基于多尺度SincNet和CGAN的端到端说话人辨认方法
本发明属于说话人辨认,特别涉及一种基于多尺度sincnet和cgan的端到端说话人辨认方法。
背景技术:
1、说话人辨认(speaker identification,si)是生物识别技术的一种,它可以根据某段语音从若干已知说话人中辨别是谁在说话,对应于一对多的选择关系。这种任务对人类来说具有很大的挑战性。说话人辨认被广泛应用于众多领域中,主要原因是声纹具有易采集、非接触、特征稳定等优势。随着深度学习的发展,深度神经网络在特征提取和模型分类方面表现突出,为说话人辨认技术的进一步发展指明了新方向。最近,提出的多种识别模型实现了相当高的准确度,但在实际工业应用中仍面临一些挑战。例如,在实际应用中遇到的短话语识别、方言识别、无序语音识别等问题。短语音由于不能提取出充足的区分性信息导致si系统的鲁棒性变差。另外,在有限训练数据约束下,由于无法提取更多有效的说话人特征参数导致过拟合现象发生。特别地,基于深度神经网络的数据驱动建模方法需要海量的训练数据。但是受实际环境的限制,不易获取用户较多的语音数据,无法提取充足的代表说话人特征的信息。
2、传统的说话人辨认实现过程复杂、识别率低,其过程包括语音信号预处理、声学特征提取、分类模型构建和学习模型评价。一般地,建立和应用一个说话人辨认系统需要经历两个阶段,即训练阶段和测试阶段。然而无论是训练还是测试,都需要首先对输入原始信号进行预处理并进行特征提取。在特征提取方面,人们大多数尝试的是基于手工制作的特征设计的,如mel频率倒谱系数(mfcc)和梅尔滤波器组系数(fbank)。reynolds等人利用提取到的声学特征来训练高斯混合模型-通用背景模型(gaussian mixture model-universalbackground model,gmm-ubm),以缓解数据稀疏问题。另外,为了解决信道干扰导致识别性能下降的问题,2006年campbell等人,研究将支持向量机(svm)添加到gmm-ubm中,有效提高了模型识别性能;第二年,kenny等人对联合因子分析进行了深入研究,仅抽取与说话人相关的特性,克服了信道多变性的影响。2010年,dehak等人提出把语音映射到一个固定的、低维的向量上,即用i-vector来表示给定的话语。该方法提高了si系统的鲁棒性和泛化能力。
3、随着深度神经网络(dnns)的发展,研究人员们开始倾向于使用基于dnns的方法来替代传统方法。基于dnns的数据驱动建模方法依赖于大规模的训练数据,而现实中易受环境的限制无法获取用户大量的语音数据。另外,深度学习常常使用的手工特征在转换过程中可能会丢失重要信息,导致识别性能下降。
技术实现思路
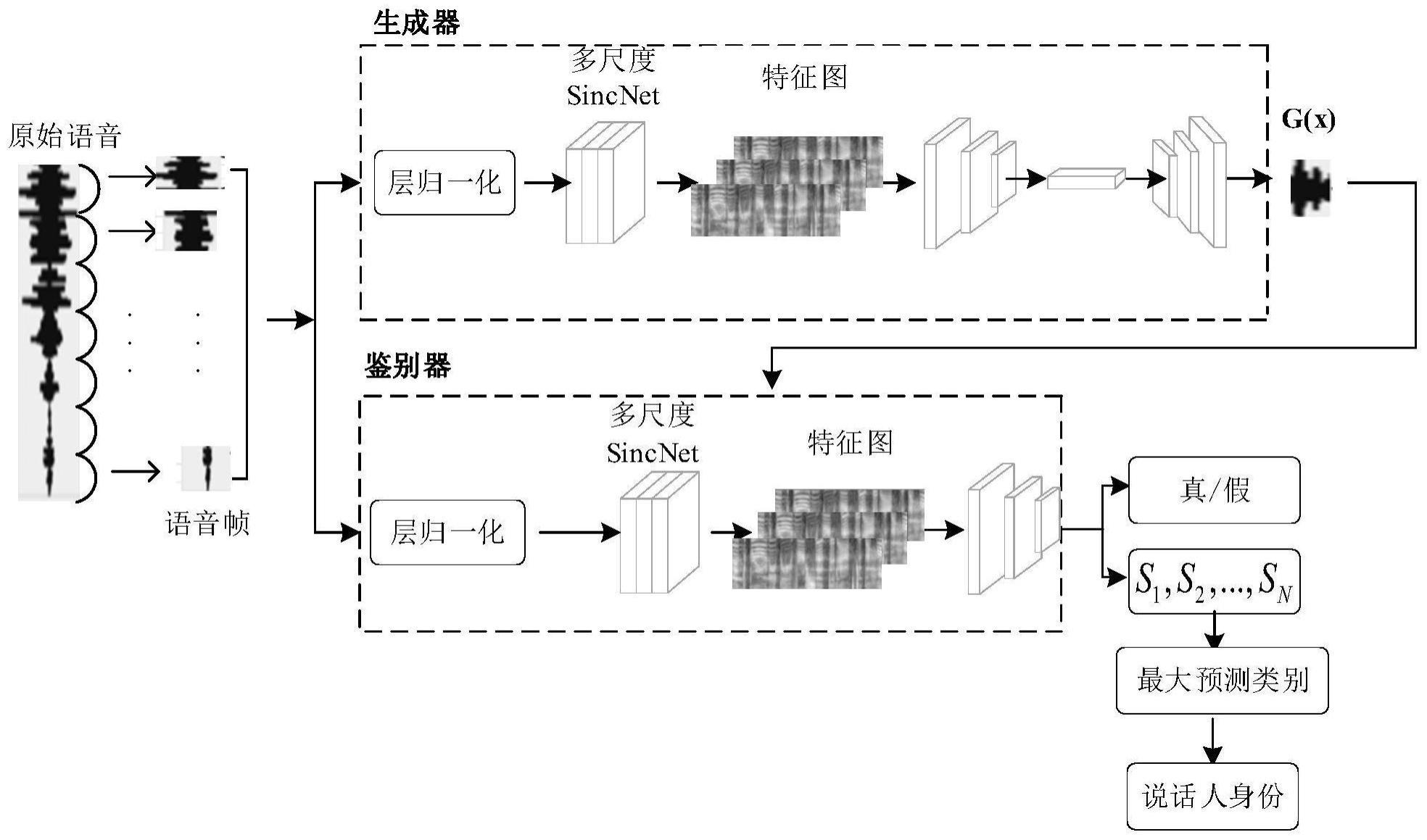
1、本发明的目的在于提出一种基于多尺度sincnet和cgan的端到端说话人辨认方法,通过引入多尺度sincnet直接对输入的原始波形进行识别,避免在手工特征转换时丢失重要的信息,同时利用条件生成对抗网络进行端到端识别,实现用少量的训练语句辨别说话人。
2、本发明为了实现上述目的,采用如下技术方案:
3、基于多尺度sincnet和cgan的端到端说话人辨认方法,包括如下步骤:
4、步骤1.对输入的原始语音信号进行语音分帧预处理操作,得到语音帧,将语音帧作为真实语音样本;将真实语音样本分为训练样本和测试样本,分别用于模型训练和测试;
5、步骤2.搭建说话人辨认模型sincgan;
6、说话人辨认模型sincgan由生成器网络以及鉴别器网络组成;
7、生成器网络包括一个多尺度sincnet层、三个卷积层、两个转置卷积层和一个自适应平均池化层;
8、定义生成器网络中的多尺度sincnet层为第一多尺度sincnet层;定义生成器网络中的三个卷积层分别为第一、第二、第三卷积层,两个转置卷积层分别为第一、第二转置卷积层;
9、真实语音样本在生成器网络中的处理流程如下:
10、真实语音样本首先经过第一多尺度sincnet层进行特征提取,得到语音信号的二维特征,然后语音信号的二维特征依次经过第一卷积层、第二卷积层、第一转置卷积层、第二转置卷积层、第三卷积层以及自适应平均池化层,生成虚假语音样本;
11、鉴别器网络包括一个多尺度sincnet层、五个卷积层、三个瓶颈式残差块堆叠层和四个全连接层;
12、定义鉴别器网络中的多尺度sincnet层为第二多尺度sincnet层;
13、定义鉴别器网络中的五个卷积层分别为第四、第五、第六、第七以及第八卷积层;
14、定义鉴别器网络中的三个瓶颈式残差块堆叠层分别为第一、第二以及第三瓶颈式残差块堆叠层,四个全连接层分别为第一、第二、第三以及第四全连接层;
15、真实语音样本和虚假语音样本在鉴别器网络中的处理流程如下:
16、真实语音样本和虚假语音样本首先经过第二多尺度sincnet层进行特征提取,得到语音信号的二维特征,然后语音信号的二维特征依次经过第四卷积层、第一瓶颈式残差块堆叠层、第五卷积层、第二瓶颈式残差块堆叠层、第六卷积层、第二瓶颈式残差块堆叠层、第七卷积层、第八卷积层、第一全连接层以及第二全连接层;
17、第二全连接层的输出分为两路,一路经过第三全连接层输出真/假标志,另一路经过第四全连接层输出n维向量,分别对应于真实语音样本的说话人类别标签;
18、鉴别器网络输出的n维向量输入到softmax函数中,通过将输出的向量映射到概率分布上,将最大概率预测类别的说话人类别标签作为预测输出;
19、步骤3.利用步骤1中的真实语音样本对步骤2搭建的说话人辨认模型sincgan进行训练,通过反向传播优化说话人辨认模型的参数以最小化损失函数,得到训练好的说话人辨认模型sincgan;
20、步骤4.利用训练好的sincgan对给定的语音信号进行预测,输出对应的说话人标签。
21、此外,在上述基于多尺度sincnet和cgan的端到端说话人辨认的基础上,本发明还提出了一种计算机设备,该计算机设备包括存储器和一个或多个处理器。
22、所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,用于实现上面述及的基于多尺度sincnet和cgan的端到端说话人辨认的步骤。
23、此外,在上述基于多尺度sincnet和cgan的端到端说话人辨认的基础上,本发明还提出了一种计算机可读存储介质,其上存储有程序。该程序被处理器执行时,用于实现上面述及的基于多尺度sincnet和cgan的端到端说话人辨认的步骤。
24、本发明具有如下优点:
25、如上所述,本发明述及了一种基于多尺度sincnet和cgan的端到端说话人辨认方法。本发明方法中引入多尺度sincnet,避免了在手工特征转换时丢失重要的信息,多尺度sincnet根据三个定制滤波器组来捕获波形中三个通道的低级语音表示,使sincgan模型更好地捕获重要的窄带说话人特征。本发明方法基于改进的条件生成对抗网络进行端到端识别,实现了用少量的训练语句辨别说话人,本发明损失函数包括经典gan的对抗损失和分类任务的分类交叉熵损失。实验结果表明,在timit和librispeech语料库上,本发明模型表现出更好的性能。在缺乏训练数据以时,本发明模型表现出比基线方法更强的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!