应的预设头像,且各个预设头像的具体显示内容不同,例如各个预设头像的头发颜色不同、肤色不同或造型不同等,从而用于区分生理特征相同情况下的不同的语音对象。
147.下面对预设头像为多个的情况下的目标预设头像的确定方式进行说明。
148.在一些实施例中,在语音对象与头像信息不匹配的情况下,将存储的目标预设头像确定为语音对象的标识221,可以包括:
149.基于语音对象对应的音频信息的语音特征,确定语音对象的生理特征;
150.基于生理特征,从存储的多个预设头像中筛选得到目标预设头像;
151.将目标预设头像确定为语音对象的标识221。
152.在该实施例中,电子设备中存储有多个预设头像,不同的预设头像具有不同的特征,如电子设备中存储有女孩对应的预设头像、男孩对应的预设头像、老人对应的预设头像以及年轻男人对应的预设头像等。
153.语音特征包括音频信息对应的频率特征和音色特征中的至少一种。
154.生理特征包括:年龄、性别以及物种等特征。
155.基于音频信息的频率特征和音色特征中的至少一种,可以确定该音频信息对应的语音对象的物种、年龄以及性别等特征;然后基于该特征,从存储的多个预设头像中筛选得
到与该特征类似的预设头像,并将筛选得到的预设头像确定为该语音对象的标识221。
156.例如,电子设备基于女孩对应的音频信息的语音特征,确定该语音对象的生理特征为性别女,且年龄较小;则从存储的多个预设头像中筛选与该生理特征匹配的预设头像,从而筛选得到女孩对应的预设头像,则将女孩对应的预设头像确定为女孩对应的标识221,并进行显示,如图2所示。
157.在一些实施例中,在女孩对应的预设头像为多个的情况下,则电子设备可以从女孩对应的多个预设头像中随机选择一个预设头像作为目标预设头像。
158.在一些实施例中,通过对多个音频信息进行语音特征识别以识别到多个女孩对应的语音对象,且多个女孩对应的语音对象中至少两个女孩对应的语音对象不存在于图像序列所包括的发声对象的情况下,则可以分别从存储的多个预设头像中随机选择不重复的至少两个预设头像作为目标预设头像。
159.根据本技术实施例提供的视频处理方法,在音频信息对应的语音对象与图像序列对应的头像信息不匹配的情况下,基于语音对象的生理特征从多个预设头像中筛选得到与生理特征接近的预设头像作为该语音对象的标识221,使得在图像序列中不包括语音对象的情况下,仍能够显示该语音对象的标识221,从而实现对画外音的有效标记,便于后续用户对画外音进行筛选等操作,显著提高了显示的全面性、准确性以及使用的普适性。
160.例如,继续参考图2,在电子设备将图像序列中的男孩的头像确定为男孩的头像信息,将年轻女人的头像确定为年轻女人的头像信息,将浪花确定为海浪的头像信息;并将多个音频信息分别确定为男孩、女孩、年轻女人以及海浪等多个语音对象后;电子设备将男孩、女孩、年轻女人以及海浪等多个语音对象分别与年轻女人、男孩、海鸥以及海浪等头像信息进行匹配,得到匹配结果如下:
161.男孩这一语音对象与图像序列中的男孩的头像信息匹配;年轻女人这一语音对象与图像序列中的年轻女人的头像信息匹配海浪;海浪这一语音对象与图像序列中的海浪的头像信息匹配;未匹配到与女孩相关的头像信息。
162.则电子设备基于以上匹配结果,将男孩的头像信息确定为男孩的标识221,将年轻女人的头像信息确定为年轻女人的标识221,将海浪的头像信息确定为海浪的标识221,并将系统默认的头像确定为女孩的标识221。
163.电子系统将各语音对象的标识221显示于电子设备的屏幕上,生成如图2所示的界面。
164.根据本技术实施例提供的视频处理方法,通过在语音对象与头像信息匹配的情况下,将头像信息确定为语音对象的标识221,而在语音对象与头像信息不匹配的情况下,将存储的目标预设头像确定为语音对象的标识221,能够有效结合图像序列与音频信息,提高画面显示的条理性、精确性和真实性。
165.在一些实施例中,在步骤130之后,该方法还可以包括:
166.显示视频播放界面210,视频播放界面210包括图像序列和多个标签,多个标签与多个语音对象一一对应;
167.从多个标签中确定第一目标标签;
168.基于时间顺序,播放图像序列和与第一目标标签对应的音频信息。
169.在该实施例中,显示视频播放界面210用于播放待播放视频。
170.待播放视频包括图像序列和多个语音对象对应的多个音频信息。
171.其中,图像序列为用于进行视频播放的待播放图像信息。
172.第一目标标签为用于进行视频播放的音频信息对应的标签。
173.第一目标标签的数量可以为一个或多个。
174.每一个第一目标标签对应于一个语音对象。
175.第一目标标签可以通过电子设备自动确定,具体确定方式类似上文所述的目标音频信息的确定方式;当然,在其他实施例中,第一目标标签也可以基于用户确定,将在下文对两种确定方式进行说明,在此暂不作赘述。
176.需要说明的是,根据本技术实施例,在实际视频播放过程中,播放待播放视频可以包括:播放待播放视频的全部图像序列以及全部音频信息;或者播放待播放视频的全部图像序列以及部分音频信息。
177.在播放待播放视频的全部图像序列以及部分音频信息的情况下,该部分音频信息即第一目标标签对应的音频信息。
178.时间顺序即图像序列中各视频帧对应的生成顺序。
179.基于各视频帧对应的生成顺序顺次播放视频帧,并在播放视频帧的同时对应播放与当前所播放的视频帧对应的音频信息,且该音频信息为第一目标标签所对应的音频信息。
180.在一些实施例中,基于时间顺序,播放图像序列和与第一目标标签对应的音频信息可以包括:
181.接收第三输入;
182.响应于第三输入,基于时间顺序,播放图像序列和与第一目标标签对应的音频信息。
183.在该实施例中,第三输入用于确认播放视频。
184.第三输入可以为与第一输入相同的触控输入、实体按键输入、语音输入以及字符输入等,在此不作赘述。
185.例如,继续参考图2,该待播放视频对应的视频播放界面210包括四个标签,分别为:男孩对应的标签、女孩对应的标签、年轻女人对应的标签以及海浪对应的标签。
186.播放之前,将四个标签中的年轻女人对应的标签确定为第一目标标签。
187.用户点击播放控件以实现第三输入,则电子设备响应于第三输入,对待播放视频进行处理,屏蔽多个音频信息中除年轻女人对应的音频信息外的其他音频信息,即屏蔽男孩对应的音频信息,女孩对应的音频信息以及海浪对应的音频信息;在播放图像序列的同时,仅在相应时间点播放年轻女人对应的音频信息。
188.则用户所最终看到的视频中,仅包括图像序列和年轻女人对应的音频信息。
189.又如,在将年轻女人对应的标签确定为第一目标标签,且用户通过第一输入将年轻女人对应的音频信息修改为动漫人物对应的语音特征所对应的音频信息的情况下,则在播放视频的过程中,在播放图像序列的同时,仅在相应时间点播放修改后的年轻女人对应的音频信息,该音频信息的文本内容与修改前的年轻女人对应的音频信息的文本内容一致,但该音频信息的语音特征为动漫人物对应的语音特征。
190.在本技术中,在播放待播放视频之前,显示与待播放视频所包括的多个音频信息
对应的多个标签,便于用户了解该待播放视频所对应的全部语音对象的身份以区分不同的语音对象,显示简洁明了;除此之外,还方便后续用户对单独的语音对象对应的音频信息进行相关操作,提高了操作的便捷性;
191.通过从多个标签中确定第一目标标签,并在视频播放过程中,仅播放图像序列以及所选中的第一目标标签对应的音频信息,能够有效屏蔽视频采集过程中的环境噪声,还能够屏蔽所涉及到的一些重要或较为隐私的音频信息,以避免因重要或隐私音频泄露所造成的安全问题,从而提高视频播放的安全性和私密性。
192.根据本技术实施例提供的视频处理方法,通过从待播放视频对应的多个音频信息所对应的多个标签中确定第一目标标签,以在视频播放过程中仅播放图像序列以及所确定的第一目标标签对应的音频信息,可以选择性地播放所需的音频信息,并屏蔽其他音频信息,从而避免因重要或隐私音频泄露所造成的安全问题,从而有效保障视频播放的安全性和隐私性。
193.在一些实施例中,在显示视频播放界面210之后,该方法还可以包括:
194.接收对多个标签中第二目标标签的第一输入;
195.响应于第一输入,更新第二目标标签对应的音频信息。
196.在该实施例中,更新后的第二目标标签对应的音频信息可以用于后续视频播放。
197.第一输入用于增删第二目标标签对应的音频信息,或者用于修改第二目标标签对应的音频信息。
198.其中,第一输入可以为如下至少一种方式:
199.其一,第一输入可以为触控操作,包括但不限于点击操作、滑动操作和按压操作等。
200.在该实施方式中,接收第一输入,可以为,接收用户在电子设备的显示屏的显示区域的触控操作。为了降低用户误操作率,可以将第一输入的作用区域限定在特定的区域内,比如显示界面的中间区域。或者在当前界面显示相应控件,触摸相应控件,即可实现第一输入。或者还可以将第一输入设置为在目标时间间隔内对显示区域的连续多次敲击操作。
201.其二,第一输入可以为实体按键输入。
202.在该实施方式中,终端的机身上设有对应的实体按键,接收第一输入,可以为,接收用户按压对应的实体按键的第一输入;第一输入还可以为同时按压多个实体按键的组合操作。
203.其三,第一输入可以为语音输入。
204.在该实施方式中,电子设备可以在接收到语音如“选择男孩对应的标签”时,触发第一输入。
205.当然,在其他实施例中,第一输入也可以为其他形式,包括但不限于字符输入等,具体可根据实际需要决定,本技术实施例对此不作限定。
206.更新第二目标标签对应的音频信息,可以包括:增加第二目标标签对应的音频信息,删减第二目标标签对应的音频信息,修改第二目标标签对应的音频信息的语音特征以及修改第二目标标签对应的音频信息所对应的文本特征等。
207.其中,修改第二目标标签对应的音频信息的语音特征可以包括:修改第二目标标签对应的音频信息的频率特征或音色特征等。
208.在实际执行过程中,可以通过修改音频信息对应的频率特征的参数或音色特征的参数以修改第二目标标签对应的音频信息的语音特征;或者也可以通过修改第二目标标签对应的语音对象的生理特征(如年龄、性别、语速以及频率等),以对应修改该语音对象对应的音频信息的语音特征。
209.在实际执行过程中,用户可以通过第一输入对任意语音对象对应的音频信息进行选择、增加、删除以及修改等操作;电子设备响应于第一输入,生成经用户选择、增加、删除或修改后的该语音对象对应的新的音频信息。
210.该新的音频信息可以用于后续视频播放。
211.在一些实施例中,第一输入可以包括第一子输入和第二子输入,接收对多个标签中第二目标标签的第一输入,可以包括:
212.接收对多个标签中第二目标标签的第一子输入;
213.响应于第一子输入,显示编辑界面460;
214.接收对编辑界面460的第二子输入。
215.在该实施例中,第一子输入用于确定第二目标标签,并触发编辑情景。
216.其中,编辑情景包括但不限于选择、增加、删除以及修改等。
217.第二子输入用于更新第二目标标签对应的音频信息。
218.如图3示例了一种视频播放界面210,每一个标签前显示有与该标签对应的目标控件230,用户点击年轻女人对应的标签所对应的目标控件230,即可实现第一子输入;
219.电子设备响应于第一子输入,跳转至如图4所示的编辑界面460,该编辑界面460包括该语音对象的音频信息所对应的文本信息的全文。
220.在一些实施例中,该全文可以表现为列表形式,如图4所示,该列表中每一条子文本410对应一句话,每一句话对应一个时刻值。
221.用户通过勾选子文本410对应的控件420并点击“确认”对应的控件440即可实现第二子输入,如勾选“这一片海滩是本市人气最高的海滩”以及“海滩的名字叫xxx”等子文本410对应的控件420并进行确认;电子设备响应于第二子输入,将所勾选的子文本410确定为目标子文本410,并将该语音对象对应的音频信息更新为目标子文本410对应的音频信息。
222.又如,继续参考图4,用户点击“+”对应的控件430,以进行添加语音信息的操作,如插入新的文字等,以实现第二子输入;电子设备响应于第二子输入,基于所选的语音对象的语音特征合成所插入新的文字对应的语音信息,并将合成的语音信息添加至该语音对象原本所对应的音频信息中,以生成新的音频信息。
223.又如,继续参考图4,用户点击“编辑”对应的控件450,并修改该语音对象的语音特征,如修改该语音对象的性别、年龄、语速以及频率等;或者也可以直接将该语音对象替换为系统提供的明星或动漫人物等对应的语音特征,从而实现二子输入;电子设备响应于第二子输入,基于修改后的语音对象的语音特征生成该语音对象对应的新的音频信息。
224.根据本技术实施例提供的视频处理方法,通过第一输入以对第二目标标签对应的音频信息进行增删以及修改等操作,使得用户可以基于实际需求对应调整所需播放的音频信息,具有较高的灵活性和实用性,且趣味性较高。
225.下面分别从两种不同的实现角度,对第一目标标签的确定方式进行具体说明。
226.一、用户手动选择第一目标标签
227.在一些实施例中,从多个标签中确定第一目标标签可以包括:
228.接收对视频播放界面210的第二输入;
229.响应于第二输入,从多个标签中确定第一目标标签。
230.在该实施例中,第二输入用于确定第一目标标签。
231.第一目标标签为用于播放的音频信息所对应的标签。
232.第二输入可以为与第一输入相同的触控输入、实体按键输入、语音输入以及字符输入等,在此不作赘述。
233.例如,在显示视频播放界面210的状态下,如图3所示,分别在每一个标签之前显示与该标签对应的目标控件230,触摸目标控件230,如点击年轻女人对应的标签所对应的目标控件230,即可实现第二输入;
234.电子设备响应于第二输入,将年轻女人对应的标签确定为第一目标标签。
235.又如,电子设备可以在接收到语音如“选择男孩对应的标签和海浪声”时,触发第二输入;
236.电子设备响应于第二输入,将男孩对应的标签和海浪对应的标签均确定为第一目标标签。
237.继续参考图3,在电子设备将年轻女人对应的标签确定为第一目标标签之后,点击确认即可进行视频播放;则电子设备将年轻女人对应的音频信息与图像序列进行合成,并播放新合成的视频;该视频包括图像序列和年轻女人对应的音频信息,而不包括男孩、女孩以及海浪等声音。
238.根据本技术实施例提供的视频处理方法,用户通过第二输入从多个音频信息中选择所需的音频信息确定为最终用于视频播放的音频信息,使得用户可以基于实际需求对多个音频信息进行筛选,用户操作空间大且灵活性高。
239.二、电子设备自动确定第一目标标签
240.在一些实施例中,从多个标签中确定第一目标标签可以包括:
241.基于图像序列,从多个标签中确定第一目标标签。
242.在该实施例中,可以通过电子设备自动确定第一目标标签。
243.例如,基于音频信息的内容和图像序列的内容之间的相关性、语音对象是否在图像序列的画面内、语音对象的年龄和性别、音频信息的内容的长短、音频信息的内容是否重复、是否方言以及是否清晰等确定是否将音频信息对应的第一标签确定为第一目标标签。
244.可选地,基于图像序列,从多个标签中确定第一目标标签,可以包括:
245.对图像序列进行图像特征识别,确定图像特征;
246.在语音对象对应的文本信息222与图像特征匹配的情况下,将语音对象对应的标签确定为第一目标标签;文本信息222为对与语音对象对应的音频信息进行文本特征识别确定的。
247.其中,图像特征用于表征图像序列所包含的画面内容。
248.语音对象对应的文本信息222与图像特征匹配,包括文本信息222对应的文本特征与图像特征相同或相似。
249.继续参考图2所示的视频播放界面210,电子设备对该待播放视频的图像序列进行图像特征识别,得到包括年轻女人、男孩、海鸥、海浪、帆船以及沙滩等多个图像特征;
250.同时,电子设备还将对该待播放视频的多个音频信息进行文本识别,以提取得到多个文本特征,如提取到年轻女人对应的文本特征包括:沙滩以及海边等多个关键词。
251.通过比较每一个音频信息所对应的文本特征与图像特征是否匹配,在匹配的情况下,如确定年轻女人对应的文本特征与图像特征均包括沙滩特征的情况下,则确定年轻女人对应的文本特征与图像特征匹配,则将年轻女人对应的标签确定为第一目标标签。
252.在语音对象对应的文本信息222与图像特征不匹配的情况下,则在后续视频播放过程中屏蔽该语音对象对应的音频信息。
253.可选地,基于图像序列,从多个标签中确定第一目标标签还还可以包括:
254.对图像序列进行图像特征识别,确定图像序列包含的发声对象;
255.将发声对象对应的标签确定为第一目标标签。
256.在该实施例中,通过判断语音对象是否在待播放视频的画面内,来确定是否播放该语音对象的音频信息。
257.当语音对象在待播放视频的画面内时,则播放该语音对象的音频信息;而当语音对象不在待播放视频的画面内时,则不播放该语音对象的音频信息。从而能够有效去除画外音,保证所播放的视频的画面与声音具有一致性。
258.可选地,基于图像序列,从多个标签中确定第一目标标签还还可以包括:基于用户的喜好信息、语音对象的生理特征、各标签对应的音频信息的质量以及各标签对应的音频信息的特点中的至少一项,从多个标签中确定第一目标标签。
259.在该实施例中,用户的喜好信息包括:用户的历史使用习惯、使用偏好以及播放目的等。
260.语音对象的生理特征包括:语音对象的年龄以及性别等。
261.各标签对应的音频信息的特点包括:音频信息的内容的长短、内容是否重复以及是否为方言等。
262.各标签对应的音频信息的质量包括:音频是否清晰以及音频是否完整等。
263.在实际执行过程中,电子设备可以基于用户的喜好信息、语音对象的生理特征、各标签对应的音频信息的质量以及各标签对应的音频信息的特点中的至少一项,来判断该任意标签对应的音频信息是否为用户喜欢的内容;在确定为用户喜欢的内容的情况下,则将该标签确定为第一目标标签。
264.当然,在其他实施例中,还可以基于其他标准来确定第一目标标签,本技术不作限定。
265.根据本技术实施例提供的视频处理方法,通过电子设备自动基于图像序列筛选与图像序列匹配的音频信息作为最终用于合成视频的音频信息,可以自动实现自动降噪以及消除环境音等功能,从而提高视频播放的语音清晰度,以提高视频播放效果,有效减少用户的操作步骤,智能化程度较高。
266.下面以目标界面为视频采集界面为例,对该实施例进行说明。
267.在一些实施例中,步骤110还可以包括:
268.接收第四输入;
269.响应于第四输入,显示视频采集界面,所述视频采集界面包括至少一个标签。
270.在该实施例中,第四输入用于进行视频采集且显示视频采集界面。
271.第四输入可以为与第一输入相同的触控输入、实体按键输入、语音输入以及字符输入等,在此不作赘述。
272.标签用于表征当前时刻下所采集的音频信息中的语音对象的信息。
273.标签与语音对象一一对应。
274.可以理解的是,标签所对应的语音对象可能为当前采集的图像序列所包括的发声对象,也可能为当前采集的图像序列所不包括的发声对象;其中当前采集的音频信息与当前采集的图像序列相对应。
275.在一些实施例中,标签可以包括语音对象的标识,以及语音对象对应的文本特征;文本信息为对与语音对象对应的音频信息进行文本特征识别确定的。
276.其中,标识可以为语音对象的头像、昵称或id等。
277.在标识表现为头像的情况下,标识可以为图像序列中的头像信息,也可以为系统预设头像。
278.标识的确定步骤与视频播放情景下的标识的确定步骤一致,在此不作赘述。
279.例如,在实际执行过程中,用户点击开始控件,以实现第四输入;
280.电子设备响应于第四输入,开启摄像头以采集图像序列,开启拾音器以采集音频信息。
281.在采集的同时,显示视频拍摄界面,该视频拍摄界面包括当前时刻下所采集的图像序列,以及当前时刻下所采集的音频信息对应的标签。
282.其中,标签的数量与当前时刻下所采集的全部音频信息所对应的语音对象的数量一致。
283.例如,在采集上文中的待播放视频时,电子设备对当前时刻下所采集的图像序列进行图像特征识别,确定图像序列包含的发声对象包括:男孩、年轻女人和海浪等;并从图像序列中提取发声对象对应的头像信息;
284.同时,电子设备还会对当前时刻所采集的音频信息进行语音特征识别,确定语音对象包括:男孩、女孩、年轻女人和海浪等。
285.然后,电子设备对语音对象与头像信息进行匹配。
286.在二者匹配的情况下,将头像信息确定为语音对象的标识并在屏幕中显示,如显示年轻女人对应的头像信息;
287.在二者不匹配的情况下,确定语音对象对应的生理特征,从存储的多个预设头像中筛选得到与该生理特征匹配的预设头像作为该语音对象的标识并在屏幕中显示,如显示女孩对应的预设头像。
288.在一些实施例中,电子设备还会对当前采集的音频信息进行文本特征识别,得到各语音对象对应的音频信息的文本信息,并将文本信息显示于屏幕,如在男孩对应的标识后显示男孩对应的文本信息。
289.点击停止控件,即可结束拍摄。
290.电子设备将采集的图像序列和音频信息进行存储。
291.根据本技术实施例提供的视频处理方法,通过在视频采集过程中,同步显示当前时刻采集的音频信息中各语音对象对应的标签,便于用户实时了解音频信息的采集情况,且无需用户手动识别,自动化程度高,且操作简单便捷。
292.本技术实施例提供的视频处理方法,执行主体可以为视频处理装置。本技术实施例中以视频处理装置执行视频处理方法为例,说明本技术实施例提供的视频处理装置。
293.本技术实施例还提供一种视频处理装置。
294.如图5所示,该视频处理装置包括:第一获取模块510、第一处理模块520和第二处理模块530。
295.第一获取模块510,用于获取图像序列和多个音频信息,多个音频信息与多个语音对象一一对应;
296.第一处理模块520,用于基于图像序列对应的特征、音频信息对应的特征和语音对象对应的特征中的至少一种,从多个音频信息中确定目标音频信息;
297.第二处理模块530,用于基于图像序列和目标音频信息,生成目标视频。
298.根据本技术实施例提供的视频处理装置,通过图像序列对应的特征、音频信息对应的特征和语音对象对应的特征中的至少一种,从多个音频信息中确定目标音频信息,并基于确定的目标音频信息和获取的图像序列合成目标视频,丰富了视频的生成方式。
299.在一些实施例中,第一处理模块520,还可以用于:
300.对图像序列进行特征提取,得到多个图像特征;对多个音频信息进行特征提取得到多个文本信息;
301.在多个文本信息中目标文本信息与图像特征匹配的情况下,将目标文本信息对应的音频信息确定为目标音频信息;
302.或者,在多个图像特征包括多个语音对象中第一目标语音对象对应的特征的情况下,将第一目标语音对象对应的音频信息确定为目标音频信息;
303.或者,在多个语音对象中第二目标语音对象对应的生理特征与图像特征对应的生理特征匹配的情况下,将第二目标语音对象对应的音频信息确定为目标音频信息;
304.或者,在多个语音对象中第三目标语音对象对应的音频信息的质量满足目标条件的情况下,将第三目标语音对象对应的音频信息确定为目标音频信息。
305.在一些实施例中,该装置还可以包括:第一显示模块,用于显示目标界面,目标界面包括图像序列和多个标签,多个标签与多个语音对象一一对应,目标界面包括视频采集界面或视频播放界面。
306.在一些实施例中,该装置还可以包括::
307.第二处理模块,用于对多个音频信息进行语音特征识别,确定各音频信息对应的语音对象;
308.第三处理模块,用于对图像序列进行图像特征识别,确定图像序列中发声对象对应的头像信息;
309.第四处理模块,用于在语音对象与头像信息匹配的情况下,将头像信息确定为语音对象的标识;
310.第五处理模块,用于在语音对象与头像信息不匹配的情况下,将存储的目标预设头像确定为语音对象的标识。
311.在一些实施例中,第五处理模块,还可以用于:
312.基于语音对象对应的音频信息的语音特征,确定语音对象的生理特征;
313.基于生理特征,从存储的多个预设头像中筛选得到目标预设头像;
314.将目标预设头像确定为语音对象的标识。
315.在一些实施例中,该装置还可以包括:
316.第二显示模块,用于在基于图像序列和目标音频信息,生成目标视频之后,显示视频播放界面,视频播放界面包括图像序列和多个标签,多个标签与多个语音对象一一对应;
317.第六处理模块,用于从多个标签中确定第一目标标签;
318.第七处理模块,用于基于时间顺序,播放图像序列和与第一目标标签对应的音频信息。
319.在一些实施例中,该装置还可以包括:
320.第一接收模块,用于在显示视频播放界面之后,接收对多个标签中第二目标标签的第一输入;
321.第八处理模块,用于响应于第一输入,更新第二目标标签对应的音频信息。
322.在一些实施例中,第六处理模块,还可以用于:
323.接收对视频播放界面的第二输入;
324.响应于第二输入,从多个标签中确定第一目标标签。
325.在一些实施例中,第六处理模块,还可以用于:基于图像序列,从多个标签中确定第一目标标签。
326.本技术实施例中的视频处理装置可以是电子设备,也可以是电子设备中的部件,例如集成电路或芯片。该电子设备可以是终端,也可以为除终端之外的其他设备。示例性的,电子设备可以为手机、平板电脑、笔记本电脑、掌上电脑、车载电子设备、移动上网装置(mobile internet device,mid)、增强现实(augmented reality,ar)/虚拟现实(virtual reality,vr)设备、机器人、可穿戴设备、超级移动个人计算机(ultra-mobile personal computer,umpc)、上网本或者个人数字助理(personal digital assistant,pda)等,还可以为个人计算机(personal computer,pc)、电视机(television,tv)、柜员机或者自助机等,本技术实施例不作具体限定。
327.本技术实施例中的视频处理装置可以为具有操作系统的装置。该操作系统可以为安卓(android)操作系统,可以为ios操作系统,还可以为其他可能的操作系统,本技术实施例不作具体限定。
328.本技术实施例提供的视频处理装置能够实现图1至图4的方法实施例实现的各个过程,为避免重复,这里不再赘述。
329.可选地,如图6所示,本技术实施例还提供一种电子设备600,包括处理器601,存储器602,存储在存储器602上并可在所述处理器601上运行的程序或指令,该程序或指令被处理器601执行时实现上述视频处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
330.需要说明的是,本技术实施例中的电子设备包括上述所述的移动电子设备和非移动电子设备。
331.图7为实现本技术实施例的一种电子设备的硬件结构示意图。
332.该电子设备700包括但不限于:射频单元701、网络模块702、音频输出单元703、输入单元704、传感器705、显示单元706、用户输入单元707、接口单元708、存储器709以及处理器710等部件。
333.本领域技术人员可以理解,电子设备700还可以包括给各个部件供电的电源(比如电池),电源可以通过电源管理系统与处理器710逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。图7中示出的电子设备结构并不构成对电子设备的限定,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置,在此不再赘述。
334.其中,输入单元704,用于获取图像序列和多个音频信息,多个音频信息与多个语音对象一一对应;
335.处理器710,用于基于图像序列对应的特征、音频信息对应的特征和语音对象对应的特征中的至少一种,从多个音频信息中确定目标音频信息;
336.处理器710,用于基于图像序列和目标音频信息,生成目标视频。
337.根据本技术实施例提供的电子设备,通过通过图像序列对应的特征、音频信息对应的特征和语音对象对应的特征中的至少一种,从多个音频信息中确定目标音频信息,并基于确定的目标音频信息和获取的图像序列合成目标视频,丰富了视频的生成方式。
338.可选地,处理器710,还用于:
339.对图像序列进行特征提取,得到多个图像特征;对多个音频信息进行特征提取得到多个文本信息;
340.在多个文本信息中目标文本信息与图像特征匹配的情况下,将目标文本信息对应的音频信息确定为目标音频信息;
341.或者,在多个图像特征包括多个语音对象中第一目标语音对象对应的特征的情况下,将第一目标语音对象对应的音频信息确定为目标音频信息;
342.或者,在多个语音对象中第二目标语音对象对应的生理特征与图像特征对应的生理特征匹配的情况下,将第二目标语音对象对应的音频信息确定为目标音频信息;
343.或者,在多个语音对象中第三目标语音对象对应的音频信息的质量满足目标条件的情况下,将第三目标语音对象对应的音频信息确定为目标音频信息。
344.可选地,显示单元706,用于显示目标界面,目标界面包括图像序列和多个标签,多个标签与多个语音对象一一对应,目标界面包括视频采集界面或视频播放界面。
345.可选地,标签包括语音对象的标识,以及语音对象对应的文本信息;文本信息为对与语音对象对应的音频信息进行文本特征识别确定的。
346.可选地,处理器710,还用于:
347.对多个音频信息进行语音特征识别,确定各音频信息对应的语音对象;
348.对图像序列进行图像特征识别,确定图像序列中发声对象对应的头像信息;
349.在语音对象与头像信息匹配的情况下,将头像信息确定为语音对象的标识;
350.在语音对象与头像信息不匹配的情况下,将存储的目标预设头像确定为语音对象的标识。
351.可选地,处理器710,还用于:
352.基于语音对象对应的音频信息的语音特征,确定语音对象的生理特征;
353.基于生理特征,从存储的多个预设头像中筛选得到目标预设头像;
354.将目标预设头像确定为语音对象的标识。
355.可选地,
356.显示单元706,还用于在基于图像序列和目标音频信息,生成目标视频之后,显示视频播放界面,视频播放界面包括图像序列和多个标签,多个标签与多个语音对象一一对应;
357.处理器710,还用于从多个标签中确定第一目标标签;
358.基于时间顺序,播放图像序列和与第一目标标签对应的音频信息。
359.可选地,
360.用户输入单元707,用于在显示视频播放界面之后,接收对多个标签中第二目标标签的第一输入;
361.处理器710,还用于响应于第一输入,更新第二目标标签对应的音频信息。
362.可选地,处理器710,还用于:
363.接收对视频播放界面的第二输入;
364.响应于第二输入,从多个标签中确定第一目标标签。
365.可选地,处理器710,还用于基于图像序列,从多个标签中确定第一目标标签。
366.应理解的是,本技术实施例中,输入单元704可以包括图形处理器(graphics processing unit,gpu)7041和麦克风7042,图形处理器7041对在视频捕获模式或图像捕获模式中由图像捕获装置(如摄像头)获得的静态图片或视频的图像数据进行处理。显示单元706可包括显示面板7061,可以采用液晶显示器、有机发光二极管等形式来配置显示面板7061。用户输入单元707包括触控面板7071以及其他输入设备7072中的至少一种。触控面板7071,也称为触摸屏。触控面板7071可包括触摸检测装置和触摸控制器两个部分。其他输入设备7072可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆,在此不再赘述。
367.存储器709可用于存储软件程序以及各种数据。存储器709可主要包括存储程序或指令的第一存储区和存储数据的第二存储区,其中,第一存储区可存储操作系统、至少一个功能所需的应用程序或指令(比如声音播放功能、图像播放功能等)等。此外,存储器709可以包括易失性存储器或非易失性存储器,或者,存储器709可以包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(read-only memory,rom)、可编程只读存储器(programmable rom,prom)、可擦除可编程只读存储器(erasable prom,eprom)、电可擦除可编程只读存储器(electrically eprom,eeprom)或闪存。易失性存储器可以是随机存取存储器(random access memory,ram),静态随机存取存储器(static ram,sram)、动态随机存取存储器(dynamic ram,dram)、同步动态随机存取存储器(synchronous dram,sdram)、双倍数据速率同步动态随机存取存储器(double data rate sdram,ddrsdram)、增强型同步动态随机存取存储器(enhanced sdram,esdram)、同步连接动态随机存取存储器(synch link dram,sldram)和直接内存总线随机存取存储器(direct rambus ram,drram)。本技术实施例中的存储器709包括但不限于这些和任意其它适合类型的存储器。
368.处理器710可包括一个或多个处理单元;可选地,处理器710集成应用处理器和调制解调处理器,其中,应用处理器主要处理涉及操作系统、用户界面和应用程序等的操作,调制解调处理器主要处理无线通信信号,如基带处理器。可以理解的是,上述调制解调处理器也可以不集成到处理器710中。
369.本技术实施例还提供一种可读存储介质,所述可读存储介质上存储有程序或指
令,该程序或指令被处理器执行时实现上述视频处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
370.其中,所述处理器为上述实施例中所述的电子设备中的处理器。所述可读存储介质,包括计算机可读存储介质,如计算机只读存储器rom、随机存取存储器ram、磁碟或者光盘等。
371.本技术实施例另提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现上述视频处理方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
372.应理解,本技术实施例提到的芯片还可以称为系统级芯片、系统芯片、芯片系统或片上系统芯片等。
373.本技术实施例提供一种计算机程序产品,该程序产品被存储在存储介质中,该程序产品被至少一个处理器执行以实现如上述显示方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
374.需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。此外,需要指出的是,本技术实施方式中的方法和装置的范围不限按示出或讨论的顺序来执行功能,还可包括根据所涉及的功能按基本同时的方式或按相反的顺序来执行功能,例如,可以按不同于所描述的次序来执行所描述的方法,并且还可以添加、省去、或组合各种步骤。另外,参照某些示例所描述的特征可在其他示例中被组合。
375.通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分可以以计算机软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端(可以是手机,计算机,服务器,或者网络设备等)执行本技术各个实施例所述的方法。
376.上面结合附图对本技术的实施例进行了描述,但是本技术并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本技术的启示下,在不脱离本技术宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本技术的保护之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1