语音实时翻译方法、系统、设备以及存储介质与流程
本发明涉及在线翻译,具体地说,涉及一种语音实时翻译方法、系统、设备以及存储介质。
背景技术:
1、随着国际性交流的增加,使用不同语种的语言沟通越来越频繁。交流过程中,因语言不同需要依赖交流双方的语言技能或要依靠人工口语翻译才能实现交流,给交流双方带来了不便。因此,通过使用翻译设备或穿戴设备配合耳机,并借助机器人语音,来实现实时在线翻译将成为最便捷的方式。
2、通话时,机器人语音翻译,负责将说话方的内容翻译为聆听方语种的语音进行播放。但翻译内容可能与说话方本意存在一定的误差,且说话内容和实时翻译语音会存在一定的时间差,而说话方不懂翻译语音内容,所以说话方无法及时获悉刚才说的某些内容被聆听方具体获悉的时间点和正确性,即是否正确的已经被听到,导致说话方无法确定自己说的话的传达时效性和正确性,需要说话方有意识地停顿,等待语音翻译全部完成后猜测聆听方是否已经听到以及理解正确。因此无法保证交流双方的沟通效率和正确性。
技术实现思路
1、针对现有技术中的问题,本发明的目的在于提供一种语音实时翻译方法、系统、设备以及存储介质,提高了跨语言翻译的准确率以及跨语言交流双方的沟通效率。
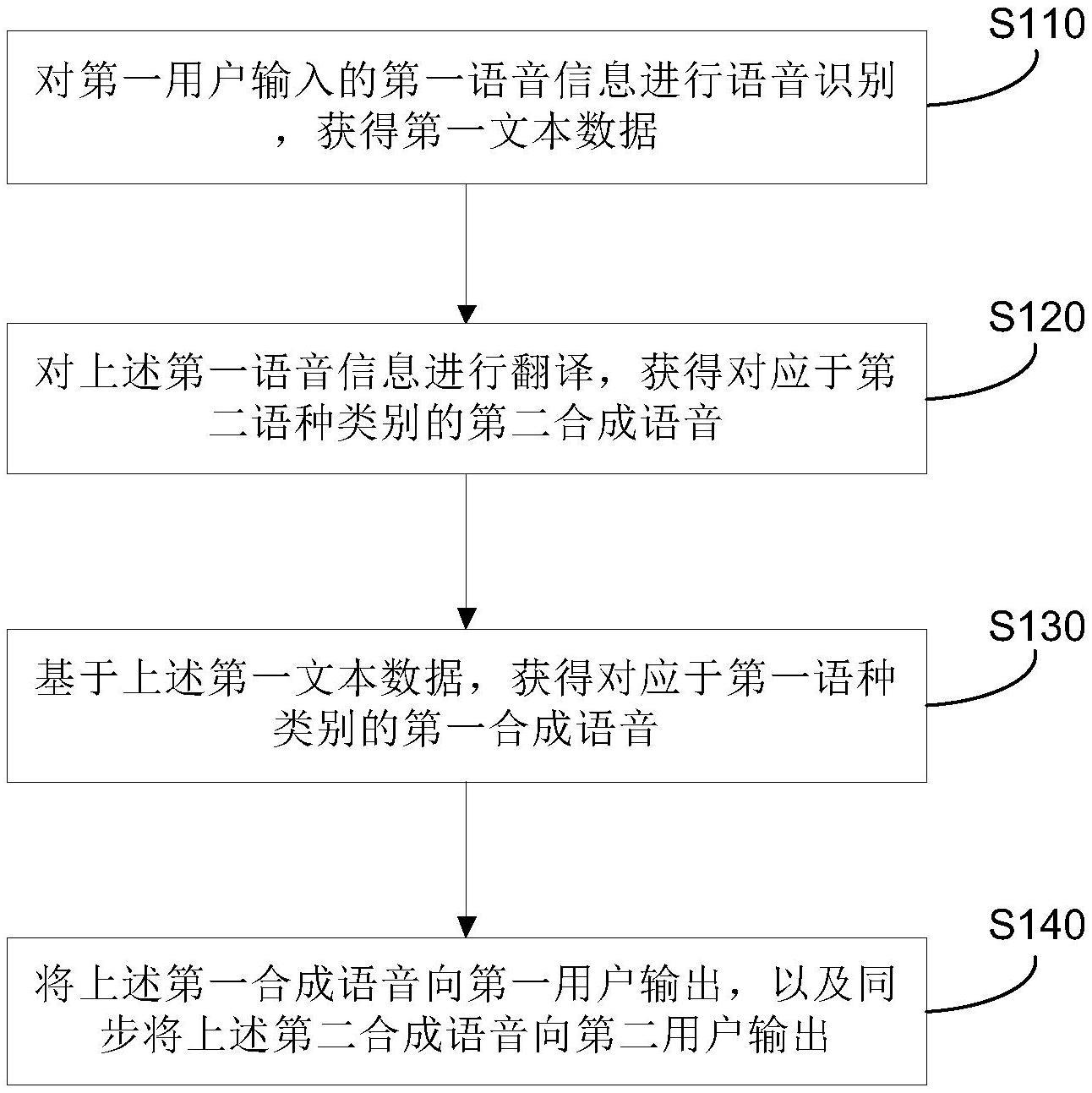
2、为实现上述目的,本发明提供了一种语音实时翻译方法,所述方法包括以下步骤:
3、对第一用户输入的第一语音信息进行语音识别,获得第一文本数据;
4、对所述第一语音信息进行翻译,获得对应于第二语种类别的第二合成语音;
5、基于所述第一文本数据,获得对应于第一语种类别的第一合成语音;
6、将所述第一合成语音向第一用户输出,以及同步将所述第二合成语音向第二用户输出。
7、可选地,所述对所述第一语音信息进行翻译,获得对应于第二语种类别的第二合成语音,包括:
8、对基于第一语音信息语音识别得到的第一文本数据进行翻译,获得对应于第二语种类别的第二文本数据;
9、基于所述第二文本数据,获得对应于第二语种类别的第二合成语音。
10、可选地,所述基于所述第一文本数据,获得对应于第一语种类别的第一合成语音,包括:
11、计算所述第二合成语音完成播放的预计耗时,得到第一预估时长;
12、基于所述第一预估时长,获得关于所述第二合成语音的第二时间戳信息;
13、基于所述第一文本数据进行语音合成,获得第一合成语音;并将所述第一合成语音对应的第一时间戳与所述第二时间戳信息进行同步。
14、可选地,所述方法还包括:
15、当接收到所述第一用户对所述第一合成语音的正反馈信息后,继续采集第一用户输入的下一段第一语音消息;
16、当接收到所述第一用户对所述第一合成语音的负反馈信息后,采集第一用户重新输入的所述第一语音信息,以及向第二用户输出关于所述第一用户重新输入的提示信息。
17、可选地,所述方法还包括:
18、分别基于所述第一文本数据和所述第二文本数据,提取各自的兴趣标签和对应的时间戳信息;
19、依据所述时间戳信息,将对应的兴趣标签分别标注于所述第一文本数据和所述第二文本数据。
20、可选地,在所述将所述第一合成语音向第一用户输出,以及同步将所述第二合成语音向第二用户输出之前,所述方法包括:
21、分别采集第一用户和第二用户的声纹信息;
22、基于所述声纹信息,分别识别得到第一用户和第二用户的身份信息;
23、基于所述第一用户和第二用户的身份信息,确定第一用户和第二用户之间的关系类型;
24、基于第一用户和第二用户之间的关系类型,以及预设身份关系兴趣库,对所述兴趣标签进行筛选,将保留的兴趣标签作为目标兴趣标签;
25、所述将所述第一合成语音向第一用户输出,以及同步将所述第二合成语音向第二用户输出,包括:
26、对所述第一合成语音以及所述第二合成语音中与所述目标兴趣标签关联的语音进行语音提示。
27、可选地,所述对第一用户输入的第一语音信息进行语音识别,获得第一文本数据,包括:
28、获取关于所述第一语音信息的前文数据;
29、对第一用户输入的第一语音信息进行语音识别,获得初始文本数据;
30、利用所述前文数据对所述初始文本数据进行修正,得到第一文本数据。
31、可选地,在所述将所述第一合成语音向第一用户输出,以及同步将所述第二合成语音向第二用户输出之前,所述方法包括:
32、当检测到用于输出语音的一对耳机分别由不同用户佩戴时,控制所述耳机工作于第一状态;当检测到第一用户和第二用户各佩戴一对耳机时,控制所述耳机工作于第二状态;
33、其中,在第一状态下,两个耳机分别输出不同的语音,被一用户佩戴的一耳机作为该用户的语音输出通道;在第二状态下,一对耳机中的两个输出相同的语音,被一用户佩戴的一对耳机作为该用户的语音输出通道。
34、可选地,所述一对耳机设有uwb通信模块;在所述将所述第一合成语音向第一用户输出,以及同步将所述第二合成语音向第二用户输出之前,所述方法包括:
35、所述一对耳机基于uwb通信模块,实时侦测两个耳机之间的距离;
36、当两个耳机之间的距离大于第一预设阈值时,控制所述耳机工作于第一状态;当两个耳机之间的距离小于第一预设阈值时,控制所述耳机工作于第二状态。
37、可选地,所述方法还包括:
38、根据第一合成语音中未播放的音频帧,以及已采集生成第一语音信息且未转换为第一合成语音的音频帧,组合形成音频调节库;
39、基于所述音频调节库中的音频帧数量,调节第一合成语音的播放语速;
40、其中,所述第一合成语音对应的播放语速随着所述音频调节库中的音频帧数量的增大而增大,且随着所述音频调节库中的音频帧数量的减小而减小。
41、本发明还提供了一种语音实时翻译系统,用于实现上述语音实时翻译方法,所述系统包括:
42、第一文本数据生成模块,对第一用户输入的第一语音信息进行语音识别,获得第一文本数据;
43、第二合成语音生成模块,对所述第一语音信息进行翻译,获得对应于第二语种类别的第二合成语音;
44、第一合成语音生成模块,基于所述第一文本数据,获得对应于第一语种类别的第一合成语音;
45、合成语音播放模块,将所述第一合成语音向第一用户输出,以及同步将所述第二合成语音向第二用户输出。
46、本发明还提供了一种语音实时翻译设备,包括:
47、处理器;
48、存储器,其中存储有所述处理器的可执行程序;
49、其中,所述处理器配置为经由执行所述可执行程序来执行上述任意一项语音实时翻译方法的步骤。
50、本发明还提供了一种计算机可读存储介质,用于存储程序,所述程序被处理器执行时实现上述任意一项语音实时翻译方法的步骤。
51、本发明与现有技术相比,具有以下优点及突出性效果:
52、本发明提供的语音实时翻译方法、系统、设备以及存储介质对说话方的说话内容,基于语音识别得到的第一文本数据,合成第一合成语音,在向聆听方播放第二合成语音的同时,向说话方同步播放第一合成语音,使得识别语音过程中出现错误导致翻译内容时产生的误差,能够及时被说话方知晓,提高了跨语言翻译的准确率以及跨语言交流双方的沟通效率;使得在跨语言交流中沟通更加顺畅。
- 还没有人留言评论。精彩留言会获得点赞!