语音数据的降噪方法、车机、存储介质和电子设备与流程
1.本发明涉及语音数据处理技术领域,特别是涉及一种语音数据的降噪方法、车机、存储介质和电子设备。
背景技术:
2.目前,随着车辆越来越智能化和语音识别技术的提高,语音识别vr逐步成为车辆中智能座舱的标配,人们在行车途中也越来越依赖语音识别。一般情况下,语音识别技术可以包括两个场景,一个是关键词唤醒,一个是语音识别。语音识别技术需要在嘈杂的声音环境中提取目标语音加以处理,其中,目标语音可来自麦克风(microphone,简称mic)音通路,嘈杂的声音环境可作为背景参考音。现有技术中,mic音走一路通路,背景参考音走另一路通路,由于两个通路的音频数据是通过两个不同的服务实现的采样,两个服务之间的启动时间以及系统任务的负载高低可能均不相同,可能导致mic音与参考音之间的时间差值产生差异。上述差异导致还原后的人声中夹杂着背景噪声,当还原后的人声用于语音识别的时候,会影响语音识别的准确率,导致用户体验不佳。
技术实现要素:
3.鉴于上述问题,提出了一种克服上述问题或者至少部分地解决上述问题的语音数据的降噪方法、车机、存储介质和电子设备。
4.本发明的一个目的是将噪声和人声在数字信号处理器中进行数据组包得到组包语音数据,以减少人声的时间差值与噪声的时间差值之间的差异。
5.本发明的一个进一步的目的是将组包语音数据通过一路传输通路发送至系统级芯片,从而进一步减少人声的时间差值与噪声的时间差值之间的差异。
6.根据本发明的一方面,本发明提供了一种语音数据的降噪方法,其中所述降噪方法应用于车机中,且所述车机包括数字信号处理器和系统级芯片,所述语音数据包括噪声和人声,所述降噪方法包括:
7.将所述语音数据中的噪声和人声在所述数字信号处理器中进行模数转换得到数字信号类型的噪声和人声;
8.将所述数字信号类型的噪声和人声在所述数字信号处理器中进行数据组包得到组包语音数据;
9.将所述组包语音数据发送至所述系统级芯片;
10.将所述系统级芯片接收的组包语音数据进行降噪,以除去其中的噪声。
11.可选地,将所述组包语音数据发送至所述系统级芯片,包括:
12.将所述组包语音数据通过一路传输通路发送至所述系统级芯片。
13.可选地,所述传输通路为时分复用通路。
14.可选地,所述系统级芯片包括异步重采样模块和回声消除降噪模块;
15.将所述系统级芯片接收的组包语音数据进行降噪,包括:
16.通过所述异步重采样模块将所述系统级芯片接收的组包语音数据的采样频率转换为所述回声消除降噪模块能够处理的采样频率;
17.通过所述回声消除降噪模块对采样频率转换后的组包语音数据进行降噪。
18.可选地,在将所述系统级芯片接收的组包语音数据进行降噪之后,包括:
19.将降噪之后的组包语音数据发送至指定应用程序,以供所述指定应用程序进行语音识别。
20.根据本发明的另一方面,本发明还提供了一种车机,包括数字信号处理器和系统级芯片,
21.所述数字信号处理器配置为将语音数据中的噪声和人声进行模数转换得到数字信号类型的噪声和人声,将所述数字信号类型的噪声和人声进行数据组包得到组包语音数据,将所述组包语音数据发送至所述系统级芯片;
22.所述系统级芯片配置为将接收的组包语音数据进行降噪,以除去其中的噪声。
23.可选地,所述数字信号处理器通过一路传输通路与所述系统级芯片连接;
24.所述数字信号处理器还配置为将所述组包语音数据通过一路传输通路发送至所述系统级芯片。
25.可选地,所述系统级芯片包括异步重采样模块和回声消除降噪模块;
26.所述异步重采样模块配置为将所述系统级芯片接收的组包语音数据的采样频率转换为所述回声消除降噪模块能够处理的采样频率;
27.所述回声消除降噪模块配置为对采样频率转换后的组包语音数据进行降噪。
28.根据本发明的再一方面,本发明还提供了一种机器可读存储介质,其上存储有机器可执行程序,所述机器可执行程序被处理器执行时实现根据上述任一项所述的语音数据的降噪方法。
29.根据本发明的又一方面,本发明还提供了一种电子设备,包括存储器和处理器,所述存储器内存储有控制程序,所述控制程序被所述处理器执行时用于实现根据上述中任一项所述的语音数据的降噪方法。
30.在本发明的语音数据的降噪方法中,将语音数据中的噪声和人声在数字信号处理器中进行模数转换得到数字信号类型的噪声和人声,将数字信号类型的噪声和人声在数字信号处理器中进行数据组包得到组包语音数据,将组包语音数据发送至系统级芯片,将系统级芯片接收的组包语音数据进行降噪,以除去其中的噪声,使人声采样信号和噪声采样信号的时间差值之间的时差明显减小或最小化,使降噪后的噪声大大减少,使还原出来的用于语音识别的人声中参杂的噪声大大减少,提高了语音识别的准确率。
31.进一步地,将组包语音数据通过一路传输通路发送至系统级芯片,相对于现有技术中通过两路传输通路分别将数字信号类型的噪声和人声发送至系统级芯片,减少了资源的占用,节约了资源成本。
32.根据下文结合附图对本发明具体实施例的详细描述,本领域技术人员将会更加明了本发明的上述以及其他目的、优点和特征。
附图说明
33.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通
技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
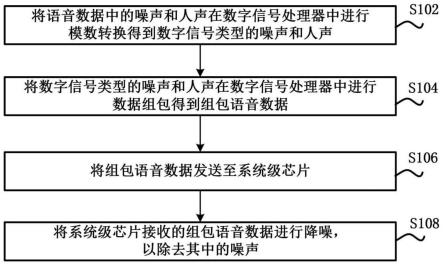
34.图1是根据本发明一个实施例的语音数据的降噪方法的流程图;
35.图2是根据本发明一个实施例的车机的结构示意图;
36.图3是根据本发明另一个实施例的车机对语音数据进行降噪的示意图;
37.图4是现有技术的车机对语音数据进行降噪的示意图。
具体实施方式
38.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
39.图1是根据本发明一个实施例的语音数据的降噪方法的流程图,其中降噪方法可以应用于车机中,车机是车载信息娱乐系统(in-vehicle infotainment,简称ivi)的简称,且车机可以包括数字信号处理器(digital signal process,简称dsp)和系统级芯片(system on chip,简称soc),语音数据可以包括噪声和人声,人声可以是通过麦克风(microphone,简称mic)采集的声音,即mic音,噪声可以是车里的背景音,也可以理解为参考音,语音数据可以是vr录音数据。降噪方法可包括以下步骤s102至步骤s108:
40.步骤s102:将语音数据中的噪声和人声在数字信号处理器中进行模数转换得到数字信号类型的噪声和人声。
41.步骤s104:将数字信号类型的噪声和人声在数字信号处理器中进行数据组包得到组包语音数据。
42.现有技术中,将语音数据中的噪声和人声在数字信号处理器中进行模数转换得到数字信号类型的噪声和人声后,是由系统级芯片将数字信号类型的噪声和人声进行数据组包得到组包语音数据,这种方式存在很多弊端。具体地,例如,数字信号处理器需要通过两路传输通路分别将数字信号类型的噪声和人声发送至系统级芯片,物理资源上占用了较多的传输通路资源,并且,在系统级芯片上需要两个服务程序,一个对噪声采样,一个对人声采样,这就造成两个服务程序采样的时间差值(噪声采样的时间差值可以理解为从系统级芯片到直接采集到还原点的时间差值;人声采样的时间差值可以理解为从麦克风采集人声到系统级芯片,再从系统级芯片到还原点的时间差值)因各自服务程序的启动时间及系统任务负载高低的不同产生差异,导致人声与噪声之间的时间差值不同,使还原出来的用于语音识别的人声中参杂很多噪声,影响了语音识别的准确率。而在本步骤中,考虑到上述两者的时间差值之间的时差越小,人声与噪声之间同时发生的时间点就越对齐,还原出来的识别音就越接近原始人声,因此将数字信号类型的噪声和人声在数字信号处理器中进行数据组包得到组包语音数据,不再需要两个服务程序,避免了上述两个服务程序带来时差的情况,使人声采样与噪声采样的时间差值之间的时差仅为不同的模数转换时产生的时域信号偏差,使两种采样信号的时间差值之间的时差明显减小或最小化,保证还原出来的用于语音识别的人声中参杂的噪声大大减少,提高了语音识别的准确率。
43.步骤s106:将组包语音数据发送至系统级芯片。
44.步骤s108:将系统级芯片接收的组包语音数据进行降噪,以除去其中的噪声。
45.在本实施例中,将语音数据中的噪声和人声在数字信号处理器中进行模数转换得到数字信号类型的噪声和人声,将数字信号类型的噪声和人声在数字信号处理器中进行数据组包得到组包语音数据,将组包语音数据发送至系统级芯片,将系统级芯片接收的组包语音数据进行降噪,以除去其中的噪声,使人声采样信号和噪声采样信号的时间差值之间的时差明显减小或最小化,使降噪后的噪声大大减少,使还原出来的用于语音识别的人声中参杂的噪声大大减少,提高了语音识别的准确率。
46.在本发明一个实施例中,将组包语音数据发送至系统级芯片,可包括:
47.将组包语音数据通过一路传输通路发送至系统级芯片。
48.在本实施例中,将组包语音数据通过一路传输通路发送至系统级芯片,相对于现有技术中通过两路传输通路分别将数字信号类型的噪声和人声发送至系统级芯片,减少了资源的占用,节约了资源成本。
49.在本发明一个实施例中,传输通路可以为时分复用通路(time division multiplexing,简称tdm)。
50.在本实施例中,传输通路为时分复用通路,不仅成本低廉,抗干扰能力强,而且信道利用率也比较高。
51.在本发明一个实施例中,系统级芯片可包括异步重采样模块(asynchronous sample rate converter,简称asrc)和回声消除降噪模块(echo cancellation&noise reduction,简称ecnr)。将系统级芯片接收的组包语音数据进行降噪,可包括:
52.通过异步重采样模块将系统级芯片接收的组包语音数据的采样频率转换为回声消除降噪模块能够处理的采样频率;
53.通过回声消除降噪模块对采样频率转换后的组包语音数据进行降噪。
54.在本实施例中,考虑到时分复用通路输出的数据的采样频率可能与回声消除降噪模块要求的数据的采样频率不同,一般情况下,时分复用通路输出的数据的采样频率为48k,回声消除降噪模块要求的数据的采样频率为8-48k,因此,通过异步重采样模块将系统级芯片接收的组包语音数据的采样频率转换为回声消除降噪模块能够处理的采样频率,然后通过回声消除降噪模块对采样频率转换后的组包语音数据进行降噪,这种方式非常简单,容易实现,并且成本较低。
55.在本发明一个实施例中,在将系统级芯片接收的组包语音数据进行降噪之后,包括:
56.将降噪之后的组包语音数据发送至指定应用程序,以供指定应用程序进行语音识别。
57.在本实施例中,将降噪之后的组包语音数据发送至指定应用程序,以供指定应用程序进行语音识别,保证识别出来的声音更加准确。
58.参见图2,图2是根据本发明一个实施例的车机的结构示意图。基于同一构思,本发明还提供了一种车机200。车机200可包括数字信号处理器201和系统级芯片202。数字信号处理器201配置为将语音数据中的噪声和人声进行模数转换得到数字信号类型的噪声和人声,将数字信号类型的噪声和人声进行数据组包得到组包语音数据,将组包语音数据发送至系统级芯片202。系统级芯片202配置为将接收的组包语音数据进行降噪,以除去其中的
噪声。
59.在本实施例中,现有技术中,数字信号处理器201将语音数据中的噪声和人声进行模数转换得到数字信号类型的噪声和人声后,然后就发送至系统级芯片202,系统级芯片202将数字信号类型的噪声和人声进行数据组包得到组包语音数据。现有技术的处理方式存在很多弊端,具体地,例如,数字信号处理器201需要通过两路传输通路分别将数字信号类型的噪声和人声发送至系统级芯片202,物理资源上占用了较多的传输通路资源,并且,系统级芯片202需要两个服务程序,一个对噪声采样,一个对人声采样,这就造成两个服务程序采样的时间差值(噪声采样的时间差值可以理解为从系统级芯片202到直接采集到还原点的时间差值;人声采样的时间差值可以理解为从麦克风采集人声到系统级芯片202,再从系统级芯片202到还原点的时间差值)因各自服务程序的启动时间及系统任务负载高低的不同产生差异,使人声与噪声之间的时间差值不同,容易导致还原出来的用于语音识别的人声参杂大量的噪声,影响了语音识别的准确率。而在本发明中,考虑到两者的时间差值之间的时差越小,人声与噪声之间同时发生的时间点就越对齐,还原出来的识别音就越接近原始人声,因此数字信号处理器201将数字信号类型的噪声和人声进行数据组包得到组包语音数据,便不再需要两个服务程序,避免了上述两个服务程序带来时差的情况,使人声采样与噪声采样的时间差值之间的时差仅为不同的模数转换时产生的时域信号偏差,使两种采样信号的时间差值之间的时差明显减小或最小化,使还原出来的用于语音识别的人声中参杂的噪声大大减少,提高了语音识别的准确率。
60.在本实施例中,本发明的数字信号处理器201将数字信号类型的噪声和人声进行数据组包得到组包语音数据,具体可以参见图3,通过麦克风采集的人声(mic音)可以包括micfl(麦克风前左)、micfr(麦克风前右)、micrl(麦克风后左)和micrr(麦克风后右),噪声可包括reffl(噪声前左)、reffr(噪声前右)、refrl(噪声后左)和refrr(噪声后右),其中,ref指reference,即参考音,也即噪声,fl即frontleft,fr即frontright,rl即rearleft,rr即rearright。组包语音数据可以通过一个时分复用通路输出至异步重采样模块203。一般情况下,一个时分复用通路可以复用出8个slot,也就是slot0-7,其中,slot0可以对应micfl,slot1可以对应micfr,slot2可以对应micrl,slot3可以对应micrr,slot4可以对应reffl,slot5可以对应reffr,slot6可以对应refrl,slot7可以对应refrr。时分复用通路输出至异步重采样模块203的数据的采样频率一般可以为48k。回声消除降噪模块204一般要求数据的采样频率在8-48k之间。异步重采样模块203需要将数据的频率由48k转化为8-48k之间。vr表示将降噪后的语音推送给指定的应用管理程序(application,简称app)使用,进行语音识别。
61.现有技术可以参见图4,数字信号处理器201通过两路传输通路分别将噪声和人声发送至系统级芯片202进行组包,人声可以包括micfl、micfr、micrl和micrr,噪声可包括reffl、reffr、refrl和refrr,异步重采样模块203将组包语音数据的采样频率转化为回声消除降噪模块204需要的频率,回声消除降噪模块204对频率转化后的组包语音数据进行降噪,然后通过vr推送给指定的应用管理程序使用,进行语音识别。通过图3和图4对比可以发现,本发明改变了语音数据的组包位置,从系统级芯片202内组包转移至数字信号处理器201内组包,保证人声和噪声之间的延时最小且固定,提升了语音的唤醒率及识别率。
62.在本发明一个实施例中,数字信号处理器201可通过一路传输通路与系统级芯片
202连接;
63.数字信号处理器201还配置为将组包语音数据通过一路传输通路发送至系统级芯片202。
64.在本实施例中,数字信号处理器201将组包语音数据通过一路传输通路发送至系统级芯片202,相对于现有技术中通过两路传输通路分别将数字信号类型的噪声和人声发送至系统级芯片202,减少了资源的占用,节约了资源成本。本实施例的传输通路可以为时分复用通路。传输通路为时分复用通路,不仅成本低廉,抗干扰能力强,而且信道利用率也比较高。
65.在本发明一个实施例中,系统级芯片202可包括异步重采样模块203和回声消除降噪模块204;
66.异步重采样模块203配置为将系统级芯片202接收的组包语音数据的采样频率转换为回声消除降噪模块204能够处理的采样频率;
67.回声消除降噪模块204配置为对采样频率转换后的组包语音数据进行降噪。
68.在本实施例中,考虑到时分复用通路输出的数据的采样频率可能与回声消除降噪模块204要求的数据的采样频率不同,因此,异步重采样模块203将系统级芯片202接收的组包语音数据的采样频率转换为回声消除降噪模块204能够处理的采样频率,然后回声消除降噪模块204对采样频率转换后的组包语音数据进行降噪,这种方式非常简单,容易实现,并且成本较低。
69.基于同一构思,本发明还提供了一种机器可读存储介质。机器可读存储介质上存储有机器可执行程序,机器可执行程序被处理器执行时实现根据上述实施例任一项的语音数据的降噪方法。
70.基于同一构思,本发明还提供了一种电子设备。电子设备可包括存储器和处理器,存储器内存储有控制程序,控制程序被处理器执行时用于实现根据上述实施例中任一项的语音数据的降噪方法。电子设备可以为车机、手机、平板电脑或者可穿戴设备等任何具有语音识别功能的电子设备。
71.上述各个实施例可以任意组合,根据上述任意一个优选实施例或多个优选实施例的组合,本发明实施例能够达到如下有益效果:
72.在本发明的语音数据的降噪方法中,将语音数据中的噪声和人声在数字信号处理器中进行模数转换得到数字信号类型的噪声和人声,将数字信号类型的噪声和人声在数字信号处理器中进行数据组包得到组包语音数据,将组包语音数据发送至系统级芯片,将系统级芯片接收的组包语音数据进行降噪,以除去其中的噪声,使人声采样信号和噪声采样信号的时间差值之间的时差明显减小或最小化,使降噪后的噪声大大减少,使还原出来的用于语音识别的人声中参杂的噪声大大减少,提高了语音识别的准确率。
73.至此,本领域技术人员应认识到,虽然本文已详尽示出和描述了本发明的多个示例性实施例,但是,在不脱离本发明精神和范围的情况下,仍可根据本发明公开的内容直接确定或推导出符合本发明原理的许多其他变型或修改。因此,本发明的范围应被理解和认定为覆盖了所有这些其他变型或修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1