基于动态规划的长音频和文本对齐方法与流程
本发明涉及音频和文本对齐,具体为基于动态规划的长音频和文本对齐方法。
背景技术:
1、后疫情时代,中国有声书市场、视频直播行业发展迅猛。音频与文本的对齐是有声书制作、视频直播字幕生成、会议纪要等行业发展的关键技术之一。而有声书制作以及会议纪要过程中的长音频和文本通常是不完全匹配的,因此不完全匹配的长音频和文本对齐尤为重要。
2、传统的音频和文本对齐方法有基于dtw的aeneas工具,但是此工具在长音频和文本不匹配处之后的对齐效果较差;也有基于hmm语音识别的方法。目前使用语音识别技术进行文本和语音对齐的主要方法是重复迭代语音识别和文本对齐,但是语音识别会存在一定的误差,当某些词识别不准确时会导致句子间无法完全匹配,导致了传统基于dtw的开源库只能对齐完全匹配的音频和文本以及基于hmm的迭代语音识别和文本对齐无法处理模糊音导致对齐精度低的缺点,因此我们提出了一种基于动态规划的长音频和文本对齐方法。
技术实现思路
1、针对现有技术的不足,本发明提供了基于动态规划的长音频和文本对齐方法,解决了上述背景技术中提出传统基于dtw的开源库只能对齐完全匹配的音频和文本以及基于hmm的迭代语音识别和文本对齐无法处理模糊音导致对齐精度低的缺点的问题。
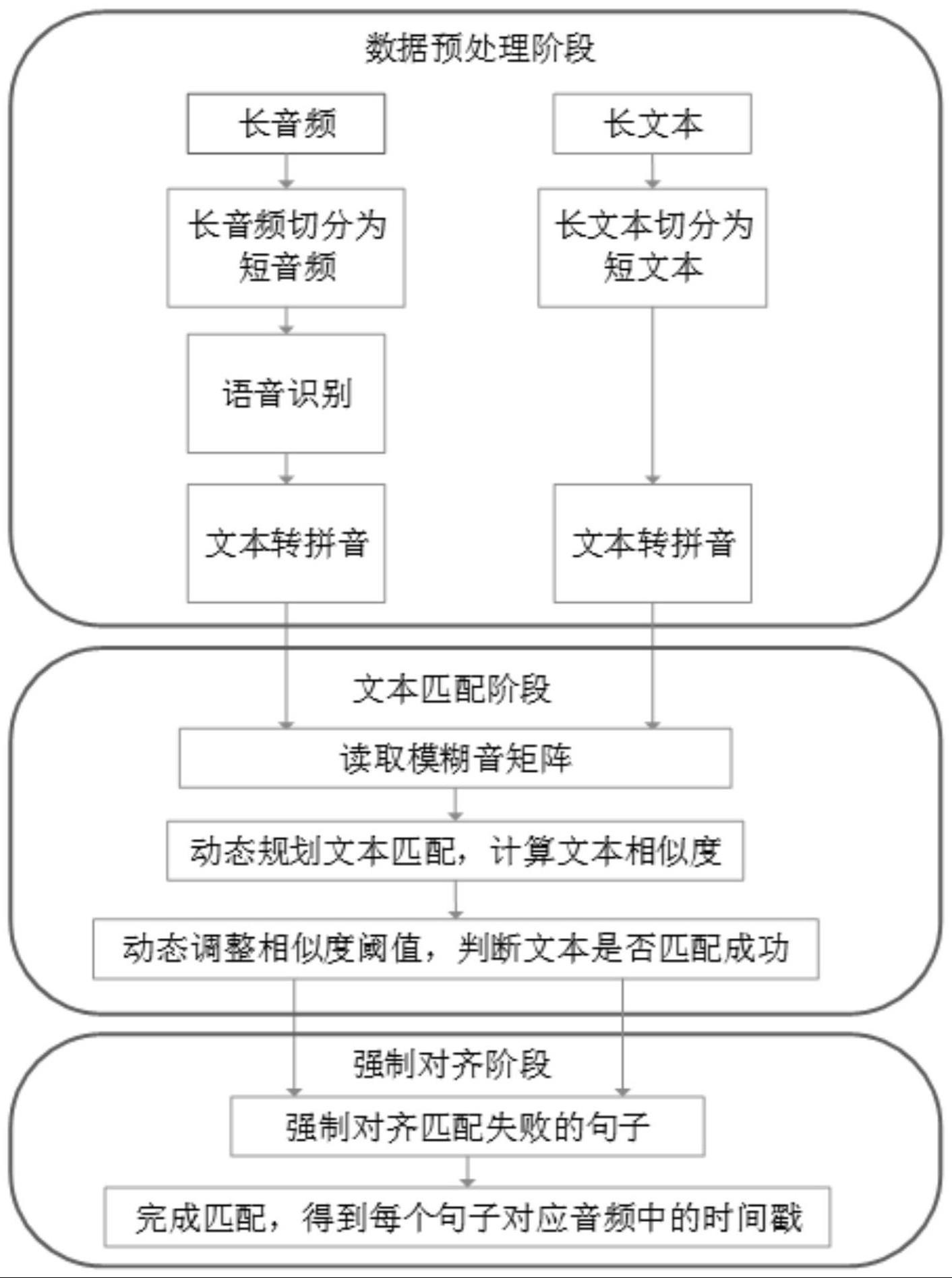
2、为实现以上目的,本发明通过以下技术方案予以实现:基于动态规划的长音频和文本对齐方法,包括以下步骤;
3、s1:数据预处理阶段,将长音频切割成较短音频再进行语音识别,可以在一定程度上加快语音识别的速度;
4、为了保证进行文本匹配的文本长度相同或相近,对实际长文本按照句子的标点切割成短文本;
5、s2:文本匹配阶段,将长文本和长音频的asr结果所转换的拼音分别记为t和a,参与匹配的较短拼音序列按序分别记为ti和aj;
6、在匹配过程中计算ti和aj、(ti+ti+1)和aj以及ti和(aj+aj+1)的文本相似度,如果相邻拼音序列合并后进行匹配的相似度减原匹配拼音序列相似度大于阈值τ,将这两个拼音序列合并起来,合并方式如下,
7、1:如果sim((ti+ti+1),aj)-sim(ti,aj)>τ:
8、ti=ti+ti+1
9、2:如果sim(ti,(aj+aj+1))-sim(ti,aj)>τ:
10、aj=aj+aj+1
11、采用动态规划的策略进行匹配,状态转移方程如下:
12、s(tiaj)=max(s(ti-1,aj-1),s(ti,aj-1),s(ti-1,aj))+sim(ti,aj)
13、其中,s(ti,aj)为ti和aj的匹配情况,sim(ti,aj)为合并后的ti和aj两个拼音序列的相似度;
14、s2.1:模糊音矩阵,初始模糊音矩阵包括初始声母模糊音矩阵、初始韵母模糊音矩阵以及初始整体认读模糊音矩阵;
15、将这三个矩阵看作上三角矩阵,主对角线上的元素都为1,表示两个音节发音的相似度为1,主对角线右侧颜色由深到浅表示两个音节的发音相似度逐渐降低,表格中的数字表示两个音节的发音相似度;
16、音频和文本预处理之后,加载模糊音矩阵;若文本初次匹配失败,则读取模糊音矩阵,重新进行匹配;如果当前音节为整体认读音节,模糊音矩阵中的相似度即为当前拼音的相似度;如果当前音节不是整体认读音节,根据声母和韵母模糊音矩阵计算出当前拼音的发音相似度,当前拼音的发音相似度simpyi计算公式如下:
17、simpyi=α×siminitials+β×simvowel
18、其中,α和β为权重因子,且有α+β=1;siminitials为当前拼音的声母发音相似度,simvowel为当前拼音的韵母发音相似度;
19、在文本匹配过程中,如果当前句子没有匹配成功,重新计算当前句子的编辑距离以及文本相似度,编辑距离d(ti,aj)的计算公式如下:
20、
21、每次上传音频和文本进行对齐之后,都会统计此音频中的模糊音,加入到模糊音矩阵中并调整发音相似度;
22、s2.2:文本相似度计算,采用编辑距离来度量两个拼音的相似程度;编辑距离指的是在两个拼音ti,aj之间,由其中一个拼音ti转换为另一个拼音aj所需要的最少单拼音编辑操作次数;根据编辑次数定义ti和aj文本相似性sim(ti,aj),公式如下所示:
23、
24、其中,lti,laj为拼音ti和aj的字符长度,d为拼音ti和aj的编辑距离,max为取最大值函数;
25、s2.3:动态调整相似度阈值,在文本匹配的过程中,当前句子是否匹配成功是由当前文本相似度以及相似度阈值共同决定的;
26、相似度阈值是受到当前句子前后的句子的匹配情况约束的,相似度阈值在文本匹配的过程中是动态变化的,计算公式如下:
27、
28、其中,α和β为权重因子,且有α+β=1;n1为当前句子之前连续匹配成功的句子数;n2为当前句子之后连续匹配成功的句子数;
29、s3:强制对齐阶段,首先根据文本匹配的结果找到所有连续匹配成功的块,其中包含句子最多的块即为置信度最高的,记为chunkmax,同时记录下chunkmax开始和结束的位置;从chunkmax开始位置向前以及结束位置向后搜索匹配错误的句子,再由匹配错误的句子找到其所在的最小的两端都为匹配成功句子的块,由此局部匹配的最优情况强制对齐匹配错误的句子;
30、s3.1:强制对齐模块,文本匹配结束后,匹配失败的句子从全局进行调整是比较麻烦的;
31、以匹配错误的句子t8、t4、t3为例;从t8向前查找第一个匹配正确的句子为t7,接着从t8向后查找第一个匹配正确的句子为t9;t8在以t7和t9这两个句子为边界的范围内强制对齐:将文本t8匹配的音频强制置为t7对应音频中结束时刻到t9对应音频中开始时刻的音频;对于t3和t4来说,向前查找的第一个匹配正确的句子都为t2,向后查找的第一个匹配正确的句子都为t5;t3和t4在以t2和t5这两个句子为边界的范围内强制对齐:
32、将文本t3和t4合并起来记为(t3+t4),其匹配的音频强制置为t2对应音频中结束时刻到t5对应音频中开始时刻的音频;这样每个句子都有了对应到原音频的开始和结束时间戳。
33、优选的,所述s1中由于语音识别的人名、地名等专有名词与实际文本中的会有差异,会影响文本匹配的效果,所以将汉字转换成拼音进行匹配。
34、优选的,所述s3中由于参与文本匹配的两部分文本长度并不是每次都相同或相近,会存在个别匹配错误的情况,针对这些匹配错误的句子,设计了强制对齐模块。
35、本发明提供了基于动态规划的长音频和文本对齐方法,具备以下有益效果:
36、1、该基于动态规划的长音频和文本对齐方法,对小段语料文本和小段识别文本进行拼音转换,加载模糊音处理矩阵,基于动态规划状态转移方程获取拼音文本初始相似度,动态调整相似度阈值匹配小段语料文本与小段识别文本;提取剩余未对齐的识别文本片段,获取所述小段识别文本的时间边界,计算识别文本置信度,按照局部最优原则修复对齐错误的小段识别文本,通过将语音识别与动态规划相结合,采用动态规划的策略对参考文本和语音识别文本所转换的拼音进行匹配,并通过模糊音处理、计算文本相似度、文语强制对齐等方法提高了目前基于语音识别的不完全匹配的长音频和文本的对齐效果,弥补了传统基于dtw的开源库只能对齐完全匹配的音频和文本以及基于hmm的迭代语音识别和文本对齐无法处理模糊音导致对齐精度低的缺点,提高了生产效率并节省人力资源。
- 还没有人留言评论。精彩留言会获得点赞!