一种音频处理方法、装置以及存储介质与流程
本技术涉及信号处理,特别涉及一种音频处理方法、装置以及存储介质。
背景技术:
1、随着电子设备的快速发展,微型扬声器在智能手机、物联网终端等便携式电子设备中得到了广泛的应用。然而微型扬声器在播放包含钢琴声的音乐时,有时会发出“沙沙”声,通常将该“沙沙”声称为“钢琴杂音”。
2、传统的钢琴杂音抑制算法通常采用静态eq(equalizer,均衡器)或者mbdrc(multiband dynamic range control,多频带动态范围控制)的方式压制特定频点或频带,以消除钢琴杂音。这种方法虽能抑制钢琴杂音,但是会让音乐整体声音变闷,对音效影响较大,不利于听觉感受。
技术实现思路
1、本技术实施例提供了一种音频处理方法、装置以及存储介质,以解决现有技术中钢琴杂音抑制算法会让音乐整体声音变闷,影响听感的问题。
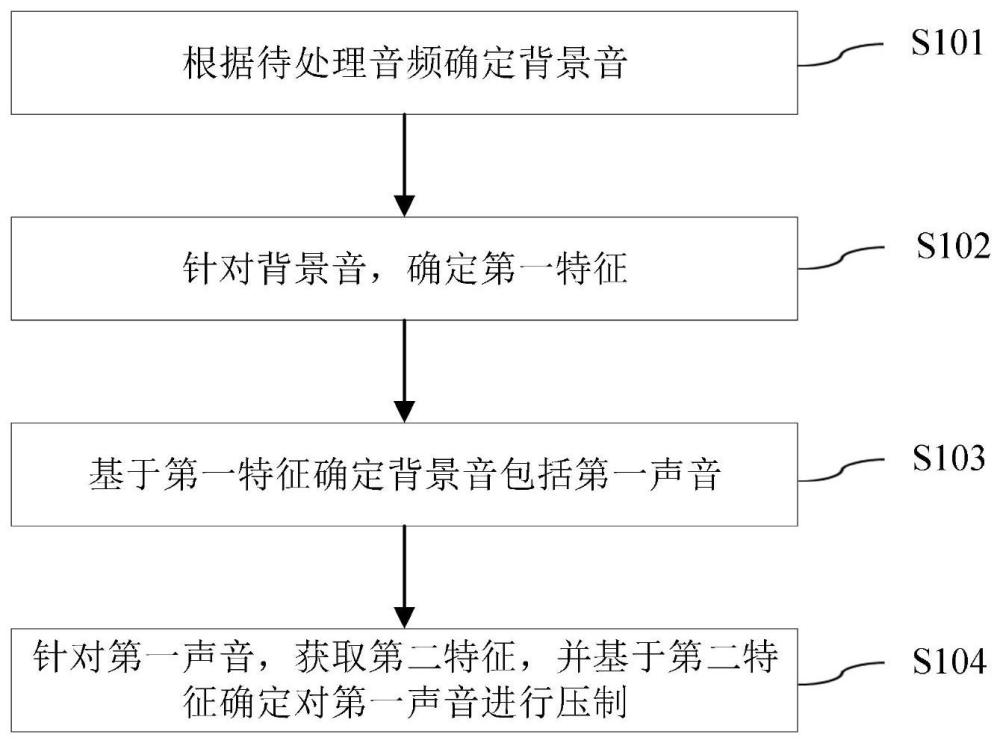
2、第一方面,本技术实施例提供了一种音频处理方法,包括:
3、根据待处理音频确定背景音;
4、针对背景音,确定第一特征,第一特征包括背景音的频域特征和时域特征中的至少一种;
5、基于第一特征确定背景音包括第一声音;
6、针对第一声音,获取第二特征,并基于第二特征对第一声音进行压制,第二特征能够表征第一声音的能量。
7、具体地,待处理音频可以为乐曲等音频,其中可包含人声或非人声(背景音),第一声音可以为钢琴音等因能量较大而易于使扬声器产生杂音的音频。
8、本方案首先对待处理音频中的人声和背景音进行识别区分,从而准确避免了对歌曲中的人声进行误压;其次对识别出来的背景音再次进行第一声音(例如钢琴音)的识别,若背景音包括第一声音,则进一步确定第一声音的能量特征(比如该钢琴音频的振幅等特征),当第一声音的能量特征满足预设条件时,对该音频信号进行压制,否则,直接输出该音频信号。通过上述方案,可在极大程度上提高对人声和其他不产生杂音片段的误压情况,从而改善音乐压制后的听感。
9、在上述第一方面的一种可能的实现中,基于第一特征确定背景音包括第一声音,包括:
10、获取第一预测模型,第一预测模型是基于多个预设音频的目标特征获取的用于识别第一声音的模型;
11、基于第一预测模型和背景音的第一特征,获取背景音的预测值;
12、基于背景音的预测值确定背景音包括第一声音。
13、具体地,多个预设音频包括若干第一声音,预设音频的目标特征与背景音的第一特征的类型相同,比如当第一特征为时域特征中的短时能量特征时,预设音频的目标特征也相应地表征为预设音频的短时能量特征。
14、基于预设音频的目标特征得到用于识别第一声音的第一预测模型,并将背景音的第一特征代入第一预测模型中以获取背景音的预测值,再根据背景音的预测值判断背景音是否包括第一声音,该过程将对于第一声音的特征识别转换为通过数值比较进行,进一步简化了第一声音的识别过程,提高了识别效率。
15、在上述第一方面的一种可能的实现中,基于背景音的预测值确定背景音包括第一声音,包括:
16、对背景音的预测值进行归一化处理;
17、根据归一化处理后的背景音的预测值在第一阈值范围内,确定背景音包括第一声音。
18、具体地,归一化处理可以包括min-max归一化、z-score 0均值归一化等处理方法,通过归一化处理可以将背景音的预测值限制在预期的数值范围内,便于后续数据处理的方便,进一步提高识别效率。
19、在上述第一方面的一种可能的实现中,对背景音的预测值进行归一化处理,包括:
20、确定第一预设音频集;
21、基于第一预测模型和第一预设音频集,获取第一参考预测值和第二参考预测值,其中,第二参考预测值小于第一参考预测值;
22、确定背景音的预测值与第二参考预测值的差值作为第一差值;
23、确定第一参考预测值与第二参考预测值的差值作为第二差值;
24、确定第一差值和第二差值的比值,作为归一化处理后的背景音的预测值。
25、具体地,该第一预设音频集中包含若干不同第一特征的第一声音,特别地,该第一预设音频集被预期包含了通常音频中最大第一特征的第一声音以及通常音频中最小第一特征的第一声音。将第一预设音频集中的各个音频代入第一预测模型,分别获取第一预设音频集中各音频对应的预测值,然后从中确定最大预测值和最小预测值,其中,最大预测值对应通常音频中第一特征最为显著的音频的预测值经第一预测模型处理后的数据值,最小预测值对应通常音频中第一特征最小的音频的预测值经第一预测模型处理后的数据值。而后采用min-max归一化处理,即根据获取的最大预测值和最小预测值对待处理音频的背景音的预测值进行归一化,获取归一化处理后的背景音的预测值。由于第一特征可作为判断背景音是否为第一声音的依据,因此通过对背景音的第一特征相关的预测值做min-max归一化处理,能够在保证第一特征可识别性的基础上,提高识别的效率。
26、在上述第一方面的一种可能的实现中,第一预测模型基于支持向量机算法获取。
27、具体的,多个预设音频构成训练集,支持向量机算法基于该训练集获取第一预测模型。进一步的,多个预设音频包括若干第一特征不同的第一声音和若干第一特征不同的非第一声音和非人声(例如当第一声音为钢琴音时,非第一声音和非人声可以包含鼓音、萧音、古筝音、吉他音等等非钢琴乐器音)。即,该训练集被预期包含了各种乐器的音频,以便于支持向量机算法从中获得用于识别第一声音的第一预测模型。
28、在上述第一方面的一种可能的实现中,针对第一声音,确定第二特征,并基于第二特征对第一声音进行压制,包括:
29、获取第一参考幅值、第二参考幅值以及第一声音的幅值,第二特征为第一声音的幅值;
30、获取第一声音的幅值与第二参考幅值的差值和第一参考幅值与第二参考幅值的差值的比值;
31、获取目标值,并确定比值与目标值的大小;
32、当比值大于目标值,对第一声音压制后输出;
33、当比值小于或等于目标值,直接输出第一声音。
34、对幅值较大的第一声音进行压制,能够有效避免因第一声音能量较高而带来的噪音。进一步的,针对比值大于目标值的第一声音,还可以根据其比值的大小确定压制程度。即,通过幅值检测算法实时检测钢琴音的幅值,并根据钢琴音的幅值比例(即比值)进行压制,幅值比例越大则压制越多,幅值比例越小则压制越小。这样可以使得在有效消除钢琴杂音的同时,减小了对其他非钢琴杂音音效的影响
35、在上述第一方面的一种可能的实现中,获取第一参考幅值、第二参考幅值,包括:
36、确定第二预设音频集;
37、获取第二预设音频集中各音频的幅值;
38、确定上一步骤的各幅值中的最大值和最小值,分别作为第一参考幅值和第二参考幅值。
39、具体的,该第二预设音频集中包含若干不同能量(比如不同音量)的第一声音,特别地,该第二预设音频集被预期包含了通常音频中最大能量的第一声音以及通常音频中最小能量的第一声音。进一步的,第二预设音频集可以与第一预设音频集包含完全相同的各第一声音,也可以包含部分相同的第一声音,或者还可以包含完全不同的第一声音。
40、获取第二预设音频集中的各个音频的幅值(即振幅),然后从中确定最大值和最小值分别作为第一参考幅值和第二参考幅值,其中,第一参考幅值对应通常音频中能量最大的第一声音的幅值,第二参考幅值对应通常音频中能量最小的第一声音的幅值。而后采用min-max归一化处理,即根据获取的最大值和最小值对待处理音频的第一声音的幅值进行归一化,获取第一声音的目标值。由于幅值可作为判断第一声音能量的依据,通过对第一声音的幅值做min-max归一化处理,能够在保证幅值可识别性的基础上,提高对能量较高的第一声音的识别效率。
41、在上述第一方面的一种可能的实现中,根据待处理音频确定背景音,包括:基于神经网络模型确定待处理音频是否为背景音。
42、在上述第一方面的一种可能的实现中,神经网络模型为长短时记忆网络模型。
43、在上述第一方面的一种可能的实现中,第一声音为钢琴音。
44、第二方面,本技术实施例提供了一种音频处理装置,包括:
45、背景音确定模块,用于根据待处理音频确定背景音;
46、第一获取模块,用于获取背景音的第一特征,第一特征包括背景音的频域特征和时域特征中的至少一种;
47、第一声音确定模块,用于基于第一特征确定背景音包括第一声音;
48、第二获取模块,用于针对第一声音,获取第二特征,第二特征能够表征第一声音的能量;
49、压制模块,用于基于第二特征对第一声音进行压制。
50、本方案首先对待处理音频中的人声和背景音进行识别区分,从而准确避免了对歌曲中的人声进行误压;其次对识别出来的背景音再次进行第一声音(例如钢琴音)的识别,若背景音包括第一声音,则进一步确定第一声音的能量特征(比如该钢琴音频的振幅等特征),当第一声音的能量特征满足预设条件时,对该音频信号进行压制,否则,直接输出该音频信号。通过上述方案,可在极大程度上提高对人声和其他不产生杂音片段的误压情况,从而改善音乐压制后的听感。
51、在上述第二方面的一种可能的实现中,第一声音确定模块包括:
52、模型获取子模块,用于获取第一预测模型,第一预测模型是基于多个预设音频的目标特征获取的用于识别第一声音的模型;
53、预测值获取子模块,用于基于第一预测模型和背景音的第一特征,获取背景音的预测值;
54、第一确定子模块,用于基于背景音的预测值确定背景音包括第一声音。
55、具体地,多个预设音频包括多个第一声音,预设音频的目标特征与背景音的第一特征的类型相同,比如当第一特征为时域特征中的短时能量特征时,预设音频的目标特征也相应地表征为预设音频的短时能量特征。
56、基于预设音频的目标特征得到用于识别第一声音的第一预测模型,并将背景音的第一特征代入第一预测模型中以获取背景音的预测值,再根据背景音的预测值判断背景音是否包括第一声音,该过程将对于第一声音的特征识别转换为通过数值比较进行,进一步简化了第一声音的识别过程,提高了识别效率。
57、在上述第二方面的一种可能的实现中,基于背景音的预测值确定背景音包括第一声音,包括:
58、对背景音的预测值进行归一化处理;
59、根据归一化处理后的背景音的预测值在第一阈值范围内,确定背景音包括第一声音。
60、具体地,归一化处理可以包括min-max归一化、z-score 0均值归一化等处理方法,通过归一化处理可以将背景音的预测值限制在预期的数值范围内,便于后续数据处理的方便,进一步提高识别效率。
61、在上述第二方面的一种可能的实现中,对背景音的预测值进行归一化处理,包括:
62、确定第一预设音频集;
63、基于第一预测模型和第一预设音频集,获取第一参考预测值和第二参考预测值,其中,第二参考预测值小于第一参考预测值;
64、确定背景音的预测值与第二参考预测值的差值作为第一差值;
65、确定第一参考预测值与第二参考预测值的差值作为第二差值;
66、确定第一差值和第二差值的比值,作为归一化处理后的背景音的预测值。
67、具体地,第一预设音频集中包括若干第一特征不同的第一声音和若干第一特征不同的非第一声音和非人声(例如当第一声音为钢琴音时,非第一声音和非人声可以包含鼓音、萧音、古筝音、吉他音等等非钢琴乐器音)。即,该第一预设音频集被预期包含了各种乐器的音频。将第一预设音频集中的各个音频代入第一预测模型,分别获取第一预设音频集中各音频对应的预测值,然后从中确定最大预测值和最小预测值,其中,最大预测值对应通常音频中第一特征最为显著的音频的预测值经第一预测模型处理后的数据值,最小预测值对应通常音频中第一特征最小的音频的预测值经第一预测模型处理后的数据值。而后采用min-max归一化处理,即根据获取的最大预测值和最小预测值对待处理音频的背景音的预测值进行归一化,获取归一化处理后的背景音的预测值。由于第一特征可作为判断背景音是否为第一声音的依据,因此通过对背景音的第一特征相关的预测值做min-max归一化处理,能够在保证第一特征可识别性的基础上,提高识别的效率。
68、在上述第二方面的一种可能的实现中,第一预测模型基于支持向量机算法获取。
69、在上述第二方面的一种可能的实现中,基于第二特征对第一声音进行压制,包括:
70、获取第一参考幅值、第二参考幅值以及第一声音的幅值,第二特征为第一声音的幅值;
71、获取第一声音的幅值与第二参考幅值的差值和第一参考幅值与第二参考幅值的差值的比值;
72、获取目标值,并确定比值与目标值的大小;
73、当比值大于目标值,对第一声音压制后输出;
74、当比值小于或等于目标值,直接输出第一声音。
75、对幅值较大的第一声音进行压制,能够有效避免因第一声音能量较高而带来的噪音。进一步的,针对比值大于目标值的第一声音,还可以根据其比值的大小确定压制程度。即,通过幅值检测算法实时检测钢琴音的幅值,并根据钢琴音的幅值比例(即比值)进行压制,幅值比例越大则压制越多,幅值比例越小则压制越小。这样可以使得在有效消除钢琴杂音的同时,减小了对其他非钢琴杂音音效的影响
76、在上述第二方面的一种可能的实现中,获取第一参考幅值、第二参考幅值,包括:
77、确定第二预设音频集;
78、获取第二预设音频集中各音频的幅值;
79、确定上一步骤的各幅值中的最大值和最小值,分别作为第一参考幅值和第二参考幅值。
80、具体的,该第二预设音频集中包含若干不同能量(比如不同音量)的第一声音,特别地,该第二预设音频集被预期包含了通常音频中最大能量的第一声音以及通常音频中最小能量的第一声音。获取第二预设音频集中的各个音频的幅值(即振幅),然后从中确定最大值和最小值分别作为第一参考幅值和第二参考幅值,其中,第一参考幅值对应通常音频中能量最大的第一声音的幅值,第二参考幅值对应通常音频中能量最小的第一声音的幅值。而后采用min-max归一化处理,即根据获取的最大值和最小值对待处理音频的第一声音的幅值进行归一化,获取第一声音的目标值。由于幅值可作为判断第一声音能量的依据,通过对第一声音的幅值做min-max归一化处理,能够在保证幅值可识别性的基础上,提高对能量较高的第一声音的识别效率。
81、在上述第二方面的一种可能的实现中,背景音确定模块用于根据待处理音频确定背景音,包括:背景音确定模块用于基于神经网络模型确定待处理音频是否为背景音。
82、在上述第二方面的一种可能的实现中,神经网络模型为长短时记忆网络模型。
83、第三方面,本技术实施例提供了一种音频处理装置,包括:
84、输入模块,用于接收音频信号;
85、处理器,用于执行上述第一方面的任一种可能的实现中的音频处理方法。
86、第四方面,本技术实施例提供了一种电子设备,包括:存储器和处理器,存储器中存储指令,当处理器加载指令时,处理器执行上述第一方面的任一种可能的实现中的音频处理方法。
87、第五方面,本技术实施例提供了计算机可读存储介质,计算机可读存储介质上存储有指令,该指令在计算机上执行时使得计算机执行上述第一方面的任一种可能的实现中的音频处理方法。
- 还没有人留言评论。精彩留言会获得点赞!