一种基于特定人物音色的语音实时合成方法与流程
1.本发明涉及计算机软件技术领域,特别涉及一种基于特定人物音色的语音实时合成方法。
背景技术:
2.文本到语音转换技术作为语音信号处理领域的核心研究内容,对该技术的研究与应用是学界与业界的关注重点。
3.文本到语音技术起源于二十世纪七十年代末期,最初的实现方式是基于语言规则拼接声音波形片段,以达到合成一段人声音频的目的。在英文语音合成中,由麻省理工学院研发的dectalk可以发出7种不同音色的语音,在发音速度增加到每分钟350词时,也可以保持清晰、自然的效果。在中文语音合成中,日本matsushita电子公司基于dectalk系统的技术也开发了可以将汉语文本转换成口语音频的系统。用波形拼接技术来合成语音时,能很好地保持原始拼接单元的语音声学特征,因而在有限词汇语音的合成中得到了广泛的应用,例如公共汽车报站器,以及用于特定领域文本语音转换系统中。但是,这种实现方式的缺陷在于需要人工处理大量的语料数据,并基于特定语言的知识背景制定语法及发音规则,同时难以通过上下文控制声音的韵律,导致生成人声的自然程度较低。
4.与此同时,基于声道模型的参数合成方法也在发展,根据声道特性的描述方式不同,形成了线性预测合成方法和共振峰合成方法两条技术路线。随着技术的发展,基于统计模型的参数化声音合成技术开始崭露头角,隐马尔可夫模型与高斯混合模型走到了台前,可实现文本语音转换系统的自动训练与构建,所以又被称为可训练的语音合成。其基本技术思想是对输入的语音数据进行声学参数的建模,并以训练得到的统计模型为基础构建相应的合成系统。
5.进入二十一世纪后,基于深度学习理论的语音处理技术得到了全面突破,性能显著提高,相应的研究工作在模型设计的细化、参数提取和优化,以及系统的自适应技术等方面取得了一些关键性的进展。端到端的深度学习语音合成技术是基于传统参数化模型的合成思路进行构建的,理论上可以合成高度拟人的语音,但由于过于深度学习模型参数量过大,导致需要大量训练数据才能使模型收敛,使得深度学习方案往往难以落地。
技术实现要素:
6.本发明的目的在于提供一种基于特定人物音色的语音实时合成方法,能够在给定特定人物的语音数据样本并且计算资源有限的情况下,基于给定的文本实时生成与特定人物音色相符的语音音频的模型,本方法以语音风格量化技术、语音合成技术为切入点,基于说话人物识别技术中对特定人物音色的建模方法与频域信息波形重建方法,对模型效率与性能进行优化。
7.为实现上述目的,本发明的技术方案是:一种基于特定人物音色的语音实时合成方法,包括:
8.数据预处理阶段,对原始音频数据进行规范化操作;
9.数据向量化阶段,将中文文本数据转化为拼音表示后,再转化为拼音所对应的向量编码序列,并使用带通滤波器组对文本对应的音频进行滑动窗口滤波,得到音频对应的频谱;
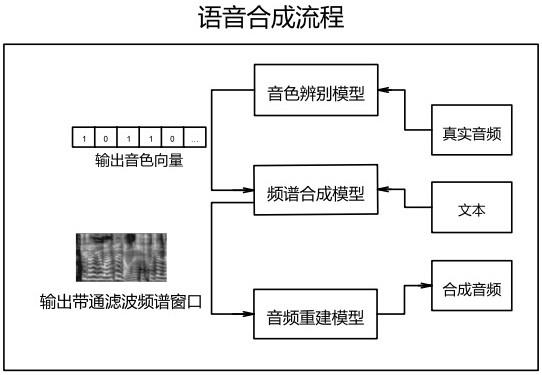
10.模型构建阶段,构建用于特定人物声音合成的神经网络模型,模型分为三个部分进行实现,分别是音色辨别模型、频谱合成模型、音频重建模型;
11.模型训练阶段,对音色辨别模型、频谱合成模型、音频重建模型分别进行拟合;音色辨别模型,采用说话人辨别的任务目标对音色辨别模型进行拟合;频谱合成模型,基于中文文本与音色辨别模型的输出的音色向量,对频谱合成模型进行拟合;音频重建模型,基于真实中文音频以及音频对应的带通滤波频谱对音频重建模型进行拟合;
12.模型推理阶段,将中文文本与特定人物的音色向量输入频谱合成模型,再将输出频谱输入到音频重建模型,最终合成出特定人物音色的语音片段。
13.相较于现有技术,本发明具有以下有益效果:本发明方法所合成的音频在语音流畅度上显著的优于声音波形拼接方案,在音色模仿任务中,能够实现实时计算并且提供拟真的音色迁移性能,现有的音色模仿方案大多需要长时间计算,无法满足实时合成的需要。并且本专利中完成音色迁移只需要特定人物十分钟左右的音频片段,其余方案在音频数据需求上往往是小时级别的时长。用户在使用本发明方法所提出的模型拟合与构建方案时,可以降低计算与时间成本,并且在有限的数据样本下,就可以实现特定人物的音色迁移以及语音合成,可以降低播音主持、直播带货、旅游解说等场景下对于人工的高度依赖。并且由于本发明在对门控循环神经网络的建模,使得在移动端等计算性能有限的设备上实现声音合成成为了现实的可能。
附图说明
14.图1为本发明语音合成流程示意图。
15.图2为本发明模型训练阶段流程示意图。
16.图3为本发明模型推理阶段流程示意图。
具体实施方式
17.下面结合附图,对本发明的技术方案进行具体说明。
18.本发明一种基于特定人物音色的语音实时合成方法,包括:
19.数据预处理阶段,对原始音频数据进行规范化操作;
20.数据向量化阶段,将中文文本数据转化为拼音表示后,再转化为拼音所对应的向量编码序列,并使用带通滤波器组对文本对应的音频进行滑动窗口滤波,得到音频对应的频谱;
21.模型构建阶段,构建用于特定人物声音合成的神经网络模型,模型分为三个部分进行实现,分别是音色辨别模型、频谱合成模型、音频重建模型;
22.模型训练阶段,对音色辨别模型、频谱合成模型、音频重建模型分别进行拟合;音色辨别模型,采用说话人辨别的任务目标对音色辨别模型进行拟合;频谱合成模型,基于中文文本与音色辨别模型的输出的音色向量,对频谱合成模型进行拟合;音频重建模型,基于
真实中文音频以及音频对应的带通滤波频谱对音频重建模型进行拟合;
23.模型推理阶段,将中文文本与特定人物的音色向量输入频谱合成模型,再将输出频谱输入到音频重建模型,最终合成出特定人物音色的语音片段。
24.以下为本发明具体实现过程。
25.如图1所示,本发明一种基于特定人物音色的语音实时合成方法,包括如下步骤:
26.步骤1、数据预处理阶段
27.本专利中所定义的模型输入数据采用真人录音,录音中普遍存在背景噪声、电流噪声、吞咽口水音以及长间隔空白片段等音频瑕疵,为了保证数据特征的有效性,以及模型收敛的稳定性,需要对原始音频进行规范化操作。第一步,对音频数据的振幅进行标准化处理,保证数据集中音频的人声处于同一响度水平。第二步,选用带通滤波器对背景与电流噪声频段进行滤波抑制噪声信号。第三步,对音频信号进行窗口积分操作以计算能量谱,通过窗口内的信号能量划分空白音频片段,并对片段进行裁剪。第四步,对数据集内的音频片段在人声信号频段重新采样,使得数据进一步规范化,并去除超出人声频段的高频信号。
28.步骤2、数据向量化阶段
29.原始音频数据经过预处理后,已经完成了初步向量化过程,还需要使用非线性滤波器组对音频进行窗口滤波,得到音频对应的非线性频谱。在步骤2中需要对中文文本数据进行向量化操作,第一步,将中文文本数据转化为拼音表示,第二步,将拼音表示转化为拼音字典中所对应的向量编码,第三步,将拼音向量编码单元组合为向量序列。
30.步骤3、模型构建阶段
31.在步骤3中构建特定人物声音合成技术所依赖的神经网络模型,模型分为三个部分进行实现,分别是音色辨别模型、频谱合成模型、音频重建模型。
32.在音色辨别模型中,构建模型的目的是将特定人物的音色量化为向量表示,并且该量化算法必须与文本内容相独立,即同一说话人所讲述的内容不同的音频,需要被映射到几何距离接近的向量空间内,而不同说话人所讲述的即使是内容相同的文本驱动的音频之间,也必须有足够大的几何距离,能够将不同人的音色进行区别。为了达到这一量化目的,本专利中基于余弦距离与感知机的思想构建了音色量化模型。在余弦距离cd(cosine distance)的计算上,本专利分别对语义余弦距离scd(semantic cosine distance)与音色余弦距离tcd(timbre cosine distance)进行定义与计算,采用梯度下降法调整两个余弦距离对音色量化的影响权重。其中scd是对不同说话人在同一中文文本下音频数据的向量嵌入描述,tcd是对不同中文文本在同一说话人下音频数据的向量嵌入描述。
33.以下对scd与tcd进行定义:
[0034][0035][0036]
[0037][0038]
其中,
[0039]
v:向量化的语音数据集全集;
[0040]
m:数据集中说话人数量
[0041]
n:数据集中样例语句数量
[0042]
m∈[1,m];
[0043]
n∈[1,n];
[0044]vmn
:语音数据集中m说话人按照n样例讲述的音频向量;
[0045]
ωs:语义余弦距离权重;
[0046]
βs:语义余弦距离偏置;
[0047]
ω
t
:音色余弦距离权重;
[0048]
β
t
:音色余弦距离偏置;
[0049]
在频谱合成模型的部分,模型的目的是基于给定的中文文本,合成出文本对应音频信号的频域表示。基于这一目的,第一步要提取中文文本向量序列中的语义表示,本专利中采用词嵌入技术与双向记忆循环神经网络,对中文向量序列中的语义表征进行提取。第二步,获取音色辨别模型输出的特定人物音色向量表征,将音色表征与中文语义表征进行合并,获得音色与语义嵌入表征。第三步,基于音色与语义嵌入表征解码出对应的频谱表示向量,在本专利中对于频谱向量的解码采用基于位置编码的注意力机制与长短期记忆循环神经网络进行建模,其中的位置编码实现了对语序的建模,循环神经网络实现了语音中上下文依赖的建模。解码的结果即是中文文本对应的频谱表示向量。
[0050]
在音频重建模型的部分,模型的目的是基于频谱合成模型输出的频谱表示向量,解码出频谱的时域表示,即音频在时域的幅度谱。基于这一目的,在本专利中采用降采样卷积技术对频谱表征进行上下文采样,再将采样后的特征输入由门控循环神经网络构建的解码器单元,由解码器生成出音频信号的时域表示。
[0051]
步骤4、模型训练阶段
[0052]
如图2所示,在模型训练阶段中,一阶段采用说话人辨别的任务目标对音色辨别模型进行拟合。二阶段基于中文文本与对应的音频以及音色辨别模型的输出的音色向量,对频谱合成模型进行拟合,拟合特定人物音色所需的音频总时长在10分钟左右,即可达到音色迁移的功能,相比于其他方案,只需要较短时长的音频数据是本专利的独创点之一。在第三阶段中,基于真实中文音频以及音频对应的非线性频谱对音频重建模型进行拟合。
[0053]
步骤5、模型推理阶段
[0054]
如图3所示,将文本与音色向量输入频谱合成模型,计算得到非线性频谱输入音频重建模型,即可合成特定人物音色的语音片段。本发明中采用门控循环神经网络单元构建的模型结构,能够降低计算开销,能以极低的延迟合成音频,是本发明的独创点之一。
[0055]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1