一种基于Fca-Res2Net融合自注意力的说话人识别方法
本发明属于语音信号处理与模式识别领域,特别是一种基于fca-res2net融合自注意力的说话人识别方法。
背景技术:
1、说话人识别,又称声纹识别,是通过语音特征来识别正在讲话的人的过程,在很大程度上取决于发出声音的说话者。说话者之间的差异大多来源于说话风格、声带和声音形式以及在传达特定含义时说话者表达的差异。这些特征被最先进的说话人识别系统应用,在现实生活中多用于安全系统。如用在:信用卡声纹保护、电话银行客户验证、公安取证等。随着各种应用的需求不断增加、说话人识别相关技术的不断成熟,提高系统识别准确率成为了各大研究今年来的热点。
2、说话人识别基本系统框架主要分为特征提取和说话人模型建立。特征提取是提取说话人得语音信号特征向量作为说话人模型的输入,使其能够充分反映出说话者个体差异,提高识别准确率。说话人特征中常见的时域特征包括振幅、能量等。然而这些特征通常是直接通过滤波器从原始语音信号中获得特征向量,虽然处理简单但稳定性差,因此近年来很少使用。常见的变换域特征包括线性预测系数(linear prediction coefficient,lpc)、基于滤波器组的fbank(filter bank,fbank)特征、梅尔频率倒谱mfcc系数等。而由于梅尔滤波器是基于人耳结构构造得一种滤波器,可以更好地拟合人耳接收信号的特性,充分反映出说话者的特征,因此说话人识别系统多用mfcc特征提取方法。
3、随着深度学习的发展,由于其出色的建模能力,基于深度学习的说话人识别方法越来越受到欢迎。深度学习是通过构建隐藏层的模型和训练大量的参数数据,来学习更有用的特征,从而提升分类或识别的准确性。然而浅层网络提取的特征表征能力弱,因此人们致力于用更深的网络提取更深层次的网络参数,然而由于网络层数加深会导致梯度爆炸和梯度消失问题的出现,由gao等人在深度残差网络的基础上提出res2net,该网络结构通过残差块分层连接,可以更好地融合浅层和深层以及不同通道说话人特征信息,在不增加参数计算负载的前提下,获得更强大的特征提取能力。
4、在以前的用于说话人识别的深度学习网络中,不同的特征和通道被赋予相同的权重,所获得的说话人识别模型无法专注于最重要的声纹特征,因此,将注意力机制引入说话人识别逐渐成为热点。通道注意力通过不同的通道直接学习重视权重来强调我们感兴趣区域同时抑制不相关背景区域的机制。传统的通道注意力机制se-net(squeeze andexcitation net)使用标量来表示通道,且使用全局平均池化(global average pooling,gap)只保留最低频率的信息,来自其他频率的所有分量都被丢弃,为了更好地压缩信道并引入更多信息,浙大学者提出了一种新注意力机制方法:频率域通道注意力网络称为fcanet。
5、该专利使用的特征提取方法提取的是单特征信息,无法表征说话者的高频信号和动态特征信息,本发明提出了一种改进的mfcc特征提取方法,将逆梅尔倒谱系数imfcc与mfcc相结合并对二者进行差分运算,融合得到的特征可以充分反映出说话者的特征。该专利使用的模型为resnet34网络,而resnet34已经被证明分类提取性能并没有resnet50的好,而本发明在继承了resnet50优点的基础上提出res2net50,该网络结构通过残差块分层连接,可以更好地融合浅层和深层以及不同通道说话人特征信息,在不增加参数计算负载的前提下,获得更强大的特征提取能力。该专利在主干网络上使用简单的通道注意力模块,只保留了最低频率分量而损失其他频率分量,影响了说话人识别性能,本发明使用了新型的通道注意力网络fca-net,保留了所有通道的所有频率信息,且在最后融合了自注意力机制,在提取说话人空间信息的基础上关注了其全局时序信息,提高了说话人识别性能。
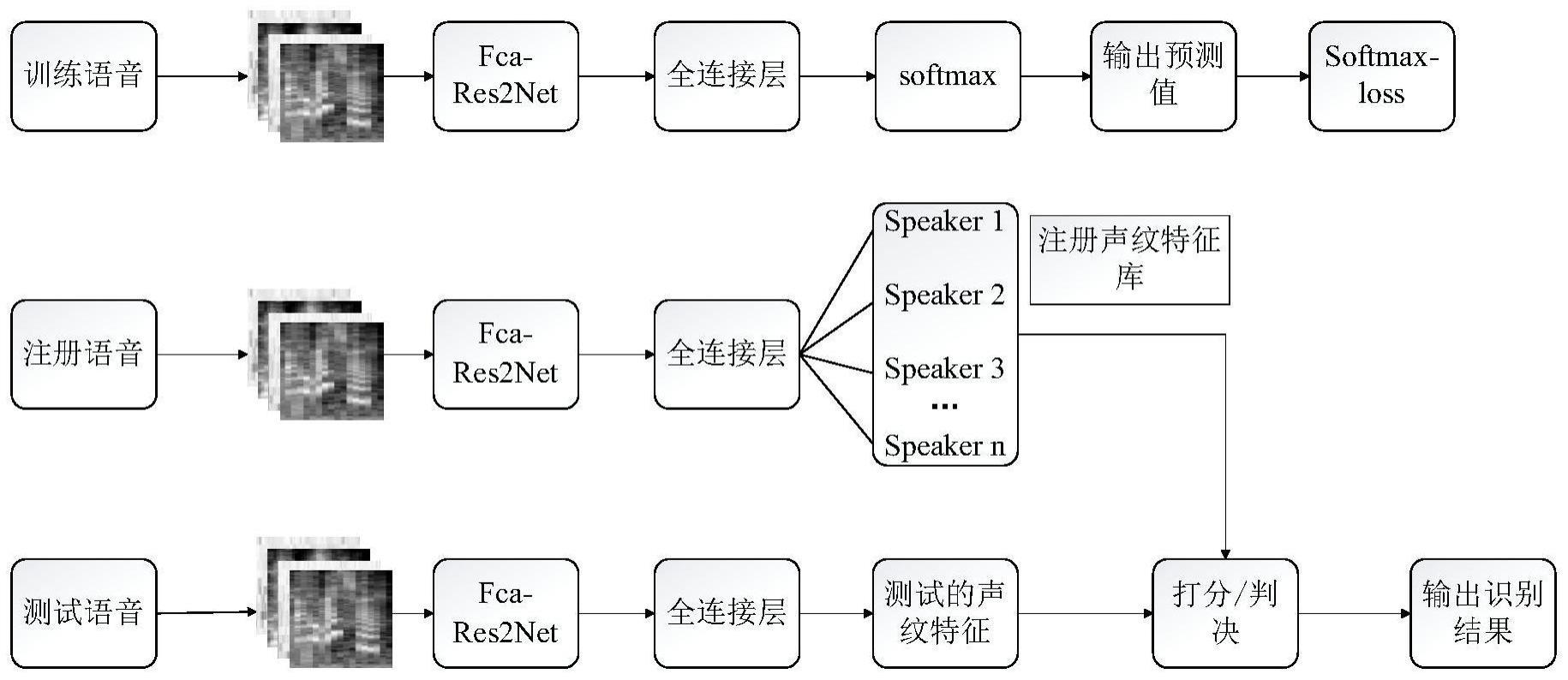
6、本发明将fcanet引入轻量级网络res2net,提出了一种基于fcanet-res2net的说话人识别模型,首先提出了一种改进的mfcc特征提取方法,将逆梅尔倒谱系数imfcc与mfcc相结合;然后设计了一种新的结合注意力机制的说话人识别网络,包括频率域通道注意力和自注意力汇集机制,可以对不同通道信息和段级特征分配相应的权重,提高说话人识别准确率。
技术实现思路
1、本发明旨在解决以上现有技术的问题。提出了一种基于fca-res2net融合自注意力的说话人识别方法。本发明的技术方案如下:
2、一种基于fca-res2net融合自注意力的说话人识别方法,其包括以下步骤:
3、s1、对原始语音信号进行预加重、分帧、加窗预处理,将预处理后的语音信号经过不同滤波器,并分别进行差分运算得到一组水平长度与信号持续时间相关、垂直长度与滤波器组相关的二维对数梅尔谱图;
4、s2、将经过步骤s1处理后的二维对数梅尔谱图用于预训练fca-res2net,fca-res2net即改进的残差网络模型融合频率域通道注意力网络,说话人识别网络提高泛化能力,res2net是由resnet改进而成的,在继承了resnet优点的同时又不增加参数计算量,通过增加感受野的大小来提高卷积神经网络的特征提取能力;
5、s3、通过改进的残差网络res2net融合频率域通道注意力网络fcanet得到融合浅层和深层的说话人特征信息,并用于获取不同特征通道权重信息;
6、s4、提出一种结合自注意力机制的fca-res2net模型,将说话人空间特征与时序特征相结合,捕获长时间跨度的语音特征;
7、s5、在模型训练的过程中,以交叉熵误差函数作为训练目标函数,通过更新参数最小化交叉熵损失,同时通过adam算法进行优化,得到最终网络模型,最后由softmax层进行说话人分类。
8、进一步的,s1:对原始语音信号进行预加重、分帧、加窗等预处理得到三维对数梅尔谱图,具体步骤如下:
9、(1)采用如下式所示高通滤波器提升高频部分:
10、h(z)=1-μz-1 (1)
11、其中,h(z)为z域的传递函数,z表示z域的坐标值,h(z)是传递函数,z域是对离散时间系统的描述,z变换是对采样函数拉式变换的变形,对连续时间系统进行采样,并对采样信号进行处理的空间域称为z域。μ表示预加重系数,预加重后的输出结果为x(n);μ表示预加重系数,预加重后的输出结果为x(n);
12、(2)对预加重后的输出x(n)进行分帧,为了解决分帧后端点处不连续问题,采用汉明窗进行加窗:
13、
14、y(n)表示分帧后的语音信号,w(n,a)表示汉明窗的窗函数,其中a取值0.46,n=0,1,...,n-1,n为帧长,加窗后语音信号为:s(n)=y(n)×w(n);
15、(3)端点检测去除无声片段后,由离散傅里叶变换获得语音信号频域上的能量分布,输出是包含n个频带的复数s(k),表示原始信号中某一频率的幅度和相位,下式所示:
16、
17、(4)根据人耳敏感程度,将频谱划分为多个mel滤波器组和多个逆mel滤波器组,通过m个两个不同滤波器后滤波器后得到频率响应为hm(k),再计算每个滤波器组输出的对数能量:
18、
19、(5)再由差分运算得到对应的一阶差分,将对数频谱及其一阶差分叠加在一起,充分利用语音高低频段动态与静态信息,得到水平长度与信号持续时间相关、垂直长度与滤波器组相关的对数梅尔谱图。
20、进一步的,所述步骤s2将经过步骤s1处理后的二维对数梅尔谱图用于预训练fca-res2net,fca-res2net即改进的残差网络模型融合频率域通道注意力网络,具体包括:
21、(1)卷积块由卷积层、组归一化层gn和线性整流单元relu组成,用于特征的获取;
22、(2)注意力模块使用了新型通道注意力网络fcanet协助res2net在空间和通道方面捕捉精细化特征;
23、(3)结合使用resnet的跳跃残差连接技巧,设计了四个个残差注意力块fca-res2net block来依次学习深层融合浅层特征。
24、进一步的,所述(3)结合使用resnet的跳跃残差连接技巧,设计了四个个残差注意力块fca-res2net block来依次学习深层融合浅层特征,具体包括:
25、将对数梅尔谱图大小调整为300×256×4作为fca-res2net的输入,第一层卷积核大小为7×7,步长为2;最大池化层大小为3×3,步长为2,保留突出部分的显著特征;接下来,每个残差块运算一样,依次连接通道注意力模块fca block,对从残差块中得到的特征进行通道方面全面关注;在第一个残差中,过3个res2net block,步长为1的卷积层。第二个残差块,过4个res2net block,步长为1的卷积层;第三个残差块,过6个res2net block,步长为1的卷积层;第四个残差块,过3个res2net block,步长为1的卷积层;四个残差块的输出通道增加;最后,应用步长为1×2×2的全局平均池化层,对信道的全局特征进行描述。
26、进一步的,所述步骤s3通过改进的残差网络res2net融合频率域通道注意力网络fcanet得到融合浅层和深层的说话人特征信息,并用于获取不同特征通道权重信息,具体为:
27、(1)改进的残差网络res2net利用分通道的类残差跳层连接,通过增加感受野的大小,分层并行的网络结构也增加了模型的接受域、跨通道融合不同分层下的说话人信息;
28、(2)在主干网络res2net-50中加入注意力模块fca-block,将其与res2net-block连接,用来语音信息权重以及抑制输入特征中与说话人特征提取不相关的信息;
29、(3)fca-block是一种基于se-block的新型注意力机制,fca-block使用二维离散余弦变化2d-dct来压缩特征图,保留了其它频率分量;
30、由设计好的fca-res2net网络提取局部-整体、空间-通道特征,丰富说话人特征的表现形式。
31、进一步的,所述步骤s4中设计的结合自注意力机制的fca-res2net模型将说话人空间特征与时序特征相结合,捕获长时间跨度的语音特征,具体步骤如下:
32、(1)对于原始语音片段预处理后,将输入谱图进行分段并行输入fca-res2ne,做多个输出通道;
33、(2)将多个输出拉直、编码后同时送入self-attention块,会得到与整个时间序列相关的长语音特征时间序列,解码后作说话人特征信息,筛选出最具判别性的特征;
34、经过self-attention输出的特征是时间序列中所有样本的加权和,可以看到所有输入的时间样本,根据不同权重关注说话人自己的时间注意点。
35、进一步的,所述self-attention能够捕捉任意长度序列的长期依赖关系,使用来自fca-res2net提取出的特征作为输入,经过编码器得到一系列输入向量,将输入向量分别与矩阵wq、wk、wv做内积得到每个输入的qi、ki、vi,两两输入之间的qi、kj进行内积过softmax函数得到两个输入之间的相似度矩阵将与vi进行内积相加得到每个输入的输出序列;每个输入的qi、ki、vi结合起来形成输入矩阵值q、k、v,则输出矩阵计算如公式(5)所示;
36、
37、其中,其中dk为qi、ki的等长维度,attention即为输出注意力;
38、采用了self-attention,将输出矩阵经过解码器得到最终输出特征值。
39、进一步的,所述步骤s5在模型训练的过程中,采用交叉熵误差函数作为训练目标函数,同时利用adam算法进行优化,最后由softmax层进行情感分类,具体包括:
40、交叉熵算法定义如下:
41、
42、其中,m表示样本的数量,表示第i个样本的真实值,yi表示第i个样本的预测输出值,l表示损失值;
43、adaptive moment estimation(adam,适应性矩估计)算法是将stochasticgradient descent with momentum(sgdm,动量随机梯度下降)算法和root mean squareprop(rmsprop,前向均方根梯度下降)算法结合在一起,最后更新权重后的定义如下:
44、
45、其中,表示经过偏差修正的momentum指数加权平均数,表示经过偏差修正的rmsprop指数加权平均数,α和ε为超参数;
46、softmax函数的公式如下:
47、
48、n表示分类的个数,一共有n个用数值表示的分类sk,k∈(0,n],i表示k中的某个分类,gi表示该分类的值,si表示第i个元素的分类概率。
49、本发明的优点及有益效果如下:
50、本发明提供了一种融合自注意力机制的fca-res2net说话人识别模型,在相同的实验条件下,提出了一种融合自注意力机制的fca-res2net说话人识别模型,能够改善说话人识别模型泛化能力差和说话人特征识别率低的问题。具体步骤:首先,使用改进的梅尔频率倒谱系数(mel-frequency cepstral coefficients,mfcc)作为系统特征输入,将逆梅尔倒谱系数imfcc与mfcc相结合,提取出更具代表性的语音频谱特征并在此基础上融合其差分参数,来充分利用高低频段动态与静态信息,作为fca-res2net说话人网络的输入进行预训练,网络的权重参数被迁移到后续学习过程中进而得到更好的权重初始化结果,减小过拟合发生的可能;其次,在基线模型res2net上引入频率域通道注意力网络;fcanet,利用残差模块融合浅层和深层说话人特征信息,在不增加参数量的前提下更好地获取不同特征通道权重信息;最后,为了更好的引入时序信息,捕获长时间跨度的语音特征,本发明结合自注意力机制(self-attention)来增强语音特性的长跨度建模,最后对分类输出结果进行识别,提高说话人识别准确率。
- 还没有人留言评论。精彩留言会获得点赞!