语音识别方法、语音识别模型的训练方法及装置、设备与流程
本公开涉及计算机、语音识别和金融领域,更具体地,涉及一种语音识别方法及装置、电子设备、计算机可读存储介质和计算机程序产品。
背景技术:
1、随着计算机技术的发展,语音识别技术已广泛应用于各种场景。语音识别技术可以指计算机通过对输入的语音信号进行识别和理解,将该语音信号转变为相应的文本或命令的技术。
2、在实现本公开构思的过程中,发明人发现相关技术中至少存在如下问题:由于嘈杂语音场景下背景噪音的影响,容易导致语音识别的识别率较低,因而无法保障语音识别的准确性。
技术实现思路
1、有鉴于此,本公开提供了一种语音识别方法及装置、电子设备、计算机可读存储介质和计算机程序产品。
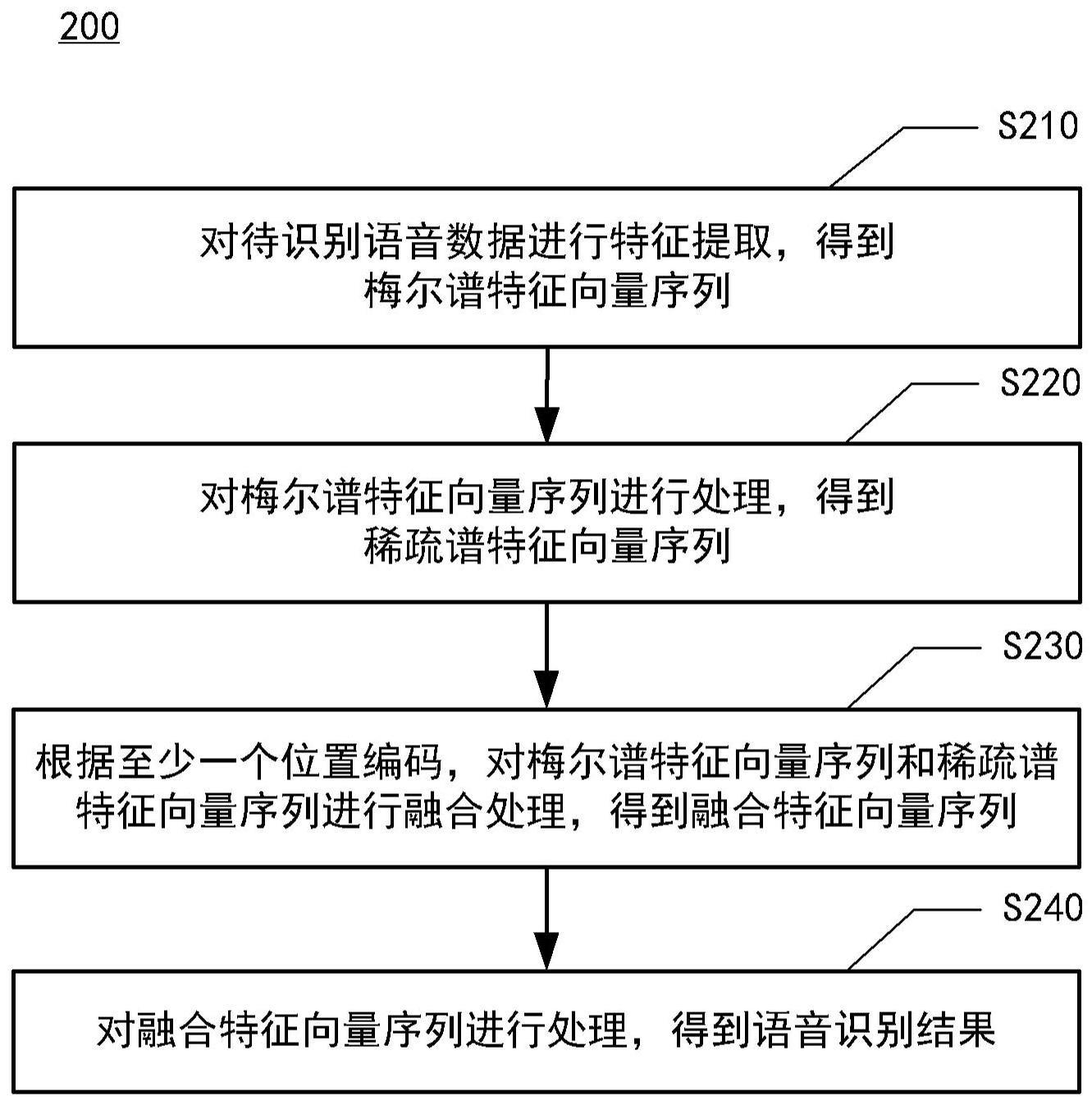
2、根据本公开的一个方面,提供了一种语音识别方法,包括:
3、对待识别语音数据进行特征提取,得到梅尔谱特征向量序列,其中,上述梅尔谱特征向量序列包括至少一个位置编码和与上述至少一个位置编码各自对应的梅尔谱特征向量;
4、对上述梅尔谱特征向量序列进行处理,得到稀疏谱特征向量序列,其中,上述稀疏谱特征向量序列包括上述至少一个位置编码和与上述至少一个位置编码各自对应的稀疏谱特征向量;
5、根据上述至少一个位置编码,对上述梅尔谱特征向量序列和上述稀疏谱特征向量序列进行融合处理,得到融合特征向量序列;以及
6、对上述融合特征向量序列进行处理,得到语音识别结果。
7、根据本公开的实施例,上述根据上述至少一个位置编码,对上述梅尔谱特征向量序列和上述稀疏谱特征向量序列进行融合处理,得到融合特征向量序列包括:
8、针对上述至少一个位置编码中的每个位置编码,
9、确定与上述位置编码对应的目标梅尔谱特征向量和目标稀疏谱特征向量;
10、根据上述目标梅尔谱特征向量,确定第一查询矩阵、第一键矩阵和第一值矩阵;
11、根据上述目标稀疏谱特征向量,确定第二查询矩阵、第二键矩阵和第二值矩阵;以及
12、根据上述第一查询矩阵、上述第一键矩阵、上述第一值矩阵、上述第二查询矩阵、上述第二键矩阵和上述第二值矩阵,确定与上述位置编码对应的融合特征向量。
13、根据本公开的实施例,上述根据上述第一查询矩阵、上述第一键矩阵、上述第一值矩阵、上述第二查询矩阵、上述第二键矩阵和上述第二值矩阵,确定与上述位置编码对应的融合特征向量包括:
14、根据上述第一查询矩阵和上述第二键矩阵,确定第一注意力权重矩阵;
15、根据上述第二查询矩阵和上述第一键矩阵,确定第二注意力权重矩阵;
16、根据上述第一注意力权重矩阵和上述第二值矩阵,得到第一特征向量;
17、根据上述第二注意力权重矩阵和上述第一值矩阵,得到第二特征向量;以及
18、根据上述第一特征向量和上述第二特征向量,得到上述融合特征向量。
19、根据本公开的实施例,上述对上述梅尔谱特征向量序列进行处理,得到稀疏谱特征向量序列包括:
20、根据上述梅尔谱特征向量序列,确定目标字典;
21、针对上述至少一个位置编码中的每个位置编码,
22、根据上述目标字典,对与上述位置编码对应的梅尔谱特征向量进行处理,得到与上述位置编码对应的稀疏谱特征向量;以及
23、根据与每个上述位置编码各自对应的上述稀疏谱特征向量,确定上述稀疏谱特征向量序列。
24、根据本公开的实施例,上述根据上述梅尔谱特征向量序列,确定目标字典包括:
25、根据至少一个上述梅尔谱特征向量,构建字典训练样本集;
26、根据上述字典训练样本集,确定初始字典;以及
27、基于字典学习算法,对上述初始字典进行处理,得到上述目标字典。
28、根据本公开的实施例,上述根据上述目标字典,对与上述位置编码对应的梅尔谱特征向量进行处理,得到与上述位置编码对应的稀疏谱特征向量包括:
29、基于追踪算法,对梅尔谱特征向量进行稀疏表示,得出稀疏编码系数;以及
30、根据上述目标字典和上述稀疏编码系数,确定与上述位置编码对应的上述稀疏谱特征向量。
31、根据本公开的实施例,上述对待识别语音数据进行特征提取,得到梅尔谱特征向量序列包括:
32、对上述待识别语音数据进行预处理,得到梅尔谱序列数据,其中,上述梅尔谱序列数据包括至少一个梅尔谱数据;
33、根据上述梅尔谱序列数据和位置编码序列数据,确定中间编码序列数据,其中,上述位置编码序列数据包括上述至少一个位置编码;以及
34、对上述中间编码序列数据进行特征提取,得到上述梅尔谱特征向量序列。
35、根据本公开的实施例,上述对上述待识别语音数据进行预处理,得到梅尔谱序列数据包括:
36、对上述待识别语音数据进行数据增强处理,得到增强语音数据;
37、对上述增强语音数据进行加窗处理,得到目标语音数据;以及
38、对上述目标语音数据进行特征提取,得到上述梅尔谱序列数据。
39、根据本公开的实施例,上述语音识别方法基于深度学习模型实现,上述深度学习模型包括特征提取层、注意力层和时序分类层,上述方法还包括:
40、将上述待识别语音数据输入至上述特征提取层,得到上述梅尔谱特征向量序列和上述稀疏谱特征向量序列;
41、将上述梅尔谱特征向量序列和上述稀疏谱特征向量序列输入至上述注意力层,得到上述融合特征向量序列;
42、将上述融合特征向量序列输入至上述时序分类层,得到上述语音识别结果。
43、根据本公开的另一个方面,提供了一种语音识别模型的训练方法,包括:
44、对至少一个待识别样本语音数据分别进行特征提取,得到与上述至少一个待识别样本语音数据各自对应的样本梅尔谱特征向量序列,其中,上述样本梅尔谱特征向量序列包括至少一个样本位置编码和与上述至少一个样本位置编码各自对应的样本梅尔谱特征向量,上述至少一个待识别样本语音数据各自对应有真实语音识别结果;
45、对上述与上述至少一个待识别样本语音数据各自对应的样本梅尔谱特征向量序列进行处理,得到与上述至少一个待识别样本语音数据各自对应的样本稀疏谱特征向量序列,其中,上述样本稀疏谱特征向量序列包括上述至少一个样本位置编码和与上述至少一个样本位置编码各自对应的样本稀疏谱特征向量;
46、根据上述至少一个样本位置编码,对与上述至少一个待识别样本语音数据各自对应的上述样本梅尔谱特征向量序列和上述样本稀疏谱特征向量序列分别进行融合处理,得到与上述至少一个待识别样本语音数据各自对应的样本融合特征向量序列;以及
47、利用上述与上述至少一个待识别样本语音数据各自对应的上述真实语音识别结果和上述样本融合特征向量序列,训练深度学习模型,得到语音识别模型。
48、根据本公开的实施例,上述深度学习模型包括注意力层。
49、根据本公开的实施例,上述根据上述至少一个样本位置编码,对与上述至少一个待识别样本语音数据各自对应的上述样本梅尔谱特征向量序列和上述样本稀疏谱特征向量序列分别进行融合处理,得到与上述至少一个待识别样本语音数据各自对应的样本融合特征向量序列包括:
50、将与上述至少一个待识别样本语音数据各自对应的上述样本梅尔谱特征向量序列和上述样本稀疏谱特征向量序列,输入至上述注意力层,得到与上述至少一个待识别样本语音数据各自对应的样本融合特征向量序列。
51、根据本公开的实施例,上述利用上述与上述至少一个待识别样本语音数据各自对应的上述真实语音识别结果和上述样本融合特征向量序列,训练深度学习模型,得到语音识别模型包括:
52、将与上述至少一个待识别样本语音数据各自对应的上述样本融合特征向量序列输入上述深度学习模型,得到与上述至少一个待识别样本语音数据各自对应的样本语音识别结果;
53、根据与上述至少一个待识别样本语音数据各自对应的上述真实语音识别结果和上述样本语音识别结果,得到与上述至少一个待识别样本语音数据各自对应的损失函数值;以及
54、根据与上述至少一个待识别样本语音数据各自对应的上述损失函数值调整上述深度学习模型的模型参数,直至满足预定结束条件,得到上述语音识别模型。
55、根据本公开的实施例,上述深度学习模型还包括时序分类层,上述时序分类层包括第一一维卷积层、第二一维卷积层、最大池化层、全连接层和归一化层。
56、根据本公开的实施例,上述将与上述至少一个待识别样本语音数据各自对应的上述样本融合特征向量序列输入上述深度学习模型,得到与上述至少一个待识别样本语音数据各自对应的样本语音识别结果包括:
57、针对与上述至少一个待识别样本语音数据各自对应的上述样本融合特征向量序列中的每个样本融合特征向量序列,
58、将上述样本融合特征向量序列,输入至上述第一一维卷积层,得到第一中间样本特征向量序列;
59、将上述第一中间样本特征向量序列,输入至上述第二一维卷积层,得到第二中间样本特征向量序列;
60、将上述第二中间样本特征向量序列,输入至上述最大池化层,得到第三中间样本特征向量序列;
61、将上述第三中间样本特征向量序列,输入至上述全连接层,得到第四中间样本特征向量序列;以及
62、将上述第四中间样本特征向量序列,输入至上述归一化层,得到上述样本语音识别结果。
63、根据本公开的另一个方面,提供了一种语音识别装置,包括:
64、第一特征提取模块,用于对待识别语音数据进行特征提取,得到梅尔谱特征向量序列,其中,上述梅尔谱特征向量序列包括至少一个位置编码和与上述至少一个位置编码各自对应的梅尔谱特征向量;
65、第一处理模块,用于对上述梅尔谱特征向量序列进行处理,得到稀疏谱特征向量序列,其中,上述稀疏谱特征向量序列包括上述至少一个位置编码和与上述至少一个位置编码各自对应的稀疏谱特征向量;
66、第一融合处理模块,用于根据上述至少一个位置编码,对上述梅尔谱特征向量序列和上述稀疏谱特征向量序列进行融合处理,得到融合特征向量序列;以及
67、第二处理模块,用于对上述融合特征向量序列进行处理,得到语音识别结果。
68、根据本公开的另一个方面,提供了一种语音识别模型的训练装置,包括:
69、第二特征提取模块,用于对至少一个待识别样本语音数据分别进行特征提取,得到与上述至少一个待识别样本语音数据各自对应的样本梅尔谱特征向量序列,其中,上述样本梅尔谱特征向量序列包括至少一个样本位置编码和与上述至少一个样本位置编码各自对应的样本梅尔谱特征向量,上述至少一个待识别样本语音数据各自对应有真实语音识别结果;
70、第三处理模块,用于对上述与上述至少一个待识别样本语音数据各自对应的样本梅尔谱特征向量序列进行处理,得到与上述至少一个待识别样本语音数据各自对应的样本稀疏谱特征向量序列,其中,上述样本稀疏谱特征向量序列包括上述至少一个样本位置编码和与上述至少一个样本位置编码各自对应的样本稀疏谱特征向量;
71、第二融合处理模块,用于根据上述至少一个样本位置编码,对与上述至少一个待识别样本语音数据各自对应的上述样本梅尔谱特征向量序列和上述样本稀疏谱特征向量序列分别进行融合处理,得到与上述至少一个待识别样本语音数据各自对应的样本融合特征向量序列;以及
72、训练模块,用于利用上述与上述至少一个待识别样本语音数据各自对应的上述真实语音识别结果和上述样本融合特征向量序列,训练深度学习模型,得到语音识别模型。
73、根据本公开的另一个方面,提供了一种电子设备,包括:
74、一个或多个处理器;
75、存储器,用于存储一个或多个指令,
76、其中,当上述一个或多个指令被上述一个或多个处理器执行时,使得上述一个或多个处理器实现如本公开所述的方法。
77、根据本公开的另一个方面,提供了一种计算机可读存储介质,其上存储有可执行指令,上述可执行指令被处理器执行时使处理器实现如本公开所述的方法。
78、根据本公开的另一个方面,提供了一种计算机程序产品,上述计算机程序产品包括计算机可执行指令,上述计算机可执行指令在被执行时用于实现如本公开所述的方法。
79、根据本公开的实施例,由于梅尔谱特征向量序列是通过对待识别语音数据进行特征提取得到的,因而梅尔谱特征向量序列能够用于表征待识别语音数据的梅尔谱特征。由于稀疏谱特征向量序列是通过对梅尔谱特征向量序列进行处理得到的,因而稀疏谱特征向量序列能够用于表征待识别语音数据的稀疏谱特征。在此基础上,通过对梅尔谱特征向量序列和稀疏谱特征向量序列进行融合处理,能够使梅尔谱特征和稀疏谱特征得到相互补充,因而至少部分地克服了相关技术中由于嘈杂语音场景下背景噪音的影响,容易导致语音识别的识别率较低的技术问题,进而提高了语音识别的准确性。
- 还没有人留言评论。精彩留言会获得点赞!