一种针对长尾目标的语音鉴伪模型的训练方法及装置与流程
本公开涉及神经网络,具体而言,涉及一种针对长尾目标的语音鉴伪模型的训练方法及装置。
背景技术:
1、语音鉴伪任务在实际应用中,基于深度学习的分类模型会遇到长尾分布问题导致不佳。这是因为长尾分布数据集的头部少数类占据了大多数数据,而尾部多数类却占据了很少的一部分数据,深度学习模型在处理长尾分布数据集时会偏向头部类。长尾目标识别分类的难点主要包括:长尾分布的数据集,整体不均衡;深度学习模型的损失由头部类主导,使分类超平面严重偏离尾部类;尾部类数据太少,类内多样性太低。
2、当前解决长尾分布的方法主要有:重采样,构造出平衡的数据集;重加权,在损失函数中给小的类别分配大的权重;迁移学习,分别对头部类和尾部类建模,将学到的头部类的信息、表示、知识迁移给少数类使用;解耦特征学习和分类器学习,把不平衡学习分为两个阶段,在特征学习阶段正常采样,在分类器学习阶段平衡采样,以此来克服类别重新平衡方法的缺点;模型融合或集成学习等方法。但是,现有解决长尾目标识别方法,均存在一定的局限性对尾部的少量数据往往进行反复学习,缺少足够多的样本差异,不够鲁棒,而头部拥有足够差异的大量数据又往往得不到充分学习;重加权主要体现在分类的损失函数,但修改损失函数大多不能满足损失函数在降到最低时,错误率也要达到最小的需求。
技术实现思路
1、本公开实施例至少提供一种针对长尾目标的语音鉴伪模型的训练方法及装置,可以解决长尾识别任务中数据不平衡问题和少样本问题,提升实际场景中语音鉴伪模型的泛化性能。
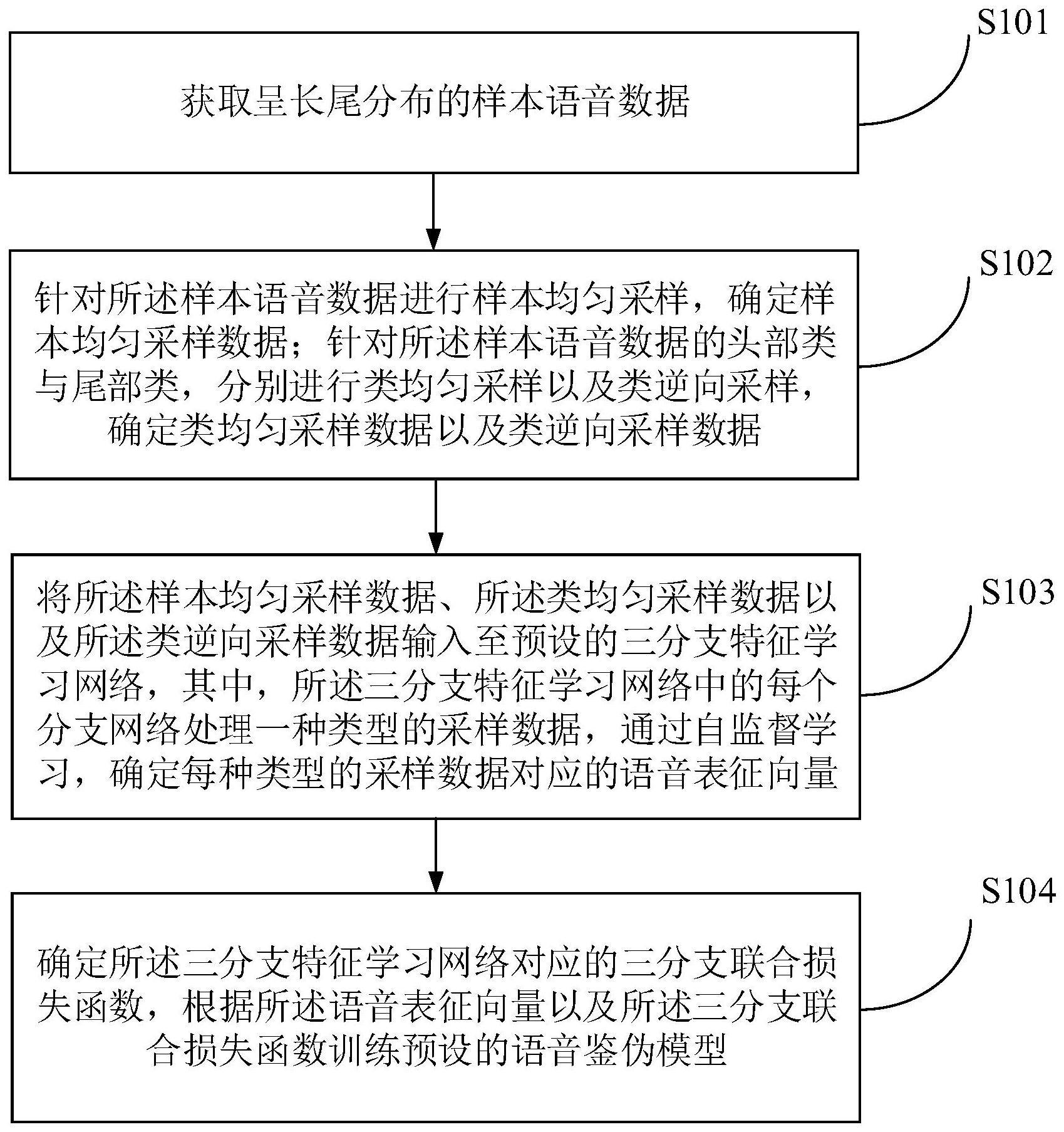
2、本公开实施例提供了一种针对长尾目标的语音鉴伪模型的训练方法,包括:
3、获取呈长尾分布的样本语音数据;
4、针对所述样本语音数据进行样本均匀采样,确定样本均匀采样数据;针对所述样本语音数据的头部类与尾部类,分别进行类均匀采样以及类逆向采样,确定类均匀采样数据以及类逆向采样数据;
5、将所述样本均匀采样数据、所述类均匀采样数据以及所述类逆向采样数据输入至预设的三分支特征学习网络,其中,所述三分支特征学习网络中的每个分支网络处理一种类型的采样数据,通过自监督学习,确定每种类型的采样数据对应的语音表征向量;
6、确定所述三分支特征学习网络对应的三分支联合损失函数,根据所述语音表征向量以及所述三分支联合损失函数训练预设的语音鉴伪模型。
7、一种可选的实施方式中,基于以下步骤采样所述类均匀采样数据:
8、在每个训练周期中,以相同的预设第一采样概率选取样本语音数据的头部类或尾部类;
9、在选定的类别中,抽取所述样本语音数据作为所述类均匀采样数据。
10、一种可选的实施方式中,基于以下步骤采样所述类均匀采样数据:
11、确定所述样本语音数据中,处于头部类或尾部类的样本数据量;
12、针对头部类或尾部类的所述样本语音数据,根据对应的所述样本数据量进行反向加权,确定头部类或尾部类的样本数据对应的逆向采样概率;
13、根据预设第二采样概率选取样本语音数据的头部类或尾部类,在选定的类别中,抽取所述样本语音数据作为所述类逆向采样数据。
14、一种可选的实施方式中,在所述三分支特征学习网络中的每个分支网络中,提供依次连接的自监督学习模型、归一化和高斯误差线性单元激活函数层、前馈网络层、长短时记忆网络、自注意网络以及全连接层,其中,所述前馈网络层还跳转连接至所述自注意网络。
15、一种可选的实施方式中,所述将所述样本均匀采样数据、所述类均匀采样数据以及所述类逆向采样数据输入至预设的三分支特征学习网络,其中,所述三分支特征学习网络中的每个分支网络处理一种类型的采样数据,通过自监督学习,确定每种类型的采样数据对应的语音表征向量,具体包括:
16、所述采样数据在经过所述自监督学习模型的预训练后,确定所述采样数据对应的所述语音表征向量;
17、在所述自监督学习模型的transformer编码器网络层的输出,通过所述归一化和高斯误差线性单元激活函数层,进行输出规整;
18、在所述归一化和高斯误差线性单元激活函数层之后,采用前馈网络层针对所述语音表征向量进行向量降维;
19、所述语音表征向量在经过前馈网络层的降维后,输入至所述长短时记忆网络进行声音特征提取,并同时输入至所述自注意网络;
20、通过所述自注意网络,采用自注意力池化机制抓取所述语音表征向量的局部特征;
21、由所述全连接层作为所述分支网络的输出,将所述分支网络输出的向量维度转换为与所述语音鉴伪模型的输入维度一致。
22、一种可选的实施方式中,所述确定所述三分支特征学习网络对应的三分支联合损失函数,具体包括:
23、确定针对所述样本均匀采样数据进行处理的分支网络对应的样本均匀采样损失函数;
24、确定针对所述类均匀采样数据进行处理的分支网络对应的类均匀采样损失函数;
25、确定针对所述类逆向采样数据进行处理的分支网络对应的类逆向采样损失函数;
26、分别为所述样本均匀采样损失函数、所述类均匀采样损失函数以及所述类逆向采样损失函数配置对应的优化学习超参数;
27、根据所述优化学习超参数,针对所述样本均匀采样损失函数、所述类均匀采样损失函数以及所述类逆向采样损失函数加权求和,确定所述三分支联合损失函数。
28、一种可选的实施方式中,所述三分支联合损失函数采用大边界softmax损失函数。
29、本公开实施例还提供一种针对长尾目标的语音鉴伪模型的训练装置,所述装置包括:
30、获取模块,用于获取呈长尾分布的样本语音数据;
31、采样模块,用于针对所述样本语音数据进行样本均匀采样,确定样本均匀采样数据;针对所述样本语音数据的头部类与尾部类,分别进行类均匀采样以及类逆向采样,确定类均匀采样数据以及类逆向采样数据;
32、特征学习模块,用于将所述样本均匀采样数据、所述类均匀采样数据以及所述类逆向采样数据输入至预设的三分支特征学习网络,其中,所述三分支特征学习网络中的每个分支网络处理一种类型的采样数据,通过自监督学习,确定每种类型的采样数据对应的语音表征向量;
33、鉴伪分类学习模块,用于确定所述三分支特征学习网络对应的三分支联合损失函数,根据所述语音表征向量以及所述三分支联合损失函数训练预设的语音鉴伪模型。
34、本公开实施例还提供一种电子设备,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当电子设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行上述语音鉴伪模型的训练方法,或上述语音鉴伪模型的训练方法中任一种可能的实施方式中的步骤。
35、本公开实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述语音鉴伪模型的训练方法,或上述语音鉴伪模型的训练方法中任一种可能的实施方式中的步骤。
36、本公开实施例还提供一种计算机程序产品,包括计算机程序/指令,该计算机程序、指令被处理器执行时实现上述语音鉴伪模型的训练方法,或上述语音鉴伪模型的训练方法中任一种可能的实施方式中的步骤。
37、本公开实施例提供的一种针对长尾目标的语音鉴伪模型的训练方法及装置,通过获取呈长尾分布的样本语音数据;针对样本语音数据进行样本均匀采样,确定样本均匀采样数据;针对样本语音数据的头部类与尾部类,分别进行类均匀采样以及类逆向采样,确定类均匀采样数据以及类逆向采样数据;将样本均匀采样数据、类均匀采样数据以及类逆向采样数据输入至预设的三分支特征学习网络,其中,三分支特征学习网络中的每个分支网络处理一种类型的采样数据,通过自监督学习,确定每种类型的采样数据对应的语音表征向量;确定三分支特征学习网络对应的三分支联合损失函数,根据语音表征向量以及三分支联合损失函数训练预设的语音鉴伪模型。可以解决长尾识别任务中数据不平衡问题和少样本问题,提升实际场景中语音鉴伪模型的泛化性能。
38、为使本公开的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!