一种音素时长信息的生成方法、装置、存储介质及设备与流程
本发明涉及语音合成,尤其涉及一种音素时长信息的生成方法、装置、存储介质及设备。
背景技术:
1、语音合成,也称为文本与语音之间的转换,可以将任意的输入文本转换成自然流畅的语音输出。目前,语音合成模型包括两种类型,分别为自回归语音合成模型和非自回归语音合成模型。自回归语音合成模型中常见的模型包括tactotron2、transformer、deepvoice等模型。自回归语音合成模型的合成速度较慢,并且易出现重复吐字或者漏词的现象。非自回归语音合成模型使用全并行的非自回归架构,能够提高合成速度。同时,非自回归语音合成模型引入音素时长信息、能量及频率等作为输入参数进行训练,能够大量减少重复吐字或者漏词的现象。因此,非自回归语音合成模型经常被用来作为语音合成的工具。
2、音素时长、能量及频率等信息是非自回归语音合成模型中的重要训练参数。其中,音素时长信息直接影响合成语音的长度和整体韵律,决定语音合成的质量。然而,现有的音素时长预测模型均存在着各自的缺陷。比如,mfa对齐模型的对齐效果取决于模型的准确率,并且针对长文本处理的能力不足。再比如tacotron2教师模型是根据样本语音和样本语音对应的文本的注意力矩阵,确定音素时长信息,同样,音素时长的准确率取决于注意力矩阵。因此,亟需一种技术方案,以解决上述技术问题,进而能够使得语音合成中的音素时长信息更加准确,进一步提高语音合成的质量。
技术实现思路
1、本发明提供了一种音素时长信息的生成方法、装置、存储介质及电子设备,以解决现有技术中,语音合成中音素时长信息准确率较低的技术问题。
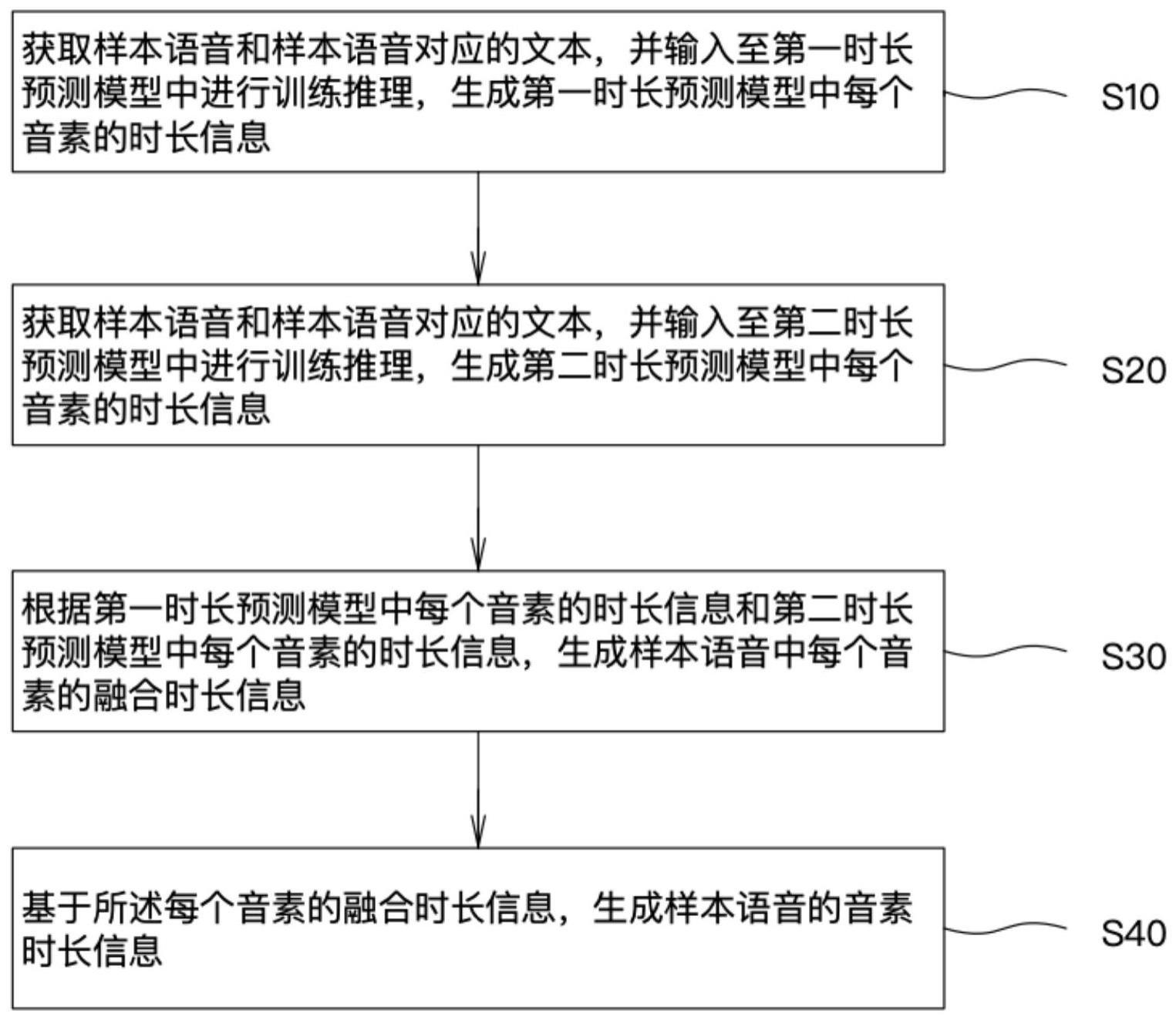
2、第一方面,提供了一种音素时长信息的生成方法,包括:
3、获取样本语音和样本语音对应的文本,并输入至第一时长预测模型中进行训练推理,生成第一时长预测模型中每个音素的时长信息;
4、获取样本语音和样本语音对应的文本,并输入至第二时长预测模型中进行训练推理,生成第二时长预测模型中每个音素的时长信息;
5、根据第一时长预测模型中每个音素的时长信息和第二时长预测模型中每个音素的时长信息,生成样本语音中每个音素的融合时长信息;
6、基于所述每个音素的融合时长信息,生成样本语音的音素时长信息。
7、在一种可能的实现方式中,所述根据第一时长预测模型中每个音素的时长信息和第二时长预测模型中每个音素的时长信息,生成样本语音中每个音素的融合时长信息,包括:
8、根据第一时长预测模型中每个音素的时长信息和第二时长预测模型中每个音素的时长信息,计算每个音素的平均时长信息;
9、将所述平均时长信息确定为样本语音中每个音素的融合时长信息。
10、在一种可能的实现方式中,所述基于所述每个音素的融合时长信息,生成样本语音的音素时长信息,包括:
11、将每个音素的融合时长信息依次相加,生成多个音素的总时长信息;
12、判断所述总时长信息是否和样本语音的总时长信息相一致;
13、如果不一致,则在最后一个音素位置处,增加或减少空白时长信息,以确保融合后的总时长信息和样本语音的总时长信息相一致;
14、根据每个音素的融合时长信息及所增加或减少的空白时长信息,确定样本语音的音素时长信息。
15、在一种可能的实现方式中,所述第一时长预测模型为tacotron2教师模型,所述获取样本语音和样本语音对应的文本,并输入至第一时长预测模型中进行训练推理,生成第一时长预测模型中每个音素的时长信息,包括:
16、基于tacotron2教师模型中的注意力机制,生成样本语音和样本语音对应的文本的注意力矩阵;
17、根据所述注意力矩阵,生成第一时长预测模型中每个音素的时长信息。
18、在一种可能的实现方式中,所述第二时长预测模型为mfa对齐模型,所述获取样本语音和样本语音对应的文本,并输入至第二时长预测模型中进行训练推理,生成第二时长预测模型中每个音素的时长信息,包括:
19、根据mfa对齐模型中的词典库,将样本语音对应的文本拆分成多个音素,其中,所述词典库中包括文本拼音及文本拼音对应的音素;
20、通过音素对齐,并根据样本语音,生成第二时长预测模型中每个音素的时长信息。
21、在一种可能的实现方式中,所述基于所述每个音素的融合时长信息,生成样本语音的音素时长信息之后,还包括:
22、获取样本语音,并分别输入至基频、能量提取模型中,生成样本语音的基频和能量信息;
23、将样本语音对应的文本以及所述音素时长、基频和能量信息输入至语音合成模型中进行训练。
24、在一种可能的实现方式中,所述语音合成模型为fastspeech2模型,所述将样本语音对应的文本以及所述音素时长、基频和能量信息输入至语音合成模型中进行训练之后,还包括:
25、获取目标文本,并将目标文本输入至fastspeech2模型,生成目标文本对应的语音。
26、第二方面,提供了一种音素时长信息的生成装置,包括:
27、第一时长信息生成模块:用于获取样本语音和样本语音对应的文本,并输入至第一时长预测模型中进行训练推理,生成第一时长预测模型中每个音素的时长信息;
28、第二时长信息生成模块:用于获取样本语音和样本语音对应的文本,并输入至第二时长预测模型中进行训练推理,生成第二时长预测模型中每个音素的时长信息;
29、融合时长信息生成模块:用于根据第一时长预测模型中每个音素的时长信息和第二时长预测模型中每个音素的时长信息,生成样本语音中每个音素的融合时长信息;
30、音素时长信息生成模块:用于基于所述每个音素的融合时长信息,生成样本语音的音素时长信息。
31、在一种可能的实现方式中,上述融合时长信息生成模块,还用于:
32、根据第一时长预测模型中每个音素的时长信息和第二时长预测模型中每个音素的时长信息,计算每个音素的平均时长信息;
33、将所述平均时长信息确定为样本语音中每个音素的融合时长信息。
34、在一种可能的实现方式中,上述音素时长信息生成模块,还用于:
35、将每个音素的融合时长信息依次相加,生成多个音素的总时长信息;
36、判断所述总时长信息是否和样本语音的总时长信息相一致;
37、如果不一致,则在最后一个音素位置处,增加或减少空白时长信息,以确保融合后的总时长信息和样本语音的总时长信息相一致;
38、根据每个音素的融合时长信息及所增加或减少的空白时长信息,确定样本语音的音素时长信息。
39、在一种可能的实现方式中,所述第一时长预测模型为tacotron2教师模型,上述第一时长信息生成模块,还用于:
40、基于tacotron2教师模型中的注意力机制,生成样本语音和样本语音对应的文本的注意力矩阵;
41、根据所述注意力矩阵,生成第一时长预测模型中每个音素的时长信息。
42、在一种可能的实现方式中,所述第二时长预测模型为mfa对齐模型,上述第二时长信息生成模块,还用于:
43、根据mfa对齐模型中的词典库,将样本语音对应的文本拆分成多个音素,其中,所述词典库中包括文本拼音及文本拼音对应的音素;
44、通过音素对齐,并根据样本语音,生成第二时长预测模型中每个音素的时长信息。
45、在一种可能的实现方式中,上述音素时长信息的生成装置,还包括训练模块,用于:
46、获取样本语音,并分别输入至基频、能量提取模型中,生成样本语音的基频和能量信息;
47、将样本语音对应的文本以及所述音素时长、基频和能量信息输入至语音合成模型中进行训练。
48、在一种可能的实现方式中,上述音素时长信息的生成装置,还包括语音生成模块,用于:
49、用于获取目标文本,并将目标文本输入至语音合成模型,生成目标文本对应的语音。
50、第三方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现上述音素时长信息的生成方法的步骤。
51、第四方面,提供了一种电子设备,包括存储器、处理器以及存储在存储器中并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述音素时长信息的生成方法的步骤。
52、上述音素时长信息的生成方法、装置、存储介质及电子设备,通过获取样本语音和样本语音对应的文本,并输入至第一时长预测模型中进行训练推理,生成第一时长预测模型中每个音素的时长信息;然后,将获取的样本语音和样本语音对应的文本,输入至第二时长预测模型中进行训练推理,生成第二时长预测模型中每个音素的时长信息;并且,根据第一时长预测模型中每个音素的时长信息和第二时长预测模型中每个音素的时长信息,生成样本语音中每个音素的融合时长信息;最后,基于所述每个音素的融合时长信息,生成样本语音的音素时长信息。
53、本技术通过结合两个时长预测模型的特征,生成样本语音的音素时长信息,能够提高音素时长信息的准确率。比如,当第一时长预测模型为tacotron2教师模型,第二时长预测模型为mfa对齐模型时,将两个时长预测模型所生成的每个音素的时长信息进行融合,一方面能够帮助克服mfa对齐模型中针对长文本处理能力不足的问题,另一方面,能够结合两个模型的准确率确定音素时长信息。
- 还没有人留言评论。精彩留言会获得点赞!