一种智能化的语音信号处理系统
本发明属于语音信号处理,尤其涉及一种智能化的语音信号处理系统。
背景技术:
1、语音,即语言的物质外壳,是语言的外部形式,是最直接地记录人的思维活动的符号体系。它是人的发音器官发出的具有一定社会意义的声音。语音的物理基础主要有音高、音强、音长、音色,这也是构成语音的四要素。语音即语言的声音,是语言符号系统的载体。它由人的发音器官发出,负载着一定的语言意义。语言依靠语音实现它的社会功能。语言是音义结合的符号系统,语言的声音和语言的意义是紧密联系着的,因此,语言虽是一种声音,但又与一般的声音有着本质的区别。语音是人类发音器官发出的具有区别意义功能的声音,不能把语音看成纯粹的自然物质;语音是最直接地记录思维活动的符号体系,是语言交际工具的声音形式;然而,现有智能化的语音信号处理系统采集的语音会有很大的噪声残留或者对目标声音有很大的损伤;同时,对语音识别不准确。
2、通过上述分析,现有技术存在的问题及缺陷为:
3、(1)现有智能化的语音信号处理系统采集的语音会有很大的噪声残留或者对目标声音有很大的损伤。
4、(2)对语音识别不准确。
技术实现思路
1、针对现有技术存在的问题,本发明提供了一种智能化的语音信号处理系统。
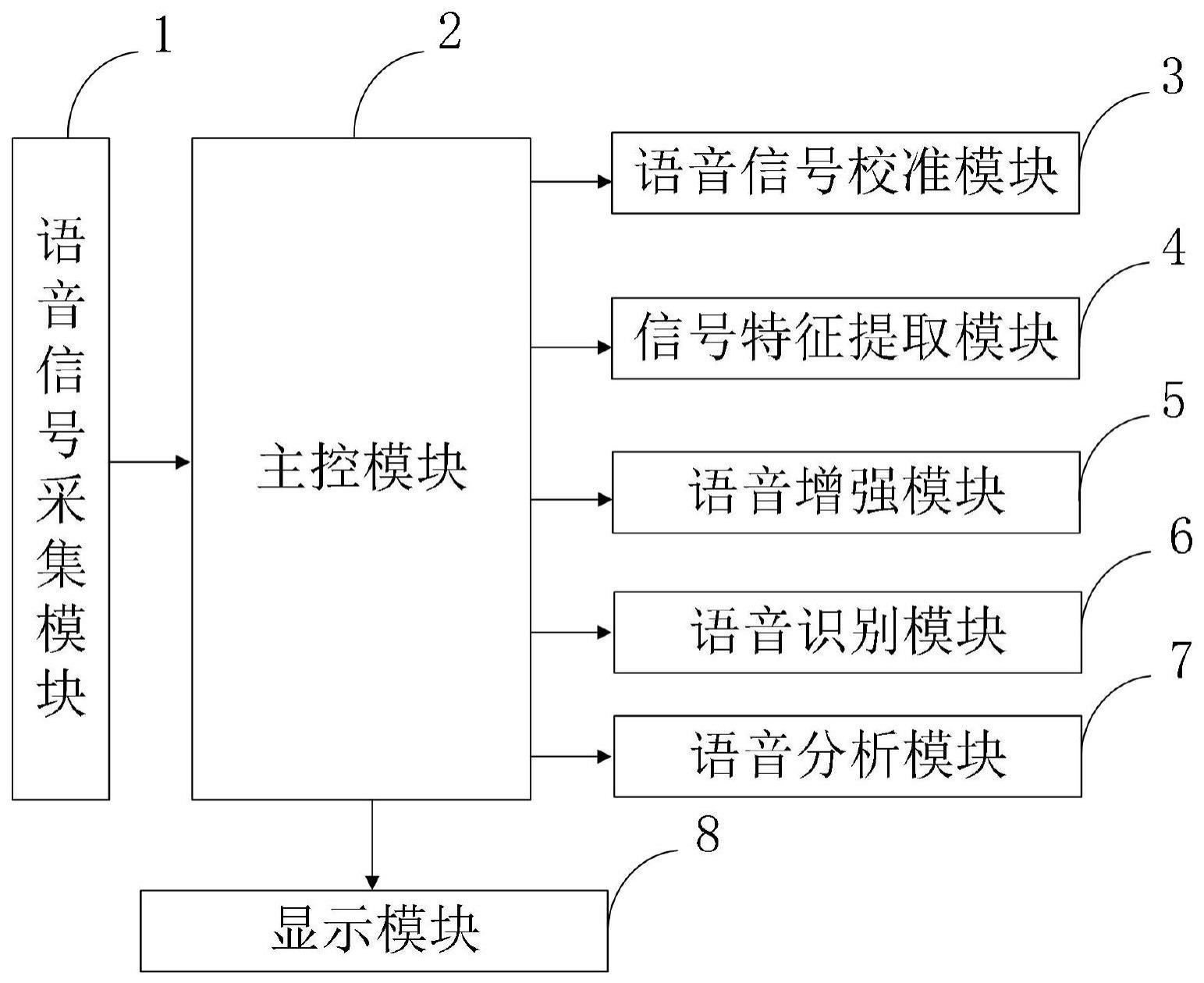
2、本发明是这样实现的,一种智能化的语音信号处理系统包括:
3、语音信号采集模块,与主控模块连接,用于通过声波在需求环境内采集目标语音信号;
4、主控模块,与语音信号采集模块、语音信号校准模块、信号特征提取模块、语音增强模块、语音识别模块、语音分析模块、显示模块连接,用于调节控制各个模块的数据信息,保障各个模块的正常工作;
5、语音信号校准模块,与主控模块连接,用于对获取到的语音信号进行自动校准;
6、信号特征提取模块,与主控模块连接,用于根据校准后的目标语音信号提取语音信号特征;
7、语音增强模块,与主控模块连接,用于对目标语音输入信号去噪处理、时频补偿,计算经过时频补偿的多个目标语音特征信息,并对目标语音输入信号进行分类得到目标语音分类结果,获得目标语音掩蔽值,最后获得目标语音输出信号;
8、语音识别模块,与主控模块连接,用于根据目标语音帧序列的每个语音帧中各时频点的强度获得每个语音帧中各时频点对应的色彩信息,生成目标语音信号的语谱图,在语谱图提取并识别语谱片段,得到语音识别语谱片段涉及的目标语种;
9、语音分析模块,与主控模块连接,用于对识别到的目标语音信号的语种进行分析;
10、显示模块,与主控模块连接,用于对各个模块中语音信号、识别结果、分析结果的显示,便于主控模块的操作。
11、进一步,所述语音增强模块增强方法如下:
12、(1)获取目标语音输入信号;对目标语音输入信号去噪处理;对所述目标语音输入信号进行时频补偿;计算经过时频补偿的多个目标语音特征信息,并对所述目标语音输入信号进行分类得到目标语音分类结果;
13、(2)根据所述多个目标语音特征信息和目标语音分类结果,确定目标语音掩蔽值;
14、根据所述多个目标语音特征信息和目标语音分类结果,确定目标语音掩蔽值的步骤,包括根据所述多个目标语音特征信息和预设掩蔽门限值,得到第一掩蔽值;在得到频域信号零和频域信号一后,采用分频带谱减法得到第二掩蔽值;基于所述目标语音分类结果,确定第三掩蔽值;在确定所述目标语音分类结果为噪声信号时,则确定目标语音掩蔽值为第三掩蔽值;在确定所述目标语音分类结果为目标语音信号时,则比较所述第一掩蔽值和第二掩蔽值,并基于比较结果确定目标语音掩蔽值;
15、基于所述目标语音掩蔽值,确定目标语音输出信号;
16、对所述目标语音输入信号进行时频补偿的步骤,包括:分别获取所述目标语音输入信号中第一麦克风的时域信号零和第二麦克风的时域信号一;对所述时域信号零进行分帧处理得到频域信号零,和,对所述时域信号一进行分帧处理得到频域信号一,其中,所述频域信号零和所述频域信号一包含有多个时频单元,每个所述时频单元对应一帧频域信号的一个频带;
17、确定与所述频域信号一中的每个时频单元对应的时频补偿参数一;基于所述时频补偿参数一对所述频域信号一中的各个所述时频单元进行时频补偿。
18、进一步,所述计算经过时频补偿的多个目标语音特征信息的步骤,包括:
19、计算经过时频补偿的双通道时间差itd和双通道能量差iid;
20、将所述双通道时间差itd和所述双通道能量差iid确定为所述目标语音输入信号的多个目标语音特征信息。
21、进一步,所述在计算经过时频补偿的多个目标语音特征信息之后,所述方法还包括:
22、判断所述频域信号零的目标帧是否为噪声信号;
23、在所述频域信号零的目标帧为噪声信号时,确定目标语音分类结果为噪声信号;或者,在所述频域信号零的目标帧不是噪声信号时,确定目标语音分类结果为目标语音信号。
24、进一步,所述在确定目标语音分类结果为噪声信号之后,所述方法还包括:基于所述频域信号零和所述频域信号一的信号差值更新所述时频补偿参数一。
25、进一步,所述基于所述目标语音掩蔽值,确定目标语音输出信号的步骤,包括:
26、对所述目标语音掩蔽值进行平滑处理;
27、基于平滑处理后的所述目标语音掩蔽值和经过分帧处理后得到的所述频域信号零,重建目标语音信号;
28、将重建后的目标语音信号确定为所述目标语音输出信号。
29、进一步,所述语音识别模块识别方法如下:
30、1)获取目标语音帧序列的每个语音帧中各时频点的强度;根据目标语音信号对应的匹配参数确定匹配参数对应的目标彩色色卡;匹配参数包括统计特征参数和聚类结果参数中的至少一项;根据目标彩色色卡所限定强度与色彩信息之间的对应关系和每个语音帧中各时频点的强度,确定每个语音帧中各时频点对应的色彩信息;按照每个语音帧中各时频点对应的色彩信息,生成目标语音信号的语谱图;获取待识别目标语音的语谱图;
31、2)基于第一滑窗在所述语谱图逐窗进行语种识别的第一识别结果,从所述语谱图提取再识别语谱片段;基于若干第二滑窗分别在所述再识别语谱片段逐窗进行语种识别的第二识别结果,分析得到所述再识别语谱片段涉及的目标语种;其中,所述若干第二滑窗的尺寸各不相同,且所述第二滑窗的尺寸小于所述第一滑窗的尺寸。
32、进一步,所述基于第一滑窗在所述语谱图逐窗进行语种识别的第一识别结果,从所述语谱图提取再识别语谱片段,包括:
33、基于所述第一滑窗在所述语谱图逐窗进行语种识别,得到若干第一语谱片段的第一识别结果;其中,所述第一识别结果包括所述第一语谱片段分别与若干预设语种的第一相关分值;
34、对于每一所述第一语谱片段,获取最高的第一相关分值与次高的第一相关分值之间的第一分值差值;
35、基于所述第一分值差值,从所述语谱图提取所述再识别语谱片段。
36、进一步,所述基于所述第一分值差值,从所述语谱图提取所述再识别语谱片段,包括:
37、基于所述第一分值差值低于第一阈值且连续的至少一组所述第一语谱片段,确定至少一组提取时段;其中,每组所述提取时段包括开始时刻和结束时刻;
38、分别基于各组所述提取时段,从所述语谱图提取得到所述再识别语谱片段。
39、进一步,所述识别方法还包括:
40、基于所述第一语谱片段的第一分值差异不低于第一阈值,将最高的第一相关分值对应的预设语种,作为所述第一语谱片段涉及的目标语种;
41、所述基于若干第二滑窗分别在所述再识别语谱片段逐窗进行语种识别的第二识别结果,分析得到所述再识别语谱片段涉及的目标语种,包括:
42、获取各个所述第二滑窗分别在所述再识别语谱片段逐窗进行语种识别的第二识别结果;所述第二识别结果包括所述再识别语谱片段分别与若干预设语种的第二相关分值;
43、对于每个所述第二滑窗,利用所述第二滑窗对应的统计识别结果对所述第二滑窗对应的第二识别结果进行规整,得到所述第二滑窗对应的规整识别结果;其中,所述统计识别结果是基于所述第二滑窗分别在若干样本语谱逐窗进行语种识别的样本识别结果而统计得到的;
44、基于融合所述若干第二滑窗对应的规整识别结果而得到的最终识别结果,确定所述再识别语谱片段涉及的目标语种;
45、所述获取各个所述第二滑窗分别在所述再识别语谱片段逐窗进行语种识别的第二识别结果,包括:
46、将各个所述第二滑窗分别作为当前滑窗;
47、基于所述当前滑窗在所述再识别语谱片段逐窗进行语种识别,得到若干第二语谱片段的第三识别结果;其中,所述第三识别结果包括所述第二语谱片段分别与若干预设语种的第三相关分值;
48、基于各个所述第二语谱片段分别与所述预设语种的第三相关分值,得到所述再识别语谱片段与对应所述预设语种的第二相关分值;
49、所述样本识别结果包括所述第二滑窗在所述样本语谱提取的若干样本语谱片段分别与所述若干预设语种的样本相关分值,所述统计识别结果是基于所述样本相关分值而统计到的标准差以及各个所述预设语种的平均相关分值,且所述规整识别结果包括所述再识别语谱片段分别与所述若干预设语种的规整相关分值;所述利用所述第二滑窗对应的统计识别结果对所述第二滑窗对应的第二识别结果进行规整,得到所述第二滑窗对应的规整识别结果,包括:
50、分别将各个所述预设语种作为当前语种;
51、获取所述当前语种对应的第二相关分值和所述平均相关分值之间的第二分值差值,并将所述第二分值差值与所述标准差之比,作为所述再识别语谱片段与所述当前语种的规整相关分值。
52、结合上述的技术方案和解决的技术问题,请从以下几方面分析本发明所要保护的技术方案所具备的优点及积极效果为:
53、第一、针对上述现有技术存在的技术问题以及解决该问题的难度,紧密结合本发明的所要保护的技术方案以及研发过程中结果和数据等,详细、深刻地分析本发明技术方案如何解决的技术问题,解决问题之后带来的一些具备创造性的技术效果。具体描述如下:
54、本发明通过语音增强模块对目标语音输入信号进行时频补偿,计算经过时频补偿的多个目标语音特征信息,并对目标语音输入信号进行分类得到目标语音分类结果,根据多个目标语音特征信息和目标语音分类结果,确定目标语音掩蔽值,最后基于目标语音掩蔽值,确定目标语音输出信号,降低噪音,提高语音清晰度;同时,通过语音识别模块获取待识别目标语音的语谱图,并基于第一滑窗在语谱图逐窗进行语种识别的第一识别结果,从语谱图提取再识别语谱片段,有利于进一步提升识别准确性。
55、第二,把技术方案看做一个整体或者从产品的角度,本发明所要保护的技术方案具备的技术效果和优点,具体描述如下:
56、本发明通过语音增强模块对目标语音输入信号进行时频补偿,计算经过时频补偿的多个目标语音特征信息,并对目标语音输入信号进行分类得到目标语音分类结果,根据多个目标语音特征信息和目标语音分类结果,确定目标语音掩蔽值,最后基于目标语音掩蔽值,确定目标语音输出信号,降低噪音,提高语音清晰度;同时,通过语音识别模块获取待识别目标语音的语谱图,并基于第一滑窗在语谱图逐窗进行语种识别的第一识别结果,从语谱图提取再识别语谱片段,有利于进一步提升识别准确性。
- 还没有人留言评论。精彩留言会获得点赞!