一种基于自适应注意力机制的语音合成方法和系统与流程
本发明涉及语音合成,具体涉及一种基于自适应注意力机制的语音合成方法和系统。
背景技术:
1、在现有的语音合成方法中,生成的语音质量受到了训练数据的限制,采用少量数据很难生成高相似度、高自然度的语音,并且模型存在过拟合风险;因此在训练语音合成系统时,往往会应用到大量的语音数据;目前,多人的语音合成模型已经可以很好的拟合多个说话人的音色,并且可以通过控制文本输入来合成自己想要的输出结果,然而适应性语音合成仍然是一个非常具有挑战性的任务,如何用更少的数据,生成更加逼真和相似的语音是研究的重点。
2、现有的适应性语音合成方法有两个主要方向:
3、第一:例如unet-tts通过优化模型结构更好的捕获说话人音色,并且在真正合成时只提取说话人音色而不去优化模型参数(zero-shot),但其存在合成的说话人的语音质量和语音相似度并不好的缺陷;
4、第二:例如adaspeech模型通过少量的未知说话人语音样本,对模型进行微小调整,从而生成更高质量和相似度的未知说话人语音(few-shot or one-shot),合成的语音质量和说话人相似度更高,但其在微调时,并未考虑不同说话人的音高和能量不同,存在合成的语音效果不高的缺陷。
技术实现思路
1、针对上述问题,本发明的一个目的是提供一种基于自适应注意力机制的语音合成方法,该方法采用少量未知说话人的语音数据,通过微小变化语音合成模型的参数来合成未知说话人声音,具体包括以说话人高维特征作为条件去控制语音合成模型的注意力机制和诸如音高、时长等的预测模块的权重,从而达到更加快速的适应说话人音色,显著提高生成的说话人语音的效果。
2、本发明的第二个目的是提供一种基于自适应注意力机制的语音合成系统。
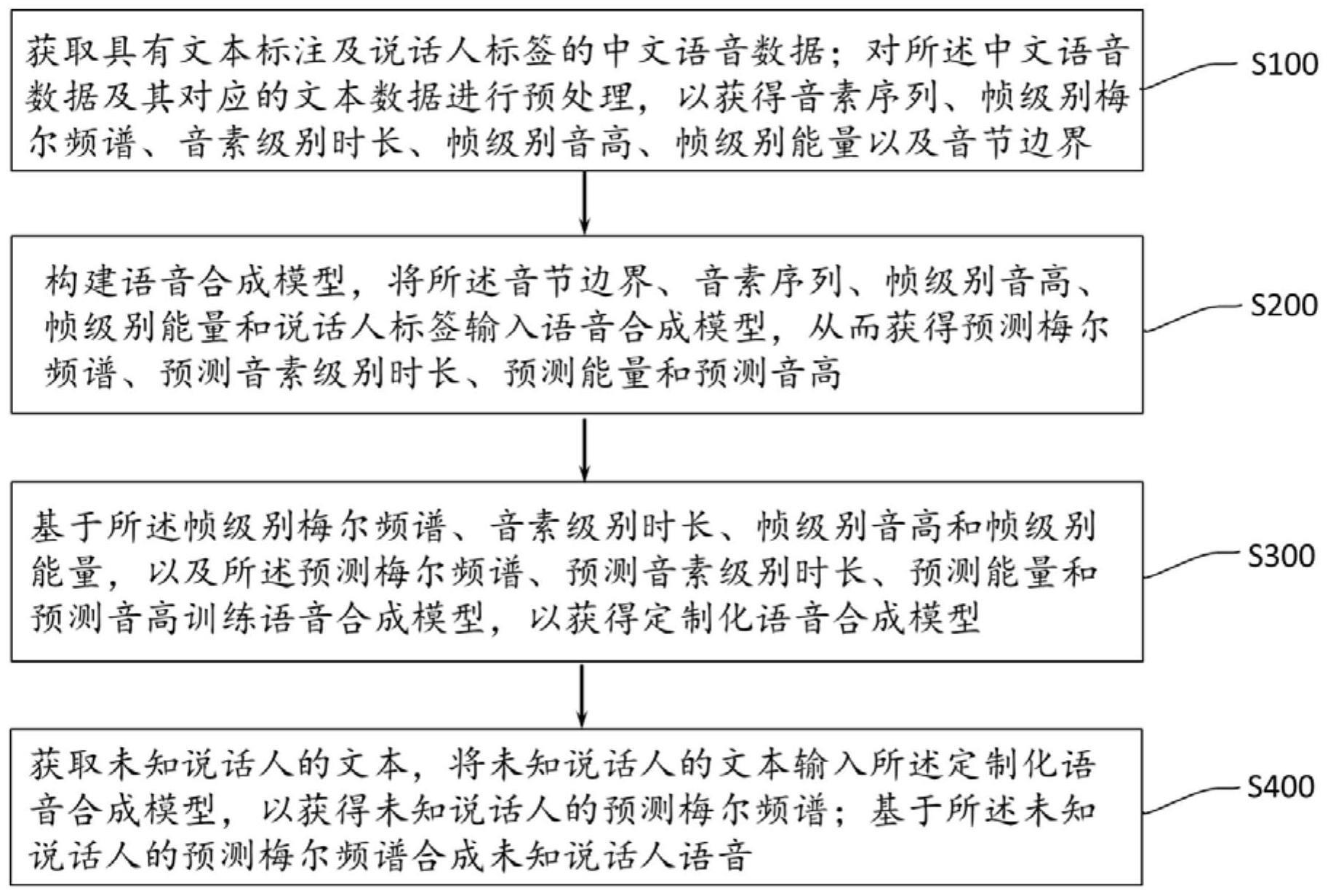
3、本发明所采用的第一个技术方案是:一种基于自适应注意力机制的语音合成方法,包括以下步骤:
4、s100:获取具有文本标注及说话人标签的中文语音数据;对所述中文语音数据及其对应的文本数据进行预处理,以获得音素序列、帧级别梅尔频谱、音素级别时长、帧级别音高、帧级别能量以及音节边界;
5、s200:构建语音合成模型,将所述音节边界、音素序列、帧级别音高、帧级别能量和说话人标签输入语音合成模型,从而获得预测梅尔频谱、预测音素级别时长、预测能量和预测音高;
6、s300:基于所述帧级别梅尔频谱、音素级别时长、帧级别音高和帧级别能量,以及所述预测梅尔频谱、预测音素级别时长、预测能量和预测音高训练语音合成模型,以获得定制化语音合成模型;
7、s400:获取未知说话人的文本,将未知说话人的文本输入所述定制化语音合成模型,以获得未知说话人的预测梅尔频谱;基于所述未知说话人的预测梅尔频谱合成未知说话人语音。
8、优选地,所述步骤s100中的预处理包括以下子步骤:
9、s110:将所述文本数据转换为音素序列;
10、s120:将所述音素序列和对应的中文语音数据送入对齐模型,从而获得音素级别时长;
11、s130:通过预设字典生成每个文本数据对应的各个音节边界;
12、s140:对所述中文语音数据进行音高的预测,获得帧级别音高;
13、s150:将中文语音数据的语音波形通过短时傅立叶变换以及梅尔频谱转换,以生成帧级别梅尔频谱以及帧级别能量。
14、优选地,所述步骤s200中的语音合成模型包括说话人特征表、音素特征表、自适应编码器、自适应预测器组和自适应解码器;
15、所述自适应编码器包括音素编码器、音节编码器、时长预测器、长度规整器、音节生成器以及自适应交叉注意力模块;
16、所述自适应预测器组包括自适应音高预测器和自适应能量预测器。
17、优选地,所述步骤s200中通过以下子步骤获得预测梅尔频谱、预测音素级别时长、预测能量和预测音高:
18、s210:基于所述音素序列查询音素特征表,从而生成初始音素特征;以及基于说话人标签查询说话人特征表,从而生成说话人特征;
19、s220:将所述初始音素特征、说话人特征和音节边界输入自适应编码器,从而获得预测音素级别时长和帧级别第二隐藏特征;
20、s230:将所述帧级别第二隐藏特征、说话人特征以及帧级别音高和帧级别能量输入自适应预测器组,从而生成预测能量、预测音高以及帧级别第三隐藏特征;
21、s240:将所述帧级别第三隐藏特征和说话人特征输入自适应解码器,从而得到预测梅尔频谱。
22、优选地,所述步骤s220包括:
23、1)将所述初始音素特征输入音素编码器,以生成音素级第一隐藏特征;
24、2)将所述音素级第一隐藏特征和音节边界输入音节生成器,以生成音节初步特征;
25、3)将所述音节初步特征输入音节编码器进行编码,从而获得音节级第一隐藏特征;
26、4)将所述音素级第一隐藏特征和音节边界输入时长预测器,从而得到预测音素级别时长,并对所述预测音素级别时长求和,从而输出音节级别时长;
27、5)基于所述音节级别时长将所述音节级第一隐藏特征通过长度规整器扩充为帧级别第一隐藏特征;
28、6)将所述帧级别第一隐藏特征和音节级第一隐藏特征作为参数、说话人特征作为条件输入自适应交叉注意力模块,从而获得帧级别第二隐藏特征。
29、优选地,所述步骤s230包括:
30、将所述帧级别第二隐藏特征和说话人特征均分别输入自适应能量预测器和自适应音高预测器,从而输出预测能量和预测音高;
31、将所述帧级别音高和帧级别能量加入所述帧级别第二隐藏特征中,从而生成帧级别第三隐藏特征。
32、优选地,所述步骤s300包括以下子步骤:
33、s310:将所述预测梅尔频谱、预测音素级别时长、预测能量和音高以及帧级别梅尔频谱、音素级别时长、帧级别音高、帧级别能量,通过损失函数计算损失,对所述语音合成模型进行预训练直至收敛;
34、s320:对预训练好的语音合成模型进行微调训练,以获得定制化语音合成模型。
35、优选地,所述步骤s310中的损失函数通过以下公式表示:
36、lossadaptor=λp*lossp+λe*losse+λd*lossd
37、loss=lossadaptor+lossmel
38、式中,loss为总损失;lossmel为梅尔频谱损失;lossadaptor为自适应预测器组的损失;λp、λe、λd分别为自适应音高预测器、自适应能量预测器、时长预测器的权重,权重值都为1;lossp为音高损失;losse为能量损失;lossd为时长损失。
39、优选地,使用均方误差对所述预测梅尔频谱和帧级别梅尔频谱进行计算,以获得梅尔频谱损失;
40、使用均方误差对所述预测音素级别时长和音素级别时长进行计算,以获得时长损失;
41、采用平均绝对值误差对所述预测能量和帧级别能量进行计算,以获得能量损失;
42、采用平均绝对值误差对所述预测音高和帧级别音高进行计算,以获得音高损失。
43、本发明所采用的第二个技术方案是:一种基于自适应注意力机制的语音合成系统,包括预处理模块、模型构建模块、训练模块和语音合成模块;
44、所述预处理模块用于获取具有文本标注及说话人标签的中文语音数据;对所述中文语音数据及其对应的文本数据进行预处理,以获得音素序列、帧级别梅尔频谱、音素级别时长、帧级别音高、帧级别能量以及音节边界;
45、所述模型构建模块用于构建语音合成模型,将所述音节边界、音素序列、帧级别音高、帧级别能量和说话人标签输入语音合成模型,从而获得预测梅尔频谱、预测音素级别时长、预测能量和预测音高;
46、所述训练模块用于基于所述帧级别梅尔频谱、音素级别时长、帧级别音高和帧级别能量,以及所述预测梅尔频谱、预测音素级别时长、预测能量和预测音高训练语音合成模型,以获得定制化语音合成模型;
47、所述语音合成模块用于获取未知说话人的文本,将未知说话人的文本输入所述定制化语音合成模型,以获得未知说话人的预测梅尔频谱;基于所述未知说话人的预测梅尔频谱合成未知说话人语音。
48、上述技术方案的有益效果:
49、(1)本发明公开的一种基于自适应注意力机制的语音合成方法采用少量未知说话人的语音数据,通过微小变化语音合成模型参数来合成未知说话人声音,具体包括以说话人高维特征作为条件去控制语音合成模型的注意力机制和诸如音高、时长等的预测模块的权重,从而达到更加快速的适应说话人音色,显著提高生成的说话人语音的效果。
- 还没有人留言评论。精彩留言会获得点赞!