一种预训练方法及相关方法和设备与流程
本发明涉及数据处理,尤其涉及一种预训练方法及相关方法和设备。
背景技术:
1、基于编码器-解码器(encoder-decoder)框架的任务模型(比如语音合成模型)的一般获得方式为,先通过预训练方式获得编码器,即对初始的语言模型进行训练,训练后的语言模型作为编码器,在此基础上构建包括编码器和解码器的模型,进而利用指定任务的训练数据对构建的模型进行微调,从而得到最终的任务模型(比如,用语音合成任务的训练数据对构建的模型进行微调,得到语音合成模型)。
2、目前的预训练方式一般为基于音素信息的预训练方式,即获取训练文本对应的音素信息序列,利用训练文本对应的音素信息序列对初始的语言模型进行训练。然而,在利用训练文本对应的音素信息序列对语言模型进行训练时,语言模型仅能学习到发音信息,而无法学习到其它重要信息,这导致训练得到语言模型作为编码器应用于下游任务(比如语音合成任务)时,效果不佳。
技术实现思路
1、有鉴于此,本发明提供了一种预训练方法及相关方法和设备,用以解决采用现有的预训练方式对语言模型进行预训练时,语言模型仅能学习到发音信息,而无法学习到其它重要信息,进而导致训练得到语言模型作为编码器应用于下游任务时,效果不佳的问题,其技术方案如下:
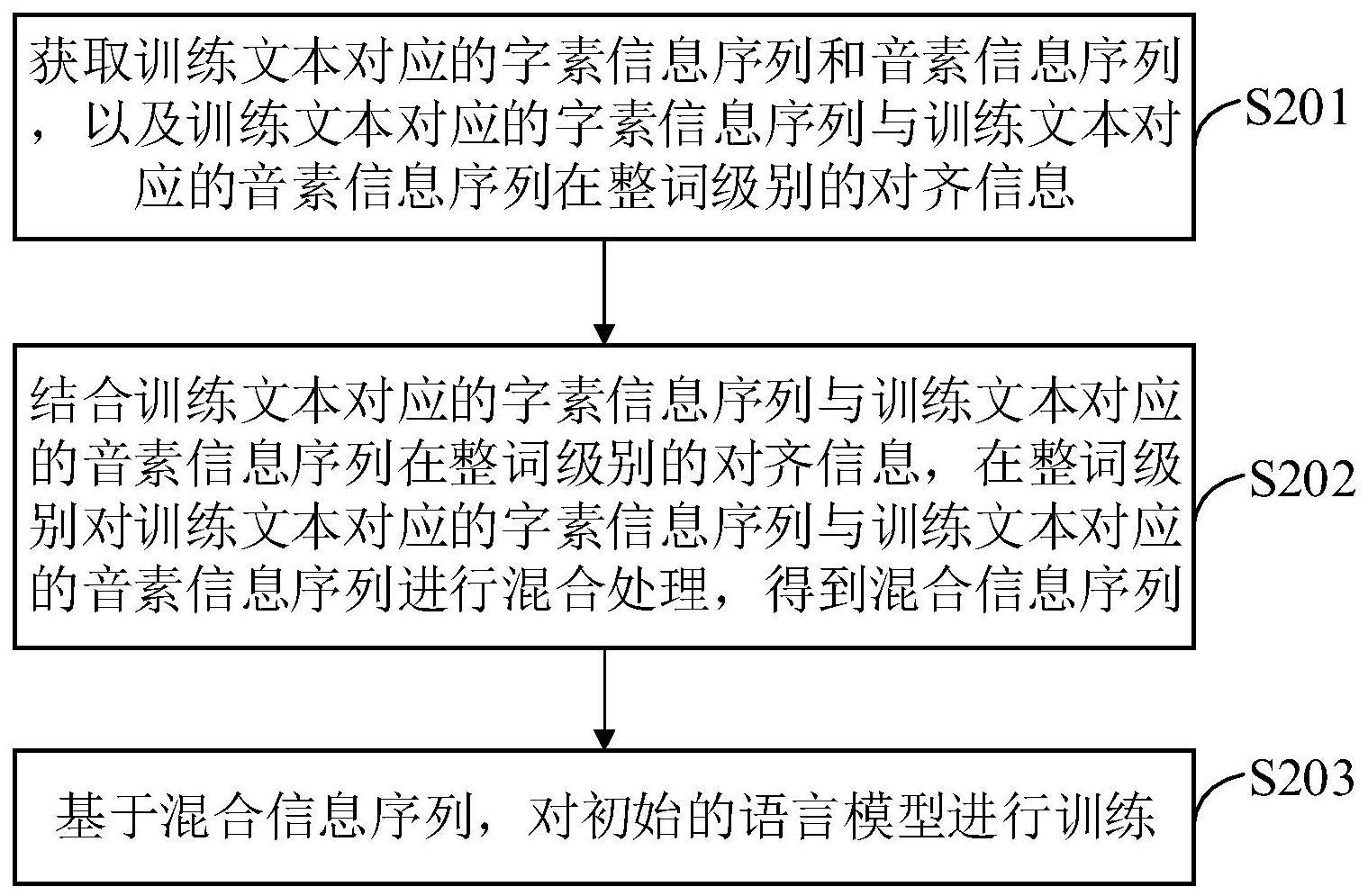
2、一种预训练方法,包括:
3、获取训练文本对应的字素信息序列和音素信息序列,以及所述字素信息序列与所述音素信息序列在整词级别的对齐信息,其中,所述字素信息序列中的每个字素信息为对所述训练文本进行分词得到一分词单元的信息,所述音素信息序列中的每个音素信息为所述训练文本中一整词的音素信息;
4、结合所述对齐信息,在整词级别对所述字素信息序列与所述音素信息序列进行混合处理,得到混合信息序列,其中,在进行混合处理时,针对同一整词,只保留字素信息和音素信息中的一种信息;
5、基于所述混合信息序列,对初始的语言模型进行训练。
6、可选的,获取训练文本对应的字素信息序列和音素信息序列,包括:
7、对所述训练文本进行子词粒度的切分,针对通过切分得到的子词序列中的每个子词,将该子词映射为表征该子词在词典中的位置的标识,作为该子词对应的字素标识,将由所述子词序列中各子词分别对应的字素标识组成的序列确定为所述训练文本对应的字素信息序列;
8、针对所述训练文本中的每个整词,获取该整词对应的音素序列,并将该整词对应的音素序列中的每个音素映射为表征该音素在所述词典中的位置的标识,得到标识序列作为该整词对应的音素标识,将由所述训练文本中各整词分别对应的音素标识组成的序列确定为所述训练文本对应的音素信息序列;
9、其中,所述词典中包括若干整词分别对应的子词切分方式和音素序列。
10、可选的,获取所述字素信息序列与所述音素信息序列在整词级别的对齐信息,包括:
11、获取所述字素信息序列中的每个字素信息所对应的整词在所述训练文本中的位置信息,以得到第一位置信息序列,并获取所述音素信息序列中的每个音素信息所对应的整词在所述训练文本中的位置信息,以得到第二位置信息序列;
12、将所述第一位置信息序列和所述第二位置信息序列,确定为所述字素信息序列与所述音素信息序列在整词级别的对齐信息。
13、可选的,所述结合所述对齐信息,在整词级别对所述字素信息序列与所述音素信息序列进行混合处理,包括:
14、以所述对齐信息为依据,随机生成第一掩码;
15、基于所述第一掩码,在整词级别对所述字素信息序列与所述音素信息序列进行混合处理,其中,所述第一掩码用于决定所述字素信息序列中的字素信息与所述音素信息序列中的音素信息的组合方式。
16、可选的,所述预训练方法还包括:
17、获取所述训练文本对应的标点信息序列,其中,所述标点信息序列包含所述训练文本在整词级别的标点信息;
18、所述基于所述混合信息序列,对初始的语言模型进行训练,包括:
19、基于所述混合信息序列和所述标点信息序列,对初始的语言模型进行训练。
20、可选的,所述获取所述训练文本对应的标点信息序列,包括:
21、获取对所述训练文本进行子词粒度的切分所得到子词序列中每个子词的标点信息,其中,一子词的标点信息为该子词所属整词的标点信息;
22、将所述子词序列中每个子词的标点信息映射为表征该标点信息在词典中的位置的标识,得到所述子词序列中每个子词对应的标点标识,其中,所述词典中包括若干标点信息;
23、将由所述子词序列中各子词分别对应的标点标识组成的序列,确定为所述训练文本对应的标点信息序列。
24、可选的,所述基于所述混合信息序列和所述标点信息序列,对初始的语言模型进行训练,包括:
25、在整词级别分别对所述混合信息序列中的部分信息和所述标点信息序列中的部分信息进行屏蔽处理,屏蔽处理后的混合信息序列作为第一目标信息序列;
26、对屏蔽处理后的标点信息序列中缺失的指示无标点的标点信息进行恢复处理,恢复处理后的标点信息序列作为第二目标信息序列;
27、利用所述第一目标信息序列和所述第二目标信息序列,对初始的语言模型进行训练。
28、可选的,所述在整词级别分别对所述混合信息序列中的部分信息和所述标点信息序列中的部分信息进行屏蔽处理,包括:
29、以所述对齐信息为依据,随机生成第二掩码;
30、基于所述第二掩码,在整词级别对所述混合信息序列中的部分信息进行屏蔽处理,并基于所述第二掩码,在整词级别对所述标点信息序列中的部分信息进行屏蔽处理。
31、可选的,所述利用所述第一目标信息序列和所述第二目标信息序列,对初始的语言模型进行训练,包括:
32、获取所述第一目标信息序列的表示向量以及所述第二目标信息序列的表示向量;
33、将所述第一目标信息序列的表示向量与所述第二目标信息序列的表示向量融合后输入所述初始的语言模型进行编码,得到编码结果;
34、以所述编码结果为依据,对所述第一目标信息序列中缺失的信息进行预测,得到第一预测结果,并以所述编码结果为依据,对所述第二目标信息序列中缺失的信息进行预测,得到第二预测结果;
35、基于所述第一预测结果和所述第二预测结果,对初始的语言模型进行参数更新。
36、可选的,所述基于所述第一预测结果和所述第二预测结果,对初始的语言模型进行参数更新,包括:
37、基于所述第一预测结果以及所述第一目标信息序列中缺失的实际信息,确定第一预测损失;
38、基于所述第二预测结果以及所述第二目标信息序列中缺失的实际信息,确定第二预测损失;
39、将所述第一预测损失与所述第二预测损失融合,得到融合后损失;
40、基于所述融合后损失,对初始的语言模型进行参数更新。
41、一种语音合成模型的获取方法,包括:
42、采用上述任一项所述的预训练方法对初始的语言模型进行预训练,得到预训练后的语言模型;
43、将所述预训练后的语言模型作为编码器,构建包括所述编码器和解码器模型,作为初始的语音合成模型;
44、采用语音合成任务的训练数据,对初始的语音合成模型进行训练,得到最终的语音合成模型。
45、一种语音合成方法,包括:
46、获取目标文本;
47、基于语音合成模型,合成所述目标文本对应的语音,其中,所述语音合成模型采用上述的语音合成模型的获取方法获得。
48、一种预训练装置,包括:第一信息获取模块、信息处理模块和模型训练模块;
49、所述第一信息获取模块,用于获取训练文本对应的字素信息序列和音素信息序列,以及所述字素信息序列与所述音素信息序列在整词级别的对齐信息,其中,所述字素信息序列中的每个字素信息为对所述训练文本进行分词得到一分词单元的信息,所述音素信息序列中的每个音素信息为所述训练文本中一整词的音素信息;
50、所述信息处理模块,用于结合所述对齐信息,在整词级别对所述字素信息序列与所述音素信息序列进行混合处理,得到混合信息序列,其中,在进行混合处理时,针对同一整词,只保留字素信息和音素信息中的一种信息;
51、所述模型训练模块,用于基于所述混合信息序列,对初始的语言模型进行训练。
52、可选的,所述预训练装置还包括:第二信息获取模块;
53、所述第二信息获取模块,用于获取所述训练文本对应的标点信息序列,其中,所述标点信息序列包含所述训练文本在整词级别的标点信息;
54、所述模型训练模块在基于所述混合信息序列,对初始的语言模型进行训练时,具体用于基于所述混合信息序列和所述标点信息序列,对初始的语言模型进行训练。
55、一种处理设备,包括:存储器和处理器;
56、所述存储器,用于存储程序;
57、所述处理器,用于执行所述程序,实现上述任一项所述的预训练方法的各个步骤,和/或,实现上述的语音合成模型的获取方法的各个步骤,和/或,实现上述的语音合成方法的各个步骤。
58、一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述任一项所述的预训练方法的各个步骤,和/或,实现上述的语音合成模型的获取方法的各个步骤,和/或,实现上述的语音合成方法的各个步骤。
59、本发明提供的预训练方法,首先获取训练文本对应的字素信息序列和音素信息序列,以及字素信息序列与音素信息序列在整词级别的对齐信息,然后结合对齐信息,在整词级别对字素信息序列与音素信息序列进行混合处理,得到包含字素信息和音素信息的混合信息序列,最后基于混合信息序列,对初始的语言模型进行训练。基于音素信息对语言模型进行预训练,语言模型能够学习到发音信息,基于字素信息对语言模型进行预训练,语言模型能够学习到语义信息,由于本发明基于混合有字素信息和音素信息的混合信息序列对语言模型进行预训练,因此,通过训练,语言模型既能够学习到发音信息,又能够学习到语义信息,这使得最终训练得到的语言模型具有较好的表示能力。
60、在本发明提供的预训练方法的基础上,还提供了一种语音合成模型的获取方法,该方法首先采用本发明提供的预训练方法对初始的语言模型进行预训练,然后将预训练后的语言模型作为编码器,构建包括编码器和解码器的模型,最后采用语音合成任务的训练数据,对构建的模型进行训练,从而得到最终的语音合成模型,由于语音合成模型中的编码器采用本发明提供的预训练方法预训练得到,因此其具有较好的表示能力,进而语音合成模型具有较好的性能。在本发明提供的语音合成模型的获取方法的基础上,本发明还提供了一种语音合成方法,由于该方法采用本发明提供的语音合成模型的获取方法获取的语音合成模型合成目标文本对应的语音,因此可获得质量较好的合成语音。
- 还没有人留言评论。精彩留言会获得点赞!