语音活性检测方法、装置、设备及存储介质与流程
本技术涉及人工智能,特别涉及一种语音活性检测方法、装置、设备及存储介质。
背景技术:
1、语音活性检测(voice activity detection,vad),也称语音活动检测,是人工智能发展过程中的一项重要技术,常被用于人机对话场景,用于检测语音信号是否存在。
2、相关技术中,由于部分用户说话节奏较慢,比如一句话中间有多次短暂停顿,因此在进行语音活性检测时,很容易出现用户说话被设备打断的问题。即,话还没讲完,但语音交互设备的vad模型却错误判断用户讲话已结束,继而做出响应。
3、这无疑会严重影响人机对话过程中的对话质量,人机交互效果差。
技术实现思路
1、本技术实施例提供了一种语音活性检测方法、装置、设备及存储介质,能够提高人机对话过程中的对话质量,人机交互效果佳。所述技术方案如下:
2、一方面,提供了一种语音活性检测方法,所述方法包括:
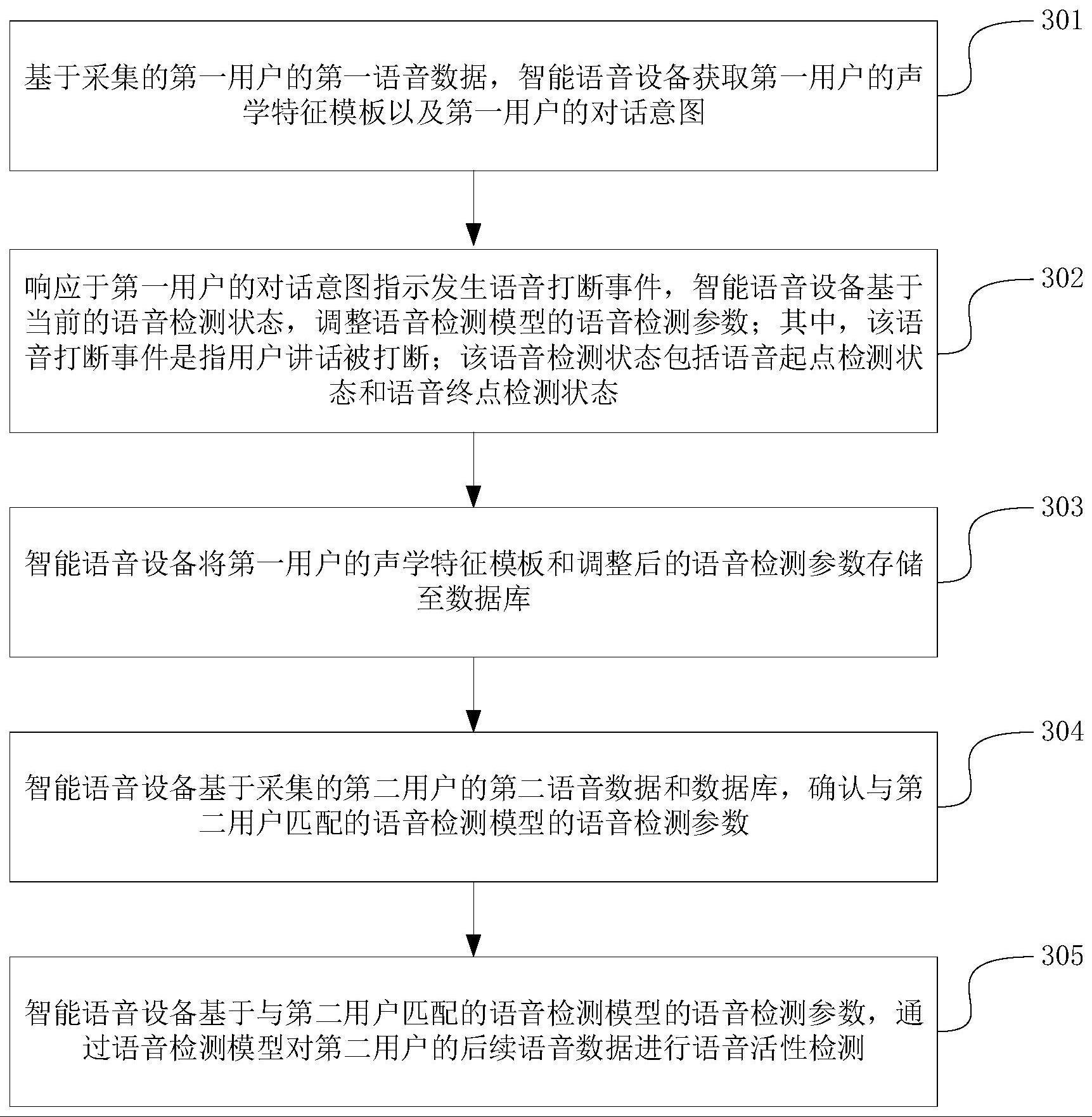
3、基于采集的第一用户的第一语音数据,获取所述第一用户的声学特征模板以及所述第一用户的对话意图;
4、响应于所述第一用户的对话意图指示发生语音打断事件,基于当前的语音检测状态,调整语音检测模型的语音检测参数;所述语音打断事件是指用户讲话被打断;所述语音检测状态包括语音起点检测状态和语音终点检测状态;
5、将所述第一用户的声学特征模板和调整后的语音检测参数存储至数据库;
6、基于采集的第二用户的第二语音数据和所述数据库,确认与所述第二用户匹配的语音检测模型的语音检测参数;
7、基于与所述第二用户匹配的语音检测模型的语音检测参数,通过所述语音检测模型对所述第二用户的后续语音数据进行语音活性检测。
8、在一种可能的实现方式中,所述基于当前的语音检测状态,调整语音检测模型的语音检测参数,包括:
9、响应于当前还未进入所述语音起点检测状态,增大第一语音检测参数的取值;其中,所述第一语音检测参数用于指示前端静音检测超时时间;
10、响应于当前已进入所述语音终点检测状态,增大第二语音检测参数的取值;其中,所述第二语音检测参数用于指示后端停顿时间。
11、在一种可能的实现方式中,所述方法还包括:
12、获取所述第一语音数据的信号能量;
13、响应于获取到的信号能量开始大于第一阈值,确定当前已进入所述语音起点检测状态;
14、响应于获取到的信号能量小于第二阈值且持续时长已超过预设时长,确定当前已进入所述语音终点检测状态。
15、在一种可能的实现方式中,所述基于当前的语音检测状态,调整语音检测模型的语音检测参数,包括:
16、基于当前的语音检测状态和目标约束条件,调整所述语音检测模型的语音检测参数;
17、其中,所述目标约束条件包括:最大可调整幅度、单次调整的调整步长。
18、在一种可能的实现方式中,所述基于采集的第一用户的第一语音数据,获取所述第一用户的声学特征模板,包括:
19、对所述第一语音数据进行声学特征提取;
20、对所述第一语音数据进行用户年龄分析,得到所述第一用户的年龄特征;
21、对所述第一语音数据进行用户性别分析,得到所述第一用户的性别特征;
22、对所述第一语音数据进行用户情绪分析,得到所述第一用户的情绪特征;
23、对提取到的声学特征、所述年龄特征、所述性别特征和所述情绪特征进行特征融合,得到所述第一用户的声学特征;
24、将所述第一用户的声学特征输入声纹识别模型,得到所述第一用户的声学特征模板。
25、在一种可能的实现方式中,所述基于采集的第一用户的第一语音数据,获取所述第一用户的对话意图,包括:
26、确定当前拾音环境的环境类型,基于与所述环境类型匹配的语音识别模型,对所述第一语音数据进行语音识别,得到语音识别结果;
27、对所述语音识别结果进行意图识别,得到所述第一用户的对话意图;
28、其中,所述环境类型包括安静环境和噪音环境;
29、所述语音识别模型是基于样本集对预训练模型进行再训练得到的,所述样本集中包括在相应环境下采集的语音数据。
30、在一种可能的实现方式中,所述基于与所述环境类型匹配的语音识别模型,对所述第一语音数据进行语音识别,包括:
31、响应于当前拾音环境为安静环境,基于与所述安静环境匹配的第一语音识别模型,对所述第一语音数据进行语音识别;
32、响应于当前拾音环境为噪音环境,基于与所述噪音环境匹配的第二语音识别模型,对所述第一语音数据进行语音识别;
33、其中,所述第一语音识别模型是基于第一样本集对预训练模型进行再训练得到的,所述第一样本集中包括在所述安静环境下采集的语音数据;
34、所述第二语音识别模型是基于第二样本集对预模型进行再训练得到的,所述第二样本集中包括在所述噪音环境下采集的语音数据。
35、在一种可能的实现方式中,所述确定当前拾音环境的环境类型,包括:
36、确定当前拾音环境所属的场所类型、周边基础设施信息以及当前拾音时间;
37、根据所述场所类型、所述周边基础设施信息以及当前拾音时间,确定当前拾音环境的环境类型。
38、在一种可能的实现方式中,所述基于采集的第二用户的第二语音数据和所述数据库,确认与所述第二用户匹配的语音检测模型的语音检测参数,包括:
39、对所述第二语音数据进行声学特征提取;
40、将所述第二用户的声学特征输入声纹识别模型,得到所述第二用户的声学特征模板;
41、将所述第二用户的声学特征模板与所述数据库中存储的声学特征模板进行比对;
42、响应于所述第二用户的声学特征模板与所述数据库中的目标声学特征模板的匹配度大于第三阈值,将所述目标声学特征模板对应的语音检测参数,作为与所述第二用户匹配的语音检测模型的语音检测参数。
43、另一方面,提供了一种语音活性检测装置,所述装置包括:
44、第一获取模块,被配置为基于采集的第一用户的第一语音数据,获取所述第一用户的声学特征模板以及所述第一用户的对话意图;
45、参数调整模块,被配置为响应于所述第一用户的对话意图指示发生语音打断事件,基于当前的语音检测状态,调整语音检测模型的语音检测参数;所述语音打断事件是指用户讲话被打断;所述语音检测状态包括语音起点检测状态和语音终点检测状态;
46、存储模块,被配置为将所述第一用户的声学特征模板和调整后的语音检测参数存储至数据库;
47、第二获取模块,被配置为基于采集的第二用户的第二语音数据和所述数据库,确认与所述第二用户匹配的语音检测模型的语音检测参数;
48、语音检测模块,被配置为基于与所述第二用户匹配的语音检测模型的语音检测参数,通过所述语音检测模型对所述第二用户的后续语音数据进行语音活性检测。
49、在一种可能的实现方式中,所述参数调整模块,被配置为:
50、响应于当前还未进入所述语音起点检测状态,增大第一语音检测参数的取值;其中,所述第一语音检测参数用于指示前端静音检测超时时间;
51、响应于当前已进入所述语音终点检测状态,增大第二语音检测参数的取值;其中,所述第二语音检测参数用于指示后端停顿时间。
52、在一种可能的实现方式中,所述参数调整模块,被配置为:
53、获取所述第一语音数据的信号能量;
54、响应于获取到的信号能量开始大于第一阈值,确定当前已进入所述语音起点检测状态;
55、响应于获取到的信号能量小于第二阈值且持续时长已超过预设时长,确定当前已进入所述语音终点检测状态。
56、在一种可能的实现方式中,所述参数调整模块,被配置为:
57、基于当前的语音检测状态和目标约束条件,调整所述语音检测模型的语音检测参数;
58、其中,所述目标约束条件包括:最大可调整幅度、单次调整的调整步长。
59、在一种可能的实现方式中,所述第一获取模块,被配置为:
60、对所述第一语音数据进行声学特征提取;
61、对所述第一语音数据进行用户年龄分析,得到所述第一用户的年龄特征;
62、对所述第一语音数据进行用户性别分析,得到所述第一用户的性别特征;
63、对所述第一语音数据进行用户情绪分析,得到所述第一用户的情绪特征;
64、对提取到的声学特征、所述年龄特征、所述性别特征和所述情绪特征进行特征融合,得到所述第一用户的声学特征;
65、将所述第一用户的声学特征输入声纹识别模型,得到所述第一用户的声学特征模板。
66、在一种可能的实现方式中,所述第一获取模块,被配置为:
67、确定当前拾音环境的环境类型,基于与所述环境类型匹配的语音识别模型,对所述第一语音数据进行语音识别,得到语音识别结果;
68、对所述语音识别结果进行意图识别,得到所述第一用户的对话意图;
69、其中,所述环境类型包括安静环境和噪音环境;
70、所述语音识别模型是基于样本集对预训练模型进行再训练得到的,所述样本集中包括在相应环境下采集的语音数据。
71、在一种可能的实现方式中,所述第一获取模块,被配置为:
72、响应于当前拾音环境为安静环境,基于与所述安静环境匹配的第一语音识别模型,对所述第一语音数据进行语音识别;
73、响应于当前拾音环境为噪音环境,基于与所述噪音环境匹配的第二语音识别模型,对所述第一语音数据进行语音识别;
74、其中,所述第一语音识别模型是基于第一样本集对预训练模型进行再训练得到的,所述第一样本集中包括在所述安静环境下采集的语音数据;
75、所述第二语音识别模型是基于第二样本集对预模型进行再训练得到的,所述第二样本集中包括在所述噪音环境下采集的语音数据。
76、在一种可能的实现方式中,所述第一获取模块,被配置为:
77、确定当前拾音环境所属的场所类型、周边基础设施信息以及当前拾音时间;
78、根据所述场所类型、所述周边基础设施信息以及当前拾音时间,确定当前拾音环境的环境类型。
79、在一种可能的实现方式中,所述第二获取模块,被配置为:
80、对所述第二语音数据进行声学特征提取;
81、将所述第二用户的声学特征输入声纹识别模型,得到所述第二用户的声学特征模板;
82、将所述第二用户的声学特征模板与所述数据库中存储的声学特征模板进行比对;
83、响应于所述第二用户的声学特征模板与所述数据库中的目标声学特征模板的匹配度大于第三阈值,将所述目标声学特征模板对应的语音检测参数,作为与所述第二用户匹配的语音检测模型的语音检测参数。
84、另一方面,提供了一种智能语音设备,所述设备包括处理器和存储器,所述存储器中存储有至少一条程序代码,所述至少一条程序代码由所述处理器加载并执行以实现上述的语音活性检测方法。
85、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条程序代码,所述至少一条程序代码由处理器加载并执行以实现上述的语音活性检测方法。
86、另一方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机程序代码,该计算机程序代码存储在计算机可读存储介质中,智能语音设备的处理器从计算机可读存储介质读取该计算机程序代码,处理器执行该计算机程序代码,使得该智能语音设备执行上述的语音活性检测方法。
87、本技术实施例能够基于说话对象的讲话习惯智能调整语音检测模型的语音检测参数,以此降低设备打断用户讲话的发生概率。详细来说,该方案在采集到某个用户的语音数据后,会先获取该用户的声学特征模板和对话意图;如果该用户的对话意图指示发生语音打断事件,则基于当前的语音检测状态,来调整语音检测模型的语音检测参数,并将该用户的声学特征模板和调整后的语音检测参数存储至数据库。这样在后续人机对话过程中,如果采集到某个用户(既可以与上述用户相同也可以不同)的语音数据,则设备会利用该数据库确认与该用户匹配的语音检测模型的语音检测参数;进而基于与该用户匹配的语音检测模型的语音检测参数,通过语音检测模型对该用户的后续语音数据进行语音活性检测。
88、换言之,通过识别用户意图,本技术实施例能够及时发现设备侧产生的语音流是否存在打断用户讲话的情况,进而通过调整语音检测参数来降低语音打断事件的发生概率,该方法显著提升了人机对话质量;另外,本技术实施例通过声学特征来区分不同用户,提高了辨别不同用户的准确性。
89、综上所述,本技术实施例降低了设备打断用户讲话的发生概率,提高了人机对话过程中的对话质量,人机对话效果佳,进而提升了用户体验。
- 还没有人留言评论。精彩留言会获得点赞!