语音处理方法、电子设备和计算机存储介质与流程
本技术涉及人机交互,尤其涉及一种语音处理方法、电子设备和计算机存储介质。
背景技术:
1、车辆的语音助手具有多音区的特性,即可以在逻辑上将车舱空间按照座位划分为多个区域(可称为音区)。对于每个音区,车辆可以接收该音区的音频信号,并判断该音频信号是否包括预设的唤醒词(例如“小a小a”),当判断结果为是时,语音助手可以被唤醒,例如播放音频“我在”来提示用户,然后,用户再说出语音指令,唤醒的语音助手可以响应该语音指令。也就是说,唤醒车辆的语音助手需要特定的唤醒词,交互过程复杂,功能不够智能。
技术实现思路
1、本技术公开了一种语音处理方法、电子设备和计算机存储介质,能够为多个音区中的每个音区的用户提供全时免唤醒功能,简化交互过程,产品功能更加智能丰富。
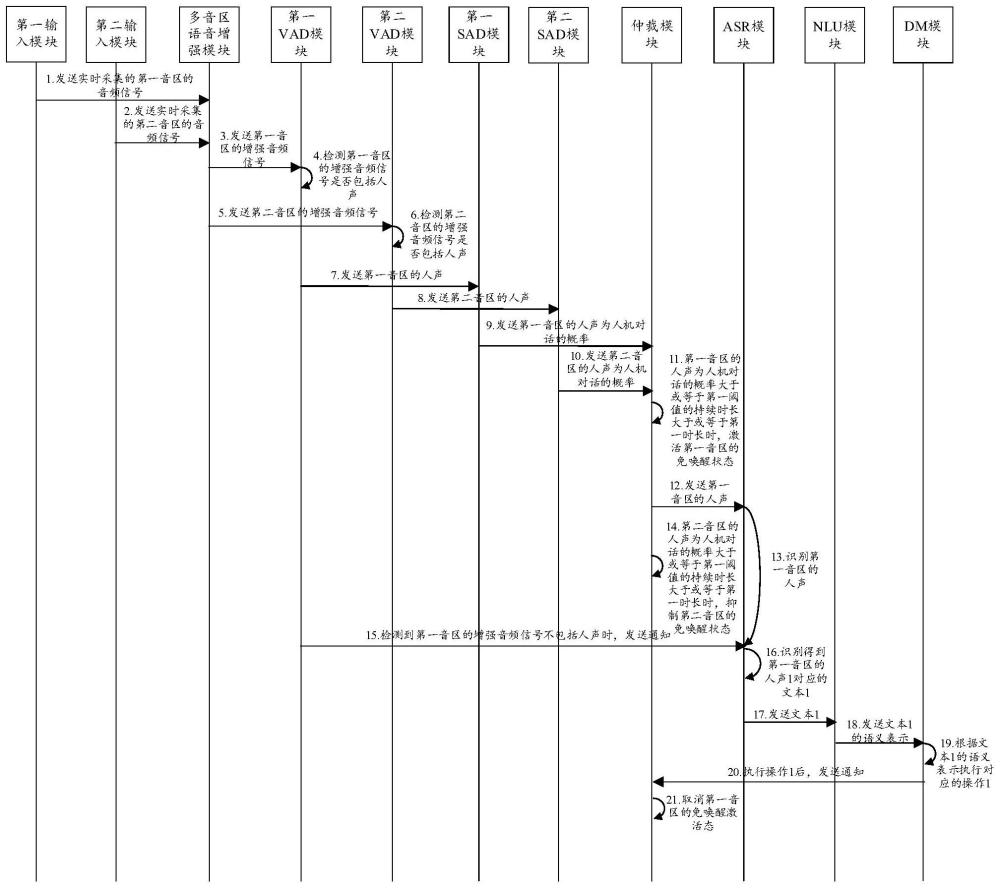
2、第一方面,本技术提供了一种语音处理方法,应用于电子设备,所述电子设备对应的空间包括m个音区,m大于或等于2,所述m个音区包括第一音区,该方法包括:采集所述m个音区中每个音区的音频信号;获取所述m个音区中每个音区的音频信号为人机对话的概率;当检测到所述第一音区满足预设条件时,识别所述第一音区的音频信号,执行所述第一音区的音频信号对应的第一操作;所述预设条件包括自检测到第一概率大于或等于第一阈值的时刻起始的预设时长内,所述第一概率始终大于或等于所述第一阈值,所述第一概率为所述第一音区的音频信号为人机对话的概率。
3、在上述方法中,电子设备可以实时采集每个音区的音频信号和判断每个音区的音频信号是否为人机对话,并识别和响应最早确定为人机对话的第一音区的音频信号,第一音区为m个音区中的任意一个音区(即第一音区不局限为特定音区),同时,即使第一音区的音频信号不包括特定的唤醒词电子设备也会正常响应,因此为m个音区中的每个音区提供了一致的全时免唤醒功能,简化交互过程,其中,电子设备识别和响应的是最早确定为人机对话的一个音区(第一音区)的音频信号,而不是对m个音区的音频信号都进行识别和响应,降低对电子设备的算力的要求,功能可用性高。
4、在一种可能的实现方式中,所述m个音区包括第二音区,所述预设条件还包括:第一时刻早于第二时刻,所述第一时刻为检测到所述第一概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻,所述第二时刻为检测到第二概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻,所述第二概率为所述第二音区的音频信号为人机对话的概率。
5、在一种可能的实现方式中,所述检测到所述第一音区满足预设条件时,所述第二概率小于所述第一阈值,或者,自检测到所述第二概率大于或等于所述第一阈值的时刻起始的持续时长小于所述预设时长。
6、在一种可能的实现方式中,m等于3,所述预设条件还包括:所述第一时刻早于第三时刻,所述第三时刻为检测到第三概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻,所述第三概率为所述第三音区的音频信号为人机对话的概率。
7、在一些示例中,所述当检测到所述第一音区满足预设条件时,识别所述第一音区的音频信号,包括:在第四时刻检测到所述第一概率大于或等于所述第一阈值;判断当前时刻和所述第四时刻的差值是否大于或等于所述预设时长;在当前时刻和所述第四时刻的差值大于或等于所述预设时长时,识别所述第一音区的音频信号。
8、在一种可能的实现方式中,所述预设条件包括:所述第一时刻早于第五时刻,所述第五时刻为检测到第四概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻,所述第四概率为第四音区的音频信号为人机对话的概率,所述第四音区为所述m个音区中除所述第一音区外的任意一个音区。
9、在一种可能的实现方式中,所述获取所述m个音区中每个音区的音频信号为人机对话的概率,包括:检测到所述第一音区的音频信号包括人声;获取所述第一音区的音频信号为人机对话的概率。
10、在一种可能的实现方式中,所述获取所述m个音区中每个音区的音频信号为人机对话的概率,包括:未采集到第五音区的音频信号或者检测到所述第五音区的音频信号不包括人声时,确定所述第五音区的音频信号为人机对话的概率为零,所述第五音区为所述m个音区中除所述第一音区外的一个音区。
11、在上述方法中,电子设备可以先检测采集到的音区的音频信号是否包括人声,当确定包括人声时,再计算该音频信号为人机对话的概率,当确定不包括人声时,可以直接确定该音频信号为人机对话的概率为0,无需再进行计算,减少不必要的计算资源,进一步降低对电子设备的算力的要求。
12、在一种可能的实现方式中,所述识别所述第一音区的音频信号,包括:获取所述第一音区的音频信号对应的第一文本;获取所述第一文本的语义表示;所述执行所述第一音区的音频信号对应的第一操作,包括:根据所述第一文本的语义表示执行所述第一操作。
13、在一些示例中,所述获取所述第一音区的音频信号对应的第一文本为通过自动语音识别asr实现的。在一些示例中,所述获取所述第一文本的语义表示为通过自然语言理解nlu实现的。
14、在一些示例中,所述获取所述第一文本的语义表示,包括:识别所述第一文本是否为人机对话的文本;当所述第一文本为人机对话的文本时,获取所述第一文本的语义表示。例如,所述识别所述第一文本是否为人机对话的文本为通过文本受话人检测tad实现的。
15、在上述方法中,电子设备获取到第一音区的音频信号对应的第一文本后,可以先判断第一文本是否为人机对话的文本,即在文本层面再进行一次人机对话的检测,若第一文本为人机对话的文本,电子设备再获取第一文本的语义表示,若第一文本不为人机对话的文本,电子设备可以不获取第一文本的语义表示,不仅进一步避免了误唤醒的情况,而且减少了不必要的计算资源。
16、在一种可能的实现方式中,所述方法还包括:在所述检测到所述第一音区满足预设条件之前,显示第一界面,所述第一界面包括所述m个音区的指示灯,所述m个音区的指示灯均为熄灭状态;在所述检测到所述第一音区满足预设条件时,显示第二界面,所述第二界面包括所述第一音区的指示灯,所述第一音区的指示灯为点亮状态。
17、在一些示例中,在所述第二界面中,所述第一音区的指示灯的显示方式和所述m个音区中除所述第一音区以外的其他音区的指示灯的显示方式不同。
18、在上述方法中,音频信号被最早确定为人机对话的第一音区(可称为处于免唤醒激活态)的指示灯和其他音区的指示灯的显示方式不同,让用户可以感知到第一音区的免唤醒激活态,以及在何时发出了什么语音造成第一音区处于免唤醒激活态,提升用户体验。
19、在一种可能的实现方式中,所述方法还包括:在所述检测到所述第一音区满足预设条件之前,显示第三界面,所述第三界面包括所述m个音区的指示灯,所述m个音区的指示灯均为熄灭状态;在所述检测到所述第一音区的音频信号包括人声时,显示第四界面,所述第四界面包括所述第一音区的指示灯,所述第一音区的指示灯为点亮状态;显示第五界面,所述第五界面包括所述第一音区的指示灯,显示所述第四界面时的所述第一概率小于显示第五界面时的所述第一概率,所述第四界面中的所述第一音区的指示灯的亮度小于所述第五界面中的所述第一音区的指示灯的亮度。
20、在上述方法中,当检测到音频信号包括人声时电子设备就可以点亮当前音区的指示灯,并且通过指示灯的亮度来表征当前音区的音频信号为人机对话的概率,概率越大,亮度越亮,让用户可以感知到实时检测的过程,提升用户体验。
21、在一种可能的实现方式中,所述方法还包括:在所述执行所述第一音区的音频信号对应的第一操作时,显示第六界面,所述第六界面包括所述第一音区的指示灯,所述第一音区的指示灯为闪烁状态。
22、在一些示例中,在所述第六界面中,所述m个音区中除所述第一音区以外的其他音区的指示灯不为闪烁状态。
23、在上述方法中,电子设备可以通过第一音区的指示灯的特定状态来表征当前正在响应第一音区的音频信号,让用户可以感知到音频信号的响应过程,提升用户体验。
24、在一种可能的实现方式中,所述方法还包括:在所述检测到所述第一音区满足预设条件之后,检测到所述第二音区满足:自检测到第二概率大于或等于所述第一阈值的时刻起始的所述预设时长内,所述第二概率始终大于或等于所述第一阈值,所述第二概率为所述第二音区的音频信号为人机对话的概率;所述电子设备不执行所述第二音区的音频信号对应的操作。
25、在一些示例中,所述执行所述第一音区的音频信号对应的第一操作之后,所述方法还包括:采集所述第二音区的音频信号;获取所述第二音区的音频信号为人机对话的概率;在第六时刻检测到所述第二音区的音频信号为人机对话的概率大于或等于所述第一阈值;确定当前时刻和所述第六时刻的差值大于或等于所述预设时长;识别所述第二音区的音频信号;执行所述第二音区的音频信号对应的第二操作。
26、在一些示例中,所述执行所述第一音区的音频信号对应的第一操作之后采集的所述第二音区的音频信号包括的用户语音,和,所述采集所述m个音区中每个音区的音频信号得到的所述第二音区的音频信号包括的用户语音相同。
27、在上述方法中,在执行所述第一音区的音频信号对应的第一操作之前(可以称为是此次免唤醒的人机交互过程结束之前),电子设备只会识别和响应音频信号被最早确定为人机对话的第一音区,即使后续存在音频信号被确定为人机对话的其他音区(例如第二音区),电子设备也不会识别和响应,可以理解为是每次免唤醒的人机交互过程电子设备只响应一个音区的音频信号,进一步降低对电子设备的算力的要求,功能可用性高。
28、在一种可能的实现方式中,所述方法还包括:在所述检测到所述第一音区满足预设条件之前,显示第七界面,所述第七界面包括所述m个音区的指示灯,所述m个音区的指示灯均为熄灭状态;在第二时刻,显示第八界面,所述第八界面包括所述第一音区的指示灯和所述第二音区的指示灯,所述第一音区的指示灯为第一颜色的点亮状态,所述第二音区的指示灯为第二颜色的点亮状态,所述第二时刻为检测到所述第二概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻。
29、在一些示例中,在所述检测到所述第一音区满足预设条件时,所述电子设备显示的所述第一音区的指示灯为所述第一颜色的点亮状态。
30、在一些示例中,在所述第八界面中,所述第一音区的指示灯、所述第二音区的指示灯和所述m个音区中除所述第一音区和所述第二音区以外的其他音区的指示灯的显示方式不同。
31、在上述方法中,电子设备可以通过指示灯展示各个音区的状态,让各个音区的用户都能感知到当前音区的状态,以及在何时发出了什么语音造成当前音区处于该状态,提升用户体验。
32、在一种可能的实现方式中,所述方法还包括:在所述执行所述第一音区的音频信号对应的第一操作之后,显示第九界面,所述第九界面包括所述第一音区的指示灯,所述第一音区的指示灯为熄灭状态。
33、在一些示例中,在所述第九界面中,所述m个音区中除所述第一音区外的其他音区的指示灯也为熄灭状态。在一些示例中,在所述执行所述第一音区的音频信号对应的第一操作之后,电子设备确定此次免唤醒的人机交互过程完成,以进行下一次免唤醒的人机交互过程。
34、在上述方法中,电子设备可以在响应第一音区的音频信号之后,可以熄灭第一音区的指示灯,让第一音区的用户感知到此次发出的语音指令已被执行完毕,方便用户发出下一次的语音指令,提升用户体验。
35、第二方面,本技术提供了一种电子设备,所述电子设备对应的空间(示例地,所在的空间)包括m个音区,m大于或等于2,所述m个音区包括第一音区和第二音区,所述电子设备包括m个输入模块、m个概率模块和处理模块,其中:所述m个输入模块,分别用于采集所述m个音区的音频信号;所述m个概率模块,分别用于获取所述m个音区的音频信号为人机对话的概率;所述处理模块,用于当检测到所述第一音区满足预设条件时,识别所述第一音区的音频信号,执行所述第一音区的音频信号对应的第一操作;所述预设条件包括自检测到第一概率大于或等于第一阈值的时刻起始的预设时长内,所述第一概率始终大于或等于所述第一阈值,所述第一概率为所述第一音区的音频信号为人机对话的概率。
36、在一些示例中,所述m个输入模块中任意一个输入模块包括至少一个麦克风。
37、在一些示例中,所述m个概率模块中任意一个概率模块包括一个声音活动检测vad模块和一个语音受话人检测sad模块。
38、在上述方法中,电子设备可以实时采集每个音区的音频信号和判断每个音区的音频信号是否为人机对话,并识别和响应最早确定为人机对话的第一音区的音频信号,第一音区为m个音区中的任意一个音区(即第一音区不局限为特定音区),同时,即使第一音区的音频信号不包括特定的唤醒词电子设备也会正常响应,因此为m个音区中的每个音区提供了一致的全时免唤醒功能,简化交互过程,其中,电子设备识别和响应的是最早确定为人机对话的一个音区(第一音区)的音频信号,而不是对m个音区的音频信号都进行识别和响应,降低对电子设备的算力的要求,功能可用性高。
39、在一种可能的实现方式中,所述预设条件还包括:第一时刻早于第二时刻,所述第一时刻为检测到所述第一概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻,所述第二时刻为检测到第二概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻,所述第二概率为所述第二音区的音频信号为人机对话的概率。
40、在一种可能的实现方式中,所述检测到所述第一音区满足预设条件时,所述第二概率小于所述第一阈值,或者,自检测到所述第二概率大于或等于所述第一阈值的时刻起始的持续时长小于所述预设时长。
41、在一种可能的实现方式中,m等于3,所述预设条件还包括:所述第一时刻早于第三时刻,所述第三时刻为检测到第三概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻,所述第三概率为所述第三音区的音频信号为人机对话的概率。
42、在一些示例中,所述当检测到所述第一音区满足预设条件时,识别所述第一音区的音频信号,包括:在第四时刻检测到所述第一概率大于或等于所述第一阈值;判断当前时刻和所述第四时刻的差值是否大于或等于所述预设时长;在当前时刻和所述第四时刻的差值大于或等于所述预设时长时,识别所述第一音区的音频信号。
43、在一种可能的实现方式中,所述预设条件包括:所述第一时刻早于第五时刻,所述第五时刻为检测到第四概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻,所述第四概率为第四音区的音频信号为人机对话的概率,所述第四音区为所述m个音区中除所述第一音区外的任意一个音区。
44、在一种可能的实现方式中,所述获取所述m个音区中每个音区的音频信号为人机对话的概率,包括:第一vad模块检测到所述第一音区的音频信号包括人声;第一sad模块获取所述第一音区的音频信号为人机对话的概率,所述第一vad模块和所述第一sad模块属于所述m个概率模块中和所述第一音区对应的概率模块。
45、在一种可能的实现方式中,所述获取所述m个音区中每个音区的音频信号为人机对话的概率,包括:未采集到第五音区的音频信号或者检测到所述第五音区的音频信号不包括人声时,确定所述第五音区的音频信号为人机对话的概率为零,所述第五音区为所述m个音区中除所述第一音区外的一个音区。
46、在上述方法中,电子设备可以先检测采集到的音区的音频信号是否包括人声,当确定包括人声时,再计算该音频信号为人机对话的概率,当确定不包括人声时,可以直接确定该音频信号为人机对话的概率为0,无需再进行计算,减少不必要的计算资源,进一步降低对电子设备的算力的要求。
47、在一种可能的实现方式中,所述处理模块包括自动语音识别asr模块和自然语言理解nlu模块,所述识别所述第一音区的音频信号,包括:所述asr模块获取所述第一音区的音频信号对应的第一文本;所述nlu模块获取所述第一文本的语义表示;所述执行所述第一音区的音频信号对应的第一操作,包括:根据所述第一文本的语义表示执行所述第一操作。
48、在一些示例中,所述处理模块还包括文本受话人检测tad模块,所述tad模块用于识别所述m个音区中任意一个音区的音频信号对应的文本是否为人机对话的文本,所述nlu模块用于在所述tad模块识别到所述第一文本为人机对话的文本时获取所述第一文本的语义表示。
49、在上述方法中,电子设备获取到第一音区的音频信号对应的第一文本后,可以先判断第一文本是否为人机对话的文本,即在文本层面再进行一次人机对话的检测,若第一文本为人机对话的文本,电子设备再获取第一文本的语义表示,若第一文本不为人机对话的文本,电子设备可以不获取第一文本的语义表示,不仅进一步避免了误唤醒的情况,而且减少了不必要的计算资源。
50、在一种可能的实现方式中,所述电子设备还包括显示模块,所述显示模块,用于:在所述检测到所述第一音区满足预设条件之前,显示第一界面,所述第一界面包括所述m个音区的指示灯,所述m个音区的指示灯均为熄灭状态;在所述检测到所述第一音区满足预设条件时,显示第二界面,所述第二界面包括所述第一音区的指示灯,所述第一音区的指示灯为点亮状态。
51、在一些示例中,在所述第二界面中,所述第一音区的指示灯的显示方式和所述m个音区中除所述第一音区以外的其他音区的指示灯的显示方式不同。
52、在上述方法中,音频信号被最早确定为人机对话的第一音区(可称为处于免唤醒激活态)的指示灯和其他音区的指示灯的显示方式不同,让用户可以感知到第一音区的免唤醒激活态,以及在何时发出了什么语音造成第一音区处于免唤醒激活态,提升用户体验。
53、在一种可能的实现方式中,所述电子设备还包括显示模块,所述显示模块,用于:在所述检测到所述第一音区满足预设条件之前,显示第三界面,所述第三界面包括所述m个音区的指示灯,所述m个音区的指示灯均为熄灭状态;在所述检测到所述第一音区的音频信号包括人声时,显示第四界面,所述第四界面包括所述第一音区的指示灯,所述第一音区的指示灯为点亮状态;显示第五界面,所述第五界面包括所述第一音区的指示灯,显示所述第四界面时的所述第一概率小于显示第五界面时的所述第一概率,所述第四界面中的所述第一音区的指示灯的亮度小于所述第五界面中的所述第一音区的指示灯的亮度。
54、在上述方法中,当检测到音频信号包括人声时电子设备就可以点亮当前音区的指示灯,并且通过指示灯的亮度来表征当前音区的音频信号为人机对话的概率,概率越大,亮度越亮,让用户可以感知到实时检测的过程,提升用户体验。
55、在一种可能的实现方式中,所述电子设备还包括显示模块,所述显示模块,用于:在所述执行所述第一音区的音频信号对应的第一操作时,显示第六界面,所述第六界面包括所述第一音区的指示灯,所述第一音区的指示灯为闪烁状态。
56、在一些示例中,在所述第六界面中,所述m个音区中除所述第一音区以外的其他音区的指示灯不为闪烁状态。
57、在上述方法中,电子设备可以通过第一音区的指示灯的特定状态来表征当前正在响应第一音区的音频信号,让用户可以感知到音频信号的响应过程,提升用户体验。
58、在一种可能的实现方式中,所述处理模块,还用于:在所述检测到所述第一音区满足预设条件之后,检测到所述第二音区满足:自检测到第二概率大于或等于所述第一阈值的时刻起始的所述预设时长内,所述第二概率始终大于或等于所述第一阈值,所述第二概率为所述第二音区的音频信号为人机对话的概率;所述电子设备不执行所述第二音区的音频信号对应的操作。
59、在一些示例中,所述执行所述第一音区的音频信号对应的第一操作之后,所述m个输入模块中和所述第二音区对应的输入模块,还用于采集所述第二音区的音频信号;所述m个概率模块中和所述第二音区对应的概率模块,还用于获取所述第二音区的音频信号为人机对话的概率;所述处理模块,还用于:在第六时刻检测到所述第二音区的音频信号为人机对话的概率大于或等于所述第一阈值;确定当前时刻和所述第六时刻的差值大于或等于所述预设时长;识别所述第二音区的音频信号;执行所述第二音区的音频信号对应的第二操作。
60、在一些示例中,所述执行所述第一音区的音频信号对应的第一操作之后采集的所述第二音区的音频信号包括的用户语音,和,所述采集所述m个音区中每个音区的音频信号得到的所述第二音区的音频信号包括的用户语音相同。
61、在上述方法中,在执行所述第一音区的音频信号对应的第一操作之前(可以称为是此次免唤醒的人机交互过程结束之前),电子设备只会识别和响应音频信号被最早确定为人机对话的第一音区,即使后续存在音频信号被确定为人机对话的其他音区(例如第二音区),电子设备也不会识别和响应,可以理解为是每次免唤醒的人机交互过程电子设备只响应一个音区的音频信号,进一步降低对电子设备的算力的要求,功能可用性高。
62、在一种可能的实现方式中,所述电子设备还包括显示模块,所述显示模块,用于:在所述检测到所述第一音区满足预设条件之前,显示第七界面,所述第七界面包括所述m个音区的指示灯,所述m个音区的指示灯均为熄灭状态;在第二时刻,显示第八界面,所述第八界面包括所述第一音区的指示灯和所述第二音区的指示灯,所述第一音区的指示灯为第一颜色的点亮状态,所述第二音区的指示灯为第二颜色的点亮状态,所述第二时刻为检测到所述第二概率大于或等于所述第一阈值的时刻起始的所述预设时长后的时刻。
63、在一些示例中,在所述检测到所述第一音区满足预设条件时,所述显示模块显示的所述第一音区的指示灯为所述第一颜色的点亮状态。
64、在一些示例中,在所述第八界面中,所述第一音区的指示灯、所述第二音区的指示灯和所述m个音区中除所述第一音区和所述第二音区以外的其他音区的指示灯的显示方式不同。
65、在上述方法中,电子设备可以通过指示灯展示各个音区的状态,让各个音区的用户都能感知到当前音区的状态,以及在何时发出了什么语音造成当前音区处于该状态,提升用户体验。
66、在一种可能的实现方式中,所述电子设备还包括显示模块,所述显示模块,用于:在所述执行所述第一音区的音频信号对应的第一操作之后,显示第九界面,所述第九界面包括所述第一音区的指示灯,所述第一音区的指示灯为熄灭状态。
67、在一些示例中,在所述第九界面中,所述m个音区中除所述第一音区外的其他音区的指示灯也为熄灭状态。在一些示例中,在所述执行所述第一音区的音频信号对应的第一操作之后,电子设备确定此次免唤醒的人机交互过程完成,以进行下一次免唤醒的人机交互过程。
68、在上述方法中,电子设备可以在响应第一音区的音频信号之后,可以熄灭第一音区的指示灯,让第一音区的用户感知到此次发出的语音指令已被执行完毕,方便用户发出下一次的语音指令,提升用户体验。
69、第三方面,本技术提供了又一种电子设备,包括收发器、处理器和存储器,上述存储器用于存储计算机程序,上述处理器调用上述计算机程序,用于执行上述任一方面任一项可能的实现方式中的语音处理方法。
70、第四方面,本技术提供了一种计算机存储介质,该计算机存储介质存储有计算机程序,该计算机程序被处理器执行时,实现上述任一方面任一项可能的实现方式中的语音处理方法。
71、第五方面,本技术提供了一种计算机程序产品,当该计算机程序产品在电子设备上运行时,使得该电子设备执行上述任一方面任一项可能的实现方式中的语音处理方法。
72、第六方面,本技术提供一种电子设备,该电子设备包括执行本技术任一实现方式所介绍的方法或装置。上述电子设备例如为芯片。
73、应当理解的是,本技术中对技术特征、技术方案、有益效果或类似语言的描述并不是暗示在任意的单个实现方式中可以实现所有的特点和优点。相反,可以理解的是对于特征或有益效果的描述意味着在至少一个实现方式中包括特定的技术特征、技术方案或有益效果。因此,本说明书中对于技术特征、技术方案或有益效果的描述并不一定是指相同的实现方式。进而,还可以任何适当的方式组合本技术中所描述的技术特征、技术方案和有益效果。本领域技术人员将会理解,无需特定实现方式的一个或多个特定的技术特征、技术方案或有益效果即可实现本技术。在其他实现方式中,还可在没有体现本技术的特定实现方式中识别出额外的技术特征和有益效果。
- 还没有人留言评论。精彩留言会获得点赞!