一种诈骗用户识别方法、装置、电子设备和存储介质与流程
本发明涉及通信安全,特别是涉及一种诈骗用户识别方法、一种诈骗用户识别装置、一种电子设备和一种计算机可读存储介质。
背景技术:
1、目前,电信网络诈骗逐渐显现出诈骗话术更新快、呼叫特征隐藏性强等新趋势与新特点。而电信运营商采用的传统诈骗电话检测方法大多是基于语义特征识别与呼叫行为特征分析的,尽管已取得较为突出的涉诈号码识别与拦截效果,但在面对使用新型诈骗话术的诈骗行为、具有低频呼叫特征的诈骗行为、伪装高可信度用户的诈骗行为等的时候,也存在着误拦截率较高、难以适应复杂应用场景的局限性。
技术实现思路
1、鉴于上述问题,提出了本发明实施例以便提供一种克服上述问题或者至少部分地解决上述问题的一种诈骗用户识别方法和相应的一种诈骗用户识别装置、一种电子设备,以及一种计算机可读存储介质。
2、本发明实施例公开了一种诈骗用户识别方法,所述方法包括:
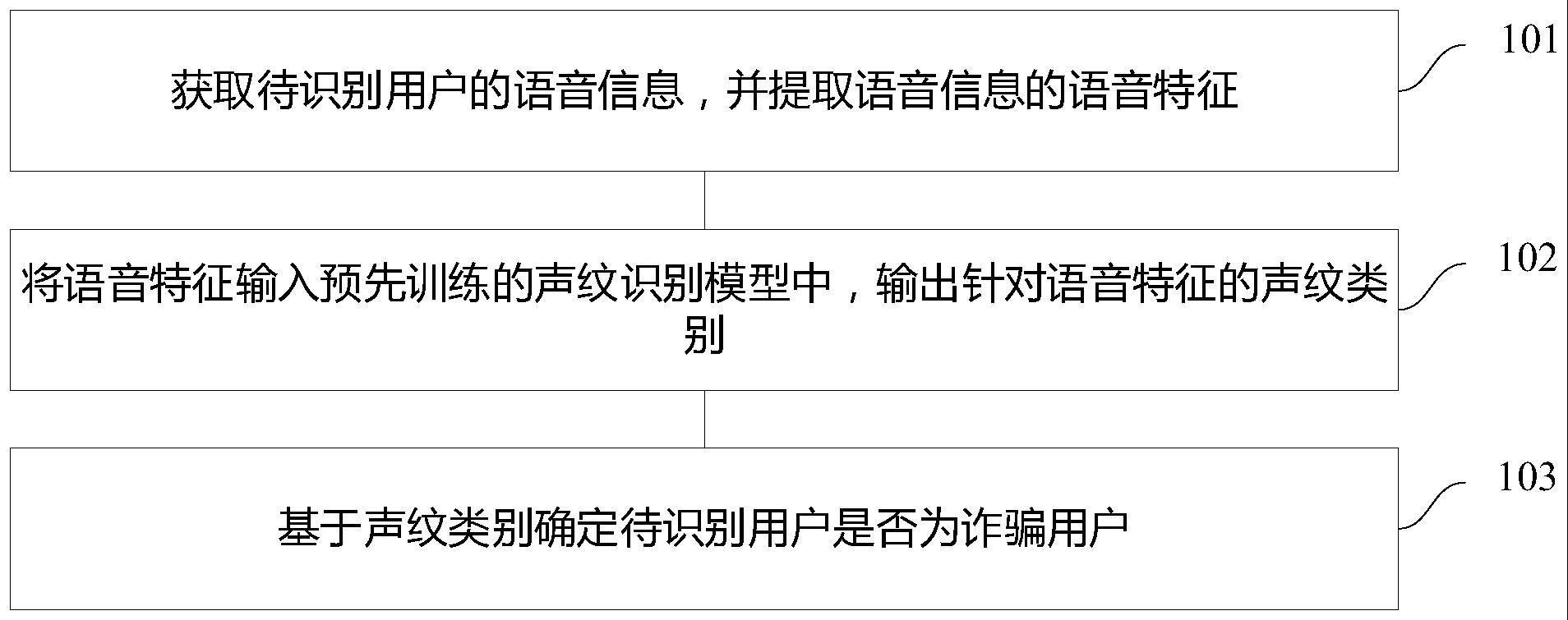
3、获取待识别用户的语音信息,并提取所述语音信息的语音特征;
4、将所述语音特征输入预先训练的声纹识别模型中,输出针对所述语音特征的声纹类别;其中,所述声纹识别模型由输入层、bi lstm层、注意力层、全连接层和分类层依次连接而成;所述声纹类别为通过所述输入层接收所述语音特征,通过所述bi lstm层提取针对所述语音特征的声纹特征,通过所述注意力层基于注意力机制获得针对所述声纹特征的注意力特征表达,以及通过所述全连接层对所述注意力特征表达进行加权计算后,由所述分类层基于进行加权计算后的所述注意力特征表达确定的;
5、基于所述声纹类别确定所述待识别用户是否为诈骗用户。
6、可选地,所述预先训练的声纹识别模型通过以下方式训练得到:
7、获取预先建立的声纹数据库中的语音样本;
8、对所述语音样本依次进行预加重处理和分帧加窗处理,获取多个样本帧;
9、对所述样本帧进行傅里叶变换,以获取各所述样本帧分别对应的能量密度谱;
10、基于各所述样本帧分别对应的能量密度谱确定各所述样本帧分别对应的梅尔频率倒谱系数;
11、基于各所述样本帧分别对应的梅尔频率倒谱系数确定针对所述语音样本的所述语音特征样本;
12、采用所述语音特征样本进行模型训练,得到用于分辨声纹类别的所述声纹识别模型。
13、可选地,所述基于各所述样本帧分别对应的梅尔频率倒谱系数确定针对所述语音样本的所述语音特征样本,包括:
14、确定所述梅尔频率倒谱系数所对应的mfcc一阶差分参数和mfcc二阶差分参数,并将所述mfcc一阶差分参数和所述mfcc二阶差分参数作为针对所述语音样本的所述语音特征样本。
15、可选地,所述获取预先建立的声纹数据库中的语音样本,包括:
16、获取灰名单数据库;所述灰名单数据库中存储有预先收集的疑似异常号码和各所述疑似异常号码分别对应的号码呼叫行为信息;
17、基于所述疑似异常号码和对应的所述号码呼叫行为信息,确定所述疑似异常号码为异常号码的置信度;
18、若所述置信度大于预设置信度阈值,则确定所述疑似异常号码为异常号码,将所述异常号码导出,生成黑名单号码数据库;
19、对所述黑名单号码数据库中的所述异常号码的通话内容进行录音,并将所述录音作为所述语音样本存储于所述声纹数据库中。
20、可选地,所述号码呼叫行为信息包括预设周期内的主叫呼叫占比、主叫呼叫频次、被叫号码外省归属占比、预设周期内的短通话时长占比和预设时间段内的呼叫活跃度,所述基于所述疑似异常号码和对应的所述号码呼叫行为信息,确定所述疑似异常号码为异常号码的置信度,包括:
21、基于所述预设周期内的主叫呼叫占比、所述主叫呼叫频次和所述被叫号码外省归属占比确定针对所述疑似异常号码的第一疑似度;
22、将所述疑似异常号码所对应的tac码与预设tac码进行匹配,根据匹配结果确定针对所述疑似异常号码的第二疑似度;
23、基于所述预设周期内的短通话时长占比确定针对所述疑似异常号码的第三疑似度;
24、基于所述预设时间段内的呼叫活跃度确定针对所述疑似异常号码的第四疑似度;
25、基于所述第一疑似度、第二疑似度、第三疑似度和第四疑似度确定所述置信度。
26、可选地,所述基于所述第一疑似度、第二疑似度、第三疑似度和第四疑似度确定所述置信度,包括:
27、确定与所述第一疑似度对应的第一贡献度,并计算所述第一疑似度与所述第一贡献度的第一乘积;
28、确定与所述第二疑似度对应的第二贡献度,并计算所述第二疑似度与所述第二贡献度的第二乘积;
29、确定与所述第三疑似度对应的第三贡献度,并计算所述第三疑似度与所述第三贡献度的第三乘积;
30、确定与所述第四疑似度对应的第四贡献度,并计算所述第四疑似度与所述第四贡献度的第四乘积;
31、将所述第一乘积、第二乘积、第三乘积和所述第四乘积的和值作为所述置信度。
32、可选地,所述声纹类别包括诈骗声纹类别,所述基于所述声纹类别确定所述待识别用户是否为诈骗用户,包括:
33、若所述声纹类别为所述诈骗声纹类别,则确定所述待识别用户为诈骗用户。
34、本发明实施例还公开了一种诈骗用户识别装置,所述装置包括:
35、获取及提取模块,用于获取待识别用户的语音信息,并提取所述语音信息的语音特征;
36、输入及输出模块,用于将所述语音特征输入预先训练的声纹识别模型中,输出针对所述语音特征的声纹类别;其中,所述声纹识别模型由输入层、bi lstm层、注意力层、全连接层和分类层依次连接而成;所述声纹类别为通过所述输入层接收所述语音特征,通过所述bi lstm层提取针对所述语音特征的声纹特征,通过所述注意力层基于注意力机制获得针对所述声纹特征的注意力特征表达,以及通过所述全连接层对所述注意力特征表达进行加权计算后,由所述分类层基于进行加权计算后的所述注意力特征表达确定的;
37、第一确定模块,用于基于所述声纹类别确定所述待识别用户是否为诈骗用户。
38、可选地,所述装置还用于训练所述获得所述声纹识别模型,所述装置还包括:
39、第一获取模块,用于获取预先建立的声纹数据库中的语音样本;
40、第二获取模块,用于对所述语音样本依次进行预加重处理和分帧加窗处理,获取多个样本帧;
41、第三获取模块,用于对所述样本帧进行傅里叶变换,以获取各所述样本帧分别对应的能量密度谱;
42、第二确定模块,用于基于各所述样本帧分别对应的能量密度谱确定各所述样本帧分别对应的梅尔频率倒谱系数;
43、第三确定模块,用于基于各所述样本帧分别对应的梅尔频率倒谱系数确定针对所述语音样本的所述语音特征样本;
44、模型训练模块,用于采用所述语音特征样本进行模型训练,得到用于分辨声纹类别的所述声纹识别模型。
45、可选地,所述第三确定模块,包括:
46、第一确定子模块,用于确定所述梅尔频率倒谱系数所对应的mfcc一阶差分参数和mfcc二阶差分参数,并将所述mfcc一阶差分参数和所述mfcc二阶差分参数作为针对所述语音样本的所述语音特征样本。
47、可选地,所述第一获取模块,包括:
48、获取子模块,用于获取灰名单数据库;所述灰名单数据库中存储有预先收集的疑似异常号码和各所述疑似异常号码分别对应的号码呼叫行为信息;
49、第二确定子模块,用于基于所述疑似异常号码和对应的所述号码呼叫行为信息,确定所述疑似异常号码为异常号码的置信度;
50、导出及生成子模块,用于若所述置信度大于预设置信度阈值,则确定所述疑似异常号码为异常号码,将所述异常号码导出,生成黑名单号码数据库;
51、录音及确定子模块,用于对所述黑名单号码数据库中的所述异常号码的通话内容进行录音,并将所述录音作为所述语音样本存储于所述声纹数据库中。
52、可选地,所述号码呼叫行为信息包括预设周期内的主叫呼叫占比、主叫呼叫频次、被叫号码外省归属占比、预设周期内的短通话时长占比和预设时间段内的呼叫活跃度,所述第二确定子模块,包括:
53、第一确定单元,用于基于所述预设周期内的主叫呼叫占比、所述主叫呼叫频次和所述被叫号码外省归属占比确定针对所述疑似异常号码的第一疑似度;
54、第二确定单元,用于将所述疑似异常号码所对应的tac码与预设tac码进行匹配,根据匹配结果确定针对所述疑似异常号码的第二疑似度;
55、第三确定单元,用于基于所述预设周期内的短通话时长占比确定针对所述疑似异常号码的第三疑似度;
56、第四确定单元,用于基于所述预设时间段内的呼叫活跃度确定针对所述疑似异常号码的第四疑似度;
57、第五确定单元,用于基于所述第一疑似度、第二疑似度、第三疑似度和第四疑似度确定所述置信度。
58、可选地,所述第五确定单元,包括:
59、第一确定及计算子单元,用于确定与所述第一疑似度对应的第一贡献度,并计算所述第一疑似度与所述第一贡献度的第一乘积;
60、第二确定及计算子单元,用于确定与所述第二疑似度对应的第二贡献度,并计算所述第二疑似度与所述第二贡献度的第二乘积;
61、第三确定及计算子单元,用于确定与所述第三疑似度对应的第三贡献度,并计算所述第三疑似度与所述第三贡献度的第三乘积;
62、第四确定及计算子单元,用于确定与所述第四疑似度对应的第四贡献度,并计算所述第四疑似度与所述第四贡献度的第四乘积;
63、置信度确定单元,用于将所述第一乘积、第二乘积、第三乘积和所述第四乘积的和值作为所述置信度。
64、可选地,所述声纹类别包括诈骗声纹类别,所述第一确定模块,包括:
65、第三确定子模块,用于若所述声纹类别为所述诈骗声纹类别,则确定所述待识别用户为诈骗用户。
66、本发明实施例还公开了一种电子设备,包括:处理器、存储器及存储在所述存储器上并能够在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现如上所述一种诈骗用户识别方法的步骤。
67、本发明实施例还公开了一种计算机可读存储介质,所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现如上所述一种诈骗用户识别方法的步骤。
68、本发明实施例包括以下优点:
69、在本发明实施例中,声纹识别模型由输入层、bi lstm层、注意力层、全连接层和分类层依次连接而成,可以通过输入层接收待识别用户所对应的语音特征,通过bi lstm层提取针对该语音特征的声纹特征,通过注意力层基于注意力机制获得针对该声纹特征的注意力特征表达,通过全连接层对该注意力特征表达进行加权计算,以及通过分类层基于进行加权计算后的注意力特征表达确定该语音特征所属的声纹类别,采用该声纹类别确定待识别用户是否为诈骗用户。通过采用上述方法,声纹识别模型选用bi-lstm网络学习语音声纹的特征并对其进行识别,bi-lstm网络能够全局化处理和持续记忆多时刻信息,相比较于卷积神经网络等其他深度神经网络,bi-lstm网络在分析、处理时间序列数据时具有更大的优越性;将声纹识别方法与传统涉诈号码分析方法结合,提升了现有涉诈判别技防体系的适应性,声纹识别技术更注重于语音呼叫主体的生物特征,可以更好地识别频繁更换终端、呼叫行为模式不明确、变声处理等特殊场景下的涉诈行为。
- 还没有人留言评论。精彩留言会获得点赞!