基于diffusion的语音合成方法、装置、设备、存储介质与流程
本技术涉及人工智能,尤其涉及一种基于diffusion的语音合成方法、装置、设备、存储介质。
背景技术:
1、随着深度学习的不断发展,能够通过基于深度学习的语音合成模型生成与人类语音相似度高的语音信息。基于深度学习的语音合成模型大多由声学模型和声码器两部分构成,声学模型用于将文本信息转换为声学特征信息,声码器用于将声学特征信息生成语音信息。目前的基于深度学习的语音合成模型中的声码器主要使用基于生成对抗网络(generative adversarial networks,gan)的声码器或基于流flow的声码器,基于gan的声码器存在导致语音合成模型训练难以收敛的问题,基于flow的声码器需要的模型参数量较大,使得语音合成模型需要耗费大量的计算资源,导致语音合成模型难以收敛,从而使得语音合成效率较低。
技术实现思路
1、本技术实施例的主要目的在于提出一种基于diffusion的语音合成方法、装置、设备、存储介质,能够有效提高语音合成的效率。
2、为实现上述目的,本技术实施例的第一方面提出了一种基于扩散概率模型的语音合成方法,所述方法包括:
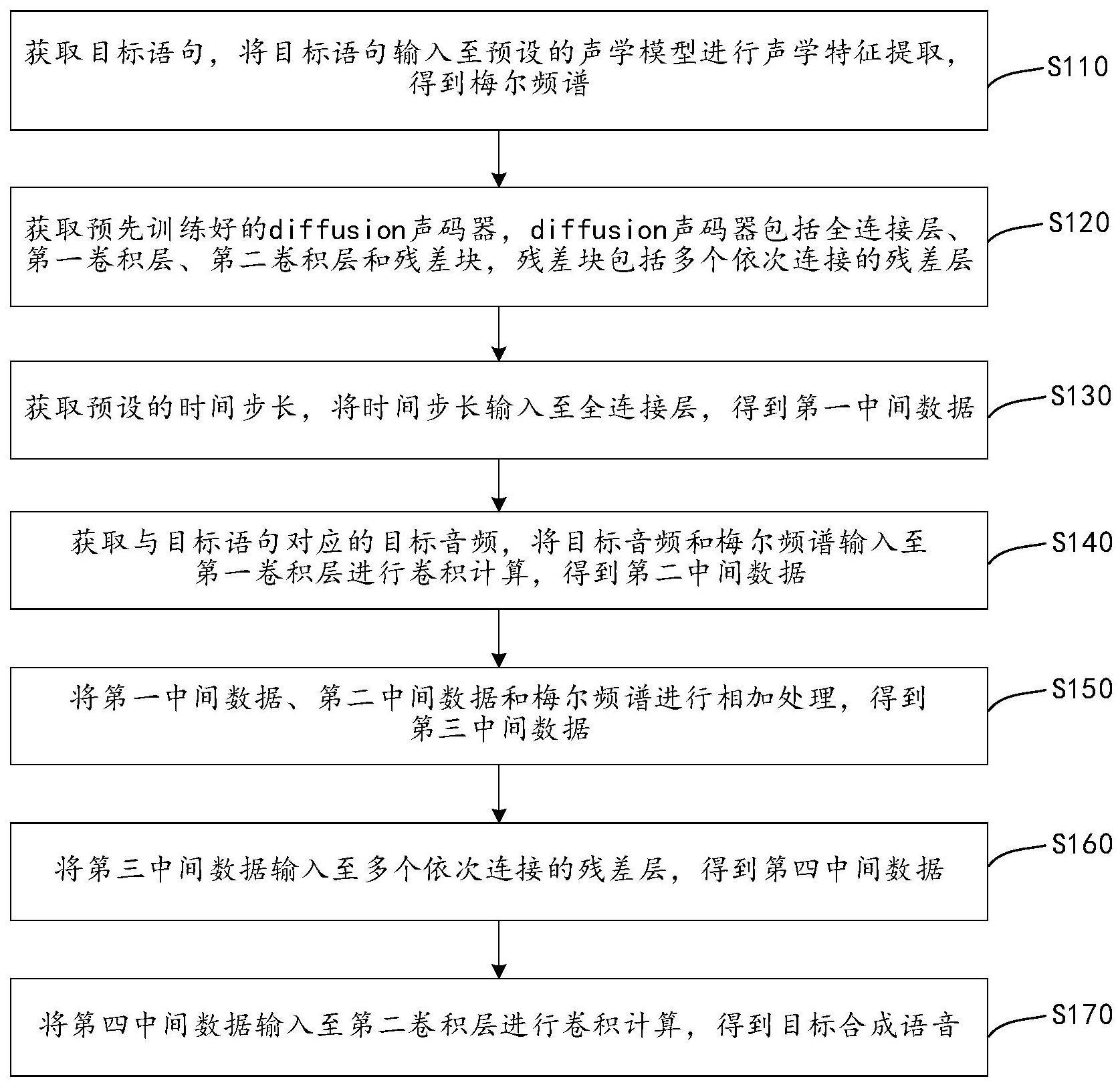
3、获取目标语句,将所述目标语句输入至预设的声学模型进行声学特征提取,得到梅尔频谱;
4、获取预先训练好的diffusion声码器,所述diffusion声码器包括全连接层、第一卷积层、第二卷积层和残差块,所述残差块包括多个依次连接的残差层;
5、获取预设的时间步长,将所述时间步长输入至所述全连接层,得到第一中间数据;
6、获取与所述目标语句对应的目标音频,将所述目标音频和所述梅尔频谱输入至第一卷积层进行卷积计算,得到第二中间数据;
7、将所述第一中间数据、第二中间数据和所述梅尔频谱进行相加处理,得到第三中间数据;
8、将所述第三中间数据输入至多个依次连接的所述残差层,得到第四中间数据;
9、将所述第四中间数据输入至所述第二卷积层进行卷积计算,得到目标合成语音。
10、在一些实施例中,所述目标音频包括初始语音分布信息,所述diffusion声码器通过以下步骤训练得到:
11、获取预设的马尔科夫链;
12、将所述初始语音分布信息和所述梅尔频谱输入至所述马尔科夫链进行数据转换,得到高斯噪声分布信息;
13、将所述高斯噪声分布信息和所述梅尔频谱输入至所述马尔科夫链进行数据转换,得到目标语音分布信息;
14、根据所述目标语音分布信息、所述梅尔频谱和所述时间步长训练所述diffusion声码器。
15、在一些实施例中,所述将所述初始语音分布信息和所述梅尔频谱输入至所述马尔科夫链进行数据转换,得到高斯噪声分布信息,根据以下公式确定:
16、
17、其中,x0为所述初始语音分布信息,mel为所述梅尔频谱,xt为当前时间步长的隐变量,xt为所述高斯噪声分布信息,t为所述时间步长,q(xt|xt-1,mel)根据以下公式确定:
18、
19、其中,βt为常数,i为与所述初始语音分布信息x0对应的第一标准正态分布信息,为所述高斯噪声分布信息的均值,βti为所述高斯噪声分布信息的方差。
20、在一些实施例中,所述将所述高斯噪声分布信息和所述梅尔频谱输入至所述马尔科夫链进行数据转换,得到目标语音分布信息,根据以下公式确定:
21、
22、其中,x0为所述目标语音分布信息,mel为所述梅尔频谱,t为所述时间步长,pθ(xt-1|xt,mel)根据以下公式确定:
23、pθ(xt-1|xt,mel)=n(xt-1;μθ(xt,t);σθ(xt,t)2i);
24、其中,μθ和σθ为预设的待训练模型,t为所述时间步长。
25、在一些实施例中,所述根据所述目标语音分布信息、所述梅尔频谱和所述时间步长训练所述diffusion声码器,包括:
26、获取预设的初始diffusion声码器;
27、根据所述目标语音分布信息、所述梅尔频谱和所述时间步长构建目标损失函数;
28、根据所述目标损失函数对所述初始diffusion声码器进行训练,得到所述diffusion声码器。
29、在一些实施例中,所述目标损失函数根据以下公式确定:
30、
31、其中,mel为所述梅尔频谱,x0为所述目标语音分布信息,ε为与所述目标始语音分布信息x0对应的第二标准正态分布信息,εθ为所述diffusion声码器,t为所述时间步长,和αt根据以下公式确定:
32、
33、αt=1-βt;
34、其中,所述βt为常数。
35、在一些实施例中,各个所述残差层包括第三卷积层、第四卷积层、tanh层和sigmoid层,所述将所述第三中间数据输入至多个依次连接的所述残差层,得到第四中间数据,包括:
36、将所述第三中间数据输入至所述第三卷积层进行卷积计算,得到第五中间数据;
37、将所述第三中间数据输入至所述tanh层进行数据激活处理,得到第一激活数据;
38、将所述第三中间数据输入至所述sigmoid层进行数据激活处理,得到第二激活数据;
39、对所述第一激活数据和所述第二激活数据进行相乘处理,得到目标激活数据;
40、将所述目标激活数据输入至所述第四卷积层进行卷积计算,得到第六中间数据;
41、对所述第五中间数据和所述第六中间数据进行相加处理,得到所述第四中间数据。
42、为实现上述目的,本技术实施例的第二方面提出了一种基于diffusion的语音合成装置,所述装置包括:
43、声学特征转换模块,用于获取目标语句,将所述目标语句输入至预设的声学模型进行数据转换处理,得到梅尔频谱;
44、模型获取模块,用于获取预先训练好的diffusion声码器,所述diffusion声码器包括全连接层、第一卷积层、第二卷积层和残差块,所述残差块包括多个依次连接的残差层;
45、第一数据处理模块,用于获取预设的时间步长,将所述时间步长输入至所述全连接层,得到第一中间数据;
46、第二数据处理模块,用于获取与所述目标语句对应的目标音频,将所述目标音频和所述梅尔频谱输入至第一卷积层进行卷积计算,得到第二中间数据;
47、第三数据处理模块,用于将所述第一中间数据、第二中间数据和所述梅尔频谱进行相加处理,得到第三中间数据;
48、第四数据处理模块,用于将所述第三中间数据输入至多个依次连接的所述残差层,得到第四中间数据;
49、目标合成语音获取模块,用于将所述第四中间数据输入至所述第二卷积层进行卷积计算,得到目标合成语音。
50、为实现上述目的,本技术实施例的第三方面提出了一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的基于diffusion的语音合成方法。
51、为实现上述目的,本技术实施例的第四方面提出了一种存储介质,所述存储介质为计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述的方法。
52、本技术提出的基于diffusion的语音合成方法、装置、设备、存储介质,其通过获取目标语句,将所述目标语句输入至预设的声学模型进行声学特征提取,得到梅尔频谱;获取预先训练好的diffusion声码器,所述diffusion声码器包括全连接层、第一卷积层、第二卷积层和残差块,所述残差块包括多个依次连接的残差层;获取预设的时间步长,将所述时间步长输入至所述全连接层,得到第一中间数据;获取与所述目标语句对应的目标音频,将所述目标音频和所述梅尔频谱输入至第一卷积层进行卷积计算,得到第二中间数据;将所述第一中间数据、第二中间数据和所述梅尔频谱进行相加处理,得到第三中间数据;将所述第三中间数据输入至多个依次连接的所述残差层,得到第四中间数据;将所述第四中间数据输入至所述第二卷积层进行卷积计算,得到目标合成语音。根据本实施例的技术方案,通过引入diffusion声码器降低了用于模型训练的参数量,从而提高了语音合成的效率。
- 还没有人留言评论。精彩留言会获得点赞!