一种轻量级语音关键词识别方法、设备、介质
1.本发明涉及语音识别技术领域,尤其是涉及一种轻量级语音关键词识别方法、设备、介质。
背景技术:
2.随着语音处理技术的进步和边缘计算的普及,语音识别、交互的应用场景更加广泛,而智能手表等边缘智能设备在实时语音交互应用时面临隐私保护、实时通信、功耗等约束,出现了对参数量及运算量均较小的轻量级、本地化语音关键词识别机制的需要。传统语音关键词识别方法包括:隐马尔可夫模型(hidden marko model,hmm)和高斯混合模型(gaussian mixture models,gmms)等方法,此类方法需要较高的计算能力,难以高效应用到嵌入式设备等系统中。近年来,神经网络模型方法在语音关键词识别中使用不断普及,包括:基于深度神经网络(deep neuralnetwork,dnn)的方法,但dnn模型的参数量普遍较大,同时难以有效提取语音的时序间相关性信息;基于卷积神经网络(convolutional neural network,cnn) 的方法,在更小的参数量上能够取得了较好的识别效果,但cnn方法在识别效率上仍有较大提升空间;基于残差网络(residual network,resnet)的方法,使用空洞卷积来扩大网络的感受野,但基于resnet的方法往往需要数十万及以上的参数量,网络模型较重;基于时间卷积神经网络(temporal convolutional network, tcn)的方法,在时序数据的特征提取等领域取得了较好的效果。基于此,现有方法面临:若要获得较高的识别准确率,一般方法涉及的神经网络模型往往参数量较大,动辄超过100kb的参数量,而ram/flash空间有限的嵌入式系统难以有效承载和运行;同时复杂模型结构带来较高的运算复杂度也带来了运算延时等问题。
3.综上,当前的关键词识别方法存在神经网络参数量大、模型复杂度高的问题。
技术实现要素:
4.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种轻量级语音关键词识别方法、设备、介质,通过特定的神经网络结构设计,取得了以较小的模型总参数量和较低的模型复杂度为代价实现较高准确率的识别效果,从而更适合在内存较小、算力较低的mcu等嵌入式系统进行部署。
5.本发明的目的可以通过以下技术方案来实现:
6.本发明的一个方面,提供了一种轻量级语音关键词识别方法,包括如下步骤:
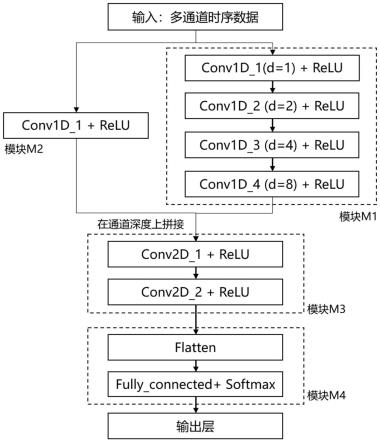
7.获取待识别语音,将所述待识别语音转换为与预设格式匹配的特征帧向量,输入预训练好的关键词识别模型,获取与目标关键词匹配的分类标签的概率数组,根据所述概率数组确定所述待识别语音内是否包含所述目标关键词,
8.其中,所述关键词识别模型包括:
9.时间卷积模块,包括多个按照预设的空洞系数组合的卷积层,用于根据所述特征帧向量,提取时序间相关性信息,获取第一输出数据;
10.嵌套模块,用于根据所述特征帧向量,获取第二输出数据;
11.压缩模块,包括多个按照预设的步长组合的卷积层,用于对所述第一输出数据以及所述第二输出数据拼接后的数据进行压缩与特征提取,获取第三输出数据;
12.全连接分类输出模块,用于根据所述第三输出数据,获取所述概率数组。
13.作为优选的技术方案,所述的时间卷积模块包括按照所述空洞系数进行组合并顺次连接的多组conv1d和/或conv2d层以及对应的激活函数层。
14.作为优选的技术方案,所述的压缩模块包括按照所述步长进行组合并顺次连接多组conv1d和/或conv2d层以及对应的激活函数层,用于实现所述第一输出数据和所述第二输出数据在通道维度上拼接并对拼接后的数据进行特征提取和压缩处理。
15.作为优选的技术方案,所述的全连接分类输出模块包括顺次连接的拉直层以及对应的分类层。
16.作为优选的技术方案,所述的时间卷积模块包括四组conv1d层以及对应的 relu激活函数层,并按照预设的空洞系数进行组合并顺次连接;所述的嵌套模块包括一层conv1d层以及对应的relu激活函数层;所述的压缩模块包括两组 conv2d层以及对应的relu激活函数层,并按照预设步长进行组合并顺次连接;所述的全连接分类输出模块包括顺次连接的flatten拉直层与softmax分类层。
17.作为优选的技术方案,所述的空洞系数为[1,2,4,8],所述的步长为[2,2]。
[0018]
作为优选的技术方案,所述的特征帧向量的获取过程包括如下步骤:
[0019]
采用梅尔滤波器组获取所述待识别语音的梅尔频率倒谱系数,根据所述梅尔频率倒谱系数,获取具有多通道时序数据格式的所述特征帧向量。
[0020]
作为优选的技术方案,所述的预训练好的关键词识别模型的数据输入过程具体为:
[0021]
判断所述特征帧向量是否小于或等于预设长度,若是,所述特征帧向量的首帧作为起点帧,且所述特征帧向量不足所述预设长度的部分用0填充,若否,从所述特征帧向量的首帧开始,按照预设的帧步长在时序方向平移,循环确定所述起点帧;
[0022]
从所述起点帧开始,读取预设长度的特征帧向量作为所述关键词识别模型的输入数据。
[0023]
本发明的另一个方面,提供了一种电子设备,包括:一个或多个处理器以及存储器,所述存储器内储存有一个或多个程序,所述一个或多个程序包括用于执行上述轻量级语音关键词识别方法的指令。
[0024]
本发明的另一个方面,提供了计算机可读存储介质,包括供电子设备的一个或多个处理器执行的一个或多个程序,所述一个或多个程序包括用于执行上述轻量级语音关键词识别方法的指令。
[0025]
与现有技术相比,本发明具有以下优点:
[0026]
(1)通过在关键词识别模型中引入模块时间卷积模块,与经典cnn卷积神经网络相比,能够有效提取语音数据的时序间的相关性信息特征,在特定参数量约束下实现了较高识别准确率的效果,提高了模型对时序间相关性信息的提取能力。
[0027]
(2)通过引入嵌套模块,对时间卷积模块及嵌套模块的输出数据在通道深度上进行拼接,实现增加后续模块对原始输入数据的特性提取能力。
[0028]
(3)通过在关键词识别模型引入压缩模块,在增加模型非线性性同时,大幅减小模型的输出数据量,从而大幅压缩全连接分类输出模块及压缩模块的参数量,使得在获得较高识别准确率的同时,实现神经网络模型的总参数量大幅降低,实现模型运行时占用内存更小。
附图说明
[0029]
图1为实施例1及实施例2中神经网络模型的结构图;
[0030]
图2为实施例1的实施例步骤流程图;
[0031]
图3为实施例1中的实施例算法流程图;
[0032]
图4为实施例2中的神经网络模型在通用数据集上的训练与测试效果示意图。
具体实施方式
[0033]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
[0034]
实施例1
[0035]
本实施例提供了一种轻量级语音关键词识别方法。如图1所述为本实施例使用的神经网络模型的结构图。如图2所述为本实施例识别方法的流程示意图。如图3 所述为本实施例算法流程示意图。
[0036]
本实施例的关键词识别方法包括如下步骤:
[0037]
步骤s1,待识别语音的mfcc特征提取,通过特定操作提取特定长度(t_1 ≥1s)语音的mfcc特征数据,在实施例中相关设置:采样率为16k;帧长为480,对应时长为0.03s;步长为320,对应时长为0.02s;对待识别语音进行mfcc特征提取相关操作,可得到输出大小为(t_1/0.02s向上取整)列*40行的二维时-频特征数据,其中1s时长对应为50*40的二维时-频特征数据。
[0038]
步骤s1具体包含操作:
[0039]
s11,分帧,对语音数据按0.03s时长为一段,以0.02s时长为步长进行分割,以分割的每一段为一帧数据;
[0040]
s12,加窗,对每一帧数据进行窗函数处理;
[0041]
s13,fft变换,将加窗后的一帧数据进行傅立叶变换(fft);
[0042]
s14,mel滤波,根据人类的听觉感知系统特点,对于fft变换得到的幅度谱,分别与每一个滤波器进行频率相乘累加,得到的值即为该帧数据在该滤波器对应频段的能量值;
[0043]
s15,dct变换,应用离散余弦变换(dct)对滤波器组系数执行相关处理。
[0044]
步骤s2,在神经网络模型运算部分,将步骤s1中提取的mfcc特征数据,从本次循环的数据起点列开始读取50列数据,其中第一次执行循环时数据起点为第1列,对应读取50*40的二维特征数据,输入至已训练的神经网络模型,经模型运算后,输出一个概率数组。
[0045]
在可以完成10个语音关键词识别的模型中,输出的概率数组为长度为11的1 维数组,对应11个分类标签,其前10个数值为可识别目标关键词对应标签对应的概率值,最后一
个数值为未识别/unknown标签对应的概率值。
[0046]
在神经网络模型的训练部分,在python环境下对训练用语音数据集进行mfcc 特征提取,其中采样率、帧长、步长等设置均与步骤s1中设置完全一致。然后使用tfrecord工具将提取的mfcc特征数据创建成tensorflow v2.x机器学习框架可读的数据集格式。使用tensorflow v2.x中的keras框架来实现图1-2所示的神经网络模型中的m1、m2、m3及m4模块与整个模型的搭建。在模型构建完成后,将已创建的数据集读入模型,调整训练相关超参数,完成模型训练,保存模型。
[0047]
步骤s3:对步骤s1提取的mfcc特征数据,以特定的循环频率0.1s时长,对应步长为5帧/列,第n次循环对应的数据起点为第(n-1)*5+1列,连续读取50列,对应50*40的二维特征数据,输入至已训练的神经网络模型进行运算,每执行完一次步骤s2,n加1。
[0048]
步骤s4:根据执行单次循环时模型输出的概率数组中最大概率值p及对应分类标签y,作为单次循环的识别结果;根据n次循环的输出结果的最大概率值pn= max{pi}对应的分类标签yn,以确定待识别语音数据中存在目标关键词;若n次循环输出结果最大概率值对应分类标签均为unknown,则语音数据中不存在目标关键词;若n次循环输出的最大概率值对应分类标签并非均为unknown,则概率值最大的非unknown标签对应的关键词为已识别的目标关键词。
[0049]
实施例2
[0050]
本实施例通过结合具体语音数据集对实施例1提供的轻量级语音关键词识别方法的效果进行说明:
[0051]
(1)语音数据集
[0052]
data_speech_commands_v0.02(google brain,2018)是由google公司提供的第二版英文语音数据集,该数据集包含35个词汇的合计105829条wav格式的语音,每条语音数据为单通道pcm值,时间长度均为1秒且只包含一个英语词汇。根据目前语音关键词识别研究中常用模型准确率计量思路,选取“yes、no、up、 down、left、right、on、off、stop及go”等10个词汇语音作为待识别目标关键词,其余语音数据标为“unknown”,用于对应在前述10个词汇之外的待识别语音,合计11个标签。在本实施例中,将数据集按照8:1:1的比例进行分配,分为训练集(training set)、验证集(validation set)和测试集(test set)三个数据集。
[0053]
(2)实施过程
[0054]
在神经网络模型训练部分,采用librosa(python)库工具对前述三个数据集的语音数据进行mfcc特征提取,本实施例中相关设置:采样率为16k;帧长为480,对应时长为0.03s;步长为320,对应时长为0.02s;每一条语音数据可得到50*40 的带通道深度为40的一维(50组)特征数据。使用tfrecord工具将上述mfcc 特征数据创建成tensorflow v2.x机器学习框架可读的数据集,最终包括:训练数据集(training dataset)、验证数据集(validation dataset)和测试数据集(test dataset) 三个数据集。
[0055]
在训练过程中采用分多步连续训练思路,具体分六步,其中各步训练epoch为 [130,70,70,70,70,130],对应的drop rate为[0.31,0.21,0.16,0.12,0.1,0.1];在第六步,使用reducelronplateau工具自动降低模型训练中的学习步长。同时,在训练中采用adam优化策略;训练监测(monitor)目标设置为验证集损失(validation loss),损失函数由keras框架提供;模型的识别效果采用识别准确率(accuracy)进行统计,准确率采用归一
化处理。
[0056]
(3)实施效果
[0057]
为了评估本发明中模型及方法的效果,本实施例利用上述数据集进行实验与效果分析。图4所示,为本发明中的模型及方法在训练过程中在训练集与验证集上的损失与准确率过程记录,表1所示,为已训练完毕的模型在上述三个数据集以及数据集整体的推断准确率情况,其中在测试集的识别准确率为97.84%。
[0058]
表1:本发明中神经网络模型在数据集上的测试效果
[0059][0060]
根据相关文献综述(l
ó
pez-espejo i,tan z h,hansen j,et al.deep spokenkeyword spotting:an overview[j].ieee access,2021.),本实施例与当前主要语音关键词识别网络方法进行比较,如表2所示,本发明中的模型及方法在较小参数量与运算复杂度下,获得较高识别准确率,其他更高识别准确率的模型的参数量往往在数百kb以上,难以在内存及算力有限的嵌入式系统上实现有效部署。
[0061]
表2:本发明中神经网络模型与现有研究比较
[0062][0063]
由本实施例中上述图、表可见,在通用语音数据集上,本发明中的模型及方法能够在较小的参数量与运算复杂度约束下获得较高的识别准确率,从而能够更好的匹配内存较小、算力较低的嵌入式系统。
[0064]
实施例3
[0065]
本实施例提供了一种电子设备,包括:一个或多个处理器以及存储器,所述存储器内储存有一个或多个程序,所述一个或多个程序包括用于执行如实施例1所述轻量级语音关键词识别方法的指令。
[0066]
实施例4
[0067]
本实施例提供了计算机可读存储介质,包括供电子设备的一个或多个处理器执行的一个或多个程序,所述一个或多个程序包括用于执行如实施例1所述轻量级语音关键词
识别方法的指令。
[0068]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1